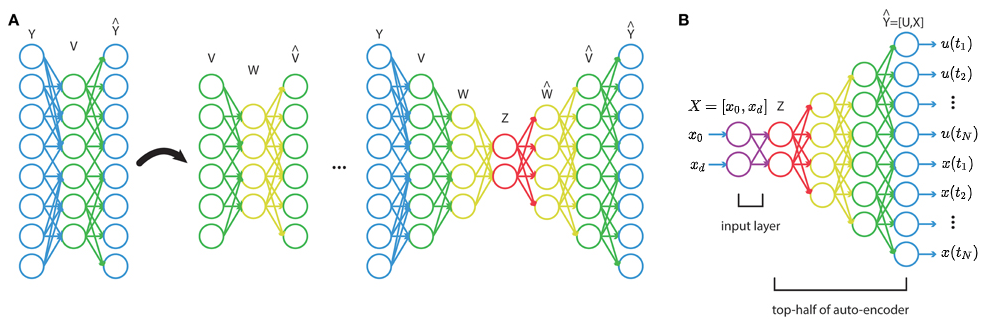
An autoencoder is a feedforward neural network that aims to learn how to compress the original dataset. Its aim is to copy input to its output. Therefore, instead of mapping features to the input layer and labels to the output layer, we will map the features to both the input and output layers. The number of units in the hidden layers is usually different from the number of units in the input layers, which forces the network to either expand or reduce the number of original features. This way, the network will learn the important features, while effectively applying dimensionality reduction.
An example network is shown in the following diagram. The three-unit input layer is first expanded into a four-unit layer and then compressed into a single-unit layer. The other side of the network restores the single layer unit back in to the four-unit layer, and then to the original three-input layer:

Once the network is trained, we can take the left-hand side to extract the image features like we would with traditional image processing. It consists of encoders and decoders, where the encoder's work is to create or make hidden a layer or layers that captures the essence of the input, and the decoders reconstruct the input from the layers.
The autoencoders can be also combined into stacked autoencoders, as shown in the following diagram. First, we will discuss the hidden layer in a basic autoencoder, as described previously. Then, we will take the learned hidden layer (green circles) and repeat the procedure, which in effect learns a more abstract presentation. We can repeat this procedure multiple times, transforming the original features into increasingly reduced dimensions. At the end, we will take all of the hidden layers and stack them into a regular feedforward network, as shown at the top-right part of the diagram: