
According to the United Nations Global Audit of Web Accessibility, 73 percent of leading websites rely on JavaScript for important functionalities (refer to http://www.un.org/esa/socdev/enable/documents/execsumnomensa.doc). The use of JavaScript can vary from simple form events to single page apps that download all their content after loading. The consequence of this is that for many web pages the content that is displayed in our web browser is not available in the original HTML, and the scraping techniques covered so far will not work. This chapter will cover two approaches to scraping data from dynamic JavaScript dependent websites. These are as follows:
- Reverse engineering JavaScript
- Rendering JavaScript
Let's look at an example dynamic web page. The example website has a search form, which is available at http://example.webscraping.com/search, that is used to locate countries. Let's say we want to find all the countries that begin with the letter A:
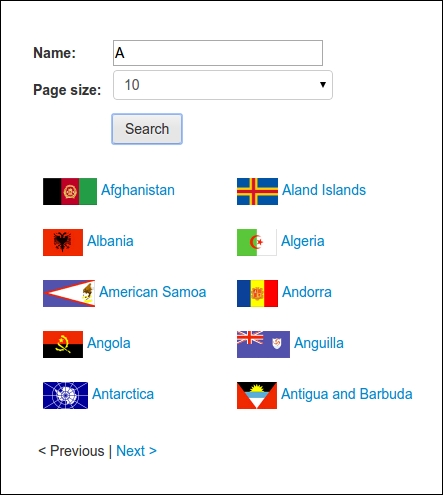
If we right-click on these results to inspect them with Firebug (as covered in Chapter 2, Scraping the Data), we would find that the results are stored within a div element of ID "results":
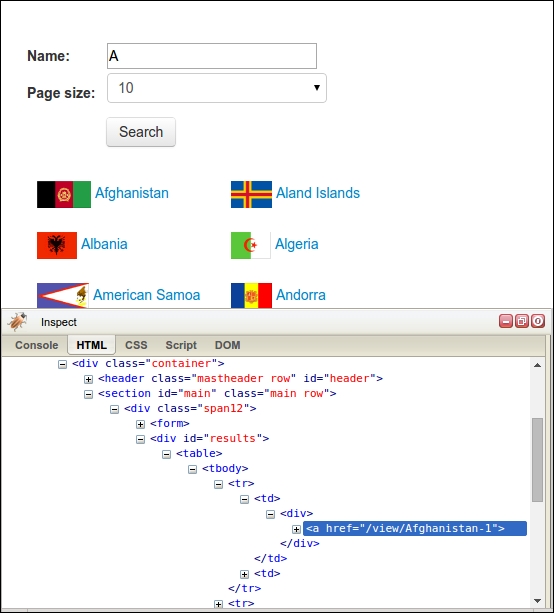
Let's try to extract these results using the lxml module, which was also covered in Chapter 2, Scraping the Data, and the Downloader class from Chapter 3, Caching Downloads:
>>> import lxml.html
>>> from downloader import Downloader
>>> D = Downloader()
>>> html = D('http://example.webscraping.com/search')
>>> tree = lxml.html.fromstring(html)
>>> tree.cssselect('div#results a')
[]The example scraper here has failed to extract results. Examining the source code of this web page can help you understand why. Here, we find that the div element we are trying to scrape is empty:
<div id="results"> </div>
Firebug gives us a view of the current state of the web page, which means that the web page has used JavaScript to load search results dynamically. In the next section, we will use another feature of Firebug to understand how these results are loaded.
Note
What is AJAX
AJAX stands for Asynchronous JavaScript and XML and was coined in 2005 to describe the features available across web browsers that made dynamic web applications possible. Most importantly, the JavaScript XMLHttpRequest object, which was originally implemented by Microsoft for ActiveX, was available in many common web browsers. This allowed JavaScript to make HTTP requests to a remote server and receive responses, which meant that a web application could send and receive data. The traditional way to communicate between client and server was to refresh the entire web page, which resulted in a poor user experience and wasted bandwidth when only a small amount of data needed to be transmitted.
Google's Gmail and Google Maps were early examples of the dynamic web applications and helped take AJAX to a mainstream audience.