
CAPTCHA stands for Completely Automated Public Turing test to tell Computers and Humans Apart. As the acronym suggests, it is a test to determine whether the user is human or not. A typical CAPTCHA consists of distorted text, which a computer program will find difficult to interpret but a human can (hopefully) still read. Many websites use CAPTCHA to try and prevent bots from interacting with their website. For example, my bank website forces me to pass a CAPTCHA every time I log in, which is a pain. This chapter will cover how to solve a CAPTCHA automatically, first through Optical Character Recognition (OCR) and then with a CAPTCHA solving API.
In the preceding chapter on forms, we logged in to the example website using a manually created account and skipped automating the account creation part, because the registration form requires passing a CAPTCHA. This is how the registration page at http://example.webscraping.com/user/register looks:
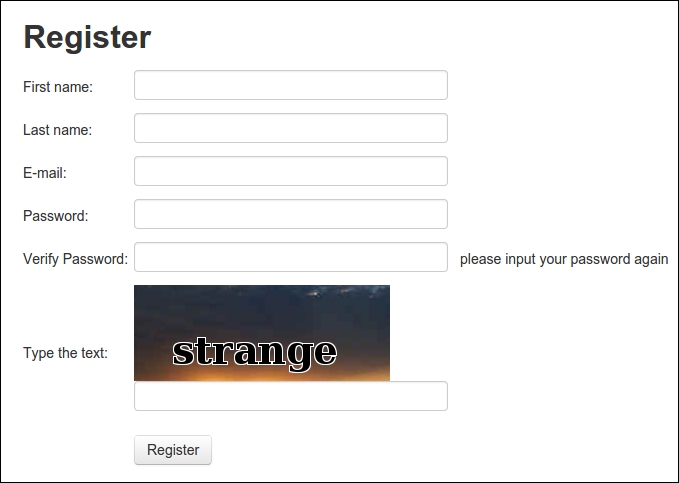
Note that each time this form is loaded, a different CAPTCHA image will be shown. To understand what the form requires, we can reuse the parse_form() function developed in the preceding chapter.
>>> import cookielib, urllib2, pprint
>>> REGISTER_URL = 'http://example.webscraping.com/user/register'
>>> cj = cookielib.CookieJar()
>>> opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
>>> html = opener.open(REGISTER_URL).read()
>>> form = parse_form(html)
>>> pprint.pprint(form)
{'_formkey': '1ed4e4c4-fbc6-4d82-a0d3-771d289f8661',
'_formname': 'register',
'_next': '/',
'email': '',
'first_name': '',
'last_name': '',
'password': '',
'password_two': None,
'recaptcha_response_field': None}All of the fields in the preceding code are straightforward, except for recaptcha_response_field, which in this case requires extracting strange from the image.
Before the CAPTCHA image can be analyzed, it needs to be extracted from the form. FireBug shows that the data for this image is embedded in the web page, rather than being loaded from a separate URL:

To work with images in Python, we will use the Pillow package, which can be installed via pip using this command:
pip install Pillow
Alternative ways to install Pillow are covered at http://pillow.readthedocs.org/installation.html.
Pillow provides a convenient Image class with a number of high-level methods that will be used to manipulate the CAPTCHA images. Here is a function that takes the HTML of the registration page, and returns the CAPTCHA image in an Image object:
from io import BytesIO
import lxml.html
from PIL import Image
def get_captcha(html):
tree = lxml.html.fromstring(html)
img_data = tree.cssselect('div#recaptcha img')[0].get('src')
img_data = img_data.partition(',')[-1]
binary_img_data = img_data.decode('base64')
file_like = BytesIO(binary_img_data)
img = Image.open(file_like)
return imgThe first few lines here use lxml to extract the image data from the form. This image data is prepended with a header that defines the type of data. In this case, it is a PNG image encoded in Base64, which is a format used to represent binary data in ASCII. This header is removed by partitioning on the first comma. Then, this image data needs to be decoded from Base64 into the original binary format. To load an image, PIL expects a file-like interface, so this binary data is wrapped with BytesIO and then passed to the Image class.
Now that we have the CAPTCHA image in a more useful format, we are ready to attempt extracting the text.
Note
Pillow vs PIL
Pillow is a fork of the better known Python Image Library (PIL), which currently has not been updated since 2009. It uses the same interface as the original PIL package and is well documented at http://pillow.readthedocs.org. The examples in this chapter will work with both Pillow and PIL.