
Chapter 10: Security and Compliance
Cloud Pak for Data is an offering for enterprises that have stringent requirements. Cloud Pak for Data as a multi-user platform is also expected to provide governance in the implementation of separation of duties, auditing, and other compliance requirements.
The Cloud Pak for Data security white paper [1] describes many security aspects, starting with the development of software to deployment and operations.
For a containerized platform offering such as Cloud Pak for Data, where multiple services operate in a co-located manner and different user personas are expected to access the system, there are strict guidelines on how these services are developed and delivered, as well as how these services are to be managed and monitored in enterprise data centers. Chapter 9, Technical Overview, Management and Administration introduced the core concepts of the architecture stack, including how clusters can even be shared and operated securely for different tenants with sufficient isolation.
In this chapter, we will begin by exploring how IBM ensures security during the development of Cloud Pak for Data and how the stack ensures security from the ground up. Security Administrators will gain insight into specific operational considerations and techniques for safely operating Cloud Pak for Data on behalf of their users, as well as, learning of mechanisms to satisfy regulatory compliance requirements.
In this chapter, we will be exploring these different aspects:
- Secure engineering – how Cloud Pak for Data services are developed securely
- Secure operations in a shared environment
- User access control and authorizations
- Meeting compliance requirements
Technical requirements
For a deeper understanding of the topics described in this chapter, you are expected to have some familiarity with the following technologies and concepts:
- The Linux operating system and its security primitives
- Cloud-native approaches to developing software services
- Virtualization, containerization, and Docker technologies
- Kubernetes (Red Hat OpenShift Container Platform is highly recommended)
- Storage provisioning and filesystems
- Security hardening of web applications, Linux hosts, and containers
- The Kubernetes operator pattern (highly recommended)
- The kubectl and oc command-line utilities, as well as the YAML and JSON formats needed to work with Kubernetes objects
- An existing Cloud Pak for Data installation on an OpenShift Kubernetes cluster, with administration authority
The sections will also provide links to key external reference material, in context, to help you understand a specific concept in greater detail or to gain some fundamental background on the topic.
Security and Privacy by Design
The objective of Security and Privacy by Design (SPbD) is to ensure that the best practices of secure engineering are followed during the development of any offering and to implement processes for the continuous assessment of the security posture of that product. Release engineering processes and timely remediation of any security incidents or discovered vulnerabilities via Product Security Incident Response Team (PSIRT) mandates are also critical to reduce the risk of exposures and to protect against malicious actors who may compromise the system. IBM's secure development practices are described in detail in the Redbook [2]. IBM also has a formal process to track and respond to any vulnerabilities via the Product Security Incident and Response team [3].
Development practices
IBM requires all products to be developed and evaluated using strict secure engineering practices, and the services delivered for Cloud Pak for Data are no exception. With such offerings also being operated in an as-a-service fashion, accessible to the general public, security is of paramount importance right from the design of the software.
The security practices and reports are independently reviewed by the IBM hybrid cloud Business Information Security Office (BISO) prior to any release of the software.
This section describes some of the important practices used to develop security-hardened services in Cloud Pak for Data.
Vulnerability detection
A key initiative is to detect possible security weak points or potential areas that a malicious operator could leverage to introduce man-in-the-middle attacks, access sensitive data, or inject malware. Given that quite a bit of interaction with Cloud Pak for Data is through a web browser or HTTP-based clients in general, care is taken to ensure protection from both outside and in-cluster influences:
- Threat modeling: This is a process to analyze where the system is most vulnerable to attack, by building out inter-service and intra-service detailed data flow diagrams, understanding potential attack vectors, as well as evaluating whether existing protection is deemed sufficient. The output of the threat modeling exercise is used to drive the development of additional security constructs or to refactor service interactions to mitigate potential threats.
- Security quality assurance and code reviews: Additional tests are developed by a team focused on security and operating independently from typical functional development and quality assurance squads. This effort also involves validation of cross-service/cross-product integrations and a thorough evaluation of general system reliability using Chaos Monkey style testing approaches (that is, mechanisms to generate random failures in the system to validate resiliency).
This allows for a better objective evaluation of a proposed software delivery against required security guidelines. As part of this initiative, this team also conducts independent code reviews and approval of any mitigations proposed by the service development teams.
- Code scans: Static code scans and web application scans are mandatory, and a key requirement is to identify and mitigate threats as described by the Open Web Application Security Project [4] initiative. IBM Security AppScan for static source code is typically run as part of daily builds of the software and dynamic web application scanning is performed side by side with functional verification tests.
- Penetration testing: Deep testing to mimic cyber threats to identify security flaws, vulnerabilities, and unreliable systems, and in general, multiple ethical hacking techniques are required to be performed as part of every major release. This is required to be performed by a specialist organization or third-party company for independent evaluation of the deployed software.
Any findings are reviewed independently by the IBM BISO organization and tracked for immediate resolutions, even via software patches or by publishing mitigation guidelines.
In this section, we have looked at the secure engineering processes that are employed in the development of Cloud Pak for Data software. In the next section, we will look at how this software is released for customers to access in a secure manner from a trusted source.
Delivering security assured container images
Each Cloud Pak for Data service is delivered as container images and loaded into a registry. Such images are composed of various layers, with each layer bringing in multiple files and operating system packages. To mitigate risks associated with deploying such images, IBM processes require Cloud Pak for Data services to use a number of techniques prior to a release.
Vulnerability scanners
Common Vulnerabilities and Exposures (CVEs) are publicly disclosed security issues found in operating system libraries and open source packages. A fundamental risk reduction mechanism is to frequently scan all images and quickly mitigate any issues found. The IBM Vulnerability Advisor, a sophisticated service offered in the IBM Cloud, scans images for known CVEs, insecure operating system settings, exposed sensitive information in configuration files, and misconfigured applications.
Certified base images
Red Hat makes available secure Enterprise Linux (RHEL) base images [5] for offerings such as Cloud Pak for Data to leverage.
The Red Hat Universal Base Images (UBIs) provide for a supported set of operating systems and open source packages. These images also contain a much-reduced set of packages than the typical RHEL distribution and thus expose a smaller attack surface. Red Hat continuously tracks security and reliability issues on all packages and provides new versions of these base images.
By using such certified base images, Cloud Pak for Data services are able to provide a trusted and secure foundation for their functionality.
Signing
Code signing and container image signing enable enterprises to validate the IBM provenance of the Cloud Pak for Data software and ensure the integrity of the containers that run within their Kubernetes clusters. This practice reduces the risk of any malicious injection into the released container images.
The IBM Container Registry (ICR)
Container images for Cloud Pak for Data are hosted in ICR. This enables the continuous delivery of images, including security fixes and monitoring these images for vulnerabilities via online scanners, and so on.
This registry is secure, not open to the public, and access is available to only customers who have entitlement to these services. These customers will be able to pull these images with their own keys [6] and with a registered IBM ID.
Operator Lifecycle Manager (OLM)
OpenShift v4 includes OLM [7] out of the box and a prescriptive method to introduce operators, such as from Cloud Pak for Data services, into the cluster as well as to enable the continuous delivery and update of these operators. This makes it easier for cluster administrators to securely manage all operators and grant access to specific operators to individual projects within that cluster.
Supporting air-gapped clusters
Air-gapped data centers permit neither inbound nor outbound internet access. This makes it complicated for OpenShift clusters to directly pull container images from IBM's registry. While in some cases, IP whitelisting may be possible to allow such pulls, it may not work for many enterprises. Besides, there could be latency or network disruptions that impact the day-to-day operation of services in the OpenShift Kubernetes cluster.
Hence, it is expected that all OpenShift clusters are able to pull images from a designated Enterprise container registry in their own private network. It is expected that pull secrets are made available to the service accounts used by Cloud Pak for Data.
The role of a bastion node
Bastion nodes are typically machines that are deployed outside of the enterprise's private network, with controlled access to repositories and registries. Such hosts facilitate access to container images, utilities, scripts, and other content from IBM and make them available to OpenShift clusters for provisioning.
One approach is to download all images as tar.gz files and transfer these files into the private network where they can be loaded into an appropriate container registry. However, a more convenient approach is to use the container registry to directly replicate container images from ICR into the enterprise's own registry, from such a bastion node. This is made possible because the Bastion node has access to the internet and to the enterprise's own data center or at least the target registry for the duration. A bastion node's role may extend beyond just the initial installation since this approach is quite useful for pulling or replicating newer container images, including those that patch any serious vulnerabilities.
In this section, we covered how IBM Cloud Pak for Data containerized software is made available for customers from a trusted location for customers to ensure its provenance, and how these images can be introduced into the customer's own registry. In the next section, we will look at what it means to operate Cloud Pak for Data securely.
Secure operations in a shared environment
In traditional systems, many applications share the same operating system, be it a virtual machine or bare metal. However, for security reasons, these applications are typically never granted access to the operating system or run as root. Since many programs, from different products or vendors, would be operating on the same machine, care is also taken to isolate each of these operating system processes from each other.
While it has been common to simply spin up a separate virtual machine for each application to completely isolate them, it was also expensive to operate and could possibly lead to a waste of compute resources. Containers have proven to be much less expensive in the long run, but there is a trade-off with regard to less isolation of workloads. In this section, we will look at how the stack enables security from the ground up, starting with the host operating system in the cluster, to OpenShift security constructs as well as how Cloud Pak for Data leverages Kubernetes access control primitives to enforce controls on all Services operating in that cluster.
Securing Kubernetes hosts
OpenShift and Red Hat Enterprise Linux (RHEL) CoreOS provide certain constructs and safeguards to ensure the secure operation of containerized workloads on the same set of Kubernetes compute nodes. RHEL CoreOS is also considered to be immutable for the most part, and the included CRI-O container engine has a smaller footprint and presents a reduced attack surface.
Controlling host access
By default, access to the host systems for containerized workloads on OpenShift is controlled to prevent vulnerabilities in such workloads from taking over the host.
Even for the installation of Cloud Pak for Data software, logging in to the OpenShift hosts is not required nor desired. None of the running containers are permitted to expose Secure Shell (SSH) style access either.
The RHEL CoreOS hosts provide specific configuration settings [8] out of the box to ensure security even when different workloads are running on the same host.
SELinux enforcement
RHEL provides a construct called Security-Enhanced Linux (SELinux) that provides a secure foundation in the operating system [9]. It provides for isolations between containers and mandatory access control (MAC) for every user, application, process, and file and thus dictates how individual processes can work with files and how processes can interact with each other.
OpenShift requires SELinux policy to be set to "enforcing" and thus forces security at the operating system level to be hardened. SELinux provides finely-grained policies that define how processes can interact with each other and access various system resources.
Security in OpenShift Container Platform
Service accounts are authorization mechanisms that allow for a particular component to connect to the Kubernetes API server and invoke specific actions as part of its day-to-day operations. Kubernetes roles are bound to such service accounts and dictate what exactly that service account is permitted to do.
OpenShift provides additional constructs on top of Kubernetes to harden security in a cluster over and above roles.
Security Context Constraints (SCCs)
The concept of Security Context Constraints (SCCs)[10] allows cluster administrators to decide how much privilege to associate with any specific workload. SCCs define the set of conditions a Kubernetes pod must adhere to for it to be scheduled on the platform. The permissions granted, especially to access host resources such as filesystems or networks, or even which user IDs or group IDs a Pod's processes can run as, are governed by the associated SCCs. For example, the privileged SCC allows all privileges and access to host directories, even run as root, while the restricted SCC denies all of that.
By default, the restricted SCC is used for all Pods, while anything over restricted is considered an exception that a cluster administrator needs to authorize by creating a binding of that SCC to a service account.
With restricted, running processes as root is disabled and Linux capabilities are dropped, such as KILL, MKNOD, SETUID, SETGID, and so on. This SCC prevents running privileged containers as well. Host paths, host network access, and Inter-Process Communication (IPC) are denied. This is enforced by OpenShift when Pods are started up and any attempt by processes within the Pod to violate this policy results in the Pod being shut down with appropriate errors.
Cloud Pak for Data v3 introduced additional SCCs that granted incremental additional capabilities over restricted for some of its Pods without needing to use far more open SCCs such as privileged or anyuid:
- cpd-user-scc:-This custom SCC added a fixed UID range (1000320900 to 1000361000), which allows all Pods that were associated with this SCC to be run with these user IDs. This allowed different Pods to be deterministically run with well-known user IDs and helped with the management of file ownership. Note: running as root is still prohibited. This policy also removed the need to assign an FSGroup policy to every Pod, which could have adverse effects in setting filesystem permissions for shared volumes.
The FSGroup policy is needed to work around a problem where Kubernetes recursively resets file system permissions on mounted volumes. While this has a serious performance impact for large volumes, even causing timeouts and failures when pods start up, a more serious problem is associated with file permissions getting reset and perhaps made accessible to more Pods and users than originally intended.
A future capability in Kubernetes (fsGroupChangePolicy) is expected to help workloads avoid this problem. [12]
- cpd-zensys-scc: This custom SCC is identical to cpd-user-scc, except that it also allows SETUID/SETGID privileges. It also designates one UID, 1000321000, as a System user. The primary reason for this SCC is to enable system Jobs and containers to initialize persistent volumes with the right file system ownership and permissions to allow individual content in shared volumes to be safely read or modified by other Pods.
Note
With Cloud Pak for Data v4, and since OpenShift Container Platform v3.11 is reaching end-of-support, and with OpenShift Container Platform v4.6 providing additional security constructs needed for Cloud Pak for Data, these custom SCCs are no longer created. However, some services such as DB2 and Watson Knowledge Catalog continue to require additional custom SCCs in v4 as well. These are described in the service documentation [37].
Namespace scoping and service account privileges
Cloud Pak for Data services are deployed into specific OpenShift project namespaces and their service accounts are scoped to only operate within those namespaces. These service accounts are associated with various Kubernetes Deployments running in those namespaces.
OpenShift assigns a unique Multi-Category Security (MCS) label in SELinux to each OpenShift project. This ensures that Pods from one namespace cannot access files created by Pods in another namespace or by host processes with the same UID. [11].
RBAC and the least privilege principle
The concept of roles in Kubernetes helps Cloud Pak for Data employ the principle of least privilege to grant each Pod only as much authorization for actions as needed and nothing more. This is done by introducing the following roles into the namespace where Cloud Pak for Data is deployed:

Figure 10.1 – Kubernetes roles used by Cloud Pak for Data service accounts
Specific service accounts are introduced into the namespace, which are then bound to these roles. That defines the scope of privileges each account is granted.
Note
With Cloud Pak for Data v4, since custom SCCs are no longer required, a different set of service accounts, with the prefix zen- were introduced to ensure that any existing SCCs are no longer picked, even accidentally.
Kubernetes pods run with the authority of a service account. Apart from being only permitted to work within the confines of a namespace, the Cloud Pak for Data Service accounts are designed to assign only the least privileges needed for the specific actions being performed. The following table represents the key namespace scoped service accounts used in Cloud Pak for Data with v3.5 and v4 with details about what they are used for and what they are permitted to do.
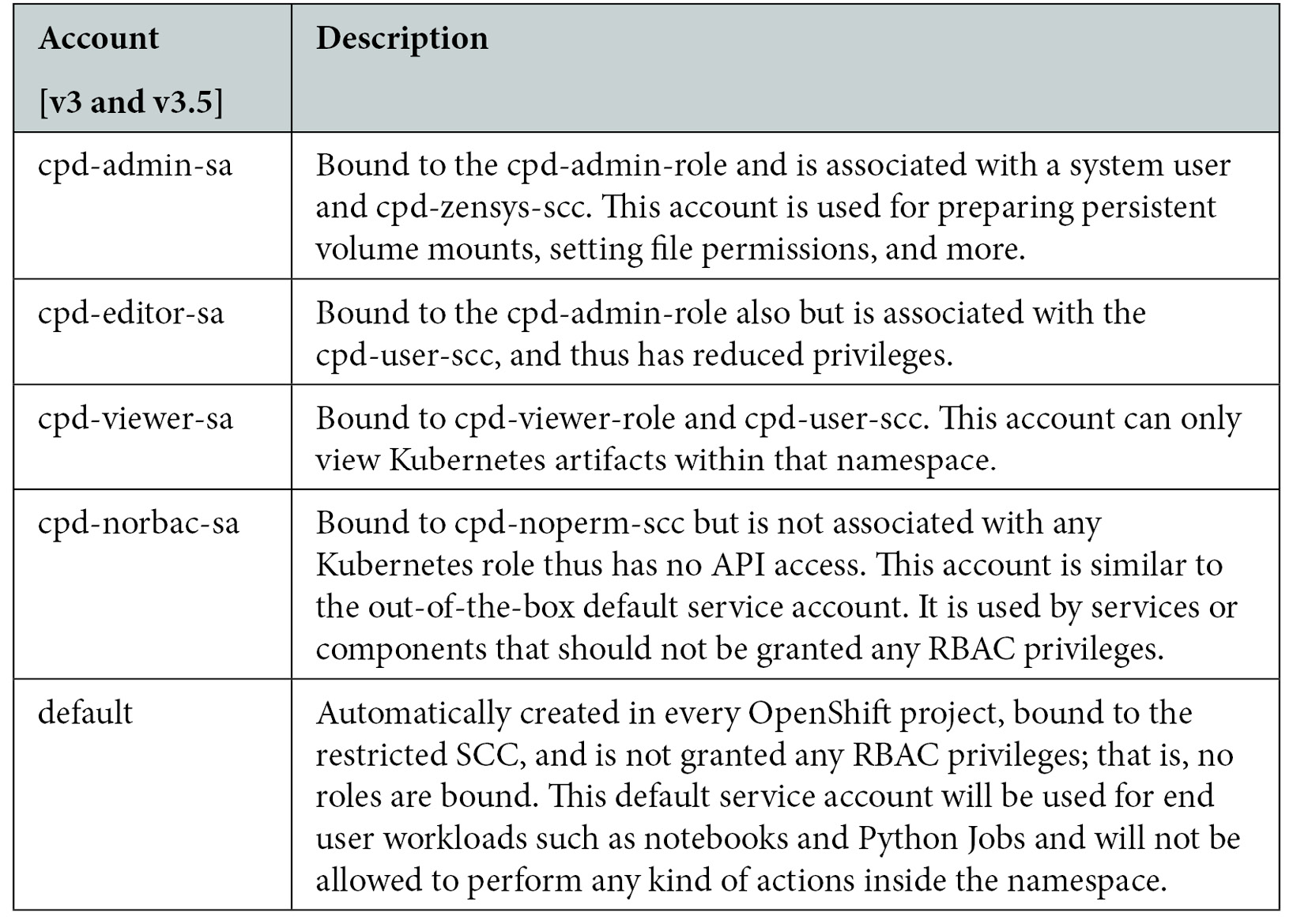
Figure 10.2 – Namespace scoped service accounts used in Cloud Pak for Data – with v3 and v3.5
Following is the Namespace scoped service accounts used in Cloud Pak for Data – with v4:
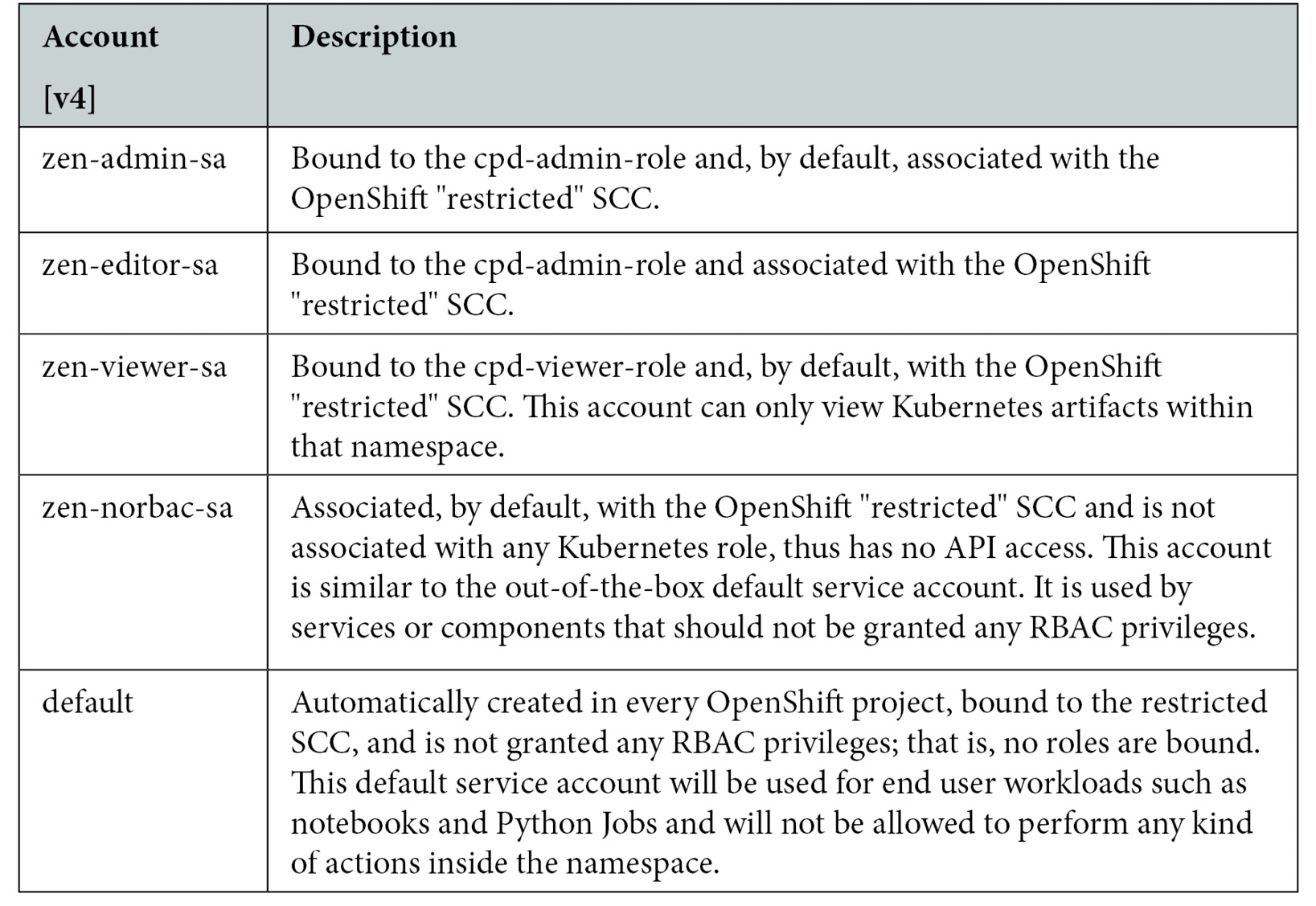
Figure 10.3 – Namespace scoped service accounts used in Cloud Pak for Data – with v3.5 and v4
Hence, system Pods and Jobs typically use cpd-admin-sa to perform higher-privileged operations, whereas regular user Pods and Jobs (such as data science environments and refinery Jobs) would be associated with default or cpd-norbac-sa to designate that they are not granted any privileges whatsoever.
A typical Cloud Pak for Data Pod spec, as shown in the following code snippet, includes securityContext directives that indicate which Linux capabilities to add or drop, as well as which user ID to run as, and even identify explicitly that the Pod must only be run with a non-root UID. The service account is also identified, which in turn grants the Pod specific RBAC in terms of working with Kubernetes resources and APIs:
securityContext:
capabilities:
drop:
- ALL
runAsNonRoot: true
serviceAccount: cpd-editor-sa
serviceAccountName: cpd-editor-sa
Workload notification and reliability assurance
Cloud Pak for Data also follows a specific convention where every container in its namespace is clearly tagged with a specific set of labels and annotations. This allows the clear identification of each Pod or Job running in the cluster, which proves crucial in identifying any rogue or compromised workloads.
The following code block shows an example of such a convention:
annotations:
cloudpakName: "IBM Cloud Pak for Data
productID: "eb9998dcc5d24e3eb5b6fb488f750fe2"
productName: "IBM Cloud Pak for Data Control Plane"
labels:
app=0020-zen-base
component=zen-core-api
icpdsupport/addOnId=zen-lite
icpdsupport/app=framework
release=0020-core
With dynamic workloads and sharing of compute, "noisy neighbor" situations can occur, where workloads grow to consume all available compute resources leading to an adverse impact on the stability of the cluster. To avoid such problems, every Pod and Job spun up in the namespace is also associated with resource requests and limits.
Cloud Pak for Data provides mechanisms to scale up and scale out compute, and by explicitly setting such compute specifications, it ensures that each Pod or Job sticks to its assigned compute resources and supports the reliable operation of a balanced cluster.
The following code block shows a Pod spec including a resource specification:
resources:
limits:
cpu: 500m
memory: 1Gi
requests:
cpu: 100m
memory: 256Mi
Additional considerations
In the previous sections, we looked at how Cloud Pak for Data workloads can be uniquely identified, how the least privilege principle is used to grant RBAC to each microservice, and even how resources consumed by each micro-service can be capped. In this section, we will cover aspects of security that apply across multiple microservices or even the entire Cloud Pak for Data installation.
We will explore what it means to do the following:
- Ensure security for data in motion between two microservices
- Secure data at rest
- Understand the relevance of traditional anti-virus software
Encryption in motion and securing entry points
Cloud Pak for Data exposes one HTTPS port as the primary access point for the browser-based user experience and for API-based access. This port is exposed as an OpenShift route. All communication inside the namespace and inbound is encrypted using SSL, with only TLS 1.2 highly secure cryptographic ciphers being enabled.
The installation of Cloud Pak for Data in an OpenShift namespace causes the generation of a self-signed TLS certificate. By default, this certificate is untrusted by all HTTPS clients and should be replaced with the enterprise's own signed TLS certificate [13].
All services in Cloud Pak for Data are required to support TLS-based encryption for service-to-service communication and for communicating with external systems. For example, DB2 exposes TLS over ODBC and JDBC for client applications, even from outside the cluster to connect securely and ensure data in transit is also encrypted. Connecting to external customer-identified databases and data lakes in services such as Data Virtualization, Watson Studio can also be configured to be over TLS.
Note that such in-transit TLS-based encryption in Cloud Pak for Data services is over and above anything that may be configured in the infrastructure. For example, it is possible that Kubernetes inter-node communication networks are also encrypted as part of a cloud infrastructure or VPN techniques.
Encryption at rest
OpenShift Container Platform supports the encryption of the etcd database [14] that stores secrets and other sensitive Kubernetes objects that are critical for day-to-day operations.
By default, only Pods within the same namespace are granted access to mount persistent volume claims. However, it is also important to encrypt data stored in these Persistent Volumes as well to avoid not just malicious actors, but also admins or operators themselves from getting access to sensitive data. Typical regulatory requirements, such as compliance to the separation of duties, require that client data is kept private and out of reach of operators. Encryption goes a long way in ensuring security and compliance in the platform.
Cloud Pak for Data supports multiple storage providers on OpenShift, each with its own techniques to encrypt volumes. Some examples are listed as follows:
- Portworx [15] provides the ability to encrypt all volumes with a cluster-wide secret passphrase or each individual volume with its own secret passphrase. Portworx also integrates with typical cloud key management systems to support the bring-your-own-keys requirement.
- Red Hat OpenShift Container Storage v4.6 and later [16] supports encryption of the whole storage cluster with a per-device encryption key stored as a Kubernetes Secret.
- IBM Cloud File Storage [17] with Endurance or Performance options support for encryption-at-rest by default and encryption keys managed in-house with the Key Management Interoperability Protocol (KMIP).
- Network file system (NFS) volume encryption depends on the underlying storage provider. The standard Linux Unified Key Setup-on-disk-format (LUKS) [18] can be leveraged as a general disk encryption technique.
While raw block or filesystem-based data-at-rest encryption is essentially beyond the scope of Cloud Pak for Data and is heavily reliant on storage infrastructure, it must be noted here that Cloud Pak for Data, by itself, ensures encryption for specific sensitive data. Examples of such data are user credentials for database connections or service keys, and these are encrypted natively by the appropriate service in its own repository, without any dependency on the underlying storage technology.
Anti-virus software
The use of traditional anti-virus software can have an adverse effect on OpenShift. For example, such software may lock critical files or consume CPU in an ad hoc fashion in the operating system, stepping around OpenShift's careful management of resources.
It is best not to think of these Kubernetes nodes as general-purpose Linux systems, but rather as specialized machines secured and managed by OpenShift as a cluster. OpenShift provides security and operations for the entire stack from the operating system to containers to individual workloads. Traditional anti-virus software cannot cover the entire stack and may interfere with the operations or reliability of the cluster.
Red Hat and OpenShift provide additional security hardening to reduce the need for anti-virus software in the first place [19]. Note that traditional scanners are typically used to locate viruses in shared file systems (such as those served by Samba) and mounted on Windows clients. But, with the prescriptive approach for operating Kubernetes within OpenShift Container Platform and on RHEL CoreOS, such arbitrary file serving should not be set up on these Kubernetes nodes in the first place.
In this section, we explored the security constructs that are available in the Operating System and OpenShift. We also looked at how Cloud Pak for Data, with the judicious use of Kubernetes RBAC can ensure the least privileges for each service account and uses a convention of labels and annotations to tag all workloads. It also constrains the assignment of compute resources to ensure secure and reliable operations. In the following section, we will look at what controls are available for Cloud Pak for Data administrators to configure authentication and ensure the right level of authorization for each user.
User access and authorizations
Cloud Pak for Data is a platform into itself, is a multi-user system, and thus also provides access control for users. It also integrates with Enterprise LDAP or Active Directory and other identity providers to ensure secure access to its services. Auditing is also supported for tracking access to the Cloud Pak for Data platform as well.
As with any multi-user system, Cloud Pak for Data identifies roles and permissions that are granted to specific users or groups of users. A suitably privileged user is tasked with the responsibility of ensuring that only authorized users can access the services and content hosted by Cloud Pak for Data.
Authentication
While Cloud Pak for Data includes a simple out-of-the-box mechanism to identify users and grant them access, this is only for initial runs and is not meant for secure production use, and will fail to meet any compliance regulation requirements. For example, password policies or multi-factor authentication cannot be supported with this default mechanism. Instead, the expectation is that the enterprise sets up connectivity to an identity provider.
Identity providers and SSO
Cloud Pak for Data provides a user experience for configuring LDAP/Active Directory for authentication, as shown in the following figure:

Figure 10.4 – LDAP setup for authentication
When LDAP is configured, authentication is delegated to the LDAP server for every sign-in to Cloud Pak for Data. Similarly, when Security Assertion Markup Language (SAML) Web Single Sign-On (SSO) [20] is set up, sign-in is redirected to the SAML log-in page instead.
Cloud Pak for Data can also be configured to cache a list of users and LDAP groups that were granted access to Cloud Pak for Data. This can be done to reduce querying LDAP for every lookup and avoid any adverse impact on the LDAP server and other enterprise services. Cloud Pak for Data provides an asynchronous Job that can be enabled and configured to run at a fixed interval to keep this cache consistent with each user's profile and group membership in LDAP.
Cloud Pak for Data also supports integrating [22] with IBM Cloud Platform Common Services IAM [21] as a mechanism to work with other identity providers and to support SSO. This is particularly useful when there are multiple Cloud Paks installed on the same OpenShift cluster. Once Cloud Pak for Data administrator privileges have been granted to a user who is authenticated by an identity provider or LDAP/Active Directory (AD), it is recommended that such an admin disable or remove all users from the internal out-of-the-box user repository, including the default admin user [23]. This is critical from an audit and compliance perspective as well, since all users would need to be authenticated by the prescribed mechanism, rather than via back doors that may exist.
Session management
Cloud Pak for Data relies on the concept of a bearer token (JSON Web Tokens) to identify a user's session. This token expires based on the policies defined in the Cloud Pak for Data configuration. For interactive usage, in the Cloud Pak for Data user experience in web browsers, the user's token is short-lived but is continuously renewed as long as the user is actively using the experience. A Cloud Pak for Data administrator can configure [24] the token expiry time and the web session token refresh period in accordance with enterprise security and compliance requirements. The web session token refresh period helps keep the user's session active. If a user is idle in their web browser for more than the configured length of time, then the user is automatically logged out of the web client.
There are two configuration parameters that govern user sessions:
- Token expiry_time – The length of time until a user's session expires.
A user who is idle for this duration will find their browser session automatically logged out.
- Token_refresh period – The length of time that a user has to refresh their session.
This defines the longest the user can stay logged in. Once their session has reached this time limit, their tokens will no longer be refreshed – even if they are active all along – and will force them to log out.
Authorization
With permissions and roles, an enterprise can define their own personas and grant them specific access to different Cloud Pak for Data services.
A role is an entity that is used to define what collection of permissions (privileges) are granted to a particular user persona.
Cloud Pak for Data services introduce one or more out-of-the-box roles to get started with and an experience to help manage roles. Enterprises can use such roles to adhere to separation of duties policies needed for compliance reasons. For example, administrators may be denied access to data (which is the default for database instances they did not provision in the first place), and also to data catalogs, by revoking specific permissions.
Granular privileges can also be granted, for example, only granting a specific set of users the ability to manage user access and to manage group access, but they need not be granted access to other administrative functions.
The administrator typically configures roles using the user management experience, as shown in the following figure:

Figure 10.5 – Managing roles experience
The following tables show examples of permissions assigned to the different out-of-the-box roles [38] in Cloud Pak for Data, as well as the associated service offerings:
- Administrator role: Administrator is a pre-defined role in Cloud Pak for Data and includes a specific set of permissions as listed in the following table. The set of permissions present depends on which services have been installed. For example, if Watson Knowledge Catalog is not present, then the Access governance artifacts permissions will not be available.

Figure 10.6 – Permissions granted to the Administrator role
- Data Scientist role: This role designates the user persona typically involved with advanced analytics and machine learning. They reference data from catalogs and collaborate with other users within projects. A small set of permissions is typically sufficient for such users, as listed in the following table. This also grants them the permission to work with deployments such as machine learning models.

Figure 10.7 – Permissions granted to the Data Scientist role
- User role: The User role is special as it typically indicates the least set of privileges assigned to a certain type of guest user. Assigning the User role to somebody just implies that they will be able to sign in and view any content that does not require any additional authorizations. Assigning the User role also serves to introduce new users to the platform, which enables them to be subsequently added (as individuals) into user groups or assigned access to projects, catalogs, or even databases.
However, when certain services, such as Watson Knowledge Catalog or Watson Studio are installed, by default, they grant additional permissions to this User role. This enables these users to at least work privately within the confines of their own projects or deployment spaces. Of course, just as with any pre-defined role, administrators can choose to alter this role and remove these permissions or introduce additional ones to suit their definition of a "least" privileged role.

Figure 10.8 – Permissions granted to the User role
The default user (admin) is automatically assigned all of the following roles out of the box, but this can be changed as needed:
- Administrator
- Business Analyst
- Data Engineer
- Data Quality Analyst
- Data Scientist
- Data Steward
- Developer
An enterprise can customize this by defining its own roles as well [25]. The admin can edit the out-of-the-box roles or create new roles if the default set of permissions doesn't align with business needs.
As part of a role's definition [26], specific permissions can be selected and associated with that role.

Figure 10.9 – Example of associating permissions with a new role
In this section, we discussed the semantics of permissions and how roles are defined or updated to suit the enterprise's requirements on access control and to identify suitable personas.
Roles are relevant to individual users as well as user groups, that is, roles can be assigned to Cloud Pak for Data User Groups, which implies that all members of that group will automatically inherit this role. In the following section, we will look more closely at how users are identified and groups are defined.
User management and groups
Cloud Pak for Data exposes APIs and a user experience for Admins to be able to manage authentication and role-based authorization for each user. The following figure provides an example of the user experience that helps the Admin grant and revoke access to users.

Figure 10.10 – Managing user access
An admin (or a user with the manage users permission) can authorize additional users to access Cloud Pak for Data.
For example, via the user experience, a new user could be introduced and assigned appropriate roles:

Figure 10.11 – Example of granting the Administrator role to a new user
As seen in the preceding figure, the Administrator granting such access can also review which permissions will be granted when this role assignment is completed. They could also choose to assign multiple roles to the same individual, granting them a union of the permissions from those roles.
Instead of granting permissions to individual users one at a time, Admins can also create user groups to simplify the process of managing large groups of users with similar access requirements. For example, if a set of users need the same combination of roles, then these users will be added to a group that is assigned the role combination. If a member of the group leaves the company, that user will be removed from the group.
Note that entire LDAP or Active Directory groups can also be assigned (mapped) to such Cloud Pak for Data user groups. This enables an enterprise to continue to leverage its existing organizational grouping, without needing to authorize every individual user one at a time.
By default, Cloud Pak for Data includes the All-users group. As the name suggests, all Cloud Pak for Data users are automatically included in this group. The group is used to give all platform users access to assets such as with Connections.
The user experience [27], shown in the following figure, enables the creation of such user groups and the assigning of roles to such groups:
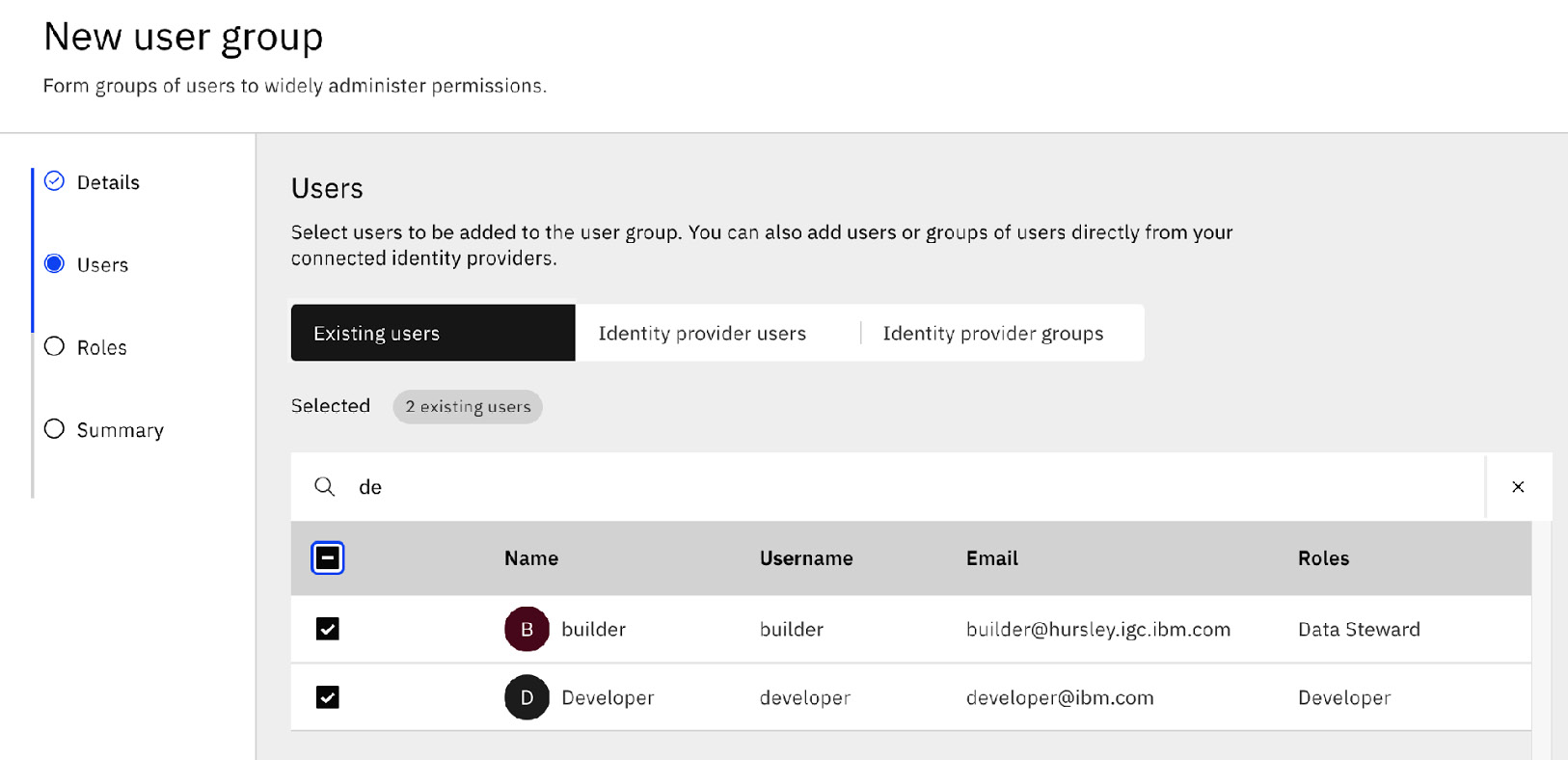
Figure 10.12 – Defining a new user group
To introduce members to such a user group, the Administrator also has the option to browse through any configured identity providers (such as LDAP) to identify individuals to add as well as map in existing LDAP groups. This provides quite a bit of flexibility as the Administrator is not limited by a fixed organizational structure in their Enterprise LDAP (say, as decided by HR) and can also, in ad hoc terms, enable sets of users even from different LDAP groups to collaborate.
The following figure illustrates how the experience enables browsing for existing LDAP groups to introduce as members of the Cloud Pak for Data user group.

Figure 10.13 – Selecting existing LDAP groups to be assigned to a new User Group
As shown in the preceding figure, the experience enables the selection of existing fully qualified LDAP groups as members of the new Cloud Pak for Data User Group.
Once at least one individual user or LDAP group has been selected, the Administrator has the option to pick one or more roles to assign to this new User Group, as shown in the following figure:
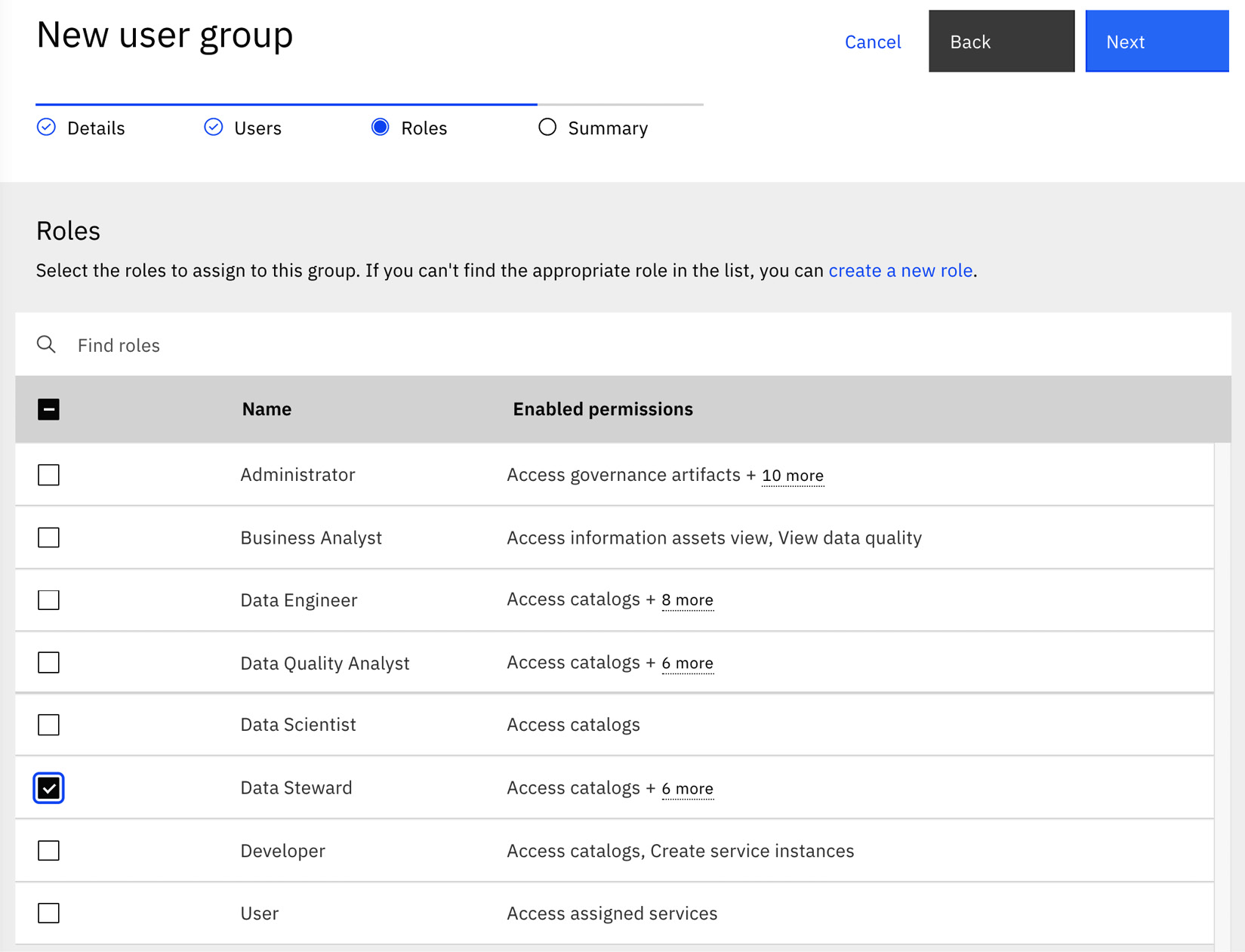
Figure 10.14 – Defining a new user group
In the preceding figure, you will notice that the Data Steward role has been assigned to the Reviewers User Group. This indicates that all members of this group will automatically be identified as data stewards and inherit the permissions that come with that role. The Administrator can also choose to change this role assignment at any time or introduce additional roles to this user group.
Note that the membership of a User Group and, by extension, the roles assigned to an individual, are dynamic when LDAP groups are used. This means that when a user is removed from an LDAP group or assigned to a different group, their subsequent sign-in will automatically ensure that their permissions reflect their current membership. An individual user may also be assigned to multiple User Groups, which means that their permissions represent a union of those inherited from their membership in all these groups.
In this section, we walked through how users and user groups are managed, and how Cloud Pak for Data integrates with enterprise authentication mechanisms, such as LDAP. Only after such a user is authenticated will they be able to access services or privileged resources in Cloud Pak for Data. In addition, there are also authorization checks. For example, users or user groups need to be granted at least a viewer role in resources such as projects or catalogs before being able to access them. Such users or groups could similarly be granted access to the Data Virtualization Service (DVS) instance as a DV Engineer or perhaps just as a Database user to an instance of a DB2 database. In summary, the User Management service supports a broad range of security requirements as it enables both authentication and flexible RBAC in the platform as well as authorization mechanisms scoped to individual resources or service instances.
Securing credentials
Cloud Pak for Data is a platform that provides several capabilities and services. It is expected that users and applications may need to connect from outside the cluster to specific API endpoints in a Cloud Pak for Data instance. Developers may also need to connect to external systems, such as databases and data lakes, as part of their day-to-day activities, for example, programmatically from notebooks or as part of Apache Spark Jobs. Such code is typically shared with other users, possibly even committed to source code repositories and, as such, it would not be prudent to have passwords and other sensitive content.
In this section, we will look at features in Cloud Pak for Data that provide the ability for such developers to avoid exposing their credentials in plain text.
API keys
Developers who invoke Cloud Pak for Data APIs from client programs can use API keys to avoid the need to persist their credentials within those clients.
Cloud Pak for Data v3.5 and later supports API keys for authentication and authorization. This allows client programs to authenticate to the Cloud Pak for Data platform or to a specific instance of a service.
Each user can generate a platform API key, which is of a broader scope and allows access to all services on the platform.
An instance API key is a particular service, and thus is only usable for that specific scope. The platform API key enables client scripts and applications to access everything that they would typically be able to access when they directly log in to the Cloud Pak for Data web client. An instance API key enables access only to the specific instance from which is it generated.
Note
The instance API key is not available for some services in the Cloud Pak for Data v3.5 release.
Cloud Pak for Data provides user interfaces and APIs [28] to generate, re-generate, or delete a platform API key or an instance API key.
The Secrets API and working with vaults
The Secrets API [29] in Cloud Pak for Data provides the ability to access sensitive credentials from configured vaults. This helps avoid the need to use plain-text credentials as part of developer-authored content such as notebooks or scripts. Using a vault, Enterprises can also control policies to rotate keys and credentials independently.
Since Cloud Pak for Data's Secrets API retrieves the contents of the vault only when required, it will get the latest password or key. This also prevents the need for users to update passwords in many places.
Cloud Pak for Data will continue to introduce integrations with different vault vendors and technologies as part of its roadmap.
Meeting compliance requirements
Regulatory compliance and enterprise policies require stringent monitoring of systems to ensure that they are not compromised. There are usually multiple standards to adhere to and different audit techniques that are required. Red Hat and IBM Cloud Pak for Data provide tools and mechanisms for security architects to design and configure the system as per the policies of their organization as well as to audit usage.
In this section, we will take a brief look at the capabilities that help enterprises plan for compliance.
Configuring the operating environment for compliance
For Cloud Pak for Data, Red Hat's Enterprise Linux for the host and OpenShift Container Platform represent the technological foundation. Hence, to ensure compliance, the foundation needs to be properly configured. A few key aspects of the technical stack that help in compliance readiness are listed as follows:
- RHEL supports a strong security and compliance posture such as setting up for the Federal Information Processing Standard (FIPS) publication 140-2. Several advanced techniques exist to secure RHEL hosts [30], including tools, scanners, and best practice guidance.
- OpenShift Container Platform v4 introduces a compliance operator [31] to help ensure compliance and detect gaps with RHEL CoreOS based hosts in general. The National Institute of Standards and Technology (NIST) organization, among other things, also provides utilities and guidance for robust compliance practices that enterprises strictly adhere to as a general principle. The OpenShift Compliance Operator provides the right level of automation to help enterprises leverage the NIST OpenSCAP utility, for example, for scanning and enforcement of policies in such complex, dynamic environments.
Cluster admins are generally tasked with the responsibility of ensuring that the cluster is set up appropriately to meet compliance standards. It is also important that there is sufficient monitoring of privileged actions in the cluster, whether in the infrastructure or at higher levels, such as with Cloud Pak for Data. The next section identifies additional configuration that would be needed to ensure the reporting of all privileged activities.
Auditing
Auditing provides a way for enterprises to prove compliance and to monitor for irregularities.
Auditing can be enabled at various levels in the stack:
- At the operating system level [32], RHEL provides mechanisms for the enterprise to monitor violations of any security policies. The audit system logs access watches for any sensitive or critical file access on that host.
- At the OpenShift Container Platform level [33], Administrators can configure auditing levels to log all requests to the Kubernetes API server by all users or other services.
- At the Cloud Pak for Data level, audit logging supports generating, collecting, and forwarding Cloud Auditing Data Federation (CADF) [34] compliant audit records for core platform auditable events.
You can configure IBM Cloud Pak for Data audit logging to forward audit records to your security information and event management (SIEM) solutions, such as Splunk, LogDNA, or QRadar.
The audit logging implementation uses Fluentd output plugins [35] to forward and export audit records. After you install IBM Cloud Pak for Data, the Audit Logging Service is not configured out of the box. External SIEM Configuration [36] can be added to the zen-audit-config Kubernetes configmap to define where the Audit Logging Service forwards all collected audit records.
While audit logging generally only covers specific privileged actions, there are typically additional regulatory requirements with regards to tracking access of data by users and applications. In the following section, we will see how that too can be implemented.
Integration with IBM Security Guardium
Guardium provides the ability to monitor data access and to ensure data security. IBM Security Guardium's Database Activity Monitoring (DAM) capability offers an advanced centralized audit repository, reporting mechanisms, as well as tools to support forensics and compliance audits. These capabilities are complementary to the system-level auditing and privileged action audit recording described in previous sections as they can expand to data protection as well.
Cloud Pak for Data enables integration with Guardium in two ways:
- Auditing sensitive data access: Cloud Pak for Data users with the Manage Catalog permissions have the authority to identify sensitive data, such as Personally identifiable information (PII), and configure it to be monitored by Guardium [39]. Since Cloud Pak for Data's Watson Knowledge Catalog service can also scan and tag sensitive data, it makes it easier for authorized users to enable those data assets to be monitored by Guardium.
- Cloud Pak for Data facilitates the provisioning of databases as well. It is critical for regulatory compliance that access to such data also be monitored. This is facilitated by a service called the Guardium E-STAP [40] service that is provisioned on top of Cloud Pak for Data and configured to intercept traffic to DB2 databases. All access to the DB2 database is then only conducted through the E-STAP interface. This service is configured to work with the Guardium appliance, which enables access logging and reporting, and access policy enforcement.
Guardium is an established and mature offering in the data protection and compliance segment. Many enterprises already leverage Guardium to automate compliance controls in a centralized fashion and the ability to integrate with Guardium enables Cloud Pak for Data customers to accelerate compliance readiness efforts with regard to their own data, complementing what is offered by the Cloud Pak for Data platform and operating environment.
In this section, we explored what techniques are available for the enterprise to get ready for regulatory compliance. In general, Cloud Pak for Data provides elegant mechanisms for RBAC and for the enterprise to be able to configure or change out-of-the-box roles to support any regulatory compliance, such as separation of duties.
Compliance requirements vary quite a bit depending on the industry the customer is in, as well as geographical requirements. In the preceding section, we also identified the need to appropriately configure all elements of the stack, including OpenShift Container Platform and its host nodes, as well as Cloud Pak for Data itself for privileged action auditing, and other integration options, such as Guardium to support data access monitoring.
Summary
In this chapter, we discussed how Cloud Pak for Data is developed and the IBM secure engineering practices that are employed. We also looked at how container images are delivered from trusted locations for customers to pull from or download.
Once Cloud Pak for Data is installed, care must be taken to ensure that it is operated in a secure manner. We looked at constructs with which RHEL and OpenShift provide a secure foundation for workloads and the security posture of Cloud Pak for Data on OpenShift Container Platform.
We also looked at how administrators are tasked with the responsibility of managing user and group access to ensure authorization is enforced in addition to configuring appropriate identity managers for authentication, as well as defining appropriate roles or modifying out-of-the-box user roles.
Security is critical to any software installation and Cloud Pak for Data is no exception. This chapter, in addition to describing the technology, also provided pointers to practical mechanisms to secure and monitor each part of the stack to ensure the safe and reliable operation of Cloud Pak for Data in your enterprise.
In the next chapter, we will look at storage, yet another foundational and critical construct for the reliable operation of Cloud Pak for Data.
References
- Cloud Pak for Data Security Whitepaper: https://community.ibm.com/community/user/cloudpakfordata/viewdocument/security-white-paper-for-cloud-pak?CommunityKey=c0c16ff2-10ef-4b50-ae4c-57d769937235&tab=librarydocuments
- Redbook: [ Security in Development: The IBM Secure Engineering Framework: [https://www.redbooks.ibm.com/redpapers/pdfs/redp4641.pdf]
- IBM PSIRT: [ IBM Security and Vulnerability management]: https://www.ibm.com/trust/security-psirt
- The Open Web Application Security Project (OWASP): https://owasp.org/www-project-top-ten/
- Red Hat Enterprise Linux (RHEL) base images: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html-single/building_running_and_managing_containers/index/#working-with-container-images_building-running-and-managing-containers
- IBM Container Software Library Access keys: https://myibm.ibm.com/products-services/containerlibrary
- Operator Lifecycle Manager: https://docs.openshift.com/container-platform/4.6/operators/understanding/olm/olm-understanding-olm.html
- Host and VM security: https://docs.openshift.com/container-platform/4.6/security/container_security/security-hosts-vms.html
- Security Enhanced Linux (SELinux): https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/using_selinux/getting-started-with-selinux_using-selinux#introduction-to-selinux_getting-started-with-selinux
- OpenShift Security Context Constraints: https://docs.openshift.com/container-platform/4.6/authentication/managing-security-context-constraints.html
- A Guide to OpenShift and UIDs: https://www.openshift.com/blog/a-guide-to-openshift-and-uids
- Kubernetes volume permission and ownership change policy: https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#configure-volume-permission-and-ownership-change-policy-for-pods
- Using a custom TLS certificate for the Cloud Pak for Data service: https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_latest/cpd/install/https-config-openshift.html
- Encrypting etcd: https://docs.openshift.com/container-platform/4.6/security/encrypting-etcd.html
- Portworx volume encryption: https://docs.portworx.com/portworx-install-with-kubernetes/storage-operations/create-pvcs/create-encrypted-pvcs/
- Encryption with OpenShift Container Storage: https://access.redhat.com/documentation/en-us/red_hat_openshift_container_storage/4.6/html-single/planning_your_deployment/index#data-encryption-options_rhocs
- IBM Cloud File Storage encryption: https://cloud.ibm.com/docs/FileStorage?topic=FileStorage-mng-data
- Implementing Linux Unified Key Setup-on-disk-format (LUKS): https://access.redhat.com/solutions/100463
- Anti-virus software for RHEL: https://access.redhat.com/solutions/9203
- Configuring Single Sign-on with SAML for Cloud Pak for Data: https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_latest/cpd/install/saml-sso.html
- IBM® Cloud Platform Common Services Identity and Access Management: https://www.ibm.com/support/knowledgecenter/en/SSHKN6/iam/3.x.x/admin.html
- Integrating Cloud Pak for Data with Cloud Platform Common Services: https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_latest/cpd/install/common-svcs.html
- Disabling the out-of-the-box Cloud Pak for Data Admin user: https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_latest/cpd/admin/remove-admin.html
- Configuring the Cloud Pak for Data idle session timeout: https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_latest/cpd/install/session-timeout.html
- Managing Roles in Cloud Pak for Data: https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_latest/cpd/admin/manage-roles.html
- Pre-defined Roles and Permissions in Cloud Pak for Data: https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_latest/cpd/admin/roles-permissions.html
- Managing Cloud Pak for Data user groups: https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_latest/cpd/admin/manage-groups.html
- Generating Cloud Pak for Data API keys: https://www.ibm.com/support/producthub/icpdata/docs/content/SSQNUZ_latest/cpd/get-started/api-keys.html
- Cloud Pak for Data secrets API: https://www.ibm.com/support/knowledgecenter/SSQNUZ_3.5.0/dev/vaults.html
- Configuring RHEL for compliance: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/security_hardening/scanning-the-system-for-configuration-compliance-and-vulnerabilities_security-hardening#configuration-compliance-tools-in-rhel_scanning-the-system-for-configuration-compliance-and-vulnerabilities
- OpenShift Compliance Operator: https://docs.openshift.com/container-platform/4.6/security/compliance_operator/compliance-operator-understanding.html
- RHEL Auditing: https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/8/html/security_hardening/auditing-the-system_security-hardening
- Configuring OpenShift Audit Polices: https://docs.openshift.com/container-platform/4.6/security/audit-log-policy-config.html
- Cloud Auditing Data Federation (CADF): https://www.dmtf.org/standards/cadf
- Fluentd output plugins: https://docs.fluentd.org/output
- Exporting IBM Cloud Pak for Data audit records to your security information and event management solution: https://www.ibm.com/support/pages/node/6201850
- Creating Custom Security Context Constraints (SCC) for Services: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=tasks-creating-custom-sccs
- Pre-defined Roles and Permissions in Cloud Pak for Data: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=users-predefined-roles-permissions
- Data Access Monitoring with Guardium: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=integrations-auditing-your-sensitive-data-guardium
- Guardium E-STAP for supporting compliance monitoring and data security for databases in Cloud Pak for Data: https://www.ibm.com/docs/en/cloud-paks/cp-data/3.5.0?topic=catalog-guardium-external-s-tap