
Chapter 4: Item-Level Operations: Enumeration
4.2 Enumeration: Basics and Classification
4.2.1 Enumeration as a Process
4.2.2 Enumerating a Hash Table
4.2.3 KeyNumerate (Key Enumerate) Operation
4.3.1 KeyNumerate Operation Mechanics
4.3.2 FIND_NEXT: Implicit vs Explicit
4.3.3 Other KeyNumerate Coding Styles
4.3.4 Version 9.4 Add-On: DO_OVER
4.3.5 Forward and Backward, In and Out
4.3.6 Staying within the Item List (Keeping It Set)
4.3.7 HAS_NEXT and HAS_PREV Peculiarities
4.3.9 Harvesting Hash Items via Explicit Calls
4.3.10 Selective DELETE and UPDATE Operations
4.3.11 Selective DELETE: Single Item
4.3.12 Selective Delete: Multiple Items
4.3.14 Selective DELETE vs Selective UPDATE
4.3.15 KeyNumerate Operation Hash Tools
4.3.16 KeyNumerate Operation Hash-PDV Interaction
4.4.1 The Hash Iterator Object
4.4.2 Creating and Linking the Iterator Object
4.4.4 Direct Iterator Access: First Item
4.4.5 Direct Iterator Access: Last Item
4.4.6 Direct Iterator Access: Key-Item
4.4.8 Enumerating from the End Points
4.4.9 Iterator Priming Using NEXT and PREV
4.4.10 FIRST/LAST vs NEXT/PREV
4.4.11 Keeping the Iterator in the Table
4.4.12 Enumerating Sequentially from a Key-Item
4.4.13 Harvesting Same-Key Items from a Key-Item
4.4.14 The Hash Iterator and Item Locking
4.4.16 Locking Same-Key Item Groups
4.4.17 Locking the Entire Hash Table
4.4.18 ENUMERATE ALL Operation Hash Tools
4.1 Introduction
Under a number of real-life programming scenarios a hash table, in one way or another, needs to be processed sequentially one item at a time- i.e., enumerated. The item-level operations discussed thus far do not provide for this capability: They process either a single item or all items in a same-key item group at once. However, the hash object includes special tools designed to enumerate a hash table in a number of variations. In this chapter, we are discussing the hash table operations based on these tools. In the chapters that follow they will be further exemplified in a variety of ways.
4.2 Enumeration: Basics and Classification
The SAS hash object supports two enumeration operations on its tables: KeyNumerate (aka Key Enumerate) and Enumerate All. In the next two sections we will discuss them separately in detail. However, before getting to it, let us briefly dwell on what "enumeration" means in general and what it means specifically as applied to a hash object table.
4.2.1 Enumeration as a Process
Generally speaking, to enumerate means to list items in a collection sequentially in their intrinsic order. There are a number of reasons to enumerate. For example, the goal may be just to determine the number of items in the collection or to find out how many of them carry information, in which case it is sufficient merely to list the items without retrieving the data stored in them. On the other hand, it may be desirable to extract the data in order to process it or store elsewhere. Enumeration is an intrinsic part of SAS programming. Just a few examples of enumeration include (you can doubtless think of more):
● Reading a SAS data file sequentially.
● Scanning through an array.
● Scanning through a character string one character at a time.
Note that in all these cases, enumeration can be related either to the whole data collection or just part of it. Also, the items be simply listed to discover certain properties of the data collection, or the data they carry can be extracted into the PDV as well.
4.2.2 Enumerating a Hash Table
Just like in the case of a general data collection, enumerating a hash table means accessing its items sequentially. However, in terms of a SAS hash object, enumerating the table always means not merely listing the items, but also retrieving the values of the data portion variables into their respective PDV host counterparts. In other words, when a hash table is enumerated, the Retrieve operation is always performed latently on each item it visits.
In terms of the hash object, there are two different ways to enumerate a hash table corresponding to two different enumeration operations. Let us look at them separately.
4.2.3 KeyNumerate (Key Enumerate) Operation
This operation works by taking the following course of actions:
● Given a key-value, find the group of items sharing this key-value.
● If an item group with this key-value exists in the table, access the items in this, and this group only, sequentially, starting from the logically first item in this group.
Also, the KeyNumerate operation has certain limitations:
● It requires a key-value in order to point to a specific same-key item group on which to work.
● It cannot cross the boundaries of a given same-key item group. Only the items in this group can be enumerated. To enumerate another item group, another key-value must be used.
● It is supported only if the MULTIDATA:"Y" argument tag is set.
4.2.4 Enumerate All Operation
The Enumerate All operation works according to the following three alternative modes:
1. Start from the logically first item in the table and access one or more items, one at a time, in the direction of the table logical order, i.e., forward.
2. Start from the logically last item in the table and access one or more items, one at a time, against the direction of the table logical order, i.e., backward.
3. Start with an item with a given key-value and access one or more items, one at a time, either forward or backward. The items visited can be any of the items in the table, regardless of the same-key item group or any subset of the items in the group thereof.
The Enumerate All operation eliminates the limitations of the Keynumerate operation since it is not constrained to a single same-key item group:
● In modes 1 and 2, it does not require a key in order to operate at all.
● In mode 3, it needs a key-value only to locate the starting point. Thereafter, no key is required for it in order to work.
● It can access items across all same-key item groups, i.e., the entire table.
● It operates in the same exact way regardless of whether MULTIDATA:"Y" is set or not.
● However, in order to work, it requires an auxiliary structure, the hash iterator object, linked to the instance of the hash table in question.
4.2.5 Template DATA Step
We will discuss the KeyNumerate and Enumerate All operations and the hash tools they are implemented with in the two following sections separately. However, we will be using the same sample hash table to illustrate the concepts in both. Consider the following template DATA step:
Program 4.1 Chapter 4 Template Data Step.sas
data _null_ ;
dcl hash H (multidata:"Y", ordered:"N") ;
H.definekey ("K") ;
H.definedata ("D") ;
H.definedone () ;
do K = 1, 2, 2, 3, 3, 3 ;
q + 1 ;
D = char ("ABCDEF", q) ;
H.ADD() ;
end ;
h.output(dataset: "AsLoaded") ;
/*...Insert demo code snippets below this line...*/
stop ;
run ;
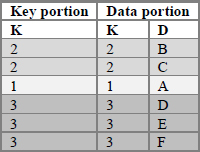
Note that ORDERED:"N" in the table H declaration indicates that it uses its default internal ordering rather than explicit "A" (ascending) or "D" (descending). Also, MULTIDATA:"Y" is intentionally set to allow items with duplicate key-values. After all input value pairs (K,D) have been inserted in the table via the ADD method, the content of the loaded table H is as follows:

● To test-run the code snippets presented in the next two sections, all we need is to paste the snippet in question into the template step above after the comment line, just before the STOP statement.
● Note, however, that for each snippet, the programs supplied with the book present the full template step with the relevant snippet included.
● The call to the OUTPUT method is included in the step for diagnostic purposes, so that the data portion of the table could be viewed as reflected in the content of data set work.AsLoaded.
● The reason for setting ORDERED:"N" and MULTIDATA:"Y" is that it makes the ensuing discussion more generic and applies equally to the hash table with these particular argument tag values or any other values.
4.3 KEYNUMERATE Operation
Suppose that, given table H above, we need to list all the items with K=3 and retrieve the values of D (i.e., "D", "E", "F") from each item into the PDV host variable D. Such need, for example, arises when hash tables are used to perform a one-to-many or many-to-many table join and in a number of other use cases as well.
Doing so is a two-step process:
1. Point at the logically first item of the K=3 same-item group- i.e., the item with D="D" and retrieve the value of hash variable D into PDV host variable D.
2. Step down the list one item at a time. Each time, retrieve the value of D. If there are no more items in the list, terminate.
4.3.1 KeyNumerate Operation Mechanics
It is important to get a good grip on what is happening within the key group on which the Keynumerate operating is working in order to apply the operation's programming logic cognizantly and avoid befuddling surprises. In the SAS language, the two-step plan outlined above can be implemented as shown in this snippet (inserted in the template step above for testing):
Program 4.2 Chapter 4 Keynumerate Mechanics Snippet.sas
call missing (K, D, RC) ; ❶
put "Before Enumeration:" ;
put +3 (RC K D) (=) ;
put "During Enumeration:" ;
RC = H.FIND(KEY:3) ; ❷
do while (RC = 0) ; ❸
put +3 (RC K D) (=) ;
RC = H.FIND_NEXT() ; ❹
end ;
put "After Enumeration:" ;
put +3 (RC K D) (=) ;
Running this snippet within the template step prints the following information in the SAS log:
Before Enumeration:
RC=. K=. D=
During Enumeration:
RC=0 K=. D=D
RC=0 K=. D=E
RC=0 K=. D=F
After Enumeration:
RC=160038 K=. D=F ❺
❶ Before the KeyEnumerate operation is invoked, K, D, and RC in the PDV are set to nulls just to see how their values will change.
❷ H.FIND(KEY:3) call points to the group of items with K=3. Another way to phrase it is that the call sets the list of items with K=3. Setting the list places the enumeration pointer at the logically first item in the group. FIND executes the direct Retrieve operation, extracting the hash value D="D" from the first item in the group into its PDV host variable. Thus, the missing value for D is overwritten with "D". Since the call is explicit, there is no need to assign K=3 in the PDV.
❸ A DO loop is launched to call H.FIND_NEXT()repeatedly until such time when the method call fails with RC≠0.
❹ H.FIND_NEXT() is called in the loop. Its first iteration moves the pointer from the first item (where the FIND call placed it) to the second, and every next iteration moves it one more item down the list. In each iteration, FIND_NEXT retrieves the hash value of D from the corresponding item into host variable D. This way, D="D" is first overwritten with "E", and then with "F", which is what the log records indicate.
❺ At this point, there are no more items in the group left to enumerate. Thus, when FIND_NEXT is called once again, it fails returning RC=160038. Since RC≠0, the loop terminates at the next iteration at the top of the loop because of the RC=0 condition in the WHILE clause. This action moves the pointer outside the K=3 item group, which unsets the item list and terminates the operation.
A few more points deserve to be emphasized:
● Since K is not specified in the data portion of table H, neither the FIND nor FIND_NEXT method retrieves its value from the table into its host variable, and thus K=. in the PDV remains unchanged during the whole process.
● After the item list has been unset, the only way to enumerate the item group anew is to set the item list again by calling FIND again.
● Incidentally, in addition to FIND, both the CHECK and REF method calls can set an item group for enumeration. In other words, they also place the enumeration pointer on the first item in the group and enable further enumeration using FIND_NEXT. However, unlike FIND or FIND_NEXT, neither CHECK nor REF retrieves the data portion values from the first item due to their design. Thus, they can be useful in terms of Keynumerate only in a hypothetical situation where the data has to be retrieved from all items in an item group except the logically first. Whether there can be a realistic use case for such a functionality is moot. However, the capability does exist, and we would like you to be aware of it, even if it is not much more than a curiosity.
4.3.2 FIND_NEXT: Implicit vs Explicit
Note that the FIND_NEXT call is implicit- i.e., it does not have the KEY argument tag specified. However, the method is provided with the option of calling it explicitly, so why not do it? Actually, there is a reason behind it:
● The FIND_NEXT method always works only with a key-value group set by the initial call to the FIND method (or, as an option, CHECK or REF). Without such a priming call, it would not work at all because the item list for it to operate upon would not be set.
● Hence, calling FIND_NEXT explicitly is pointless: If, instead of the implicit call, we coded the method explicitly with any value of the argument tag KEY, it would change nothing since the arguments provided for the KEY argument tag are ignored. For example, the calls H.FIND_NEXT(KEY:0), H.FIND_NEXT(KEY:3), or H.FIND_NEXT(KEY:999) would result in the same outcome as H.FIND_NEXT().
4.3.3 Other KeyNumerate Coding Styles
The Keynumerate code section can be written more concisely by dropping the FIND call before the DO loop and instead including it in the loop's index specification:
Program 4.3 Chapter 4 Keynumerate Loop Style2 Snippet.sas
do RC = H.FIND(KEY:3) BY 0 while (RC = 0) ;
put +3 (RC K D) (=) ;
RC = H.FIND_NEXT() ;
end ;
By including FIND in the loop, above, we call it automatically on the first iteration, and the RC value the call returns is evaluated at the top of the loop. If the key-value provided with the FIND call is not in the table, there is no same-key group to enumerate, so the loop stops right there and then. Otherwise, it proceeds to calling FIND_NEXT repeatedly in the same manner as before. The BY 0 clause is a subterfuge used to keep the loop iterating: Without it, the loop would terminate at the first iteration according to the DO loop index rules. Above, we want the loop to be controlled not by its index but by the WHILE condition and terminate when RC≠0.
Yet another, even more concise, style is based on calling FIND conditionally and using the UNTIL condition instead of WHILE:
Program 4.4 Chapter 4 Keynumerate Loop Style3 Snippet.sas
if H.FIND(KEY:3) = 0 then do until (H.FIND_NEXT() ne 0) ;
put +3 (RC K D) (=) ;
end ;
This style is more convenient in the sense that it does not require including the FIND_NEXT call in the body of the DO loop, much in the same vein as the DO_OVER technique discussed below.
4.3.4 Version 9.4 Add-On: DO_OVER
The styles of invoking KeyNumerate shown above work in SAS 9.2 and later. Since the advent SAS 9.4, the operation can be activated without calling the combination of FIND and FIND_NEXT, but by calling the DO_OVER method instead:
Program 4.5 Chapter 4 Keynumerate Loop DO_OVER Snippet.sas
do while (H.DO_OVER(KEY:3) = 0) ;
put +3 (K D) (=) ;
end ;
On the first call, DO_OVER accepts a key-value from the PDV or explicitly and sets the pointer to the first item of the group with the key. Then it retrieves the data portion values and moves the pointer to the second item. On the subsequent calls, it proceeds down the list one item at a time. For each item on which it works, it performs the indirect Retrieve operation, snatching the data portion values from the table and overwriting the host variables with them. When it is called for the last item in the list, it moves the pointer outside the
group, thus unsetting it. This causes the next call to fail and the loop to stop because of a non-zero return code. Thus, effectively, the DO_OVER method:
● Acts as the FIND method on the first call.
● Acts as the FIND_NEXT method on the ensuing calls.
● Is called unassigned in the WHILE clause and thus there is no need for RC=.
If the DO_OVER method, as a tool for keyed enumeration is so convenient and concise that a question arises: Why not call it alone rather than use other methods described above for the same purpose? The answer is three-fold:
● We have found out that while DO_OVER works without a glitch when we merely need to harvest the hash data from an entire same-key group (as in the snippet above), it has issues with the Selective Delete and Selective Update operations (Sections 4.3.10-4.3.14). At the same time, the theoretically equivalent combination of FIND and FIND_NEXT works as expected under those scenarios as well.
● As we will see below, combining it with a priming call to CHECK or REF adds a degree of flexibility not offered by calling DO_OVER alone.
● SAS version independence: The FIND and FIND_NEXT combination works in SAS 9.2 through SAS 9.4.
4.3.5 Forward and Backward, In and Out
When a given key is in the table and the list of the items with this key is set, we can use the techniques shown above to Keynumerate one, more, or all items in the group forward. Is it possible to do it backward? The answer is "yes, but to a degree", and here is why:
● There exists a hash tool, the FIND_PREV method, designed to Keynumerate backward. Its name speaks for itself.
● Unfortunately, it cannot be used starting with the bottom of the list. This is because any method setting the item list (e.g., FIND) always points to the logically first item.
● Therefore, to scan backward starting with a given item, we need to scan forward first in order to reach it.
● In doing so, we must be careful not to let the pointer escape the item group when it dwells on the last and first item. Such an attempt will unset the item list, thus precluding any further enumeration, forward or backward, unless the list is reset anew.
To make these points more eminent, let us recall the content of table H created in our template DATA step (note that the column Item# below is not a variable in the table - it is included just to indicate the logical order of the items):

Suppose that we want to enumerate the item group with K=3 backward from item #6 to item #4 and then forward to item #6. To accomplish it, we can proceed in this manner:
● Call FIND with K=3 to set the list and latch onto item #4.
● Call FIND_NEXT twice to reach item #6.
● Call FIND_PREV twice, enumerating items #5 and #4 backward in succession.
● Call FIND_NEXT twice, enumerating items #5 and #6.
The problem with this fine plan is that we have based our actions on knowing, ahead of time, the item group content and thus knowing exactly when to stop calling FIND_NEXT and FIND_PREV to get what we want without unsetting the item list. Calling either method one more time than indicated above would unset the list, pushing the enumeration pointer out of either the bottom or the top of the item group. Therefore, in order to be able to code dynamically, we need a means to tell whether the pointer currently dwells on the last or first item of the group without knowing the number of items in it beforehand.
4.3.6 Staying within the Item List (Keeping It Set)
In real-life situations, we usually do not know ahead of time how many items are in any same-key group, nor what the values of D for each item are. Therefore, if we need to stay within the item list during the Keynumerate operation without unsetting the list, we need to be able to call FIND_NEXT and FIND_PREV only if the next or previous item, respectively, still exists.
The auxiliary methods HAS_NEXT and HAS_PREV, respectively, are designed to provide the means of knowing it. By calling them, we can predict whether to call FIND_NEXT or FIND_PREV another time in order to stay within the item list without unsetting it. This snippet causes the Keynumerate operation to walk forward, then backward, and then again forward within the K=3 item group without ever moving the enumeration pointer out of it:
Program 4.6 Chapter 4 Keeping Item List Set Snippet.sas
put "Forward:" ;
RC = H.FIND(KEY:3) ;
do while (1) ;
put +3 RC= D= ;
RC = H.HAS_NEXT(RESULT:NEXT) ;
if not NEXT then LEAVE ;
RC = H.FIND_NEXT() ;
end ;
put "Backward:" ;
do while (1) ;
RC = H.HAS_PREV(RESULT:PREV) ;
if not PREV then LEAVE ;
RC = H.FIND_PREV() ;
put +3 RC= D= ;
end ;
put "Forward:" ;
do while (1) ;
RC = H.HAS_NEXT(RESULT:NEXT) ;
if not NEXT then LEAVE ;
RC = H.FIND_NEXT() ;
put +3 RC= D= ;
end ;
Note that the methods HAS_NEXT and HAS_PREV are supplied with the argument tag RESULT. It accepts the unquoted name of a numeric variable (in the snippet above, NEXT and PREV), into which the result of the call is to be placed. We will dwell on this distinctive feature in Section 4.3.7. Running the template step with this snippet inserted into it prints the following in the SAS log:
Forward:
RC=0 D=D
RC=0 D=E
RC=0 D=F
Backward:
RC=0 D=E
RC=0 D=D
Forward:
RC=0 D=E
RC=0 D=F
This diagnostic log output confirms that, by keeping the item list set (or preventing it from being unset), we can make the operation scan the item group to and fro as intended.
4.3.7 HAS_NEXT and HAS_PREV Peculiarities
It should be noted that these methods, compared to other hash methods, possess a few peculiar traits:
● Judging from their return codes, both methods are always successful. That is, they generate a zero return code, even if no data item list is set. This is odd since the way the methods work makes any sense only within the concept of a group of same-key items whose list is set by calling FIND, CHECK, REF, or DO_OVER. By contrast, the FIND_NEXT and FIND_PREV methods always return a non-zero code if they are called when no item list is set, which is par for the course.
● As already noted, the methods are packed with the argument tag RESULT. It accepts the unquoted name of a numeric variable, to which the call returns the result (not the return code!) it generates. This is in sharp contrast with other methods whose argument tags accept variable names only as character expressions.
● If the variable name given to RESULT already exists in the PDV and it is numeric, it is fine; but if it is character, it creates a data type conflict. This is because, unlike the other methods, HAS_NEXT and HAS_PREV actually look to see if the variable with the name specified to the RESULT argument tag already exists in the PDV. If it does not, they create a numeric variable with this name in the PDV. But if it does and it has a different data type, a conflict ensues and the step is terminated. Unlike its behavior in many other cases, with the hash object SAS does not provide for implicit character-to-numeric conversion (along with the corresponding notes in the log).
● The fact that these two methods create PDV variables on their own accord sets them apart from the rest of the methods, which accept variable names as character expressions only if they already exist in the PDV. By contrast, with these two methods, the RESULT argument tag expects not a character expression resolving to a valid SAS variable name, but an unquoted SAS variable name itself.
● The values returned into the variable (whose name is assigned to the RESULT argument tag such as variables Next and Prev above) follow standard SAS conventions for logical expressions. That is, if the next or previous item exists, the respective method returns 1 (i.e., logical True); otherwise, they return 0 (logical False). This is the opposite of the return codes all method calls generate, for which RC=0 (i.e., logical False) means success and non-missing RC≠0 (logical True) means failure.
4.3.8 Harvesting Hash Items
So far, we have concentrated on a single same-key group (with K=3) for the purpose of explanation and illustration of a number of principles. However, in the real data management world, we are usually given a set of key-values and need to perform an action on all same-key groups whose keys are found in the table.
In most cases, the action means collecting - or "harvesting" - the values from the data portion hash variables for each key-value in the set. And most often, its key-values come from a file - as it happens, for instance, when the Keynumerate operation is used to combine data sets (discussed in Chapter 6).
In the sample step below, a set of key-values (including both the key-values present and not present in our hash table) is coded into an array. For each array element, whose value matches the key of an item group in hash table H, the group is enumerated, so that the value of D is retrieved from every item in the group (i.e., harvested), and a record is added to output data set work.Harvest. (Compared to the template step, in the step below the DATA statement list is not _NULL_, so instead of just showing the code snippet, the step is presented in full.)
Program 4.7 Chapter 4 Harvesting Items via Implicit FIND and FIND_NEXT.sas
data harvest (keep = K D) ;
dcl hash H (multidata:"Y", ordered:"N") ;
H.definekey ("K") ;
H.definedata ("D") ;
H.definedone () ;
do K = 1, 2, 2, 3, 3, 3 ;
q + 1 ;
D = char ("ABCDEF", q) ;
H.add() ;
end ; ❶
array keySet [5] _temporary_ (0 1 5 7 3) ; ❷
K = . ; ❸
do i = 1 to dim (keySet) ; ❹
K = keySet[i] ; ❺
do RC = H.FIND() by 0 while (RC = 0) ; ❻
output ;
RC = H.FIND_NEXT() ; ❼
end ;
end ;
stop ;
run ;
Note that in this step:
● Table H is loaded with the same content as before.
● The name of the output data set is defined in the DATA statement, rather than via the OUTPUT method argument tag DATASET.
● Key variable K is not defined in the data portion, as shown below.

The fact that K is not in the data portion in addition to the key portion has its important implications, as we will see below. Let us take a look at some details of the code snippet above.
❶ At this point, table H has been loaded with the content shown above.
❷ Temporary array keySet contains 5 items values at compile time. They contain some (but not all) key-values present in table H (1, 3) and also key-values not loaded in the table (0, 5, 7).
❸ PDV host variable K is set to missing just to observe what happens to its value; from the standpoint of harvesting, it is irrelevant.
❹ The key-values to be searched for and harvested from table H are extracted from the array in a loop one at a time.
❺ With the intent to use implicit method calls, the value of the current key-value from the array is assigned to the PDV host variable K, overwriting its value.
❻ The FIND method is called implicitly with the current key-value of K as a key.
If the value of K is not present in the table, FIND returns RC≠0, and the DO loop terminates without executing any of the statements inside it because of the RC=0 condition in its WHILE clause. This causes program control to go back to the outer DO loop and get the next element from the array (if there are any left).
If the value of K is present in the table, the method call (a) sets the item list for enumeration, (b) retrieves the value of hash variable D into the PDV host variable D for the first item in the group, and (c) returns RC=0, which causes the DO loop to continue its current iteration and execute the statements inside the loop. This way, after the successful FIND call, the current PDV value pair (K,D) is written to the output data set as a record, and then program control is passed to the FIND_NEXT call.
❼ If the FIND call was successful, FIND_NEXT is called. If there is more than one item in the group, it retrieves the value of hash variable D from the second item (and third, and so on) and sets RC=0. If the second item does not exist, FIND_NEXT returns RC≠0. In both cases, after the method call, program control is passed to the top of the DO WHILE loop. If RC≠0, the loop terminates at the top. Otherwise, the current PDV value pair (K,D) is written to the output file as a record. Then FIND_NEXT is called again to enumerate the next item. The process continues in this manner for every iteration of the loop until there are no more items for FIND_NEXT to retrieve and it returns RC≠0, thus terminating the loop. At this point, program control is passed to the outer loop to get the next key-value from the array.
Since the only array key-values matching the keys in table H are keySet[2]=1 and keySet[5]=3, only the items from the item groups with K=(1,3) are harvested. As a result, running this step generates output data set work.Harvest with the following content:

Instead of using the FIND and FIND_NEXT pair, the harvesting DO loop can be rewritten more simply and tersely by using the DO_OVER method:
Program 4.8 Chapter 4 Harvesting Items via Implicit DO_OVER Snippet.sas
do i = 1 to dim (keySet) ;
K = keySet[i] ;
do while (H.DO_OVER() = 0) ;
output ;
end ;
end ;
Both of the implicit call techniques work, and the OUTPUT statement writes out the expected values of K and D. It means that at the time the statement is executed, both PDV host variables have the correct values. However, because K is not defined in the data portion, the DO_OVER calls extract only the values of hash variable D into its PDV host variable D, while PDV host variable K gets the proper values because they are assigned to it via the array references. Below we will see how to get both K and D retrieved from the table in the absence of the assignment statement.
4.3.9 Harvesting Hash Items via Explicit Calls
Instead of assigning the needed key value to PDV host variable K and making implicit calls, the FIND and DO_OVER methods can also be called explicitly by using the array reference directly as an expression with the argument tag KEY. For example, in the case of using DO_OVER, we could code:
Program 4.9 Chapter 4 Harvesting Items via Explicit DO_OVER Snippet.sas
K = . ;
do i = 1 to dim (keySet)
do while (H.DO_OVER(KEY:keySet[i]) = 0) ;
output ;
end ;
end ;
Note that above, the assignment statement K=keySet[i] is omitted, and the array reference is essentially moved from it to the argument tag. However, if we rerun the template step with this little change, the output we get will look as follows:

Clearly, it is not what we want. So, why is it that the implicit calling techniques shown above do work and the one with the explicit call does not? The reason is that with both implicit calling techniques we get correct output values of K merely because the expected values are assigned to the PDV host variable K from the array - and not because the calls retrieve the values of hash variable K into its PDV host variable K. Moreover, the latter cannot happen as long as K is not part of the data portion. The obvious remedy is to add K to the data portion:
H.definedata ("K", "D") ;
The content of table H loaded with this definition in place will now look like so:
With the hash table entry defined this way, the current hash value of K is retrieved into the PDV host variable K alongside with D with every successful DO_OVER call, and so now the step will generate correct output. Incidentally, with K now added to the data portion, the variant with the FIND and FIND_NEXT pair can be recoded with an explicit call to FIND:
Program 4.10 Chapter 4 Harvesting Items via Explicit FIND and FIND_NEXT Snippet.sas
do i = 1 to dim (keySet) ;
do RC = H.FIND(KEY:keySet[i]) by 0 while (RC = 0) ;
output ;
RC = H.FIND_NEXT() ;
end ;
end ;
As explained earlier, the FIND_NEXT call can be left implicit, since even if an expression is assigned to its argument tag KEY, it is disregarded because the FIND_NEXT method operates only within the confines of the item group set by calling the FIND method.
The behavior observed above vis-a-vis the absence or presence of key portion variables in the data portion adheres to the general principle that any Retrieve operation, either direct or indirect, extracts the values only from the hash variables defined in the data portion. You will quite often see hash table definitions which include the key variables also included in the data portion for exactly this reason.
4.3.10 Selective DELETE and UPDATE Operations
Let us recall that the Delete All operation - activated by the REMOVE method - obliterates the entire group of hash items with a given key-value if the key is in the table. However, often it is desirable to delete, not all the items in the same-key item group, but only specific items based on certain conditions.
Likewise, the Update All operation (in SAS 9.4 and later) - activated by the REPLACE method - updates the data portion hash variables for all items with a given key-value if it is in the table. But yet again, by the same token as with Delete, we may need to update not all the items in a same-key item group, but only certain items in the group that meet specific criteria, including those based on the data portion values of the items targeted for deletion.
For same-key item groups containing but a single item - for example, if the uniqueness of the table key is enforced programmatically - Delete All and Update All can be used for conditional deletion and update just fine. The reason is that in this case there is no need to enumerate multiple items. Otherwise, to select items for deletion or update from a multiple-item same-key group, we need the capability to scroll through the group in order to decide which items to act upon.
This capability is provided by the Selective Delete and Selective Update operations. They are built on the Keynumerate operation as a backbone. The reason is two-fold. On the one hand, in order to delete or update a specific item in a multi-item same-key group, the item has to be reached and latched onto first. On the other hand, the hash methods REMOVEDUP and REPLACEDUP designed for Selective Delete and Update, respectively, work only if the item list for the group is set and thus can be enumerated. We will discuss these two operations one at a time.
4.3.11 Selective DELETE: Single Item
To illustrate the operation, we will use, as a guinea pig, the same template step and hash table H as we have already used in this section. Imagine that in the item group with K=3 we need to delete the item whose data-value D="E", i.e., item #5. Again, please note that Item# is not in the table and is shown here just to indicate the logical order:

In the plug-in snippet below, the item group with K=3 is enumerated beginning with table item #4, and for every item encountered, the data-value of hash variable D is retrieved into host variable D. When the latter becomes "E", program control dwells on the item to be deleted, which is then done by calling the REMOVEDUP method. The next enumerating loop is used only to check the content of the item group K=3 after the deletion.
Program 4.11 Chapter 4 Selective Delete Single Item Snippet.sas
put "Enumerate to delete item with D=E:" ;
do RC_enum = H.FIND(KEY:3) by 0 while (RC_enum = 0) ;
if D in ("E") then RC_del = H.REMOVEDUP() ;
RC_enum = H.FIND_NEXT() ;
end ;
put +3 RC_enum= RC_del= D= /;
put "Enumerate again to check result:" ;
do RC_enum = H.FIND(KEY:3) by 0 while (RC_enum = 0) ;
put +3 RC_enum= D= ;
RC_enum = H.FIND_NEXT() ;
end ;
Running the template step with this snippet prints the following in the SAS log:
Enumerate to delete item with D=E:
RC_enum=160038 RC_del=0 D=E
Enumerate again to check result:
RC_enum=0 D=D
RC_enum=0 D=F
It confirms that the item with D="E" has indeed been deleted. So, in this particular case - when the deletion criterion is specific to a single item - everything appears to work right. Indeed, we wanted to delete the item (K,D)=(3,E), and that is what happened.
However, the log tells us that, after the first loop, we have D="E" from item #5 in the PDV. It suggests that RC_enum=160038 is triggered not by not having any more items to enumerate (in which case we would have D="F" from item #6) but by the fact that after REMOVEDUP successfully removed item #5, FIND_NEXT failed to enumerate item #6, generating RC≠0 and stopping the loop. In turn, it means that if, after deleting item #5, we also needed to delete item #6, we could not do it in the same loop.
Unfortunately, this is indeed the case. So, if more than one item satisfies the deletion criterion, things become more complicated. Let us look how the problem can be addressed.
4.3.12 Selective Delete: Multiple Items
Suppose that now we would like to delete both the item where D="E" and the next item where D="F", like so:

It would be a natural inclination to merely alter the IF statement accordingly to:
if D in ("E", "F") then RC_del = H.REMOVEDUP() ;
However, if we rerun the step with this change, we will quickly discover that what the step prints in the log is exactly the same as it printed before. In other words, while the item with D="E" has been deleted, the item with D="F" has NOT been deleted! We have already hinted at the reason why it happens in the previous subsection. However, it is important enough to add more gory details to the explanation:
● If we look at the log attentively, we will see that after the first enumerating loop terminated, the value of D is still "E". But if after the deletion of item #5 the enumeration process continued unabated, the last item visited would be item #6 and so the value of D after the loop ended would be "F". Since the value of D is still “E”, that means the first loop had terminated before enumerating the remaining values. The loop terminated because RC_enum was not 0. The REMOVEDUP method caused the FIND_NEXT method call to fail.
● It fails because a successful REMOVEDUP call not only removes the item but also unsets the item list, and this causes the next FIND_NEXT call trying to progress to the next item to fail. This is why - and not because it ran out of the items in the set item list - FIND_NEXT returned RC_enum=160038 and caused the loop to end, having never visited item #6.
The conclusion is that during a single pass of Keynumerate it is possible to delete only the item from a same-key group that meets the deletion criterion. In other words, in order to delete more than one item, we need to enumerate the group as many times as there are items to be deleted, resetting the item list every time.
Unfortunately, this fact complicates selective Delete programming, for not only do we have to enumerate repeatedly, but in addition we need to check to see whether the process has progressed to the very last item in the group. Yet fortunately, it is not difficult to do by making use of the HAS_NEXT method:
Program 4.12 Chapter 4 Selective Delete Multiple Items Snippet.sas
put "Keynumerate to delete items with D in ('E','F'):" ;
do ENUM_iter = 1 by 1 until (not MORE_ITEMS) ; ❶
do RC_enum = H.FIND(KEY:3) by 0 while (RC_enum = 0) ; ❷
H.HAS_NEXT(RESULT:MORE_ITEMS) ; ❸
if D in ("E", "F") then H.REMOVEDUP() ; ❹
RC_enum = H.FIND_NEXT() ; ❺
end ;
put +3 ENUM_iter= MORE_ITEMS= ;
end ;
put "Keynumerate again to check result:" ;
do RC_enum = H.FIND(KEY:3) by 0 while (RC_enum = 0) ; ❻
put +3 RC_enum= D= ;
RC_enum = H.FIND_NEXT() ;
end ;
By plugging the snippet into the template step and running it, we will have the following result in the SAS log:
Enumerate to delete items with D=(E,F):
ENUM_iter=1 MORE_ITEMS=1
ENUM_iter=2 MORE_ITEMS=0
Enumerate again to check result:
RC_enum=0 D=D
Now, both required items have been deleted - at the expense of performing the Keynumerate operation twice, as indicated by ENUM_iter=2. Let us take a closer look at the details of the code snippet above:
❶ Organize a DO loop to make as many Keynumerate passes through the K=3 item group as necessary until all required items are deleted.
The ENUM_iter variable counts the iterations of the loop for diagnostic and display purposes.
Boolean variable MORE_ITEMS tells this DO loop when to stop by indicating that in its final iteration, no more items are left to enumerate, i.e., the last item in the group has been processed.
The UNTIL clause causes the loop to execute the statements inside it at least once. Hence, there is no need to initialize MORE_ITEMS beforehand - it will be set inside the loop to 1 when the iteration process hits the bottom item; and to 0 for each item prior to that. The only way the UNTIL condition
evaluates true is if we are pointing to the last item in the group; and the only way that can happen is if there were no more items to remove.
❷ Keynumerate the item group with K=3 by using an explicit call to FIND to set the item list and enumerate the first item in the group. Variable RC_enum controls the termination of the loop. It is set to 0 on the first successful call to FIND. Thereafter, it is set to RC_enum≠0 by the FIND_NEXT call either after a successful REMOVEDUP call or having reached the bottom of the item list and thus failing to locate the next item to enumerate. Either way, the loop is terminated, and program control is passed back to the outer DO loop.
❸ Call HAS_NEXT to detect whether the item, on which the enumeration pointer currently dwells, is the last in the item group. If so, MORE_ITEMS is set to 0; else it is set to 1. If it is set to 0, it will make the outer DO loop terminate as soon as program control leaves the inner loop, due to the UNTIL clause (whose condition is checked at the bottom of the outer loop).
❹ If the value retrieved into the PDV host variable D in the prior FIND or FIND_NEXT call is "E" or "F", delete the item.
❺ Keynumerate the next item in the item list by calling FIND_NEXT. It returns RC_enum≠0 if (a) the prior item has been successfully deleted, or (b) the bottom item has already been enumerated, so there are no more items to fetch, or (c) both.
Otherwise, RC_enum is set to 0.
Either way, program control is passed to the top of the inner loop. If RC_enum=0, the loop goes into the next iteration. Otherwise, it terminates, and program control is passed back to the bottom of the outer loop. If at this point MORE_ITEMS=0, the outer loop terminates, thus making the current Keynumerate pass final.
❻ The item group with K=3 goes through another Keynumerate pass, merely to show in the SAS log which items are left in the item group after the deletions.
The same result, as far as Selective Delete is concerned, can be achieved more tersely code-wise by using the DO_OVER method instead of the tandem of FIND and FIND_NEXT in the first (nested) loop:
do until (not MORE_ITEMS) ;
do while (H.DO_OVER(KEY:3) = 0) ;
RC_next = H.HAS_NEXT(RESULT:MORE_ITEMS) ;
If D in ("E", "F") then RC_del = H.REMOVEDUP() ;
end ;
end ;
However, regardless of the methods activating the Keynumerate operation, the same principle still stands: Since a successful call to REPLACEDUP unsets the item list, Keynumerate must be performed repeatedly if more than one item satisfies the deletion criterion. The nested loop shown in the two last snippets works regardless of how many items are to be deleted; and since usually the latter is unknown ahead of time, we recommend using this coding pattern. If it so happens that there is only a single item satisfying the deletion criterion, the worst case scenario is enumerating the item group twice. In general, this approach will enumerate the group one time more than that the number of items to be deleted.
4.3.13 Selective UPDATE
Just like selective Delete, selective Update can work only in tandem with the Enumerate operation. But, unlike selective Delete, the operation works in a straightforward manner regardless of the number of items updated within a same-key item group. Suppose, for example, that we need to perform the following updates:

The scheme to attain the goal is fairly plain:
1. Enumerate the item group where K=3.
2. For each item visited in the group in the process, whose data-value of D meets the criterion, update the value of hash variable D by calling the REPLACEDUP method.
The code snippet below does exactly that. The second loop is used only to display the data content of the updated item group in the SAS log:
Program 4.13 Chapter 4 Selective Update Snippet.sas
put "Enumerate to update D=(D,F) with D=(X,Z):" ;
do RC_enum = H.FIND(KEY:3) by 0 while (RC_enum = 0) ;
D = translate (D, "XZ", "DF") ;
RC_updt = H.REPLACEDUP() ;
RC_enum = H.FIND_NEXT() ;
end ;
put +3 RC_updt= ;
put "Enumerate again to check result:" ;
do RC_enum = H.FIND(KEY:3) by 0 while (RC_enum = 0) ;
put +3 RC_enum= D= ;
RC_enum = H.FIND_NEXT() ;
end ;
Running the template step with this snippet plugged in prints in the SAS log:
Enumerate to update D=(D,F) with D=(X,Z):
RC_updt=0
Enumerate again to check result:
RC_enum=0 D=X
RC_enum=0 D=E
RC_enum=0 D=Z
So, all the necessary selective updates can be done in a single pass over the same-key item group because a successful REPLACEDUP call, unlike REMOVEDUP, does not unset the item list, and thus the enumerating process continues unabated until after the logically last item in the group is reached.
Note that in the snippet above, REPLACEDUP is called implicitly. It means that it accepts its values from the PDV host variables. To let it accept the desired values, the assignment statement preceding the call:
D = translate (D, "XZ", "DF") ;
changes the value of PDV host variable D as required by the updating logic before the method call.
However, under certain scenarios, alerting the host variable values may be undesirable. To avoid it, REPLACEDUP can be called explicitly instead. In addition, the first DO loop (the one actually doing selective Update) can be coded more concisely by replacing the tandem of FIND and FIND_NEXT with the DO_OVER method:
Program 4.14 Chapter 4 Selective Update Explicit REPLACEDUP Snippet.sas
do while (H.DO_OVER(KEY:3) = 0) ;
RC_updt = H.REPLACEDUP(DATA: translate (D, "XZ", "DF")) ;
end ;
4.3.14 Selective DELETE vs Selective UPDATE
In addition to the obvious distinction between two operations with regard to their self-explanatory purposes and results, let us underscore the difference they have on the Keynumerate operation, without the aid of which neither can succeed:
● The Selective Delete operation is a bit tricky. This is because once an item is removed from a same-key group, it unsets the item list and thus precludes enumerating this group further till the end of the list. Therefore, in order to ensure that all the items meeting the deletion criteria are deleted, the item list has to be reset and the enumeration process repeated until we have discovered that the item on which the enumerating pointer dwells is now the logically last in the item group.
● The selective Update operation presents no such complications. All the items in the requisite same-key group fitting the updating criteria can be updated accordingly in a single Keynumerate pass through the item group.
4.3.15 KeyNumerate Operation Hash Tools
● Methods: FIND, CHECK, REF, FIND_NEXT, FIND_PREV, DO_OVER, HAS_NEXT, HAS_PREV, REMOVEDUP, REPLACEDUP.
● Argument tags: MULTIDATA, ORDERED, RESULT.
4.3.16 KeyNumerate Operation Hash-PDV Interaction
● The Keynumerate operation performs the indirect Retrieve operation on every hash item it visits. To wit, it extracts the values from the data portion variables into the corresponding PDV host variables, overwriting their values with those from the table. Hence, it directs data movement from the hash table to the PDV.
● The Selective Delete and Selective Update operations rely on the Keynumerate operation. They work in the opposite directions by, respectively, (a) deleting specific hash table items and (b) updating their data portion values with the values of their PDV host variables or expressions specified to the argument tags used in explicit method calls.
4.4 ENUMERATE ALL Operation
The KeyNumerate (Enumerate by Key) operation discussed in Section 4.2.4 is predicated on using a key-value to access the table and enumerates the items in the item group with this value if the key is in the table. However, often we need to enumerate one or more table items:
1. Without any prior knowledge and regardless of their key-values, merely starting from the logical beginning or logical end of the table.
2. From the logically first item of the item group with a given key across not only this group but also across other item groups whose keys we do not know beforehand.
This important hash table functionality (in a way similar to reading a SAS data file forward and backward using the SET statement option POINT=) is delivered by the Enumerate All operation. It is supported by a structure known as the hash iterator object and the methods specifically designed to control its actions against the hash table to which it is linked.
4.4.1 The Hash Iterator Object
Before discussing how the hash iterator object can be used practically to support the Enumerate All operation, we need to point out a few fundamental facts about its nature. To materialize an iterator and make it operable, we need to perform a number of actions described below.
1. Declare a hash iterator object:
DECLARE hiter IH ;
This compile time statement does the following:
● Declares a hash iterator object named IH.
● Defines a PDV variable IH of hash iterator type.
The statement must conform to a set of rules:
● The "DECLARE" keyword can be abbreviated as "DCL". Only these two spellings are accepted.
● "Hiter" is also a keyword, so it must also be spelled exactly.
● The statement must appear before variable IH is referenced.
● It can appear with the same iterator name (in this case, IH) only once. The reason is that a non-scalar variable, once defined, cannot be defined again.
2. Create a new hash iterator object instance:
IH = _new_ hiter("H") ;
This run-time assignment statement does the following:
● Creates a new instance of iterator object IH.
● Generates a distinct value of type hash iterator to identify the iterator instance.
● Assigns the value to PDV variable IH.
● Links it to the active instance of hash object H named in the statement.
This statement also must satisfy a number of rules:
● "_NEW_" and "hiter" are keywords, and so they cannot be misspelled.
● Argument "H" is a reference to a PDV variable of type hash whose current value identifies an active instance of hash object H. This is the value the statement uses to link the newly created hash iterator instance to a specific instance of hash object H.
● Hence, by the time this statement has program control, the active hash object instance identified by the value of variable H must already exist; and IH must have been defined in the PDV as a non-scalar variable of type hash iterator.
If everything above is done according to the rules:
● The newly created instance of hash iterator IH is linked to a specific instance of hash object H.
● The current PDV value of variable IH identifies the active hash iterator instance. That is, unless and until this value is changed, any hash iterator method referencing IH will use that iterator instance with the hash object instance (i.e., its hash table) to which it is linked.
● Once a hash iterator instance is linked to a hash object instance, it remains permanently paired with the latter, and only with the latter.
● Whenever IH is referenced, the program uses the active iterator instance, i.e., the one identified by the current PDV value of IH.
● This active hash iterator instance operates only against the hash object instance to which it has been linked - irrespective of whether the latter is currently active or not.
● An iterator instance cannot be linked to more than one hash object instance - otherwise the iterator would not know which hash table to enumerate.
● However, more than one iterator instance can be linked to the same hash object instance, in which case any of them can be used to enumerate the same hash table as a matter of choice.
Just as with the hash object, the DECLARE statement and _NEW_ operator statements can be fused into a single compound DECLARE|DCL statement:
declare hiter IH("H") ;
Also similarly, the compound statement works partially at compile time and run time:
● At compile time, the actions related to the stand-alone DECLARE statement are performed.
● At run time, the actions related to the stand-alone _NEW_ operator statement are performed.
One significant difference between the two separate statements and compound statement is that if more than one instance of hash iterator IH needs to be created at different points in the program, the stand-alone _NEW_ operator statement can be explicitly repeated after the object is declared:
dcl hiter IH ;
...
IH = _new_ hiter("H") ;
...
IH = _new_ hiter("H") ;
Each _NEW_ operator call creates a new hash iterator instance. (The ellipses above denote program logic that may need to be included between the statements.) However, the compound DECLARE statement referencing the same variable IH cannot be repeated for the same reason the stand-alone DECLARE statement cannot: It would be an attempt to define a non-scalar variable more than once. Therefore, to use the compound statement in order to create more than one hash iterator object instance, it has to be enclosed in a loop. For example:
do i = 1, 2 ;
...
dcl hiter IH("H") ;
...
end ;
Alternatively, the program can be constructed to let the implied DATA step loop to do the work. For example, if the intent is to create a new iterator instance only in its first and second iteration, one might code:
data ... ;
...
if _n_ in (1, 2) then dcl hiter IH("H") ;
...
run ;
In both cases, the compiler sees the DECLARE statement referencing IH only once, whereas its run-time component is executed twice, each time creating a new hash iterator instance.
4.4.2 Creating and Linking the Iterator Object
Now that we know the rules, let us consider an example. The DATA step below is a program template for the rest of the chapter. The code snippets presented throughout can be merely pasted in the space marked "Demo code snippet using iterator IH". (Note that for every snippet, the sample programs supplied with the book contain the complete template step including the snippet in question.)
Program 4.15 Chapter 4 Create and Link Hash Iterator.sas
data _null_ ;
dcl hash H (multidata:"Y", ordered:"N") ;
H.definekey ("K") ;
H.definedata ("D", "K") ;
H.definedone () ;
do K = 1, 2, 2, 3, 3, 3 ;
q + 1 ;
D = char ("ABCDEF", q) ;
H.add() ;
end ;
DECLARE HITER IH ;
IH = _NEW_ HITER ("H") ;
/*Demo code snippet using iterator IH */
stop ;
run ;
We can make a few relevant notes from the outset:
● The iterator object instance is linked to the hash object instance by specifying the name of the latter as the character literal constant "H".
● However, it can be any valid character expression as long as it resolves to the name of the hash object we need to link - in this case, object H.
● The iterator instance is created after the hash object is instantiated but before the iterator is to be used.
The statement with the _NEW_ operator can be repeated or used in a loop to create multiple instances of hash iterator object IH, each with its own distinct identifier. This may be necessary when the tables of multiple hash object instances need to be enumerated independently. This functionality will be exemplified in (the more advanced) Chapter 9.
Most of the time, though, a single iterator object instance linked to a single hash object instance is used. In this case, it is simpler to use the compound DECLARE described above:
declare hiter IH ("H") ;
This is all it takes to create an instance of a hash iterator for the Enumerate All operation. Its different actions are activated by the respective methods supplied with the hash iterator object. In particular, they support the following actions:
● Direct access, i.e., non-sequential access from any item in the table or from outside it:
a. To the logically first hash table item.
b. To the logically last hash table item.
c. To the key-item, i.e., the logically first item in the item group with a given key-value.
● Sequential access, i.e., one item at a time:
a. To all items, starting from any item, to the end of the table in the direction of the logical order, i.e., Enumerate forward.
b. To all items, starting from any item, to the beginning of the table in the opposite direction, i.e., Enumerate backward.
c. Note that while it rarely makes sense to Enumerate forward from the last item or backward from the first item, nothing precludes being able to do this.
● Data retrieval:
a. For every item accessed in any manner described above, retrieve the values of its data portion variables into their corresponding PDV host variables.
Before we proceed with the description of these Enumerate All actions, let us recall that the content of hash table H created and loaded by the template step above, shown in its logical order indicated by Item# below (which is not a hash variable in the table), looks as follows:

4.4.3 Hash Iterator Pointer
The hash iterator pointer is a concept convenient for helping visualize the enumeration process. It is somewhat similar to that of the file pointer used to describe the mechanics of reading a file.
One can imagine the iterator pointer as a cursor that at any given point in time dwells in one of the two general domains:
1. On a particular hash item inside the table.
2. Outside the table, i.e., on no hash item at all.
If no enumeration action has been taken yet, the pointer can be thought of as currently located outside the table. In this state, the Enumerate All operation can begin an enumeration process by moving the pointer into the table directly to one of the following locations inside it:
● The logically first item. In our sample table H above, it is item #1.
● The logically last item. In our table H, it is item #6.
● The key-set item. In our table H, for the item group with K=3, it is item #4.
As a result, the pointer will be located inside the table dwelling on a certain item. Let us call it the pointer item. After the pointer has been moved into the table, an enumeration action that follows can move the iterator pointer from the pointer item:
● To the item immediately following the pointer item - if the pointer item is not the last table item.
● To the item immediately preceding the pointer item - if the pointer item is not first table item.
● Outside the table - if the pointer item is the first or the last table item (or both in case there is only one item in the table).
The item to which the pointer has moved now becomes the pointer item itself. It is said that the pointer item is locked by the hash iterator. What it really means is that while the pointer dwells on the item, it cannot be removed. (In fact, as we will see in more detail later, all the items in the item group with the same key as the pointer item are also locked.) As opposed to that, when the pointer is located outside the table, no pointer item exists and so no item is locked. Note that the iterator pointer can be moved out of the table only if the current item is first or the last - it cannot be done directly from any other pointer item in the middle of the table.
Overall, the current position of the iterator pointer indicates what kind of enumerating actions can or cannot be performed next. Thus, the iterator pointer concept is useful from the standpoint of thinking about an enumeration process visually. Also, it appears to be handy semantically. There is no scalar or non-scalar field accessible to our DATA step program that represents the value of the pointer. It is just a semantic construct to aid in the understanding of the Enumerate All operation facilities.
4.4.4 Direct Iterator Access: First Item
The hash iterator object provides a means to access the logically first item regardless of its key directly. The latter means that the iterator pointer can be moved to the first item regardless of its current location (either inside or outside the table) and without the need to visit any other items. Let us look at how the hash object tools facilitate this functionality and bear in mind that everything said about direct access to the logically first item pertains, almost to a tee, to direct access to the logically last item as well.
The primary hash iterator tool that activates this action is the FIRST method, its name speaking for itself. It can be called both when the iterator pointer (a) is originally located outside the table or (b) already dwells
on a pointer item. Let us first consider the case when it is located outside the table at the time of call. Consider this code snippet:
Program 4.16 Chapter 4 Access First Item Snippet.sas
call missing (K, D) ;
put K= D= ;
RC = IH.FIRST() ;
put K= D= RC= ;
Because no enumerating action had been taken yet, the iterator pointer is outside the table at the time of the method call. Here the host variables K and D are preset to missing values only for the sake of illustrating the principle.
Before running the template step with this snippet, let us recall that in it, key variable K was added to the data poriton on purpose:
H.definedata ("D", "K") ;
Now if we insert the snippet into the template step above and run it, it prints in the SAS log:
K=. D=
K=2 D=B RC=0
As we see, as a result of the successful (RC=0) method call, the originally missing values of PDV host variables K and D have been replaced with the values of their corresponding hash variables from the logically first item. (The reason why K has not remained missing is that it was defined in the data portion in addition to the key portion as shown above.) In other words, the method call accesses the logically first item and performs the data retrieval.
As a result of the FIRST method call, the pointer has been moved to the logically first item inside the table. Let us call the method once again:
Program 4.17 Chapter 4 Access First Item Twice Snippet.sas
call missing (K, D) ;
put K= D= ;
RC = IH.FIRST() ;
put K= D= RC= ;
RC = IH.FIRST() ;
put K= D= RC= ;
Rerunning the template step with this snippet inserted produces the following in the SAS log:
K=. D=
K=2 D=B RC=0
K=2 D=B RC=0
In other words, calling the FIRST method results in the same outcome irrespective of whether the call pointer was outside the table or already dwelled on the first item. If your power of inductive reasoning makes you suspect that calling FIRST always results in the same outcome regardless of the pointer's pre-call location, your intuition does not deceive you: This is indeed the case.
Let us draw some conclusions and add a few notes:
● Calling the FIRST iterator method accesses the logically first item in the table directly.
● It moves the iterator pointer to the first table item, no matter where the pointer is located before the call, whether it is on any other item or outside the table.
● Therefore, calling FIRST repeatedly always results in the same outcome (provided that, between the calls, the first item has not been deleted or updated).
● It extracts only the values of the data portion, but not of the key portion, variables into their PDV host variables; in this case, into variables D and K. The value of K is retrieved because it is also included in the data portion.
● The values of the key PDV host variables before the call are irrelevant. The FIRST method does not use them; or, for that matter, it needs no key at all to do its job. It merely moves the interator pointer directly to the first item to access it.
● Calling the FIRST method is always successful, except when the table is empty - i.e., contains no items. Hence, if the table is not empty, it can be used unassigned.
● The method has no argument tags. Thus, it is always called implicitly.
4.4.5 Direct Iterator Access: Last Item
Accessing the logically last directly is ideologically identical to that of accessing the logically first item directly. The only difference is that instead of the FIRST method, the LAST method must be used.
Still keeping variable K in the data portion, let us replace the last snippet above with this:
Program 4.18 Chapter 4 Access Last Item Twice Snippet.sas
call missing (K, D) ;
put K= D= ;
RC = IH.LAST() ;
put K= D= RC= ;
RC = IH.LAST() ;
put K= D= RC= ;
and rerun the template step. It will print the following in the SAS log:
K=. D=
K=3 D=F RC=0
K=3 D=F RC=0
This agrees with the (K,D)=(3,F) values of the logically last item. The picture observed here logically matches to a tee the picture after the two successive FIRST method. The only difference is that instead of the logically first item, the iterator pointer accesses the logically last item, and so the different data portion values are retrieved into the PDV.
Other than that, everything else said with regard accessing the first item directly using the FIRST method and the details of its activity applies to accessing the last item as well.
4.4.6 Direct Iterator Access: Key-Item
This component of the Enumerate All operation stands apart from the rest because it is the only one which requires a key-value to work. This is because this action, unlike the rest of Enumerate All operation actions, is used to access a specific key-item based on its key-value. It can work either stand-alone to retrieve the data just from the key item or used to start enumerating other items in the table forward or backward sequentially.
It may seem that this kind of functionality is already provided by the Keynumerate operation. Indeed, we can use the latter to point at the item group with a given key and enumerate the items within the group. However, with Keynumerate, such access is restricted to that particular item group, whose boundaries the operation cannot cross without unsetting its item list. Enumerate All is free of such constraints: After a key-item has been latched onto, it can use it as a starting point to enumerate any number of items in the table below or above the key-item crossing any item group.
Let us look at our sample table H and imagine that we want to access, via the hash iterator, an item with K=3 directly, regardless of where the iteration pointer currently dwells. This purpose is served by the SETCUR method. However, a question immediately arises. In our table H, there are three items in the item group with K=3, as shown in this subset:

So, which one of these items are we going to get as the key-item? The way the SETCUR method works resolves the ambiguity by making the choice for us. Let us insert this code snippet in the template step and run it:
Program 4.19 Chapter 4 Access Key-item Snippet.sas
call missing (K, D) ;
put K= "IS NOT in the table:" @ ;
RC = IH.SETCUR() ;
put +1 (K D RC) (=) ;
put "K=3 EXISTS in the table:" @ ;
RC = IH.SETCUR(KEY:3) ;
put +1 (K D RC) (=) ;
In response, we get this printout in the SAS log:
K=. IS NOT in the table: K=. D= RC=160038
K=3 EXISTS in the table: K=3 D=D RC=0
This output demonstrates the following:
● The first SETCUR call is implicit. Hence, it accepts the current PDV host value of K, which at this point is missing. Since there is no such key-value in the table, the call fails with RC≠0 and no data retrieval occurs, so the host variable values remain intact.
● The second SETCUR call is explicit and is given the key-value of 3. While the table has an item group with 3 items with this key, the method sets the iterator pointer at the logically first item in the group (item #4). Then it retrieves its data-values, overwriting the values of the PDV host variables - in this case, both D and K because both are included in the data portion.
Note that the result of calling SETCUR does not depend on how the table is ordered. Ordering the table by its key, as we already know, does not change the relative sequence of the items within the same-key item groups, which always remains as originally inserted.
4.4.7 Sequential Access
Direct access to the first item, last item, and key-item are important components of the Enumerate All operation, for they can access items from which the whole table can be enumerated. But sequential access to table items is the backbone of the operation because it makes it possible to scroll through a hash table one item at a time using a previously accessed item as the point of departure. Thus, by enumerating sequentially, we can cover the entire table or any part of it thereof.
To enumerate the table sequentially in its logical order and in reverse, the Enumerate All operation works in essentially the same way. The only difference between the two modes is the direction in which the items are enumerated and the methods called to activate them.
There are a number of conceivable ways an iterative enumeration process can be organized:
● Enumerate forward starting from the logically first item in the table.
● Enumerate backward starting from the logically last item in the table.
● Enumerate forward or backward starting from a key-item.
● Enumerate forward or backward starting from the current pointer item.
Before any enumeration action has been taken yet, the iterator pointer dwells outside the table. So, to start enumerating sequentially, it must be moved into the table. As we already know, the effect can be achieved by priming the process by accessing the first item, the last item, and a key-item directly. Let us proceed in this order.
4.4.8 Enumerating from the End Points
The end points are the logically first and last items. Starting from the logically first item can be done by calling the FIRST method. After that, the next item can be enumerated by calling the NEXT method. This is what the snippet below does:
Program 4.20 Chapter 4 Enumerate from First Item Snippet.sas
call missing (K, D) ;
RC = IH.FIRST() ;
put RC= K= D= ;
RC = IH.NEXT() ;
put RC= K= D= ;
Inserting it in the template step (with K still kept in the data portion) and running it prints the following in the SAS log:
RC=0 K=2 D=B
RC=0 K=2 D=C
If we want to enumerate more items going forward, calling the NEXT method in this manner, one call at a time, is rather impractical. The obvious solution is to enclose the NEXT method call in a DO loop. For example, to enumerate all items in the table forward, we can code:
Program 4.21 Chapter 4 Enumerate from First Item Forward Snippet.sas
call missing (K, D) ;
do RC = IH.FIRST() by 0 while (RC = 0) ;
put RC= K= D= ;
RC = IH.NEXT() ;
end ;
put RC= ;
(As a side note, the by-specification is included to ensure that the DO loop will iterate more than once. This is because when only the from-specification is present, it stops after the first iteration. The by-specification is set to 0 to prevent the RC value set in the from-specification from being incremented.) Running the template step with this excerpt inserted, we get the following output:
RC=0 K=2 D=B
RC=0 K=2 D=C
RC=0 K=1 D=A
RC=0 K=3 D=D
RC=0 K=3 D=E
RC=0 K=3 D=F
RC=160038
It corresponds exactly with the content and logical order of the table. A few points can be emphasized here:
● The return code of the FIRST method call is assigned to the FROM expression of the DO loop, RC being used as the loop index. The call enumerates the logically first item. Hence, by the time the PUT statement is executed, the values of the pair (K,D)=(2,B) are already in the PDV host variables, and so this is what the PUT statement writes.
● Since the TO expression is absent from the loop, BY 0 is coded in to ensure that the loop does not stop after the first iteration and the subsequent RC modifications occur only inside the body of the loop.
● The WHILE condition is what causes the loop to continue and to terminate. This dovetails with the BY 0 construct and the absence of the TO construct.
● After the fifth NEXT call has enumerated the logically last item, it is called again. This time, there are no more items left, and so the call fails with RC≠0, thus terminating the loop. At the same time, it moves the iterator pointer out of the table.
Enumerating sequentially backward is completely analogous to enumerating forward. The only differences are:
● Enumerate Backward begins with the logically last item.
● The primary move of the iterator pointer into the table is done using the LAST method.
● Stepping backward through the table is done using the PREV method.
Correspondingly, to enumerate the whole table backward, the last snippet has to be changed to:
Program 4.22 Chapter 4 Enumerate from Last Item Backward Snippet.sas
call missing (K, D) ;
do RC = IH.LAST() by 0 while (RC = 0) ;
put RC= K= D= ;
RC = IH.PREV() ;
end ;
put RC= ;
Running it as part of the template DATA step prints the following in the SAS log:
RC=0 K=3 D=F
RC=0 K=3 D=E
RC=0 K=3 D=D
RC=0 K=1 D=A
RC=0 K=2 D=C
RC=0 K=2 D=B
RC=160038
In this case, the output sequence totally agrees with listing the items in the sequence opposite to the logical order of the table, which is what the intent of enumerating backward is in the first place. Note that in this case, just like with the NEXT method before, the final call to PREV fails and, by doing so, terminates the loop and moves the iterator pointer out of the table.
4.4.9 Iterator Priming Using NEXT and PREV
The enumerating loops shown above can be coded more simply, and here is why. When the iterator pointer dwells outside the table - and only outside the table:
● Calling the NEXT method has the same effect as calling the FIRST method.
● Calling the PREV method has the same effect as calling the LAST method.
Therefore, in the Enumerate Forward loop shown above, FIRST can be recoded as NEXT, without any change in the outcome:
Program 4.23 Chapter 4 Iterator Priming Next Method Snippet.sas
do RC = IH.NEXT() by 0 while (RC = 0) ;
put RC= K= D= ;
RC = IH.NEXT() ;
end ;
But then there no longer exists any reason for coding NEXT twice, and so the loop can be further reduced to the following form:
Program 4.24 Chapter 4 Iterator Priming Next Method Terse Snippet.sas
do while (IH.NEXT() = 0) ;
put K= D= ;
end ;
Likewise, the backward-enumerating loop can be recoded as:
Program 4.25 Chapter 4 Iterator Priming Prev Method Terse Snippet.sas
do while (IH.PREV() = 0) ;
put K= D= ;
end ;
Again, neither recoded loop changes the result of respective forward and backward enumeration.
4.4.10 FIRST/LAST vs NEXT/PREV
Coding this way being rather concise and elegant, it raises a question: Why not ditch the FIRST and LAST methods altogether and use the NEXT and PREV methods at all times? There are a number of reasons and meaningful distinctions.
Namely, because the FIRST and LAST methods are direct access methods, the following are true:
● They move the iterator pointer to their respective end points unconditionally.
● That is, they do it regardless of where the pointer currently dwells, whether on some pointer item inside the table or outside it.
● The result of calling either method repeatedly is always exactly the same.
● They fail only if the table has no items. Otherwise, they always succeed.
● Neither method can move the pointer out of the table (and this unlock the respective end point item).
By contrast, because the NEXT and PREV methods are sequential access methods, the following are true:
● They move the iterator pointer to the logically first and last items, respectively, only when before the call, the pointer is not inside the table.
● Hence, these methods are good for setting the end points only: (a) if no enumeration action has been taken yet; and (b) after either method has moved the iterator out of the table as a result of being called past the respective end point.
● Calling these methods repeatedly results in enumerating the next or previous item and moving the pointer one item further in the corresponding direction.
● In addition to failing when the table is empty, these methods also fail if there are no more items to enumerate forward or backward, respectively. In this case, they unlock the end point items by moving the iterator out of the table.
In other words, compared to the NEXT and PREV methods, the FIRST and LAST methods possess a number of distinct features that are valuable under specific programming scenarios. In fact, combining any or all of these methods in the manner dictated by a specific task is what makes the Enumerate All operation powerful and flexible.
4.4.11 Keeping the Iterator in the Table
The advantage of ending the loop using RC≠0 from the extra call to NEXT or PREV past their respective end point items is that it makes the iterator pointer leave the table, and so neither item is any longer locked.
In certain situations, however, it is useful to keep the iterator pointer confined inside the table. For example, imagine that we need to enumerate our sample table H repeatedly, without re-enumerating the end points, in the following manner:
● Looping forward, from item #1 through item #6.
● Looping backward from item #5 through item #1.
Stopping the forward loop with the failing call to the NEXT method is ill-suited for the task. Indeed, since it moves the pointer out of the table, it has to be moved into the table again to enumerate backward. But it means revisiting item #6, which we want to avoid. Thus, to perform the task as outlined, another way of terminating the loop has to be found.
One such way is offered by using the NUM_ITEMS attribute. It tells us the number of items in the table, at any given run-time point, a priori. So, the goal can be attained by coding the two successive DO loops. The
entire step, rather than the snippet, is shown since its DATA statement differs from that in the template step:
Program 4.26 Chapter 4 Keeping Iterator in Table.sas
data Forward (keep=ItemNo K D)
Backward(keep=ItemNo K D)
;
dcl hash H (multidata:"Y", ordered:"N") ;
H.definekey ("K") ;
H.definedata ("D", "K") ;
H.definedone () ;
do K = 1, 2, 2, 3, 3, 3 ;
q + 1 ;
D = char ("ABCDEF", q) ;
H.add() ;
end ; ❶
dcl hiter IH ("H") ;
do ItemNo = 1 to H.Num_Items ; ❷
RC = IH.NEXT() ; ❸
output Forward ;
end ;
/* end of forward loop */ ❹
do ItemNo = H.Num_Items - 1 by -1 to 1 ; ❺
RC = IH.PREV() ; ❻
output Backward ;
end ;
run ;
❶ At this point, table H has been loaded with the same content as before:
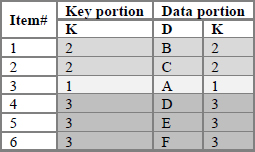
❷ Make this DO loop execute exactly as many times as there are items in the table.
❸ Call the NEXT method. The first call moves the iterator pointer to the first item in the table. Each ensuing call enumerates the next item in the table order and retrieves the values of hash variables (K,D) into their PDV host variables (K,D). The OUTPUT statement writes these PDV values, along with that of ItemNo, to the output data set Forward.
❹ At this point, the iterator pointer dwells on the last item.
❺ Make this DO loop execute one fewer time than the number of items in the table because we now want to enumerate items #5 through #1 backward.
❻ Call the PREV method. The first call moves the pointer from item #6 to item #5. Each ensuing call enumerates the next item in the reverse table order and retrieves the values of hash variables (K,D) into their PDV host variables (K,D). The OUTPUT statement writes these PDV values, along with that of ItemNo, to the output data set Backward.
Running the template step generates two output test data sets Forward and Backward. Their contents are shown in the matrix below side by side:

The output shows that the enumeration process works as intended. In this manner, merely by using a single variable like ItemNo to track the location of the iterator pointer, we can walk forward and backward through the table without ever leaving its boundaries.
4.4.12 Enumerating Sequentially from a Key-Item
As we already know, accessing the key-item directly using the SETCUR method with a given key-value moves the iterator pointer, regardless of where it is currently located, to the key-item, which is the logically first item of the same-key item group with the given key-value. Hence, by doing it first, it is possible to enumerate beginning from the key-item, rather than from either end point of the table. The ability to do so has a number of useful applications and performance advantages. This is because the ability to enumerate directly from the key-item in either direction makes it unnecessary to iterate toward it from either end point of the table in order to reach it.
For example, suppose that we have our table H sorted using the argument tag ORDERED:"A" instead of ORDERED:"N", so its content now looks as follows:

Suppose further that we want to discover the key and data values of the 2 items with K<3 immediately preceding the item group with K=3. Of course, we can enumerate from the first item of the table forward until we hit K=3 and then enumerate two steps backward. Or, we can enumerate from the end of the table backward till we hit K<3 and then take one more step backward. The problem with both of these propositions is that since we do not know a priori where the item group with K=3 is located in the table, we do not know which path - from the beginning of from the end - is shorter or longer. Moreover, by guessing either approach, we may end up scanning almost the entire table, while in fact we only need to enumerate but two items.
The ability to access the key-item with K=3 directly rids us of this dilemma because we can use SETCUR to latch onto the logically first item in the item group with K=3 at once and then step sequentially only two items backward. This is what the following snippet does:
Program 4.27 Chapter 4 Enumerating from Key-Item Snippet.sas
RC = IH.SETCUR(KEY:3) ;
do count = 1 to 2 while (RC = 0) ;
RC = IH.PREV() ;
if RC = 0 then put K= D= RC= ;
end ;
Running this snippet as part of the template step with ORDERED:"Y" results in the following text in the SAS log:
K=2 D=C RC=0
K=2 D=B RC=0
It shows that the code works as intended. The RC=0 condition in the WHILE clause is needed just as a precaution to stop the loop in case there is only one item with K<3 (meaning that it is the first item in the table). To check it for robustness, we can change KEY:3 to KEY:2, which means that now we would be seeking two items with K<2, while there is just one item like that in the table with K=1, and it is the first in the table. Running the step with this change would produce:
K=1 D=A RC=0
In other words, the PREV method enumerates the only item available to it, and stops the loop by generating RC≠0 when there are no more items in the table for it to access.
4.4.13 Harvesting Same-Key Items from a Key-Item
Previously, we have shown how the data can be "harvested" from all the items in a same-key item group using the KeyNumerate operation. The availability of the hash iterator object and its ability to enumerate from a key-item offers an alternative.
For example, suppose that we want to collect the data from all the items where K=2. As we know, if we call the SETCUR with K=2, it will point to the logically first item in the item group with K=2- i.e., to item #1 in the case of our table H. Also recall that no matter how the table is ordered, the items sharing the same key-value are always grouped together. Hence, starting with the key-item, we can simply enumerate forward until either (a) a different key is encountered or (b) we have reached the end of the table. Translating it into the SAS language, we can code:
Program 4.28 Chapter 4 Harvesting Same Key Items from Key Item Snippet.sas
call missing (K, D) ;
_K = 2 ;
do RC = IH.SETCUR(KEY:_K) by 0 while (RC = 0 and K = _K) ;
put K= D= RC= ;
RC = IH.NEXT() ;
end ;
put RC= ;
Running the template step with this snippet included, we get in the SAS log:
K=2 D=B RC=0
K=2 D=C RC=0
RC=0
For the item group with K=2, the loop is terminated because a different key, K=1, is encountered. Since at this point the last item in the table has not been reached, we still have RC=0.
The group with K=3 represents the other situation where the last item in the group is at the same time the last item in the table. So, if we recode _K=2 above as _K=3 and rerun, the step will print in the SAS log:
K=3 D=D RC=0
K=3 D=D RC=0
K=3 D=F RC=0
RC=160038
This time, the loop is stopped not because a different key-value has been encountered but due to the NEXT method call's attempt to enumerate past the last item in the table, thus setting RC≠0.
4.4.14 The Hash Iterator and Item Locking
Before we introduce the issue, let us again refresh in the mind the image of our sample table H created and populated in the template DATA step (with ORDERED:"N"):

Next, let us consider the following test code snippet:
Program 4.29 Chapter 4 Iterator Locking Snippet.sas
_K = 2 ; * <--Key-value to delete ; ❶
RC = IH.FIRST() ; ❷
* RC = IH.NEXT() ; ❸
* RC = IH.NEXT() ;
put "Item:" +3 K= D= RC= ; ❺
RC = H.REMOVE(KEY:_K) ; ❻
put "Remove:" +1 RC= ;
RC = H.CHECK(KEY:_K) ; ❹
put "Check:" +2 RC= ;
Before running the snippet as part of the template step, let us review what this code does:
❶ An auxiliary variable _K is assigned the key-value for the items intended for deletion. By varying it, we can see how it affects the outcome.
❷ Call the FIRST method to set the iterator pointer at item #1. Its key is K=2. Note that this has nothing to do with the fact that we assigned _K=2.
❸ For the time being, both NEXT calls are inactivated. By activating one or both of them, we can observe how moving the pointer forward to items #2 and #3 affects the result.
❹ The CHECK method is called to see whether the Delete operation has succeeded. If it has, the call will return RC≠0.
❺ The PUT statements are used to write test information to the SAS log.
❻ The REMOVE method call is an attempt to perform the Delete All operation against the item group with K=2. It should be successful, both items #1 and #2 would be purged, and the call would return RC=0.
Now, it we insert the snippet in the template step and run it, we will discover the following error messages in the SAS log:
Item: K=2 D=B RC=0
ERROR: Cannot remove record from a hash object which has been locked by an iterator at line <X> column <Y>.
ERROR: DATA STEP Component Object failure. Aborted during the EXECUTION phase.
Note that the PUT statements following the REMOVE call print nothing. These statements are never executed because the step generates an error and is terminated altogether immediately as a result. The error message makes it clear that the issue is in the locking of hash items.
4.4.15 Locking and Unlocking
This simple test illustrates the phenomenon of the iterator item locking. It makes it pretty obvious that the item pointed to by the iterator pointer is locked by the iterator and thus cannot be deleted from the table. In turn, it raises the question: Does this cause any other items to be locked as well; and if yes, then which ones?
To find out, let us first change the _K=2 to _K=3 and rerun the step. The intent is to see if the pointer dwelling on item #1 with K=2 prevents items with another key from being deleted. This time, the step runs normally and reports the following in the log:
Item: K=2 D=B RC=0
Remove: RC=0
Check: RC=160038
In other words, the item group with K=3 was successfully deleted, even though the first item with K=2 is locked as a result of the FIRST call. Thus, having an item locked in one same-key item group does not affect the ability to delete an item group with a different key.
Now let us restore _K=2 and uncomment the first NEXT call:
_K = 2 ;
RC = IH.FIRST() ;
RC = IH.NEXT() ;
* RC = IH.NEXT() ;
The NEXT call causes the pointer to move to item #2, whose key is also K=2. Running the template step this way brings back the error message and step termination. Logically, it adds up because now item #2 is locked, while the REMOVE call aims to delete both item #2 and #1, both having K=2.
From what we have seen above for _K=3, it is logical to expect that if we move the pointer out of the item group with K=2 to the next item #3, we should be able to delete the item group with K=2 successfully since the iterator will no longer lock either item in the K=2 item group. This is indeed the case: If we now activate, in addition to the first, the second call to NEXT, the latter is expected to move the pointer to item #3 with K=1:
_K = 2 ;
RC = IH.FIRST() ;
RC = IH.NEXT() ;
RC = IH.NEXT() ;
So, with this change, the step runs normally and prints the following in the SAS log:
Item: K=1 D=A RC=0
Remove: RC=0
Check: RC=160038
Expectedly, the CHECK call fails with RC≠0 because the items with K=2 have been deleted and so the key is no longer in the table.
In this case, the second NEXT call moves the pointer out of the K=2 item group to the immediately adjacent item group where K=1. Does it matter from the standpoint of unlocking the K=2 item group; or will moving the pointer anywhere out of the group unlock it? The answer to this question is: It does not matter where the pointer is moved as long as it is moved out of the group, including out of the table altogether. For example, we can replace the pair of the NEXT calls above with either of the following two calls:
RC = IH.PREV() ;
Or:
RC = IH.SETCUR(KEY:3) ;
Because the FIRST call makes the first table item the pointer item, the PREV method has no item to fetch, and so the call will move the pointer out of the table. Calling SETCUR as shown above moves the pointer directly to the first item in the K=3 item group. Either way, the pointer is moved out of the K=2 item group. So, if the template step is now rerun with the call to PREV or call to SETCUR as shown above instead of the two NEXT calls, it still runs normally and the K=2 item group is deleted successfully.
Note that when SETCUR method is used to move the pointer out of a same-key item group where it currently dwells, it must be called with a key-value different from the one identifying the group but still present in the table. Calling it with a key-value absent from the table will not move the pointer out of its current position.
4.4.16 Locking Same-Key Item Groups
The examples presented above leave one final aspect unclear. Since in all of them the Delete All operation attempts to delete all items from a same-key item group, the removal is impossible regardless of which item in the group is locked. However, in addition to Delete All, we also have the Selective Delete operation to delete individual items from a same-key item group rather than the entire group.
So, a germane question arises: Does the hash iterator lock the individual item on which the iterator pointer dwells; or does it lock the entire same-item group to which the pointer item belongs? If we could delete one item from a same-key group while the iterator pointer dwells on another, the answer would be "individual point item"; otherwise, it would be "entire same-item group". The question is easy to answer using the item group with K=2 (items #1 and #2) from our sample table H as a guinea pig. Let us insert this code snippet in the template step:
Program 4.30 Chapter 4 Locking Same Item Key Group Snippet.sas
RC = IH.FIRST() ; ❶
RC = H.FIND(KEY:2) ; ❷
RC = H.FIND_NEXT(KEY:2) ; ❷
RC = H.REMOVEDUP(KEY:2) ; ❸
put RC= ;
The intent of this test case is to:
❶ Call the FIRST method to set the iterator pointer on item #1, the first item in the K=2 group.
❷ Call the FIND and then FIND_NEXT methods to move the Keynumerate pointer to item #2. Note that these methods are not iterator object methods and thus do not affect the position of the iterator pointer, which after these calls keeps dwelling on item #1.
❸ Call the REMOVEDUP method in an attempt to remove item #2, presumably not locked because the iterator pointer still dwells on item #1.
Running the template step with this snippet results in the same log error message "locked by the iterator" we have seen earlier. The unescapable conclusion is that when a pointer item is locked by the iterator:
● All the items in the same-key item group to which the pointer item belongs are locked.
● In other words, iterator locking occurs, not at the level of an individual point item, but at the level of its entire same-key item group.
4.4.17 Locking the Entire Hash Table
The verbiage in the "locked by the iterator" SAS log error message suggests that the entire table is locked when the iterator pointer dwells inside it. However, it is more intimidating than necessary, for as we have established earlier, it is true only in the situation when the table contains a single same-key item group - in other words, when all items in the table have the same key-value. Otherwise, only the same-key item group containing the pointer item is locked; and the items from the rest of the groups can be deleted successfully, whether unconditionally or selectively. To unlock an item group, all you need to do is to move the iterator pointer out of it, no matter where.
The impression that "the entire table is locked by the iterator" is most often created when an attempt to perform the Clear operation is made- i.e., to delete every single item from the table. Since the CLEAR method aims to purge every item, it does not matter on which particular item the iterator pointer dwells since the item is inevitably a target for deletion. Therefore, the only way to make the CLEAR method succeed when a hash table has an iterator object linked to it is to ensure that the iterator pointer is out of the table.
Often, this state occurs naturally as a result of the enumerating logic. For example, if an enumerating loop is terminated with the NEXT or PREV method called beyond the last or first table item, respectively, the iterator pointer is moved outside the table as a result, and so no item in the table is locked any longer.
Otherwise, if the iterator pointer, for one reason or another, still dwells inside the table when it has to be cleared, a surefire method to guarantee that the CLEAR method succeeds is to force the iterator pointer out of the table. Either pair of the statements below:
RC = H.FIRST() ;
RC = H.PREV() ;
Or:
RC = H.LAST() ;
RC = H.FIRST() ;
is equally good for the purpose. The first moves the pointer directly from any location to the first item and then forces it out of the table with the failing call past the end point. The second does the same in the opposite direction. After either of these statement pairs has been executed, the CLEAR method will always succeed since no item in the table will be locked by the iterator.
4.4.18 ENUMERATE ALL Operation Hash Tools
● Statements: DECLARE (DCL) HITER.
● Operators: _NEW_.
● Methods: FIRST, LAST, NEXT, PREV, SETCUR.
● Argument Tags: KEY.
4.4.19 Hash-PDV Interaction
Any iterator method, if it succeeds, performs the indirect Retrieve operation by extracting the values of the data portion hash variables and overwriting their PDV host variable counterparts with them.