
Chapter 10. Generic algorithms and iterators
This chapter covers
- Using map(), filter(), and reduce()beyond arrays
- Using a set of common algorithms to solve a wide range of problems
- Ensuring that a generic type supports a required contract
- Enabling various algorithms with different iterator categories
- Implementing adaptive algorithms
This chapter is all about generic algorithms—reusable algorithms that work on various data types and data structures.
We looked at one version each of map(), filter(), and reduce() in chapter 5, when we discussed higher-order functions. Those functions operated on arrays, but as we saw in the previous chapters, iterators provide a nice abstraction over any data structure. We’ll start by implementing generic versions of these three algorithms that work with iterators, so we can apply them to binary trees, lists, arrays, and any other iterable data structures.
map(), filter(), and reduce() are not unique. We’ll talk about other generic algorithms and algorithm libraries that are available to most modern programming languages. We’ll see why we should replace most loops with calls to library algorithms. We’ll also briefly talk about fluent APIs and what a user-friendly interface for algorithms looks like.
Next, we’ll go over type parameter constraints; generic data structures and algorithms can specify certain features they need available on their parameter types. This type of specialization allows for generic data structures and algorithms that don’t work everywhere; they are somewhat less general.
We’ll zoom in on iterators and talk about all the different categories of iterators. More specialized iterators enable more efficient algorithms. The trade-off is that not all data structures can support specialized iterators.
Finally, we’ll take a quick look at adaptive algorithms. Such algorithms provide more general, less efficient implementations for iterators with fewer capabilities and more efficient, less general implementations for iterators with more capabilities.
10.1. Better map(), filter(), reduce()
In chapter 5, we talked about map(), filter(), and reduce(), and looked at a possible implementation of each of them. These algorithms are higher-order functions, as they each take another function as an argument and apply it over a sequence.
map() applies the function to each element of the sequence and returns the results. filter() applies a filtering function to each element and returns only the elements for which that function returns true. reduce() combines all the values in the sequence, using the given function, and returns a single value as the result.
Our implementation in chapter 5 used a generic type parameter T, and the sequences were represented as arrays of T.
10.1.1. map()
Let’s take a look at how we implemented map(). We used two type parameters: T and U. The function takes an array of T values as the first argument and a function from T to U as the second argument. It returns an array of U values, as shown in the next listing.
Listing 10.1. map()
function map<T, U>(items: T[], func: (item: T) => U): U[] { 1
let result: U[] = []; 2
for (const item of items) {
result.push(func(item)); 3
}
return result; 4
}
- 1 map() takes an array of items of type T and a function from T to U, and returns an array of Us.
- 2 Start with an empty array of Us.
- 3 For each item, push the result of func(item) to the array of Us.
- 4 Return the array of Us.
Now that we know about iterators and generators, let’s see in the next listing how we can implement map() to work on any Iterable<T>, not only arrays.
Listing 10.2. map() with iterator
function* map<T, U>(iter: Iterable<T>, func: (item: T) => U): 1
IterableIterator<U> { 2
for (const value of iter) {
yield func(value); 3
}
}
- 1 map() is now a generator that takes an Iterable<T> as the first argument.
- 2 map() returns an IterableIterator<U>.
- 3 The given function is applied to each value retrieved from the iterator, and the result is yielded.
Whereas the original implementation was restricted to arrays, this one works with any data structure that provides an iterator. Not only that, but it is also more concise.
10.1.2. filter()
Let’s do the same for filter(). Our original implementation expected an array of type T and a predicate. As a reminder, a predicate is a function that takes one argument of some type and returns a boolean. We say that a value satisfies the predicate if the function returns true for that value.
Listing 10.3. filter()
function filter<T>(items: T[], pred: (item: T) => boolean): T[] { 1
let result: T[] = [];
for (const item of items) {
if (pred(item)) { 2
result.push(item);
}
}
return result;
}
- 1 filter() takes an array of Ts and a predicate (a function from T to boolean).
- 2 If the predicate returns true, the item is added to the result array; otherwise, it’s skipped.
Just as we did with map(), we are going to use an Iterable<T> instead of an array and implement this iterable as a generator that yields values that satisfy the predicate, as shown in the following listing.
Listing 10.4. filter() with iterator
function* filter<T>(iter: Iterable<T>, pred: (item: T) => boolean): 1
IterableIterator<T> { 2
for (const value of iter) {
if (pred(value)) {
yield value; 3
}
}
}
- 1 filter() is now a generator that takes an Iterable<T> as the first argument.
- 2 filter() returns an IterableIterator<T>.
- 3 If a value satisfies the predicate, it is yielded.
We again end up with a shorter implementation that works with more than arrays. Finally, let’s update reduce().
10.1.3. reduce()
Our original implementation of reduce() expected an array of T, an initial value of type T (in case the array is empty), and an operation op(). The operation is a function that takes two values of type T and returns a value of type T. reduce() applies the operation to the initial value and the first element of the array, stores the result, applies the operation to the result and the next element of the array, and so on.
Listing 10.5. reduce()
function reduce<T>(items: T[], init: T, op: (x: T, y: T) => T): T { 1
let result: T = init;
for (const item of items) {
result = op(result, item); 2
}
return result;
}
- 1 reduce() takes an array of Ts, an initial value, and an operation combining two Ts into one.
- 2 Each item in the array is combined with the running total, using the given operation.
We can rewrite this to use an Iterable<T> instead so that it works with any sequence, as shown in the following code. In this case, we don’t need a generator. Unlike the previous two functions, reduce() does not return a sequence of elements, but a single value.
Listing 10.6. reduce() with iterator
function reduce<T>(iter: Iterable<T>, init: T, 1
op: (x: T, y: T) => T): T {
let result: T = init;
for (const value of iter) {
result = op(result, value);
}
return result;
}
The rest of the implementation is unchanged.
10.1.4. filter()/reduce() pipeline
Let’s see how we can combine these algorithms into a pipeline that takes only the even numbers from a binary tree and sums them up. We’ll use our BinaryTreeNode<T> from chapter 9, with its in-order traversal, and chain this with an even number filter and a reduce() using addition as the operation.
Listing 10.7. filter()/reduce() pipeline
let root: BinaryTreeNode<number> = new BinaryTreeNode(1); 1
root.left = new BinaryTreeNode(2);
root.left.right = new BinaryTreeNode(3);
root.right = new BinaryTreeNode(4);
const result: number =
reduce(
filter(
inOrderIterator(root), 2
(value) => value % 2 == 0), 3
0, (x, y) => x + y); 4
console.log(result);
- 1 The same example binary tree we used in the previous chapter
- 2 We get an IterableIterator<number> that traverses the tree in order.
- 3 We filter using a lambda that returns true only if a number is even.
- 4 We reduce from an initial value of 0 with a lambda that sums two numbers.
This example should reinforce how powerful generics are. Instead of having to implement a new function to traverse the binary tree and sum up even numbers, we simply put together a processing pipeline customized for this scenario.
10.1.5. Exercises
Build a pipeline that processes an iterable of type string by concatenating all nonempty strings.
Build a pipeline that processes an iterable of type number by selecting all odd numbers and squaring them.
10.2. Common algorithms
We looked at map(), filter(), and reduce(), and also mentioned take() in chapter 9. Many other algorithms are commonly used in pipelines. Let’s list a few of them. We will not look at the implementations—just describe what arguments besides the iterable they expect and how they process the data. We’ll also mention some synonyms under which the algorithm might appear:
- map() takes a sequence of T values and a function (value: T) => U, and returns a sequence of U values, applying the function to all the elements in the sequence. It is also known as fmap(), select().
- filter() takes a sequence of T values and a predicate (value: T) => boolean, and returns a sequence of T values containing all the items for which the predicate returns true. It is also known as where().
- reduce()takes a sequence of T values, an initial value of type T, and an operation that combines two T values into one (x: T, y: T) => T. It returns a single value T after combining all the elements in the sequence using the operation. It is also known as fold(), collect(), accumulate(), aggregate().
- any()takes a sequence of T values and a predicate (value: T) => boolean. It returns true if any one of the elements of the sequence satisfies the predicate.
- all()takes a sequence of T values and a predicate (value: T) => boolean. It returns true if all the elements of the sequence satisfy the predicate.
- none()takes a sequence of T values and a predicate (value: T) => boolean. It returns true if none of the elements of the sequence satisfies the predicate.
- take() takes a sequence of T values and a number n. It returns a sequence consisting of the first n elements of the original sequence. It is also known as limit().
- drop() takes a sequence of T values and a number n. It returns a sequence consisting of all the elements of the original sequence except the first n. The first n elements are dropped. It is also known as skip().
- zip() takes a sequence of T values and a sequence of U values. It returns a sequence containing pairs of T and U values, effectively zipping together the two sequences.
There are many more algorithms for sorting, reversing, splitting, and concatenating sequences. The good news is that because these algorithms are so useful and generally applicable, we don’t need to implement them. Most languages have libraries that provide these algorithms and more. JavaScript has the underscore.js package and the lodash package, both of which provide a plethora of such algorithms. (At the time of writing, these libraries don’t support iterators—only the JavaScript built-in array and object types.) In Java, they are in the java.util.stream package. In C#, they are in the System.Linq namespace. In C++, they are in the <algorithm> standard library header.
10.2.1. Algorithms instead of loops
You may be surprised that a good rule of thumb is to check, whenever you find yourself writing a loop, whether a library algorithm or a pipeline can do the job. Usually, we write loops to process a sequence, which is exactly what the algorithms we talked about do.
The reason to prefer library algorithms to custom code in loops is that there is less opportunity for mistakes. Library algorithms are tried and tested and implemented efficiently, and the code we end up with is easier to understand, as the operations are spelled out.
We’ve looked at a few implementations throughout this book to get a better understanding of how things work under the hood, but you’ll rarely need to implement an algorithm yourself. If you do end up with a problem that the available algorithms can’t solve, consider making a generic, reusable implementation of your solution rather than a one-off specific implementation.
10.2.2. Implementing a fluent pipeline
Most libraries also provide a fluent API to chain algorithms into a pipeline. Fluent APIs are APIs based on method chaining, making the code much easier to read. To see the difference between a fluent and a nonfluent API, let’s take another look at the filter/reduce pipeline from section 10.1.4.
Listing 10.8. filter/reduce pipeline
let root: BinaryTreeNode<number> = new BinaryTreeNode(1);
root.left = new BinaryTreeNode(2);
root.left.right = new BinaryTreeNode(3);
root.right = new BinaryTreeNode(4);
const result: number =
reduce(
filter(
inOrderBinaryTreeIterator(root),
(value) => value % 2 == 0),
0, (x, y) => x + y);
console.log(result);
Even though we apply filter() first and then pass the result to reduce(), if we read the code from left to right, we see reduce() before filter(). It’s also a bit hard to make sense of which arguments go with which function in the pipeline. Fluent APIs make the code much easier to read.
Currently, all our algorithms take an iterable as the first argument and return an iterator. We can use object-oriented programming to improve our API. We can put all our algorithms in a class that wraps an iterable. Then we can call any of the iterables without explicitly providing an iterable as the first argument; the iterable is a member of the class. Let’s do this for map(), filter(), and reduce() by grouping them into a new FluentIterable<T> class wrapping an iterable, as shown in the next listing.
Listing 10.9. Fluent iterable
class FluentIterable<T> { 1
iter: Iterable<T>; 1
constructor(iter: Iterable<T>) {
this.iter = iter;
}
*map<U>(func: (item: T) => U): IterableIterator<U> { 2
for (const value of this.iter) {
yield func(value);
}
}
*filter(pred: (item: T) => boolean): IterableIterator<T> { 2
for (const value of this.iter) {
if (pred(value)) {
yield value;
}
}
}
reduce(init: T, op: (x: T, y: T) => T): T { 2
let result: T = init;
for (const value of this.iter) {
result = op(result, value);
}
return result;
}
}
- 1 FluentIterable<T> wraps an Iterable<T>.
- 2 map(), filter(), and reduce() are similar to the previous implementations, but instead of taking an iterable as the first argument, they use the this.iter iterable.
We can create a FluentIterable<T> out of an Iterable<T>, so we can rewrite our filter()/reduce() pipeline into a more fluent form. We create a Fluent-Iterable<T>, call filter() on it, create a new FluentIterable<T> from its result, and call reduce() on it, as the following listing shows.
Listing 10.10. Fluent filter/reduce pipeline
let root: BinaryTreeNode<number> = new BinaryTreeNode(1);
root.left = new BinaryTreeNode(2);
root.left.right = new BinaryTreeNode(3);
root.right = new BinaryTreeNode(4);
const result: number =
new FluentIterable(
new FluentIterable(
inOrderIterator(root) 1
).filter((value) => value % 2 == 0) 2
).reduce(0, (x, y) => x + y); 3
console.log(result);
- 1 We get an iterable over the binary tree from inOrderIterator and use it to initialize a FluentIterable.
- 2 We call filter() on the FluentIterable and then create another FluentIterable from the result.
- 3 Finally, we call reduce() on the FluentIterable to get the final result.
Now filter() appears before reduce(), and it’s very clear that arguments go to that function. The only problem is that we need to create a new Fluent-Iterable<T> after each function call. We can improve our API by having our map() and filter() functions return a FluentIterable<T> instead of the default IterableIterator<T>. Note that we don’t need to change reduce(), because reduce() returns a single value of type T, not an iterable.
Because we’re using generators, we can’t simply change the return type. Generators exist to provide convenient syntax for functions, but they always return an IterableIterator<T>. Instead, we can move the implementations to a couple of private methods—mapImpl() and filterImpl()—and handle the conversion from IterableIterator<T> to FluentIterable<T> in the public map() and reduce() methods, as shown in the following listing.
Listing 10.11. Better fluent iterable
class FluentIterable<T> {
iter: Iterable<T>;
constructor(iter: Iterable<T>) {
this.iter = iter;
}
map<U>(func: (item: T) => U): FluentIterable<U> {
return new FluentIterable(this.mapImpl(func)); 1
}
private *mapImpl<U>(func: (item: T) => U): IterableIterator<U> {
for (const value of this.iter) { 2
yield func(value);
}
}
filter<U>(pred: (item: T) => boolean): FluentIterable<T> {
return new FluentIterable(this.filterImpl(pred)); 3
}
private *filterImpl(pred: (item: T) => boolean): IterableIterator<T> {
for (const value of this.iter) { 4
if (pred(value)) {
yield value;
}
}
}
reduce(init: T, op: (x: T, y: T) => T): T { 5
let result: T = init;
for (const value of this.iter) {
result = op(result, value);
}
return result;
}
}
- 1 map() forwards its argument to mapImpl() and converts the result to a FluentIterable.
- 2 mapImpl() is the original map() implementation with a generator.
- 3 Like map(), filter() forwards its argument to filterImpl() and converts the result to a FluentIterable.
- 4 filterImpl() is the original filter() implementation with a generator.
- 5 reduce() stays unchanged because it doesn’t return an iterator.
With this updated implementation, we can more easily chain the algorithms, as each returns a FluentIterable that contains all the algorithms as methods, as shown in the next listing.
Listing 10.12. Better fluent filter/reduce pipeline
let root: BinaryTreeNode<number> = new BinaryTreeNode(1);
root.left = new BinaryTreeNode(2);
root.left.right = new BinaryTreeNode(3);
root.right = new BinaryTreeNode(4);
const result: number =
new FluentIterable(inOrderIterator(root)) 1
.filter((value) => value % 2 == 0) 2
.reduce(0, (x, y) => x + y); 3
console.log(result);
- 1 We need to explicitly new up a FluentIterable only once, from the original iterator over the tree.
- 2 filter() is a method of FluentIterable and returns a FluentIterable itself.
- 3 We can call reduce() on the result of filter().
Now, in true fluent fashion, the code reads easily from left to right, and we can chain any number of algorithms that make up our pipeline with a very natural syntax. Most algorithm libraries take a similar approach, making it as easy as possible to chain multiple algorithms.
Depending on the programming language, one downside of a fluent API approach is that our FluentIterable ends up containing all the algorithms, so it is difficult to extend. If it is part of a library, calling code can’t easily add a new algorithm without modifying the class. C# provides extension methods, which enable us to add methods to a class or interface without modifying its code. Not all languages have such features, though. That being said, in most situations, we should be using an existing algorithm library, not implementing a new one from scratch.
10.2.3. Exercises
Extend FluentIterable with take(), the algorithm that returns the first n elements from an iterator.
Extend FluentIterable with drop(), the algorithm that skips the first n elements of an iterator and returns the rest.
10.3. Constraining type parameters
We saw how a generic data structure gives shape to the data, regardless of what its specific type parameter T is. We also looked at a set of algorithms that uses iterators to process sequences of values of some type T, regardless of what that type is. Now let’s look at a scenario in the following listing in which the type matters: we have a renderAll() generic function that takes an Iterable<T> as argument and calls the render() method on each element of the iterator.
Listing 10.13. renderAll sketch
function renderAll<T>(iter: Iterable<T>): void { 1
for (const item of iter) {
item.render(); 2
}
}.
- 1 renderAll() takes an Iterable<T> as argument.
- 2 We call render() on each item returned by the iterator.
The function fails to compile, with the following error message:
Property 'render' does not exist on type 'T'.
We are attempting to call render() on a generic type T, but we have no guarantee that such a method exists on the type. For this type of scenario, we need a way to constrain the type T so that it can be instantiated only with types that have a render() method.
Constraints on type parameters
Constraints inform the compiler about the capabilities that a type argument must have. Without any constraints, the type argument could be any type. As soon as we require certain members to be available on a generic type, we use constraints to restrict the set of allowed types to those that have the required members.
In our case, we can define an IRenderable interface that declares a render() method, as shown in the next listing. Then we can add a constraint on T by using the extends keyword to tell the compiler that we accept only type arguments that are IRenderable.
Listing 10.14. renderAll with constraint
interface IRenderable { 1
render(): void;
}
function renderAll<T extends IRenderable>(iter: Iterable<T>): void { 2
for (const item of iter) {
item.render();
}
}
- 1 IRenderable interface requires implementers to provide a render() method.
- 2 T extends IRenderable and tells the compiler to accept only types that implement IRenderable as T.
10.3.1. Generic data structures with type constraints
Most generic data structures don’t need to constrain their type parameters. We can store values of any type in a linked list, a tree, or an array. There are a few exceptions, though, such as a hash set.
A set data structure models a mathematical set, so it stores unique values, discarding duplicates. Set data structures usually provide methods to union, intersect, and subtract other sets. They also provide a way to check whether a given value is already part of the set. To check whether a value is already part of a set, we can compare it with every element of the set, but that approach is not the most efficient. Comparing with every element in the set requires us, in the worst case, to traverse the whole set. Such a traversal requires linear time, or O(n). See the sidebar “Big O notation” on the next page for a refresher.
A more efficient implementation can hash each value and store it in a key-value data structure like a hash map or dictionary. Such data structures can retrieve a value in constant time, or O(1), making them more efficient. A hash set wraps a hash map and can provide efficient membership checks. But it does come with a constraint: the type T needs to provide a hash function, which takes a value of type T and returns a number: its hash value.
Some languages ensure that all values can be hashed by providing a hash method on their top type. The Java top type, Object, has a hashCode() method, whereas the C# Object top type has a GetHashCode() method. But if a language doesn’t have that, we need a type constraint to ensure that only hash-able types can be stored in the data structures. We could define an IHashable interface, for example, and make it a type constraint on the key type of our generic hash map or dictionary.
Big O notation provides an upper bound to the time and space required by a function to execute as its arguments tend toward a particular value n. We won’t go too deep into this topic; instead we’ll outline a few common upper bounds and explain what they mean.
Constant time, or O(1), means that a function’s execution time does not depend on the number of items it has to process. The function first(), which takes the first element of a sequence, runs just as fast for a sequence of 2 or 2 million items, for example.
Logarithmic time, or O(log n), means that the function halves its input with each step, so it is very efficient even for large values of n. An example is binary search in a sorted sequence.
Linear time, or O(n), means that the function run time grows proportionally with its input. Looping over a sequence is O(n), such as determining whether all elements of a sequence satisfy some predicate.
Quadratic time, or O(n2), is much less efficient than linear, as the run time grows much faster than the size of the input. Two nested loops over a sequence have a run time of O(n2).
Linearithmic, or O(n log n), is not as efficient as linear but more efficient than quadratic. The most efficient comparison sort algorithms are O(n log n); we can’t sort a sequence with a single loop, but we can do it faster than two nested loops.
Just as time complexity sets an upper bound on how the run time of a function increases with the size of its input, space complexity sets an upper bound on the amount of additional memory a function needs as the size of its input grows.
Constant space, or O(1), means that a function doesn’t need more space as the size of the input grows. Our max() function, for example, requires some extra memory to store the running maximum and the iterator, but the amount of memory is constant regardless of how large the sequence is.
Linear space, or O(n), means that the amount of memory a function needs is proportional to the size of its input. An example of such a function is our original in-Order() binary tree traversal, which copied the values of all nodes into an array to provide an iterator over the tree.
10.3.2. Generic algorithms with type constraints
Algorithms tend to have more constraints on their types than data structures. If we want to sort a set of values, we need a way to compare those values. Similarly, if we want to determine the minimum or maximum element of a sequence, the elements of that sequence need to be comparable.
Let’s look at a possible implementation of a max() generic algorithm in the next listing. First, we will declare an IComparable<T> interface and constrain our algorithm to use it. The interface declares a single compareTo() method.
Listing 10.15. IComparable interface
enum ComparisonResult { 1
LessThan,
Equal,
GreaterThan
}
interface IComparable<T> {
compareTo(value: T): ComparisonResult; 2
}
- 1 ComparisonResult represents the result of a comparison.
- 2 IComparable declares a compareTo interface that compares the current instance with another value of the same type and returns a Comparison result.
Now let’s implement a max() generic algorithm that expects an iterator over an IComparable set of values and returns the maximum element, as shown in listing 10.16. We will need to handle the case in which the iterator has no values, in which case max() will return undefined. For that reason, we won’t use a for...of loop; rather, we will advance the iterator manually by using next().
Listing 10.16. max() algorithm
function max<T extends IComparable<T>>(iter: Iterable<T>)
: T | undefined { 1
let iterator: Iterator<T> = iter[Symbol.iterator](); 2
let current: IteratorResult<T> = iterator.next(); 3
if (current.done) return undefined; 4
let result: T = current.value; 5
while (true) {
current = iterator.next();
if (current.done) return result; 6
if (current.value.compareTo(result) ==
ComparisonResult.GreaterThan) {
result = current.value; 7
}
}
}
- 1 max() puts an IComparable<T> constraint on the type T.
- 2 We get an Iterator<T> from the Iterable<T> argument.
- 3 We call next() once to get to the first value.
- 4 In case there is no first value, we return undefined.
- 5 We initialize result to be the first value returned by the iterator.
- 6 When the iterator is done, we return the result.
- 7 Whenever the current value is greater than the currently stored maximum, we update the result with the current value.
Many algorithms, such as max(), require certain things from the types they operate on. An alternative is to make the comparison an argument to the function itself as opposed to a generic type constraint. Instead of IComparable<T>, max() can expect a second argument—a compare() function—from two arguments of type T to a ComparisonResult, as shown in the following code.
Listing 10.17. max() algorithm with compare() argument
function max<T>(iter: Iterable<T>,
compare: (x: T, y: T) => ComparisonResult) 1
: T | undefined {
let iterator: Iterator<T> = iter[Symbol.iterator]();
let current: IteratorResult<T> = iterator.next();
if (current.done) return undefined;
let result: T = current.value;
while (true) {
current = iterator.next();
if (current.done) return result;
if (compare(current.value, result)
== ComparisonResult.GreaterThan) { 2
result = current.value;
}
}
}
- 1 compare() is a function that takes two Ts and returns a ComparisonResult.
- 2 Instead of the IComparable.compareTo() method, we call the compare() argument.
The advantage of this implementation is that the type T is no longer constrained, and we can plug in any comparison function. The disadvantage is that for types that have a natural order (numbers, temperatures, distances, and so on), we have to keep supplying a compare function explicitly. Good algorithm libraries usually provide both versions of an algorithm: one that uses a type’s natural comparison and another for which callers can supply their own.
The more an algorithm knows about the methods and properties that a type T it operates on provides, the more it can leverage those in its implementation. Next, let’s see how algorithms can use iterators to provide more efficient implementations.
10.3.3. Exercise
Implement a generic function clamp() that takes a value, a low, and a high. If the value is within the low-high range, it returns the values. If the value is less than low, it returns low. If the value is larger than high, it returns high. Use the IComparable interface defined in this section.
10.4. Efficient reverse and other algorithms using iterators
So far, we’ve looked at algorithms that process a sequence in a linear fashion. map(), filter(), reduce(), and max() all iterate over a sequence of values from start to finish. They all run in linear time (proportionate to the size of the sequence) and constant space. (Memory requirements are constant regardless of the size of the sequence.) Let’s look at another algorithm: reverse().
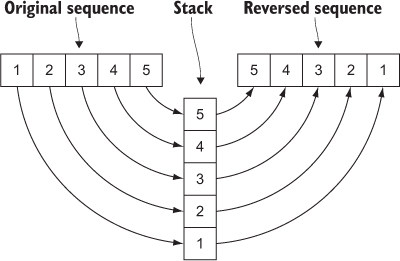
This algorithm takes a sequence and reverses it, making the last element the first one, the second-to-last element the second one, and so on. One way to implement reverse() is to push all elements of its input into a stack and then pop them out, as shown in figure 10.1 and listing 10.18.
Figure 10.1. Reversing a sequence with a stack: elements from the original sequence get pushed on the stack and then popped to produce the reversed sequence.
Listing 10.18. reverse() with stack
function *reverse<T>(iter: Iterable<T>): IterableIterator<T> { 1
let stack: T[] = []; 2
for (const value of iter) {
stack.push(value); 3
}
while (true) {
let value: T | undefined = stack.pop(); 4
if (value == undefined) return; 5
yield value; 6
}
}
- 1 reverse() is a generator, following the same pattern as our other algorithms.
- 2 JavaScript arrays provide push() and pop() methods, so we use one as a stack.
- 3 We push all values from the sequence on the stack.
- 4 We pop a value from the stack; this is undefined if the stack is empty.
- 5 If we emptied the stack, return, as we are done.
- 6 Yield the value and repeat.
This implementation is straightforward but not the most efficient. Although it runs in linear time, it also requires linear space. The larger the input sequence, the more memory this algorithm will need to push all its elements onto the stack.
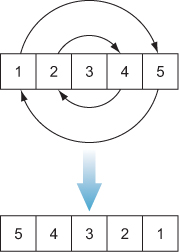
Let’s set iterators aside for now and look at how we would implement an efficient reverse over an array, as shown in listing 10.19. We can do this in-place, swapping the elements of the array starting from both ends without requiring an additional stack (figure 10.2).
Figure 10.2. Reversing an array in place by swapping its elements
Listing 10.19. reverse() for array
function reverse<T>(values: T[]): void { 1
let begin: number = 0; 2
let end: number = values.length; 2
while (begin < end) { 3
const temp: T = values[begin]; 4
values[begin] = values[end - 1]; 4
values[end - 1] = temp; 4
begin++; 5
end--; 5
}
}
- 1 This version of reverse() expects an array of Ts, not an Iterable.
- 2 begin and end originally point to the beginning and end of the array.
- 3 Repeat until the two meet or pass each other.
- 4 Swap the value at begin with the value at end - 1. (Originally, end was one element after the last one in the array.)
- 5 Increment the begin index and decrement the end index.
As we can see, this implementation is more efficient than the preceding one. It is still linear time, as we need to touch every element of the sequence (it is impossible to reverse a sequence without touching each element), but it requires constant space to run. Unlike the previous version, which needed a stack as large as its input, this one uses the temporary temp of type T, regardless of how large the input is.
Can we generalize this example and provide an efficient reverse algorithm for any data structure? We can, but we need to tweak our notion of iterators. Iterator<T>, Iterable<T>, and the combination of the two, IterableIterator<T>, are interfaces that TypeScript provides over the JavaScript ES6 standard. Now we’ll go beyond that and look at some iterators that are not part of the language standard.
10.4.1. Iterator building blocks
JavaScript iterators allow us to retrieve values and advance until the sequence is exhausted. If we want to run an in-place algorithm, we need a few more capabilities. We also need to be able not only to read values at a given position, but also set them. In our reverse() case, we start from both ends of the sequence and end in the middle, which means that an iterator can’t tell when it is done all by itself. We know that reverse() is done when begin and end pass each other, so we need a way to tell when two iterators are the same.
To support efficient algorithms, let’s redefine our iterators as a set of interfaces, each describing additional capabilities. First, let’s define an IReadable<T> that exposes a get() method returning a value of type T. We will use this method to read a value from an iterator. We’ll also define an IIncrementable<T> that exposes an increment() method we can use to advance our iterator, as the following listing shows.
Listing 10.20. IReadable<T> and IIncrementable<T>
interface IReadable<T> {
get(): T; 1
}
interface IIncrementable<T> {
increment(): void; 2
}
- 1 IReadable declares a single method, get(), that retrieves the current value T of an iterator.
- 2 IIncrementable declares a single method, increment(), that advances an iterator to the next element.
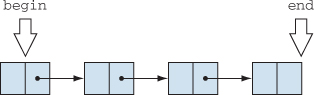
These two interfaces are almost enough to support our original linear traversal algorithms such as map(). The last thing missing is figuring out when we should stop. We know that an iterator can’t tell by itself when it is done, as sometimes it doesn’t need to traverse the whole sequence. We’ll introduce the concept of equality: an iterator begin and an iterator end are equal when they point to the same element. This is much more flexible than the standard Iterator- <T> implementation. We can initialize end to be one element after the last element of a sequence. Then we can advance begin until it is equal to end, in which case we’ll know that we’ve traversed the whole sequence. But we can also move end back until it points to the first element of the sequence—something we couldn’t have done with the standard Iterator<T>. (figure 10.3).
Figure 10.3. begin and end iterators define a range: begin points to the first element, and end points past the last element.
Let’s define an IInputIterator<T> interface in the next listing as an interface that implements both IReadable<T> and IIncrementable<T>, plus an equals() method we can use to compare two iterators.
Listing 10.21. IInputIterator<T>
interface IInputIterator<T> extends IReadable<T>, IIncrementable<T> {
equals(other: IInputIterator<T>): boolean;
}
The iterator itself can no longer determine when it has traversed the whole sequence. A sequence is now defined by two iterators—an iterator pointing to the start of the sequence and an iterator pointing to one past the last element of the sequence.
With these interfaces available, let’s update our linked list iterator from chapter 9 in the next listing. Our linked list is implemented as the type LinkedListNode<T> with a value property and a next property that can be a LinkedListNode<T> or undefined for the last node in the list.
Listing 10.22. Linked list implementation
class LinkedListNode<T> {
value: T;
next: LinkedListNode<T> | undefined;
constructor(value: T) {
this.value = value;
}
}
Let’s see how we can model a pair of iterators over this linked list in the following listing. First, we’ll need to implement a LinkedListInputIterator<T> that satisfies our new IInputIterator<T> interface for a linked list.
Listing 10.23. Linked list input iterator
class LinkedListInputIterator<T> implements IInputIterator<T> {
private node: LinkedListNode<T> | undefined;
constructor(node: LinkedListNode<T> | undefined) {
this.node = node;
}
increment(): void { 1
if (!this.node) throw Error();
this.node = this.node.next;
}
get(): T { 2
if (!this.node) throw Error();
return this.node.value;
}
equals(other: IInputIterator<T>): boolean { 3
return this.node == (<LinkedListInputIterator<T>>other).node;
}
}
- 1 If the current node is undefined, throw an error; otherwise, advance to the next node.
- 2 If the current node is undefined, throw an error; otherwise, get its value.
- 3 Iterators are considered to be equal if they wrap the same node. We can cast to LinkedListInputIterator<T> because callers shouldn’t compare iterators of different types.
Now we can create a pair of iterators over a linked list by initializing begin to be the head of the list and end to be undefined, as shown in the following code.
Listing 10.24. Pair of iterators over linked list
const head: LinkedListNode<number> = new LinkedListNode(0); 1 head.next = new LinkedListNode(1); head.next.next = new LinkedListNode(2); let begin: IInputIterator<number> = new LinkedListInputIterator(head); 2 let end: IInputIterator<number> = new LinkedListInputIterator(undefined); 3
- 1 A list with a few nodes
- 2 begin is the head of the linked list passed as an argument.
- 3 end is undefined.
We call this an input iterator because we can read values from it by using the get() method.
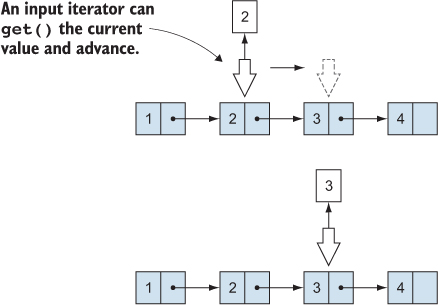
Input iterators
An input iterator is an iterator that can traverse a sequence once and provide its values. It can’t replay the values a second time, as the values may no longer be available. An input iterator doesn’t have to traverse a persistent data structure; it can also provide values from a generator or some other source (figure 10.4).
Figure 10.4. An input iterator can retrieve the value of the current element and advance to the next element.
Let’s also define an output iterator as an iterator we can write to. For that, we’ll declare an IWritable<T> interface with a set() method and have our IOutput-Iterator<T> be the combination of IWritable<T>, IIncrementable<T>, and an equals() method, as shown in the next listing.
Listing 10.25. IWritable<T> and IOutputIterator<T>
interface IWritable<T> {
set(value: T): void;
}
interface IOutputIterator<T> extends IWritable<T>, IIncrementable<T> {
equals(other: IOutputIterator<T>): boolean;
}
We can write values to this type of iterator, but we can’t read them back.
Output iterators
An output iterator is an iterator that can traverse a sequence and write values to it; it doesn’t have to be able to read them back. An output iterator doesn’t have to traverse a persistent data structure; it can also write values to other outputs.
Let’s implement an output iterator that writes to the console. Writing to an output stream is the most common use case for an output iterator: that’s when we can output data but can’t read it back. We can write data (without being able to read it) to a network connection, standard output, standard error, and so on. In our case, advancing the iterator doesn’t do anything, whereas setting a value calls console.log(), as shown in the next listing.
Listing 10.26. Console output iterator
class ConsoleOutputIterator<T> implements IOutputIterator<T> {
set(value: T): void {
console.log(value); 1
}
increment(): void { } 2
equals(other: IOutputIterator<T>): boolean {
return false; 3
}
}
- 1 set() logs to the console.
- 2 increment() doesn’t have to do anything because we’re not traversing a data structure in this case.
- 3 equals() can safely always return false, as writing to the console doesn’t have an end to compare against.
Now we have an interface that describes an input iterator and a concrete instance of an implementation over our linked list. We also have an interface that describes an output iterator and a concrete implementation that logs to the console. With these pieces in place, we can provide an alternative implementation of map() in listing 10.27.
This new version of map() will take as argument a pair of begin and end input iterators that define a sequence and an output iterator out, where it will write the results of mapping the given function over the sequence. Because we are no longer using standard JavaScript, we lose some of the syntactic sugar—no yield and no for...of loops.
Listing 10.27. map() with input and output iterators
function map<T, U>(
begin: IInputIterator<T>, end: IInputIterator<T>, 1
out: IOutputIterator<U>, 2
func: (value: T) => U): void {
while (!begin.equals(end)) { 3
out.set(func(begin.get())); 4
begin.increment(); 5
out.increment(); 5
}
}
- 1 begin and end iterators define the input sequence.
- 2 out is an output iterator for the result of the function.
- 3 Repeat until we traverse the whole sequence and begin becomes end.
- 4 Output the result of applying the function to the current element.
- 5 Increment both the input and the output iterators.
This version of map() is as general as the one based on the native Iterable-Iterator<T>: we can provide any IInputIterator<T>, one that traverses a linked list, one that traverses a tree in order, and so on. We can also provide any IOutput-Iterator<T>—one that writes to the console or one that writes to an array.
So far, this doesn’t gain us much. We have an alternative implementation that can’t leverage the special syntax that TypeScript provides. But these iterators are just the basic building blocks. We can define more-powerful iterators, and we’ll look at these next.
10.4.2. A useful find()
Let’s take another common algorithm: find(). This algorithm takes a sequence of values and a predicate, and returns the first element for which the predicate returns true. We can implement this by using the standard Iterable<T>, as the following listing shows.
Listing 10.28. find() with iterable
function find<T>(iter: Iterable<T>,
pred: (value: T) => boolean): T | undefined {
for (const value of iter) {
if (pred(value)) {
return value;
}
}
return undefined;
}
This works, but it’s not that useful. What if we want to change the value after we find it? If we are searching over a linked list of numbers for the first occurrence of 42 so that we can replace it with 0, it doesn’t help us that find() returns 42. The result may as well be a boolean, as this function tells us only whether the value exists in the sequence.
What if, instead of returning the value itself, we get an iterator pointing to that value? The out-of-the-box JavaScript Iterator<T> is read-only. We’ve seen how to create an iterator through which we can also set values. For this scenario, we’ll need a combination of readable and writable iterators. Let’s define a forward iterator.
Forward Iterators
A forward iterator is an iterator that can be advanced, can read the value at its current position, and update that value. A forward iterator can also be cloned, so that advancing one copy of the iterator does not advance the clone. This is important, as it allows us to traverse a sequence multiple times, unlike input and output iterators (figure 10.5).
Figure 10.5. A forward iterator can read and write the value of the current element, advance to the next element, and create a clone of itself that enables multiple traversals. In this figure, we see how clone() creates a copy of the iterator. As we advance the original, the clone doesn’t move.
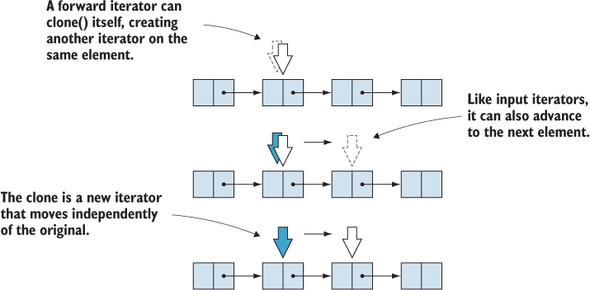
Our IForwardIterator<T> interface shown in the next listing is a combination of IReadable<T>, IWritable<T>, IIncrementable<T>, and the equals() and clone() methods.
Listing 10.29. IForwardIterator<T>
interface IForwardIterator<T> extends
IReadable<T>, IWritable<T>, IIncrementable<T> {
equals(other: IForwardIterator<T>): boolean;
clone(): IForwardIterator<T>;
}
As an example, let’s implement the interface to iterate over our linked list in the following listing. We’ll update our LinkedListIterator<T> to also provide the additional methods required by our new interface.
Listing 10.30. LinkedListIterator<T> implementing IForwardIterator<T>
class LinkedListIterator<T> implements IForwardIterator<T> { 1
private node: LinkedListNode<T> | undefined;
constructor(node: LinkedListNode<T> | undefined) {
this.node = node;
}
increment(): void {
if (!this.node) return;
this.node = this.node.next;
}
get(): T {
if (!this.node) throw Error();
return this.node.value;
}
set(value: T): void { 2
if (!this.node) throw Error();
this.node.value = value;
}
equals(other: IForwardIterator<T>): boolean { 3
return this.node == (<LinkedListIterator<T>>other).node;
}
clone(): IForwardIterator<T> { 4
return new LinkedListIterator(this.node);
}
}
- 1 This version of LinkedListIterator<T> implements the new IForwardIterator<T> interface.
- 2 set() is an additional method required by IWritable<T> that updates the value of a linked list node.
- 3 equals() now expects another IForwardIterator<T>.
- 4 clone() creates a new iterator pointing to the same node as this iterator.
Now let’s look at a version of find() that takes a pair of begin and end iterators, and returns an iterator pointing to the first element satisfying the predicate, shown in the next listing. With this version, we can update the value when we find it.
Listing 10.31. find() with forward iterator
function find<T>(
begin: IForwardIterator<T>, end: IForwardIterator<T>, 1
pred: (value: T) => boolean): IForwardIterator<T> { 2
while (!begin.equals(end)) { 3
if (pred(begin.get())) {
return begin; 4
}
begin.increment(); 5
}
return end; 6
}
- 1 begin and end forward iterators define the sequence.
- 2 The function returns a forward iterator pointing to the found element.
- 3 Repeat until we traverse the whole sequence.
- 4 If we found the element we were looking for, return the iterator.
- 5 Increment iterator and advance to the next element in the sequence.
- 6 If we’ve reached the end, we haven’t found an element. We return the end iterator.
Let’s use a linked list of numbers, the iterator we just implemented to traverse a linked list, and apply this algorithm to find the first value equal to 42 and replace it with a 0, as shown in the following code.
Listing 10.32. Replacing 42 with 0 in a linked list
let head: LinkedListNode<number> = new LinkedListNode(1); 1
head.next = new LinkedListNode(2);
head.next.next = new LinkedListNode(42);
let begin: IForwardIterator<number> =
new LinkedListIterator(head); 2
let end: IForwardIterator<number> =
new LinkedListIterator(undefined); 2
let iter: IForwardIterator<number> =
find(begin, end, (value: number) => value == 42); 3
if (!iter.equals(end)) { 4
iter.set(0); 5
}
- 1 Create a linked list containing the sequence 1, 2, 42.
- 2 Initialize begin and end forward iterators for the linked list.
- 3 Call find and get an iterator to the first node with the value 42.
- 4 We need to ensure that we found a node with value 42; otherwise, we are past the end of the list.
- 5 If we did, we can update its value to 0.
Forward iterators are extremely powerful, as they can traverse a sequence any number of times and also modify it. This feature allows us to implement in-place algorithms that don’t need to copy over a whole sequence of data to transform it. Finally, let’s tackle the algorithm with which we started this section: reverse().
10.4.3. An efficient reverse()
As we saw in the array implementation, an in-place reverse() starts from both ends of the array and swaps elements, incrementing the front index and decrementing the back index until the two cross.
We can generalize the array implementation to work with any sequence, but we need one extra capability on our iterator: the ability to decrement its position. An iterator with this ability is called a bidirectional iterator.
Bidirectional iterator
A bidirectional iterator has the same capabilities as a forward iterator; additionally, it can be decremented. In other words, a bidirectional iterator can traverse a sequence both forward and backward (figure 10.6).
Figure 10.6. A bidirectional iterator can read and write the value of the current element, clone itself, and step both forward and backward.
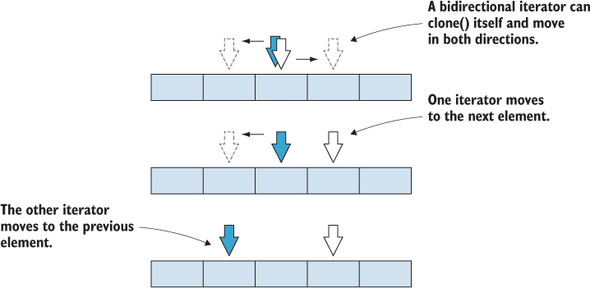
Let’s define an IBidirectionalIterator<T> interface similar to IForward-Iterator<T> interface with an additional decrement() method. Note that not all data structures can support such an iterator, such as our linked list. Because a node has a reference only to its successor, we cannot move backward to the preceding node. But we can provide a bidirectional iterator over a doubly linked list, in which a node holds references to both its successor and its predecessor or an array. Let’s implement an ArrayIterator<T> as an IBidirectionalIterator<T> in the next listing.
Listing 10.33. IBidirectionalIterator<T> and ArrayIterator<T>
interface IBidirectionalIterator<T> extends
IReadable<T>, IWritable<T>, IIncrementable<T> {
decrement(): void; 1
equals(other: IBidirectionalIterator<T>): boolean;
clone(): IBidirectionalIterator<T>;
}
class ArrayIterator<T> implements IBidirectionalIterator<T> {
private array: T[];
private index: number;
constructor(array: T[], index: number) {
this.array = array;
this.index = index;
}
get(): T {
return this.array[this.index];
}
set(value: T): void {
this.array[this.index] = value;
}
increment(): void {
this.index++;
}
decrement(): void {
this.index--;
}
equals(other: IBidirectionalIterator<T>): boolean {
return this.index == (<ArrayIterator<T>>other).index;
}
clone(): IBidirectionalIterator<T> {
return new ArrayIterator(this.array, this.index);
}
}
Now let’s implement reverse() in terms of a pair of begin and end bidirectional iterators. We will swap the values, increment begin, decrement end, and stop when the two iterators meet. We must make sure that the two iterators never pass each other, so as soon as we move one of them, we check whether they met.
Listing 10.34. reverse() with bidirectional iterator
function reverse<T>(
begin: IBidirectionalIterator<T>, end: IBidirectionalIterator<T>
): void {
while (!begin.equals(end)) { 1
end.decrement(); 2
if (begin.equals(end)) return; 3
const temp: T = begin.get(); 4
begin.set(end.get()); 4
end.set(temp); 4
begin.increment(); 5
}
}
- 1 Repeat until begin and end meet.
- 2 Decrement end. Remember that end starts at one element past the end of the array, so we need to decrement it before using it.
- 3 Check again that decrementing end didn’t get the two iterators pointing to the same element.
- 4 Swap the values.
- 5 Finally, increment start and then repeat. (The while loop condition checks again whether the two iterators met.)
Let’s try it out on an array of numbers in the following listing.
Listing 10.35. Reversing an array of numbers
let array: number[] = [1, 2, 3, 4, 5];
let begin: IBidirectionalIterator<number>
= new ArrayIterator(array, 0); 1
let end: IBidirectionalIterator<number>
= new ArrayIterator(array, array.length); 2
reverse(begin, end);
console.log(array); 3
- 1 Initialize begin over the array at index 0.
- 2 Initialize end over the array at index length (one past the last element).
- 3 This will log [5, 4, 3, 2, 1].
Using bidirectional iterators, we can generalize an efficient, in-place reverse() to work on any data structure that we can traverse in two directions. We extended the original algorithm, which was limited to arrays to work with any IBidirectional-Iterator<T>. We can apply the same algorithm to reverse a doubly linked list and any other data structure over which we can move an iterator backward and forward.
Note that we can also reverse a singly linked list, of course, but such an algorithm does not generalize. When we reverse a singly linked list, we alter the structure, as we’re flipping references to each next element to refer to the previous element instead. Such an algorithm is tightly coupled to the data structure it operates on and can’t be generalized. By contrast, our generic reverse() that requires a bidirectional iterator works the same way for any data structure that can provide such an iterator.
10.4.4. Efficient element retrieval
There are algorithms that require more from their iterators than increment() and decrement(). A good example is sorting algorithms. An efficient, O(n log n) sort such as quicksort will have to jump around the data structure that it is sorting, accessing elements at arbitrary locations. For this purpose, a bidirectional iterator is not enough. We need a random-access iterator.
Random-Access Iterators
A random-access iterator can jump forward and backward any given number of elements in constant time. Unlike a bidirectional iterator, which can be incremented or decremented one step at a time, a random-access iterator can move any number of elements (figure 10.7).
Figure 10.7. A random-access iterator can read and write the value of the current element, clone itself, and move backward or forward any number of steps.
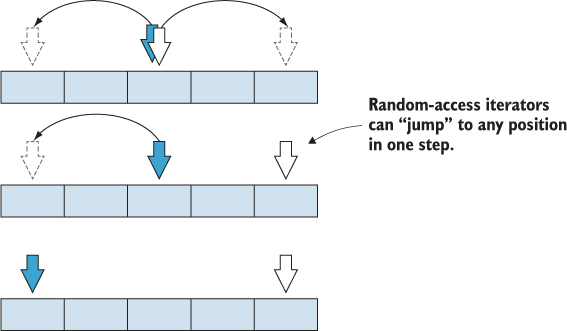
Arrays are good examples of random-accessible data structures, in which we can index and quickly retrieve any element. By contrast, with a doubly linked list, we need to traverse through successor or predecessor references to reach an element. A doubly linked list cannot support a random-access iterator.
Let’s define an IRandomAccessIterator<T> as an iterator that supports not only all the capabilities of IBidirectionalIterator<T>, but also a move() method that moves the iterator n elements. With random access iterators, it’s also useful to tell how far apart two iterators are. We will add a distance() method that returns the difference between two iterators in the following listing.
Listing 10.36. IRandomAccessIterator<T>
interface IRandomAccessIterator<T>
extends IReadable<T>, IWritable<T>, IIncrementable<T> {
decrement(): void;
equals(other: IRandomAccessIterator<T>): boolean;
clone(): IRandomAccessIterator<T>;
move(n: number): void;
distance(other: IRandomAccessIterator<T>): number;
}
Let’s update our ArrayIterator<T> in the next listing to implement IRandom-AccessIterator<T>.
Listing 10.37. ArrayIterator<T> implementing a random-access iterator
class ArrayIterator<T> implements IRandomAccessIterator<T> {
private array: T[];
private index: number;
constructor(array: T[], index: number) {
this.array = array;
this.index = index;
}
get(): T {
return this.array[this.index];
}
set(value: T): void {
this.array[this.index] = value;
}
increment(): void {
this.index++;
}
decrement(): void {
this.index--;
}
equals(other: IRandomAccessIterator<T>): boolean {
return this.index == (<ArrayIterator<T>>other).index;
}
clone(): IRandomAccessIterator<T> {
return new ArrayIterator(this.array, this.index);
}
move(n: number): void {
this.index += n; 1
}
distance(other: IRandomAccessIterator<T>): number { 2
return this.index - (<ArrayIterator<T>>other).index;
}
}
- 1 move() advances the iterator n steps. (n can be negative to move backward.)
- 2 distance() determines the distance between two iterators
Let’s take a very simple algorithm that benefits from a random-access iterator: elementAt(). This algorithm takes as arguments a begin and end iterator defining a sequence and a number n. It will return an iterator to the nth element of the sequence or the end iterator if n is larger than the length of the sequence.
We can implement this algorithm with an input iterator, but we would have to increment the iterator n times to reach the element. That is linear time complexity, or O(n). With a random-access iterator, we can do this in constant time, or O(1), as shown in the next listing.
Listing 10.38. Element at
function elementAtRandomAccessIterator<T>(
begin: IRandomAccessIterator<T>, end: IRandomAccessIterator<T>,
n: number): IRandomAccessIterator<T> {
begin.move(n); 1
if (begin.distance(end) <= 0) return end; 2
return begin; 3
}
- 1 Move begin n elements forward.
- 2 If it is equal or larger than end, n is larger than the sequence, so return end.
- 3 Otherwise, return an iterator to the element.
Random-access iterators enable the most efficient algorithms, but fewer data structures can provide such iterators.
10.4.5. Iterator recap
We’ve looked at the various categories of iterators and how their different capabilities enable more efficient algorithms. We started with input and output iterators, which perform a one-pass traversal over a sequence. Input iterators allow us to read values, whereas output iterators allow us to set values.
This is all we need for algorithms such as map(), filter(), and reduce(), which process their input in linear fashion. Most programming languages provide algorithm libraries for only this type of iterator, including Java and C#, with their Iterable<T> and IEnumerable<T>.
Next, we saw that adding the ability to both read and write a value, and to create a copy of an iterator, enables other useful algorithms that can modify data in place. These new capabilities were supplied by a forward iterator.
In some cases, such as the reverse() example, moving only forward through a sequence is not enough. We need to move both ways. An iterator that can step both forward and backward is called a bidirectional iterator.
Finally, some algorithms perform better if they can jump around a sequence and access items at arbitrary locations without needing to traverse step by step. Sorting algorithms are good examples; so is the simple elementAt() that we just saw. To support such algorithms, we introduced the random-access iterator, which can move over multiple elements in one step.
These ideas are not new; the C++ standard library provides a set of efficient algorithms that use iterators with similar capabilities. Other languages limit themselves to a smaller set of algorithms or less-efficient implementations.
You may have noticed that the iterator-based algorithms were not fluent, as they took a pair of iterators as input and returned either void or an iterator. C++ is moving from iterators to ranges. We won’t cover this topic deeply in this book, but at a high level, a range can be thought of as a pair of begin/end iterators. Updating the algorithms to take ranges as arguments and to return ranges sets the stage for a more fluent API in which we can chain operations on ranges. It is likely that at some point in the future, range-based algorithms will make their way into other languages. The ability to run efficient, in-place, generic algorithms over any data structure with a capable-enough iterator is extremely useful.
10.4.6. Exercises
What is the minimum iterator category required to support drop() that skips the first n elements of a range?
- InputIterator
- ForwardIterator
- BidirectionalIterator
- RandomAccessIterator
What is the minimum iterator category required to support a binary search algorithm (with O(log n))? As a reminder, binary search checks the middle element of a range. If it’s larger than the value searched for, it splits the range in halves and looks at the first half. If not, it looks at the second half of the range and then repeats. The idea is that the search space is halved at each step, so the complexity of the algorithm is O(log n).
- InputIterator
- ForwardIterator
- BidirectionalIterator
- RandomAccessIterator
10.5. Adaptive algorithms
The more we ask of an iterator, the fewer the data structures that can supply it. We saw that we can create a forward iterator over a singly linked list, a doubly linked list, or an array. If we want a bidirectional iterator, singly linked lists are out of the picture. We can get a bidirectional iterator over doubly linked lists and arrays but not singly linked lists. If we want a random-access iterator, we need to drop doubly linked lists.
We want generic algorithms to be as general as possible, and they require the least capable iterator that is good enough to support the algorithm. But as we just saw, less efficient versions of an algorithm don’t require that much from their iterators. For some algorithms, we can provide multiple versions: a less-efficient version that works with a less-capable iterator and a more-efficient version that works with a more--capable iterator.
Let’s revisit our elementAt() example. This algorithm will return the nth value in a sequence or the end of the sequence if n is larger than the length of the sequence. If we have a forward iterator, we can increment it n times and return the value. This has linear, or O(n) complexity, as we need to perform more steps as n increases. On the other hand, if we have a random-access iterator, we can retrieve the element in constant, or O(1), time.
Do we want to provide a more-general, less-efficient algorithm or a more-efficient algorithm that is limited to fewer data structures? The answer is that we don’t have to choose: we can provide two versions of the algorithm, and depending on the type of iterator we get, we can leverage the most-efficient implementation.
Let’s implement an elementAtForwardIterator() that retrieves the element in linear time and an elementAtRandomAccessIterator() that retrieves the element in constant time, as shown in the following listing.
Listing 10.39. elementAt() with input and random-access iterators
function elementAtForwardIterator<T>(
begin: IForwardIterator<T>, end: IForwardIterator<T>,
n: number): IForwardIterator<T> {
while (!begin.equals(end) && n > 0) {
begin.increment(); 1
n--; 1
}
return begin; 2
}
function elementAtRandomAccessIterator<T>( 3
begin: IRandomAccessIterator<T>, end: IRandomAccessIterator<T>,
n: number): IRandomAccessIterator<T> {
begin.move(n);
if (begin.distance(end) <= 0) return end;
return begin;
}
- 1 While n is greater than 0 and we haven’t reached the end of the sequence, move the iterator to the next element and decrement n.
- 2 Return begin. This will be either the nth element or the end of the sequence.
- 3 This is the elementAt() implementation from the preceding section.
Now we can implement an elementAt() that picks the algorithm to apply based on the capabilities of the iterators it receives as arguments, as shown in listing 10.40. Note that TypeScript doesn’t support function overloading, so we need to use a function that determines the type of the iterator. In other languages, such as C# and Java, we can simply provide methods that have the same name but take different arguments.
Listing 10.40. Adaptive elementAt()
function isRandomAccessIterator<T>(
iter: IForwardIterator<T>): iter is IRandomAccessIterator<T> {
return "distance" in iter; 1
}
function elementAt<T>(
begin: IForwardIterator<T>, end: IForwardIterator<T>,
n: number): IForwardIterator<T> {
if (isRandomAccessIterator(begin) && isRandomAccessIterator(end)) {
return elementAtRandomAccessIterator(begin, end, n); 2
} else {
return elementAtForwardIterator(begin, end, n); 3
}
}
- 1 We consider iter to be a random-access iterator if it has a distance method.
- 2 If iterators are random-access, we call the efficient elementAtRandomAccessIterator() function.
- 3 If not, we fall back to the less-efficient elementAtForwardIterator() function.
A good algorithm works with what it has; it adapts to a less-capable iterator with a less-efficient implementation while enabling the most-efficient implementation for more-capable iterators.
10.5.1. Exercise
Implement nthLast(), a function that returns an iterator to the nth-last element of a range (or end if the range is too small). If n is 1, we return an iterator pointing to the last element; if n is 2, we return an iterator pointing to the second to last element, and so on. If n is 0, we return the end iterator pointing one past the last element of the range.
Hint: we can implement this with a ForwardIterator with two passes. The first pass counts the elements of the range. In the second pass, because we know the size of the range, we know when to stop to be n items from the end.
Summary
- Generic algorithms operate on iterators, so they can be reused across different data structures.
- Whenever you write a loop, consider whether a library algorithm or a composition of algorithms can achieve the same result.
- Fluent APIs provide a nice interface for chaining algorithms.
- Type constraints allow algorithms to require certain capabilities from the types they operate on.
- Input iterators can read values and can be advanced. We read from a stream, like standard input, with an input iterator. After we read a value, we can’t reread; we can only move forward.
- Output iterators can be written to and can be advanced. We write to a stream, like standard output, with an output iterator. After we write a value, we can’t read it back.
- Forward iterators can read values and be written to, advanced, and cloned. A linked list is a good example of a data structure that can support a forward iterator. We can move to the next element and hold multiple references to the current element, but we can’t move to the previous element unless we save a reference to it when we are initially on it.
- Bidirectional iterators have all the features of forward iterators but can also move backward. A doubly linked list is an example of a data structure that supports a bidirectional iterator. We can move to both the next and the previous element as needed.
- Random-access iterators can freely move to any position in a sequence. An array is a data structure that supports a random-access iterator. We can jump in one step to any element.
- Most mainstream languages provide algorithm libraries for input iterators.
- More-capable iterators enable more-efficient algorithms.
- Adaptive algorithms provide multiple implementations: the more capable the iterators, the more efficient the algorithm.
In chapter 11, we’ll step it up to the next level of abstraction—higher kinded types—and explain what a monad is and what we can do with it.
Answers to exercises
Better map(), filter(), reduce()
A possible implementation using reduce() and filter():
function concatenateNonEmpty(iter: Iterable<string>): string { return reduce( filter( iter, (value) => value.length > 0), "", (str1: string, str2: string) => str1 + str2); }
A possible implementation using map() and filter():
function squareOdds(iter: Iterable<number>): IterableIterator<number> { return map( filter( iter, (value) => value % 2 == 1), (x) => x * x ); }
Common algorithms
A possible implementation:
class FluentIterable<T> { /* ... */ take(n: number): FluentIterable<T> { return new FluentIterable (this.takeImpl(n)); } private *takeImpl(n: number): IterableIterator<T> { for (const value of this.iter) { if (n-- <= 0) return; yield value; } } }
A possible implementation:
class FluentIterable<T> { /* ... */ drop(n: number): FluentIterable<T> { return new FluentIterable(this.dropImpl(n)); } private *dropImpl(n: number): IterableIterator<T> { for (const value of this.iter) { if (n-- > 0) continue; yield value; } } }
Constraining type parameters
A possible solution using a generic type constraint to ensure that T is IComparable:
function clamp<T extends IComparable<T>>(value: T, low: T, high: T): T { if (value.compareTo(low) == ComparisonResult.LessThan) { return low; } if (value.compareTo(high) == ComparisonResult.GreaterThan) { return high; } return value; }
Efficient reverse and other algorithms using iterators
a—drop() can be used even on potentially infinite streams of data. Being able simply to advance is sufficient.
d—Binary search needs to be able to jump to the middle of the range at each step to be efficient. A bidirectional iterator would still have to step element by element to reach the half of the range, which would not make it O(log n). (Step by step is O(n) or linear.)
Adaptive algorithms
An adaptive algorithm will decrement from the back if it receives bidirectional iterators and use the two-pass approach when it receives forward iterators. Here is a possible implementation:
function nthLastForwardIterator<T>( begin: IForwardIterator<T>, end: IForwardIterator<T>, n: number) : IForwardIterator<T> { let length: number = 0; let begin2: IForwardIterator<T> = begin.clone(); // Determine the length of the range while (!begin.equals(end)) { begin.increment(); length++; } if (length < n) return end; let curr: number = 0; // Advance until the current element is the nth from the back while (!begin2.equals(end) && curr < length - n) { begin2.increment(); curr++; } return begin2; } function nthLastBidirectionalIterator<T>( begin: IBidirectionalIterator<T>, end: IBidirectionalIterator<T>, n: number) : IBidirectionalIterator<T> { let curr: IBidirectionalIterator<T> = end.clone(); while (n > 0 && !curr.equals(begin)) { curr.decrement(); n--; } // Range is too small if we reached begin before decrementing n times if (n > 0) return end; return curr; } function isBidirectionalIterator<T>( iter: IForwardIterator<T>): iter is IBidirectionalIterator<T> { return "decrement" in iter; } function nthLast<T>( begin: IForwardIterator<T>, end: IForwardIterator<T>, n: number) : IForwardIterator<T> { if (isBidirectionalIterator(begin) && isBidirectionalIterator(end)) { return nthLastBidirectionalIterator(begin, end, n); } else { return nthLastForwardIterator(begin, end, n); } }