
Chapter 11: Storage
Cloud Pak for Data leverages the Kubernetes concept of persistent volumes, which is supported in OpenShift, to enable its various services so that it can store data and metadata. Cloud Pak for Data services can also connect to remote databases, lakes, and object stores, as well as remotely exported filesystems as sources of data. We will look at the concepts and technologies that power both in-cluster PVs and off-cluster external storage. By the end of this chapter, you will have learned about what options are available in various public and private cloud infrastructures, as well as how to best optimize data storage for your use cases. You will also learn how storage should be operationalized, especially to support the continuous availability of your entire solution.
In this chapter, we're going to cover the following main topics:
- Persistent volumes
- Connectivity to external volumes
- Operational considerations
Understanding the concept of persistent volumes
We will start by providing a quick introduction to the foundational storage concepts in Kubernetes and how Cloud Pak for Data leverages storage. Typical containers are stateless, which means that any files they create or any changes they make will be ephemeral; upon restarting the container, these changes would not be restored. Also, in-container files would be created in a temporary location on the host, which can cause contention with other, similar consumers of that location. In Kubernetes, the concept of volumes [1] enables the persistence of directory files that are needed for stateful containers. Such volumes are mounted in a Kubernetes Pod and, depending on the access mode associated with that volume, the same directory contents can be shared with other Pods running concurrently within that Kubernetes namespace.
In this section, you will learn what it means to provision entities known as persistent volumes, which provide storage for Cloud Pak for Data workloads and can be configured for performance, reliability, and scale.
Multiple technologies and vendors enable storage in Kubernetes; we will explore those currently certified by Cloud Pak for Data.
Kubernetes storage introduction
Kubernetes provides a construct called persistent volume claims (PVCs)[2] as an abstraction for Pods to mount block and file persistent volumes (PVs) [2] without needing vendor-specific handling. Storage vendors, typically introduced as operators, provide the necessary services to define storage classes [3] and dynamic provisioners [4] to create, initialize, and mount these volume filesystems in different Pods. While the storage software and configuration are vendor-specific, the concept of PVCs makes consuming storage a standard procedure that's immune from the technology that's used to provide that storage.
Note that Cloud Pak for Data requires the use of dynamic provisioners; that is, the ability to provision storage on-demand. Static provisioners, which predefine storage volumes, are insufficient as Cloud Pak for Data services are deployed via a dynamic, plug-n-play mechanism. Scaling out such services could also, in many classes, automatically require us to create new volumes.
PVs and storage classes are Kubernetes resources at a cluster-wide scope. However, PVCs are OpenShift project (Kubernetes namespace) scoped entities, which means they can only be associated with stateful sets and Deployments within the same namespace.
Types of persistent volumes
From Cloud Pak for Data's perspective, PVs can be classified as follows:
- Dedicated volumes: These are block stores that are mounted by only one Pod at a time. Access mode: Read-Write-Once (RWO).
- Shared volumes: These are shared filesystems that are mounted read-write by many Pods in the same namespace. Access mode: Read-Write-Many (RWX).
The following diagram shows an example of the user-home persistent volume, which is mounted by many different Pods at the same time:
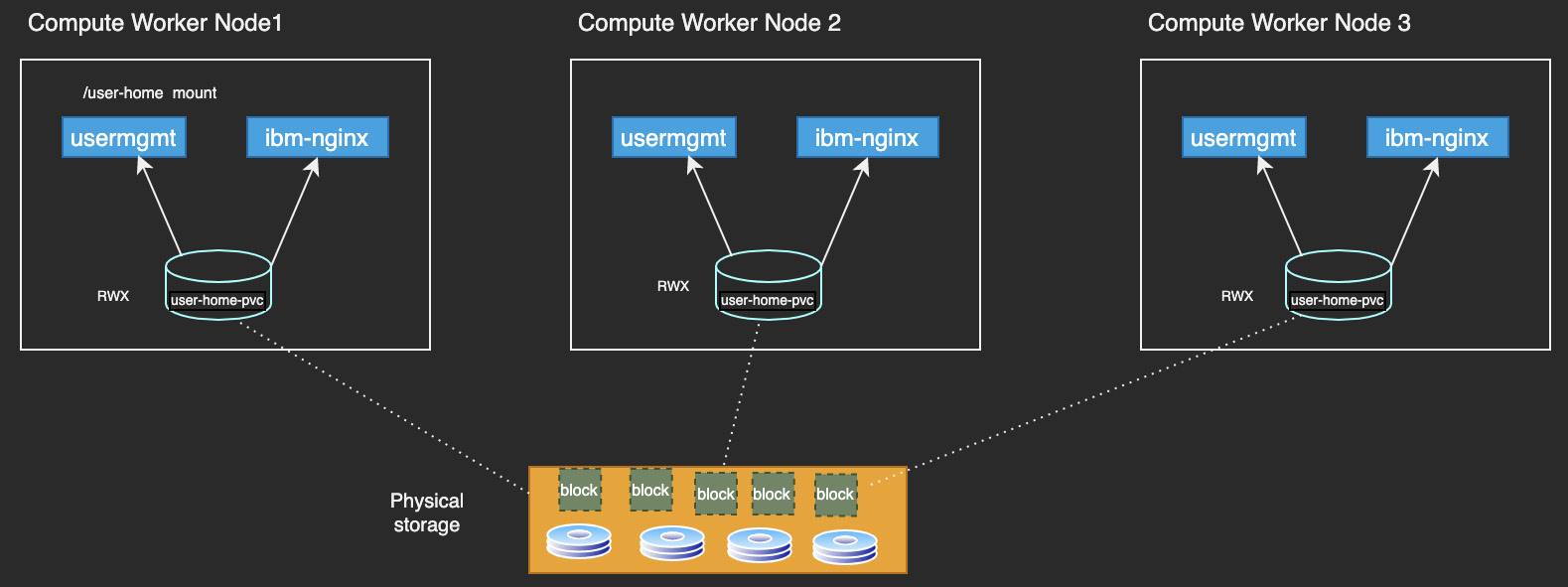
Figure 11.1 – The user-home shared volume
Depending on the storage technology being used, the blocks of data may be distributed across different disk devices and replicated for durability and resilience. Even if there are concurrent reads and writes from multiple Pods, these are typically synchronized across the different copies of the blocks. The storage drivers typically provide a POSIX [5] compliant filesystem interface and abstract all the physical aspects. Some vendors even provide caching techniques from a performance perspective.
Storage classes, represented by the StorageClass Kubernetes Kind resource, are used to reference each type of volume. When Cloud Pak for Data services are provisioned, they include PVC declarations, which are then processed by Kubernetes to provision and bind PVs.
For example, the user-home volume is requested by defining a PersistentVolumeClaim that resembles the following:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: "user-home-pvc"
spec:
storageClassName: {{ <user-selected-storage-class> }}
accessModes:
- ReadWriteMany
resources:
requests:
storage: {{ default "100Gi" or <user-selected-size> }}
You will also notice that the PVC definition identifies parameters, such as the storage class to use and the storage size that's been requested. These are introduced via the installation options for the Cloud Pak for Data services.
The declarations in the claim, along with the class of storage and other attributes (such as size and accessModes), represent a request to Kubernetes to provision a volume for use by the Cloud Pak for Data service. Once the storage volume has been provisioned, Kubernetes then satisfies that claim by binding the provisioned PV to the PVC. This binding metadata then enables Kubernetes to always mount the same storage volume in the Pods, as well as for services to use the abstraction of the PVC to always refer to the volume, without needing to know the specifics of where the volume exists physically or the driver/storage technology behind it.
Note
You will not need to explicitly define the PVC yourself. The PVC will be declared during the Cloud Pak for Data service installation process.
StorageClass definitions can also identify the vendor-specific provisioner to be used. Some storage classes are predefined when the storage software is installed in the OpenShift cluster, while other vendors provide this for defining new storage classes, with custom parameters for fine-tuning volumes for specific use cases.
As an example, the ocs-storagecluster-ceph-rbd (RWO) and ocs-storagecluster-cephfs (RWX) storage classes are present as part of the OpenShift container storage installation, while Portworx defines storage classes explicitly with different sets of configurable attributes for performance or quality.
The Portworx Essentials for IBM installation package includes a list of storage classes that are used by Cloud Pak for Data services. Here is a snippet of one of the RWX classes; that is, portworx-shared-gp3:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: portworx-shared-gp3
parameters:
priority_io: high
repl: "3"
sharedv4: "true"
io_profile: db_remote
disable_io_profile_protection: "1"
allowVolumeExpansion: true
provisioner: kubernetes.io/portworx-volume
reclaimPolicy: Retain
volumeBindingMode: Immediate
Here is a snippet of the portworx-metastoredb-sc RWO class:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: portworx-metastoredb-sc
parameters:
priority_io: high
io_profile: db_remote
repl: "3"
disable_io_profile_protection: "1"
allowVolumeExpansion: true
provisioner: kubernetes.io/portworx-volume
reclaimPolicy: Retain
volumeBindingMode: Immediate
Here, you can see that there are some vendor-specific parameters. Some are meant for performance optimization, while others are meant for redundancy (replication) and control, such as checking whether such provisioned volumes can be expanded.
Similarly, other storage provisioners, such as IBM Spectrum Scale, have similar configuration parameters as part of their storage classes.
Once Kubernetes provisions these PVs, as specified in the requested PVCs, Kubernetes uses the binding between the physical location of the storage and the PV construct to abstract how storage is accessed by individual Pods. These provisioned PVs are then mounted by Kubernetes upon startup of the individual Cloud Pak for Data Pods, using drivers provided by the storage vendors or the underlying technology.
As part of installing Cloud Pak for Data services, specific storage classes are selected by the user as installation parameters. The Cloud Pak for Data documentation [6] includes guidance on which types of storage classes are appropriate for each service [7].
Now, let's look a bit deeper into the storage topology itself, such as where the storage could be located and what it means for different Kubernetes Nodes to access this.
Broadly, we can classify the storage locations like so:
- In-cluster storage: This is where the physical storage devices/disks and the storage software control system are. They are used to provision and manage volumes in those devices, and they are also part of the same Kubernetes cluster as Cloud Pak for Data itself.
- Off-cluster storage: This is where the physical storage devices and the storage software is operated independently from the Kubernetes cluster where Cloud Pak for Data is expected to run. Only the storage drivers may exist on the Kubernetes cluster, as well as their provision and mount volumes from that remote storage system.
From a storage volume access perspective, various types of software drivers (software-defined storage) and plugin code exist in the Kubernetes ecosystem to support mounting volumes [12]. Some are called "in-tree" volume provisioners, which refer to code that natively exists in Kubernetes itself to work with such types of storage, while others are referred to as "out-of-tree" provisioners, which refer to code that exists outside of Kubernetes but can be plugged to work with different storage solutions. Recent versions of Kubernetes also include a driver standard called the Container Storage Interface (CSI) [13]. These provisioners present one or more storage classes that provide the storage abstraction needed for applications in Kubernetes. Hence, Kubernetes applications can be designed to work against the PVC and storage class standards and be completely independent of the actual physical location, the organization, or the drivers needed to work with storage.
In-cluster storage
This deployment option typically refers to co-locating storage and compute within the same Kubernetes cluster as Cloud Pak for Data services. Storage devices are attached to multiple compute worker or infrastructure Nodes, while a software-defined storage solution coordinates how the storage will be provisioned and consumed by mounting the volumes wherever they're needed. These Nodes are typically connected over a low latency and high throughput network inside the cluster. Such storage is only meant to be used by applications and workloads running inside that Kubernetes cluster.
Kubernetes natively includes the ability to mount volumes directly by using hostPath from the compute host [8], as well as node affinity mechanisms by using local volumes [9] to work around the logistical issues of scheduling Pods on the same workers as storage. However, these options do not provide dynamic provisioning support, and reliability is compromised when the underlying worker Nodes go offline. Also, OpenShift's restricted security context [11], by default, will not permit large numbers of such volumes from the host. The use of hostPath or local volumes also causes a tight coupling with Kubernetes applications in terms of storage. The portability of applications and the clean abstraction of storage classes and provisioning technologies is lost. For these reasons, Cloud Pak for Data does not rely on hostPath or local volume types.
Optimized hyperconverged storage and compute
This deployment model takes advantage of storage devices that are physically co-located in a hyperconverged fashion with compute. The storage is in the proximity of the same physical worker node as the compute, which enables optimization to occur, as well as workloads to distribute themselves to take advantage of such co-location [10]. This can be seen in the following diagram:

Figure 11.2 – Compute and storage in the same cluster
Note that the blocks of data may be distributed across devices on multiple Nodes, promoting durability and failure recovery for high availability. Some storage technologies can schedule the co-location of a Pod with physical storage and deliver optimization to provide a "local" mount, without the overhead of network access [10]. Others may still network mount volumes from the same host, but co-location still provides a performance advantage.
In the previous diagram, you will also notice that it is entirely possible to have Nodes that do not have storage but can mount volumes from other storage Nodes. This can potentially allow for partial co-location and independent scale-out of computing from storage.
Separated compute and storage Nodes
A slight variation of the in-cluster storage model is to have dedicated storage Nodes and dedicated compute Nodes. Storage Nodes can have disks but they only allow the storage software service Pods to run. That is, the Cloud Pak for Data Pods are run separately from storage, and each can be scaled independently:

Figure 11.3 – Fully separated storage and compute Nodes
This organization can still be considered hyperconverged in the sense that the Kubernetes cluster supports both storage and compute. The private low latency network between the Nodes in the Kubernetes cluster would still be able to support access to storage from Pods in a performant manner.
This variation would not be able to support the possibility of a "local" mount optimization taking advantage of the physical co-location of storage blocks and compute, but it has the advantage of simplifying node operations and maintenance. This separation can help ensure the storage services are not impacted by a sudden surge (of noisy neighbor syndrome) from other Kubernetes workloads and vice versa.
Provisioning procedure summary
Let's take a look at the procedure for making such storage available to Cloud Pak for Data services:
- First, you must install the storage software, including the associated provisioner, in the OpenShift cluster and configure the disk devices for locating the volumes. This is usually done through the storage vendor's operator and operator life cycle manager:
Currently, Cloud Pak for Data supports OpenShift Container Storage (OCS) and Portworx Essentials for IBM/Portworx Enterprise. Spectrum Scale CSI Drivers and IBM Cloud File Storage are certified for a subset of its services.
NFS is also supported, but NFS is not an in-cluster storage solution per se, but rather a protocol that allows us to access storage in a standard manner from remote file servers. NFS is used to provision volumes on other cloud storage providers such as Google Cloud Filestore, Azure locally redundant SSDs, AWS Elastic File System, and more.
If needed, you can also label the Nodes or select infrastructure Nodes as storage Nodes, as opposed to co-locating storage with compute.
- Next, define the storage classes as needed with references to the storage vendor-specific dynamic provisioner.
- Install Cloud Pak for Data services and use the storage class names as parameters:
PVCs and template declarations will include the storage class names for identifying the right type of volumes to provision.
Individual Kubernetes Deployments and stateful sets specifications will associate these claims with mount points.
In this section, you learned how physical storage can compute and be part of the same Kubernetes cluster, as well as how to take advantage of such hyperconverged co-location. However, there is one distinct disadvantage – such a storage organization is considered scoped for containerized applications within that one cluster only. Two Kubernetes clusters would not be able to take advantage of a pool of storage devices, and the storage management operational expenses would double.
In the next section, we will look at a different organization, where storage is managed so that it supports multiple Kubernetes clusters, and perhaps even non-containerized storage requirements.
Off-cluster storage
In some situations, enterprises prefer to fully separate compute and storage, or even use a centralized storage management solution that is independently operated, to support the provisioning requirements of multiple clusters. This is quite similar to the separated compute and storage (Figure 11.3) model we described previously, except that the storage cluster is not part of the same OpenShift cluster. This also enables enterprises to leverage their existing investments in storage management solutions outside of Kubernetes.
It is important to note that the use of PVCs, with their abstraction of the location of physical storage, makes it possible for Kubernetes applications to seamlessly work in this case as well. Essentially, Cloud Pak for Data services mount these volumes without having to be know if the storage is external to the OpenShift cluster. Just selecting alternative storage classes during installation would make this possible.
In this deployment model, a sophisticated storage management solution exposes the ability to consume storage from many different Kubernetes clusters (and usually traditional VMs or bare-metal ones too), at the very least with the ubiquitous NFS protocol. Many storage solutions, such as IBM Spectrum Scale [15] and Red Hat OpenShift Container Storage [16], can also support this kind of topology using CSI drivers [13], without needing NFS.
NFS-based persistent volumes
Kubernetes supports the NFS protocol out of the box. However, it is meant to work with exported NFS volumes outside the cluster with vendor storage technology that can expose the NFS protocol. The Kubernetes project provides the NFS dynamic provisioner service, which can be used to identify an external NFS server and one exported filesystem, and then create PVs as sub-directories in that NFS exported filesystem on demand.
The following diagram shows an example of how a central storage management solution can expose volumes (either via the standard NFS protocol or other custom mechanisms):

Figure 11.4 – Centralized storage management with NFS
Storage is expected to be provisioned dynamically as needed, by provisioners, to satisfy the PVCs defined in Kubernetes. Drivers (or, natively, NFS) support how these volumes are physically mounted in different Pods that have been scheduled on different Kubernetes compute workers.
For detailed guidance on how to use this provisioner and the storage class to define, see [14] in the Further reading section.
Note that the expectation, from a production perspective, is that this assigned NFS server does not become a single point of failure, that it is highly available, and that it supports automatic failover (that is, it can't be something as trivial as the NFS daemon on a single Linux system). If the NFS server fails, all the PVC mounts would become unusable. Hence, an enterprise-class resilient storage management solution is critical for ensuring overall reliability.
Operational considerations
In the previous sections, we discussed what it means to provide or consume storage either in-cluster or off-cluster for the containerized services in Cloud Pak for Data. However, it is also critical to make sure that the storage infrastructure itself is resilient and that operational practices exist to ensure that there is no data loss. Storage failover must also be taken into account from a disaster recovery (DR) standpoint.
In this section, we will take a quick look at some typical practices and tools we can use to ensure that the Cloud Pak for Data services operate with resilience, and that data protection is assured.
Continuous availability with in-cluster storage
A core tenet in Kubernetes is to ensure the continuous availability of applications. This includes load balancing and replicas for compute that can span multiple zones. Such zones could be failure (or availability) zones in public clouds or perhaps independently powered racks of hardware for an on-premises deployment [17].
In terms of in-cluster storage, this requires that the storage is also continuously replicated – this heavily depends on the storage vendor or technology in use. Here is an example topology for continuous availability, sometimes also referred to as active-active DR:

Figure 11.5 – Active-active DR
This model is sometimes referred to as a stretched cluster due to the assumption is that there is just one cluster, even though some Nodes may be located in different physical "zones."
The key here is to ensure that the storage blocks are replicated across zones in a near-real-time fashion. With this kind of deployment, stateful Pods would always have access to their PVs, regardless of which zone they are physically located in. The failure of one storage node/replica should not cause the entire application to fail. This is because other storage replicas should be able to serve the necessary blocks of data. The storage drivers in Kubernetes that support this notion of continuous availability completely abstract (via PVCs) where the data is physically picked up from, and they can fail over automatically to use storage from a different replica.
From a load balancing perspective, we typically consider that all compute Pods are always active and available for use, irrespective of the zone they are located in. Even if an entire zone becomes unavailable, only the compute and storage replicas become inaccessible, which means other replicas can take up the slack.
Such storage drivers are typically also configured to be aware of the cluster topology [18], for example, by the use of Kubernetes node labels to designate failure zones. This enables them to place PV replicas in different zones and thus offer resiliency in the case of the loss of one zone. A common problem with such a replication model is the "split brain" effect, where storage replicas have inconsistent data blocks because of failure situations where different Nodes don't communicate and synchronize data. Hence, such storage drivers have the sophistication to cordon off storage under these conditions, as well as identify when a replica has been offline for too long and needs to be updated to "catch up" or copy over data blocks when new storage replicas are added. This is critical to ensure that application data is always kept consistent in all its replicas.
While having a low latency network between such zones is critical, this multi-zone replication technique also requires such sophistication from the storage technology being used. For example, Red Hat OpenShift Container Storage (Ceph) and Portworx Enterprise support such requirements, as do most public cloud IaaS storage providers.
Continuous storage availability is technically possible with off-cluster storage as well, though it takes a bit more effort to align the storage zones with the Kubernetes cluster zones. External storage managers such as IBM Spectrum Scale, Dell EMC Isilon, NetApp onTap, and NAS-based solutions have traditionally provided mechanisms for synchronous replication across zones.
Data protection – snapshots, backups, and active-passive disaster recovery
It is critical for enterprises to ensure that consistent data and metadata backups occur at periodic intervals. Even if continuous availability can be achieved, having mechanisms for performing backups is essential. For example, having point-in-time backups help support "rollbacks" after data corruption incidents.
In some situations, offsite passive DR may be required. In this model, there isn't a stretch cluster or active Nodes, but a standby cluster that can be activated when there is a failure. If the DR site is geographically distant and network latency is not within the norms of a "stretch" cluster, or for a reliable performance of continuous replication for storage, then passive DR might be the only option available. In the case of a failover from the DR site, you would take previously backed up data and metadata from the active cluster and restore from backup it in the standby cluster. Then, you would designate the DR site cluster as the "active" cluster. The disadvantage here is the need to keep additional compute and storage resources in reserve, and that frequent backups are present, as well as mature operational playbooks to activate the cluster from those backups so that they meet the desired Recovery Point Objective (RPO) and minimize the downtime (Recovery Time Objective) the enterprise can tolerate.
Cloud Pak for Data, as a platform, provides options within the cpd-cli utility for data protection in general [19]. The cpd-cli backup-and-restore command enables two kinds of mechanisms to be leveraged:
- Via a storage snapshot: A snapshot of a PVC represents the state of that volume at that time. Snapshots are instantaneous because storage drivers do not take a full copy of the data blocks in that volume. The biggest advantage is that both taking a snapshot and restoring to that snapshot can be done very quickly.
A typical installation of Cloud Pak for Data services uses many PVCs. This is why a "group" snapshot that takes a snapshot of multiple PVCs in that Kubernetes namespace is recommended. Note that CSI snapshots currently do not support group snapshots and that some vendors natively snapshot mechanisms. With Portworx [20], for example, a group PVC snapshot is done by temporarily freezing I/O on all those PVCs before triggering snapshots. The cpd-cli utility provides a backup-restore snapshot command that simplifies how Portworx snapshots are triggered and managed for all Cloud Pak for Data PVs.
Snapshots are commonly stored in the same devices, which means they are only as reliable as the devices themselves. Hence, storage vendors [20] also provide mechanisms for creating such snapshots for cloud storage, such as S3 object stores.
- Via a copy of the available volume data: This approach relies on rsync or a copy of some data from PVCs being sent to another PVC (typically, a remote storage volume) or an object store. The cpd-cli backup-and-restore utility has a Kubernetes service that allows us to copy data from PVs to the backup volume.
However, this technique requires all the services in that Kubernetes namespace to be put into "maintenance mode" (or fully quiesced) to prevent any I/O from occurring while the volume data is being copied. The advantage though is that this works for any kind of storage that's used, including NFS, for the PVs and does not require anything specific from the storage system.
Quiescing Cloud Pak for Data services
For application-level consistency, writes must be paused while backups are in progress. To support such a requirement, the cpd-cli utility includes a backup-restore quiesce command that tells services to temporarily put themselves into maintenance mode. This utility also scales down some of the Deployments to prevent any I/O activity. Once the backup is complete, the backup-restore unquiesce command is used to scale up services from maintenance. Note that while such a quiesce implies that Cloud Pak for Data is unavailable for that duration - that is, under maintenance mode – being able to achieve application-consistent backups is also important.
The quiesce mechanism can also be leveraged for external storage backups or snapshots, such as when NFS is used for PVs. For example, when IBM Spectrum Scale provides NFS volumes, you could quiesce the services in the Cloud Pak for Data namespace, then trigger a GPFS snapshot and unquiesce the services.
Db2 database backups and HADR
Ensuring that databases operate in a reliable and continuous manner is often critical to an enterprise. While write suspends/quiesce is supported, Db2 provides additional techniques that allow Db2 databases to be available online [22] for use, even when backup operations are in progress. This is also independent of the storage technology chosen and it can support incremental backups.
The Db2 High Availability Disaster Recovery (HADR) configuration [23] airs two Db2 database instances that could exist in either the same cluster (say, a different Kubernetes namespace) or even a remote cluster. In this configuration, data is replicated from the active source database to a standby target. There is an automatic failover to the standby when a site-wide failure occurs or when the active Db2 database is deemed unreachable. The Db2 HADR Automatic Client Reroute (ACR) feature is a mechanism where clients connecting to the failed Db2 database seamlessly get switched over to the new active Db2 database.
Kubernetes cluster backup and restore
The snapshot mechanisms and the cpd-cli backup-and-restore utility described previously can only copy data from PVCs and restore it in new PVCs. When restoring such a backup in a new cluster, the expectation is that the target cluster is set up in the same way the original cluster was. This means that the necessary Cloud Pak for Data services must be installed in the target cluster, and that all the Kubernetes resources are present before the data restoration process takes place.
The Velero project [24] introduced a mechanism for backing up all Kubernetes resource artifacts as well. This allows the target cluster to be reconstructed with ease before data restoration occurs. The OpenShift API for Data Protection Operators [25], which was introduced by Red Hat for OpenShift clusters, combined with Ceph-CSI drivers, provides a way to better operationalize cluster-level backup and restore. It also supports additional use cases, such as to duplicate or migrate clusters.
Summary
In this chapter, we introduced the concept of PVs in Kubernetes and how Cloud Pak for Data works with different storage technologies and vendors. We also discussed storage topologies and vendors or technologies that may exist in different enterprises.
This chapter also stressed the importance of data protection and the operationalization of backup and restore, as well as DR practices. Ensuring that you have a deep understanding of storage ensures that Cloud Pak for Data services and the enterprise solutions that are built on top of them operate with both resiliency and the desired level of performance.
Further reading
- Kubernetes Volumes: https://kubernetes.io/docs/concepts/storage/volumes/
- Kubernetes Persistent Volumes and Claims: https://kubernetes.io/docs/concepts/storage/persistent-volumes/
- Storage Classes: https://kubernetes.io/docs/concepts/storage/storage-classes/
- Dynamic volume provisioning: https://kubernetes.io/docs/concepts/storage/dynamic-provisioning/
- Portable Operating System Interface (POSIX): https://pubs.opengroup.org/onlinepubs/9699919799/nframe.html
- Cloud Pak for Data Documentation – Storage Considerations: https://www.ibm.com/docs/en/cloud-paks/cp-data/3.5.0?topic=planning-storage-considerations
- Cloud Pak for Data documentation – Hardware and Storage Requirements per Service: https://www.ibm.com/docs/en/cloud-paks/cp-data/3.5.0?topic=requirements-system-services#services_prereqs__hw-reqs
- Kubernetes hostPath-Based Volumes: https://kubernetes.io/docs/concepts/storage/volumes/#hostpath
- Kubernetes Local Volumes: https://kubernetes.io/docs/concepts/storage/volumes/#local
- Portworx Hyperconvergence Using the Stork Scheduler: https://docs.portworx.com/portworx-install-with-kubernetes/storage-operations/hyperconvergence/
- OpenShift Security Context Constraints for Controlling Volumes: https://docs.openshift.com/container-platform/4.7/authentication/managing-security-context-constraints.html#authorization-controlling-volumes_configuring-internal-oauth
- Container Storage Interface Volume Plugins in Kubernetes Design Doc: https://github.com/kubernetes/community/blob/master/contributors/design-proposals/storage/container-storage-interface.md
- Container Storage Interface Specification: https://github.com/container-storage-interface/spec/blob/master/spec.md
- NFS External Provisioner: https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
- IBM Spectrum Scale Container Storage Interface: https://www.ibm.com/docs/en/spectrum-scale-csi
- Deploying OpenShift Container Storage in External Mode: https://access.redhat.com/documentation/en-us/red_hat_openshift_container_storage/4.6/html/deploying_openshift_container_storage_in_external_mode/index
- Kubernetes – Running in Multiple Zones: https://kubernetes.io/docs/setup/best-practices/multiple-zones/
- Portworx – Cluster Topology Awareness: https://docs.portworx.com/portworx-install-with-kubernetes/operate-and-maintain-on-kubernetes/cluster-topology/
- Backup and Restore: https://www.ibm.com/docs/en/cloud-paks/cp-data/3.5.0?topic=recovery-backing-up-restoring-your-project
- Portworx PVC Snapshots: https://docs.portworx.com/portworx-install-with-kubernetes/storage-operations/kubernetes-storage-101/snapshots/#snapshots
- OpenShift Container Storage Snapshots: https://access.redhat.com/documentation/en-us/red_hat_openshift_container_storage/4.6/html/deploying_and_managing_openshift_container_storage_using_google_cloud/volume-snapshots_gcp
- Db2 Backup: https://www.ibm.com/docs/en/cloud-paks/cp-data/3.5.0?topic=up-online-backup
- Db2 HADR: https://www.ibm.com/docs/en/cloud-paks/cp-data/3.5.0?topic=db2-high-availability-disaster-recovery-hadr
- Velero for Kubernetes Backup and Restore: https://velero.io/docs/v1.6/
- OpenShift API for Data Protection: https://github.com/konveyor/oadp-operator