
Chapter 5. Function types
This chapter covers
- Simplifying the strategy pattern with function types
- Implementing a state machine without switch statements
- Implementing lazy values as lambdas
- Using the fundamental data processing algorithms map, filter, and reduce to reduce code duplication
We covered basic types and types built up from them. We also looked at how we can declare new types to increase the safety of our programs and enforce various constraints on their values. This is about as far as we can get with algebraic data types or the ability to combine types as sum types and product types.
The next feature of type systems we are going to cover, which unlocks a whole new world of expressiveness, is the ability to type functions. If we can name function types and use functions in the same places we use values of other types—as variables, arguments, and function returns—we can simplify the implementation of several common constructs and abstract common algorithms to library functions.
In this chapter, we’ll look at how we can simplify the implementation of the strategy design pattern. (We’ll also have a quick refresher on the pattern, in case you forgot it.) Then we’ll talk about state machines and how they can be implemented more succinctly with function properties. We’ll cover lazy values, or how we can defer expensive computation in the hope that we won’t need it. Finally, we’ll deep dive into the fundamental map(), reduce(), and filter() algorithms.
All these applications are enabled by function types, the next step in the evolution of type systems after basic types and their combinations. Because most programming languages nowadays support these types, we’ll get a fresh look at some old, tried, and tested concepts.
5.1. A simple strategy pattern
One of the most commonly used design patterns is the strategy pattern. The strategy design pattern is a behavioral software design pattern that enables selecting an algorithm at run time from a family of algorithms. It decouples the algorithms from the components using them, which improves the flexibility of the overall system. The pattern is usually presented as in figure 5.1.
Figure 5.1. Strategy pattern made up of an IStrategy interface, ConcreteStrategy1 and ConcreteStrategy2 implementations, and a Context that uses the algorithms through the IStrategy interface.

Let’s look at a concrete example. Suppose that we have a car wash with two types of services: a Standard wash and a Premium wash (which, for an extra $3, provides additional polish).
We can implement this example as a strategy, in which our IWashingStrategy interface provides a wash() method. Then we provide two implementations of this interface: a StandardWash and a PremiumWash. Our CarWash is the context that applies an IWashingStrategy.wash() to a car depending on which service the customer paid for.
Listing 5.1. Car-wash strategy
class Car {
/* Represents a car */ 1
}
interface IWashingStrategy { 2
wash(car: Car): void;
}
class StandardWash implements IWashingStrategy { 3
wash(car: Car): void {
/* Perform standard wash */
}
}
class PremiumWash implements IWashingStrategy { 3
wash(car: Car): void {
/* Perform premium wash */
}
}
class CarWash {
service(car: Car, premium: boolean) {
let washingStrategy: IWashingStrategy;
if (premium) { 4
washingStrategy = new PremiumWash();
} else {
washingStrategy = new StandardWash();
}
washingStrategy.wash(car); 4
}
}
- 1 The Car class represents a car to be washed.
- 2 IWashingStrategy is the interface of our strategy pattern declaring a wash() method.
- 3 StandardWash and PremiumWash are concrete implementations of the strategy.
- 4 Depending on a flag, we select the algorithm to use and then wash() the car instance with it.
This code works, but it is needlessly verbose. We’ve introduced an interface and two implementing types, each providing a single wash() method. These types are not really important; the valuable part of our code is the washing logic. This code is just a function, so we can simplify our code a lot if we move from interfaces and classes to a function type and the two concrete implementations.
5.1.1. A functional strategy
We can define WashingStrategy to be a type representing a function that receives a Car as an argument and returns void. Then we can implement the two types of washes as two functions—standardWash() and premimumWash()—both taking a Car and returning void. The CarWash can select one of them to apply to a given car.
Listing 5.2. Car-wash strategy revisited
class Car {
/* Represents a car */
}
type WashingStrategy = (car: Car) => void; 1
function standardWash(car: Car): void { 2
/* Perform standard wash */
}
function premiumWash(car: Car): void { 2
/* Perform premium wash */
}
class CarWash {
service(car: Car, premium: boolean) {
let washingStrategy: WashingStrategy; 3
3
if (premium) { 3
washingStrategy = premiumWash;
} else {
washingStrategy = standardWash;
}
washingStrategy(car); 4
}
}
- 1 WashingStrategy is a function that takes a Car and returns void.
- 2 standardWash() and premiumWash() implement our car-washing logic.
- 3 Now we can assign a function directly to washingStrategy when we select the algorithm.
- 4 Because the washingStrategy variable is a function, we can simply call it.
This implementation has fewer parts than the preceding one, as we can see in figure 5.2.
Figure 5.2. Strategy pattern made up of a Context that uses a function: either concreteStrategy1() or concreteStrategy2()

Let’s zoom in on the function type declaration, because we’re using one for the first time.
5.1.2. Typing functions
The function standardWash() takes an argument of type Car and returns void, so its type is function from Car to void or, in TypeScript syntax, (car: Car) => void. The function premiumWash(), even though it has a different implementation, has exactly the same argument type and return type, so it has the same type.
Function type or signature
The type of a function is given by the type of its arguments and its return type. If two functions take the same arguments and return the same type, they have the same type. The set of arguments plus return type is also known as the signature of a function.
We want to refer to this type, so we give it a name by declaring type WashingStrategy = (car: Car) => void. Whenever we use WashingStrategy as a type, we mean the function type (car: Car) => void. We refer to it in the CarWash.service() method.
Because we can type functions, we can have variables that represent functions. In our example, the washingStrategy variable represents a function with the signature we just named. We can assign any function that takes a Car and returns void to this variable. We can also call it as we would a function. In the first example that used an IWashingStrategy interface, we ran our car-washing logic by calling washingStrategy.wash(car). In our second example, in which washingStrategy is a function, we simply called washingStrategy(car).
First-class functions
The ability to assign functions to variables and treat them like any other values in the type system results in what are called first-class functions. That means the language treats functions like first-class citizens, granting them the same rights as other values: they have types; and they can be assigned to variables and passed around as arguments, checked for validity, and converted (if compatible) to other types.
5.1.3. Strategy implementations
Earlier, we saw two ways to implement a strategy pattern. Contrasting the two implementations, the by-the-book strategy implementation in the first example requires a lot of extra machinery: we need to declare an interface, and we need to have multiple classes implementing that interface to provide the concrete logic of the strategy. The second implementation is boiled down to the essence of what we are trying to achieve: we have two functions implementing the logic, and we refer to them directly.
Both implementations achieve the same goals. The reason why the first one, which relies on interfaces, is more widespread is that when design patterns became all the rage in the 1990s, not all mainstream programming languages supported first-order functions. In fact, few of them did. This is no longer the case. Most languages can type functions now, and we can leverage that capability to provide more-succinct implementations of some design patterns.
It’s important to keep in mind that the pattern is the same: we are still encapsulating a family of algorithms and selecting at run time the one to use. The difference is in the implementation, which modern capabilities allow us to express more easily. We’re replacing an interface and two classes (each class implementing a method) with a type declaration and two functions.
In most cases, the more-succinct implementation is enough. We might need to reconsider the interface and classes implementation when the algorithms are not representable as simple functions. Sometimes, we need multiple functions or need to track some state, in which case the first implementation would be better suited, as it groups the related pieces of a strategy under a common type.
5.1.4. First-class functions
Before we move on, let’s quickly review some of the terms introduced in this section:
- The set of arguments plus the return value of a function is called the signature of a function. The following two functions have the same signature:
function add(x: number, y: number): number { return x + y; } function subtract(x: number, y: number): number { return x - y; } - The signature of a function is equivalent to its type in languages that can type functions. The preceding two functions have the type function from (number, number) to number, or (x: number, y: number) => number. Note that the actual name of the arguments doesn’t matter; (a: number, b: number) => number has the same type as (x: number, y: number) => number.
- When languages treat functions as they do any other values, we say that they support first-class functions. Functions can be assigned to variables, passed as arguments, and used like other values, which makes code more expressive.
5.1.5. Exercises
What is the type of a function isEven() that takes a number as an argument and returns true if the number is even and false otherwise?
- [number, boolean]
- (x: number) => boolean
- (x: number, isEven: boolean)
- {x: number, isEven: boolean}
What is the type of a function check() that takes a number and a function of the same type as isEven() as arguments and returns the result of applying the given function to the given value?
- (x: number, func: number) => boolean
- (x: number) => (x: number) => boolean
- (x: number, func: (x: number) => boolean) => boolean
- (x: number, func: (x: number) => boolean) => void
5.2. A state machine without switch statements
One very useful application of first-class functions enables us to define a property of a class as having a function type. Then we can assign different functions to it, changing the behavior at run time. This acts as a plug-in method on the class, and we can swap it as needed.
We can implement a pluggable Greeter, for example. Instead of implementing a greet() method, we implement a greet property with a function type. Then we can assign multiple greeting functions to it, such as sayGoodMorning() and sayGoodNight().
Listing 5.3. Pluggable Greeter
function sayGoodMorning(): void { 1
console.log("Good morning!");
}
function sayGoodNight(): void { 1
console.log("Good night!");
}
class Greeter {
greet: () => void = sayGoodMorning; 2
}
let greeter: Greeter = new Greeter();
greeter.greet(); 3
greeter.greet = sayGoodNight; 4
greeter.greet(); 5
- 1 Two greeting functions that output their respective greetings to the console
- 2 greet is a function with no arguments that returns void and defaults to sayGoodMorning().
- 3 Because greet is a function property, we can call it as a method of the class.
- 4 We can assign another function to it.
- 5 The second call will invoke sayGoodNight().
This follows from the strategy pattern implementation discussed in the previous section, but it’s worth noting that this approach enables us to easily add pluggable behavior to a class. If we want to add a new greeting, we simply need to add another function with the same signature and assign it to the greet property.
5.2.1. Early Programming with Types
While working on an early draft of this book, I wrote a small script to help me keep the source code in sync with the text. The draft was written in the popular Markdown format. I kept the source code in separate TypeScript files so I could compile them and ensure that even if I update the code samples, they’ll still work.
I needed a way to ensure that the Markdown text always contains the latest code samples. The code samples always appear between a line containing ```ts and a line containing ```. When HTML is generated from the Markdown source, ```ts is interpreted as the beginning of a TypeScript code block, which gets rendered with TypeScript syntax highlighting, whereas ``` marks the end of that code block. The contents of these code blocks had to be inlined from actual TypeScript source files that I could compile and validate outside the text (figure 5.3).
Figure 5.3. Two TypeScript (.ts) files containing code samples that should be inlined in the Markdown document between ```ts and ``` markers. The <!-- ... --> comments annotate the code samples for my script.
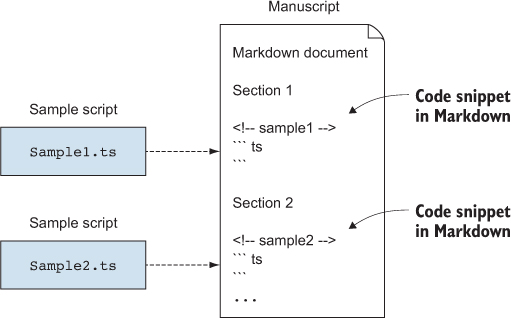
To determine which code sample went where, I relied on a small trick. Markdown allows raw HTML in the document text, so I annotated each code sample with an HTML comment, such as <!-- sample1 -->. HTML comments do not get rendered, so when Markdown is converted to HTML, they became invisible. On the other hand, my script could use these comments to determine which code sample to inline where.
When all code samples were loaded from disk, I had to process each Markdown document of the draft and produce an updated version as follows:
- In text processing mode, simply copy each line of the input text to the output document as is. When a marker is encountered (<!-- sample -->), grab the corresponding code sample, and switch to marker processing mode.
- In marker processing mode, again copy each line of the input text to the output document until we encounter a code block marker (```ts). When the code marker is encountered, output the latest version of the code sample as loaded from the TypeScript file, and switch to code processing mode.
- In code processing mode, we already ensured that the latest version of the code is in the output document, so we can skip the potentially outdated version in the code block. We skip each line until we encounter the end of code block marker (```). Then we switch back to text processing mode.
With each run, the existing code samples in the document preceded by a <!-- ... --> marker get updated to the latest version of the TypeScript files on disk. Other code blocks that aren’t preceded by <!-- ... --> don’t get updated, as they are processed in text processing mode.
As an example, here is a helloWorld.ts code sample.
Listing 5.4. helloWorld.ts
console.log("Hello world!");
We want to embed this code in Chapter1.md and make sure that it’s kept up to date, as shown in the next listing.
Listing 5.5. Chapter1.md
# Chapter 1
Printing "Hello world!".
<!-- helloWorld -->
```ts
console.log("Hello"); 1
```
- 1 This is not quite up to date. The string here is “Hello”, which does not match helloWorld.ts.
This document gets processed line by line as follows:
- In text processing mode, "# Chapter 1" is copied to the output as is.
- "" (blank line) is copied to the output as is.
- "Printing "Hello world!"." is copied to the output as is.
- "<!-- helloWorld -->" is copied to the output as is. This is a marker, though, so we keep track of the code sample to be inlined (helloWorld.ts) and switch to marker processing mode.
- "```ts" is copied to the output as is. This marker is a code block marker, so immediately after copying it to the output, we also output the contents of helloWorld.ts. We also switch to code processing mode.
- "console.log("Hello");" is skipped. We don’t copy lines in code processing mode, as we are replacing them with the latest in the code sample file.
- "```" is an end-of-code-block marker. We insert it and then switch back to text processing mode.
5.2.2. State machines
The behavior of our text processing script is best modeled as a state machine. A state machine has a set of states and a set of transitions between pairs of states. The machine starts in a given state, also known as the start state; if certain conditions are met, it can transition to another state.
This is exactly what our text processor does with its three processing modes. Input lines are processed in a certain way in text processing mode. When some condition is met (a <!-- sample --> marker is encountered), our processor transitions to marker processing mode. Again, when some other condition is met (a ```ts code-block marker is encountered), it transitions to code processing mode. When the end of the code-block marker is encountered (```), it transitions back to text processing mode (figure 5.4).
Figure 5.4. Text processing state machine with the three states (text processing, marker processing, code processing) and transitions between the states based on input. Text processing is the initial state or start state.

Now that we’ve modeled the solution, let’s look at how we would implement it. One way to implement a state machine is to define the set of states as an enumeration, keeping track of the current state, and get the desired behavior with a switch statement that covers all possible states. In our case, we can define a TextProcessingMode enum.
Our TextProcessor class will keep track of the current state in a mode property and implement the switch statement in a process-Line() method. Depending on the state, this method will in turn invoke one of the three processing methods: processTextLine(), processMarkerLine(), or process-CodeLine(). These functions will implement the text processing and then, when appropriate, transition to another state by updating the current state.
Processing a Markdown document consisting of multiple lines of text means processing each line in turn, using our state machine, and then returning the final result to the caller, as shown in the next listing.
Listing 5.6. State machine implementation
enum TextProcessingMode { 1
Text,
Marker,
Code,
}
class TextProcessor {
private mode: TextProcessingMode = TextProcessingMode.Text;
private result: string[] = [];
private codeSample: string[] = [];
processText(lines: string[]): string[] {
this.result = [];
this.mode = TextProcessingMode.Text;
for (let line of lines) { 2
this.processLine(line);
}
return this.result;
}
private processLine(line: string): void {
switch (this.mode) { 3
case TextProcessingMode.Text:
this.processTextLine(line);
break;
case TextProcessingMode.Marker:
this.processMarkerLine(line);
break;
case TextProcessingMode.Code:
this.processCodeLine(line);
break;
}
}
private processTextLine(line: string): void { 4
this.result.push(line);
if (line.startsWith("<!--")) { 4
this.loadCodeSample(line);
this.mode = TextProcessingMode.Marker;
}
}
private processMarkerLine(line: string): void { 5
this.result.push(line);
if (line.startsWith("```ts")) { 5
this.result = this.result.concat(this.codeSample);
this.mode = TextProcessingMode.Code;
}
}
private processCodeLine(line: string): void { 6
if (line.startsWith("```")) { 6
this.result.push(line);
this.mode = TextProcessingMode.Text;
}
}
private loadCodeSample(line: string) { 7
/* Load sample based on marker, store in this.codeSample */
}
}
- 1 States are represented as an enum.
- 2 Processing a text document means processing each line and returning the resulting string array.
- 3 The state machine switch statement calls the appropriate processor based on the current state.
- 4 Processes a line of text. If the line starts with “<!--”, load code sample and transition to next state.
- 5 Processes marker. If the line starts with “```ts”, inline code sample and transition to next state.
- 6 Process code by skipping lines. If the line starts with “```”, transition to text processing state.
- 7 The body of this function is omitted, as it’s not important for this example.
We omitted the code to load a sample from an external file, as it isn’t particularly relevant to our state machine discussion. This implementation works but can be simplified if we use a pluggable function.
Note that all our text processing functions have the same signature: they take a line of text as a string argument and return void. What if, instead of having processLine() implement a big switch statement and forward to the appropriate function, we make processLine() one of those functions?
Instead of implementing processLine() as a method, we can define it as a property of the class with type (line: string) => void and initialize it with process-TextLine(), as shown in the following code. Then, in each of the three text processing methods, instead of setting mode to a different enum value, we set processLine to a different method. In fact, we no longer need to keep track of our state externally. We don’t even need an enum!
Listing 5.7. Alternative state machine implementation
class TextProcessor {
private result: string[] = [];
private processLine: (line: string) => void = this.processTextLine;
private codeSample: string[] = [];
processText(lines: string[]): string[] {
this.result = [];
this.processLine = this.processTextLine;
for (let line of lines) {
this.processLine(line);
}
return this.result;
}
private processTextLine(line: string): void {
this.result.push(line);
if (line.startsWith("<!--")) {
this.loadCodeSample(line);
this.processLine = this.processMarkerLine; 1
}
}
private processMarkerLine(line: string): void {
this.result.push(line);
if (line.startsWith("```ts")) {
this.result = this.result.concat(this.codeSample);
this.processLine = this.processCodeLine; 1
}
}
private processCodeLine(line: string): void {
if (line.startsWith("```")) {
this.result.push(line);
this.processLine = this.processTextLine; 1
}
}
private loadCodeSample(line: string) {
/* Load sample based on marker, store in this.codeSample */
}
}
The second implementation gets rid of the TextProcessingMode enum, the mode property, and the switch statement that forwarded processing to the appropriate method. Instead of handling forwarding, processLine now is the appropriate processing method.
This implementation removes the need to keep track of states separately and keep that in sync with the processing logic. If we ever wanted to introduce a new state, the old implementation would’ve forced us to update the code in several places. Besides implementing the new processing logic and state transitions, we would’ve had to update the enum and add another case to the switch statement. Our alternative implementation removes the need for that task: a state is represented purely by a function.
One caveat is that for state machines with many states, capturing states and even transitions explicitly might make the code easier to understand. Even so, instead of using enums and switch statements, another possible implementation represents each state as a separate type and the whole state machine as a sum type of the possible states, allowing us to break it apart into type-safe components. Following is an example of how we would implement the state machine by using a sum type. The code is a bit more verbose, so if possible, we should try the implementation we’ve discussed so far, which is another alternative to a switch-based state machine.
When a sum type is used, each state is represented by a different type, so we have a TextLineProcessor, a MarkerLineProcessor, and a CodeLine-Processor. Each keeps track of the processed lines so far in a result member and provides a process() method to handle a line of text.
State machine with sum type
class TextLineProcessor {
result: string[];
constructor(result: string[]) {
this.result = result;
}
process(line: string): TextLineProcessor | MarkerLineProcessor { 1
this.result.push(line);
if (line.startsWith("<!--")) { 2
return new MarkerLineProcessor(
this.result, this.loadCodeSample(line));
} else {
return this;
}
}
private loadCodeSample(line: string): string[] {
/* Load sample based on marker, store in this.codeSample */
}
}
class MarkerLineProcessor {
result: string[];
codeSample: string[]
constructor(result: string[], codeSample: string[]) {
this.result = result;
this.codeSample = codeSample;
}
process(line: string): MarkerLineProcessor | CodeLineProcessor { 3
this.result.push(line);
if (line.startsWith("```ts")) { 4
this.result = this.result.concat(this.codeSample);
return new CodeLineProcessor(this.result);
} else {
return this;
}
}
}
class CodeLineProcessor {
result: string[];
constructor(result: string[]) {
this.result = result;
}
process(line: string): CodeLineProcessor | TextLineProcessor { 5
if (line.startsWith("```")) { 6
this.result.push(line);
return new TextLineProcessor(this.result);
} else {
return this;
}
}
}
function processText(lines: string): string[] {
let processor: TextLineProcessor | MarkerLineProcessor 7
| CodeLineProcessor = new TextLineProcessor([]);
for (let line of lines) {
processor = processor.process(line); 8
}
return processor.result;
}
- 1 TextLineProcessor returns either a TextLineProcessor or a MarkerLineProcessor to process the next line.
- 2 If the line starts with “<!--”, return a new MarkerLineProcessor; otherwise, return this processor.
- 3 MarkerLineProcessor returns either a MarkerLineProcessor or a CodeLineProcessor.
- 4 If we encounter “```ts”, load the code sample and return a new CodeLineProcessor; otherwise, return this processor.
- 5 CodeLineProcessor returns a CodeLineProcessor or a TextLineProcessor.
- 6 If the line starts with “```”, append it to the result and return a new TextLineProcessor; otherwise, return this processor.
- 7 The states are represented by the processor, which is a sum type of TextLineProcessor, MarkerLineProcessor, and CodeLineProcessor.
- 8 processor gets updated after each line processed, in case there is a state change.
All our processors return a processor instance: this, if there is no state change, or a new processor as state changes. The processText() runs the state machine by calling process() on each line of text and updating processor as state changes by reassigning it to the result of the method call.
Now the set of states is spelled out explicitly in the signature of the processor variable, which can be a TextLineProcessor, a MarkerLineProcessor, or a CodeLineProcessor.
The possible transitions are captured in the signatures of the process() methods. TextLineProcessor.process returns TextLineProcessor | MarkerLine-Processor, for example, so it can stay in the same state (TextLineProcessor) or transition to the MarkerLineProcessor state. These state classes can have more properties and members if needed. This implementation is slightly longer than the one that relies on functions, so if we don’t need the extra features, we are better off using the simpler solution.
5.2.3. State machine implementation recap
Let’s quickly review the alternative implementations discussed in this section and then look at other applications of function types:
- The “classical” implementation of a state machine uses an enum to define all the possible states, a variable of that enum type to keep track of the current state, and a big switch statement to determine which processing should be performed based on the current state. State transitions are implemented by updating the current state variable. The drawback of this implementation is that states are removed from the processing that we want to run during each state, so the compiler can’t prevent mistakes when we run the wrong processing while in a given state. Nothing stops us, for example, from calling processCodeLine() even when we’re in TextProcessingMode.Text. We also have to maintain state and transitions as a separate enum, with the risk of running out of sync. (We might add a new value to the enum but forget to add a case for it in the switch statement, for example.)
- The functional implementation represents each processing state as a function and relies on a function property to track the current state. State transitions are implemented by assigning the function property to another state. This implementation is lightweight and should work for many cases. There are two drawbacks: sometimes, we need to associate more information with each state; and we might want to be explicit when declaring the possible states and transitions.
- The sum type implementation represents each processing state as a class and relies on a variable representing the sum type of all the possible states to keep track of the current state. State transitions are implemented by reassigning the variable to another state, which allows us to add properties and members to each state and keep them grouped together. The drawback is that the code is more verbose than the functional alternative.
This concludes our discussion of state machines. In the next section, we look at another use of function types: implementing lazy evaluation.
5.2.4. Exercises
Model a simple connection that can be open or closed as a state machine. A connection is opened with connect and closed with disconnect.
Implement the preceding connection as a functional state machine with a process() function. In a closed connection, process() opens a connection. In an open connection, process() calls a read() function that returns a string. If the string is empty, the connection is closed; otherwise, the read string is logged to the console. read() is given as declare function read(): string;.
5.3. Avoiding expensive computation with lazy values
Another advantage of being able to use functions as any other value is that we can store them and invoke them only when needed. Sometimes, a value we may want is expensive to compute. Let’s say that my program can build a Bike and a Car. I may want a Car. But a Car is expensive to build, so I might decide to ride my bike instead. A Bike is extremely cheap to build, so I’m not worried about the cost. Instead of always building a Car with each run of the program, just so I can use it if I want it, wouldn’t it be better to give me the ability to ask for a Car? In that case, I would ask for it when I really needed it and execute the expensive building logic then. If I never asked for it, no resources would be wasted.
The idea is to postpone expensive computation as much as possible, in the hope that it may not be needed at all. Because computation is expressed as functions, we can pass around functions instead of actual values and call them when and whether we need the values. This process is called lazy evaluation. The opposite is eager evaluation, in which we produce the values immediately and pass them around even if we decide later to discard them.
Listing 5.8. Eager Car production
class Bike { } 1
class Car { } 1
function chooseMyRide(bike: Bike, car: Car): Bike | Car { 2
if (isItRaining()) {
return car;
} else {
return bike;
}
}
chooseMyRide(new Bike(), new Car()); 3
- 1 Car and Bike. Let’s assume that Car is expensive to create.
- 2 The chooseMyRide() function will pick Bike or Car, depending on some condition
- 3 To call chooseMyRide(), we need to create a Car.
In our eager Car production example, to call chooseMyRide(), we need to supply a Car object, so we’re already paying the cost of building a Car. If the weather is nice and I decide to ride my bike, the Car instance was created for nothing.
Let’s switch to a lazy approach. Instead of providing a Car, let’s provide a function that returns a Car when called.
Listing 5.9. Lazy Car production
class Bike { }
class Car { }
function chooseMyRide(bike: Bike, car: () => Car): Bike | Car { 1
if (isItRaining()) {
return car(); 2
} else {
return bike;
}
}
function makeCar(): Car { 3
return new Car();
}
chooseMyRide(new Bike(), makeCar); 3
- 1 Instead of a Car argument, chooseMyRide() now takes a function that returns a Car.
- 2 We call this function only when we know for sure that we need a Car.
- 3 We wrap car-making in a function and pass that to chooseMyRide().
The lazy version will not create an expensive Car unless it’s really needed. If I decide to ride my bike instead, the function never gets called, and no Car gets created.
This is something we could achieve with pure object-oriented constructs, albeit with a lot more code. We could declare a CarFactory class that wraps a makeCar() method and use that as the argument to chooseMyRide(). We would then create a new instance of CarFactory when calling chooseMyRide(), which would invoke the method when needed. But why write more code when we can write less? In fact, we can make our code even shorter.
5.3.1. Lambdas
Most modern programming languages support anonymous functions, or lambdas. Lambdas are similar to normal functions but don’t have names. We would use lambdas whenever we have a one-off function: a function we usually refer to only once, so going through the trouble of naming it becomes extra work. Instead, we can provide an inline implementation.
In our lazy car example, a good candidate is makeCar(). Because chooseMyRide() needs a function with no arguments that returns a Car, we had to declare this new function that we refer to only once: when we pass it as an argument to chooseMyRide(). Instead of this function, we can use an anonymous function, as shown in the following listing.
Listing 5.10. Anonymous Car production
class Bike { }
class Car { }
function chooseMyRide(bike: Bike, car: () => Car): Bike | Car {
if (isItRaining()) {
return car();
} else {
return bike;
}
}
chooseMyRide(new Bike(), () => new Car()); 1
- 1 A lambda that doesn’t take any arguments and returns a Car
The TypeScript lambda syntax is very similar to the function type declaration: we have the list of arguments (none in this particular case) in parentheses, then =>, and then the body of the function. If the function had multiple lines, we would’ve put them between { and }, but because we have only a single call to new Car(), this is implicitly considered to be the return statement for the lambda, so we get rid of makeCar() and put the construction logic in a one-liner.
Lambda or anonymous function
A lambda, or anonymous function, is a function definition that doesn’t have a name. Lambdas are usually used for one-off, short-lived processing and are passed around like data.
Lambdas wouldn’t be very useful if we were unable to type functions. What would we do with an expression such as () => new Car()? If we couldn’t store it in a variable or pass it as an argument to another function, there really wouldn’t be much use for it. On the other hand, having the ability to pass functions around like values enables scenarios like the preceding one, in which producing a Car instance lazily is just a few characters longer than the eager version.
A common feature of many functional programming languages is lazy evaluation. In such languages, everything is evaluated as late as possible, and we don’t have to be explicit about it. In such languages, chooseMyRide() would by default construct neither a Bike nor a Car. Only when we actually try to use the object returned by chooseMyRide()—by calling ride() on it, for example—would the Bike or Car be created.
Imperative programming languages such as TypeScript, Java, C#, and C++ are eagerly evaluated. That being said, as we saw previously, we can simulate lazy evaluation fairly easily when necessary. We’ll see more examples of this when we discuss generators later.
5.3.2. Exercise
Which of the following implements a lambda that adds two numbers?
- function add(x: number, y: number)=> number { return x + y; }
- add(x: number, y: number) => number { return x + y; }
- add(x: number, y: number) { return x + y; }
- (x: number, y: number) => x + y;
5.4. Using map, filter, and reduce
Let’s look at another capability unlocked by typed functions: functions that take as arguments or return other functions. A “normal” function that accepts one or more nonfunction arguments and returns a nonfunction type is also known as a first-order function, or a regular, run-of-the-mill function. A function that takes a first-order function as an argument or returns a first-order function is called a second-order function.
We could climb up the ladder and say that a function that takes a second-order function as an argument or returns a second-order function is called a third-order function, but in practice, we simply refer to all functions that take or return other functions as higher-order functions.
An example of a higher-order function is the second iteration of chooseMyRide() from the preceding section. That function requires an argument of type () => Car, which would be a function itself.
In fact, it turns out that several very useful algorithms can be implemented as higher-order functions, the most fundamental ones being map(), filter(), and reduce(). Most programming languages ship with libraries that provide versions of these functions, but in DIY fashion, we’ll look at possible implementations and go over the details.
5.4.1. map()
The premise behind map() is very straightforward: given a collection of values of some type, call a function on each of those values, and return the collection of results. This type of processing shows up over and over in practice, so it makes sense to reduce code duplication.
Let’s take two scenarios as examples. First, we have an array of numbers, and we want to square each number in the array. Second, we have an array of strings, and we want to compute the length of each string in the array.
We could implement these examples with a couple of for loops, but looking at them side by side, as shown in the next listing, should give us a feeling that some of the commonality could be abstracted away into shared code.
Listing 5.11. Ad hoc mapping
let numbers: number[] = [1, 2, 3, 4, 5]; 1
let squares: number[] = [];
for (const n of numbers) {
squares.push(n * n); 2
}
let strings: string[] = ["apple", "orange", "peach"]; 3
let lengths: number[] = [];
for (const s of strings) {
lengths.push(s.length); 4
}
- 1 Array of numbers
- 2 For each number in the array, we square it and add it to the squares array.
- 3 Array of strings
- 4 For each string in the array, we add its length to the lengths array.
Although the arrays and transformations are different, the structure is obviously very similar (figure 5.5).
Figure 5.5. Squaring numbers and getting string lengths are very different scenarios, but the overall structure of the transformation is the same: take an input array, apply a function, and produce an output array.

DIY map
Let’s look at an implementation of map() for arrays and see how we can avoid writing this kind of loop over and over. We’ll use generic types T and U, as the implementation works regardless of what T and U are. This way, we can use this function with different types, as opposed to restricting it to, say, arrays of numbers.
Our function takes an array of Ts and a function that takes an item T as argument and returns a value of type U. It collects the result in an array of Us. The implementation in the next listing simply goes over each item in the array of Ts, applies the given function to it, and then stores the result in the array of Us.
Listing 5.12. map()
function map<T, U>(items: T[], func: (item: T) => U): U[] { 1
let result: U[] = []; 2
for (const item of items) {
result.push(func(item)); 3
}
return result; 4
}
- 1 map() takes an array of items of type T and a function from T to U, and returns an array of Us.
- 2 Start with an empty array of Us.
- 3 For each item, push the result of func(item) to the array of Us.
- 4 Return the array of Us.
This simple function encapsulates the common processing of the preceding example. With map(), we can produce the array of squares and the array of string lengths with a couple of one-liners, as the following listing shows.
Listing 5.13. Using map()
let numbers: number[] = [1, 2, 3, 4, 5]; let squares: number[] = map(numbers, (item) => item * item); 1 let strings: string[] = ["apple", "orange", "peach"]; let lengths: number[] = map(strings, (item) => item.length); 2
- 1 Call map() with the lambda (item) => item * item. (In this case, item is a number.)
- 2 Call map() with the lambda (item) => item.length. (In this case, item is a string.)
map() encapsulates the application of the function that we give it as argument. We just hand it an array of items and a function, and we get back the array resulting from the application of the function. Later, when we discuss generics, we’ll see how we can generalize this even further to make it work with any data structure, not only arrays. Even with the current implementation, though, we get a very good abstraction for applying functions to sets of items, which we can reuse in many situations.
5.4.2. filter()
The next very common scenario, the cousin of map(), is filter(). Given a collection of items and a condition, filter out the items that don’t meet the condition and return the collection of items that do.
Going back to our numbers and strings examples, let’s filter the list so that we keep only the even numbers and the strings of length 5. map() can’t help us here, as it processes all elements in the collection, but in this case, we want to discard some. The ad-hoc implementation would again consist of looping over the collections and checking whether the condition is met, as shown in the next listing.
Listing 5.14. Ad hoc filtering
let numbers: number[] = [1, 2, 3, 4, 5];
let evens: number[] = []
for (const n of numbers) {
if (n % 2 == 0) { 1
evens.push(n);
}
}
let strings: string[] = ["apple", "orange", "peach"];
let length5Strings: string[] = [];
for (const s of strings) {
if (s.length == 5) { 2
length5Strings.push(s);
}
}
- 1 Push item only if it is even
- 2 Push item only if it has length 5
Again, we immediately see a common underlying structure (figure 5.6).
Figure 5.6. Even numbers and strings with length 5 share a structure. We traverse the input, apply the filter, and output the items for which the filter returns true.

DIY filter
Just as we did with map(), we can implement a generic filter() higher-order function that takes as arguments an input array and a filter function, and returns the filtered output, as shown in the following code. In this case, if the input array is of type T, the filter function is a function that takes a T as argument and returns a boolean. A function that takes a single argument and returns a boolean is also called a predicate.
Listing 5.15. filter()
function filter<T>(items: T[], pred: (item: T) => boolean): T[] { 1
let result: T[] = [];
for (const item of items) {
if (pred(item)) { 2
result.push(item);
}
}
return result;
}
- 1 filter() takes an array of Ts and a predicate (a function from T to boolean).
- 2 If the predicate returns true, the item is added to the result array; otherwise, it’s skipped.
Let’s see what the filtering code looks like when we use the common structure that we implemented in our filter() function. Both the even numbers and strings of length 5 become one-liners in the next listing.
Listing 5.16. Using filter()
let numbers: number[] = [1, 2, 3, 4, 5]; let evens: number[] = filter(numbers, (item) => item % 2 == 0); let strings: string[] = ["apple", "orange", "peach"]; let length5Strings: string[] = filter(strings, (item) => item.length == 5);
The arrays are filtered by using a predicate—in the first case, a lambda that returns true if the number is divisible by 2, and in the second case, a lambda that returns true if the string has length 5.
With the second common operation implemented as a generic function, let’s move on to the third and last operation covered in this chapter.
5.4.3. reduce()
So far, we can apply a function to a collection of items by using map(), and we can remove items that don’t meet certain criteria from a collection by using filter(). The third common operation involves merging all the collection items into a single value.
We might want to calculate the product of all numbers in a number array, for example, and concatenate all the strings in a string array to form one big string. These scenarios are different but have a common underlying structure. First, let’s look at the ad hoc implementation.
Listing 5.17. Ad hoc reducing
let numbers: number[] = [1, 2, 3, 4, 5];
let product: number = 1; 1
for (const n of numbers) {
product = product * n; 2
}
let strings: string[] = ["apple", "orange", "peach"];
let longString: string = ""; 3
for (const s of strings) {
longString = longString + s; 4
}
- 1 In the product case, we start with an initial value of 1.
- 2 We proceed to multiply product by every number in our collection, accumulating the result.
- 3 In the string case, we start with an empty string.
- 4 We append each string to the empty string, accumulating the result.
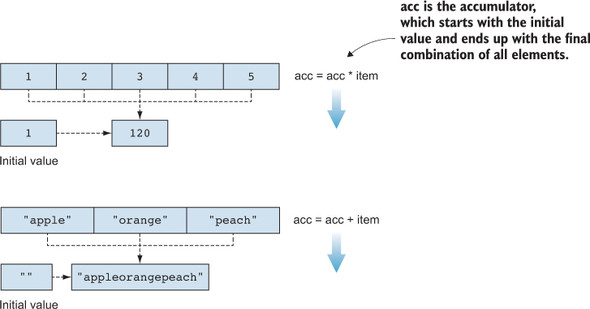
In both scenarios, we start with an initial value; then we accumulate the result by going over the collections and combining each item with the accumulator. When we’re done going over the collections, product contains the product of all the numbers in the numbers array, and longString is the concatenation of all strings in the strings array (figure 5.7).
Figure 5.7. Common structure of combining the numbers in a number array and strings in a string array. In the first case, the initial value is 1, and the combination we apply is multiplication with each item. In the second case, the initial value is "", and the combination we apply is concatenation with each item.
DIY reduce
In listing 5.18, we’ll implement a generic function that takes an array of Ts, an initial value of type T, and a function that takes two arguments of type T and returns a T. We’ll store the running total in a local variable and update it by applying the function to it and each element of the input array in turn.
Listing 5.18. reduce()
function reduce<T>(items: T[], init: T, op: (x: T, y: T) => T): T { 1
let result: T = init;
for (const item of items) {
result = op(result, item); 2
}
return result;
}
- 1 reduce() takes an array of Ts, an initial value, and an operation combining two Ts into one.
- 2 Each item in the array is combined with the running total by using the given operation.
This function has three arguments, and the others have two. The reason why we need an initial value instead of starting with, say, the first element of the array is that we need to handle the case when the input array is empty. What would result be if there was no item in the collection? Having an initial value covers that case, as we would simply return that.
Let’s see how we can update our ad-hoc implementations to use reduce().
Listing 5.19. Using reduce()
let numbers: number[] = [1, 2, 3, 4, 5]; let product: number = reduce(numbers, 1, (x, y) => x * y); 1 let strings: string[] = ["apple", "orange", "peach"]; let longString: string = reduce(strings, "", (x, y) => x + y); 2
- 1 For numbers, we start with an initial value of 1 and the operation (x, y) => x * y (multiplication).
- 2 For strings, we start with an initial value of "" and the operation (x, y) => x + y (concatenation).
reduce() has a few subtleties that the other two functions don’t. Besides requiring an initial value, the order in which the items are combined may affect the final result. For the operations and initial values in our example, that’s not the case. But what if our initial string was "banana"? Then, concatenating from left to right, we would get "bananaappleorangepeach". But if we traversed the array from right to left, always adding the item to the beginning of the string, we would get "appleorangepeachbanana".
Or if our combining operation appended the first letters of each string together, applying that to "apple" and "orange" first would give us "ao". Applying it again to "ao" and "peach" would give us "ap". On the other hand, if we started with "orange" and "peach", we would have "op". Then "apple" and "op" would give us "ao" (figure 5.8).
Figure 5.8. Combining an array of strings with the operation “first letter of both strings” gives us different results when applied from left to right and when applied from right to left. In the first case, we start with an empty string and "apple", then "a" and "orange" , then "ao" and "peach", giving us "ap". In the second case, we start with "peach" and an empty string, followed by "orange" and "p", giving us "op"; and then "apple" and "op", giving us "ao".

Conventionally, reduce() is applied left to right, so whenever you encounter it as a library function, it should be safe to assume that’s how it works. Some libraries also provide a right-to-left version. The JavaScript Array type, for example, has both reduce() and reduceRight() methods. See the sidebar “Monoids” if you want to learn more about the math behind this.
In abstract algebra, we deal with sets and operations on those sets. As we saw previously, we can think of a type as a set of possible values. An operation on type T that takes two Ts and returns another T, (T, T) => T, can be interpreted as an operation on the set of values T. The set of number and +, which is (x, y) => x + y, for example, forms an algebraic structure.
These structures are defined by the properties of their operations. An identity is an element id of T for which the operation op(x, id) == op(id, x) == x. In other words, combining id with any other element leaves the other element unchanged. Identity is 0 when the set is number and the operation is addition, 1 when the set is number and the operation is multiplication, and "" (the empty string) when the set is string and the operation is string concatenation.
Associativity is a property of the operation that says the order in which we apply it to a sequence of elements doesn’t matter, as we’ll get the same result in the end. For any x, y, z of T, op(x, op(y, z)) == op(op(x, y), z). This is true, for example, for number addition and multiplication but not true for subtraction or our “first letter of both strings” operation.
If a set T with an operation op has an identity element and the operation is associative, the resulting algebraic structure is called a monoid. For a monoid, starting with the identity as the initial value, reducing from left to right or right to left yields the same result. We can even remove the requirement for an initial value and default to the identity if the collection is empty. We can also parallelize reduction. We could reduce the first half and the second half of the collection in parallel and combine the results, for example, because the associativity property guarantees that we’ll get the same result. For [1, 2, 3, 4, 5, 6], we can combine 1 + 2 + 3 and, in parallel, 4 + 5 + 6, and then add the results together.
As soon as we drop one of the properties, we lose these guarantees. If we don’t have associativity, but just a set, an operation, and an identity element, although we still don’t require an initial value (we use the identity element), the direction in which we apply the operations becomes important. If we drop the identity element but keep associativity, we have a semigroup. Without an identity, it matters whether we put the initial value on the left of the first element or the right of the last element.
The key takeaway is that reduce() works seamlessly on a monoid, but if we don’t have a monoid, we should be careful what we use for our initial value and the direction we’re reducing on.
5.4.4. Library support
As mentioned at the start of this section, most programming languages have library support for these common algorithms. They may show up under different names, though, as there is no golden standard for naming them.
In C#, map(), filter(), and reduce() show up in the System.Linq namespace as Select(), Where(), and Aggregate() respectively. In Java, they show up as map(), filter(), and reduce() in java.util.stream.
map() is also known as Select() or transform(). filter() is also known as Where(). reduce() is also known as accumulate(), Aggregate(), or fold(), depending on the language and library.
Even though they have many names, these algorithms are fundamental and useful across a broad range of applications. We’ll discuss many similar algorithms later in the book, but these three form the foundation of data processing using higher-order functions.
Google’s famous MapReduce large-scale data processing framework uses the same underlying principles of the map() and reduce() algorithms by running a massively parallel map() operation on multiple nodes and combining the results via a reduce()-like operation.
5.4.5. Exercises
Implement a first() function that takes an array of Ts and a function pred (for predicate) that takes a T as an argument and returns a boolean. first() will return the first element of the array for which pred() returns true or undefined if pred() returns false for all elements.
Implement an all() function that takes an array of Ts and a function pred (for predicate) that takes a T as an argument and returns a boolean. all() will return true if pred() is true for all the elements of the array; otherwise, it will return false.
5.5. Functional programming
Although the material covered in this chapter was a bit more complex, the good news is that we went over most of the key ingredients of functional programming. The syntax of some functional languages may be off-putting if you’re used to imperative, object-oriented languages. Their type systems usually offer some combinations of sum types, product types, and first-order function support, as well as a set of library functions such as map(), filter(), and reduce() to process data. Many functional languages employ lazy evaluation, which we also discussed in this chapter.
With the ability to type functions, many of the concepts originating from functional programming languages can be implemented in languages that aren’t functional (or purely functional). We saw this throughout this chapter; we touched on all these topics and provided imperative implementations for all these key components.
Summary
- If we can type functions, we can implement the strategy pattern in a much simpler way by focusing on the functions that implement the logic and discarding the surrounding scaffolding.
- The ability to plug a function into a class as a property and call it as a method allows us to implement state machines that don’t rely on big switch statements. This way, the compiler can prevent mistakes like accidentally applying the wrong processing in some given state.
- Another alternative to switch statements for a state machine implementation is a sum type in which each state is captured by a different type.
- We can defer expensive computation by relying on lazy values, which are functions we pass around that wrap the expensive computation. We call them when needed to produce a value, but if we never need them, we can skip the expensive computation.
- Lambdas are nameless functions we can use for one-off logic in which naming a function wouldn’t be very useful.
- A higher order function is a function that takes another function as an argument or returns a function.
- map(), filter(), and reduce() are three fundamental higher-order functions, with many applications in data processing.
In chapter 6, we’ll look at a few more applications of typed functions. We’ll learn about closures and how we can use them to simplify another common design pattern: the decorator pattern. We’ll also talk about promises, as well as tasking and event-driven systems. All these applications are made possible by the ability to represent computation (functions) as first-class citizens of the type system.
Answers to exercises
A simple strategy pattern
b—That is the only function type; the other declarations do not represent functions.
c—The function takes a number and an (x: number) => boolean and returns boolean.
A state machine without switch statements
We can model the connection as a state machine with two states—open and closed—and two transitions—connect transitions from closed to open and disconnect transitions from open to closed.
A possible implementation:
declare function read(): string; class Connection { private doProcess: () => void = this.processClosedConnection; public process(): void { this.doProcess(); } private processClosedConnection() { this.doProcess = this.processOpenConnection; } private processOpenConnection() { const value: string = read(); if (value.length == 0) { this.doProcess = this.processClosedConnection; } else { console.log(value); } } }
Avoiding expensive computation with lazy values
d—The other implement named functions; this is the only anonymous implementation.
Using map, filter, and reduce
A possible implementation for first():
function first<T>(items: T[], pred: (item: T) => boolean): T | undefined { for (const item of items) { if (pred(item)) { return item; } } return undefined; }
A possible implementation for all():
function all<T>(items: T[], pred: (item: T) => boolean): boolean { for (const item of items) { if (!pred(item)) { return false; } } return true; }