
Data transformation techniques tame the dataset to a format that a machine learning algorithm expects as input and may even help the algorithm to learn faster and achieve better performance. It is also known as data munging or data wrangling. Standardization, for instance, assumes that data follows Gaussian distribution and transforms the values in such a way that the mean value is 0 and the deviation is 1, as follows:
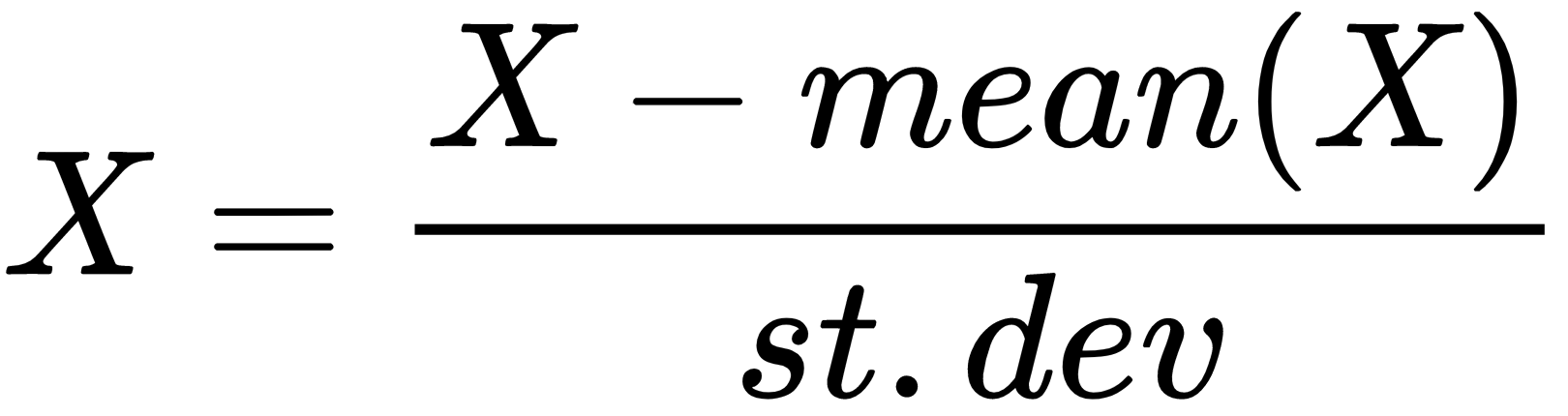
Normalization, on the other hand, scales the values of attributes to a small, specified range, usually between 0 and 1:
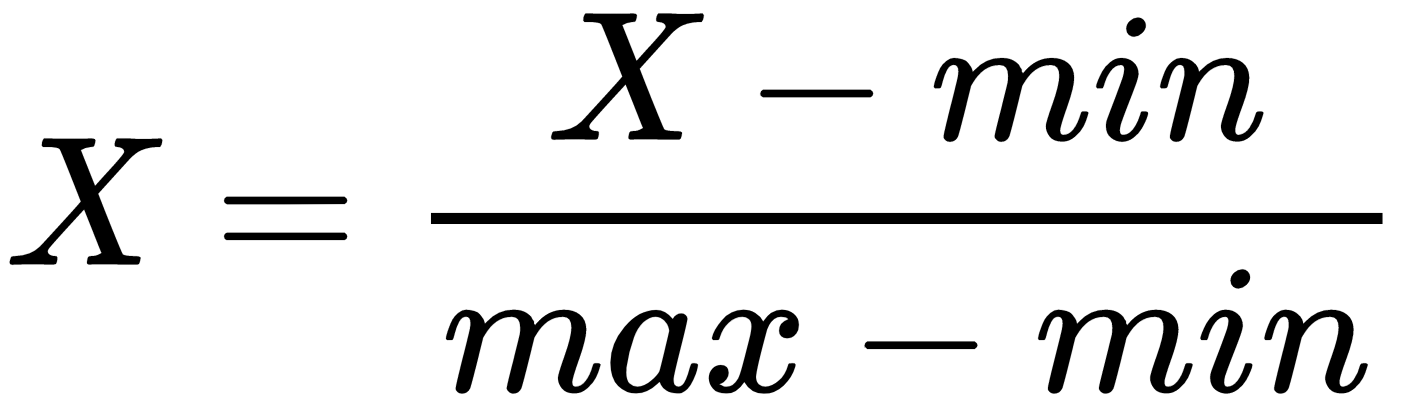
Many machine learning toolboxes automatically normalize and standardize the data for you.
The last transformation technique is discretization, which divides the range of a continuous attribute into intervals. Why should we care? Some algorithms, such as decision trees and Naive Bayes prefer discrete attributes. The most common ways to select the intervals are as follows:
- Equal width: The interval of continuous variables is divided into k equal width intervals
- Equal frequency: Supposing there are N instances, each of the k intervals contains approximately N or k instances
- Min entropy: This approach recursively splits the intervals until the entropy, which measures disorder, decreases more than the entropy increase, introduced by the interval split (Fayyad and Irani, 1993)
The first two methods require us to specify the number of intervals, while the last method sets the number of intervals automatically; however, it requires the class variable, which means it won't work for unsupervised machine learning tasks.