
Alright, let's look at another example of using Spark in MLlib, and this time we're going to look at k-means clustering, and just like we did with decision trees, we're going to take the same example that we did using scikit-learn and we're going to do it in Spark instead, so it can actually scale up to a massive Dataset. So, again, I've made sure to close out of everything else, and I'm going to go into my book materials and open up the SparkKMeans Python script, and let's study what's going on in.
Alright, so again, we begin with some boilerplate stuff.
from pyspark.mllib.clustering import KMeans from numpy import array, random from math import sqrt from pyspark import SparkConf, SparkContext from sklearn.preprocessing import scale
We're going to import the KMeans package from the clustering MLlib package, we're going to import array and random from numpy, because, again, we're free to use whatever you want, this is a Python script at the end of the day, and MLlib often does require numpy arrays as input. We're going to import the sqrt function and the usual boilerplate stuff, we need SparkConf and SparkContext, pretty much every time from pyspark. We're also going to import the scale function from scikit-learn. Again, it's OK to use scikit-learn as long as you make sure its installed in every machine that you're going to be running this job on, and also don't assume that scikit-learn will magically scale itself up just because you're running it on Spark. But, since I'm only using it for the scaling function, it's OK. Alright, let's go ahead and set things up.
I'm going to create a global variable first:
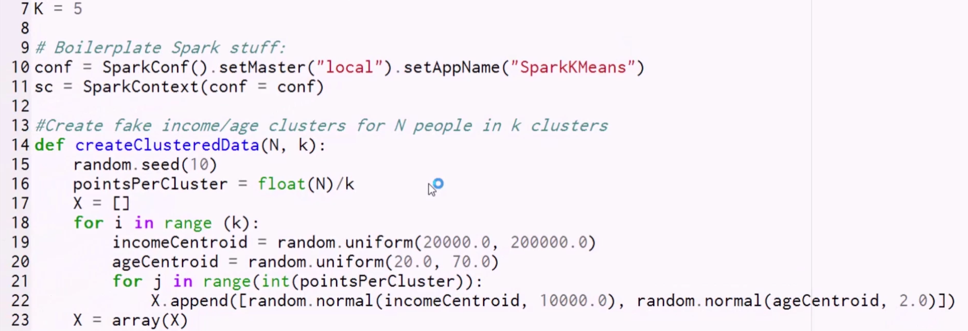
K=5
I'm going to run k-means clustering in this example with a K of 5, meaning with five different clusters. I'm then going to go ahead and set up a local SparkConf just running on my own desktop:
conf = SparkConf().setMaster("local").setAppName("SparkKMeans")
sc = SparkContext(conf = conf)
I'm going to set the name of my application to SparkKMeans and create a SparkContext object that I can then use to create RDDs that run on my local machine. We'll skip past the createClusteredData function for now, and go to the first line of code that gets run.
data = sc.parallelize(scale(createClusteredData(100, K)))
- The first thing we're going to do is create an RDD by parallelizing in some fake data that I'm creating, and that's what the createClusteredData function does. Basically, I'm telling you to create 100 data points clustered around K centroids, and this is pretty much identical to the code that we looked at when we played with k-means clustering earlier in the book. If you want a refresher, go ahead and look back at that chapter. Basically, what we're going to do is create a bunch of random centroids around which we normally distribute some age and income data. So, what we're doing is trying to cluster people based on their age and income, and we are fabricating some data points to do that. That returns a numpy array of our fake data.
- Once that result comes back from createClusteredData, I'm calling scale on it, and that will ensure that my ages and incomes are on comparable scales. Now, remember the section we studied saying you have to remember about data normalization? This is one of those examples where it is important, so we are normalizing that data with scale so that we get good results from k-means.
- And finally, we parallelize the resulting list of arrays into an RDD using parallelize. Now our data RDD contains all of our fake data. All we have to do, and this is even easier than a decision tree, is call KMeans.train on our training data.
clusters = KMeans.train(data, K, maxIterations=10,
initializationMode="random")
We pass in the number of clusters we want, our K value, a parameter that puts an upper boundary on how much processing it's going to do; we then tell it to use the default initialization mode of k-means where we just randomly pick our initial centroids for our clusters before we start iterating on them, and back comes the model that we can use. We're going to call that clusters.
Alright, now we can play with that cluster.
Let's start by printing out the cluster assignments for each one of our points. So, we're going to take our original data and transform it using a lambda function:
resultRDD = data.map(lambda point: clusters.predict(point)).cache()
This function is just going to transform each point into the cluster number that is predicted from our model. Again, we're just taking our RDD of data points. We're calling clusters.predict to figure out which cluster our k-means model is assigning them to, and we're just going to put the results in our resultRDD. Now, one thing I want to point out here is this cache call, in the above code.
An important thing when you're doing Spark is that any time you're going to call more than one action on an RDD, it's important to cache it first, because when you call an action on an RDD, Spark goes off and figures out the DAG for it, and how to optimally get to that result.
It will go off and actually execute everything to get that result. So, if I call two different actions on the same RDD, it will actually end up evaluating that RDD twice, and if you want to avoid all of that extra work, you can cache your RDD in order to make sure that it does not recompute it more than once.
By doing that, we make sure these two subsequent operations do the right thing:
print ("Counts by value:")
counts = resultRDD.countByValue()
print (counts)
print ("Cluster assignments:")
results = resultRDD.collect()
print (results)
In order to get an actual result, what we're going to do is use countByValue, and what that will do is give us back an RDD that has how many points are in each cluster. Remember, resultRDD currently has mapped every individual point to the cluster it ended up with, so now we can use countByValue to just count up how many values we see for each given cluster ID. We can then easily print that list out. And we can actually look at the raw results of that RDD as well, by calling collect on it, and that will give me back every single points cluster assignment, and we can print out all of them.