
Chapter 3: Item-Level Operations: Direct Access
3.2 SEARCH (Pure LookUp) Operation
3.2.1 Implicit Search: No Arguments
3.2.2 Explicit Search: Using the KEY Argument Tag
3.2.6 Search Operation Hash Tools
3.2.7 Search Operation Hash-PDV Interaction
3.3.1 Dynamic Memory Acquisition
3.3.3 Implicit INSERT: Method Call Mode
3.3.4 Implicit INSERT: Methods Other Than ADD
3.3.5 Implicit INSERT: Argument Tag Mode
3.3.8 Implicit vs Explicit INSERT
3.3.9 Unique Key and Duplicate Key INSERT
3.3.13 Insert Operation Hash Tools
3.3.14 INSERT Operation Hash-PDV Interaction
3.4.1 DELETE ALL Implementation
3.4.2 DELETE ALL and Item Locking
3.4.3 DELETE ALL Operation Hash Tools
3.4.4 DELETE ALL Operation Hash-PDV Interaction
3.5.2 Successful Direct RETRIEVE
3.5.3 Unsuccessful Direct RETRIEVE
3.5.4 Implicit vs Explicit FIND Calls
3.5.5 RETRIEVE Operation Hash Tools
3.5.6 RETRIEVE Operation Hash-PDV Interaction
3.6.1 UPDATE ALL Implementation
3.6.2 Assigned vs Unassigned REPLACE Calls
3.6.3 Implicit vs Explicit REPLACE Calls
3.6.4 Selective UPDATE Operation Note
3.6.5 UPDATE ALL Operation Hash Tools
3.6.6 UPDATE ALL Operation Hash-PDV Interaction
3.7.1 ORDER Operation Invocation
3.7.2 ORDERED Argument Tag Plasticity
3.7.3 Hash Items vs Hash Item Groups
3.7.4 OUTPUT Operation Effects
3.7.5 General Hash Table Order Principle
3.7.6 Ordering by Composite Keys
3.7.7 Setting the SORTEDBY= Option
3.7.8 ORDER Operation Hash Tools
3.7.9 ORDER Operation Hash-PDV Interaction
3.1 Introduction
In this chapter, we will concentrate on the item-level operations performed by direct key access to a hash table without the explicit need to read the table sequentially in one form or another.
3.2 SEARCH (Pure LookUp) Operation
The Search operation is used only to discover whether a given key is in the hash table - and to do nothing else. That is why it is also dubbed as pure look-up. The only hash tool supporting the operation is the CHECK method. It can be called in two ways: implicitly without the argument tag KEY coded in or explicitly with the argument tag KEY coded with an argument. Let us consider these two modes separately.
3.2.1 Implicit Search: No Arguments
Suppose that H is the hash table defined with variable K in the key portion and variable D in the data portion. Correspondingly, as required by parameter type matching principle, we have host variables named K and D in the PDV.
Now suppose that we want to find out whether the current PDV value of host variable K exists in table H without affecting any data values in the PDV. In particular, we do not want any value of D in the table to affect the current value of its PDV host variable D. In other words, we need to merely search the table and do nothing else. The way to do it is to call the CHECK method designed specifically for such "pure look-up" purpose:
RC = H.CHECK() ;
For example, if, as SAS reads through a data set with variable K and its value in the current observation K=3, the CHECK method will return a return code of 0 (RC=0) if one or more items in the hash table has K=3. If RC=0, the key is in the table; otherwise, the method returns a non-zero, non-missing value. Therefore, if we want to predicate some programming actions on whether the key is in the table, we can code:
if RC = 0 then do ;
<program actions for PDV value of K found the table> ;
end ;
Or, if we want to create a Boolean 0/1 variable (Have_key, say) to indicate search success or failure, we can use any of the following code variations:
Have_key = (RC=0) ;
Have_key = not RC ;
Have_key = ifN (RC=0, 1, 0) ;
Since Search is a key-based operation, the question arises how the CHECK method call knows which key-value(s) to look for. The answer is that if it is coded implicitly, as above, it automatically accepts the values from the key host variables currently in the PDV.
3.2.2 Explicit Search: Using the KEY Argument Tag
Most of the time, calling CHECK without arguments and thus letting it infer the key to look for from the PDV host variable(s) is what is needed. However, calling it with the KEY argument tag can be much more flexible.
Suppose, for example, that we need to check if K=3 is in the table when we do not know the current value of host variable K and do not want to modify it. To call CHECK without arguments, we would need to first assign 3 to the host variable K. However, to preserve the current value of K, we would have to engage in cumbersome gymnastics of memorizing it and assigning it back:
_K = K ;
K = 3 ;
rc = H.CHECK() ;
K = _K ;
It is much simpler to achieve the same goal by using the KEY argument tag:
rc = H.CHECK(KEY:3) ;
This way, we can establish whether K=3 is in the table, leaving the current PDV value of K intact. It also results in much cleaner code and makes it more efficient by avoiding the unnecessary reassignments.
Even more flexibility in using the argument tag comes from the principle that the argument tags accept general SAS expressions as arguments and not necessarily literals. In KEY:3 above, 3 is a numeric literal, the simplest of expressions. Suppose that for some numeric variable V we want to know if table H contains a key with value V+1. Again, instead of modifying the host value K first, we can just code:
rc = H.CHECK(KEY:sum (V,1)) ;
3.2.3 Argument Tag Type Match
The data type of an expression assigned to an argument tag must match the data type it expects. For instance, the data type expected by the argument tag KEY, above, is defined by the type of hash key variable K with which the object is defined - in this case, it is numeric. Assigning a character expression to it will result in the "Type mismatch" run-time error, e.g.:
rc = H.CHECK(KEY:"3"); * Incorrect! Type mismatch;
Note that the call will not attempt to automatically convert "3" (a SAS character string) into 3 (a SAS number) using the BEST. format, as it would in hash-unrelated code. It will just fail. The same would happen if K were of the character type and a numeric expression were assigned to the argument tag.
Matching argument tag types is a general principle that must be borne in mind every time an argument tag (or a statement or operator parameter argument) is used.
3.2.4 Assigned CHECK Calls
When H.CHECK() is assigned to a separate variable as it was done above:
RC = H.CHECK() ;
the call, obviously, is assigned and its return code is captured in RC. Such assigned call generates no errors or error messages in case it fails, i.e., if the key is not found in the table. The return code can be captured because H.CHECK() is a numeric expression: It resolves to a numeric value, and that is the value assigned to RC.
But in SAS, a numeric expression can be part of a statement or any other numeric expression. In such cases, the value to which it resolves is still captured in the internal buffer and then used in whatever statement or expression it is part of. Therefore, instead of being assigned to a separate variable like RC first, H.CHECK() can be used directly as an expression in its own right. For example:
if H.CHECK() = 0 then do ;
<program actions for PDV value of K found the table> ;
end ;
Likewise, it can be used directly in the Boolean expressions shown earlier (or any other numeric expressions, for that matter). For example:
Have_key = (H.CHECK()=0) ;
In all these cases, where the return code value to which the H.CHECK() expression resolves gets captured, it is in fact physically assigned, be it to a separate variable like RC or internally. And in all these cases, no errors or error messages are generated if the CHECK call fails- i.e., if the key is not found in the table. This is why we classify any call whose return code is captured in one way or another as assigned. As we will see in the next section, unassigned calls whose return codes are not captured behave differently.
3.2.5 Unassigned CHECK Calls
The CHECK method can be also called unassigned without capturing its return code either in a separate variable or internally as part of a statement or expression:
H.CHECK() ;
However, though such a stand-alone (or naked) call is syntactically valid, it makes no sense to use it with the CHECK method for the following reasons:
● The only information sought from the Search operation is whether it is a success (the key is in the table) or failure (the key is not in the table).
● The CHECK method does nothing except provide its return code information. Hence, without looking at it, there is no reason whatsoever to call CHECK in the first place.
● A failed unassigned call results in the error message in the log "Key not found".
Note that a failed unassigned call does not cause the DATA step to stop processing. However, for each failed call, it writes the error message in the log. In many real-world situations where failed CHECK calls may number in millions, this behavior is not only bothersome, especially if SAS is run in the interactive mode, but can overfill the log with useless error messages.
The takeaway is that the CHECK method should always be called assigned - either by assigning it to a separate variable or by making it part of a statement or expression. Not coincidentally, this is true for any method whose failure does not cause the DATA step to stop immediately after a failed call since further programming actions can be based on whether the method call has succeeded or failed.
3.2.6 Search Operation Hash Tools
● Methods: CHECK.
● Argument tags: KEY.
3.2.7 Search Operation Hash-PDV Interaction
● Implicit call: The key values to search for are accepted from the current PDV values of the host key variables.
● Explicit call: None.
3.3 INSERT Operation
The very purpose of a hash table is to contain keys and data to be efficiently manipulated and/or compared to values outside the table. Thus, the utility of the Insert operation is critical: As its name implies, it inserts items into the table. The hash object is packaged with a variety of tools and options to facilitate this operation and control its behavior in terms of handling hash items with duplicate key-values.
3.3.1 Dynamic Memory Acquisition
Before the advent of the hash object, the only way to implement a memory-resident lookup table in the DATA step was to use an array. However, since the memory needed to house an array is acquired at compile time, the number of its elements (i.e., its dimension) and memory footprint cannot be determined at run time. Hence, the array dimension has to be either calculated beforehand (usually at the expense of another pass through the data) or selected using the iffy "big enough" principle.
In this sense, the hash object represents a radical departure in behavior. Regardless of the tool performing the Insert operation, the extra memory for each item added to the table is acquired separately, at run time. In other words, the table grows dynamically as the items are inserted (and, as we will see later, also shrinks dynamically as they are removed).
This way, we can have a fully functional memory-resident table without the need to determine its size ahead of time. Moreover, the hash attribute NUM_ITEMS is adjusted automatically behind-the-scenes with every item inserted into or deleted from the table and can be used to return the current number of table items at any time.
3.3.2 Implicit INSERT
Implicit Insert occurs in two modes:
1. Calling a hash object method actuating the operation (e.g., ADD) implicitly (i.e., without the argument tags). Let us call it the "method call mode".
2. Inserting the items from a SAS data file by giving its name to the DATASET argument tag. Let us call it the "argument tag mode".
3.3.3 Implicit INSERT: Method Call Mode
This mode of the implicit Insert operation is typically activated by a method call like this:
RC = H.ADD();
Note the absence of content between the parentheses. Since the call is used without the available argument tags KEY and DATA, a question arises: Which key and data values are used for the item being added to table H? The answer is that, in this case, the method automatically accepts the current values of the corresponding PDV host variables. In this snippet, a (K,D) item with values (1,A) is inserted into table H:
Program 3.1 Chapter 3 Implicit Method Call Mode Insert.sas
data _null_ ;
dcl hash H () ;
H.definekey ("K") ;
H.definedata ("D") ;
H.definedone() ;
K = 1 ;
D = "A" ;
rc = H.ADD() ;
run ;
If there is a need to add more (K,D) items, the statements in bold can be repeated with other (K,D) values either explicitly or in a loop. For example, to load (K,D) pairs with values (1,A), (2,B), (3,C) consecutively, we could replace the lines in bold above with the following:
do K = 1 to length ("ABC") ;
D = char ("ABC", K) ;
rc = H.ADD() ;
end ;
The implicit Insert operation is also convenient when a hash table is loaded from a data file (i.e., a SAS data file or an external file via the INPUT statement). This is because in this case, new host variable values are placed into the PDV automatically every time the next record is read in. Suppose we want to create a hash table from Bizarro.Player_candidates (for example, intending to search for Position_code by Player_ID):
Program 3.2 Chapter 3 Implicit Method Call Mode Insert from a File.sas
data _null_ ;
dcl hash H () ;
H.definekey ("Player_ID") ;
H.definedata ("Player_ID", "Position_code") ;
H.definedone() ;
do until (lr) ;
set bizarro.Player_candidates end = lr ;
rc = H.ADD() ;
end ;
H.output (dataset: "Players") ; *Check content of H;
stop ;
run ;
Every time a new record is read in, the pair of values (Player_ID, Position_code) from it is moved to the PDV, and from there they are implicitly consumed by the ADD method call. (The only purpose of the OUTPUT call above is diagnostic, i.e., to check the hash table content.)
3.3.4 Implicit INSERT: Methods Other Than ADD
The ADD method is not the only one available to actuate the implicit Insert operation. The two other methods, REF and REPLACE, can also be called implicitly to insert items into a hash table. As far as implicit calls are concerned, their actions are similar to ADD in the sense that they also infer the key and data values to be inserted from the current values of the corresponding PDV host variables. In other respects, their actions differ from those of ADD:
● If duplicate-key items are allowed in the table, the ADD method inserts a new item unconditionally, regardless of whether the key-value it accepts is already in the table or not.
● By contrast, the REF method inserts a new item only if the key-value it accepts is not already present in the table, irrespective of whether duplicate-key items are allowed or not.
● The ability of the REPLACE method to insert an item is a side effect of its primary function of updating the data portion variables. Namely, if the key is not in the table, there is nothing to update; hence, a new item is inserted. Other details of the REPLACE method's behavior will be discussed later on in the appropriate sections.
3.3.5 Implicit INSERT: Argument Tag Mode
This mode of the implicit Insert operation is related to loading a table from a SAS data file, whose name is specified as a character expression assigned to the argument tag DATASET. It can be done regardless of whether the DECLARE|DCL statement or the _NEW_ operator is used to instantiate the table. Suppose, for example, that we intend to load the table from the Bizarro.Player_Candidates data set. If the declaration and instantiation are combined, in order to implicitly load the values from the data set into the table, we can code:
dcl hash H (DATASET: "bizarro.Player_candidates") ;
Or, in the case when the declaration and instantiation are separated:
dcl hash H ;
H = _new_ hash (DATASET: "bizarro.Player_candidates") ;
This insertion mode is obviously implicit because no method to trigger the Insert operation is called explicitly. However, what occurs with this input mode behind the scenes is exactly identical to the implicit Insert operation done by reading the file one record at a time and calling the ADD method for each item to be inserted. Hence, the snippet below populates table H with the same content as the ADD method used above to read the file in the DO loop:
Program 3.3 Chapter 3 Implicit Argument Tag Mode Insert from a File.sas
data _null_ ;
dcl hash H (dataset: "bizarro.Player_candidates") ;
H.definekey ("Player_ID") ;
H.definedata ("Player_ID", "Position_code") ;
H.definedone() ;
H.output (dataset: "Players") ; *Check content of H;
stop ;
set bizarro.Player_candidates (keep = Player_ID Position_code) ;
run ;
Note that above, the SET statement serves to place the host variables into the PDV at compile time. Without it (or another valid means of parameter type matching), the DEFINEDONE method call will fail. Coding SET after STOP ensures that it reads no actual data from bizarro.Player_candidates at run time, letting the compiler read its descriptor at compile time.
Which mode of the implicit Insert operation to select when the key and data values to be inserted come from a data file is dictated by both convenience and utility. Their relative advantages and disadvantages by feature are presented below:
Table 3.1 Implicit INSERT Method Call Mode vs Argument Tag Call Mode

3.3.6 Explicit INSERT
The implicit Insert operation relies on the current values of the PDV host variables for its input. However, there are situations when we want to load a key or data value which is the result of an expression. To achieve that using Insert via an implicit method call, the expression must first be assigned to the PDV host variable in question.
For example, suppose that before loading the pair (Player_ID, Position_code) into table H, we need to increment Player_ID up by 1. Using an implicit ADD call, we could code:
Player_ID = sum (Player_ID, 1) ;
rc = H.ADD() ;
Such an approach, while certainly doable, presents a problem: The current PDV value of Player_ID has thus been altered, while we may want to preserve it. Doing so while keeping Insert implicit involves more code and unsightly variable reassignment gymnastics. For instance:
_Player_ID = Player_ID ;
Player_ID = sum (Player_ID, 1) ;
rc = H.ADD() ;
Player_ID = _Player_ID ;
drop _Player_ID ;
Moreover, if the DATASET argument tag is used for implicit Insert, the subterfuges shown above cannot be used, for the table can be loaded only with the values as they come from the input file.
Thankfully, all hash methods supporting the Insert operation are furnished with the argument tags KEY and DATA, both of which accept SAS expressions as arguments (just as any other hash argument tag, for that matter). Therefore, instead of resorting to the kludge used above, we can simply code:
rc = H.ADD(KEY:sum(Player_ID, 1), DATA:Position_code) ;
Such an explicit Insert operation - that is, calling a hash method with its valued argument tags - provides a wide range of run-time flexibility. This is because the expression assigned to an argument tag can be any valid SAS expression. For example, it can include references to array items, formats, informats, functions, or be a mere literal, such as 1 or "A".
The only limitation imposed on the expression is that it must be of the data type the argument tag expects (in the specific position where it is listed. See the next section). In this respect, it is important to remember that:
● The data type the KEY or DATA argument tag expects is determined by the data type of the host variable of the hash variable for which the argument tag is used.
● Non-scalar data types, such as hash and hash iterator, cannot be used with the KEY argument tag because the key portion can contain only scalar variables.
● Hash object method calls do not provide for automatic data type conversions. Hence, if the expression is not of the expected data type, the method call will fail.
3.3.7 Explicit INSERT Rules
Implicit and explicit method calls cannot be mixed. In the example above, coding the DATA argument tag cannot be omitted with the assumption that the value of Position_code will be inferred from the PDV host variable, as it happens in an implicit call. Leaving it out will cause the method to fail.
This behavior corresponds to a general rule for explicit method calls: The number of argument tags and the data types of the arguments assigned to them must coincide exactly with the number and data types of the key and data portion hash variables defined to the hash object instance.
As an example, suppose that we have a hash table X defined with the following hash variables and in the following order:
1. Key portion: KN (numeric), KC (character).
2. Data portion: DN (numeric), DC (character).
Then an exlicit call to the ADD method must be of the form:
X.ADD(KEY: <numeric expression for KN>
,KEY: <character expression for KC>
,DATA: <numeric expression for DN>
,DATA: <character expression for DC>
)
The KEY and DATA argument tags in the list do not necessarily have to be grouped together as above. However, their relative sequence must mirror the relative sequence in which the key and data portion variables, respectively, are defined. In other words, in our case, the expression for KN must precede that for KC; and the expression for DN must precede that for DC. Thus, this form of the ADD call is also correct:
X.ADD(DATA: <numeric expression for DN>
,KEY: <numeric expression for KN>
,DATA: <character expression for DC>
,KEY: <character expression for KC>
)
It is also important to remember that none of these argument tag assignments can be omitted without failing the call. Any attempt to do so will result in an error message to the effect that the number of the key or data variables is incorrect.
From our geek perspective, it might be regrettable that a method cannot be called part-explicitly and part-implicitly. In other words, it would be nifty to be able to value only the argument tags we want and imply the rest of the inserted values from the host variables. However, c'est la vie. Hence, if the hash entry contains many variables and we want to alter just a few before insertion, it may be less fuzzy to use an implicit call after assigning the needed values to their PDV host variables accordingly (and add some variable reassignment or renaming code to preserve the PDV values if needed).
3.3.8 Implicit vs Explicit INSERT
As we have seen, both styles have their respective advantages. We will see numerous examples of using both further in the book. Choosing one over the other is dictated by the programmatic situation and, to a certain degree, by personal preferences. But whatever the choice, together they provide all the tools needed to load a hash table from any imaginable data source.
3.3.9 Unique Key and Duplicate Key INSERT
The Insert operation, regardless of the tools used, always begins behind the scenes with the Search operation to determine whether the key for the item to be inserted is already in the table. After that, the actions of the Insert operation depend on the hash object definition specifications and the tool used to perform the operation.
The Insert operation can be performed in two principal ways geared toward different data processing tasks:
1. Unique Insert. Duplicate key items are prohibited. This is the default behavior, which occurs if the MULTIDATA argument tag (a) is not used at all or (b) is used with an argument other than "YES"|"Y".
2. Duplicate Insert. Duplicate key items are allowed. This mode occurs if the MULTIDATA argument tag is coded in the statement creating the hash object instance and values as "YES"|"Y".
Unique Insert is useful when we want the uniqueness of the keys loaded into a hash table to be automatically enforced by the hash object without having to code for it explicitly. For example, if we want to unduplicate the keys on input or produce aggregates for each unique key, letting the object reject duplicate-key items all by itself is the obvious choice.
Duplicate Insert is unavoidable in many practical situations when we need to load a hash table with duplicate-key items and have the capability to manipulate them within any same-key item group. For example, we may want to enumerate the group of items with a given key to extract their data. Or we may need to delete or update some items in the group selectively. The hash object offers a set of tools designed to handle items with duplicate keys in a number of ways.
Let us now consider the unique and duplicate Insert operation modes separately.
3.3.10 Unique INSERT
When the MULTIDATA argument tag is not specified or specified but valued with anything but "Y"|"YES", we let the hash object handle the duplicate rejection process according to its internal rules. In this case, questions arise:
1. Which input instance of a duplicate key does the Insert operation keep in the table?
2. How does the hash object respond and what, if any, errors does it generate if an attempt to insert a duplicate key item is made?
To illustrate more tangibly what these questions mean, suppose that table H is defined as:
dcl hash H () ;
H.definekey ("K") ;
H.definedata("D") ;
H.definedone() ;
and that our table H input consists of the following key and data value pairs:

If duplicate-key items are filtered out overtly using BY-group programming logic, any of the three input pairs above can be selected. But if we do not code MUTIDATA:"Y" and thus let the hash object handle duplicate-key input all by itself, we will see that it has its own rules with respect to (a) which input occurrence is selected and (b) how it reacts to an attempt to insert a duplicate-key item in terms of error generation and messaging.
First of all, when the hash object is left to its own devices in the unique Insert mode, it chooses either the first or the last duplicate-key input occurrence. In other words, with our sample three-record input above, either the (A,1) or (A,3) value pair is selected depending on the particular tool used in the Insert operation. Let us see how different tools handle the situation.
● The ADD method:
∘ The first duplicate-key input occurrence is kept.
∘ If ADD is called unassigned, an error message "ERROR: Duplicate key" is written to the log for every duplicate-key occurrence rejected (which can be quite pesky). However, automatic variable _ERROR_ is not set to 1, the step is not stopped, and the table load process proceeds till completion.
∘ If ADD is called assigned, no errors or error messages are generated.
● The REF method:
∘ The first duplicate-key input occurrence is kept.
∘ The REF method internal logic is "If the key is not in the table, insert; else ignore".
∘ No errors or error messages are generated regardless of whether REF is called assigned or unassigned.
∘ In this sense, calling REF is exactly equivalent to calling ADD assigned.
● The REPLACE method:
∘ The last duplicate-key input occurrence is kept.
∘ Due to the way REPLACE works, this is actually not a result of rejecting duplicate input keys. Rather, it is a result of overwriting the data portion values with new ones every time REPLACE is called with a key already present in the table.
∘ REPLACE inserts an item only once, when the key it accepts is not yet in the table. Every ensuing call with the same key-value repeatedly overwrites the data values already stored. So at the end of the process it appears as if the last duplicate-key input occurrence was inserted.
∘ No errors or error messages are generated regardless of whether REPLACE is called assigned or unassigned.
● Input from a data file specified to the DATASET argument tag:
∘ If the DUPLICATE argument tag is not also specified, the first duplicate-key input occurrence is kept. No errors or error messages are generated.
∘ If the DUPLICATE argument tag is coded with the "REPLACE"|"R" argument, the last duplicate-key occurrence is kept. No errors or error messages are generated in this case, either.
∘ If the DUPLICATE argument tag is coded with "ERROR"|"E" argument, an attempt to insert a duplicate-item causes the DATA step to be immediately terminated. No further statements are executed, and an error message is written to the log.
3.3.11 Duplicate INSERT
In this mode, i.e., if MULTIDATA:"Y" is specified, the Insert operation is always successful regardless of the tool - provided, of course, that it is used correctly. The latter means, for example, using correct syntax and the number of the argument tags and the expected data types for their arguments. Therefore, in the duplicate Insert mode, we need not be concerned with any errors or warnings when an attempt is made to insert a duplicate-key item. Nor is there any difference, in this regard, between assigned and unassigned calls. (In fact, it may be better to leave them unassigned since it helps reduce unnecessary code clutter.) Also, in this mode, there is no reason nor need to use the DUPLICATE argument tag: Since duplicates are permitted, it has no effect.
However, with respect to the duplicate Insert mode not all tools are created equal. Moreover, their effects depend on whether SAS 9.4 or earlier is used. Again, we can look at the similarities and differences all at once:
Table 3.2 Duplicate-Key INSERT Operation Actions

To illuminate the differences of the REPLACE method duplicate-key behavior before and as of SAS 9.4, suppose that a hash table is already loaded with the following items for key K="A":

Now if we call the REPLACE method with the (K,D) values of (A,4) running SAS 9.4, all the items whose K="A" will be updated with the value of D=4:

If we are running a version before SAS 9.4, the items will not be updated. Instead, an item with (K,D)=(A,4) will be inserted in the table:

3.3.12 Insertion Order
From the programming perspective, the logical order of the items in a hash table is the only order that matters. As already mentioned above, this is the order in which they are written out by the OUTPUT method or accessed by the Enumerate operation. This way, we know how to determine the logical order of the hash table items in the table after they have been inserted.
But it raises an interesting question: Can we predict the order in which the hash items will be inserted before it has actually happened? The answer is "yes" and "no", or rather "it depends". Still, there are rules:
● If the table is not explicitly sorted in ascending or descending key-value order via the argument tag ORDERED, the relative order in which the same-key item groups follow each other is random. In particular, it means that if the table is operated in the unique-key mode, i.e., with 1 item per same-key group, the order of its individual items in the table is random.
● Otherwise, the same-key groups follow each other in key-value order specified by the argument of the ORDERED argument tag.
● Within each same-key item group, the relative sequence order is exactly the same in which the items are received from input. This is true regardless of whether the table is ORDERED or not.
These rules can be easily verified by running the code snippet below. In it, the argument of ORDERED is varied from "N" (undefined order) to "A" (ascending) to "D" (descending); and the argument of MULTIDATA is varied from "Y" to "N". Each time, table H is re-created and reloaded, and its content is output to a separate data set named using the six combinations of the above values:
Program 3.4 Chapter 3 Insertion Order Demo.sas
data _null_ ;
do dupes = "Y", "N" ;
do order = "N", "A", "D" ;
dcl hash H (multidata: dupes, ordered: order) ;
H.definekey ("K") ;
H.definedata ("K", "D") ;
H.definedone () ;
do K = 2, 3, 1 ;
do D = "A", "B", "C" ;
rc = h.add() ;
end ;
end ;
h.output (dataset:catx ("_", "Hash", dupes, order)) ;
end ;
end ;
run ;
As a result, we have 6 output data sets mirroring the content of 6 hash tables created with 2 MULTIDATA and 3 ORDERED argument tag choices, automatically named as follows:
Table 3.3 Data Set Names for Different MULTIDATA and ORDERED Arguments

Of note in this example is our use of expressions to create the various alternatives and to name the output data sets to indicate to which combinations they correspond. We need not modify hard-coded values (or use macro language logic) to generate the alternatives. In the table below, the contents of these data sets (i.e., also the content of the corresponding hash tables) are shown side by side:
Table 3.4 Hash Table Order for Different MULTIDATA and ORDER Arguments


For MULTIDATA:"Y", i.e., when duplicate-key items are allowed, it shows that if table H is left unordered, the item groups with K=(2,1,3) follow each other in some random order, different from the input order in which the keys are received, i.e., K=(2,3,1). However, within each same-key group, the items follow each other exactly in the order they are received from input, i.e., D=(A,B,C). It also shows that ordering the table via the ORDERED argument tag causes the same-key items groups as a whole to be permuted into required order by key. The sequence of items themselves within each same-key group remains intact and always mirrors their input sequence regardless of the table order.
For MULTIDATA:"N" (equivalent to omitting it altogether), the duplicate-key items are rejected. Note that the relative order of the same-key groups by table key is the same as before, except that now each group contains one item only. This is the item D="A" received from the input first because the ADD method was used. Using the REPLACE method would result in keeping the last input item, D="C", instead.
The randomizing default behavior of the Insert operation is due to the fact that the hash function used behind the scenes to place the keys in the table is random by nature. Though it can be, at a certain angle, viewed as unwelcome, it has useful applications we will see in this book later on.
3.3.13 Insert Operation Hash Tools
● Methods: ADD, REPLACE, REF.
● Arguments Tags: DATASET, DUPLICATE, ORDERED.
3.3.14 INSERT Operation Hash-PDV Interaction
● Implicit Insert: The key portion and data portion values are populated from their PDV host variables counterparts.
● Explicit Insert: None.
3.4 DELETE ALL Operation
The Delete All operation is just the opposite of Insert:
● If a given key-value is in the table, it deletes all the items with this key-value. In other words, it eliminates the entire group of items sharing the key.
● If the table is constrained to unique keys only, every same-key item group contains just one item, and so this is the item that gets deleted. Otherwise, if duplicate-key items are allowed, the whole group of items with this key is deleted, whether it includes a single item or more.
● For every item deleted from the table, memory occupied by it is released and the value of the NUM_ITEMS attribute is automatically decremented by 1.
The operation can facilitate data processing in many ways. To mention just a couple:
● We can eliminate the items whose keys are deemed by programming logic "already used" and no longer needed for the purposes of other operations, such as Search, Retrieve, or Enumerate. Also, the operation comes in handy when hash tables are used to join data and some items need to be removed prior to performing the join.
● Thanks to its dynamic nature, Delete All coupled with Insert can be used to implement run-time dynamic structures, such as stacks, queues, etc. Examples of constructing them are offered in the book later on.
Let us now look at the implementation of the Delete All operation using hash object tools.
3.4.1 DELETE ALL Implementation
The Delete All operation is supported by the REMOVE method. In the snippet below, table H is populated with 3 items with the following (K,D) key-data pairs: (1,A), (2,B), (2,C). Note that the last 2 items share the same key-value, K=2. After the table is loaded, the REMOVE call deletes both items with K=2 (the current PDV value of K), so that only the pair (1,A) remains in the table:
Program 3.5 Chapter 3 Removing an Item.sas
data _null_ ;
dcl hash H (multidata:"Y") ;
H.definekey ("K") ;
H.definedata("D") ;
H.definedone() ;
do K = 1, 2, 2 ;
q + 1 ;
D = char ("ABC", q) ;
rc = H.add() ;
end ;
rc = H.REMOVE() ; *implicit/assigned call
run ;
The key and data content that the ADD method above loads in table H is as follows:

After the REMOVE method is used, the table H content looks as follows:
![]()
Note that at the time of the REMOVE call, the value of key host variable is K=2. Since the call is implicit (no argument tags are used), this is the key value accepted by the method. And since the key is in the table,
the call is successful, so the entire group of items with K=2 gets deleted. In this case, any of the following alternative REMOVE calls would achieve the same result with no errors:
H.REMOVE() ; * implicit, unassigned ;
rc = H.REMOVE(key: 2) ; * explicit, assigned ;
H.REMOVE(key: sum(_N_,1)) ; * explicit, unassigned ;
Let us make a few germane observations:
● Since the calls are successful (the key is in the table), they can be left unassigned.
● The last line works because at the time of call _N_=1.
● In fact, any expression assigned to the KEY argument tag in an explicit call will work here as long as it is of the numeric data type (because K is compiled as numeric) and resolves in 2.
● If MULTIDATA:"Y" were not coded, the only change would be that, for K=2, only the (K,D)=(2,B) item would be inserted in table H due to the unique key constraint. Therefore, only this item would be deleted.
A different picture emerges if the method is given a key that is not present in the table. For example:
K = 3 ; rc = H.REMOVE() ; * assigned call - no error ;
K = 5 ; H.REMOVE() ; * unassigned call - error! ;
rc = H.REMOVE(key:7) ; * assigned call - no error ;
H.REMOVE(key:7) ; * unassigned call - error! ;
Again, a couple of notes are due:
● Since none of the keys used above is in the table, all these calls fail, and so no items are deleted.
● If a failing call is left unassigned, the step will stop processing with an error message.
Hence, a general safety rule: If a method can fail, it should never be called unassigned. Either assign it to a variable to hold its return code or include it in another statement - for example, a conditional clause. (The REMOVE method is one of the methods that can fail - in contrast to such methods as REPLACE or REF, which never fail due to their design.)
3.4.2 DELETE ALL and Item Locking
There exists a scenario under which an item group (including a single-item group) cannot be deleted by calling the REMOVE method, even if the key-value that it is called with is in the table. Namely, it happens when the item group targeted for deletion is locked by a hash iterator linked to the table. Since this phenomenon is associated with the Enumerate All operation, the issue and ways to deal with it will be discussed in detail in the next chapter.
3.4.3 DELETE ALL Operation Hash Tools
● Methods: REMOVE.
● Argument tags: KEY.
3.4.4 DELETE ALL Operation Hash-PDV Interaction
● An implicit REMOVE call accepts the current key values from the PDV host key variables.
● None. If the operation is successful, the corresponding item or items are merely deleted from the table. Neither PDV host variables nor hash variables change their values.
3.5 RETRIEVE Operation
The Retrieve operation extracts the values of the data portion variables from the hash table into their corresponding host variables in the PDV. Retrieve is quite an important part of hash object programming since it is an integral component of such data processing tasks as data aggregation, joining tables, and a host of others.
In fact, in many cases Retrieve is done behind the scenes even when it is not performed directly. This is because it is indirectly invoked during the Enumerate operation. We ought to be cognizant of it to ensure that the values of PDV host variables get overwritten only when this is part of the intent and programming logic. We will leave these behind-the-scenes actions for the section where the Enumerate operation is reviewed later on. In this section, we will discuss the direct Retrieve operation only.
3.5.1 Direct RETRIEVE
Direct Retrieve is invoked by calling the FIND method. It triggers the following sequence of actions:
● Given a value of the table key, search the table for it.
● If the key is in the table: Extract the values of all data portion hash variables for the item with this key into the respective PDV host variables, overwriting their values. Generate a zero return code to indicate that the call is successful.
● If the key is not in the table: Generate a non-zero return code to indicate that the call has failed. If the call is unassigned, write an error message in the log to the effect that the key is not found.
Note that if the key is not found, the values of the PDV host variables remain unchanged- i.e., the same as before the method call.
To illustrate these Retrieve actions in the SAS language, we can use the same table H as in the example above, populated with the (K,D) tuples (1,A), (2,B), (2, C) in the following snippet:
Program 3.6 Chapter 3 Direct Explicit Assigned Retrieve.sas
data _null_ ;
dcl hash H (multidata:"Y") ;
H.definekey ("K") ;
H.definedata("D") ;
H.definedone() ;
do K = 1, 2, 2 ;
q + 1 ;
D = char ("ABC", q) ;
H.add() ;
end ;
D = "X" ; *pre-call value of PDV host variable D;
RC = H.FIND(KEY:1) ;
put D= RC= ;
run ;
3.5.2 Successful Direct RETRIEVE
The step, as shown above, prints the following in the SAS log:
D=A RC=0
This demonstrates the effect of the successful direct Retrieve operation: Since K=1 is found in the table, RC=0 and the value of hash variable D="A" from the hash item with K=1 overwrites the original value "X" of PDV host variable D.
If, instead of using the FIND call with key-value 1, we key it with 2, the operation will be also successful because K=2 is in the table as well. For example, any of the following calls will work:
RC = H.FIND() ; *Implicit, K=2 accepted from PDV;
RC = H.FIND(KEY: 2) ; *Explicit, 2 is a numeric literal;
RC = H.FIND(KEY: _N_+1) ; *Explicit, _N_+1 resolves to 2;
In both cases, the PUT statement prints in the log:
D=B RC=0
Evidently, the original PDV value D="X" is overwritten with "B" - that is, with the data value from the item (2,B). However, it raises a question: The table has another item with K=2, (2,C), so why is (2,B) chosen? The answer is that if a group of same-key items has more than one item, a call to FIND with this key always points to the logically first item in the group. To recap, the logically first item within any same-key item group is the one inserted first, and in this case, it is (2,B).
Direct Retrieve, via the FIND method, can perform the operation only for the logically first item in a same-key group. In order to get to the rest of the items in the group and retrieve their data, the group has to be enumerated, which involves hash tools other than FIND. They will be reviewed in the section devoted to the Enumerate operation.
3.5.3 Unsuccessful Direct RETRIEVE
Suppose that the FIND call used in the step above is replaced with one of the following:
K = 5 ; RC = H.FIND() ;
RC = H.FIND(KEY: 5) ;
In both cases, the step prints:
D=X RC=160038
Since K=5 is not in the table, the operation is unsuccessful. Hence, RC is not zero and there is no hash variable D value available to overwrite its host counterpart in the PDV, so the PDV value D="X" remains intact.
Note that all the sample FIND calls above are issued assigned. Since the method can fail when the key-value accepted by it is not in the table and, generally speaking, we do not know ahead of time whether the key is in the table or not, calling it unassigned may result in an error. So, as with all methods that can potentially fail for the same reason (e.g., CHECK or REMOVE) it is a prudent practice to always call FIND assigned, lest the DATA step generate an "ERROR: key not found" message along with the unpleasant note "The SAS System stopped processing this step because of errors".
3.5.4 Implicit vs Explicit FIND Calls
We have already discussed the relative merits of implicit and explicit calls, and the same considerations apply to the FIND method. To recap:
● The choice is dictated by a number of factors, such as the number of component hash variables in the key if it is composite, whether or not we want to preserve the current values of the PDV host key variables, etc.
● Both styles work, and often opting for one against the other is a matter of programming convenience and code brevity.
● The FIND method, if called explicitly, requires only the argument tag KEY. This is because the Retrieve operation requires nothing but a key-value in order to extract the data (as opposed to, for example, the Update All operation).
● If the table key is composite, as many KEY argument tags must be listed as there are constituent key variables in the key; and expressions assigned to them must be of the same data types as the corresponding key variables.
3.5.5 RETRIEVE Operation Hash Tools
● Methods: FIND.
● Argument tags: KEY, MULTIDATA.
3.5.6 RETRIEVE Operation Hash-PDV Interaction
● The data flow is from the hash table data portion variables to their PDV host variables.
● If the operation is successful, the values of the former overwrite the values of the latter.
3.6 UPDATE ALL Operation
A successful Retrieve operation overwrites the values of the PDV host variables with the values of the corresponding data portion hash variables. A successful Update All operation, in a sense, does the opposite: It overwrites the values of the data portion hash variables with the values of the corresponding PDV host variables (or values supplied by the program). The operation is critical for any dynamic data exchange between the PDV and the hash table. It is indispensable for a number of data processing tasks, notably, for data aggregation.
The Update All operation works according to the following pattern:
● If the key it accepts is in the table, the data portion variables of all the items with this key are updated, i.e., overwritten, with the data values accepted by the operation.
● Otherwise, a new item with the key and data values accepted by the operation is inserted into the table.
Therefore, the Update All operation is always successful, regardless of whether the key it accepts is in the table or not or whether the argument tag MULTIDATA:"Y" is in effect:
● If the key is in the table:
◦ If MULTIDATA:"Y" is not in effect, the data portion variables in the single hash item with this key are updated.
◦ If MULTIDATA:"Y" is in effect, the data portion variables in all the hash items with this key are updated.
● If the key is not in the table, a new item with this key is inserted in the table.
The Selective Update operation is possible only if MULTIDATA:"Y" is specified. In this case, we can update the data portion variables in a particular item within a group of items with the same key.
3.6.1 UPDATE ALL Implementation
The hash object tool implementing this operation is the REPLACE method. To demonstrate its mechanics, let us turn to basically the same simple DATA step we have already used for illustrative purposes, with some wrinkles:
Program 3.7 Chapter 3 Explicit Unassigned Update All.sas
data _null_ ;
dcl hash H (multidata:"Y") ;
H.definekey ("K") ;
H.definedata ("D") ;
H.definedone() ;
do K = 1, 2, 2 ;
q + 1 ;
D = char ("ABC", q) ;
rc = H.add() ;
end ;
H.REPLACE(KEY:1, DATA:"X") ; ➊
H.REPLACE(KEY:2, DATA:"Y") ; ➋
H.REPLACE(KEY:3, DATA:"Z") ; ➌
run ;
The evolution of the hash table H content after each successive REPLACE call is shown below, left to right:
Table 3.5 Results of UPDATE ALL Operation

If the argument tag MULTIDATA:"N" is used (or the argument tag is omitted), the second input item with K=2 (2,C) is auto-rejected by the Insert operation invoked via the ADD method call. However, regardless of whether a same-key item group contains one item or more, the Update All operation invoked via the REPLACE method behaves in exactly the same manner: If the key is in the table, the data portion hash variables are overwritten with the values accepted by the call for all items in the group; and if it is not in the table, a new item with these values is inserted.
3.6.2 Assigned vs Unassigned REPLACE Calls
As far as this distinction is concerned, "vs" is a misnomer here because all REPLACE calls are successful by the nature of its design: The method can fail neither if the key it accepts is found in the table, nor if it is not found. Hence, there is no reason to call REPLACE assigned, as in, for instance:
RC = REPLACE(KEY:3, DATA:"Z") ;
In any case, the result of the method call will be RC=0. So, we can always call REPLACE unassigned - and probably should - based on the principle that any piece of coding not caused by programming necessity and included just in case is to some degree misleading.
3.6.3 Implicit vs Explicit REPLACE Calls
All the considerations concerning relative merits of implicit and explicit REPLACE calls are precisely the same as those spelled out for the Insert operation and the ADD method. Their calling style is a matter of programmatic convenience based on (a) code brevity and (b) whether or not it is important to keep the values of the host variables intact.
3.6.4 Selective UPDATE Operation Note
The Update All operation is one of two update operations that can be performed on a hash table. Update All updates all the data portion variables within a same-key item group with one set of updating values. By contrast, the Selective Update operation can update specific items in the group selected according to the required programming logic (including all of them if it so dictates). Moreover, it can update different items with different sets of updating values. However, it can work only in conjunction with the Keynumerate operation because the latter is the only way to latch onto a particular item to be updated - a situation similar to the Selective Delete operation. Hence, we will postpone reviewing Selective Update till the time when we get to describe the Keynumerate operation.
3.6.5 UPDATE ALL Operation Hash Tools
● Methods: REPLACE.
● Argument tags: KEY, DATA.
3.6.6 UPDATE ALL Operation Hash-PDV Interaction
● Implicit calls: The data portion hash variables are overwritten with the values of the PDV host variables if the key-value supplied with the call is in the table.
● Explicit calls: PDV variable values (not necessarily of host variables) may be used in the expressions supplied to the argument tags KEY and DATA.
3.7 ORDER Operation
The Order operation causes the same-key item groups to be logically ordered within the table according to their key-values into a specified sequence. After the operation is complete:
1. If the Output operation is used to write the content of the table to a SAS data set, it accesses the table one item at a time in their logical order. Hence, the physical sequence of the output file records will repeat the logical sequence of the items in the table.
2. Likewise, the Enumerate operation also accesses the table in its logical sequence. Thus, if, for example, the table is ordered ascending and enumerated forward, the item group with the lowest key-value is accessed first, and so on until the group with the highest key-value is accessed last.
3.7.1 ORDER Operation Invocation
Technically, invoking the Order operation is exceedingly simple: It is done via the ORDERED argument tag at the time when a hash object instance is created - that is, either in the compound DECLARE (DCL) statement or the _NEW_ operator statement. For instance, for table H to be ordered ascending, both approaches below work:
dcl hash H(ORDERED:"A") ;
Or:
dcl hash H ;
H = _NEW_ hash (ORDERED:"A") ;
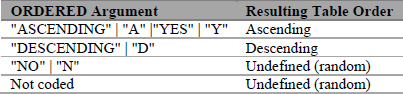
The order is determined by the value of the argument given to the argument tag ORDERED. The acceptable variants of that value are listed in the table below:
Table 3.6 Arguments for ORDERED Argument Tag
3.7.2 ORDERED Argument Tag Plasticity
Just like with any other argument tag in the hash tools arsenal, the argument of ORDERED is, generally speaking, an expression. In this case, it is required to be of the character type. It affords the flexibility to have a table ordered into a specific sequence based on a condition or control information. For example, in the step below, variable Orders represents a primitive "control table" telling which hash table instance gets which sorting order according to the position of the corresponding character. The DO loop creates 3 instances for hash object H, of which instance 1 is ordered ascending, instance 2 - descending, and instance 3 - internally:
Program 3.8 Chapter 3 ORDERED Argument Tag as Expression.sas
data _null_ ;
retain Orders "ADN" ;
dcl hash H ;
do i = 1 to 3 ;
H = _NEW_ hash (ORDERED: char (Orders, i)) ;
end ;
run ;
This kind of functional plasticity may seem a bit geeky at first. However, it illustrates the important concept of the hash object's dynamic nature. Also, it can be very useful if we intend to store hash object instance identifiers in another hash table and want the respective instances structured differently according to control (driver) information.
3.7.3 Hash Items vs Hash Item Groups
Note that when we are talking about the sequence of items within a hash table, it is not in terms of the individual items but in terms of the same-key item groups. The general principle for the sequence of the items in a hash table can be tersely formulated as follows:
● Regardless of whether or not the ORDERED argument tag has been used and/or with which argument, when items with duplicate key-values are added to the table:
◦ The items with the same key-value are always grouped together.
◦ Within each same-key item group, the sequence of its items is the same as that in which they have been added.
Now let us take a more detailed look:
● When duplicate-key items are allowed in the table via MULTIDATA:"Y", the items with the same key-value are always logically grouped together.
● The relative sequence of the items within every same-key group with more than one item is always exactly the same as received from input during the Insert operation.
● Both statements above are true regardless of the argument given to the ORDERED argument tag ("A", "D", or "N"). The latter affects only the positions of the same-key item groups as whole units relative to one another. The items with the same key-values always stick together regardless of the sequence of the groups to which they belong. The sequence of the items within each same-key group always remains as inserted.
● If "A" or "D" is specified, the Order operation permutes same-key groups as whole units to force them into ascending or descending by their key-values. The sequence of items within each group is not affected, and it is preserved as inserted.
● If "N" is specified (or if ORDERED is not coded at all), the Order operation is still performed, albeit implicitly. The only difference from "A" or "D" is that now the sequence of different same-key groups relative to one another is internal and, in fact, random. The sequence of items within each group is not affected, and it is preserved as inserted.
● If a group of items sharing the same key contains just one item, it is merely a partial case: It is still a group, and relative to the rest of the groups it behaves exactly as described above.
● If MULTIDATA:"Y" is not in effect, it forces each same-key group to have a single item with its unique key-value. Or it may happen that each item comes from input with its own unique key. In these situations, it appears that the items themselves, rather than their same-key groups, are ordered accordingly. However, it is just a mirage created by the fact that in such a case each group contains a single, unique-key item.
To inculcate this essential concept better using an example, let us run the following step, varying the value of variable Order from "N" to "A" to "D" in a loop. For each value, table H is created anew, populated using the ADD calls the same way, and its content is output to a data set named using the current value of Order.
Program 3.9 Chapter 3 Duplicate-Key Table Ordered 3-Way.sas
data _null_ ;
do order = "N", "A", "D" ;
dcl hash H (multidata:"Y", ORDERED:Order) ;
H.definekey ("K") ;
H.definedata ("K", "D") ;
H.definedone () ;
K = 1 ; D = "A" ; H.add() ;
K = 2 ; D = "B" ; H.add() ;
K = 2 ; D = "C" ; H.add() ;
K = 3 ; D = "D" ; H.add() ;
K = 3 ; D = "E" ; H.add() ;
K = 3 ; D = "F" ; H.add() ;
H.output (dataset: catx ("_", "Hash", Order)) ;
end ;
run ;
The step generates an output data set for each of the three different Order values: Hash_N, Hash_A, and Hash_D. Each mirrors the content of its own correspondingly ordered hash table. In the table below, their contents are presented side by side along with the original input order, with the same-key item groups shaded identically:
Table 3.7 Same-Key Item Groups and Hash Items Relative Order

Now, if we omit MULTIDATA:"Y" (or recode it as MULTIDATA:"N") and repeat the procedure, only the first item with a given input key-value is kept, and so we will get the following picture:
Table 3.8 Hash Items Relative Order for Unique Keys

This simple data experiment clearly confirms the principal points made above:
● With any specified sequence, the Order operation permutes the same-key groups as whole units.
● The input sequence of the items within each same-key item group is always preserved.
● These principles hold true regardless of the number of items in any same-key group.
3.7.4 OUTPUT Operation Effects
As we have seen, the Output operation, regardless of the specified order (ascending, descending, or undefined/random) reshapes the input data sequence by forcing the same-key items to bunch up into same-key groups. There are several takeaways from this fact:
● If the goal of having the table ordered is to enable BY-group processing of the data set created from the table by the Output operation, specifying ascending or descending order is extraneous. Even if the order is left (or specified) internal, the same-key items are still grouped together, so the output data set can be safely processed using the BY statement with the NOTSORTED option.
● By the same token, it is unnecessary to explicitly order the table into ascending or descending order if the only goal of a task at hand is to locate a group of (one or more) items with a given key and process or use the data within the group. Within this scope, the position of the group in the table relative to other same-key groups is irrelevant. Typical tasks of this nature include a Slowly Changing Dimensions Type 2 (SCD2) table lookup or harvesting same-key items for one-to-many or many-to-many joins.
● Under other circumstances, such as processing partially sorted data, forcing the hash table into ascending or descending order may be crucial. Usually, it occurs when a file is processed one BY group at a time and for every BY group, a number of hash tables, each sorted by a different key, need to be populated, post-processed, and reinitialized for the BY group to be processed next.
The result of the Order operation with ORDERED:"A" or ORDERED:"D” is known formally as stable sorting. It means that within every same-key group, the relative input sequence of items is preserved, while the groups themselves are permuted into the specified order according to their key-values. This is precisely analogous to the action of the SORT procedure when its EQUALS option is in effect.
The result of the implicit Order operation with ORDERED:"N" (or when the argument tag is omitted) can be called, in the same vein, stable grouping: Though the same-key groups, relative to each other, are disordered, items with the same key always abut each other, and within each same-key group, the relative input sequence of items is preserved.
3.7.5 General Hash Table Order Principle
The principal takeaway from this section can be condensed as follows:
1. The items in any hash table are always grouped by the table key.
2. The sequence of the same-key groups relative to each other is determined by the specified (or implied) order.
3. Within each same-key group, the relative position of the items is the same as in input.
3.7.6 Ordering by Composite Keys
If the hash table key is composite, i.e., comprises more than one hash variable, it is always processed by the hash object as if it were a single concatenated key. That is why the Order operation can order the table only by its composite key as a whole either ascending or descending. It cannot order it ascending by one key hash variable and descending - by another. The only way this kind of effect can be achieved is by using certain programming subterfuges, such as multiplying a numeric key variable by -1, but the purpose and value of doing so are questionable.
3.7.7 Setting the SORTEDBY= Option
When a hash table sorted by the Order operation is written out to a SAS data file, the SORTEDBY= option on this file is not set. Therefore, if it is desirable to indicate, for the sake of downstream data processing, that the file is already sorted, the option has to be spelled out explicitly. For example, if in the DATA step shown above the argument tag ORDERED is valued as "A", we may include SORTEDBY= in the DATASET argument tag specification for the OUTPUT method call:
H.output (dataset: cats ("Hash_", Order, "(SORTEDBY=K)") ;
In this case, the character expression assigned to DATASET would resolve to:
Hash_A(SORTEDBY=K)
This way, if an attempt to sort the file should be made, the SORT procedure will recognize the flag and skip sorting. Also, the SORTEDBY=K flag may cause the SQL optimizer to take the fact that the file is already sorted into account and use it to construct a more efficient query.
3.7.8 ORDER Operation Hash Tools
● Methods: OUTPUT.
● Argument tags: ORDERED, MULTIDATA.
3.7.9 ORDER Operation Hash-PDV Interaction
● None. All required sorting is done internally by the hash object.