
The item-based approach is a natural alternative to the classic user-based approach described previously, and almost repeats it, except for one thing—it applies to the transposed preference matrix, which looks for similar products instead of users.
For each client, a user-based collaborative filtering system searches a group of customers who are similar to this user in terms of previous purchases, and then the system averages their preferences. These average preferences serve as recommendations for the user. In the case of item-based collaborative filtering, the nearest neighbors are searched for on a variety of products (items)—columns of a preference matrix, and the averaging occurs precisely according to them.
Indeed, if some products are meaningfully similar to each other, then users' reactions to these products will be the same. Therefore, when we see that some products have a strong correlation between their estimates, this may indicate that these products are equivalent to each other.
The main advantage of the item-based approach over the user-based approach is lower computation complexity. When there are many users (almost always), the task of finding the nearest neighbor becomes poorly computable. For example, for 1 million users, you need to calculate and store ~500 billion distances. If the distance is encoded in 8 bytes, this is 4 terabytes (TB) for the distance matrix alone. If we take an item-based approach, then the computational complexity decreases from 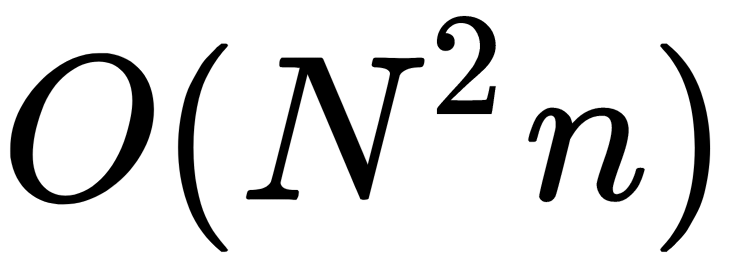 to
to 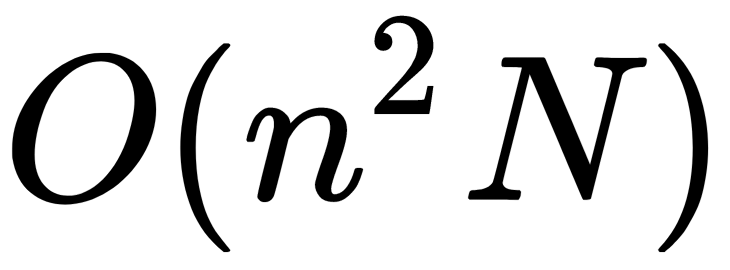 , and the distance matrix has a dimension no longer than 1 million per 1 million but 100 by 100 as per the number of items (goods).
, and the distance matrix has a dimension no longer than 1 million per 1 million but 100 by 100 as per the number of items (goods).
Estimation of the proximity of products is much more accurate than the assessment of the proximity of users. This assumption is a direct consequence of the fact that there are usually many more users than items, and therefore the standard error in calculating the correlation of items is significantly less because we have more information to work from.
In the user-based version, the description of users usually has a very sparse distribution (there are many goods, but only a few evaluations). On the one hand, this helps to optimize the calculation—we multiply only those elements where an intersection exists. But, on the other hand, the list of items that a system can recommend to a user is minimal due to the limited number of user neighbors (users who have similar preferences). Also, user preferences may change over time, but the descriptions of the goods are much more stable.
The rest of the algorithm almost wholly repeats the user-based version: it uses the same cosine distance as the primary measure of proximity and has the same need for data normalization. Since the correlation of items is considered on a higher number of observations, it is not so critical to recalculate it after each new assessment, and this can be done periodically in a batch mode.
Let's now look at another approach to generalize user interests based on matrix factorization methods.