
16 Bivariate and Multivariate Relationships
Overview
This chapter explores the relationship between two or more variables. You look for patterns and points that don’t fit the patterns. You see where the data points are located, where the distribution is dense, and which way it is oriented. You explore which variables contribute the most information, and how observations and variables can be grouped or clustered.
Detective skills are built with the experience of looking at a variety of data, and learning to look at them in different ways. As you become a better detective, you also develop better intuition for understanding more advanced techniques.
It is not easy to look at lots of variables, but the increased range of the exploratory tools and techniques at your fingertips in JMP helps you make more interesting and valuable discoveries.
Chapter Contents
The Elliptical Contours of the Normal Distribution
Correlations and the Bivariate Normal
Simulating Bivariate Correlations
Correlations across Many Variables
Outliers in Three and More Dimensions
Identify Variation with Principal Components Analysis
Principal Components for Six Variables
How Many Principal Components?
Stepwise Discriminant Variable Selection
Hierarchical Clustering: How Does It Work?
Bivariate Distributions
Previous chapters covered how the distribution of a response can vary depending on factors and groupings. This chapter returns to explore distributions as simple unstructured batches of data. However, instead of a single variable, the focus is on the joint distribution of two or more responses.
Density Estimation
As with univariate distributions, a central question is where are the data? What regions of the space are dense with data and what areas are relatively vacant? The histogram forms a simple estimate of the density of a univariate distribution. If you want a smoother estimate of the density, JMP has an option that takes a weighted count of a sliding neighborhood of points to produce a smooth curve. This idea can be extended to several variables.
One of the most classic multivariate data sets in statistics contains the measurements of iris flowers that R. A. Fisher analyzed. Fisher’s iris data are in the sample data table called Iris.jmp, with variables Sepal length, Sepal width, Petal length, and Petal width. First, look at the variables one at a time.
![]() Select Help > Sample Data Library and open Iris.jmp.
Select Help > Sample Data Library and open Iris.jmp.
![]() Select Analyze > Distribution.
Select Analyze > Distribution.
![]() Assign Sepal length and Petal length to Y, Columns and then click OK.
Assign Sepal length and Petal length to Y, Columns and then click OK.
![]() In the Distribution report, hold down Ctrl and select Continuous Fit > Smooth Curve from the red triangle menu next to Sepal length.
In the Distribution report, hold down Ctrl and select Continuous Fit > Smooth Curve from the red triangle menu next to Sepal length.
![]() When the smooth curves appear, drag the density slider beneath the histogram to see the effect of using a wider or narrower smoothing distribution (Figure 16.1).
When the smooth curves appear, drag the density slider beneath the histogram to see the effect of using a wider or narrower smoothing distribution (Figure 16.1).
Notice in Figure 16.1 that Petal length has an unusual distribution with two modes with no values between 2 and 3, which implies that there might be two distinct distributions.
Note: The bimodal distribution of Petal length could be explored using Continuous Fit > Normal Mixtures > Normal 2 Mixture, from the red triangle menu next to Petal length. But for now, we are interested in looking at how multiple variables behave together.
Figure 16.1 Univariate Distribution with Smoothing Curve

Bivariate Density Estimation
Drag the sliders to vary the smoothness of the curve.
JMP has a smoother that works with two variables to show their bivariate densities. The goal is to draw lines around areas that are dense with points. Continue with the iris data and look at Petal length and Sepal length together:
![]() Select Analyze > Fit Y by X and assign Petal length to Y, Response and Sepal length to X, Factor.
Select Analyze > Fit Y by X and assign Petal length to Y, Response and Sepal length to X, Factor.
![]() Click OK.
Click OK.
![]() When the scatterplot appears, select Nonpar Density from the red triangle menu next to Bivariate Fit.
When the scatterplot appears, select Nonpar Density from the red triangle menu next to Bivariate Fit.
The result, shown in Figure 16.2, is a contour plot, where the various contour lines show paths of equal density. The density is estimated for each point on a grid by taking a weighted average of the points in the neighborhood, where the weights decline with distance. Estimates done in this way are called kernel smoothers.
The Nonparametric Bivariate Density table beneath the plot has slider controls available to control the vertical and horizontal width of the smoothing distribution.
![]() Select Kernel Control from the red triangle menu next to the Quantile Density Contours legend (below the plot).
Select Kernel Control from the red triangle menu next to the Quantile Density Contours legend (below the plot).
![]() Adjust the slider bars. Calculating densities can take some time, so they are not re-estimated until you click the Apply button.
Adjust the slider bars. Calculating densities can take some time, so they are not re-estimated until you click the Apply button.
Figure 16.2 Bivariate Density Estimation Curves

The density contours form a map showing where the data are most dense. The contours are calculated according to quantiles, where a certain percent of the data lie outside each contour curve. These quantile density contours show where each 5% and 10% of the data are. The innermost narrow contour line encloses the densest 5% of the data. The heavy line just outside surrounds the densest 10% of the data. It is colored as the 0.9 contour because 90% of the data lie outside it. Half the data distribution is inside the solid green lines, the 50% contours. Only about 5% of the data is outside the outermost 5% contour.
One of the features of the iris petal and sepal length data is that there seem to be several local peaks in the density. There are two ”islands” of data, one in the lower left and one in the upper right of the scatterplot.
These groups of locally dense data are called clusters, and the peaks of the density are called modes.
![]() Select Mesh Plot from the menu on the legend of the Quantile Density Contours.
Select Mesh Plot from the menu on the legend of the Quantile Density Contours.
This produces a 3-D surface of the density, as shown here.
![]() Drag the mesh plot to rotate it.
Drag the mesh plot to rotate it.

Mixtures, Modes, and Clusters
Multimodal data often come from a mixture of several groups. Examining the data closely reveals that there is actually a collection of three species of iris: Virginica, Versicolor, and Setosa.
Conducting a bivariate density for each group results in the density plots in Figure 16.3. The axes are adjusted on these plots to show the same scales.
Figure 16.3 Bivariate Density Curves

Another way to examine these groupings, on the same plot, is with the Graph Builder.
![]() Select Graph > Graph Builder
Select Graph > Graph Builder
![]() Drag Petal length to the Y zone, Sepal length to the X zone, and Species to the Overlay zone.
Drag Petal length to the Y zone, Sepal length to the X zone, and Species to the Overlay zone.
![]() Click on the contour icon to see the graph in Figure 16.4.
Click on the contour icon to see the graph in Figure 16.4.
Note: Enter a value in Number of Levels to change the number of contours.
Figure 16.4 Graph Builder Contour Densities

You can again see that the three species fall in different regions for Petal length, while Virginica and Versicolor have some overlap of Sepal length.
Note: To classify an observation (an iris) into one of these three groups, a natural procedure is to compare the density estimates corresponding to the petal and sepal length of a specimen over the three groups, and assign it to the group where its point is enclosed by the highest density curve. This type of statistical method is also used in discriminant analysis and cluster analysis, shown later in this chapter.
The Elliptical Contours of the Normal Distribution
Notice that the contours of the distributions on each species are elliptical in shape. It turns out that ellipses are the characteristic shape for a bivariate normal distribution. The Fit Y by X platform can show a graph of these normal contours.
![]() Again select Analyze > Fit Y by X and assign Petal length to Y, Response and Sepal length to X, Factor.
Again select Analyze > Fit Y by X and assign Petal length to Y, Response and Sepal length to X, Factor.
![]() Click OK.
Click OK.
When the scatterplot appears:
![]() Select Group By from the red triangle menu next to Bivariate Fit and select Species as the grouping variable.
Select Group By from the red triangle menu next to Bivariate Fit and select Species as the grouping variable.
![]() Click OK.
Click OK.
![]() Select Density Ellipse from the red triangle menu next to Bivariate Fit with 0.50 as the probability level for the ellipse.
Select Density Ellipse from the red triangle menu next to Bivariate Fit with 0.50 as the probability level for the ellipse.
The result of these steps is shown in Figure 16.5. When there is a grouping variable in effect, there is a separate estimate of the bivariate normal density (or any fit you select) for each group. The normal density ellipse for each group encloses the densest 50% of the estimated distribution.
Figure 16.5 Density Ellipses for Species Grouping Variable

Notice that the two ellipses toward the top of the plot are diagonally oriented, while the one at the bottom is not. The reports beneath the plot show the means, standard deviations, and correlation of Sepal length and Petal length for the distribution of each species. Note that the correlation is low for Setosa, and high for Versicolor and Virginica. The diagonal flattening of the elliptical contours is a sign of strong correlation. If variables are uncorrelated, their normal density contours appear to have a more non-diagonal and rounder shape.
One of the main uses of correlation is to see whether variables are related. You want to know if the distribution of one variable is a function of the other. That is, if you know the value of one variable can you predict the value of the other? When the variables are normally distributed and uncorrelated, the univariate distribution of one variable is the same no matter what the value of the other variable is. When the density contours have no diagonal aspect, the density across any slice is the same no matter where you take that slice (after you normalize the slice to have an area of one so that it becomes a univariate density).
The Density Ellipse command in the Fit Y by X platform gives the correlation, which is a measure, on a scale of -1 to 1, of how close two variables are to being linearly related. A significance test on the correlation shows the p-value for the hypothesis that there is no correlation. A low p-value indicates that there is a significant correlation.
The next sections uses simulations to cover the bivariate normal distribution in more detail.
Note: Density ellipses can also be shown by using the Graph Builder.

Correlations and the Bivariate Normal
Describing normally distributed bivariate data is easy because you need only the means, standard deviations, and the correlation of the two variables to completely characterize the joint distribution. If the individual distributions are not normal, you might need a good deal more information to describe the bivariate relationship.
Correlation is a measure of the linear association between two variables. If you can draw a straight line through all the points of a scatterplot, then there is a perfect correlation. Perfectly correlated variables measure the same thing. The sign of the correlation reflects the slope of the regression line—a perfect positive correlation has a value of 1, and a perfect negative correlation has a value of –1.
Simulating Bivariate Correlations
As we saw in earlier chapters, using simulated data created with formulas provides a reference point when you move on to analyze real data.
![]() Select Help > Sample Data Library and open Corrsim.jmp.
Select Help > Sample Data Library and open Corrsim.jmp.
This table has no rows, but contains formulas to generate correlated data.
![]() Select Rows > Add Rows and enter 1000 when prompted for the number of rows.
Select Rows > Add Rows and enter 1000 when prompted for the number of rows.
![]() Click OK.
Click OK.
The formulas evaluate to give simulated correlations (Figure 16.6). There are two independent standard normal random columns, labeled X and y. The remaining columns (y.50, y.90, y.99, and y.1.00) have formulas constructed to produce the level of correlation indicated in the column names (0.5, 0.9, 0.99, and 1.00). For example, the column formula to produce the correlation of 1 is:

Figure 16.6 Partial Listing of Simulated Values

You can use the Fit Y by X platform to examine the correlations:
![]() Select Analyze > Fit Y by X and assign X to X, Factor, and all the Y columns to Y, Response.
Select Analyze > Fit Y by X and assign X to X, Factor, and all the Y columns to Y, Response.
![]() Hold down the Ctrl (or
Hold down the Ctrl (or ![]() ) key and select Density Ellipse from any red triangle menu. Select 0.90 as the density level.
) key and select Density Ellipse from any red triangle menu. Select 0.90 as the density level.
Holding down the Ctrl (or ![]() ) key applies the command to all the open plots in the Fit Y by X window simultaneously.
) key applies the command to all the open plots in the Fit Y by X window simultaneously.
![]() Do the previous step twice more with 0.95 and 0.99 as density parameters.
Do the previous step twice more with 0.95 and 0.99 as density parameters.
These steps make normal density ellipses (Figure 16.7) containing 90%, 95%, and 99% of the bivariate normal density, using the means, standard deviations, and correlation from the data.
As an exercise, create the same plot for generated data with a correlation of -1, which is the last plot shown in Figure 16.7. To do this:
![]() Create a new column and call it Y(-1.00) or whatever you want.
Create a new column and call it Y(-1.00) or whatever you want.
![]() Right-click the column header and select Formula.
Right-click the column header and select Formula.
![]() Enter the following formula.
Enter the following formula.

Note: Open the Formula Editor window for the variable called Y1.00. Select its formula and drag it to the Formula Editor window for the new column that you are creating. To place a minus sign in front of the formula, select the whole formula and click the unary sign (the +/-) button on the Formula Editor keypad.
![]() Select Analyze > Fit Y by X to create the same plots for the new column as shown above.
Select Analyze > Fit Y by X to create the same plots for the new column as shown above.
Note in Figure 16.7 that as the correlation grows from 0 to 1, the relationship between the variables gets stronger and stronger. The normal density contours are circular at correlation 0 (if the axes are scaled by the standard deviations) and collapse to the line at correlation 1.
Figure 16.7 Density Ellipses for Various Correlation Coefficients

Note: The demoCorr teaching script provides an interactive tool for exploring correlations between two variables. For example, the script enables you to add new points and drag points to see how the correlation changes for different data. To run this script, select Help > Sample Data > Teaching Scripts > Teaching Demonstrations > demoCorr.
Correlations across Many Variables
The next example involves six variables. To characterize the distribution of a six- variate normal distribution, the means, the standard deviations, and the bivariate correlations of all the pairs of variables are needed.
In a chemistry study, the solubility of 72 chemical compounds was measured with respect to six solvents (Koehler and Dunn, 1988). One purpose of the study was to see whether any of the solvents were correlated—that is, to identify any pairs of solvents that acted on the chemical compounds in a similar way.
![]() Select Help > Sample Data Library and open Solubility.jmp to see the Label (solvents) and the variables 1-Octanol, Ether, Chloroform, Benzene, Carbon Tetrachloride, and Hexane.
Select Help > Sample Data Library and open Solubility.jmp to see the Label (solvents) and the variables 1-Octanol, Ether, Chloroform, Benzene, Carbon Tetrachloride, and Hexane.
Note that the tag icon appears beside the Label column in the Columns panel to signify that JMP uses the values in this column to label points in plots.
![]() Select Analyze > Multivariate Methods > Multivariate and assign all six continuous solvent variables to Y, Columns.
Select Analyze > Multivariate Methods > Multivariate and assign all six continuous solvent variables to Y, Columns.
![]() Click OK.
Click OK.
You see a correlations table and a scatterplot matrix like the one shown in Figure 16.8. Each small scatterplot is identified by the name cells of its row and column.
Figure 16.8 Scatterplot Matrix for Six Variables

1-Octanol and Ether are highly correlated, but have weak correlations with other variables. The other four variables have strong correlations with one another. For example, note the correlation between Carbon Tetrachloride and Hexane.
You can resize the whole matrix by resizing any one of its small scatterplots.
![]() Move your mouse over the corner of any scatterplot until the cursor changes into a resize arrow. Click and drag to resize the plots.
Move your mouse over the corner of any scatterplot until the cursor changes into a resize arrow. Click and drag to resize the plots.
Also, you can change the row and column location of a variable in the matrix by dragging its name on the diagonal.
Keep this report open to use again later in this chapter.
Bivariate Outliers
Let’s switch platforms to get a closer look at the relationship between Carbon Tetrachloride and Hexane using a set of density contours.
![]() Select Analyze > Fit Y by X.
Select Analyze > Fit Y by X.
![]() Assign Carbon Tetrachloride to Y, Response and Hexane to X, Factor, and then click OK.
Assign Carbon Tetrachloride to Y, Response and Hexane to X, Factor, and then click OK.
![]() Select Density Ellipse from the red triangle menu next to Bivariate Fit to add four density contours to the plot (0.50, 0.90, 0.95, and 0.99), as shown in Figure 16.9.
Select Density Ellipse from the red triangle menu next to Bivariate Fit to add four density contours to the plot (0.50, 0.90, 0.95, and 0.99), as shown in Figure 16.9.
Under the assumption that the data are distributed bivariate normal, the inside ellipse contains half the points, the next ellipse 90%, then 95%, and the outside ellipse contains 99% of the points.
Note that there are two points that are outside even the 99% ellipse. To make your plot look like the one below:
![]() Hold down the Shift key and select the two outside points.
Hold down the Shift key and select the two outside points.
![]() With the points highlighted, select Rows > Label/Unlabel to label them.
With the points highlighted, select Rows > Label/Unlabel to label them.
![]() To better read the labels, drag the label to an open area.
To better read the labels, drag the label to an open area.
The labeled points are potential outliers. A point can be considered an outlier if its bivariate normal density contour is associated with a very low probability.
Figure 16.9 Bivariate Plot With Ellipses and Outliers

Note that P-hydroxybenzaldehyde is not an outlier for either variable individually (that is, in a univariate sense). In the scatterplot, it is near the middle of the Hexane distribution, and is barely outside the 50% limit for the Carbon Tetrachloride distribution. However, it is a bivariate outlier because it falls outside the correlation pattern, which shows most of the points in a narrow diagonal elliptical area.

A common method for identifying outliers is the Mahalanobis distance. The Mahalanobis distance is computed with respect to the correlations as well as the means and standard deviations of both variables.
![]() Click the Multivariate report that shows the scatterplot matrix to make it the active window.
Click the Multivariate report that shows the scatterplot matrix to make it the active window.
![]() Select Outlier Analysis > Mahalanobis Distances from the red triangle menu next to Multivariate.
Select Outlier Analysis > Mahalanobis Distances from the red triangle menu next to Multivariate.
This command gives the Mahalanobis Distance outlier plot shown in Figure 16.10.
Figure 16.10 Outlier Analysis with Mahalanobis Outlier Distance Plot

The reference line is drawn using an F-quantile and shows the estimated distance that contains 95% of the points. In agreement with the ellipses in the bivariate plot, Sulfathiazole and P-hydroxybenzaldehyde show as prominent outliers (along with three other solvents). To explore these two outliers, follow these steps:
![]() Make sure the two outliers are selected in the Mahalanobis distances plot. These two points are also selected in each scatterplot in the scatterplot matrix.
Make sure the two outliers are selected in the Mahalanobis distances plot. These two points are also selected in each scatterplot in the scatterplot matrix.
![]() Look at the scatterplot for Carbon Tetrachloride and Hexane. Note that the two outliers are outside the density ellipse for these two variables.
Look at the scatterplot for Carbon Tetrachloride and Hexane. Note that the two outliers are outside the density ellipse for these two variables.
![]() Click on other points in the Mahalanobis distances plot. Note that points that are far below the reference line fall within all of the density ellipses.
Click on other points in the Mahalanobis distances plot. Note that points that are far below the reference line fall within all of the density ellipses.
Outliers in Three and More Dimensions
In the previous section, we looked at two variables at a time—bivariate correlations for several pairs of variables. In this section, we discuss correlations that involve more than two variables at a time. First, let’s do a little cleanup.
![]() Select Rows > Clear Row States to unlabel the two data points.
Select Rows > Clear Row States to unlabel the two data points.
To consider three variables at a time, look at three chemical variables, 1-Octanol, Ether, and Carbon Tetrachloride.
You can see the distribution of points with a 3-D scatterplot:
![]() Select Graph > Scatterplot 3D and assign 1-Octanol, Ether, and Carbon Tetrachloride to Y, Columns.
Select Graph > Scatterplot 3D and assign 1-Octanol, Ether, and Carbon Tetrachloride to Y, Columns.
![]() Click OK.
Click OK.
![]() Select Normal Contour Ellipsoids from the red triangle menu next to Scatterplot 3D, change the coverage to 0.9, and then click OK to see the three-dimensional ellipsoid in Figure 16.11.
Select Normal Contour Ellipsoids from the red triangle menu next to Scatterplot 3D, change the coverage to 0.9, and then click OK to see the three-dimensional ellipsoid in Figure 16.11.
![]() Click in the 3-D plot and drag to rotate the plot and look for three-variate outliers.
Click in the 3-D plot and drag to rotate the plot and look for three-variate outliers.
The orientation in Figure 16.11 shows four points that appear to be outlying from the rest of the points with respect to the ellipsoid-shaped distribution.
Figure 16.11 Outliers as Seen in Scatterplot 3D

The Fit Y by X and the Scatterplot 3D platforms revealed extreme values in two and three dimensions. How do we measure outliers in six dimensions? All outliers, from two dimensions to six dimensions (and beyond), should show up on the Mahalanobis distances outlier plot shown earlier. This plot measures distance with respect to all six variables.
If you closed the scatterplot window, select Analyze > Multivariate Methods > Multivariate with all six responses as Y variables. Then select Outlier Analysis > Mahalanobis Distances from the red triangle menu next to Multivariate.
Potential outliers across all six variables are labeled in Figure 16.12.
Figure 16.12 Outlier Distance Plot for Six Variables

There is a refinement to the outlier distance that can help to further isolate outliers. When you estimate the means, standard deviations, and correlations, all points—including outliers—are included in the calculations and affect these estimates, causing an outlier to disguise itself.
Suppose that as you measure the outlier distance for a point, you exclude that point from all mean, standard deviation, and correlation estimates.
This technique is called jackknifing. The jackknifed distances often make outliers stand out better.
![]() To see the jackknifed distance plot, select Outlier Analysis > Jackknife Distances from the red triangle menu next to Multivariate.
To see the jackknifed distance plot, select Outlier Analysis > Jackknife Distances from the red triangle menu next to Multivariate.
Identify Variation with Principal Components Analysis
Lets return to the 3-D scatterplot. First, select Rows > Clear Row States to unlabel the outliers. As you rotate the plot, points in one direction in the space show a lot more variation than points in other directions. This is true in two dimensions when variables are highly correlated. The long axis of the normal ellipse shows more variance; the short axis shows the least (as shown here).

Now, in three dimensions, there are three axes with a three-dimensional ellipsoid for the trivariate normal (shown here). The solubility data seem to have the ellipsoidal contours characteristic of normal densities, except for a few outliers (as noted earlier).
The directions of the axes of the normal ellipsoids are called the principal components. They were mentioned in the Galton example in “Why It’s Called Regression” on page 269 of Chapter 10, “Fitting Curves through Points: Regression.”

The first principal component is defined as the direction of the linear combination of the variables that has maximum variance. In a 3-D scatterplot, it is easy to rotate the plot and see which direction this is.
The second principal component is defined as the direction of the linear combination of the variables that has maximum variance. The second principal component is subject to it being at a right angle (orthogonal) to the first principal component. Higher principal components are defined in the same way. There are as many principal components as there are variables. The last principal component has little or no variance if there is substantial correlation among the variables. This means that there is a direction for which the normal density hyper-ellipsoid is very thin.
The Scatterplot 3D platform can show principal components.
![]() Click the Scatterplot 3D report shown in Figure 16.11 to make it active.
Click the Scatterplot 3D report shown in Figure 16.11 to make it active.
![]() Select Principal Components from the red triangle menu next to Scatterplot 3D.
Select Principal Components from the red triangle menu next to Scatterplot 3D.
This adds three principal components to the variables list and creates a biplot with three rays corresponding to each of the variables, as shown in Figure 16.13.
The directions of the principal components are shown as rays from the origin of the point cloud. As you rotate the plot, you see that the principal component rays correspond to the directions in the data in decreasing order of variance. You can also see that the Principal Components form right angles in three-dimensional space.
The Principal Components report in Figure 16.13 shows what portion of the variance among the variables is explained by each principal component. In this example, 80% of the variance is carried by the first principal component, 18% by the second, and 2% by the third. It is the correlations in the data that make the principal components interesting and useful. If the variables are not correlated, then the principal components all carry the same variance.
Figure 16.13 Biplot and Report of Principal Components

Principal Components are also available from the Principal Components platform. Let’s repeat this analysis using this platform:
![]() Select Analyze > Multivariate Methods > Principal Components.
Select Analyze > Multivariate Methods > Principal Components.
![]() Again, assign 1-Octanol, Ether, and Carbon Tetrachloride to Y, Columns, and then click OK.
Again, assign 1-Octanol, Ether, and Carbon Tetrachloride to Y, Columns, and then click OK.
JMP displays the principal components and three plots, as shown in Figure 16.14.
Figure 16.14 Principal Components for Three Variables
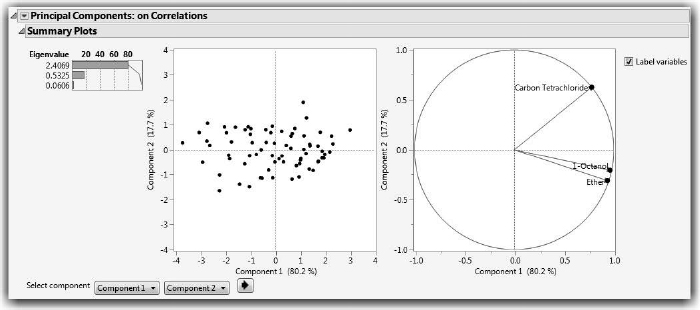
The Pareto plot (left) shows the percent of the variation accounted for by each principal component. As we saw earlier, the first principal component explains 80% of the variation in the data, while the second component accounts for 18%.
The middle score plot shows a scatterplot of the first two principal components. The first principal component accounts for far more variation (spread in the data) than the second component.
The loading plot (right) shows the correlations between the variables and the principal components. Carbon Tetrachloride is plotted by itself, while the other two variables are plotted together, indicating that they are correlated with one another. (We’ll talk more about this in the next section.)
Principal Components for Six Variables
Now let’s move up to more dimensions than humans can visualize. We return to the Solubility.jmp sample data, but this time we look at principal components for all six variables in the data table.
![]() Select Analyze > Multivariate Methods > Principal Components.
Select Analyze > Multivariate Methods > Principal Components.
![]() Assign the six solvent variables to Y, Columns and then click OK to see the results in Figure 16.15.
Assign the six solvent variables to Y, Columns and then click OK to see the results in Figure 16.15.
Figure 16.15 Principal Components for Six Variables

Examine the Pareto plot in Figure 16.15. Note that the first two principal components work together to account for 95.5% of the variation in six dimensions. To better see this, select Eigenvalues from the red triangle menu next to Principal Components.
Note the very narrow angle between rays for 1-Octanol and Ether in the loading plot (on the left). These two rays are at near right angles to the other four rays, which are clustered together. Narrow angles between principal component rays are a sign of correlation. Principal components try to squish the data from six dimensions down to two dimensions. To represent the points most accurately in this squish, the rays for correlated variables are close together because they represent most of the same information. Thus, the loading plot shows the correlation structure of high-dimensional data.

Recall the scatterplot matrix for all six variables (shown right). This plot confirms the fact that Ether and 1-Octanol are highly correlated, and the other four variables are also highly correlated with one another. However, there is little correlation between these two sets of variables.
How Many Principal Components?
In the solubility example, more than 95% of the variability in the data is explained by two principal components. In most cases, only two or three principal components are needed to explain the majority (80-90%) of the variation in the data.
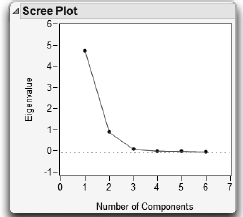
A scree plot can offer some guidance in determining the number of principal components required. Scree is a term for the rubble that accumulates at the bottom of steep cliffs, which this plot resembles. The place where the Scree Plot changes from a sharp downward slope to a more level slope (which is not always obvious) indicates the number of principal components to include.
![]() From the Principal Components Analysis report, select Scree Plot from the red triangle menu next to Principal Components.
From the Principal Components Analysis report, select Scree Plot from the red triangle menu next to Principal Components.
In the plot shown here, we can see that the plot levels out slightly after the second component, and is flat from the third component on.
Once you decide on the number of principal components needed, you can save the principal components to the data table.
![]() Select Save Principal Components from the red triangle menu next to Principal Components.
Select Save Principal Components from the red triangle menu next to Principal Components.
![]() Enter the desired number of principal components. The default is two.
Enter the desired number of principal components. The default is two.
![]() Click OK.
Click OK.
This creates new columns in the data table, which might be useful in subsequent analyses and graphs.
Note: You might also consider a simple form of factor analysis, in which the components are rotated to positions so that they point in directions that correspond to clusters of variables. In JMP, Factor Analysis is an option in the Principal Components platform. Factor Analysis is also available in the Consumer Research menu.
Discriminant Analysis
Both discriminant analysis and cluster analysis classify observations into groups. The difference is that discriminant analysis has known groups to predict; cluster analysis forms groups of points that are close together, but there is no known grouping of the points.
Discriminant analysis is appropriate for situations where you want to classify a categorical variable based on values of continuous variables. For example, you might be interested in the voting preferences (Democrat, Republican, or Other) of people of various ages and income levels. Or, you might want to classify animals into different species based on physical measurements of the animal.
There is a strong similarity between discriminant analysis and logistic regression.
● In logistic regression, the classification variable is random and predicted by the continuous variables.
● In discriminant analysis, the classifications are fixed, and the continuous factors are random variables.
However, in both cases, a categorical value is predicted by continuous variables.
Discriminant analysis is most effective when there are large differences among the mean values of the different groups. Larger separations of the means make it easier to determine the classifications.
The group classification is done by assigning a point to the group whose multivariate mean (centroid) is the closest, where closeness is with respect to the within-group covariance.
The example in this section deals with a trace chemical analysis of cherts. Cherts are rocks formed mainly of silicon, and are useful to archaeologists in determining the history of a region. By determining the original location of cherts, inferences can be drawn about the peoples that used them in tool making. Klawiter (2000) was interested in finding a model that predicted the location of a chert sample based on a trace element analysis. A subset of his data is found in the sample data table Cherts.jmp.
![]() Select Help > Sample Data Library and open Cherts.jmp.
Select Help > Sample Data Library and open Cherts.jmp.
![]() Select Analyze > Multivariate Methods > Discriminant.
Select Analyze > Multivariate Methods > Discriminant.
![]() Assign all the chemical names to Y, Covariates.
Assign all the chemical names to Y, Covariates.
![]() Assign location name to X, Categories, and then click OK.
Assign location name to X, Categories, and then click OK.
The discriminant analysis report consists of three outlines: the canonical plot, Discriminant Scores, and Score Summaries.
Note: The default discriminant method is Linear, which assumes a common covariance structure for all groups. Three other methods, Quadratic, Regularized, and Wide Linear, are also available. For details, select Help > JMP Help and refer to the Multivariate Methods book.
Canonical Plot
The canonical plot in Figure 16.16 shows the points and multivariate means in the two dimensions that best separate the groups. The term canonical refers to functions that discriminate between groupings. The first function, Canonical1, provides the most discrimination or separation between groups, and Canonical2 provides the second most separation.
Note that the biplot rays, which show the directions of the original variables in the canonical space, have been moved to better show the canonical graph. Click in the center of the biplot rays and drag them to move them around the report.
Figure 16.16 Canonical Plot of the Cherts Data

The canonical plot also displays the following items:
● the multivariate mean for each group
● a 95% confidence ellipse for the mean of each group (the inner ellipse)
● a 50% density ellipse for each group, encompassing approximately 50% of the observations
In this example, the multivariate means for Shakopee, Gran Grae, and Rushford are more separated from the cluster of locations near the center of the graph.
Discriminant Scores
The scores report shows how well each point is classified. A portion of the discriminant scores report for this example is shown in Figure 16.17. The report provides the actual classification, the distance to the mean of that classification, and the probability that the observation is in the actual classification. The histogram shows –log(prob), the loss in log-likelihood when a point is predicted poorly. When the histogram bar is large, the point is being poorly predicted. The last columns show the predicted group, the associated probability, and other predictions.
Figure 16.17 Portion of Discriminant Scores Report

The predictions for rows 8 and 14 are incorrect, notated by an asterisk to the right of the bar plot. To see why these rows were misclassified, examine them in the canonical plot.
![]() From the red triangle menu next to Discriminant Analysis, select Score Options > Select Misclassified Rows.
From the red triangle menu next to Discriminant Analysis, select Score Options > Select Misclassified Rows.
The result of this selection is shown in Figure 16.18.
Figure 16.18 Misclassified Rows

Row 8, although actually from Lake City, is very close to Gran Grae in canonical space. This closeness is the likely reason it was misclassified. Row 14, on the other hand, is close to Le Sueur, its actual value. It was misclassified because it was closer to another center, though this is not apparent in this two-dimensional projection of a seven-dimensional space.
Another quick way to examine misclassifications is to look at the Score Summaries report (Figure 16.19) found below the discrimination scores. The overall misclassification rate is summarized, and actual versus predicted classifications are provided for each category. Zeros on the non-diagonal entries indicate perfect classification. The misclassified rows 8 and 14 are represented by the 1s in the non-diagonal entries.
Figure 16.19 Counts Report

Stepwise Discriminant Variable Selection
In discriminant analysis, we are building a model to predict which group a row belongs in. But, all variables in the data set might not aid in classification. Stepwise variable selection determines which variables are useful, and allows us to build a model including only those variables.
JMP provides forward and backward variable selection. Select Stepwise Variable Selection from the red triangle menu next to Discriminant Analysis to see the figure shown here:
● In forward selection (Step Forward), each variable is reviewed to determine which one provides the most discrimination between the groups. The variable with the lowest p-value is added to the model. The model-building process continues step by step, until you choose to stop.
● In backward selection (Step Backward), all variables are added to the model, and variables that contribute the least to discrimination are removed one at a time.

For the model that you choose (click Apply this Model), the discriminant analysis is performed and misclassification rates can be compared to the full model. Note that you can save probabilities and predicted classifications for the selected model to the data table. Select Score Options > Save Formulas from the red triangle menu next to Discriminant Analysis.
The stepwise option is available from the Discriminant launch window, or from the red triangle menu in the Discriminant report.
Cluster Analysis
Cluster analysis is the process of dividing a set of observations into a number of groups where points inside each group are close to each other. JMP provides several methods of clustering, but here, we show only hierarchical clustering. Grouping observations into clusters is based on some measure of distance. JMP measures distance in the simple Euclidean way. There are many ways of measuring the proximity of observations. The essential purpose is to identify observations that are “close” to each other and place them into the same group. Each clustering method has the objective of minimizing within-cluster variation and maximizing between-cluster variation.
Hierarchical Clustering: How Does It Work?
Hierarchical clustering works like this:
● Start with each point in its own cluster.
● Find the two clusters that are closest together in multivariate space.
● Combine these two clusters into a single group centered at their combined mean.
● Repeat this process until all clusters are combined into one group.
This process is illustrated in Figure 16.20.
Figure 16.20 Illustration of Clustering Process

As a simple example, select Help > Sample Data Library and open SimulatedClusters.jmp.
![]() Select Analyze > Fit Y By X.
Select Analyze > Fit Y By X.
![]() Assign X to X, Factor and Y to Y, Response, and then click OK. The results are shown in Figure 16.21.
Assign X to X, Factor and Y to Y, Response, and then click OK. The results are shown in Figure 16.21.
Figure 16.21 Scatterplot of Simulated Data

In this example, data clearly clump together into three clusters. In reality, clusters are rarely this clearly defined. We’ll see a real life example of clustering later.
Let’s see how the Cluster platform handles clustering with this simulated data.
![]() Select Analyze > Clustering > Hierarchical Clustering.
Select Analyze > Clustering > Hierarchical Clustering.
![]() Assign both X and Y to Y, Response, and then click OK.
Assign both X and Y to Y, Response, and then click OK.
![]() For illustration purposes, select Dendrogram Scale > Even Spacing from the red triangle menu next to Hierarchical Clustering.
For illustration purposes, select Dendrogram Scale > Even Spacing from the red triangle menu next to Hierarchical Clustering.
The report appears as in Figure 16.22.
Figure 16.22 Dendrogram and Distance Graph

The top portion of the report shows a dendrogram, a visual tree-like representation of the clustering process. Branches that merge on the left join together iteratively to form larger and larger clusters, until there is a single cluster on the right.
Note the small diamonds at the bottom and the top of the dendrogram. These draggable diamonds adjust the number of clusters in the model.
The distance graph, shown beneath the dendrogram, is similar to the scree plot in principal components. This plot offers some guidance regarding the number of clusters to include. The place where the distance graph changes from a level slope to a sharp slope is an indication of the number of clusters to include. In this example, the distance graph is very flat up to the point of three simulated clusters, where it rises steeply.
To better see the clusters:
![]() From the red triangle menu next to Hierarchical Clustering, select both Color Clusters and Mark Clusters.
From the red triangle menu next to Hierarchical Clustering, select both Color Clusters and Mark Clusters.
This assigns a special color and marker to each observation, which changes dynamically as you change the number of clusters in the model. To see this:
![]() Drag the windows so that you can see both the Fit Y By X scatterplot and the dendrogram at the same time.
Drag the windows so that you can see both the Fit Y By X scatterplot and the dendrogram at the same time.
![]() Drag the number of clusters diamond to the right. Drag it to nine clusters, and then to six clusters. Observe the changes in colors and markers in the scatterplot.
Drag the number of clusters diamond to the right. Drag it to nine clusters, and then to six clusters. Observe the changes in colors and markers in the scatterplot.
![]() Move the diamond to three clusters. This should correspond to the point of the sharp rise in the distance graph.
Move the diamond to three clusters. This should correspond to the point of the sharp rise in the distance graph.
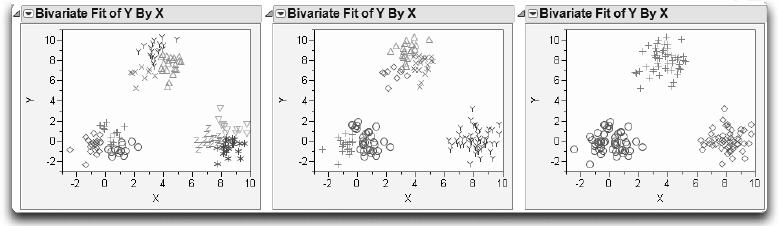
The scatterplot for nine, six, and three clusters should look similar to the ones in Figure 16.23.
Figure 16.23 Nine, Six, and Three Clusters
Once you decide that you have an appropriate number of clusters, you can save a column in the data table that holds the cluster number for each point.
![]() From the red triangle menu next to Hierarchical Clustering, select Save Clusters.
From the red triangle menu next to Hierarchical Clustering, select Save Clusters.
The cluster numbers are often useful in subsequent analyses and graphs, as we’ll see in the example to follow.
A Real-World Example
The sample data table Cereal.jmp contains nutritional information about a number of popular breakfast cereals. A cluster analysis can show which of these cereals are similar in nutritional content and which are different.
![]() Select Help > Sample Data Library and open Cereal.jmp.
Select Help > Sample Data Library and open Cereal.jmp.
![]() Select Rows > Clear Row States to remove the labels and markers.
Select Rows > Clear Row States to remove the labels and markers.
![]() Select Analyze > Clustering > Hierarchical Cluster.
Select Analyze > Clustering > Hierarchical Cluster.
![]() Select the Name column and assign it to Label.
Select the Name column and assign it to Label.
![]() Assign all of the nutritional variables, from Calories through Potassium, to Y, Columns, and then click OK.
Assign all of the nutritional variables, from Calories through Potassium, to Y, Columns, and then click OK.
When the dendrogram appears:
![]() Select Color Clusters and Mark Clusters from the red triangle menu next to Hierarchical Clustering.
Select Color Clusters and Mark Clusters from the red triangle menu next to Hierarchical Clustering.
By default, eight clusters are displayed. The distance graph (bottom of Figure 16.24) does not show a clear number of clusters for the model. However, there seems to be some change in the steepness at around six clusters.
![]() Drag the number of clusters diamond to the point corresponding to six clusters, as in Figure 16.24.
Drag the number of clusters diamond to the point corresponding to six clusters, as in Figure 16.24.
Figure 16.24 Dendrogram of Cereal Data

Examine the cereals classified in each cluster. Some conclusions based on these clusters are as follows:
● The all-bran cereals and shredded-wheat cereals form the top two clusters.
● Oat-based cereals, for the most part, form the third cluster.
● Cereals with raisins and nuts fall in the fourth cluster.
● Sugary cereals and light, puffed cereals form the last two clusters.
There are several built-in tools for exploring the clusters in the Hierarchical platform, including the cluster summaries, scatterplot matrix, and parallel coordinates plot. We encourage you to explore these options on your own.
You can also save cluster numbers to a column in the data table to help you gain additional insights into variables driving the clustering.
![]() Select Save Clusters from the red triangle menu next to Hierarchical Clustering.
Select Save Clusters from the red triangle menu next to Hierarchical Clustering.
The Graph Builder is a handy tool for graphically exploring the clustering (from Graph > Graph Builder). For example, in Figure 16.25, we can see that cereals in Cluster 1 tend to be low in calories and high in fiber. However, cereals in Cluster 5 tend to be low in both calories and fiber.
Figure 16.25 Exploring Clusters Using Graph Builder

Some Final Thoughts
When you have more than three variables, the relationships among them can get very complicated. Many things can be easily found in one, two, or three dimensions, but it is difficult to visualize a space of more than three dimensions.
The histogram provides a good one-dimensional look at the distribution, with a smooth curve option for estimating the density. The scatterplot provides a good two-dimensional look at the distribution, with normal ellipses or bivariate smoothers to study it. In three dimensions, Scatterplot 3D provides the third dimension. To look at more than three dimensions, you must be creative and imaginative.
One good basic strategy for high-dimensional exploration is to take advantage of correlations and reduce the number of dimensions. The technique for this is principal components, and the aim is to reduce a large number of variables to a smaller more manageable set that still contains most of the information content in the data.
Discriminant analysis and cluster analysis are exploratory tools for classifying observations into groups. Discriminant analysis predicts classifications based on known groups, whereas cluster analysis forms groups of points that are close together.
You can also use highlighting tools to brush across one distribution and see how the points highlight in another view.
The hope is that you either find patterns that help you understand the data, or points that don’t fit patterns. In both cases, you can make valuable discoveries.
Exercises
1. In the sample data table Crime.jmp, data are given for each of the 50 U.S. states concerning crime rates per 100,000 people for seven classes of crimes.
(a) Use the Multivariate platform to produce a scatterplot matrix of all seven variables. What pattern do you see in the correlations?
(b) Conduct an outlier analysis (using Mahalanobis distance) of the seven variables, and note the states that seem to be outliers. Do the outliers seem to be states with similar crime characteristics?
(c) Conduct a principal components analysis on the correlations of these variables. Which crimes seem to group together?
(d) Using the eigenvalues from the principal components report, how many dimensions would you retain to accurately summarize these crime statistics?
2. The sample data table Socioeconomic.jmp (SAS Institute, 1988) consists of five socioeco-nomic variables for twelve census tracts in the Los Angeles Standard Metropolitan Statistical Area.
(a) Use the Multivariate platform to produce a scatterplot matrix of all five variables.
(b) Conduct a principal components analysis (on the correlations) of all five variables. How many principal components would you retain for subsequent analysis?
(c) Using the loading plot, determine which variables load on each principal component.
3. A classic example of discriminant analysis uses Fisher’s Iris data, stored in the sample data table Iris.jmp. Three species of irises (setosa, virginica, and versicolor) were measured on four variables (sepal length, sepal width, petal length, and petal width). Use the discriminant analysis platform to make a model that classifies the flowers into their respective species using the four measurements.
4. The sample data table World Demographics.jmp contains mortality (for example, birth and death) rates for several countries. Use the cluster analysis platform to determine which countries share similar mortality characteristics. What do you notice that is similar among the countries that group together?
Save the clusters and then use the Graph Builder to explore the clustering. Summarize what you observe.