
The most common operations used for programming linear algebra algorithms are the following ones:
- Element-wise operations: These are performed in an element-wise manner on vectors, matrices, or tensors of the same size. The resulting elements will be the result of operations on corresponding input elements, as shown here:

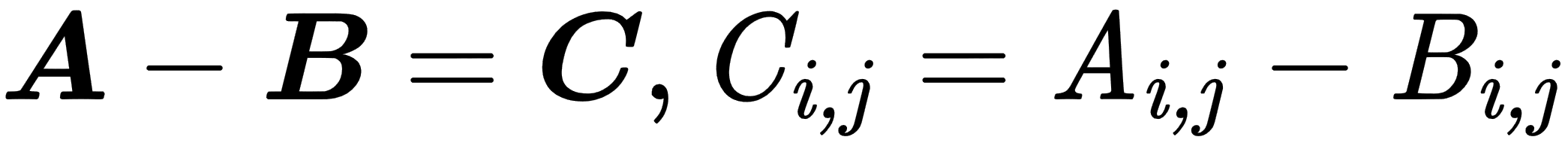
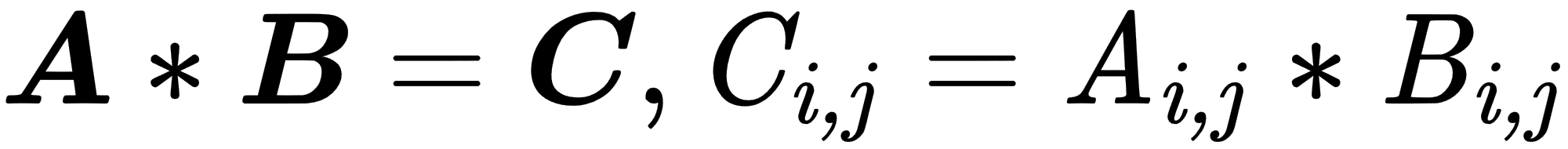
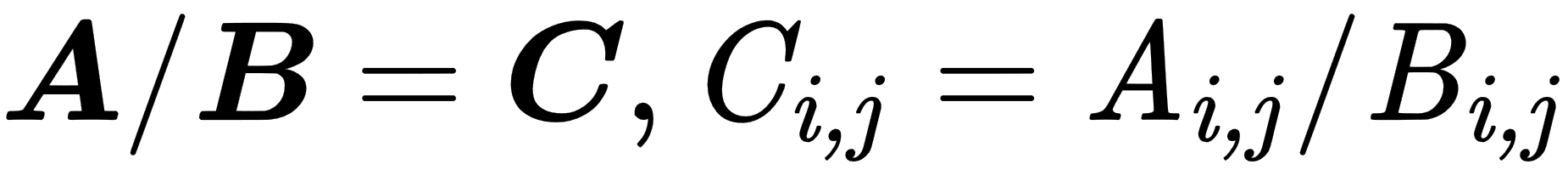
The following example shows the element-wise summation:
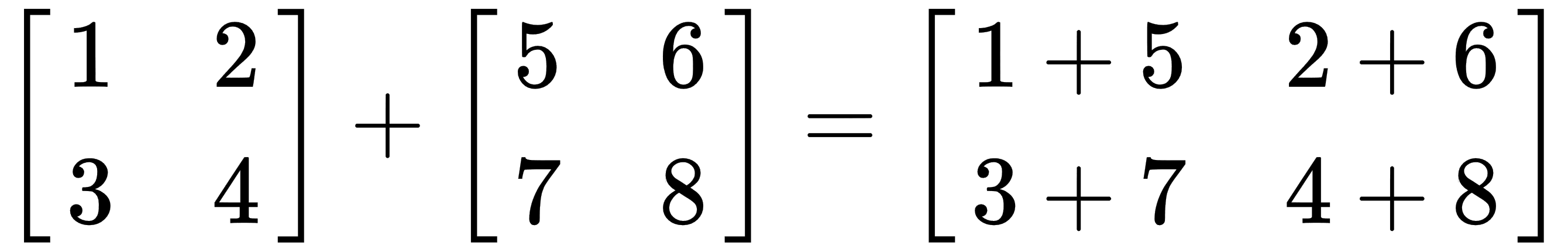
- Dot product: There are two types of multiplications for tensor and matrices in linear algebra—one is just element-wise, and the second is the dot product. The dot product deals with two equal-length series of numbers and returns a single number. This operation applied on matrices or tensors requires that the matrix or tensor A has the same number of columns as the number of rows in the matrix or tensor B. The following example shows the dot-product operation in the case when A is an n x m matrix and B is an m x p matrix:
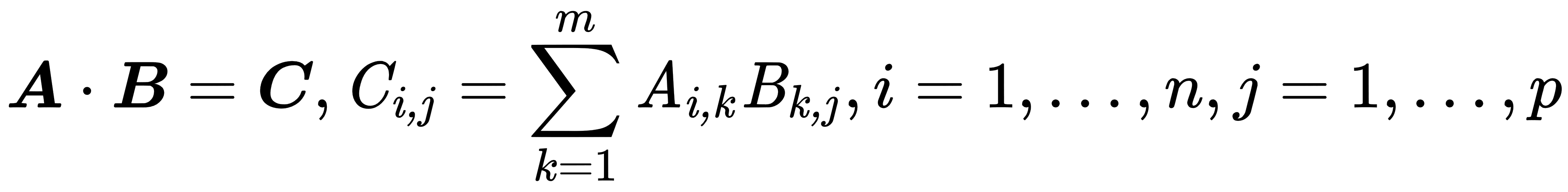
- Transposing: The transposing of a matrix is an operation that flips the matrix over its diagonal, which leads to the flipping of the column and row indices of the matrix, resulting in the creation of a new matrix. In general, it is swapping matrix rows with columns. The following example shows how transposing works:
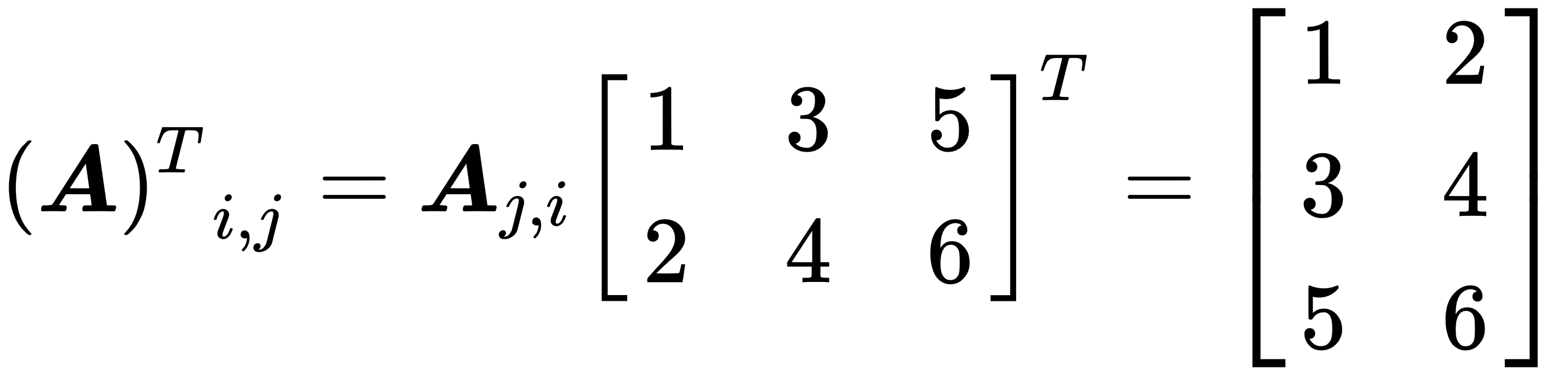
- Norm: This operation calculates the size of the vector; the result of this is a non-negative real number. The norm formula is as follows:
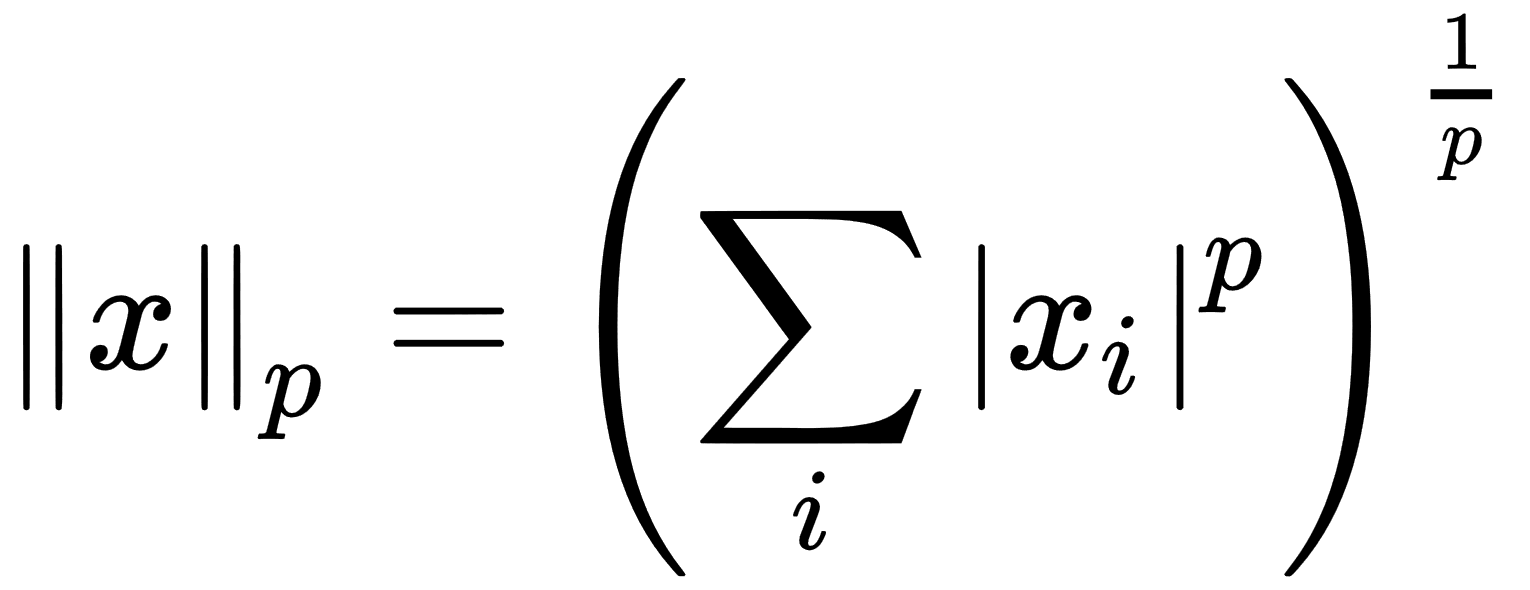
The generic name of this type of norm is 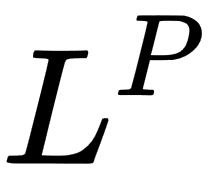 norm for
norm for 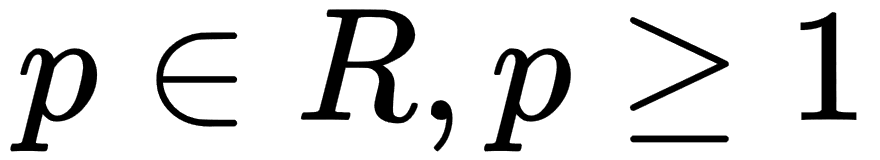 . Usually, we use more concrete norms such as an
. Usually, we use more concrete norms such as an 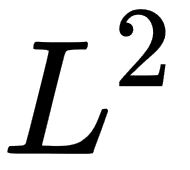 norm with p = 2, which is known as the Euclidean norm, and we can interpret it as the Euclidean distance between points. Another widely used norm is the squared norm, whose calculation formula is
norm with p = 2, which is known as the Euclidean norm, and we can interpret it as the Euclidean distance between points. Another widely used norm is the squared norm, whose calculation formula is 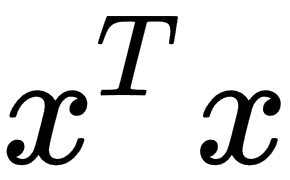 . The squared
. The squared 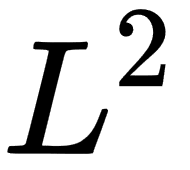 norm is more suitable for mathematical and computational operations than the norm. Each partial derivative of the squared norm depends only on the corresponding element of x, in comparison to the partial derivatives of the norm which depends on the entire vector; this property plays a vital role in optimization algorithms. Another widely used norm operation is the
norm is more suitable for mathematical and computational operations than the norm. Each partial derivative of the squared norm depends only on the corresponding element of x, in comparison to the partial derivatives of the norm which depends on the entire vector; this property plays a vital role in optimization algorithms. Another widely used norm operation is the 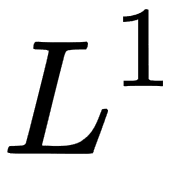 norm with p=1, which is commonly used in ML when we care about the difference between zero and nonzero elements.
norm with p=1, which is commonly used in ML when we care about the difference between zero and nonzero elements.
- Inverting: The inverse matrix is such a matrix that
 , where I is an identity matrix. The identity matrix is a matrix that does not change any vector when we multiply that vector by that matrix.
, where I is an identity matrix. The identity matrix is a matrix that does not change any vector when we multiply that vector by that matrix.
We considered the main linear algebra concepts as well as operations on them. Using this math apparatus, we can define and program many ML algorithms. For example, we can use tensors and matrices to define training datasets for training, and scalars can be used as different types of coefficients. We can use element-wise operations to perform arithmetic operations with a whole dataset (a matrix or a tensor). For example, we can use element-wise multiplication to scale a dataset. We usually use transposing to change a view of a vector or matrix to make them suitable for the dot-product operation. The dot product is usually used to apply a linear function with weights expressed as matrix coefficients to a vector; for example, this vector can be a training sample. Also, dot-product operations are used to update model parameters expressed as matrix or tensor coefficients according to an algorithm.
The norm operation is often used in formulas for loss functions because it naturally expresses the distance concept and can measure the difference between target and predicted values. The inverse matrix is a crucial concept for the analytical solving of linear equations systems. Such systems often appear in different optimization problems. However, calculating the inverse matrix is very computationally expensive.