
Chapter 3. Composition
This chapter covers
- Combining types into compound types
- Combining types as either-or types
- Implementing visitor patterns
- Algebraic data types
In chapter 2, we looked at some common primitive types that form the building blocks of a type system. In this chapter, we’ll look at ways to combine them to define new types.
We’ll cover compound types, which group values of several types. We’ll look at how naming members gives meaning to data and lowers the chance of misinterpretation, and how we can ensure that values are well-formed when they need to meet certain constraints.
Next, we’ll go over either-or types, which contain a single value from one of several types. We will look at some common types such as optional types, either types, and variants, as well as a few applications of these types. We’ll see, for example, how returning a result or an error is usually safer than returning a result and an error.
As an application of either-or types, we’ll take a look at the visitor design pattern and contrast an implementation that leverages class-hierarchies with an implementation that uses a variant to store and operate on objects.
Finally, we’ll provide a description of algebraic data types (ADTs) and see how they relate to the topics discussed in this chapter.
3.1. Compound types
The most obvious way to combine types is to group them to form new types. Let’s take a pair of X and Y coordinates on a plane. Both X and Y coordinates have the type number. A point on the plane has both an X and a Y coordinate, so it combines the two types into a new type in which values are pairs of numbers.
In general, combining one or more types this way gives us a new type in which the values are all the possible combinations of the component types (figure 3.1).
Figure 3.1. Combining two types so that the resulting type contains a value from each of them. Each emoji represents a value from one of the types. The parentheses represent the values of the combined type as pairs of values from the original types.
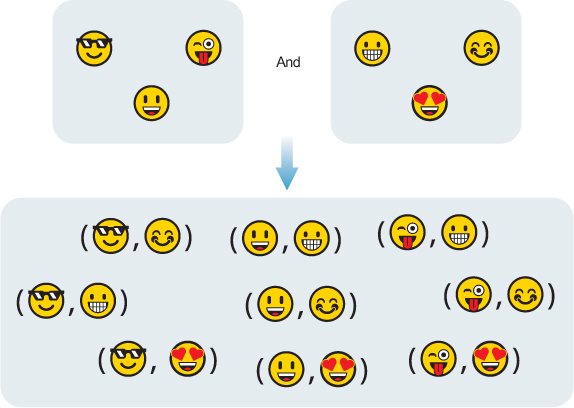
Note that we’re talking about combining values of the types, not their operations. We’ll see how operations combine when we look at elements of object-oriented programming in chapter 8. For now, we’ll stick to values.
3.1.1. Tuples
Let’s say we want to compute the distance between two points defined as pairs of coordinates. We can define a function that takes the X coordinate and Y coordinate of the first point, and the X coordinate and the Y coordinate of the second point, and then computes the distance between the two, as shown in the following listing.
Listing 3.1. Distance between two points
function distance(x1: number, y1: number, x2: number, y2: number)
: number {
return Math.sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2);
}
This works, but it’s not ideal: if we are dealing with points, x1 is meaningless without the corresponding Y coordinate. Our application likely needs to manipulate points in multiple places, so instead of passing around independent X and Y coordinates, we could group them in a tuple.
Tuple Types
Tuple types consist of a set of component types, which we can access by their position in the tuple. Tuples provide a way to group data in an ad hoc way, allowing us to pass around several values of different types as a single variable.
Using tuples, we can pass around pairs of X and Y coordinates together as points. This makes the code both easier to read and easier to write. It’s easier to read as it is now clear that we are dealing with points, and it’s easier to write as we can simply use point: Point instead of x: number, y: number, as shown in the next listing.
Listing 3.2. Distance between two points defined as tuples
type Point = [number, number]; 1
function distance(point1: Point, point2: Point): number {
return Math.sqrt(
(point1[0] - point2[0]) ** 2 + (point1[1] - point2[1]) ** 2);
}
- 1 We define a new type Point to be a tuple of numbers.
Tuples are also useful when we need to return multiple values from a function, which we can’t easily do without a way to group values. The alternative is to use out parameters, arguments that are updated by the function, but that makes the code harder to follow.
DIY Tuple
Most languages offer tuples as built-in syntax or as part of their library, but let’s look at how we would implement a tuple if it were unavailable. In the following code we’ll implement a generic tuple with two component types, also known as a pair.
Listing 3.3. Pair type
class Pair<T1, T2> {
m0: T1; 1
m1: T2; 1
constructor(m0: T1, m1: T2) {
this.m0 = m0;
this.m1 = m1;
}
}
type Point = Pair<number, number>;
function distance(point1: Point, point2: Point): number {
return Math.sqrt(
(point1.m0 - point2.m0) ** 2 + (point1.m1 - point2.m1) ** 2);
}
Looking at types as sets of possible values, if the X coordinate can be any value in the set defined by number and, similarly, the Y coordinate can be any value in the set defined by number, the Point tuple can be any value in the set defined as the pair <number, number>.
3.1.2. Assigning meaning
Defining points as pairs of numbers works, but we lose some meaning: we can interpret a pair of numbers as either X and Y coordinates or Y and X coordinates (figure 3.2).
Figure 3.2. Two ways to interpret the pair (1, 5): as point A with X coordinate 1 and Y coordinate 5, or as point B with X coordinate 5 and Y coordinate 1.
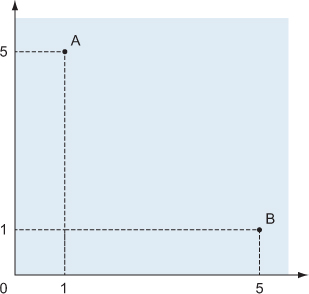
In our examples so far, we assumed that the first component is the X coordinate and the second the Y coordinate. This works but leaves room for error. It is better if we can encode the meaning within the type system and ensure that there is no room to misinterpret X as Y or Y as X. We can do this by using a record type.
Record Types
Record types, similar to tuples, combine multiple other types. Instead of the component values being accessed by their position in the tuple, record types allow us to give their components names and access them by name. Record types are known as record or struct in different languages.
If we define our Point as a record, we can assign the names x and y to the two components and leave no room for ambiguity, as the next listing shows.
Listing 3.4. Distance between two points defined as records
class Point {
x: number; 1
y: number; 1
constructor(x: number, y: number) {
this.x = x;
this.y = y;
}
}
function distance(point1: Point, point2: Point): number {
return Math.sqrt(
(point1.x - point2.x) ** 2 + (point1.y - point2.y) ** 2);
}
- 1 Point defines x and y members, so it is clear which coordinate is encoded by which component.
As a rule of thumb, it’s usually best to define records with named components instead of passing tuples around. The fact that tuples do not name their components leaves room for misinterpretation. Tuples don’t really provide anything better than records in terms of efficiency or functionality, except that we can usually declare them inline where we are using them, whereas we usually have to provide a separate definition for records. In most cases, the separate definition is worth adding, as it provides extra meaning to our variables.
3.1.3. Maintaining invariants
In languages in which record types can have associated methods, there is usually a way to define the visibility of their members. A member can be defined as public (accessible from anywhere), private (accessible only from within the record), and so on. In TypeScript, members are public by default.
In general, when we define record types, if the members are independent and can vary without causing issues, it’s fine to mark them as public. This is the case with points defined as pairs of X and Y coordinates: one of the coordinates can change independently of the other coordinate as a point moves on the plane.
Let’s take another example in which the members can’t vary independently without causing issues: the currency type we looked at in chapter 2, formed by a dollar amount and a cents amount. Let’s enhance the definition of the type with the following rules that define a well-formed currency amount:
- The dollar amount must be an integer equal to or greater than 0 and safely representable as a number type.
- The cent amount must be an integer equal to or greater than 0 and safely representable as a number type.
- We shouldn’t have more than 99 cents; every 100 cents should be converted to a dollar.
Such rules that ensure a value is well-formed are also called invariants, as they shouldn’t change even as the values that make up the composite type change. If we make the members public, external code can change them, and we can end up with ill-formed records, as shown in the next listing.
Listing 3.5. Ill-formed currency
class Currency {
dollars: number;
cents: number;
constructor(dollars: number, cents: number) {
if (!Number.isSafeInteger(cents) || cents < 0) 1
throw new Error();
dollars = dollars + Math.floor(cents / 100); 2
cents = cents % 100; 2
if (!Number.isSafeInteger(dollars) || dollars < 0) 1
throw new Error();
this.dollars = dollars;
this.cents = cents;
}
}
let amount: Currency = new Currency(5, 50);
amount.cents = 300; 3
- 1 Constructor ensures that we have valid dollars and cents values.
- 2 Every 100 cents gets converted to a dollar.
- 3 Unfortunately, having the members public still allows external code to make an invalid object.
This situation can be prevented by making the members private and providing methods to update them that ensure the invariants are maintained, as shown in the following listing. If we handle all cases in which invariants would be invalidated, we can ensure that an object is always in a valid state, as changing it would give us another well-formed object or result in an exception.
Listing 3.6. Currency maintaining invariants
class Currency {
private dollars: number = 0; 1
private cents: number = 0; 1
constructor(dollars: number, cents: number) {
this.assignDollars(dollars);
this.assignCents(cents);
}
getDollars(): number {
return this.dollars;
}
assignDollars(dollars: number) {
if (!Number.isSafeInteger(dollars) || dollars < 0) 2
throw new Error();
this.dollars = dollars;
}
getCents(): number {
return this.cents;
}
assignCents(cents: number) {
if (!Number.isSafeInteger(cents) || cents < 0) 2
throw new Error();
this.assignDollars(this.dollars + Math.floor(cents / 100)); 3
this.cents = cents % 100;
}
}
- 1 Making dollars and cents private ensures that external code can’t bypass validation.
- 2 If the dollar or cent amount is invalid (negative or nonsafe integer), throw an exception.
- 3 Normalize the value by converting 100 cents to dollars.
External code now has to go through the assignDollars() and assignCents() functions, which ensure that all invariants are maintained: if the provided values are invalid, exceptions are thrown. If the number of cents is larger than 100, it is converted to dollars.
In general, we should be fine providing direct access to public members of a record if there are no invariants to be enforced, such as the independent X and Y components of a point on a plane. On the other hand, if we have a set of rules that define what it means for a record to be well-formed, we should use private members and methods to update them to ensure that the rules are enforced.
Another option is to make the members immutable, as shown in the following listing, in which case we can ensure during initialization that the record is well-formed, but then we can allow direct access to the members because they can’t be changed by external code.
Listing 3.7. Immutable Currency
class Currency {
readonly dollars: number; 1
readonly cents: number; 1
constructor(dollars: number, cents: number) {
if (!Number.isSafeInteger(cents) || cents < 0) 2
throw new Error();
dollars = dollars + Math.floor(cents / 100); 2
cents = cents % 100;
if (!Number.isSafeInteger(dollars) || dollars < 0) 2
throw new Error();
this.dollars = dollars;
this.cents = cents;
}
}
- 1 Dollars and cents are public but read-only and can’t be changed after initialization.
- 2 All validation takes place in the constructor now.
If the members are immutable, we no longer need functions for them to uphold the invariants. The only time when the members are set is during construction, so we can move all the validation logic there. Immutable data has other advantages: accessing this data concurrently from different threads is guaranteed to be safe, as the data can’t change. Mutability can cause data races, when one thread modifies a value while another thread is using it.
The drawback of records with immutable members is that we need to create a new instance whenever we want a new value. Depending on how expensive it is to create new instances, we might opt for a record in which the members can be updated in place by using getter and setter methods, or we might go with an implementation in which each update requires creating a new object.
The goal is to prevent external code from making changes that bypass our validation rules, either by making members private and routing all access through methods or by making the members immutable and applying validation in the constructor.
3.1.4. Exercise
What is the preferred way of defining a point in 3D space?
- type Point = [number, number, number];
- type Point = number | number | number;
- type Point = { x: number, y: number, z: number };
- type Point = any;
3.2. Expressing either-or with types
So far, we’ve looked at combining types by grouping them such that values are composed of one value from each of the member types. Another fundamental way in which we can combine types is either-or, in which a value is any one of a possible set of values of one or more underlying types (figure 3.3).
Figure 3.3. Combining two types so that the resulting type allows values from either of the two types.

3.2.1. Enumerations
Let’s start with a very simple task: encoding a day of the week in the type systems. We could say the day of the week is a number between 0 and 6, 0 being the first day of the week and 6 being the last one. This is less than ideal, because multiple engineers working on the code might have different opinions of what the first day of the week is. Countries such as the United States, Canada, and Japan consider Sunday to be the first day of the week, whereas the ISO 8601 standard and most European countries consider Monday to be the first day of the week.
Listing 3.8. Encoding day of week as a number
function isWeekend(dayOfWeek: number): boolean {
return dayOfWeek == 5 || dayOfWeek == 6; 1
}
function isWeekday(dayOfWeek: number): boolean {
return dayOfWeek >= 1 && dayOfWeek <= 5; 2
}
- 1 A European developer would consider days 5 and 6 to be the weekend (Saturday and Sunday).
- 2 An American developer would consider days 1 to 5 to be weekdays (Monday through Friday).
It should be obvious from this code example that the two functions can’t both be correct. If 0 represents Sunday, isWeekend() is incorrect; if 0 represents Monday, isWeekday() is incorrect. Unfortunately, because the meaning of 0 is not enforced but determined by convention, there is no automatic way to prevent this error.
An alternative is to declare a set of constant values to represent the days of the week and make sure that these constants are used whenever a day of the week is expected.
Listing 3.9. Encoding day of week with constants
const Sunday: number = 0;
const Monday: number = 1;
const Tuesday: number = 2;
const Wednesday: number = 3;
const Thursday: number = 4;
const Friday: number = 5;
const Saturday: number = 6;
function isWeekend(dayOfWeek: number): boolean {
return dayOfWeek == Saturday || dayOfWeek == Sunday; 1
}
function isWeekday(dayOfWeek: number): boolean {
return dayOfWeek >= Monday && dayOfWeek <= Friday; 1
}
- 1 Instead of numbers, we now use named constants to ensure consistency.
This implementation is slightly better than the previous implementation, but there’s still a problem: looking at the declaration of a function, it’s not clear what the expected values are for an argument of type number. How is someone who’s new to the code supposed to know that whenever they see a dayOfWeek: number, they should use one of the constants? They may not be aware that these constants exist somewhere in some module, and instead, they could interpret the number themselves, as in our first example in listing 3.8. Someone can also call the function with completely invalid values, such as -1 or 10. An even better solution is to declare an enumeration for the days of the week.
Listing 3.10. Encoding day of week as an enum
enum DayOfWeek { 1
Sunday,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday
}
function isWeekend(dayOfWeek: DayOfWeek): boolean { 2
return dayOfWeek == DayOfWeek.Saturday
|| dayOfWeek == DayOfWeek.Sunday;
}
function isWeekday(dayOfWeek: DayOfWeek): boolean { 2
return dayOfWeek >= DayOfWeek.Monday
&& dayOfWeek <= DayOfWeek.Friday;
}
- 1 An enum replaces the constants.
- 2 We now have a distinct type that represents a day of the week.
With this approach, we directly encode the days of the week in an enumeration that has two big advantages: there is no ambiguity about what is Monday and what is Sunday, as they are spelled out in the code. Also, it’s very clear, when looking at a function declaration expecting a dayOfWeek: DayOfWeek argument, that we should pass in a member of DayOfWeek, such as DayOfWeek.Tuesday, not a number.
This is a basic example of combining a set of values into a new type. A variable of that type can be one of the provided values. We would use enumerations whenever we have a small set of possible values and want to represent them in an unambiguous manner. Next, let’s see how we apply this concept to types instead of values.
3.2.2. Optional types
Let’s say we want to convert a string, provided as user input, to a DayOfWeek. If we can interpret the string as a day of week, we want to return a DayOfWeek value, but if we can’t interpret it, we want to explicitly say that the day of the week is undefined. We can implement this in TypeScript by using the | type operator, which allows us to combine types, as shown in the following code.
Listing 3.11. Parsing input into a DayOfWeek or undefined
function parseDayOfWeek(input: string): DayOfWeek | undefined { 1
switch (input.toLowerCase()) {
case "sunday": return DayOfWeek.Sunday;
case "monday": return DayOfWeek.Monday;
case "tuesday": return DayOfWeek.Tuesday;
case "wednesday": return DayOfWeek.Wednesday;
case "thursday": return DayOfWeek.Thursday;
case "friday": return DayOfWeek.Friday;
case "saturday": return DayOfWeek.Saturday;
default: return undefined; 2
}
}
function useInput(input: string) {
let result: DayOfWeek | undefined = parseDayOfWeek(input);
if (result === undefined) { 3
console.log(`Failed to parse "${input}"`);
} else {
let dayOfWeek: DayOfWeek = result; 4
/* Use dayOfWeek */
}
}
- 1 The function returns a DayOfWeek or undefined.
- 2 If neither case matches, we return undefined to signal that we couldn’t parse the input.
- 3 Check whether we failed to parse, in which case we log an error.
- 4 If result is not undefined, we can extract a DayOfWeek value from it and use it going forward.
This parseDayOfWeek() function returns a DayOfWeek or undefined. The use-Input() function calls this function and then tries to unwrap the result, logging an error or ending up with a DayOfWeek value that it can use.
Optional Types
An optional type, also known as a maybe type, represents an optional value of another type T. An instance of the optional type can hold a value (any value) of type T or a special value indicating the absence of a value of type T.
DIY Optional
Some mainstream programming languages do not have syntax-level support for combining types this way, but a set of common constructs is available as libraries. Our DayOfWeek or undefined example is an optional type. An optional contains either a value of its underlying type or no value.
An optional type usually wraps another type provided as a generic type argument and provides a couple of methods: a hasValue() method, which tells us whether we have an actual value, and a getValue(), which returns that value. Attempting to call getValue() when no value is set causes an exception to be thrown, as shown in the next listing.
Listing 3.12. Optional type
class Optional<T> { 1
private value: T | undefined;
private assigned: boolean;
constructor(value?: T) { 2
if (value) {
this.value = value;
this.assigned = true;
} else {
this.value = undefined;
this.assigned = false;
}
}
hasValue(): boolean {
return this.assigned;
}
getValue(): T {
if (!this.assigned) throw Error(); 3
return <T>this.value;
}
}
- 1 Optional wraps a generic type T.
- 2 value is an optional argument, because TypeScript doesn’t support constructor overloads.
- 3 If this Optional is not assigned, attempting to get a value throws an exception.
In other languages that don’t have a | type operator that allows us to define a T | undefined type, we would use a nullable type instead. A nullable type allows for any value of the type or null, which represents the absence of a value.
You might wonder why this optional type is useful, considering that in most languages, reference types are allowed to be null, so there is already a way to encode “no value available” without needing such a type.
The difference is that using null is error-prone (see the sidebar “A billion-dollar mistake”), as it’s hard to tell when a variable can or can’t be null. We must add null checks all over the code or risk dereferencing a null variable, which results in a run-time error. The idea behind an optional type is to decouple the null from the range of allowed values. Whenever we see an optional, we know that it can have no value. After we check that we indeed have a value, we unwrap it from the optional and get a variable of the underlying type. From here on, we know that the variable cannot be null. This distinction is captured in the type system, as the “might be null” variable has a different type (DayOfWeek | undefined or Optional<DayOfWeek>) from the unwrapped value, which we know can’t be null (DayOfWeek). It helps that an optional type and its underlying type are incompatible, so we can’t accidentally use an optional (which may not have a value) instead of its underlying type without explicitly unwrapping the value.
Famous computer scientist and Turing Award winner Sir Tony Hoare calls null references his “billion-dollar mistake.” He is quoted as saying:
“I call it my billion-dollar mistake. It was the invention of the null reference in 1965. At that time, I was designing the first comprehensive type system for references in an object oriented language. My goal was to ensure that all use of references should be absolutely safe, with checking performed automatically by the compiler. But I couldn’t resist the temptation to put in a null reference, simply because it was so easy to implement. This has led to innumerable errors, vulnerabilities, and system crashes, which have probably caused a billion dollars of pain and damage in the last forty years.”
After decades of null dereference errors, it’s becoming clear that it is better if null, or the absence of the value, is not itself a valid value of a type.
3.2.3. Result or error
Let’s extend our DayOfWeek string conversion example so that instead of simply returning no value when we cannot determine the DayOfWeek value, we return more detailed error information. We want to distinguish between when the string is empty and when we are unable to parse it. This is useful if we run this code behind a text input control, as we want to show different error messages to the user, depending on the error (Please enter a day of week versus Invalid day of week).
A common antipattern returns both a DayOfWeek and an error code, as shown in the next listing. If the error code indicates success, we use the DayOfWeek value. If the error code indicates an error, the DayOfWeek value is invalid, and we shouldn’t use it.
Listing 3.13. Returning result and error from a function
enum InputError { 1
OK,
NoInput,
Invalid
}
class Result { #B
error: InputError;
value: DayOfWeek;
constructor(error: InputError, value: DayOfWeek) {
this.error = error;
this.value = value;
}
}
function parseDayOfWeek(input: string): Result { 2
if (input == "")
return new Result(InputError.NoInput, DayOfWeek.Sunday); 3
switch (input.toLowerCase()) {
case "sunday":
return new Result(InputError.OK, DayOfWeek.Sunday); 4
case "monday":
return new Result(InputError.OK, DayOfWeek.Monday);
case "tuesday":
return new Result(InputError.OK, DayOfWeek.Tuesday);
case "wednesday":
return new Result(InputError.OK, DayOfWeek.Wednesday);
case "thursday":
return new Result(InputError.OK, DayOfWeek.Thursday);
case "friday":
return new Result(InputError.OK, DayOfWeek.Friday);
case "saturday":
return new Result(InputError.OK, DayOfWeek.Saturday);
default:
return new Result(InputError.Invalid, DayOfWeek.Sunday); 5
}
}
- 1 InputError represents the error code.
- 2 Result combines the error code and the DayOfWeek value.
- 3 We return NoInput if the string is empty and a default DayOfWeek.
- 4 We return OK and the parsed DayOfWeek if we can successfully parse the input.
- 5 Otherwise, we return Invalid and a default DayOfWeek if we fail to parse.
This is not ideal because if we accidentally forget to check the error code, nothing prevents us from using the DayOfWeek member. Now the value can be a default, and we aren’t necessarily able to tell that it is invalid. We might propagate the error through the system, such as writing it to a database, without realizing that we shouldn’t have used the value at all.
Looking at this from the lens of types as sets, our result contains the combination of all possible error codes and all possible results (figure 3.4).
Figure 3.4. All possible values of the Result type as combinations of InputError and DayOfWeek. That’s 21 values (3 InputError x 7 DayOfWeek).

Instead, we should try to return either an error or a valid value. If we manage to do that, the set of possible values is drastically decreased, and we eliminate the possibility of using the DayOfWeek component of a Result in which the InputError component is NoInput or Invalid (figure 3.5).
Figure 3.5. All possible values of Result type as a combination of InputError or DayOfWeek. That’s 9 values (2 InputError + 7 DayOfWeek). We no longer need an OK InputError, as the absence of an error is indicated by the fact that we have a DayOfWeek value.
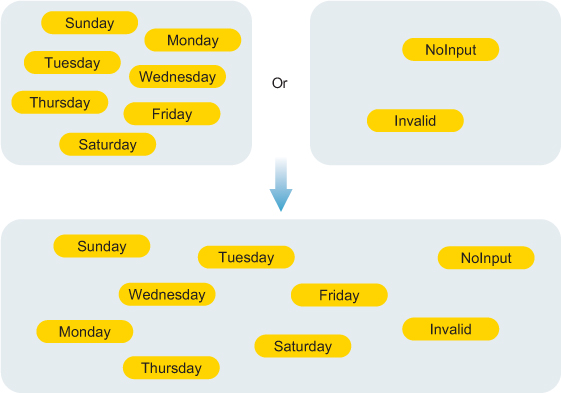
DIY Either
An Either type wraps two types, TLeft and TRight, the convention being that TLeft stores the error type and TRight stores the valid value type. (If there’s no error, the value is “right”.) Again, some programming languages provide this as part of their library, but if necessary, we can easily implement such a type.
Listing 3.14. Either type
class Either<TLeft, TRight> {
private readonly value: TLeft | TRight; 1
private readonly left: boolean; 1
private constructor(value: TLeft | TRight, left: boolean) { 2
this.value = value;
this.left = left;
}
isLeft(): boolean {
return this.left;
}
getLeft(): TLeft { 3
if (!this.isLeft()) throw new Error();
return <TLeft>this.value;
}
isRight(): boolean {
return !this.left;
}
getRight(): TRight { 3
if (!this.isRight()) throw new Error();
return <TRight>this.value;
}
static makeLeft<TLeft, TRight>(value: TLeft) { 4
return new Either<TLeft, TRight>(value, true);
}
static makeRight<TLeft, TRight>(value: TRight) { 4
return new Either<TLeft, TRight>(value, false);
}
}
- 1 The type wraps a value of TLeft or TRight and a flag to keep track of which type is used.
- 2 Private constructor, as we need to make sure that the value and boolean flag are in sync
- 3 Attempting to get a TLeft when we have a TRight or vice versa throws an error.
- 4 Factory functions call the constructor and ensure that the boolean flag is consistent with the value.
In a language that’s missing the type operator |, we could simply make the value a common type, such as Object in Java and C#. The getLeft() and getRight() methods handle conversion back to the TLeft and TRight types.
With such a type, we can update our parseDayOfWeek() implementation to return an Either<InputError, DayOfWeek> result and make it impossible to propagate an invalid or default DayOfWeek value. If the function returns an InputError, there is no DayOfWeek in the result, and attempting to unwrap one via a call to getLeft() throws an error.
Again, we have to be explicit about unpacking the value. When we know that we have a valid value (isLeft() returns true), and we extract it with getLeft(), we are guaranteed to have valid data.
Listing 3.15. Returning result or error from a function
enum InputError { 1
NoInput,
Invalid
}
type Result = Either<InputError, DayOfWeek>; 2
function parseDayOfWeek(input: string): Result {
if (input == "")
return Either.makeLeft(InputError.NoInput); 3
switch (input.toLowerCase()) { 3
case "sunday":
return Either.makeRight(DayOfWeek.Sunday);
case "monday":
return Either.makeRight(DayOfWeek.Monday);
case "tuesday":
return Either.makeRight(DayOfWeek.Tuesday);
case "wednesday":
return Either.makeRight(DayOfWeek.Wednesday);
case "thursday":
return Either.makeRight(DayOfWeek.Thursday);
case "friday":
return Either.makeRight(DayOfWeek.Friday);
case "saturday":
return Either.makeRight(DayOfWeek.Saturday);
default:
return Either.makeLeft(InputError.Invalid); 3
}
}
- 1 We no longer need an OK InputError. If we don’t have an error, we have a value.
- 2 We update Result to be an InputError or a DayOfWeek instead of a combination of the two.
- 3 We return a result or an error by Either.makeRight and Either.makeLeft.
The updated implementation leverages the type system to eliminate invalid states such as (NoInput, Sunday) from which we could’ve accidentally used the Sunday value. Also, there’s no need for an OK value for InputError because we don’t have an error if parsing succeeds.
Exceptions
Throwing an exception on error is a perfectly valid example of result or error: the function either returns a result or throws an exception. In several situations, exceptions cannot be used and an Either type is preferred, such as when propagating errors across processes or across threads; as a design principle, when the error itself is not exceptional (often the case when we deal with user input); when calling operating system APIs that use error codes; and so on. In these situations, when we can’t or don’t want to throw an exception but need to communicate that we got a value or failed, it’s best to encode this as an either value or error as opposed to value and error.
When throwing exceptions is acceptable, we can use them as another way to ensure that we don’t end up with an invalid result and an error. When an exception is thrown, the function no longer returns the “normal” way, by passing back a value to the caller with a return statement. Rather, it propagates the exception object until a matching catch is found. This way, we get a result or an exception. We won’t cover throwing exceptions in depth, because although many languages provide facilities for exceptions to be thrown and caught, from a type perspective, exceptions aren’t very special.
3.2.4. Variants
We’ve looked at optional types, which contain a value of the underlying type or no value. Then we looked at either types, which contain a TLeft or a TRight value. The generalizations of these types are the variant types.
Variant Types
Variant types, also known as tagged union types, contain a value of any number of underlying types. Tagged comes from the fact that even if the underlying types have overlapping values, we are still able to tell exactly which type the value comes from.
Let’s look at an example of a collection of geometric shapes in listing 3.16. Each shape has a different set of properties and a tag (implemented as a kind property). We can define a type that is the union of all these shapes. Then, when we want to (for example) render these shapes, we can use their kind property to determine which of the possible shapes an instance is, then cast it to that shape. This process is the same as the unwrapping in previous examples.
Listing 3.16. Tagged union of shapes
class Point {
readonly kind: string = "Point";
x: number = 0;
y: number = 0;
}
class Circle {
readonly kind: string = "Circle";
x: number = 0;
y: number = 0;
radius: number = 0;
}
class Rectangle {
readonly kind: string = "Rectangle";
x: number = 0;
y: number = 0;
width: number = 0;
height: number = 0;
}
type Shape = Point | Circle | Rectangle;
let shapes: Shape[] = [new Circle(), new Rectangle()];
for (let shape of shapes) { 1
switch (shape.kind) { 1
case "Point":
let point: Point = <Point>shape; 2
console.log(`Point ${JSON.stringify(point)}`);
break;
case "Circle":
let circle: Circle = <Circle>shape; 2
console.log(`Circle ${JSON.stringify(circle)}`);
break;
case "Rectangle":
let rectangle: Rectangle = <Rectangle>shape; 2
console.log(`Rectangle ${JSON.stringify(rectangle)}`);
break;
default: 3
throw new Error();
}
}
- 1 We iterate over the shapes and check the kind property of each.
- 2 If the kind is “Point”, we can safely use the shape as a Point. The same is true for Circle and Rectangle.
- 3 We throw an error if the kind is unknown. This means that some other type somehow made its way into the union, which should never be the case.
In the preceding example, the kind member of each class represents the tag which tells us the actual type of a value. The value of shape.kind tells us whether the Shape instance is a Point, Circle, or Rectangle. We can also implement a general--purpose variant that keeps track of the types without requiring the types themselves to store a tag.
Let’s implement a simple variant that can store a value of up to three types and keep track of the actual type stored based on a type index.
DIY Variant
Different programming languages provide different generic and type-checking features. Some languages allow a variable number of generic arguments, for example (so we can have variants of any number of types); others provide different ways to determine whether a value is of a certain type at both compile and run time.
The following TypeScript implementation has some trade-offs that don’t necessarily translate to other programming languages. It’s a starting point for a general--purpose variant, but it would be implemented differently in, say, Java or C#. TypeScript doesn’t support method overloads, for example, but in other languages, we could get away with a single make() function overloaded on each generic type.
Listing 3.17. Variant type
class Variant<T1, T2, T3> {
readonly value: T1 | T2 | T3;
readonly index: number;
private constructor(value: T1 | T2 | T3, index: number) {
this.value = value;
this.index = index;
}
static make1<T1, T2, T3>(value: T1): Variant<T1, T2, T3> {
return new Variant<T1, T2, T3>(value, 0);
}
static make2<T1, T2, T3>(value: T2): Variant<T1, T2, T3> {
return new Variant<T1, T2, T3>(value, 1);
}
static make3<T1, T2, T3>(value: T3): Variant<T1, T2, T3> {
return new Variant<T1, T2, T3>(value, 2);
}
}
This implementation takes on the responsibility of maintaining the tags, so now we can remove them from our geometric shapes.
Listing 3.18. Union of shapes as variant
class Point { 1
x: number = 0;
y: number = 0;
}
class Circle { 1
x: number = 0;
y: number = 0;
radius: number = 0;
}
class Rectangle { 1
x: number = 0;
y: number = 0;
width: number = 0;
height: number = 0;
}
type Shape = Variant<Point, Circle, Rectangle>; 2
let shapes: Shape[] = [
Variant.make2(new Circle()),
Variant.make3(new Rectangle())
];
for (let shape of shapes) {
switch (shape.index) { 3
case 0:
let point: Point = <Point>shape.value; 3
console.log(`Point ${JSON.stringify(point)}`);
break;
case 1:
let circle: Circle = <Circle>shape.value;
console.log(`Circle ${JSON.stringify(circle)}`);
break;
case 2:
let rectangle: Rectangle = <Rectangle>shape.value;
console.log(`Rectangle ${JSON.stringify(rectangle)}`);
break;
default:
throw new Error();
}
}
- 1 Shapes no longer need to store tags themselves.
- 2 Shape is now a Variant of these three types.
- 3 We look at the index property to find the tag and the value property to get the actual object.
This implementation might not look as though it adds a lot of benefit; we ended up using numeric tags and arbitrarily decided that 0 is a Point and 1 is a Circle. You might also wonder why we didn’t use a class hierarchy for our shapes, where we have a base method that each type implements instead of switching on tags.
For that task, we need to take a look at the visitor design pattern and the ways in which it can be implemented.
3.2.5. Exercises
Users can provide a selection among the colors red, green, and blue. What should be the type of this selection?
- number with Red = 0, Green = 1, Blue = 2
- string with Red = "Red", Green = "Green", Blue = "Blue"
- enum Colors { Red, Green, Blue }
- type Colors = Red | Green | Blue where the colors are classes
What should be the return type of a function that takes a string as input and parses it into a number? The function does not throw.
- number
- number | undefined
- Optional<number>
- Either b or c
Operating systems usually use numbers to represent error codes. What should be the return type of a function that can return either a numerical value or a numerical error code?
- number
- { value: number, error: number }
- number | number
- Either<number, number>
3.3. The visitor pattern
Let’s go over the visitor design pattern and look at traversing the items that make up a document—first through an object-oriented lens and then with the generic tagged union type we implemented. Don’t worry if you aren’t very familiar with the visitor design pattern; we’ll review how it works as we’re working through our example.
We’ll start with a naïve implementation, show how the visitor design pattern improves the design, and then show an alternative implementation that removes the need for class hierarchies.
We start with three document items: paragraph, picture, and table. We want to either render them onscreen or have a screen reader read them aloud for visually impaired users.
3.3.1. A naïve implementation
One approach we can take is to provide a common interface to ensure that each item knows how to draw itself on a screen and read itself, as shown in the next listing.
Listing 3.19. Naïve implementation
class Renderer { /* Rendering methods */ } 1
class ScreenReader { /* Screen reading methods */ } 1
interface IDocumentItem { 2
render(renderer: Renderer): void;
read(screenReader: ScreenReader): void;
}
class Paragraph implements IDocumentItem { 3
/* Paragraph members omitted */
render(renderer: Renderer) {
/* Uses renderer to draw itself on screen */
}
read(screenReader: ScreenReader) {
/* Uses screenReader to read itself */
}
}
class Picture implements IDocumentItem { 3
/* Picture members omitted */
render(renderer: Renderer) {
/* Uses renderer to draw itself on screen */
}
read(screenReader: ScreenReader) {
/* Uses screenReader to read itself */
}
}
class Table implements IDocumentItem { 3
/* Table members omitted */
render(renderer: Renderer) {
/* Uses renderer to draw itself on screen */
}
read(screenReader: ScreenReader) {
/* Uses screenReader to read itself */
}
}
let doc: IDocumentItem[] = [new Paragraph(), new Table()];
let renderer: Renderer = new Renderer();
for (let item of doc) {
item.render(renderer);
}
- 1 The two classes provide methods to render and read, omitted here for brevity.
- 2 The IDocumentItem interface specifies that each item can render itself and read itself.
- 3 Document elements implement IDocumentItem and, given a renderer or screen reader, draw themselves or read themselves aloud.
This approach is not great from a design point of view. The document items store information that describes document content, such as text or an image, and should not be responsible for other things, such as rendering and accessibility. Having rendering and accessibility code in each document item class bloats the code. Worse, if we need to add a new capability—say, for printing—we need to update the interface and all implementing classes to implement the new capability.
3.3.2. Using the visitor pattern
The visitor pattern is an operation to be performed on elements of an object structure. This pattern lets you define a new operation without changing the classes of the elements on which it operates.
In our example shown in listing 3.20, the pattern should allow us to add a new capability without having to touch the code of the document items. We can achieve this task with the double-dispatch mechanism, in which document items accept any visitor and then pass themselves to it. The visitor knows how to process each individual item (by rendering it, reading it aloud, and so on), so given an instance of the item, it performs the right operation (figure 3.6).
Figure 3.6. A visitor pattern. The IDocumentItem interface ensures that every document item has an accept() method that takes an IVisitor. IVisitor ensures that every visitor can handle all possible document item types. Each document item implements accept() to send itself to the visitor. With this pattern, we can separate responsibilities, such as screen rendering and accessibility, to individual components (visitors) and abstract them away from the document items.
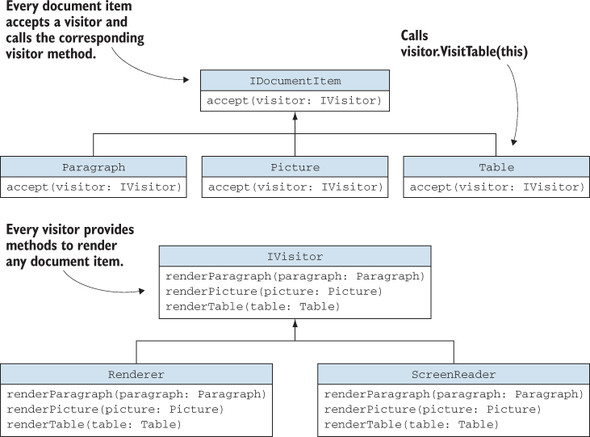
Double dispatch comes from the fact that, given an IDocumentItem, the right accept() method is called first; then, given the IVisitor argument, the right operation is performed.
Listing 3.20. Processing with the visitor pattern
interface IVisitor { 1
visitParagraph(paragraph: Paragraph): void;
visitPicture(picture: Picture): void;
visitTable(table: Table): void;
}
class Renderer implements IVisitor { 2
visitParagraph(paragraph: Paragraph) { /* ... */ }
visitPicture(picture: Picture) { /* ... */ }
visitTable(table: Table) { /* ... */ }
}
class ScreenReader implements IVisitor { 1
visitParagraph(paragraph: Paragraph) { /* ... */ }
visitPicture(picture: Picture) { /* ... */ }
visitTable(table: Table) { /* ... */ }
}
interface IDocumentItem { 3
accept(visitor: IVisitor): void;
}
class Paragraph implements IDocumentItem {
/* Paragraph members omitted */
accept(visitor: IVisitor) {
visitor.visitParagraph(this); 4
}
}
class Picture implements IDocumentItem {
/* Picture members omitted */
accept(visitor: IVisitor) {
visitor.visitPicture(this); 4
}
}
class Table implements IDocumentItem {
/* Table members omitted */
accept(visitor: IVisitor) {
visitor.visitTable(this); 4
}
}
let doc: IDocumentItem[] = [new Paragraph(), new Table()];
let renderer: IVisitor = new Renderer();
for (let item of doc) {
item.accept(renderer);
}
- 1 The IVisitor interface specifies that each visitor should be able to process all shapes.
- 2 The concrete Renderer and ScreenReader implement this interface.
- 3 Now document items need only implement an accept() method that takes any visitor.
- 4 Items call the appropriate method on the visitor and pass themselves as arguments.
Now a visitor can go over a collection of IDocumentItem objects and process them by calling accept() on each. The responsibility of processing is moved from the items themselves to the visitors. Adding a new visitor does not affect the document items; the new visitor just needs to implement the IVisitor interface, and document items would accept it as they would any other.
A new Printer visitor class would implement logic to print a paragraph, a picture, and a table in the visitParagraph(), visitPicture(), and visitTable() methods. The document items themselves would become printable without having to change.
This example is a classical implementation of the visitor pattern. Next, let’s look at how we could achieve something similar by using a variant instead.
3.3.3. Visiting a variant
First, let’s go back to our generic variant type and implement a visit() function that takes a variant and a set of functions, one for each type, and (depending on the value stored in the variant) applies the right function to it.
Listing 3.21. Variant visitor
function visit<T1, T2, T3>(
variant: Variant<T1, T2, T3>,
func1: (value: T1) => void, 1
func2: (value: T2) => void, 1
func3: (value: T3) => void 1
): void {
switch (variant.index) {
case 0: func1(<T1>variant.value); break; 2
case 1: func2(<T2>variant.value); break; 2
case 2: func3(<T3>variant.value); break; 2
default: throw new Error();
}
}
- 1 The visit function takes as arguments a function for each type that makes up the variant.
- 2 Based on index, the function matching the type of the stored value is called.
If we place our document items in a variant, we can use this function to select the appropriate visitor method. If we do this, we no longer have to force any of our classes to implement certain interfaces: responsibility for matching the right document item with the right processing method is moved to this generic visit() function.
Document items no longer need to know anything about visitors and don’t need to “accept” them, as the following listing shows.
Listing 3.22. Alternative processing with variant visitor
class Renderer {
renderParagraph(paragraph: Paragraph) { /* ... */ }
renderPicture(picture: Picture) { /* ... */ }
renderTable(table: Table) { /* ... */ }
}
class ScreenReader {
readParagraph(paragraph: Paragraph) { /* ... */ }
readPicture(picture: Picture) { /* ... */ }
readTable(table: Table) { /* ... */ }
}
class Paragraph { 1
/* Paragraph members omitted */
}
class Picture { 1
/* Picture members omitted */
}
class Table { 1
/* Table members omitted */
}
let doc: Variant<Paragraph, Picture, Table>[] = [ 2
Variant.make1(new Paragraph()),
Variant.make3(new Table())
];
let renderer: Renderer = new Renderer();
for (let item of doc) {
visit(item, 3
(paragraph: Paragraph) => renderer.renderParagraph(paragraph),
(picture: Picture) => renderer.renderPicture(picture),
(table: Table) => renderer.renderTable(table)
);
}
- 1 Document items no longer need a common interface.
- 2 We store document items in a variant that can hold any of the available items.
- 3 The visit function matches the item with the right processing method.
With this approach, we decouple the double-dispatch mechanism from the types we are using and move it to the variant/visitor. The variant and visitor are generic types that can be reused across different problem domains. The advantage of this approach is that it lets visitors be responsible only for processing and document items be responsible only for storing domain data (figure 3.7).
Figure 3.7. A simplified visitor pattern: now the document items and visitors don’t need to implement any interfaces. Contrast this figure with figure 3.6. Responsibility for matching a document item with the right visitor method is encapsulated in the visit() method. As we can see from the figure, the types are not related, which is a good thing: it makes our program more flexible.
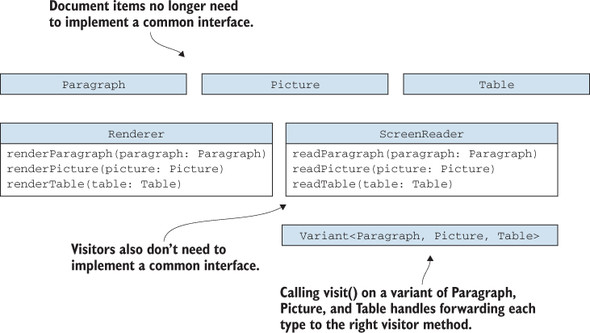
The visit() function we introduced is also the expected way to use a variant type. Performing a switch on the index of the variant when we want to figure out exactly which type it contains could be error-prone. But usually, once we have a variant, we don’t want to extract the value; instead, we apply functions to it by using visit(). This way, the error-prone switch is handled in the visit() implementation, and we don’t have to worry about it. Encapsulating error-prone code in a reusable component is good practice for reducing risk, because when the implementation is stable and tested, we can rely on it in multiple scenarios.
Using a variant-based visitor instead of the classical OOP implementation has the advantage that it fully separates our domain objects from the visitors. Now we don’t even need an accept() method, and document items don’t need to know anything about what is processing them. They also don’t have to conform to any particular interface, such as IDocumentItem in our example. That’s because the glue code that matches visitors with shapes is encapsulated in Variant and its visit() function.
3.3.4. Exercise
Our visit() implementation returns void. Extend it so that given a Variant<T1, T2, T3>, it returns a Variant<U1, U2, U3> by applying one of three functions: (value: T1) => U1, or (value: T2) => U2, or (value: T3) => U3.
3.4. Algebraic data types
You might have heard the term algebraic data types (ADTs). ADTs are ways to combine types within a type system. In fact, this is exactly what we covered during this chapter. ADTs provide two ways to combine types: product types and sum types.
3.4.1. Product types
Product types are what we called compound types in this chapter. Tuples and records are product types because their values are products of their composing types. The types A = {a1, a2} (type A with possible values a1 and a2) and B = {b1, b2} (type B with possible values b1 and b2) combine into the tuple type <A, B> as A x B = {(a1, b1), (a1, b2), (a2, b1), (a2, b2)}.
Product Types
Product types combine multiple other types into a new type that stores a value from each of the combined types. The product type of types A, B, and C—which we can write as A x B x C—contains a value from A, a value from B, and a value from C. Tuple and record types are examples of product types. Additionally, records allow us to assign meaningful names to each of their components.
Record types should be very familiar, as they are usually the first composition method that new programmers learn. Recently, tuples have made their way into mainstream programming languages, but they shouldn’t be particularly hard to understand. Tuples are very similar to record types except that we can’t name their members and usually can define them inline by specifying the types that make up the tuple. In TypeScript, for example, [number, number] defines the tuple type composed of two number values.
We covered product types before sum types, as they should be more familiar. Almost all programming languages provide ways to define record types. Fewer mainstream languages provide syntactic support for sum types.
3.4.2. Sum types
Sum types are what we called either-or types earlier in this chapter. They combine types by allowing a value from any one of the types, but only one of them. The types A = {a1, a2} and B = {b1, b2} combine into the sum type A | B as A + B = {a1, a2, b1, b2}.
Sum Types
Sum types combine multiple other types into a new type that stores a value from any one of the combined types. The sum type of types A, B, and C—which we can write as A + B + C—contains a value from A, or a value from B, or a value from C. Optional and variant types are examples of sum types.
As we saw, TypeScript has the | type operator, but common sum types such as Optional , Either, and Variant can be implemented without it. These types provide powerful ways for representing result or error and closed sets of types, and enable different ways to implement the common visitor pattern.
In general, sum types allow us to store values from unrelated types in a single variable. As in the visitor pattern example, an object-oriented alternative would be to use a common base class or interface, but that doesn’t scale as well. If we mix and match different types in different places of our application, we end up with a lot of interfaces or base classes that aren’t particularly reusable. Sum types provide a simple, clean way to compose types for such scenarios.
3.4.3. Exercises
What kind of type does the following statement declare?
let x: [number, string] = [42, "Hello"];
- A primitive type
- A sum type
- A product type
- Both a sum and a product type
What kind of type does the following statement declare?
let y: number | string = "Hello";
- A primitive type
- A sum type
- A product type
- Both a sum and a product type
Given an enum Two { A, B } and an enum Three { C, D, E }, how many possible values does the tuple type [Two, Three] have?
- 2
- 5
- 6
- 8
Given an enum Two { A, B } and an enum Three { C, D, E }, how many possible values does the type Two | Three have?
- 2
- 5
- 6
- 8
Summary
- Product types are tuples and records that group values from multiple types.
- Records allow us to name members, thus giving them meaning. Records leave less room for ambiguity than tuples.
- Invariants are rules that a well-formed record must obey. If a type has invariants, making members private or readonly ensures that the invariants are enforced and that external code cannot break them.
- Sum types group types as either-or, in which values are of one of the component types.
- Functions should return a value or an error, not a value and an error.
- Optional types hold a value of the underlying type or nothing. It’s generally less error-prone when the absence of a value is not itself part of the domain of a variable (null billion-dollar mistake).
- Either types hold a value of the left or the right type. By convention, right is right, so left is error.
- Variants can hold a value of any number of underlying types and enable us to express values of a closed sets of types without requiring any relationship between them (no common interfaces or base type).
- A visitor function that applies the right function to a variant enables an alternative implementation of the visitor pattern, with better division of responsibilities.
In this chapter, we covered various ways to create new types by combining existing types. In chapter 4, we’ll see how we can increase the safety of our program by relying on the type system to encode meaning and restricting the range of allowed values for our types. We’ll also see how we can add and remove type information and how this can be applied to scenarios such as serialization.
Answers to exercises
Compound types
c—Naming the three components of the coordinates is the preferred approach.
Expressing either-or with types
c—An enum is appropriate in this case. With existing requirements, classes aren’t needed.
d—Either a built-in sum type or Optional is a valid return type, as both can represent the absence of a value
d—A discriminate union type is best (number | number wouldn’t be able to distinguish whether the value represents an error.)
The visitor pattern
Here is a possible implementation:
function visit<T1, T2, T3, U1, U2, U3>( variant: Variant<T1, T2, T3>, func1: (value: T1) => U1, func2: (value: T2) => U2, func3: (value: T3) => U3 ): Variant<U1, U2, U3> { switch (variant.index) { case 0: return Variant.make1(func1(<T1>variant.value)); case 1: return Variant.make2(func2(<T2>variant.value)); case 2: return Variant.make3(func3(<T3>variant.value)); default: throw new Error(); } }
Algebraic data types
c—Tuples are product types.
b—This is a TypeScript sum type.
c—Because tuples are product types, we multiply the possible values of the two enums (2 x 3).
b—Because this is a sum type, we add the possible values of the two enums (2 + 3).