
Chapter 6: Multi-Cloud Strategy and Cloud Satellite
Hybrid multi-cloud support is the foundational pillar of Cloud Pak for Data, and the feature of deploying and running anywhere (private cloud or any public cloud) has been one of Cloud Pak for Data's key differentiators. In this chapter, we will learn more about the supported public and private clouds, the evolution of Cloud Pak for Data as a Service, and IBM's strategy to support managed services on third-party clouds. We will explore both the business and technical concepts behind IBM's multi-cloud support, including a brief overview of IBM Cloud Satellite. This will allow the customer to define an effective multi-cloud strategy by leveraging IBM technology.
We're going to cover the following main topics:
- IBM's multi-cloud strategy
- Supported deployment options
- Cloud Pak for Data as a Service
- IBM Cloud Satellite
- A data fabric for a multi-cloud future
IBM's multi-cloud strategy
IBM is one of the few technology vendors to have embraced a hybrid multi-cloud strategy from day one, and this is evident from the deployment options that are supported by IBM. Being able to deploy anywhere is a key differentiator for Cloud Pak for Data. While software and system deployment options enjoy customer adoption the most, Cloud Pak for Data as a Service is IBM's strategic direction in the long run. The as-a-Service managed edition of Cloud Pak for Data was launched in 2020 on IBM Cloud and is now supported on third-party clouds through Cloud Satellite, which we will cover in detail later in the chapter.
The value proposition of as-a-Service is that it allows customers to modernize how they collect, organize, analyze, and infuse AI with no installation, management, or updating required. In essence, you can derive all the benefits of an integrated data and AI platform, namely Cloud Pak for Data, without the overhead of managing the infrastructure or software.
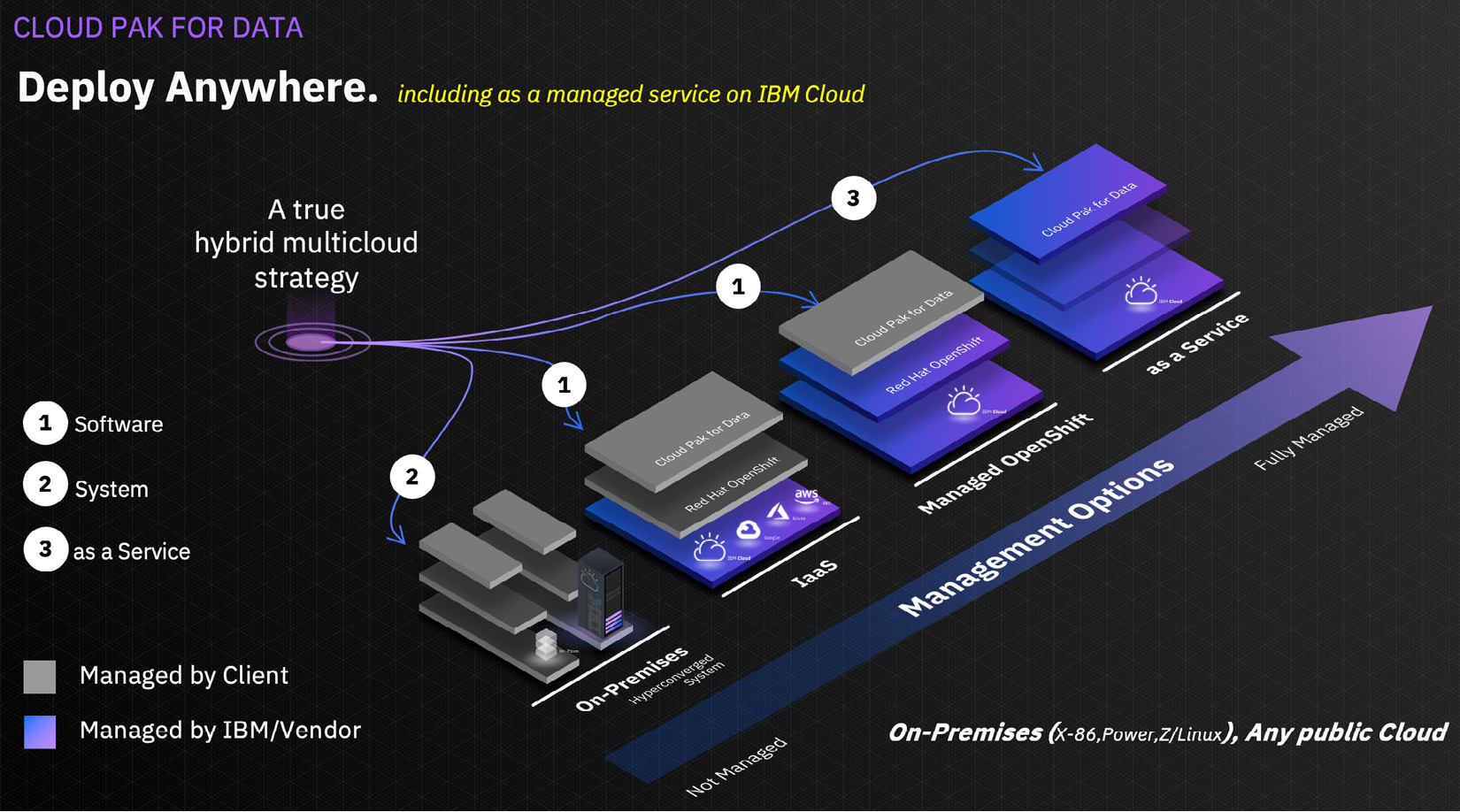
Figure 6.1 – IBM's hybrid multi-cloud strategy
Cloud Pak for Data as a Service is a strategic priority for IBM as there is a growing demand for Software as a Service (SaaS). Furthermore, IBM launched Cloud Satellite to deliver SaaS on-premises and third-party clouds. The objective is to give customers the flexibility of choice so that they can consume software and SaaS on the infrastructure of their choice such as an on-premise private cloud (x86, Power, Z) or a public cloud such as IBM Cloud, AWS, Azure, and so on. Next, we will cover supported deployment options.
Supported deployment options
Cloud Pak for Data comes in three deployment options: software, system, and as-a-Service, offering significant choice to customers as to where they deploy and run their software and how they manage Cloud Pak for Data:
- Cloud Pak for Data software runs on any private or public cloud, including AWS, Azure, and GCP. Also supported are managed OpenShift on IBM Cloud (ROKS), managed OpenShift on AWS (ROSA), and managed OpenShift on Azure (ARO).
- Cloud Pak for Data system is a true plug-and-play, all-in-one, enterprise data and AI platform that comes with all the necessary hardware and software components.
- Cloud Pak for Data as a Service runs on IBM Cloud and third-party clouds such as AWS through IBM Cloud Satellite.
For enterprise customers who cannot yet embrace the public cloud or would prefer a non-IBM cloud, the options are as follows:
- Private cloud: Cloud Pak for Data software, with its embedded Red Hat OpenShift, enables customers to deploy and operate a cloud-native data and AI platform in their own data center. Alternatively, clients can opt for Cloud Pak for Data system, an integrated appliance with hardware and software pre-installed, optimized for end-to-end data and AI workloads.
- Third-party clouds: Cloud Pak for Data software is supported on all major public clouds, including AWS, Azure, and GCP, either directly on their cloud infrastructure or on their managed OpenShift offering, such as Red Hat OpenShift on AWS (ROSA) or Azure Red Hat OpenShift (ARO).
Managed OpenShift
Red Hat has launched managed OpenShift offerings on all major cloud providers, including IBM Cloud, AWS, Azure, and GCP. Customers can run their workloads, including Cloud Pak for Data ones, without worrying about the maintenance, administration, and upgrading of OpenShift, which is not so easy for non-technology users.
IBM Cloud Pak for Data is currently available and supported on three major managed OpenShift services. They are IBM Red Hat ROKS, Amazon ROSA, and Microsoft ARO. Managed OpenShift's main value proposition includes four key points:
The main value proposition of this service spans 4 key points:
- Time saved: Red Hat takes care of OpenShift so that customers can focus on their data and AI workloads. Furthermore, delivery pipelines are pre-integrated with user-friendly management tools, simplifying the effort required to manage and administer Cloud Pak for Data.
- Consistency: Multi-cloud with Red Hat OpenShift works everywhere, including on public clouds and on-premises, and hybrid support enables flexibility of deployment. Also, it allows customers to focus and build skills in one Kubernetes distribution (namely OpenShift) that spans all deployment options.
- Portability: Run Red Hat OpenShift workloads consistently with any major cloud provider, offering customers the choice and flexibility they desire. More importantly, this gives customers the ability to migrate workloads from one cloud provider to another if needed.
- Scalable Red Hat OpenShift: Control versions and licensing from a single Red Hat account irrespective of where it is deployed.
Here are all the items managed by the provider as part of Managed OpenShift:
- Automated provisioning and configuration of infrastructure (compute, network, and storage).
- Automated installation and configuration of OpenShift, including high-availability cross-zone configuration.
- Automatic upgrades of all components (operating system, OpenShift components, and in-cluster services).
- Security patch management for operating system and OpenShift.
- Automatic failure recovery for OpenShift components and worker nodes.
- Automatic scaling of OpenShift configuration.
- Automatic backups of core OpenShift ETCD data.
- Built-in integration with the cloud platform – monitoring, logging, Key Protect, IAM, Activity Tracker, Storage, COS, Security Advisor, Service Catalog, Container Registry, and Vulnerability Advisor.
- Built-in load balancer, VPN, proxy, network edge nodes, private cluster, and VPC capabilities.
- Built-in security, including image signing, image deployment enforcement, and hardware trust.
- 24/7 global Site Reliability Engineering (SRE) to maintain the health of the environment and help with OpenShift.
- The global SRE team has lots of experience and skill in IBM Cloud infrastructure, Kubernetes, and OpenShift, resulting in much faster problem resolution.
- Automatic compliance for your OpenShift environment (HIPAA, PCI, SOC2, and ISO).
- Capacity expansion with a single click.
- Automatic multi-zone deployment in Multi-Zone Regions (MZRs), including integration with Cloud Internet Service (CIS) to do cross-zone traffic routing.
- Automatic operating system performance tuning and security hardening.
AWS Quick Start
"Quick Start" on AWS refers to templates (scripts) that automate the deployment of workloads – in this case, Cloud Pak for Data. A Quick Start launches, configures, and runs compute, network, storage, and all other related AWS infrastructure required to deploy Cloud Pak for Data on AWS in 3 hours or less. This is a significant value proposition for customers interested in running Cloud Pak for Data on AWS. It saves time through automation (eliminates many of the steps required for manual installation configuration) and helps implement AWS best practices by design.
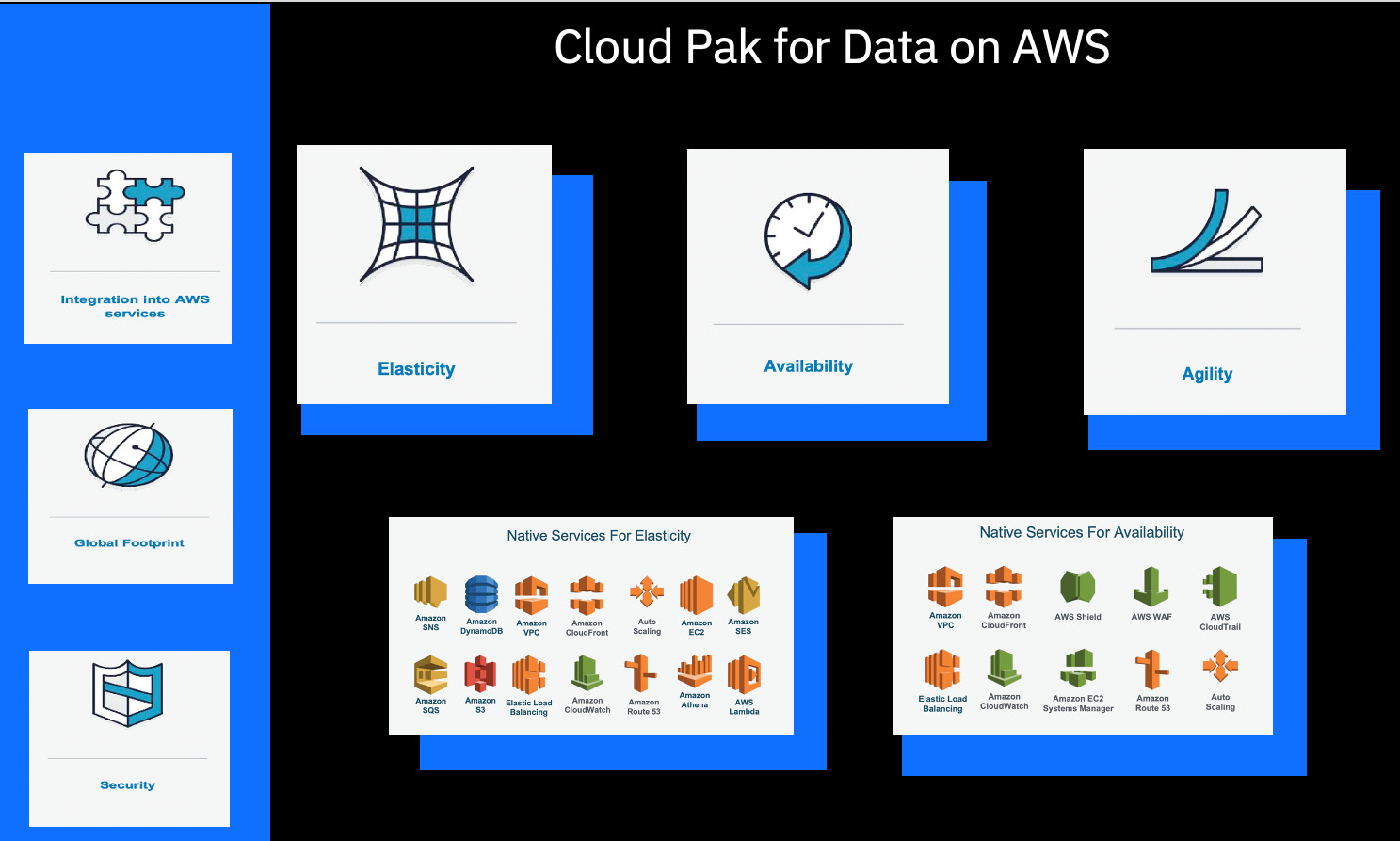
Figure 6.2 – Cloud Pak for Data on AWS – value proposition
Other benefits of AWS Quick Start include a free trial of Cloud Pak for Data for up to 60 days and a detailed deployment guide. However, it requires an AWS account – the customer is responsible for infrastructure costs. For storage, the customer has two options: OpenShift Container Storage (OCS), which was recently renamed OpenShift Data Foundations (ODF), or Portworx.
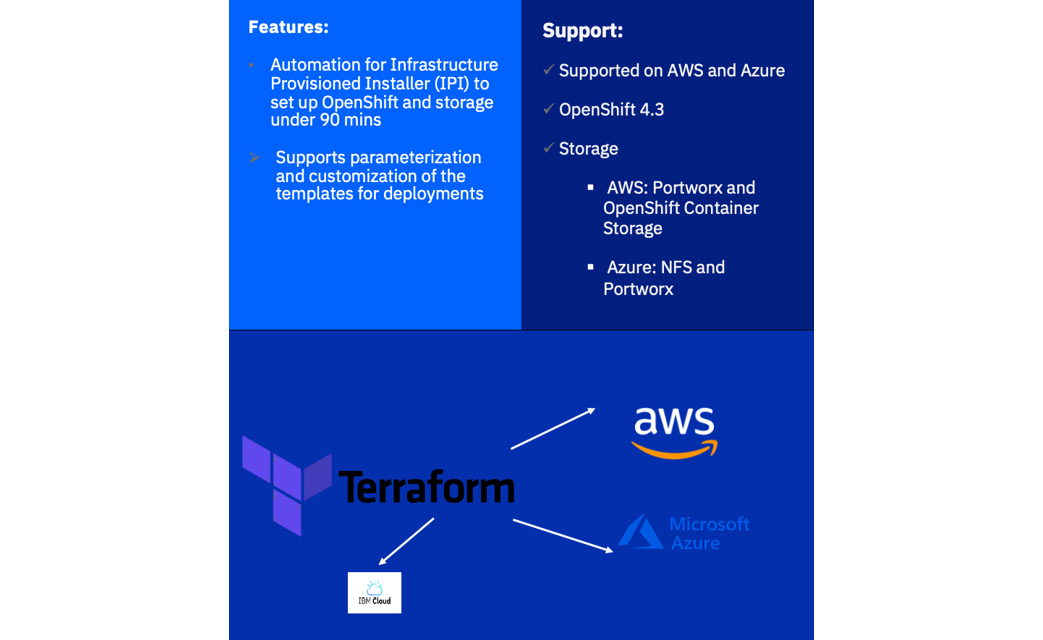
Figure 6.3 – Terraform automation
Also available on AWS, Azure, and IBM Cloud is Terraform automation, whose benefits include the following:
- Easy full-stack deployment to allow consistency and repeatability
- Increased productivity with Infrastructure as Code to write and execute code to define, deploy, and update your infrastructure in minutes
- Idempotency, with code that works correctly no matter how many times you run it
- Self-service through automation for the entire deployment process to schedule and kick off deployments as needed
Azure Marketplace and QuickStart templates
Azure Marketplace is an online applications and services marketplace ideal for IT professionals and cloud developers interested in Cloud Pak for Data software and its services. It enables customers to discover, try, buy, and deploy a solution in just a few clicks. Like AWS, Microsoft requires an Azure account and one of the two supported storage options, namely OCS or Portworx. Also, customers can have a trial at no cost for up to 60 days:

Figure 6.4 – Cloud Pak for Data on Azure Marketplace
Let's move on to cover Cloud Pak for Data as a service.
Cloud Pak for Data as a Service
Most of IBM's data and AI products are currently available as a service and packaged under a single Cloud Pak for Data subscription that is consumption-based, allowing customers to only pay for what they use. Furthermore, to accelerate the modernization of existing workloads and help customers with moving to the cloud/managed services, IBM has launched an initiative called Hybrid Subscription Advantage (HSA) that offers existing software customers discounts to use SaaS instead of software. In this section, we will cover a detailed overview of Cloud Pak for Data as a Service, including the capabilities available, how it's priced and packaged, and how IBM is enabling its customers to modernize through HSA.
As mentioned before, Cloud Pak for Data as a Service allows customers to modernize how they collect, organize, analyze, and infuse AI with no installation, management, or updating required. In other words, it helps deliver all the benefits of an integrated data and AI platform without the overhead of managing the infrastructure or software. The different services constituting Cloud Pak for Data as a Service are the same as for Cloud Pak for Data software, with the existing gaps addressed as part of the roadmap. Here is a short list of available services along with their descriptions and value propositions:
- IBM Watson Studio: Watson Studio democratizes machine learning and deep learning to accelerate the infusion of AI in your business to drive innovation. Watson Studio provides a suite of tools and a collaborative environment for data scientists, developers, and domain experts. It includes capabilities to deploy models with IBM Watson Machine Learning and manage them at scale, ensuring accuracy and governance with Watson OpenScale. Last but not least, it comes with Auto AI, which enables normal users to build complex models with just a few clicks.
a) IBM Watson Machine Learning: IBM Watson Machine Learning is a full-service IBM Cloud offering that makes it easy for developers and data scientists to work together to integrate predictive capabilities with their applications. The Machine Learning service is a set of REST APIs that you can call from any programming language to develop applications that make smarter decisions, solve tough problems, and improve user outcomes.
b) IBM Watson OpenScale: IBM Watson OpenScale tracks and measures outcomes from AI throughout its life cycle and adapts and governs AI in changing business situations. It also helps with drift explainability and bias detection.
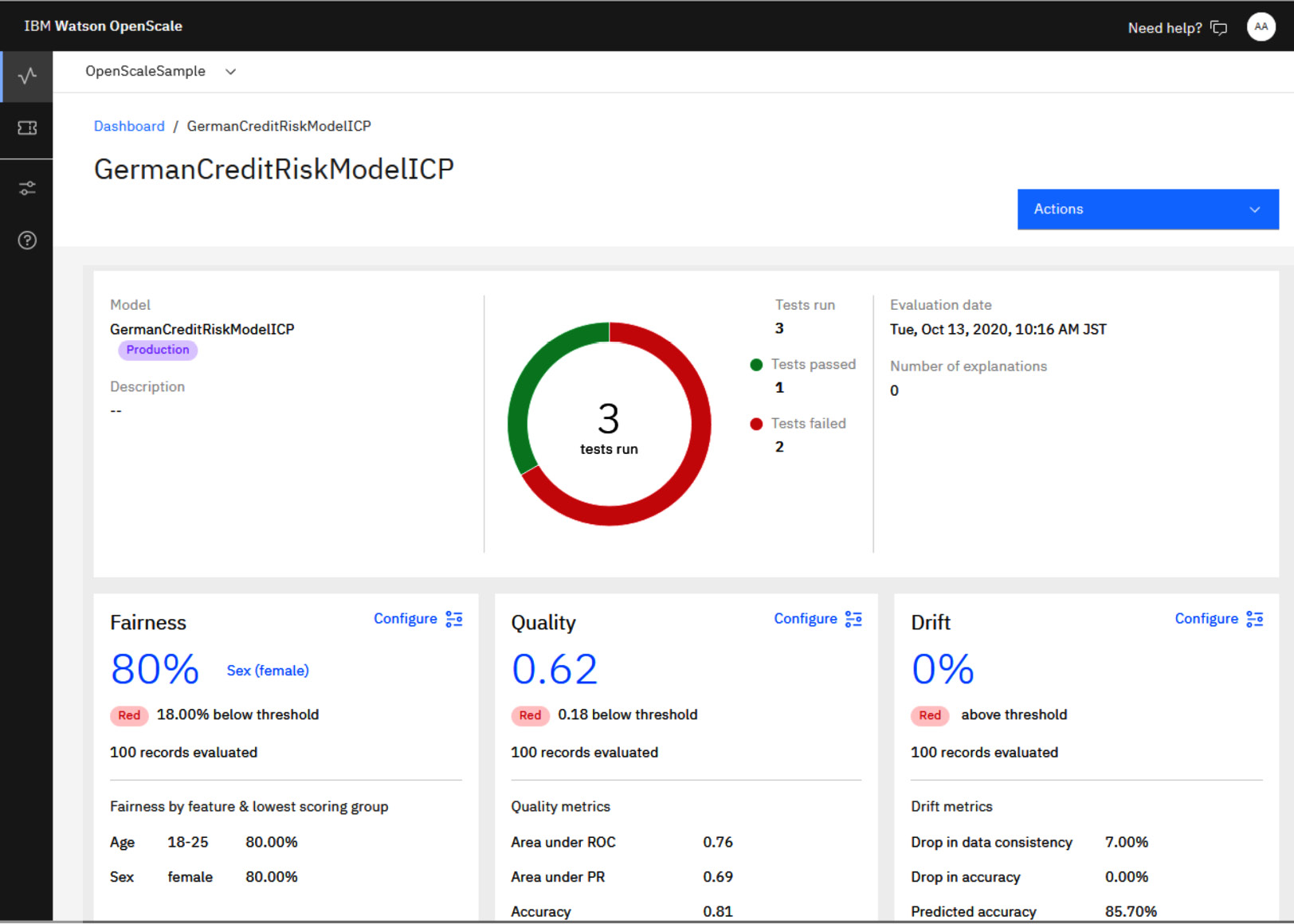
Figure 6.5 – Watson OpenScale
- IBM Watson Knowledge Catalog: Simplify and organize your enterprise data with IBM Watson Knowledge Catalog, making it easy to find, share, and govern data at scale. Customers can create a 360-degree view of their data, no matter where (or in what format) it is stored, auto-discover the data from a myriad of supported data sources, collaborate with fellow users, and control data access by defining policies and monitoring enforcement.
- Data Virtualization enables you to query data across many systems without having to copy and replicate it, saving time and reducing costs. Data Virtualization queries data from its source, simplifying your analytics by providing the latest and most accurate data. The Data Virtualization service automatically organizes your data nodes into a collaborative network for computational efficiency. You can define constellations with large or small data sources. Data is never cached in the cloud or on other devices. Also, credentials for your private databases are encrypted and stored on your local device.
- IBM Db2: A fully managed, highly performant relational data store running the enterprise-class Db2 database engine, IBM Db2 is built to take on the toughest mission-critical workloads on the planet, with advanced features such as adaptive workload management, time travel query, query federation, in-database AI, row/column access control, auditing, and support for JSON, XML, and geospatial datasets. Customers can independently scale and manage the compute and storage requirements for their deployments. Self-service managed backups to object storage with point-in-time recovery allows data to be restored to any specified time while all customer data is encrypted in motion and at rest.
a) IBM Db2 Warehouse: A fully managed elastic cloud data warehouse that delivers independent scaling of storage and compute. It delivers a highly optimized columnar data store, actionable compression, and in-memory processing to supercharge your analytics and machine learning workloads.
- IBM DataStage offers industry-leading batch and real-time data integration to build trusted data pipelines across on-premises and hybrid cloud environments allowing any integration style (ETL or ELT) to prepare data for AI. Please note that ELT stands for Extract, Transform, Load, while ELT is extract and load followed by processing. Work with your peers on DataStage Flows and control admin, editor, or viewer access to your projects. Easily perform data integration work in a no-code/low-code environment with a friendly user interface. Scale horizontally or vertically as needed in a secure cloud environment. Take advantage of shared platform connections and integrations with other products in Cloud Pak for Data.
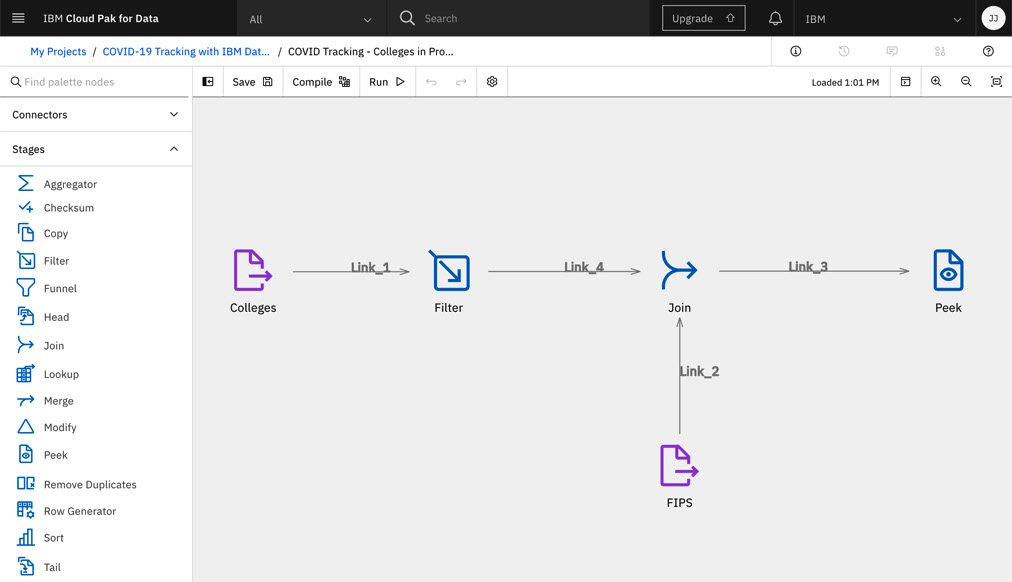
Figure 6.6 – IBM DataStage
- IBM Cognos Dashboard Embedded enables business users and developers to easily build and visualize data with a simple drag and drop interface to quickly find valuable insights and create visualizations on their own.
Figure 6.7 – Cognos Dashboard Embedded
- IBM Analytics Engine helps develop and deploy analytics applications using the open source Apache Spark and Apache Hadoop. Customize the cluster using your own analytics libraries and open source packages. Integrate with IBM Watson Studio or third-party applications to submit jobs to the cluster. An HIPAA readiness option is available in the Dallas region for standard hourly and standard monthly plans. Define clusters based on your application's requirements by choosing the appropriate software package, version, and size of the cluster. Use the cluster if required and delete it again when all the jobs have run. Customize clusters with third-party analytics libraries and packages, and deploy workloads from IBM Watson such as IBM Watson Studio and Machine Learning. Build on the ODPi-compliant Apache Spark and Apache Hadoop stack to expand on open source investments. Integrate analytics tools using standard, open source APIs, and libraries.
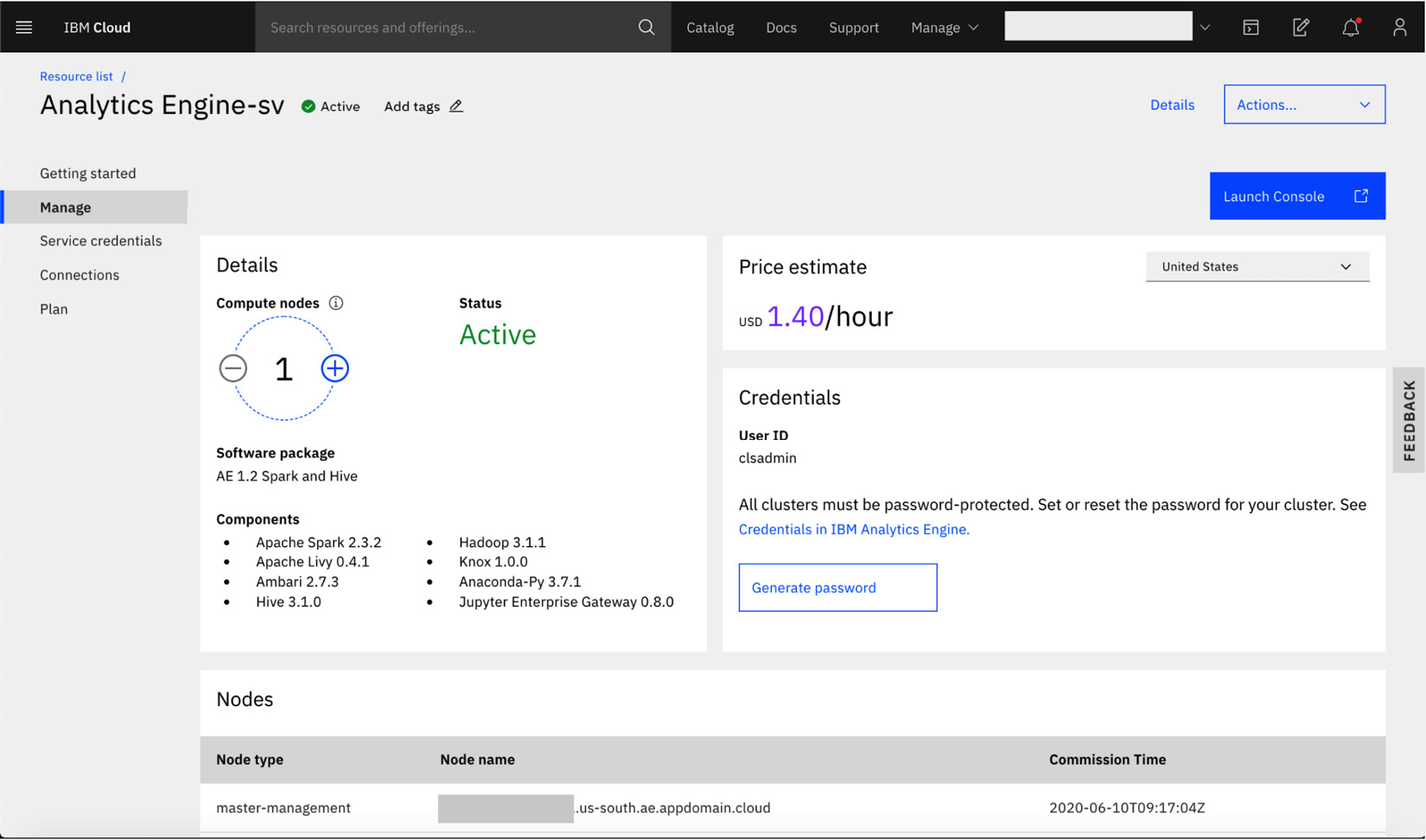
Figure 6.8 – IBM Analytics Engine
- IBM Match 360 with Watson helps quickly build data pipelines for analytics and other data science use cases using master data. Start with your IBM MDM Advanced or Standard Edition entities, or with any data assets containing party information from the knowledge catalog and quickly map and model new attributes to your data model for a more complete view of your customers. The AI-powered matching engine speeds up configuration using statistical methods clients have relied on to produce accurate results. Results can be accessed via RESTful APIs, exported to flat files, or viewed online via the entity explorer. Extend existing master data entities from MDM Advanced or Standard Edition with governed data assets. Enable text searches and queries against your master data entities. Build service integrations using RESTful APIs or IBM App Connect for use in business applications or data warehouses. Auto-classify and map fields to your data model, and tune your algorithm with data-first, AI-suggested matching attributes. Built-in machine learning and years of experience speed up configuring and tuning party matching algorithms.
- Watson Assistant: Build conversational interfaces into any application, device, or channel. Add a natural language interface to your application to automate interactions with your end users. Common applications include virtual agents and chatbots that can integrate and communicate on any channel or device. Train the Watson Conversation service through an easy-to-use web application designed so you can quickly build natural conversation flows between your apps and users, and deploy scalable, cost-effective solutions.
Figure 6.9 – IBM Watson Assistant
a) The Speech to Text service converts human voice input into text. The service uses deep learning AI to apply knowledge of grammar, language structure, and the composition of audio and voice signals to accurately transcribe human speech. It can be used in applications such as voice-automated chatbots, analytic tools for customer-service call centers, and multi-media transcription, among many others.
b) The Text to Speech service converts written text into natural-sounding speech. The service streams the synthesized audio back with minimal delay. The audio uses the appropriate cadence and intonation for its language and dialect to provide voices that are smooth and natural. The service can be used in applications such as voice-automated chatbots, as well as a variety of voice-driven and screenless applications, such as tools for the disabled or visually impaired, video narration and voice-over, and educational and home-automation solutions.
c) Natural Language Understanding helps analyze text and extract metadata from content such as concepts, entities, keywords, categories, sentiment, emotion, relations, and semantic roles. Apply custom annotation models developed using Watson Knowledge Studio to identify industry-/domain-specific entities and relations in unstructured text with Watson NLU.
- Watson Discovery adds a cognitive search and content analytics engine to applications to identify patterns, trends, and actionable insights that drive better decision making. It securely unifies structured and unstructured data with pre-enriched content and uses a simplified query language to eliminate the need for the manual filtering of results. The automated ingestion and integrated natural language processing in the fully managed cloud service remove the complexity of dealing with natural language content. Uncover deep connections in your data by using advanced out-of-the-box AI functions, such as natural language queries, passage retrieval, relevancy training, relationship graphs, and anomaly detection.
- Open source databases:
a) Cloudant is a fully managed JSON document database that offers independent serverless scaling of provisioned throughput capacity and storage. Cloudant is compatible with Apache CouchDB and accessible through a simple to use HTTPS API for web, mobile, and IoT applications.
b) Elasticsearch combines the power of a full text search engine with the indexing strengths of a JSON document database to create a powerful tool for the rich data analysis of large volumes of data. IBM Cloud Databases for Elasticsearch makes Elasticsearch even better by managing everything for you.
c) EDB is a PostgreSQL-based database engine optimized for performance, developer productivity, and compatibility with Oracle. IBM Cloud Databases for EDB is a fully managed offering with 24/7 operations and support.
d) MongoDB is a JSON document store with a rich query and aggregation framework. IBM Cloud Databases for MongoDB makes MongoDB even better by managing everything for you.
e) PostgreSQL is a powerful, open source object-relational database that is highly customizable. It's a feature-rich enterprise database with JSON support, giving you the best of both the SQL and NoSQL worlds. IBM Cloud Databases for PostgreSQL makes PostgreSQL even better by managing everything for you.
Packaging and pricing
Cloud Pak for Data as a Service is offered as a subscription wherein customers pay for what they use and no more. Also, subscription credits can be used for any of the data and AI services that make up Cloud Pak for Data. This affords a lot of flexibility to customers as they can provision and use all the in-scope services. Each of these individual services is priced competitively to reflect the value they offer and include infrastructure costs such as compute, memory, storage, and networking.
Also, IBM has an attractive initiative called HSA to incentivize existing on-premises customers to modernize to Cloud Pak for Data as a Service. The value in this initiative is that existing software customers will receive a significant discount on Cloud Pak for Data as a Service to account for the value of the software that they have already paid for. This, of course, assumes that customers will stop using other software and instead move to Cloud Pak for Data as a Service.
IBM Cloud Satellite
IBM Cloud Satellite is an extension of IBM Cloud that can run within a client's data center, on an edge server, or on any cloud infrastructure. IBM has been porting all its cloud services to Kubernetes, enabling the different services to function consistently. IBM Cloud Satellite extends and leverages the same underlying concept, running on Red Hat OpenShift as its Kubernetes management environment.
To be more precise, every Cloud Satellite location is an instance of IBM Cloud running on local hardware or any third-party public cloud (such as AWS or Azure). Furthermore, each Cloud Satellite location is connected to the IBM Cloud control plane. This connection back to the IBM Cloud control plane provides audit, packet capture, and visibility to the security team, and a global view of applications and services across all satellite locations. IBM Cloud Satellite Link connects IBM Cloud to its satellite location and offers visibility into all the traffic going back and forth.
IBM's strategy is to bring Cloud Pak for Data managed services to third-party clouds and dedicated on-premises infrastructure using Cloud Satellite. As of 2021, a subset of Cloud Pak for Data managed services, including Jupyter Notebook and DataStage, is available on Cloud Satellite to be deployed on third-party clouds. The packaging and pricing for these services is no different from how it is on IBM Cloud, and included will be the third-party cloud infrastructure to run the services. The ultimate objective here is to deliver a managed service on the infrastructure of your choice.
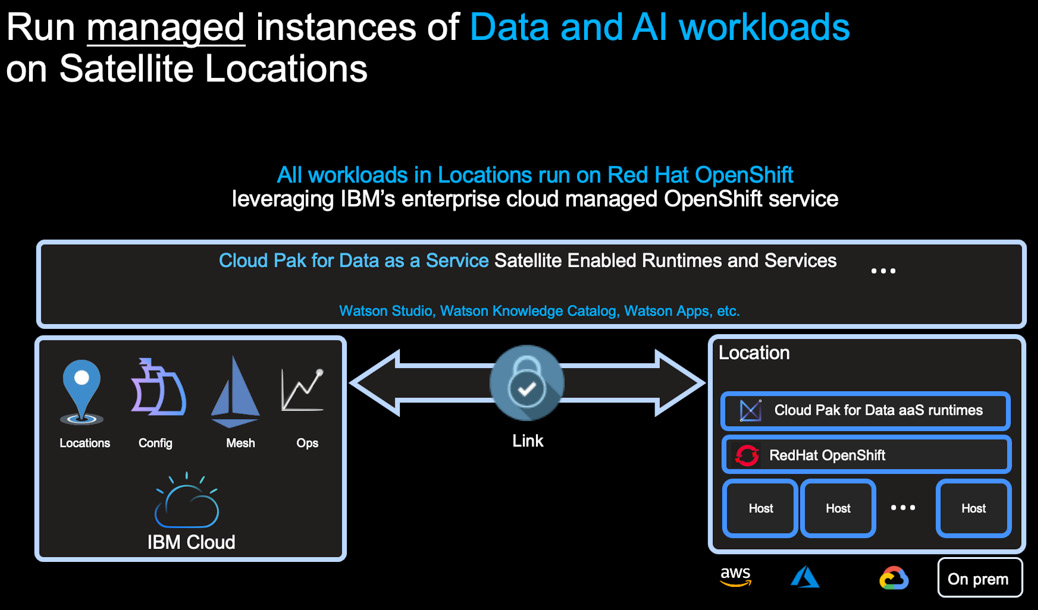
Figure 6.10 – IBM Cloud Satellite
So, how does this all work? Once a Satellite location is established, all workloads in these Satellite locations run on Red Hat OpenShift – specifically IBM Cloud's managed OpenShift service. Services integrated into Cloud Pak for Data as a Service – such as DataStage – can deploy runtimes to these Satellite locations so that these runtimes can be closer to the data or apps these services need to integrate with. A secure connection, called Satellite Link, provides communication between Cloud Pak for Data as a Service and its remote runtimes.
The value proposition of IBM Cloud Satellite specifically for data and AI workloads is threefold:
- Data gravity: Minimize data movement and redundancy, which also helps avoid egress costs. Train AI models closer to where data is located, which removes latency and improves performance.
- Modernize legacy workloads and realize cloud-native benefits on-premises or on a third-party cloud of your choice:
Easy to provision and scale up and down.
Seamless upgrades with negligible downtime.
Realize the benefits of a managed service.
- Address regulatory and compliance challenges:
Share insights without moving data: handle challenges with data sovereignty.
Comply with GDPR, CCPA, and so on.
Now that we have learned the basics of IBM Cloud Satellite and IBM's approach to multi-cloud, let's look at the data fabric.
A data fabric for a multi-cloud future
The cloud is transforming every business, and multi-cloud is the future. To be successful, enterprises will have to access, govern, secure, transform, and manage data across private and public clouds. This is what IBM is addressing using the data fabric, a significant effort that will likely span multiple years. A solid foundation to a data fabric starts with centralized metadata management, data governance, and data privacy, which, when augmented by automation, really helps in amplifying the benefits.
The following image showcases data fabric for a multi-cloud future:
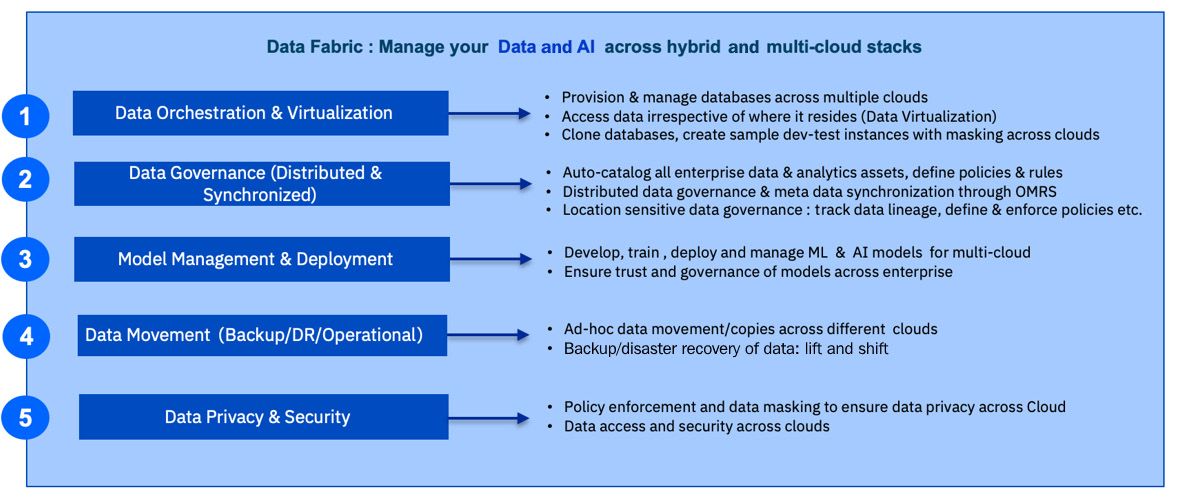
Figure 6.11 – Data fabric for a multi-cloud future
This repeats the last line in the previous paragraph - delete one of them.
Summary
Managed services/SaaS is an absolute must these days, and Cloud Pak for Data has a comprehensive and evolving set of capabilities that addresses end-to-end customer requirements. With simplified packaging and pricing and incentives to modernize, IBM makes it easy for existing and new clients to embrace Cloud Pak for Data as a Service. In this chapter you learned the different deployment options for Cloud Pak for Data, supported third-party clouds and an overview of its managed service (Cloud Pak for Data SaaS offering). You have also learned that IBM's vision is to deliver the Cloud Pak for Data managed service on any infrastructure of your choosing, including third-party cloud providers. This is made possible using Cloud Satellite, IBM's answer to AWS Outposts and Azure Stack/Arc.
Finally, IBM is making significant investments in its data fabric to access, govern, manage, and secure data and AI workloads across clouds to address the evolving requirements of a multi-cloud future.
In the next chapter, we will learn about the Cloud Pak for Data ecosystem, which complements and extends the capabilities included in the base Cloud Pak for Data.