
So far, we have tried to scrape data from a web page the same way as introduced in Chapter 2, Scraping the Data. However, it did not work because the data is loaded dynamically with JavaScript. To scrape this data, we need to understand how the web page loads this data, a process known as reverse engineering. Continuing the example from the preceding section, in Firebug, if we click on the Console tab and then perform a search, we will see that an AJAX request is made, as shown in this screenshot:
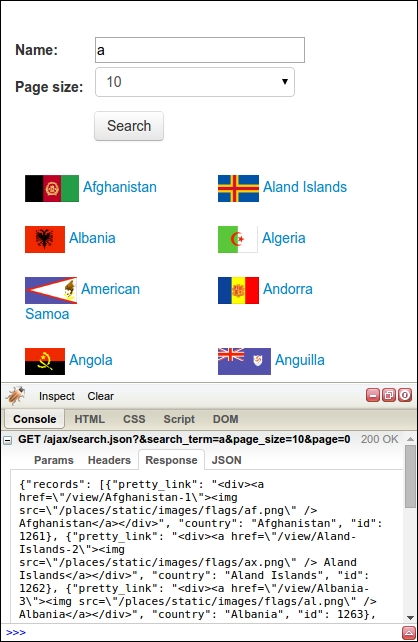
This AJAX data is not only accessible from within the search web page, but can also be downloaded directly, as follows:
>>> html = D('http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=a')The AJAX response returns data in JSON format, which means Python's json module can be used to parse this into a dictionary, as follows:
>>> import json
>>> json.loads(html)
{u'error': u'',
u'num_pages': 22,
u'records': [{u'country': u'Afghanistan',
u'id': 1261,
u'pretty_link': u'<div><a href="/view/Afghanistan-1"><img src="/places/static/images/flags/af.png" /> Afghanistan</a></div>'},
...]
}Now we have a simple way to scrape countries containing the letter A. To find the details of all these countries then requires calling the AJAX search with each letter of the alphabet. For each letter, the search results are split into pages, and the number of pages is indicated by page_size in the response. An issue with saving results is that the same countries will be returned in multiple searches—for example, Fiji matches searches for f, i, and j. These duplicates are filtered here by storing results in a set before writing them to a spreadsheet—the set data structure will not store duplicate elements.
Here is an example implementation that scrapes all of the countries by searching for each letter of the alphabet and then iterating the resulting pages of the JSON responses. The results are then stored in a spreadsheet.
import json
import string
template_url =
'http://example.webscraping.com/ajax/
search.json?page={}&page_size=10&search_term={}'
countries = set()
for letter in string.lowercase:
page = 0
while True:
html = D(template_url.format(page, letter))
try:
ajax = json.loads(html)
except ValueError as e:
print e
ajax = None
else:
for record in ajax['records']:
countries.add(record['country'])
page += 1
if ajax is None or page >= ajax['num_pages']:
break
open('countries.txt', 'w').write('
'.join(sorted(countries)))This AJAX interface provides a simpler way to extract the country details than the scraping approach covered in Chapter 2, Scraping the Data. This is a common experience: the AJAX-dependent websites initially look more complex but their structure encourages separating the data and presentation layers, which can make our job of extracting this data much easier.
The AJAX search script is quite simple, but it can be simplified further by taking advantage of edge cases. So far, we have queried each letter, which means 26 separate queries, and there are duplicate results between these queries. It would be ideal if a single search query could be used to match all results. We will try experimenting with different characters to see if this is possible. This is what happens if the search term is left empty:
>>> url = 'http://example.webscraping.com/ajax/search.json?page=0&page_size=10&search_term=' >>> json.loads(D(url))['num_pages'] 0
Unfortunately, this did not work—there are no results. Next we will check if '*' will match all results:
>>> json.loads(D(url + '*'))['num_pages'] 0
Still no luck. Now we will check '.', which is a regular expression to match any character:
>>> json.loads(D(url + '.'))['num_pages'] 26
There we go: the server must be matching results with regular expressions. So, now searching each letter can be replaced with a single search for the dot character.
Further more, you may have noticed a parameter that is used to set the page size in the AJAX URLs. The search interface had options for setting this to 4, 10, and 20, with the default set to 10. So, the number of pages to download could be halved by increasing the page size to the maximum.
>>> url = 'http://example.webscraping.com/ajax/search.json?page=0&page_size=20&search_term=.' >>> json.loads(D(url))['num_pages'] 13
Now, what if a much higher page size is used, a size higher than what the web interface select box supports?
>>> url = 'http://example.webscraping.com/ajax/search.json?page=0&page_size=1000&search_term=.' >>> json.loads(D(url))['num_pages'] 1
Apparently, the server does not check whether the page size parameter matches the options allowed in the interface and now returns all the results in a single page. Many web applications do not check the page size parameter in their AJAX backend because they expect requests to only come through the web interface.
Now, we have crafted a URL to download the data for all the countries in a single request. Here is the updated and much simpler implementation to scrape all countries:
writer = csv.writer(open('countries.csv', 'w'))
writer.writerow(FIELDS)
html = D('http://example.webscraping.com/ajax/search.json?page=0&page_size=1000&search_term=.')
ajax = json.loads(html)
for record in ajax['records']:
row = [record[field] for field in FIELDS]
writer.writerow(row)