
Clustering is a technique for grouping similar instances into clusters according to some distance measures. The main idea is to put instances that are similar (that is, close to each other) into the same cluster, while keeping the dissimilar points (that is, the ones further apart from each other) in different clusters. An example of how clusters might look like is shown in the following diagram:
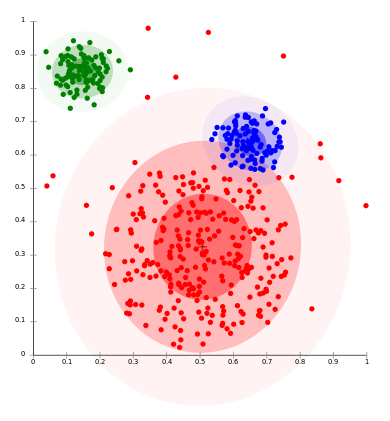
The clustering algorithms follow two fundamentally different approaches. The first is a hierarchical or agglomerative approach that first considers each point as its own cluster, and then iteratively merges the most similar clusters together. It stops when further merging reaches a predefined number of clusters, or if the clusters to be merged are spread over a large region.
The other approach is based on point assignment. First, initial cluster centers (that is, centroids) are estimated, for instance, randomly, and then, each point is assigned to the closest cluster, until all of the points are assigned. The most well known algorithm in this group is k-means clustering.
The k-means clustering either picks initial cluster centers as points that are as far as possible from one another, or (hierarchically) clusters a sample of data and picks a point that is the closest to the center of each of the k-clusters.