
Chapter 2. Basic types
This chapter covers
- Common primitive types and their uses
- How Boolean expressions are evaluated
- Pitfalls of numerical types and text encoding
- Fundamental types for building data structures
Computers represent data internally as sequences of bits. Types give meaning to these sequences. At the same time, types restrict the range of possible values any piece of data can take. Type systems provide a set of primitive or built-in types and a set of rules for combining these types.
In this chapter we will look at some of the commonly available primitive types (empty, unit, Booleans, numbers, strings, arrays, and references), their uses, and common pitfalls to be aware of. Although we use primitive types every day, each comes with subtle nuances we must be aware of to use them effectively. Boolean expressions can be short-circuited, for example, and numerical expressions can overflow.
We’ll start with some of the simplest types, which carry little or no information, and move on to types that represent data via various encodings. Finally, we’ll look at arrays and references, which are building blocks for all other more-complex data structures.
2.1. Designing functions that don’t return values
Viewing types as sets of possible values, you may wonder whether there is a type to represent the empty set. The empty set has no elements, so this would be a type for which we can never create an instance. Would such a type be useful?
2.1.1. The empty type
As part of a utility library, let’s see how we would define a function that, given a message, logs the fact that an error occurred, including a timestamp and the message, and then throws an exception, as shown in the next listing. Such a function is a wrapper over throw, so it is not meant to return a value.
Listing 2.1. Raising and logging an error if a config file is not found
const fs = require("fs");
function raise(message: string): never { 1
console.error(`Error "${message}" raised at ${new Date()}`);
throw new Error(message);
}
function readConfig(configFile: string): string {
if (!fs.existsSync(configFile)) 2
raise(`Configuration file ${configFile} missing`); 3
return fs.readFileSync(configFile, "utf-8");
}
- 1 The function never returns (always throws), so its return type is never.
- 2 Example use: if a config file is not found, we want to log and throw an error.
Note that the return type of the function in the example is never. This makes it clear to readers of the code that raise() is never meant to return. Even better, if someone accidentally updates the function later and makes it return, the code no longer compiles. Absolutely no value can be assigned to never, so the compiler ensures that the function keeps behaving as designed and never returns.
Such a type is named an uninhabitable type or empty type because no instance of it can be created.
Empty Type
An empty type is a type that cannot have any value: its set of possible values is the empty set. We can never instantiate a variable of such a type. We use an empty type to denote impossibility, such as by using it as the return type of a function that never returns (throws or loops forever).
An uninhabitable type is used to declare a function that never returns. A function might not return for several reasons: it might throw an exception on all code paths, it might loop forever, or it might crash the program. All these scenarios are valid. We might want to implement a function that does some logging or sends some telemetry before throwing an exception or crashing in case of unrecoverable error. We can have code that we want to run continuously on a loop until the whole system is shut down, such as the event-processing loop of the system.
Declaring such a function as returning void, which is the type used by most programming languages to indicate the absence of a meaningful value, is misleading. Our function not only doesn’t return a meaningful value, but also doesn’t return at all!
The empty type might seem trivial, but it shows a fundamental difference between mathematics and computer science: in mathematics, we cannot define a function from a nonempty set to an empty set. This simply doesn’t make sense. Functions in mathematics are not “evaluated”; they simply “are.”
Computers, on the other hand, evaluate programs; they execute instructions step by step. Computers can end up evaluating an infinite loop, which means that they would never stop their execution. For this reason, a computer program can define a meaningful function to the empty set, as in the preceding examples.
Consider using an empty type whenever you have a nonreturning function or otherwise want to explicitly show that it’s impossible to have a value.
DIY empty type
Not all mainstream languages provide a built-in empty type like never in TypeScript, but you can implement one in most of them. You can do this by defining an enumeration with no elements or a structure with only a private constructor such that it can never be called.
Listing 2.2 shows how we would implement an empty type in TypeScript as a class that can’t be instantiated. Note that TypeScript considers two types to be compatible if they have similar structure, so we need to add a dummy void property to ensure that other code cannot end up with a value that can be typed as Empty. Other languages, such as Java and C#, would not need this additional property, as they wouldn’t consider types to be compatible based on shape. We’ll cover this in more detail in chapter 7.
Listing 2.2. Empty type implemented as an uninstantiable class
declare const EmptyType: unique symbol; 1
class Empty {
[EmptyType]: void; 1
private constructor() { } 3
}
function raise(message: string): Empty { 3
console.error(`Error "${message}" raised at ${new Date()}`);
throw new Error(message);
}
- 1 A TypeScript-specific way to ensure that other objects with the same shape can’t be interpreted as this type
- 2 Private constructor ensures that other code cannot instantiate this type
- 3 This function is the same as in the previous example, this time using Empty instead of never.
The code compiles, as the compiler performs control flow analysis and determines no return statement is needed. On the other hand, it should be impossible to add a return statement, as we cannot create an instance of Empty.
2.1.2. The unit type
In the previous section, we looked at functions that never return. What about functions that do return but don’t return anything useful? There are many functions like this, which we call only for their side effects: they do something, change some external state, but don’t perform any useful computation to return to us.
Let’s take console.log() as an example: it outputs its argument to the debug console, but doesn’t return anything meaningful. On the other hand, the function does return control to the caller when it finishes executing, so its return type can’t be never.
The classic "Hello world!" function shown in the next listing is another good example. We call it to print a greeting (which is a side effect), not to return a value, so we specify its return value as void.
Listing 2.3. A “Hello world!” function
function greet(): void { 1
console.log("Hello world!");
}
greet(); 2
- 1 The function prints a greeting and doesn’t return anything useful.
- 2 We usually just ignore the result of such functions.
The return type of such a function is called a unit type, a type that allows just one value, and its name in TypeScript and most other languages is void. The reason why we usually don’t have variables of type void and can simply return from a void function without providing an actual value is that the value of a unit type is not important.
Unit Type
A unit type is a type that has only one possible value. If we have a variable of such a type, there is no point in checking its value; it can only be the one value. We use unit types when the result of a function is not meaningful.
Functions that take any number of arguments but don’t return any meaningful value are also called actions (because they usually perform one or more operations that change the state of the world) or consumers (because arguments go in but nothing comes out).
DIY unit type
Although a type like void is available in most programming languages, some languages treat void in a special way and may not allow you to use it exactly the same way as any other type. In such situations, you can create your own unit type by defining an enumeration with a single element or a singleton without state. Because a unit type has only one possible value, it doesn’t really matter what that value is; all unit types are equivalent. It’s trivial to convert from one unit type to another, as there is no choice to be made: the single value of one type maps to the single value of the other one.
Listing 2.4 shows how we would implement a unit type in TypeScript. As for the DIY empty type, we are using a void property to ensure that another type with a compatible structure is not implicitly converted to Unit. Other languages, such as Java and C#, would not need this additional property.
Listing 2.4. Unit type implemented as a singleton without state
declare const UnitType: unique symbol;
class Unit {
[UnitType]: void; 1
static readonly value: Unit = new Unit(); 2
private constructor() { }; 3
}
function greet(): Unit { 4
console.log("Hello world!");
return Unit.value; 4
}
- 1 Unique symbol property ensures that types with similar shape cannot be interpreted as Unit.
- 2 Static read-only property of type Unit is the only possible instance of Unit.
- 3 Private constructor ensures that other code cannot instantiate this type.
- 4 Equivalent to a function returning void, this always returns exactly the same value.
2.1.3. Exercises
What should be the return type of a set() function that takes a value and assigns it to a global variable?
- never
- undefined
- void
- any
What should be the return type of a terminate() function that immediately stops execution of the program?
2.2. Boolean logic and short circuits
After types with no possible values (empty types such as never) and types with one possible value (unit types such as void), come types with two possible values. The canonical two-valued type, available in most programming languages, is the Boolean type.
Boolean values encode truthiness. The name comes from George Boole, who introduced what is now called Boolean algebra, an algebra consisting of truth (1) and falseness (0) values and logical operations on them such as AND, OR, and NOT.
Some type systems provide Booleans as a built-in type with values true and false. Other systems rely on numbers, considering 0 to mean false and any other number to mean true (that is, whatever is not false is true). TypeScript has a built-in boolean type with possible values true and false.
Regardless of whether a primitive Boolean type exists or truthiness values are inferred from values of other types, most programming languages use some form of Boolean semantics to enable conditional branching. A statement such as if (condition) { ... } will execute the part between curly brackets only if the condition evaluates to something true. Loops rely on conditions to determine whether to iterate or finish: while (condition) { ... }. Without conditional branching, we wouldn’t be able to write very useful code. Think about how you would implement a very simple algorithm, such as finding the first even number in a list of numbers, without any loops or conditional statements.
2.2.1. Boolean expressions
Many programming languages use the following symbols for common Boolean operations: && for AND, || for OR, and ! for NOT. Boolean expressions are usually described with truth tables (figure 2.1).
Figure 2.1. AND, OR, and NOT truth tables

2.2.2. Short circuit evaluation
Suppose that you must build a gatekeeper for a commenting system as shown in listing 2.5: as users attempt to post comments, the gatekeeper rejects comments posted within 10 seconds of each other (the user is spamming) and comments with empty contents (the user accidentally clicked Comment before typing anything).
The gatekeeper function takes as arguments the comment and the user ID. You have a secondsSinceLastComment() function already implemented; this function, given the user ID, queries the database and returns the number of seconds since the last post.
If both conditions are met, post the comment to the database; if not, return false.
Listing 2.5. Gatekeeper
declare function secondsSinceLastComment(userId: string): number; 1
declare function postComment(comment: string, userId: string): void; 2
function commentGatekeeper(comment: string, userId: string): boolean {
if ((secondsSinceLastComment(userId) < 10) || (comment == "")) 3
return false;
postComment(comment, userId);
return true;
}
- 1 secondsSinceLastComment queries the database for the age of the user’s last post.
- 2 postComment writes the comment to the database.
- 3 If one of the conditions isn’t met, return false. Otherwise, post comment and return true.
Listing 2.5 is a possible implementation of the gatekeeper. Note the OR expression where we return false if either the age of the last comment in seconds is less than 10 or the current comment is empty.
Another way to implement the same logic is to switch the two operands, as shown in the following listing. First check whether the current comment is empty; then check the age of the last posted comment, as in listing 2.5.
Listing 2.6. Alternative gatekeeper implementation
declare function secondsSinceLastComment(userId: string): number;
declare function postComment(comment: string, userId: string): void;
function commentGatekeeper(comment: string, userId: string): boolean {
if ((comment == "") || (secondsSinceLastComment(userId) < 10)) 1
return false;
postComment(comment, userId);
return true;
}
- 1 The only difference between this version and the previous one is the flipped conditions.
Is one version better in any way than the other? They define the same checks—just in a different order. As it turns out, they are different. Depending on the input received, they behave differently at run time due to the way Boolean expressions are evaluated.
Most compilers and run times perform an optimization called short circuit for Boolean expressions. Expressions of the form a AND b are translated to if a then b else false. This respects the truth table for AND: if the first operand is false, then regardless of what the second operand is, the whole expression is false. On the other hand, if the first operand is true, then the whole expression is true if the second operand is also true.
A similar translation happens for a OR b, which becomes if a then true else b. Looking at the truth table for OR, if the first operand is true, then the whole expression is true regardless of what the second operand is; otherwise, if the first operand is false, then the expression is true if the second operand is true.
The reason for this translation and the name short circuit come from the fact that if evaluating the first operand provides enough information to evaluate the whole expression, the second operand is not evaluated at all. The gatekeeper function must perform two checks: a relatively inexpensive one, to make sure that the comment it receives is not empty, and a potentially expensive one, which involves querying the comment database. In listing 2.5, the database query happens first. If the last posted comment is more recent than 10 seconds, short-circuiting will not even look at the current comment and will simply return false. In listing 2.6, if the current comment is empty, the database doesn’t get queried. The second version can potentially skip an expensive check by evaluating a cheap check.
This property of Boolean expression evaluation is important and something to remember when you are combining conditions: short-circuiting can skip evaluation of the expression on the right, depending on the result of evaluating the expression on the left, so prefer ordering conditions from cheapest to most expensive.
2.2.3. Exercise
What will the following code print?
let counter: number = 0; function condition(value: boolean): boolean { counter++; return value; } if (condition(false) && condition(true)) { // ... } console.log(counter)
- 0
- 1
- 2
- Nothing; it throws an error.
2.3. Common pitfalls of numerical types
Numbers are usually provided as one or more primitive types in most programming languages. There are several gotchas you should be aware of when working with numbers. Take, for example, a simple function that adds up a shopping total. If a user purchases three sticks of bubble gum at 10 cents each, we would expect the total to be 30 cents. Depending on how we use numerical types, we might be in for a surprise.
Listing 2.7. Function adding up item total
type Item = { name: string, price: number }; 1
function getTotal(items: Item[]): number { 2
let total: number = 0;
for (let item of items) {
total += item.price;
}
return total;
}
let total: number = getTotal(
[{ name: "Cherry bubblegum", price: 0.10 }, 3
{ name: "Mint bubblegum", price: 0.10 }, 3
{ name: "Strawberry bubblegum", price: 0.10 }] 3
);
console.log(total == 0.30); 4
- 1 We represent an item by a name and a price (number).
- 2 The getTotal function returns a number as the total.
- 3 Compute total for three sticks of bubble gum, 10 cents each.
- 4 This prints “false,” even though we would expect 0.10 + 0.10 + 0.10 to be 0.30.
Why does adding up 0.10 three times not give us 0.30? To understand this, we need to look at how numerical types are represented by computers. The two defining characteristics of a numerical type are its width and its encoding.
The width is the number of bits used to represent a value. This can range from 8 bits (a byte) or even 1 bit up to 64 bits or more. Bit widths have a lot to do with the underlying chip architecture: a 64-bit CPU has 64-bit registers, thus allowing extremely fast operations on 64-bit values. There are three common ways to encode numbers of a given width: unsigned binary, two’s complement, and IEEE 754.
2.3.1. Integer types and overflow
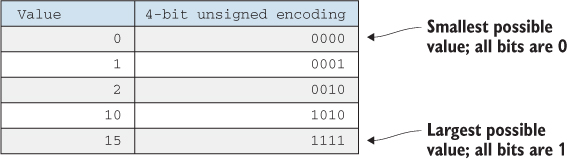
An unsigned binary encoding uses every bit to represent part of the value. A 4-bit unsigned integer, for example, can represent any value from 0 to 15. In general, an N-bit unsigned integer can represent values from 0 (all bits are 0) up to 2N-1 (all bits are 1). Figure 2.2 shows a few possible values of a 4-bit unsigned integer. You can convert a sequence of N binary digits (bN–1bN–2...b1b0) to a decimal number with the formula bN–1 * 2N–1 + bN–2 * 2N–2 + ... + b1 * 21 + b0 * 20.
Figure 2.2. 4-bit unsigned integer encoding. Smallest possible value, when all 4 bits are 0, is 0. Largest possible value, when all bits are 1, is 15 (1 * 23 + 1 * 22 + 1 * 21 + 1 * 20).
This encoding is very straightforward but can represent only positive numbers. If we also want to represent negative numbers, we need a different encoding, which is usually two’s complement. In two’s complement encoding, we reserve a bit to encode the sign. Positive numbers are represented exactly as before, whereas negative numbers are encoded by subtracting their absolute value from 2N, where N is the number of bits. Figure 2.3 shows a few possible values of a 4-bit signed integer.
Figure 2.3. 4-bit signed integer encoding. –8 is encoded as 24 – 8 (1000 binary), and –3 is encoded as 24 – 3 (1101 binary). The first bit is always 1 for negative numbers and 0 for positive numbers.

With this encoding, all negative numbers have the first bit 1, and all positive numbers and 0 have the first bit 0. A 4-bit signed integer can represent values from –8 to 7. The more bits we use to represent a value, the larger the value range we can represent.
Overflow and underflow
What happens, though, when the result of an arithmetic operation can’t be represented within the given number of bits? What if we are using a 4-bit unsigned encoding and try to add 10 + 10, even though the maximum value we can represent in 4 bits is 15?
Such a situation is called an arithmetic overflow. The opposite situation, in which we end up with a number that is too small to represent, is called an arithmetic underflow. Different languages treat these situations in different ways (figure 2.4).
The three main ways to handle arithmetic overflow and underflow are to wrap around, saturate, or error out.
Figure 2.4. Different ways to handle arithmetic overflow. An odometer wraps around from 999999 back to 0; a dial knob simply stops at the maximum possible value; a pocket calculator prints Error and stops.

Wrap around is what the hardware usually does, as it simply discards the bits that don’t fit. For a 4-bit unsigned integer, if the bits are 1111 and we add 1, the result is 10000, but because only 4 bits are allowed, one gets discarded, and we end up with 0000, wrapping back around to 0. This is the most efficient way to handle overflow but also the most dangerous, as it can cause unexpected results. Adding $1 to my $15, I can end up with $0.
Saturation is another way to handle overflow. If the result of an operation exceeds the maximum representable value, we simply stop at the maximum. This maps well to the physical world: if your thermostat only goes up to some temperature, trying to make it warmer won’t change that. On the other hand, using saturation, arithmetic operations are no longer always associative. If 7 is our maximum value, 7 + (2 – 2) = 7 + 0 = 7 but (7 + 2) – 2 = 7 – 2 = 5.
The third possibility, error out, is to throw an error when an overflow happens. This is the safest approach but has the drawback that every single arithmetic operation needs to be checked, and whenever you perform any arithmetic, your code needs to handle exceptional cases.
Detecting overflow and underflow
Depending on the language you are using, arithmetic overflows and underflows could be handled in any one of these ways. If your scenario requires different handling from the language default, you need to check whether an operation would overflow or underflow and handle that scenario separately. The trick is to do this within the range of allowed values.
To check whether adding values a and b would overflow or underflow a [MIN, MAX] range, for example, we need to ensure that we don’t have a + b < MIN (when adding two negative numbers) or a + b > MAX.
If b is positive, we can’t possibly have a + b < MIN, as we’re making a bigger, not smaller. In this case, we only need to check for overflow. We can rewrite a + b > MAX as a > MAX – b (subtract b on both sides). Because we’re subtracting a positive number, we are making the value smaller, so there is no risk of overflowing (MAX – b is within the [MIN, MAX] range). So we overflow if b > 0 and a > MAX – b.
If b is negative, we can’t possibly have a + b > MAX, as we’re making a smaller, not bigger. In this case, we only need to check for underflow. We can rewrite a + b < MIN as a < MIN – b (subtract b on both sides). Because we’re subtracting a negative number, we are making the value larger, so there is no risk of underflowing (MIN – b is within the [MIN, MAX] range). So we underflow if b < 0 and a < MIN – b, as shown in the next listing.
Listing 2.8. Checking for addition overflow
function addError(a: number, b: number,
min: number, max: number): boolean { 1
if (b >= 0) {
return a > max - b; 2
} else {
return a < min - b; 3
}
}
- 1 The function takes the numbers a and b, and the minimum and maximum allowed values.
- 2 If b is positive, we have an overflow if a > max – b.
- 3 If b is negative, we have an underflow if a < min – b.
We can use similar logic for subtraction.
For multiplication, we check for overflow and underflow by dividing on both sides by b. Here, we need to consider the signs of both numbers, as multiplying two negative numbers yields a positive number, whereas multiplying a positive and a negative number yields a negative number.
We overflow if
- b > 0, a > 0, and a > MAX / b
- b < 0, a < 0, and a < MAX / b
We underflow if
- b > 0, a < 0, and a < MIN / b
- b < 0, a > 0, and a > MIN / b
For integer division, the value of a / b is always an integer whose value is between - a and a. We only need to check for overflow and underflow if [-a,a] is not fully within [MIN,MAX]. Going back to our 4-bit signed integer example, where MIN is –8 and MAX is 7, the only case where division overflows is –8 / –1 (because [–8,8] is not fully within [–8,7]). In fact, for signed integers, the only overflow scenario is when a is the minimum representable value and b is –1. Unsigned integer division can never overflow.
Tables 2.1 and 2.2 summarize the steps necessary to check for overflow and underflow when special handling is required.
Table 2.1. Detecting integer overflow for a and b in a [MIN, MAX] range with MIN = –MAX-1
|
Subtraction |
Multiplication |
Division |
|
|---|---|---|---|
| b > 0 and a > MAX – b | b < 0 and a > MAX + b | b > 0, a > 0, and a > MAX / b b < 0, a < 0, and a < MAX / b | a == MIN and b == -1 |
Table 2.2. Detecting integer underflow for a and b in [MIN, MAX] range with MIN = –MAX-1
|
Addition |
Subtraction |
Multiplication |
Division |
|---|---|---|---|
| b < 0 and a < MIN – b | b > 0 and a < MIN + b | b > 0, a < 0, and a < MIN / b b < 0, a > 0, and a > MIN / b | N/A |
2.3.2. Floating-point types and rounding
IEEE 754 is the Institute of Electrical and Electronics Engineers standard for representing floating-point numbers, or numbers with a fractional part. In TypeScript (and JavaScript), numbers are represented as 64-bit floating-point using the binary64 encoding. Figure 2.5 details this representation.
Figure 2.5. Floating-point representation of 0.10. First, we see the in-memory binary representation of the three components: sign bit, exponent, and mantissa. Below, we have the formula to convert the binary representation to a number. Finally, we see the result of applying the formula: 0.10 is approximated to 0.100000000000000005551115123126.

The three components of a floating-point number are the sign, the exponent, and the mantissa. The sign is a single bit that is 0 for positive numbers or 1 for negative numbers. The mantissa is a fraction as described by the formula in figure 2.2. This fraction is multiplied by 2 raised to the biased exponent.
The exponent is called biased because from the unsigned integer represented by the exponent, we subtract a value so that it can represent both positive and negative numbers. In the binary64 case, the value is 1023. The IEEE 754 standard defines several encodings, some using base 10 instead of base 2, though base 2 appears more often in practice.
The standard also defines special values:
- NaN, which stands for not a number and is used to represent the result of invalid operations, such as division by 0.
- Positive and negative infinity (Inf), which are used when operations overflow as saturation values
- Even though 0.10 becomes 0.100000000000000005551115123126 according to the formula, it is rounded down to 0.1. In fact, 0.10 and 0.100000000000000005551115123126 compare as equal in JavaScript. The only way floating-point can represent fractional numbers across a huge range of values using a relatively small number of bits is by rounding and approximating.
Precision values
If precision is needed—in dealing with currency, for example—avoid using floating-point numbers. The reason why adding 0.10 together three times doesn’t equal 0.30 is that although each individual 0.10 representation gets rounded to 0.10, adding them yields a number that rounds to 0.30000000000000004.
Small integer numbers can safely be represented without rounding, so it is a better idea to encode a price as a pair of dollars and cents integers. JavaScript provides Number.isSafeInteger(), which tells us whether an integer value can be represented without rounding, so relying on that, we can design a Currency type that encodes two integer values and protects against rounding issues, as the next listing shows.
Listing 2.9. Currency class and currency addition function
class Currency {
private dollars: number; 1
private cents: number; 1
constructor(dollars: number, cents: number) {
if (!Number.isSafeInteger(dollars)) 2
throw new Error("Cannot safely represent dollar amount");
if (!Number.isSafeInteger(cents)) 2
throw new Error("Cannot safely represent cents amount");
this.dollars = dollars;
this.cents = cents;
}
getDollars(): number { 3
return this.dollars;
}
getCents(): number { 3
return this.cents;
}
}
function add(currency1: Currency, currency2: Currency): Currency {
return new Currency(
currency1.getDollars() + currency2.getDollars(), 4
currency1.getCents() + currency2.getCents()); 4
}
- 1 We store dollars and cents amounts in separate variables.
- 2 Constructor ensures that we store only values that can be safely represented without rounding.
- 3 The amounts are accessed via getters, so external code cannot modify them.
- 4 Adding two Currency values simply adds the dollar and cents amounts.
In another language we would’ve used two integer types and protected against overflow/underflow. Because JavaScript does not provide an integer primitive type, we rely on Number.isSafeInteger() to protect against rounding. When dealing with currency, it’s better to error out than to have money mysteriously appear or disappear.
The class in listing 2.9 is still pretty bare-bones. A good exercise is to extend it so that every 100 cents gets automatically converted to a dollar. You must be careful about where to check for safe integers: what if the dollar amount is a safe integer but adding 1 to it (from 100 cents) makes it unsafe?
Comparing floating-point numbers
As we’ve seen, because of rounding, it’s usually not a good idea to compare floating-point numbers for equality. There is a better way to tell whether two values are approximately the same: we can make sure that their difference is within a given threshold.
What should this threshold be? It should be the maximum possible rounding error. This value is called a machine epsilon and is encoding-specific. JavaScript provides this value as Number.EPSILON. Using this value, we can implement an equality comparison between two numbers, taking the absolute value of their difference and checking whether it is smaller than the machine epsilon. If it is, the values are within rounding error of each other, so we can consider them equal.
Listing 2.10. Floating-point equality within epsilon
function epsilonEqual(a: number, b: number): boolean {
return Math.abs(a - b) <= Number.EPSILON; 1
}
console.log(0.1 + 0.1 + 0.1 == 0.3); 2
console.log(epsilonEqual(0.1 + 0.1 + 0.1, 0.3)); 3
- 1 Check whether the two numbers are within rounding error of each other.
- 2 Prints “false” because 0.1 + 0.1 + 0.1 rounds to 0.30000000000000004.
- 3 Prints “true” because 0.3 and 0.30000000000000004 are within rounding error of each other.
It’s a good idea in general to use something like epsilonEqual() whenever comparing two floating-point numbers, as arithmetic operations can cause rounding errors that lead to unexpected results.
2.3.3. Arbitrarily large numbers
Most languages have libraries that provide arbitrarily large numbers. These types extend their width to as many bits as needed to represent any value. Python provides such a type as the default numerical type, and an arbitrarily large BigInt type is currently proposed for standardization for JavaScript. That being said, we won’t treat arbitrarily large numbers as primitive types because they can be built out of fixed-width numerical types. They are convenient, but many run times do not provide them natively, as there is no hardware equivalent. (Chips always operate on a fixed number of bits.)
2.3.4. Exercises
What will the following code print?
let a: number = 0.3; let b: number = 0.9; console.log(a * 3 == b);
- Nothing; it throws an error.
- true
- false
- 0.9
What should be the overflow behavior of a number that tracks unique identifiers?
- Saturate on overflow.
- Wrap around on overflow.
- Error on overflow.
- Any of them is OK.
2.4. Encoding text
Another common primitive type is the string, which is used to represent text. A string consists of zero or more characters, which makes it the first primitive type we are covering that can have an infinite set of values.
In the early days of computers, each character was represented by a single byte, so computers had at most 256 characters available to represent text. With the standardization of Unicode, which aims to provide a way to represent all the world’s alphabets and other characters (such as emojis), 256 characters obviously are not enough. In fact, Unicode defines more than one million characters!
2.4.1. Breaking text
Let’s take as an example a simple text-breaking function that takes a string and splits it into multiple strings of a given length so that it can fit within the width of a text-editor control, as shown in the following code.
Listing 2.11. Simple text-breaking function
function lineBreak(text: string, lineLength: number): string[] {
let lines: string[] = []; 1
while (text.length > lineLength) { 2
lines.push(text.substr(0, lineLength)); 3
text = text.substr(lineLength); 3
}
lines.push(text); 4
return lines;
}
- 1 The lines array will contain the split text.
- 2 Repeat as long as the length of the text is larger than the length of a line.
- 3 Add the first lineLength characters of text as a new line; then chop them from the text.
- 4 Add the remaining text (smaller than lineLength) to the result as the final line.
At first look, this implementation seems to be correct. For input text such as "Testing, testing" and a line length of 5, the resulting lines are ["Testi", "ng, t", "estin", "g"]. This is what we expect, as the text is divided into multiple lines at every fifth character.
Other symbols have more complex encodings, though. Take, for example, “![]() ”, the woman police-officer emoji. Even though this looks like a single character, Java-Script represents it with five characters.
"
”, the woman police-officer emoji. Even though this looks like a single character, Java-Script represents it with five characters.
"![]() ".length returns 5. If we try to break a string containing this emoji, depending on where it appears in the text, we can get unexpected results.
If we try to break the text “...
".length returns 5. If we try to break a string containing this emoji, depending on where it appears in the text, we can get unexpected results.
If we try to break the text “...![]() ” with a line length of 5, we get back the array ["...
” with a line length of 5, we get back the array ["...![]() ", "
", "![]() "].
"].
The woman police-officer emoji is composed of two separate emojis: the police-officer emoji and the female-sign emoji. The two emojis are combined with the zero-width joined character "ud002". This character does not have a graphical representation; rather, it is used for combining other characters.
The police-officer emoji, “![]() ”, is represented with two adjacent characters, as we can observe if we try to split the longer string “....
”, is represented with two adjacent characters, as we can observe if we try to split the longer string “....![]() ” with a line length of 5. This ends up splitting the police-officer emoji, giving us ["....ud83d", "udc6e
” with a line length of 5. This ends up splitting the police-officer emoji, giving us ["....ud83d", "udc6e![]() "]. uXXXX are Unicode escape sequences that represent a character that cannot be printed as is. The woman police-officer emoji, even
though it gets rendered as a single symbol, is represented by the five distinct escape sequences ud83d, udc6e, u200d, u2640, and ufe0e.
"]. uXXXX are Unicode escape sequences that represent a character that cannot be printed as is. The woman police-officer emoji, even
though it gets rendered as a single symbol, is represented by the five distinct escape sequences ud83d, udc6e, u200d, u2640, and ufe0e.
Naïvely breaking text at character boundaries can give results that can’t be rendered and can even change the meaning of the text.
2.4.2. Encodings
We need to look at character encodings to better understand how to handle text properly. The Unicode standard works with two similar but distinct concepts: characters and graphemes. Characters are the computer representations of text (police-officer emoji, zero-width joiner, and female sign), and graphemes are the symbols users see (woman police officer). When rendering text, we work with graphemes, and we don’t want to break apart a multiple-character grapheme. When encoding text, we work with characters.
Glyphs and Graphemes
A glyph is a particular representation of a character. “C” (bold) and “C” (italic) are two different visual renderings of the character “C”.
A grapheme is an indivisible unit, which would lose its meaning if it were split into components, such as the woman police-officer example. A grapheme can be represented by various glyphs. The Apple emoji for woman police officer looks different from the Microsoft one; they are different glyphs rendering the same grapheme (figure 2.6).
Figure 2.6. Character encoding of the woman police-officer emoji (police-officer emoji character + zero-width joiner + female sign emoji) and resulting grapheme (woman police officer).

Each Unicode character is defined as a code point. This is a value between 0x0 and 0x10FFFF, so there are 1,114,111 possible code points. These code points represent all the world’s alphabets, emojis, and many other symbols, with plenty of room for future additions.
UTF-32
The most straightforward way of encoding these code points is UTF-32, which uses 32 bits for each character. A 32-bit integer can represent values between 0x0 and
0xFFFFFFFF, so it can fit any code point with room to spare. The problem with UTF-32 is that it’s very inefficient, as it wastes a lot of space with unused bits. Because of that, several more compact encodings were developed that use fewer bits for smaller code points and more bits as the values get larger. These are also called variable-length encodings.
UTF-16 and UTF-8
The most commonly used encodings are UTF-16 and UTF-8. UTF-16 is the encoding used by JavaScript. In UTF-16, the unit is 16 bits. Code points that fit in 16 bits (from 0x0 to 0xFFFF) are represented with a single 16-bit integer, whereas code points that require more than 16 bits (from 0x10000 to 0x10FFFF) are represented by two 16-bit values.
UTF-8, the most popular encoding, takes this approach a step further: the unit is 8 bits and code points are represented by one, two, three, or four 8-bit values.
2.4.3. Encoding libraries
Text encoding and manipulation is a complex topic, with whole books dedicated to it. The good news is that you don’t need to learn all the details to effectively work with strings, but you do need to be aware of the complexity and look for opportunities to replace naïve text manipulation, as in our text-breaking example, with calls to libraries that encapsulate this complexity.
grapheme-splitter, for example, is a JavaScript text library that works with both characters and graphemes. You can install it by running npm install grapheme-splitter. With grapheme-splitter, we can implement the lineBreak() function to break the text at grapheme level by splitting the text into an array of graphemes and then grouping them in strings of lineLength graphemes, as the following listing shows.
Listing 2.12. Text-breaking function using grapheme-splitter library
import GraphemeSplitter = require("grapheme-splitter");
const splitter = new GraphemeSplitter();
function lineBreak(text: string, lineLength: number) {
let graphemes: string[] = splitter.splitGraphemes(text); 1
let lines: string[] = [];
for (let i = 0; i < graphemes.length; i += lineLength) { 2
lines.push(graphemes.slice(i, i + lineLength).join("")); 2
}
return lines;
}
- 1 The splitGraphemes function splits a string into an array of graphemes.
- 2 We then get slices of lineLength graphemes and join them into lines of text.
With this implementation, the strings “...![]() ” and “....
” and “....![]() ” for a line length of 5 do not split the string at all, as none of the strings is larger than five graphemes, and the string “.....
” for a line length of 5 do not split the string at all, as none of the strings is larger than five graphemes, and the string “.....![]() ” correctly gets split into [".....", "
” correctly gets split into [".....", "![]() "].
"].
The grapheme-splitter library helps prevent one of the three common classes of errors in dealing with strings:
- Manipulating encoded text at character level instead of grapheme level—This example was covered in section 2.4.1, where we broke text at character level, even though for rendering purposes we wanted to break it at the grapheme level. Breaking at the fifth character can split a grapheme into multiple graphemes. When displaying text, we also need to be aware of how sequences of characters combine into graphemes.
- Manipulating encoded text at byte level instead of character level—This situation happens when we incorrectly handle a sequence of variable-length encoded text without being aware of the encoding, in which case we might split a character into multiple characters by, for example, breaking at the fifth byte even though we meant to break at the fifth character. Depending on the encoding of the actual character, it might take up one or more bytes, so we shouldn’t make any assumptions that ignore encoding.
- Interpreting a sequence of bytes as text with the wrong encoding (such as trying to interpret UTF-16 encoded text as UTF-8 encoded, or vice-versa)—When receiving text from another component as a sequence of bytes, you must know what encoding the text uses. Different languages have different default encodings for text, so simply interpreting byte sequences as strings may give you wrong interpretations.
Figure 2.7 shows how the woman police-officer grapheme is composed out of two Unicode characters. The figure also shows their UTF-16 encoding and binary representation.
Figure 2.7. Woman police-officer emoji viewed as UTF-16 string encoding of bits in memory, UTF-16 byte sequence, sequence of Unicode code points, and grapheme.
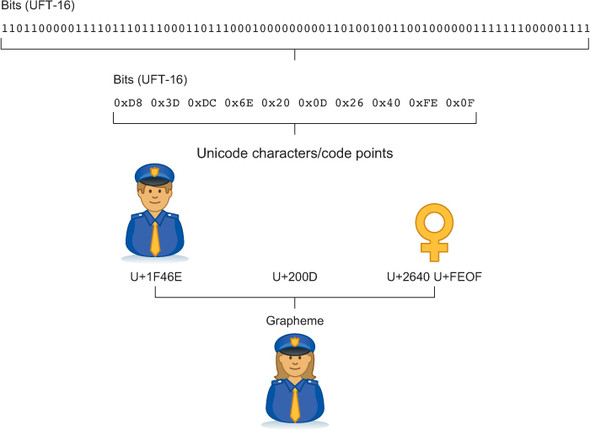
Note that for the same grapheme, the UTF-8 encoding, even though it ends up having the same representation on screen, is different. The UTF-8 encoding is 0xF0 0x9F 0x91 0xAE 0xE2 0x80 0x8D 0xE2 0x99 0x80 0xEF 0xB8 0x8F.
Always make sure you are interpreting byte sequences with the right encoding, and rely on string libraries to manipulate strings at character and grapheme levels.
2.4.4. Exercises
How many bytes are needed to encode a UTF-8 character?
- 1 byte
- 2 bytes
- 4 bytes
- It depends on the character.
How many bytes are needed to encode a UTF-32 character?
- 1 byte
- 2 bytes
- 4 bytes
- It depends on the character.
2.5. Building data structures with arrays and references
The last two common primitive types we will discuss are arrays and references. With these, we can build up any of the other more advanced data structures, such as lists and trees. These two primitives offer different trade-offs in implementing data structures. We’ll explore how to best leverage them depending on expected access patterns (read versus write frequency) and data density (sparse versus dense).
Fixed-size arrays store several values of a given type one after the other, enabling efficient access. Reference types allow us to split a data structure across multiple locations by having components reference other components.
We will not consider variable-size arrays to be primitive types, because these are implemented with fixed-size arrays and/or references, as we’ll see in this section.
2.5.1. Fixed-size arrays
Fixed-size arrays represent a contiguous range of memory that contains several values of the same type. An array of five 32-bit integers, for example, is a range of 160 bits (5 * 32) in which the first 32 bits store the first number, the second 32 bits store the next, and so on.
The reason why arrays are a common primitive as opposed to, say, linked lists is efficiency: because the values are stored one after the other, accessing any one of them is a fast operation. If an array of 32-bit integers starts at memory address 101, which is the same as saying that the first integer (at index 0) is stored as the 32 bits between 101 and 132, the integer at index N in the array is at 101 + N * 32. In general, if the list starts at address base, and the size of an element is M, the element at index N can be found at base + N * M. Because the memory is contiguous, there is a high chance the array will get paged into memory and cached all at once, which enables very fast access.
By contrast, for a linked list, accessing the Nth element requires us to start from the head of the list and follow the next pointers of each node until we reach the Nth one. There is no way to compute the address of a node directly. Nodes are not necessarily allocated one after the other, so memory might have to be paged in and out until we reach the node we want. Figure 2.8 shows in-memory representations of an array and a linked-list of integers.
Figure 2.8. Five 32-bit integers stored in a fixed-size array and in a linked list. Finding an element is extremely fast in the fixed-size array, as we can compute its exact location. On the other hand, a linked list requires us to follow the next elements until we find the element we are looking for. Elements can be anywhere in memory.

The term fixed-size comes from the fact that arrays can’t be grown or shrunk in place. If we ever want to make our array store six integers instead of five, we would have to allocate a new array that can fit six integers and copy the first five over from the original array. Contrast this with a linked list, in which we can append a node without having to modify any of the existing nodes. Depending on the expected access pattern (more reads or more appends), one representation would work better than the other.
2.5.2. References
Reference types hold pointers to objects. The value of a reference type—the actual bits of a variable—do not represent the content of an object, but where the object can be found. Multiple references to a single object do not duplicate the state of the object, so changes made to the object through one of the references are visible through all other references.
Reference types are commonly used in data structure implementations, as they provide a way to connect separate components that can be added to or removed from the data structure at run time.
In the following sections, we will look at a few common data structures and how they can be implemented with arrays, references, or a combination of the two.
2.5.3. Efficient lists
Many languages provide a list data structure as part of their library. Note this data structure is not a primitive, but a data structure implemented with primitives. Lists can shrink and grow as items are added or removed.
If lists were implemented as linked lists, we could add and remove nodes without having to copy any data, but traversing the list would be expensive (linear time or O(n) complexity, where n is the length of the list). In listing 2.13, NumberLinkedList is such a list implementation that provides two functions: at(), which retrieves the value at the given index, and append(), which adds a value to the end of the list. The implementation keeps two references: one to the beginning of the list, from which we can start a traversal, and one to the end of the list, which allows us to append elements without having to traverse the list.
Listing 2.13. Linked-list implementation
class NumberListNode {
value: number; 1
next: NumberListNode | undefined; 1
constructor(value: number) {
this.value = value;
this.next = undefined;
}
}
class NumberLinkedList {
private tail: NumberListNode = { value: 0, next: undefined }; 2
private head: NumberListNode = this.tail; 2
at(index: number): number {
let result: NumberListNode | undefined = this.head.next; 3
while (index > 0 && result != undefined) { 3
result = result.next;
index--;
}
if (result == undefined) throw new RangeError();
return result.value;
}
append(value: number) {
this.tail.next = { value: value, next: undefined }; 4
this.tail = this.tail.next; 4
}
}
- 1 A node in the list has a value and a reference to the next node or is undefined if this is the last node.
- 2 The list starts as empty, with both head and tail pointing to a dummy node.
- 3 To get the node at a given index, we must start from the head and follow the next references.
- 4 Appending a node is efficient: we just add it to the tail and then update the tail property.
As we can see, append() is very efficient in this case, as it only needs to add a node to the tail and then make that new node the tail. On the other hand, at() requires us to start from the head and move along next references until we reach the node we were looking for.
In the next listing, let’s contrast this with an array-based implementation, in which accessing an element can be done efficiently, but appending an element is the expensive operation.
Listing 2.14. Array-based list implementation
class NumberArrayList {
private numbers: number[] = []; 1
private length: number = 0; 1
at(index: number): number {
if (index >= this.length) throw new RangeError();
return this.numbers[index]; 2
}
append(value: number) {
let newNumbers: number[] = new Array(this.length + 1); 3
for (let i = 0; i < this.length; i++) { 3
newNumbers[i] = this.numbers[i];
}
newNumbers[this.length] = value; 4
this.numbers = newNumbers;
this.length++;
}
}
- 1 We store the values in a number array, originally of 0 length.
- 2 Accessing an element simply means indexing in the array.
- 3 Appending a number requires us to allocate a new array and copy the old elements.
- 4 Finally, the last element is added to the end of the new array.
Here, accessing the element at a given index simply means indexing in the underlying numbers array. On the other hand, appending a value becomes an involved operation:
- We must allocate a new array one element larger than the current array.
- Then we must copy over all the elements from the current array to the newly allocated one.
- We append the value as the last element in the new array.
- We replace the current array with the new one.
Copying all the elements of the array whenever we need to append a new value is, again, not very efficient.
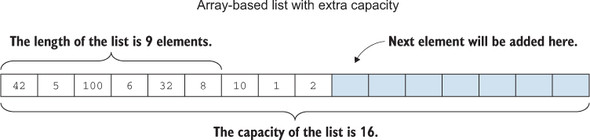
In practice, most libraries implement lists as an array with extra capacity. The array has a larger size than initially needed, so new elements can be appended without having to create a new array and copy data. When the array gets filled up, a new array is allocated, and elements do get copied over, but the new array has double the capacity (figure 2.9).
Figure 2.9. An array-based list with 9 elements and capacity for 16. Seven more elements can be appended before the data has to be moved to a larger array.
With this heuristic, the array capacity grows exponentially, so data doesn’t get copied as much as it would if the array grew by only one element every time.
Listing 2.15. Array-based list implementation with additional capacity
class NumberList {
private numbers: number[] = new Array(1); 1
private length: number = 0;
private capacity: number = 1; 1
at(index: number): number {
if (index >= this.length) throw new RangeError();
return this.numbers[index]; 2
}
append(value: number) {
if (this.length < this.capacity) { 3
this.numbers[length] = value; 3
this.length++; 3
return;
}
this.capacity = this.capacity * 2; 4
let newNumbers: number[] = new Array(this.capacity); 4
for (let i = 0; i < this.length; i++) {
newNumbers[i] = this.numbers[i];
}
newNumbers[this.length] = value;
this.numbers = newNumbers;
this.length++;
}
}
- 1 Even though the list is empty, we start with a capacity of 1.
- 2 Accessing an element is identical to the previous implementation.
- 3 If the array is not filled to capacity, we can simply add the element and update the length.
- 4 If we’re at capacity, we need to allocate a new array and copy elements, but we do this by doubling the capacity so that future appends do not require a reallocation.
Other linear data structures, such as stacks and heaps, can be implemented in a similar way. These data structures are optimized for read access, which is always extremely efficient. Using the extra capacity makes most writes efficient, but some writes, when the data structure is filled to capacity, require moving all elements to a new array, which is inefficient. There is also memory overhead, as the list allocates more elements than there are in use to make room for future appends.
2.5.4. Binary trees
Let’s look at another type of data structure: a data structure in which we can append items in multiple places. An example of such a data structure is a binary tree, in which nodes can be appended to any node that doesn’t have two children.
One option is to represent a binary tree as an array. The first level of the tree, the root, has at most one node. The second level of the tree has at most two nodes: the children of the root. The third level has at most four nodes: the children of the previous two nodes and so on. In general, for a tree with N levels, a binary tree can have at most 1 + 2 + ... + 2N–1 nodes, which is 2N–1.
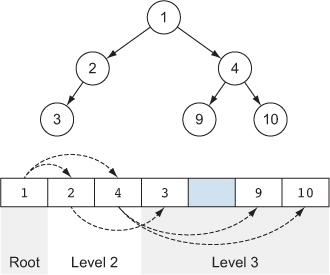
We can store a binary tree in an array by placing each level after the previous one. If the tree is not complete (not all levels have all the nodes), we mark the missing nodes as undefined. An advantage of this representation is that it’s very easy to get from a parent to its children: if the parent is at index i, the left child node is at index 2*i, and the right child node is at index 2*i+1.
Figure 2.10 shows how we can represent a binary tree as a fixed-size array.
Figure 2.10. Binary tree represented as a fixed-size array. The missing node (right child of 2) is an unused element in the array. The parent–child relation between the nodes is implicit, as the index of a child can be computed from the index of the parent, and vice versa.
Appending a node is also efficient as long as we don’t change the number of levels in the tree. As soon as we increase the level, though, we not only have to copy the whole tree, but also need to double the size of the array to make room for all the new possible nodes, as shown in the following listing. This is similar to the efficient list implementation.
Listing 2.16. Array-based binary tree implementation
class Tree {
nodes: (number | undefined)[] = []; 1
left_child_index(index: number): number {
return index * 2; 2
}
right_child_index(index: number): number {
return index * 2 + 1; 2
}
add_level() {
let newNodes: (number | undefined)[] =
new Array(this.nodes.length * 2 + 1); 3
for (let i = 0; i < this.nodes.length; i++) {
newNodes[i] = this.nodes[i]; 3
}
this.nodes = newNodes;
}
}
- 1 Nodes are stored as an array of number values or undefined to represent gaps.
- 2 Compute the index of left and right children nodes given the index of the parent.
- 3 Adding capacity for a new level doubles the size of the array and relocates nodes.
The drawback of this implementation is that the amount of additional space required can be unacceptable if the tree is sparse (figure 2.11).
Figure 2.11. A sparse binary tree with only three nodes still requires an array with seven elements to be represented correctly. If node 9 had a child, the array size would become 15.

Because of the extra-space overhead, binary trees are usually represented with a more compact representation using references. A node stores a value and references to its children.
Listing 2.17. Compact binary tree implementation
class TreeNode {
value: number; 1
left: TreeNode | undefined; 2
right: TreeNode | undefined; 2
constructor(value: number) {
this.value = value;
this.left = undefined;
this.right = undefined;
}
}
- 1 Each node stores a value.
- 2 Left and right refer to other nodes or are undefined if the node doesn’t have a child.
With this implementation, a tree is represented by a reference to its root node. From there, following left and right children, we can access any node in the tree. Appending a node anywhere involves just allocating a new node and setting the left or right property of its parent. Figure 2.12 shows how we can represent a sparse tree using references.
Figure 2.12. Sparse tree represented by using references. The diagram on the right represents the node data structure as value, left reference, right reference.

Although the references themselves require some nonzero memory to represent, the amount of space required is proportional to the number of nodes. For sparse trees, this is much better than the array-based implementation, in which space grows exponentially with the number of levels.
In general, sparse data structures where elements can be added in multiple places and we expect to have a lot of “gaps” are better represented by having elements refer to other elements, as opposed to placing the whole data structure in a fixed-size array that would end up having unacceptable overhead.
2.5.5. Associative arrays
Some programming languages provide other types of data structures as primitives, with built-in syntax support. A common such type is the associative array, also known as dictionary or hash table. This type of data structure represents a set of key-value pairs where, given a key, the value can be retrieved efficiently.
Despite what you may have thought as you followed the previous code examples, Java-Script/TypeScript arrays are associative arrays. The languages do not provide a fixed-size array primitive type. The code examples show how data structures can be implemented over fixed-size arrays. A fixed-size array assumes extremely efficient indexing and immutable size. This is not really the case in JavaScript/TypeScript. The reason we looked at fixed-size arrays instead of associative arrays is that an associative array data structure can be implemented with arrays and references. For illustrative purposes, we treated TypeScript arrays as fixed-size, so the code samples can be directly translated into most other popular programming languages.
Languages such as Java and C# provide dictionaries or hash maps as part of their library, whereas arrays and references are primitives. JavaScript and Python provide associative arrays as primitive types, but their run times also implement them with arrays and references. Arrays and references are lower-level constructs that represent certain memory layouts and access models, whereas associative arrays are higher-level abstractions.
An associative array is often implemented as a fixed-size array of lists. A hash function takes a key of an arbitrary type and returns an index to the fixed-size array. The key-value pair is added to or retrieved from the list at the given index in the array. The list is used because multiple keys can hash to the same index (figure 2.13).
Figure 2.13. Associative array implemented as an array of lists. This instance contains the key-value mappings 0 → 10, → 9, 5 → 10, and 42 → 0.

Looking up a value by key involves finding the list where the key-value pair sits, traversing it until the key is found, and returning the value. If lists become too long, lookup time increases, so efficient associative array implementations rebalance by increasing the size of the array, thus making the lists smaller.
A good hashing function ensures that keys usually get distributed across the lists evenly so that the lists are similar in length.
2.5.6. Implementation trade-offs
In the preceding section, we saw how arrays and references are enough to implement other data structures. Depending on the expected access patterns (such as read versus write frequency) and expected shape of the data (dense versus sparse), we can pick the right primitives to represent components of the data structure and combine them to get the most efficient implementation.
Fixed-size arrays have extremely fast read/update capabilities and can easily represent dense data. For variable-size data structures, references perform better on append and can represent sparse data more easily.
2.5.7. Exercise
Which data structure is best suited for accessing its elements in random order?
- Linked list
- Array
- Dictionary
- Queue
Summary
- Functions that never return (run forever or throw exceptions) should be declared as returning the empty type. An empty type can be implemented as a class that cannot be instantiated or an enum with no elements.
- Functions that finish executing but don’t return a meaningful result should be declared as returning the unit type (void in most languages). A unit type can be implemented as a singleton or an enum with a single element.
- Boolean expression evaluation is usually short-circuited, so the order of the operands can affect which of them get evaluated.
- Fixed-width integer types can overflow. The default behavior on overflow is language-specific. The desired behavior depends on the scenario.
- Floating-point numbers are represented approximately, so instead of comparing two values for equality, it’s better to check whether they are within EPSILON of each other.
- Text consists of graphemes, which are represented by one or more Unicode code points, each of which is encoded as one or more bytes. String--manipulation libraries shield us from the complexities of encoding and representation, so it’s best to rely on them rather than manipulate text directly.
- Fixed-size arrays and references are the building blocks of data structures. Depending on data access patterns and density, we can choose one or the other, or a combination of the two, to implement any data structure efficiently, no matter how complex.
Answers to exercises
Designing functions that don’t return values
c—The function doesn’t return anything meaningful, so the void unit type is a good return type.
a—The function never returns, so the empty type never is a good return type.
Boolean logic and short circuits
b—The counter is incremented only once because the function returns false, so the Boolean expression is short-circuited.
Common pitfalls of numerical types
c—The expression evaluates to false because of float rounding.
c—Because identifiers need to be unique, erroring out is the preferred behavior.
Encoding text
d—UTF-8 is a variable-length encoding.
c—UTF-32 is a fixed-length encoding; all characters are encoded in four bytes.
Building data structures with arrays and references
b—Arrays are best suited for random access.