
Currently, Facebook is the world's largest social network in terms of monthly active users, and therefore, its user data is extremely valuable.
Here is an example Facebook page for Packt Publishing at https://www.facebook.com/PacktPub:
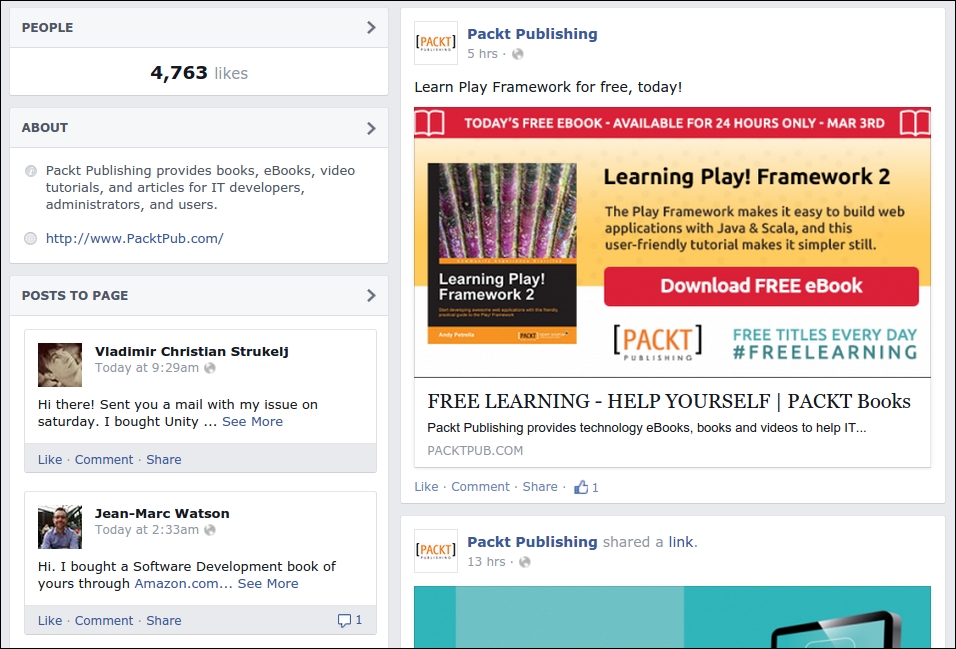
Viewing the source of this page, you would find that the first few posts are available, and that later posts are loaded with AJAX when the browser scrolls. Facebook also has a mobile interface, which, as mentioned in Chapter 1, Introduction to Web Scraping, is often easier to scrape. The same page using the mobile interface is available at https://m.facebook.com/PacktPub:
If we interacted with the mobile website and then checked Firebug we would find that this interface uses a similar structure for the AJAX events, so it is not actually easier to scrape. These AJAX events can be reverse engineered; however, different types of Facebook pages use different AJAX calls, and from my past experience, Facebook often changes the structure of these calls so scraping them will require ongoing maintenance. Therefore, as discussed in Chapter 5, Dynamic Content, unless performance is crucial, it would be preferable to use a browser rendering engine to execute the JavaScript events for us and give us access to the resulting HTML.
Here is an example snippet using Selenium to automate logging in to Facebook and then redirecting to the given page URL:
from selenium import webdriver
def facebook(username, password, url):
driver = webdriver.Firefox()
driver.get('https://www.facebook.com')
driver.find_element_by_id('email').send_keys(username)
driver.find_element_by_id('pass').send_keys(password)
driver.find_element_by_id('login_form').submit()
driver.implicitly_wait(30)
# wait until the search box is available,
# which means have successfully logged in
search = driver.find_element_by_id('q')
# now logged in so can go to the page of interest
driver.get(url)
# add code to scrape data of interest here ...This function can then be called to load the Facebook page of interest and scrape the resulting generated HTML.
As mentioned in Chapter 1, Introduction to Web Scraping, scraping a website is a last resort when their data is not available in a structured format. Facebook does offer API's for some of their data, so we should check whether these provide access to what we are after before scraping. Here is an example of using Facebook's Graph API to extract data from the Packt Publishing page:
>>> import json, pprint
>>> html = D('http://graph.facebook.com/PacktPub')
>>> pprint.pprint(json.loads(html))
{u'about': u'Packt Publishing provides books, eBooks, video tutorials, and articles for IT developers, administrators, and users.',
u'category': u'Product/service',
u'founded': u'2004',
u'id': u'204603129458',
u'likes': 4817,
u'link': u'https://www.facebook.com/PacktPub',
u'mission': u'We help the world put software to work in new ways, through the delivery of effective learning and information services to IT professionals.',
u'name': u'Packt Publishing',
u'talking_about_count': 55,
u'username': u'PacktPub',
u'website': u'http://www.PacktPub.com'}This API call returns the data in JSON format, which was parsed into a Python dict using the json module. Then, some useful features, such as the company name, description, and website can be extracted.
The Graph API provides many other calls to access user data and is documented on Facebook's developer page at https://developers.facebook.com/docs/graph-api. However, most of these API calls are designed for a Facebook app interacting with an authenticated Facebook user, and are, therefore, not useful for extracting other people's data. To extract additional details, such as user posts, would require scraping.