
Chapter 9: Technical Overview, Management, and Administration
Cloud Pak for Data is a data and AI platform that enables enterprises to tap into their data and accelerate the adoption of AI to drive better business outcomes. This platform helps them modernize their data access mechanisms, organize data for trusted analytics, develop machine learning models, and operationalize AI into their day-to-day business processes. This chapter provides an insight into the foundational aspects of Cloud Pak for Data, the technology stack that powers it, and how services integrate to deliver the key capabilities needed to be successful with AI in the enterprise.
The platform serves several user personas, enabling them to collaborate easily with each other, and helps break down silos within the enterprise. It does this by abstracting the infrastructural elements and by promoting the integration of services to provide a seamless experience for all end users. Enterprises do not start off by using all services in the platform, but rather focus on specific use cases and then gradually expand to other scenarios as needed. You can have different groups of users working on different parts of a solution on Cloud Pak for Data while collaborating and sharing assets as needed. Enterprises may even have entire departments working on different use cases, with built-in isolation, and yet provide for appropriate quality of service to each such tenant. Hence, the platform also enables a plug-n-play mechanism and multi-tenant Deployment models that support the extension of the same foundational platform with additional IBM and/or third-party services.
In this chapter, we will be exploring these different aspects:
- Architecture overview
- Infrastructure requirements, storage, and networking
- Foundational services and the control plane
- Multi-tenancy, resource management, and security
- Day 2 operations
Technical requirements
For a deeper understanding of the topics described in this chapter, the reader is expected to have some familiarity with the following technologies and concepts:
- The Linux operating system and its security primitives
- Cloud-native approaches to developing software services
- Virtualization, containerization, and Docker technologies
- Kubernetes (Red Hat OpenShift Container Platform is highly recommended)
- Storage provisioning and filesystems
- Security hardening of web applications, Linux hosts, and containers
- The Kubernetes operator pattern (highly recommended)
- The kubectl and oc command-line utilities, as well as the YAML and JSON formats needed to work with Kubernetes objects
- An existing Cloud Pak for Data installation on an OpenShift Kubernetes cluster, with administration authority
The sections will also provide links to key external reference material, in context, to help you understand a specific concept in greater detail or to gain some fundamental background on the topic.
Architecture overview
In Chapter 1, The AI Ladder: IBM's Prescriptive Approach, and Chapter 2, Cloud Pak for Data – Brief Introduction, you would have seen why we needed such a platform in the first place. In this section, we will start by exploring what exactly we mean by a data and AI platform in the first place. We will outline the requirements of such a platform and then drill down further into the technical stack that powers Cloud Pak for Data.
Characteristics of the platform
Enterprises need a reliable and modern platform founded on strong cloud-native principles to enable the modernization of their businesses. Let's look at what is expected from such a modern platform in general terms:
- Resiliency: Continuous availability is a key operational requirement in enterprises. Users need to be able to depend on a system that can self-heal and failover seamlessly without needing a system administrator to manually intervene.
- Elasticity: Enterprises expect the platform to grow along with their use cases and customers. Hence, a scalable platform is yet another key requirement. We also need a platform that can support workload bursting on demand, in other words, grow automatically when new workloads come in and shrink back when they are completed. Workloads could just be an increased concurrency with more users or background, even scheduled, jobs.
- Cost-effective: The ability to support the balancing of available compute across different types of workloads and tenants is also important. In general, this also implies that compute can be easily transferred to those workloads that need it at that time; for example, the ability to assign more compute to a nightly data transformation or ML model retraining job while granting more compute to interactive users at daytime. A production workload may get a preference compared to a development workload. Thus, this requires the platform to control workloads from crossing resource thresholds, ensuring that no noisy neighbors are impacting both performance and reliability.
- Extensibility: The platform is expected to help customers start with one use case and expand when needed. This also implies that the platform cannot be monolithic and architecturally support a plug-n-play model where capabilities and services can be turned on as needed. Enabling the integration of various enterprise and third-party systems, as well as leveraging existing investments, is also key for quickly realizing value from the platform.
- Portability: Enterprises require a platform that works the same across different Infrastructure-as-a-Service providers, including on-premises. They need to be able to easily burst into the public cloud or across multiple clouds.
- Integrated: A data and AI platform needs to be able to serve different user personas with different skill levels and responsibilities. Such a platform needs to facilitate collaborations among end users, empowering them with self-service capabilities that do not require constant IT handholding. This implies a seamless user experience and APIs that abstract the complexity of the implementation from its consumers.
- Secure: The platform must enable enterprises to operate securely, enabling end user workloads or services from multiple vendors to function within well-established boundaries. A data and AI platform also needs to ensure that the enterprise is regulatory compliance-ready. Since the economics of infrastructure cost typically implies the use of shared computing and storage resources to support multiple tenants, techniques to ensure data security and isolation of tenant workloads become fundamental to the enterprise.
Technical underpinnings
In earlier chapters, we introduced Kubernetes [1] and Red Hat OpenShift Container Platform [2] as the core infrastructure powering all Cloud Paks. In this section, we will look at the capabilities of this technology that makes it the ideal vehicle for delivering a data and AI platform.
Kubernetes is essentially a highly resilient and extensible platform for orchestrating and operating containerized workloads. It embodies the microservices architecture pattern, enabling the continuous development and Deployment of smaller, independent services:
- Resilient: Kubernetes enables containerized workloads to be clustered on multiple compute nodes. Kubernetes monitors workloads ("Pods") and, via health probes, can auto-restart them when failure is detected. Even when there are compute node failures, it can automatically move workloads to other nodes. This works out well for establishing multi-zone availability, where workloads can survive the outage of entire zones.
- Elasticity: The scale-out of computing is elegantly handled by introducing additional compute nodes to the cluster. Kubernetes treats the entire set of CPU cores and memory as a pool of resources and can allocate them to Pods as needed. It also supports the concepts of replicas and load balancing, where workloads can be scaled out with multiple copies (Pod replicas). Kubernetes can then route requests to different replicas automatically in a round-robin manner, considering those replicas that may not be healthy at any instant.
- Infrastructure abstraction: With Kubernetes, workloads are deployed using higher-level constructs and without the need to be aware of the compute infrastructure that hosts it – whether on-premises or in the cloud, or whichever hypervisor is in use. Pods are seamlessly scheduled on different worker nodes based on how much compute (CPU cores and memory) is needed. Kubernetes also includes the ability to consume storage for persistence using a vendor-independent framework, and this enables enterprises to work with a wider choice of storage technologies, including leveraging existing storage solutions that they may already have in their enterprises. Software-defined networking, and the concept of OpenShift routes and ingress, as well as service discovery patterns, also ensure that workloads are well insulated from the complexity of networking, too.
- Portable and hybrid cloud-ready: OpenShift Container Platform delivers a standardized Kubernetes operating environment in many cloud Infrastructure-as-a-Service hyper-scaler environments, even offered as a service as well as on-premises on top of both virtual machine and bare metal nodes. Kubernetes thrives as an open source community, and with that comes challenges with different versions and API compatibility. OpenShift ensures a consistent release cycle for Kubernetes with fully validated and security-hardened container platforms everywhere. This ensures that enterprises can deploy their applications anywhere they need or move to another cloud, without the danger of being locked down to an initial choice of the Infrastructure-as-a-Service.
- A rich developer ecosystem: Kubernetes has quickly become the development platform of choice for cloud-native applications. OpenShift Container Platform further extends that with developer-focused capabilities, including enriching the concept of continuous delivery/continuous integration (CI/CD). With the focus on secure development and operations, OpenShift Container Platform enables rapid innovation at enterprises for developing modern cloud-native apps and solutions.
- Enterprise and multi-tenancy ready: Kubernetes, especially with its concept of namespaces, resource quotas, and network policies, can elegantly support isolations between tenants. OpenShift Container Platform [2] introduces additional security constructs, including SELINUX host primitives that greatly improve the safe sharing of OpenShift clusters among multiple tenants in a cost-effective manner.
For these reasons and more, IBM Cloud Pak for Data is powered by the Red Hat OpenShift Container Platform. This enables Cloud Pak for Data to provide an open, extensible, reliable, and secure data and AI platform in any cloud.
The operator pattern
The operator pattern [3] is an architectural concept and best practices to build, deliver, and operate applications in Kubernetes. Operators [4] are special Controllers deployed in Kubernetes that are meant to manage individual applications in an automated manner. Essentially, operators codify human experiences to manage and correct Kubernetes workloads.
Cloud Pak for Data v4 functionality is delivered as operators [5]. These operators enable users to install and configure Day1 activities. From a Day2 perspective, operators also continuously monitor and auto-correct deviations from the norm as well as support the need to scale up/out deployed Cloud Pak for Data services when needed. Operators are also leveraged to upgrade services to newer releases in an automated fashion.
OpenShift Container Platform includes the Operator Lifecycle Manager (OLM) [6] functionality that helps the OpenShift Administrator curate operators for various services (IBM, Red Hat, open source, or other third-party vendors) in a standardized manner.
Cloud Pak for Data includes a Control Plane layer that enables all services to integrate seamlessly and be managed from a single platform layer. This control plane is deployed using an operator called the Cloud Pak for Data platform operator [5]. A user with appropriate Kubernetes privileges creates a Custom Resource (CR) object in a particular Cloud Pak for Data instance namespace to indicate what service should be deployed. In the case of Cloud Pak for Data, a custom resource of the kind Ibmcpd causes the Cloud Pak for Data platform operator to trigger the installation of the control plane in that namespace.
Cloud Pak for Data is a fully modular platform and users can install services only when needed. You could even have a single standalone product on top of the control plane, but when multiple services are installed, integration happens automatically, enabling end-to-end use cases to be supported. So, the need for a use case drives which services are provisioned on top of the control plane with appropriate configuration and scale. This mechanism of extending the platform, too, follows the operator pattern, and you begin by introducing service-specific operators [30] and then instantiating these "add-on" services on top of the control plane. Appropriately privileged Kubernetes users just create and modify CRs to define what services to provision (or alter).
The platform technical stack
The Cloud Pak for Data stack, as shown in the following screenshot, is composed of four layers: the Infrastructure-as-a-Service (IaaS) layer at the bottom, and OpenShift Kubernetes providing the key compute, storage, and network infrastructure needed to support microservices on top.
IBM delivers the two key upper layers to this stack – Foundational Services that are leveraged as a common services layer by all IBM Cloud Paks. The Cloud Pak for Data control plane (called Zen), as the uppermost layer, manages the individual Cloud Pak for Data services and externalizes the API, as well as an integrated user experience:
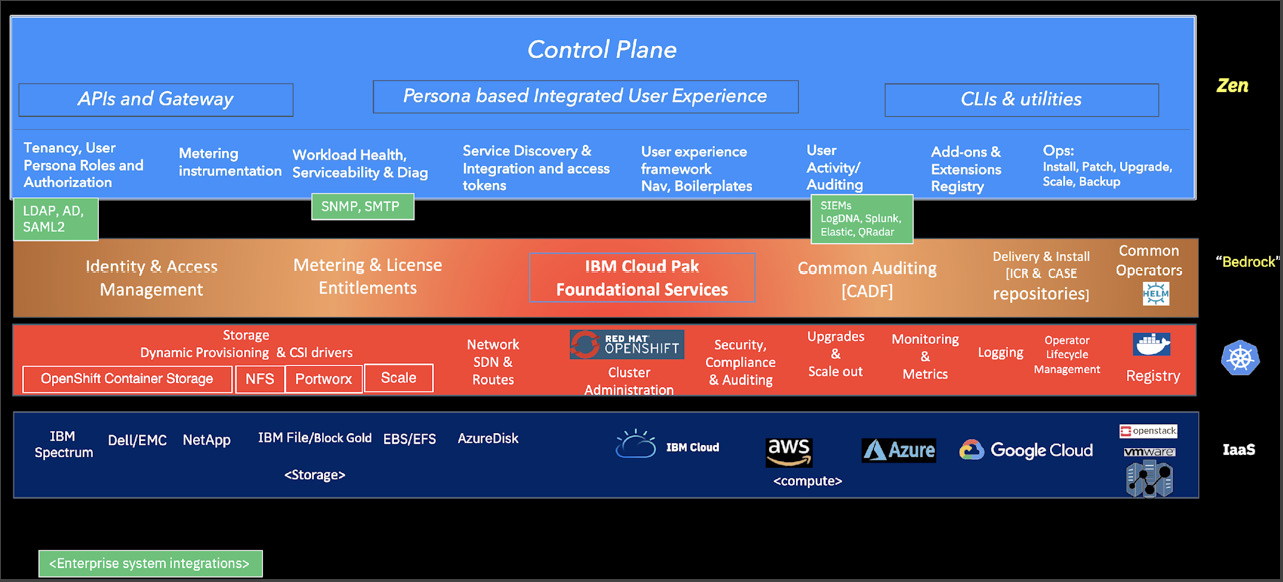
Figure 9.1 – Technical stack layers
In the following sections, we will dive deeper into the different layers of the stack and how Cloud Pak for Data, as a platform, powers data and AI solutions
Infrastructure requirements, storage, and networking
The IaaS layer could be on-premises or on the public cloud hyper-scalers. Compute could be virtualized, such as with VMware/vSphere or via Amazon AWS EC2 machines, Azure VMs, and so on, or physical bare-metal machines. These hosts form the Kubernetes master and worker nodes. Storage solutions could be native to the cloud (such as AWS EBS or IBM File Gold) or, in the case of on-premises deployments, leverage existing investments in storage solutions (such as IBM Spectrum Scale or Dell/EMC Isilon).
With OpenShift Container Platform v4, these hosts typically run Red Hat Enterprise Linux CoreOS (RHCOS), a secure, operating system purpose-built for containerized workloads. It leverages the same Linux kernel, the same packages as the traditional RHEL installation, besides being designed for remote management. In addition, for improved security, it enables SELINUX out of the box and is deployed as an immutable operating system (except for a few configuration options).
OpenShift Container Platform can thus manage CoreOS Machine configurations, save states, and even recreate machines as needed. OCP's update process can also enable the continuous upgrade of the RHCOS hosts, making it much easier to maintain and operate clusters. RHCOS, with a smaller footprint, general immutability, and limited features helps present a reduced attack surface vector, improving the platform's overall security posture.
The Kubernetes community introduced a specification called the Container Runtime Interface (CRI) [8], which enables it to plug in different container engines. RHCOS includes the CRI-O [9] container engine, which enables integration with Open Container Initiative (OCI)-compliant images. CRI-O offers compatibility with Docker and OCI image formats and provides mechanisms to trust image sources, apart from managing the container process life cycles.
The following diagram provides a simplistic high-level outline of a Kubernetes cluster [10] to illustrate how it functions, just to set the context for how Cloud Pak for Data leverages it:

Figure 9.2 – Kubernetes architecture overview
There are essentially two types of host nodes – the Master and Compute (worker) nodes. In some implementations, a node may have both the master and compute roles, but it is highly recommended to maintain separate masters to ensure a better class of reliability. Each node includes some fundamental components [11] such as the Kubelet daemon and the functionality to interact with the container runtimes on each node. The master nodes include certain special components, such as the API server and the scheduler.
Kubernetes uses the etcd database for storing configuration information and this database is critical for overall operations. etcd is a key-value distributed store and, for high availability, can work with multiple replicas on different hosts, establishing a quorum. It is recommended that you start with three master nodes and expand when it becomes necessary to support a larger set of applications at scale.
The compute nodes are where application workloads are scheduled by Kubernetes to run. All Cloud Pak for Data Pods only run on the compute (worker) nodes. Kubernetes also includes the ability to schedule Pods in specific (dedicated) nodes as well, but in general, Pods can be randomly scheduled on any of the compute nodes. If a compute node, goes down, Pods could be rescheduled to run on a different node. Cloud Pak for Data services primarily leverage Kubernetes constructs such as Deployments [12] and StatefulSets [13] to schedule its microservices in Kubernetes. These "controllers" set up the right count of replicas for that microservice, identify what persistent volume storage to mount for the Pods, and declare requests for compute resources.
Understanding how storage is used
Cloud Pak for Data requires the use of a dynamic storage provisioner [20] in Kubernetes to create persistent volumes on demand. The provisioner also abstracts the use of different storage technologies and solutions in the background and makes Cloud Pak for Data portable. For example, an nfs-client storage class could point to an IBM Spectrum Scale or Dell/EMC-powered NFS server, while the ibmc-file-gold-gid storage class may point to storage in the IBM Cloud.
Hence, as part of the installation of Cloud Pak for Data, the user would provide storage classes as configuration parameters.
The Cloud Pak for Data control plane introduces a special persistent volume claim called user-home-pvc. This is a shared, Read-Write-Many (accessMode: RWX) volume that is mounted by several Pod replicas to access the same content. This volume stores some configuration information, static user experience content, and some user-introduced customizations.
In a typical Cloud Pak for Data installation, you can inspect your PVC as follows:
kubectl get pvc user-home-pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
user-home-pvc Bound pvc-44e5a492-9921-41e1-bc42-b96a9a4dd3dc 10Gi RWX nfs-client 33d
Looking at one of the deployments (such as zen-core), you will notice how the Deployment indicates where the volume should be mounted:
kubectl get deployment zen-core -o yaml
:
- name: user-home-mount
persistentVolumeClaim:
claimName: user-home-pvc
:
volumeMounts:
- mountPath: /user-home
name: user-home-mount
In this example, you will notice that user-home-pvc gets mounted as /user-home in the zen-core Pods.
Cloud Pak for Data also uses StatefulSets, where each member replica is typically associated with its own dedicated (non-shared) persistent volume. Here's an example:
kubectl get statefulsets
This identifies a couple of StatefulSets present in the Cloud Pak for Data control plane:
NAME READY AGE
dsx-influxdb 1/1 33d
zen-metastoredb 3/3 33d
Each StatefulSet spawns one or more member Pods:
kubectl get pods -lcomponent=zen-metastoredb
The preceding snippet shows the members associated with that metastoredb StatefulSet. In this case, there are three of them and they are numbered ordinally:
NAME READY STATUS RESTARTS AGE
zen-metastoredb-0 1/1 Running 11 12d
zen-metastoredb-1 1/1 Running 11 12d
zen-metastoredb-2 1/1 Running 10 12d
Each StatefulSet member is typically associated with at least one persistent volume that serves to store data associated with that Pod. For example, each zen-metastoredb member is associated with a datadir volume where it stores its data. (The zen-metastoredb component is a SQL repository database that replicates data and responds to queries by load balancing three different members):
kubectl get pvc -lcomponent=zen-metastoredb
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
datadir-zen-metastoredb-0 Bound pvc-66bbec45-50e6-4941-bbb4-63bbeb597403 10Gi RWO nfs-client 33d
datadir-zen-metastoredb-1 Bound pvc-f0b31734-7efe-40f4-a1c1-24b2608094da 10Gi RWO nfs-client 33d
datadir-zen-metastoredb-2 Bound pvc-83fdb83e-8d2b-46ee-b551-43acac9f0d6e 10Gi RWO nfs-client 33d
In Chapter 11, Storage we will go into more detail on how storage is provided to application workloads in Kubernetes, as well as considering performance and reliability considerations.
Networking
Cloud Pak for Data leverages the concept of Kubernetes services [14] to expose these containerized microservices. A Kubernetes service (svc) exposes an internal hostname and one or more ports that represent an endpoint. A request to such a service will be routed to one or more Pod replicas in a load-balanced manner. Cloud Pak for Data services interact with each other by using the cluster-internal network enabled by Kubernetes and by using the name of the Kubernetes service. DNS enables Kubernetes services to be looked up by hostname and provides the fundamentals for service discovery. Take the following code snippet, for example:
kubectl describe svc zen-core-api-svc
This provides information relating to one microservice in Cloud Pak for Data's control plane. This svc (Kubernetes service) points to Pods identified by a specific set of Selector labels, for example:
Selector: app.kubernetes.io/component=zen-core-api,app.kubernetes.io/instance=0020-core,app.kubernetes.io/managed-by=0020-zen-base,app.kubernetes.io/name=0020-zen-base,app=0020-zen-base,component=zen-core-api,release=0020-core
svc also identifies which port is exposed and the protocol used, such as the following:
Port: zencoreapi-tls 4444/TCP
TargetPort: 4444/TCP
Endpoints: 10.254.16.52:4444,10.254.20.23:4444
Endpoints indicate the Pod IPs and 4444 ports that the requests are routed to.
If you look at the list of zen-core-api Pods, you will notice that the IPs are assigned to those specific Pods:
kubectl get pods -lcomponent=zen-core-api -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
zen-core-api-8cb44b776-2lv6q 1/1 Running 7 12d 10.254.20.23 worker1.zen-dev-01.cp.fyre.ibm.com <none> <none>
zen-core-api-8cb44b776-vxxlh 1/1 Running 10 12d 10.254.16.52 worker0.zen-dev-01.cp.fyre.ibm.com <none> <none>
Hence, in the case of a request to the kube-svc hostname zen-core-api-svc, port 4444 will be routed to one of these Pods automatically by Kubernetes. All other components within the same cluster would only use this kube-svc hostname to invoke its endpoints and are thus abstracted from the nature of the zen-core-api Pods, where exactly they run, or even how many replicas of these Pods may exist at the same time.
The Cloud Pak for Data control plane also runs a special service called ibm-nginx-svc that routes to ibm-nginx Pods. These Pods are delivered via a Deployment called ibm-nginx. This component, powered by nginx, is also known as the "front door" since it serves as the primary access point to Cloud Pak for Data services in general. Apart from any initial authentication checks, the ibm-nginx Pods also enable a reverse proxy to other microservices (identified by their kube-svc hostname) and serve the user experience.
OpenShift supports multiple ways [16] of accessing services from outside the cluster. Cloud Pak for Data exposes just one OpenShift route [17], called cpd, to invoke the user experience from a web browser and for invoking APIs from other clients:
kubectl get route cpd
NAME HOST/PORT PATH SERVICES PORT TERMINATION WILDCARD
cpd cpd-cpd-122.apps.zen-dev-01.cp.fyre.ibm.com ibm-nginx-svc ibm-nginx-https-port passthrough/Redirect None
This route represents the external access to Cloud Pak for Data and the "host" is a DNS resolvable hostname. In the preceding example, zen-dev-01.cp.fyre.ibm.com is the hostname of the OpenShift cluster itself. When a client from outside the cluster, such as a web browser, accesses this hostname, OpenShift routes it to the ibm-nginx-svc Kubernetes service, which is load-balanced across how many ibm-nginx Pods may currently be running.
OpenShift routes can also be secured using TLS [18] in general. Cloud Pak for Data also provides a way to associate custom certificates with its Kubernetes service [19].
Foundational services and the control plane
IBM has a broad portfolio of products that are now available as Cloud Paks on OpenShift Container Platform. With every such product, there is a common need to operate in different data centers, both on-premises and in the cloud, and the requirement to integrate with existing enterprise systems. To that end, a set of shared services has been developed called the Cloud Pak foundational services (CPFS).
Cloud Pak foundational services
CPFS is also known as "Bedrock." It provides key services that run on top of OpenShift Container Platform to power all Cloud Paks, including Cloud Pak for Data, and serves as a layer to support integration between all Paks.
These capabilities enabled by the CPFS services include the following:
- Certificate Management Service: This service enables Cloud Paks to generate TLS certificates, manifest them as Kubernetes secrets, and be mounted in Pods that need them. This helps in securing inter-microservice communications and promotes easier automatic rotation of certificates.
- Identity and Access Management (IAM) service: IAM enables authentication for the Cloud Pak. It provides mechanisms for admins to configure one or more identity providers (such as LDAP/AD) to help integrate with existing systems in the enterprise. IAM exposes the OpenID Connect (OIDC) standard that also makes it possible for users to single sign-on between multiple Pak installations.
- License and metering service: This service captures utilization metrics for individual services in the cluster. Each Cloud Pak Pod is instrumented with details that identify it uniquely. The license service collects the Virtual Processor Core (VPC) resources associated with each Pod and aggregates them at a product level. It also provides reports for license audit and compliance purposes.
- Operand Deployment Lifecycle Manager (ODLM): The operator pattern is used by all Cloud Paks to deliver and manage services on OpenShift Kubernetes. Kubernetes resources, such as Deployments and StatefulSets that are orchestrated and managed by an operator, are collectively referred to as the Operand controlled by that operator. ODLM [21] is an operator, developed as an open source project, that is used to manage the life cycle of such operands, in a similar way to how OLM manages operators. With higher-level constructs such as OperandRequests, ODLM can provide abstractions and simpler patterns for Paks to manage operands and even define inter-dependencies between them.
- Namespace Scoping and Projection of privileges: Operators are granted significant Role-Based Access Control (RBAC) privileges to perform their functions. They connect to the Kubernetes API server and invoke functions that allow it to deploy and manage Kubernetes resources in the cluster. It is very common for OpenShift clusters to be shared among multiple tenants and multiple vendors. Hence, from a security perspective, it becomes imperative to be able to control the breadth of access that both operators and operands are granted.
Frequently, operands are assigned to specific tenant namespaces and are expected to only operate within that namespace. Operators, however, are installed in a central namespace and need to have authority in these individual tenant namespaces. At the same time, it is desirable not to grant cluster-wide authority to operators and to limit their influence only to those namespaces.
IBM introduced the namespace scope operator [22], in open source, to help address this need. This operator can project the authority of operators (and operands if needed) to other namespaces selectively. It also provides the ability to automatically change the configurations of these operators to have them watch additional namespaces and only those namespaces, thereby improving the security posture of the Paks in shared clusters.
- Zen – the platform experience: Zen is a framework developed specifically to enable the extensibility and adoption of a plug-n-play paradigm for both the end user experience and for backend service APIs. It is a set of foundational capabilities and UI components that are leveraged by higher-level services in Cloud Paks. It ensures a focus on a single pane of glass for persona-driven and customizable (even re-brandable) user experiences. It fosters collaborations between personas and across product boundaries and, with the plug-n-play model, capabilities are dynamically enabled as and when services are provisioned.
- The cloudctl utility: This command-line interface (CLI) provides functions to deploy and manage Cloud Paks on OpenShift Container Platform. cloudctl helps with mirroring Cloud Pak images into an Enterprise Private Container Registry, even into air-gapped environments. Services in Cloud Paks are packaged and made available in the Container Application Software for Enterprises (CASE) format, a specification defined in open source [23]. The utility enables important automation for installing and upgrading services in a Pak, including creating OLM artifacts such as catalog sources and operator subscriptions.
In this section, we introduced the functionality that the Cloud Pak foundational services deliver, forming the "Bedrock" that is leveraged by all IBM Cloud Paks. In the next section, we will explore one such consumer of Bedrock – the Control Plane layer that powers Cloud Pak for Data services.
Cloud Pak for Data control plane
The control plane is an instantiation of the Zen framework in Cloud Pak for Data instance namespaces. It is a set of deployments that form the operand managed by the Zen operator. This Zen control plane is introduced and customized by the Cloud Pak for Data platform operator [5].
The following screenshot provides an architectural overview of the different Kubernetes resources. It depicts the various microservices, repositories, storage volumes, and other components that make up the control plane. It also shows service-to-service interactions, including with Cloud Pak foundational services and operators, as well as how web browsers and command-line utilities interact with that installation of Cloud Pak for Data:
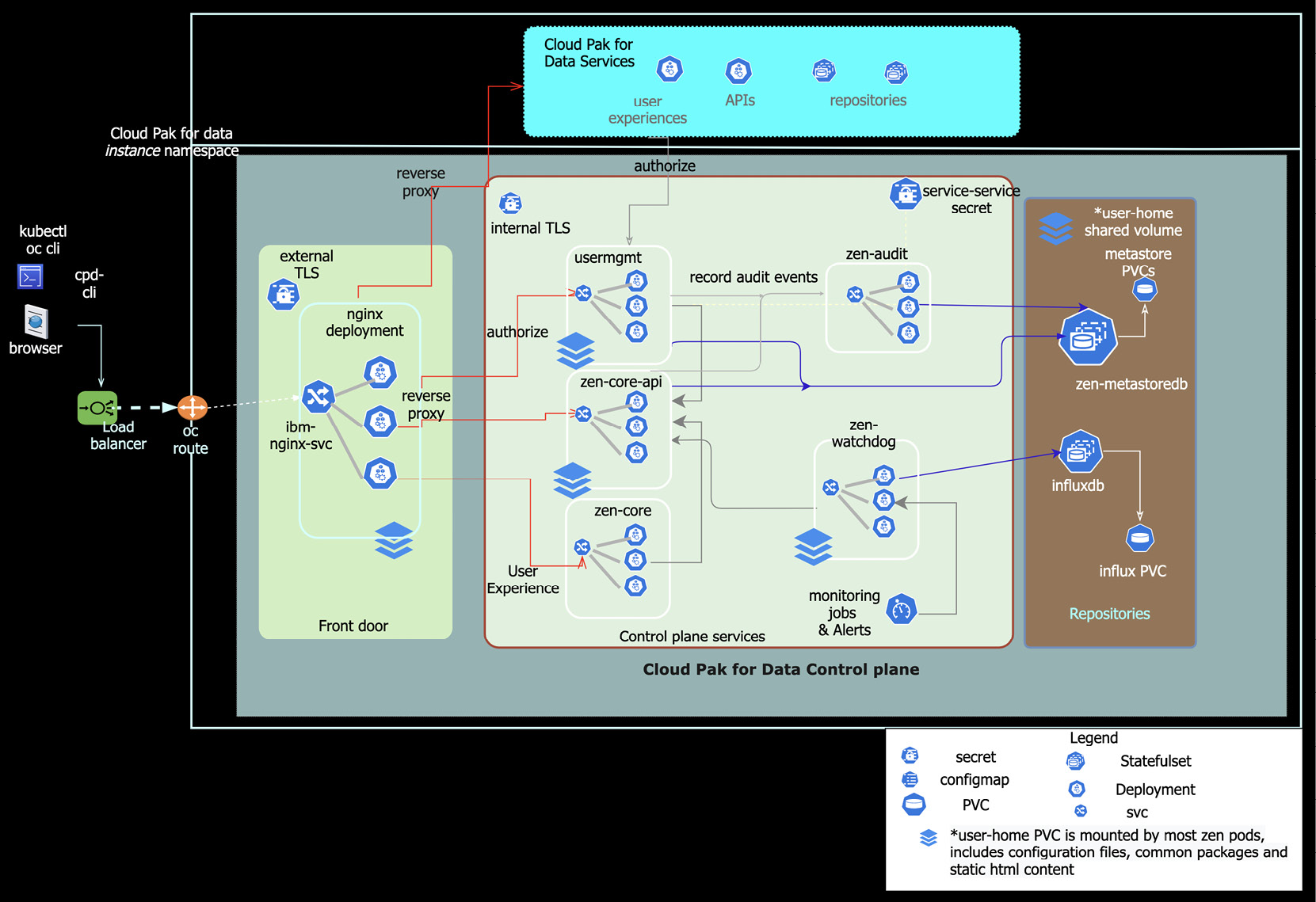
Figure 9.3 – Control Plane components and interactions
The control plane is powered by an extension registry, which is an API (delivered by the zen-core-api microservice) and a repository (zen-metastoredb) that enables a dynamic plug-n-play of services and other components. The control plane's zen-core-api microservice hosts key services and APIs, to enable service discovery and enforce authorizations, and helps present a dynamic, integrated experience to the end user.
As described earlier, the ibm-nginx microservice serves as the "front door" access point for both the user experience and API invocations. In the preceding screenshot, you will notice that the operators located in the Cloud Pak foundational services namespace manage the "operands" in the Cloud Pak for Data instance namespace.
As coarsely outlined in the preceding figure, all the Cloud Pak for Data services are deployed on top of the control plane, and they leverage the control plane APIs as well as get accessed via the same front door. These higher-order services themselves are managed by their own operators, include their own microservices, repositories, and user experiences over and above what the control plane itself hosts. These service experiences dynamically extend the Cloud Pak for Data experience in a plug-n-play fashion to present a single pane of glass for end users.
The control plane provides the following capabilities for consumers of the Cloud Pak for Data platform:
- Authorization: Cloud Pak for Data provides an access control capability (the usermgmt microservice) that enables an authorized user (an administrator) to grant access to other users. User groups, which can also be mapped to LDAP groups, can be defined to support collaboration. Users and groups can be granted role-based authorization to work with specific services or projects. The chapter on security describes user access management in greater detail.
- A persona-based experience: Cloud Pak for Data provides a browser-based integrated end user experience that is personalized appropriately for the user's role. Navigation and their home page content are automatically scoped to the access rights that have been granted. Users can choose to customize their experience as well, say with the home page content. This is delivered primarily by the "zen-core" micro-service.
- A service catalog: The service catalog encourages a self-service option for authorized users to provision instances of services in the Cloud Pak for Data platform without needing to have any sophisticated knowledge about the underlying Kubernetes infrastructure. For example, a user could choose to provision a Db2 database and grant access to others to work with that database instance. Cloud Pak for Data also includes mechanisms for users to generate API keys for service instances to programmatically interact from client applications. The catalog is powered by the zen-core-api microservice and the experience is hosted by the zen-core microservice. zen-core-api also provides the mechanism to manage access to each provisioned service instance, while supporting the ability to upgrade these instances as needed.
- Auditing: The control plane includes a zen-audit service that is used to control and abstract how auditing-related events are to be delivered to a collector in the enterprise. Microservices, whether in the control plane itself or those from Cloud Pak for Data services, emit audit events for privileged actions to this central audit service. The audit service also can also grab audit records that have been placed in special log files by individual microservices. The chapter on security describes how auditing for compliance can be supported across the whole stack, beyond just the Cloud Pak for Data platform layers.
- Monitoring: The Cloud Pak for Data control plane includes a service called the "zen-watchdog" that provides the basic capability to monitor the control plane itself and all the Cloud Pak for Data services on top of it. The next section describes this in more detail.
- The cpd-cli utility: This utility is a command-line program [24] that provides key capabilities (introduced as plugins) to manage the control plane and leverage capabilities from a client system. For example, an administrator could leverage this program to bulk authorize users for access or to gather diagnostics, or simply to work with service instances that this user has access to. The backup-restore plugin enables cpd-cli to support additional use cases.
Note
With Cloud Pak for Data v3 and v3.5, this utility was used to support Cloud Pak for Data service installs, patches, and upgrades as well. However, with the use of operators, these functions are now driven by the service operators and by specialist fields in the appropriate custom resources.
Management and monitoring
Cloud Pak for Data provides APIs and a user experience for administrators to manage the installation of Cloud Pak for Data.
Note
This does not require that these users are granted Kubernetes access either, only appropriate admin roles/permissions in Cloud Pak for Data. Such users are also referred to as Cloud Pak for Data platform administrators and would only have authority within that single instance of Cloud Pak for Data.
User access management, monitoring, configuration, and customizations, as well as the provisioning of services or storage volumes, are some of the typical administration functions in Cloud Pak for Data. In this section, we will look at some of these. Other chapters (such as Security for User Access Management) will dive deeper into some of these aspects.
Monitoring
The Cloud Pak for Data control plane provides APIs and user experiences for authorized end users to be able to monitor and control workloads in that installation.
The zen-watchdog service leverages labels and annotations [25] in different Pods to identify the service they are associated with and presents a user experience for administrators. The zen-watchdog service also periodically spins off Kubernetes Jobs to capture metrics associated with these individual Pods, aggregates them, and stores them in the influxdb time series databases.
The following screenshot shows the Monitoring page, which provides an at-a-glance view of the state of that installation:

Figure 9.4 – Monitoring overview
This page also reveals any events that need attention and summarizes recent resource consumption. Users can drill down to see what services have been deployed and their overall resource consumption, as shown in the following screenshot:

Figure 9.5 – Status and resource consumption by service
The preceding screenshot shows a user experience that helps users see a breakdown by service. It presents a view of the overall status of that service and resource utilization metrics. Users can then drill down further to get advanced details about one specific service.
The following screenshot, as an example, shows the specific Pods associated with the Watson Knowledge Catalog Service. A similar experience exists to show all Pods from all services as well, with the ability to sort and filter to quickly identify Pods that need attention:

Figure 9.6 – Pod details and actions
From this user experience, as shown in the preceding screenshot, the administrator can then look at each Pod, get more details, or access logs for troubleshooting. They could even choose to restart a Pod if they see it malfunctioning.
Note that this interface is meant to complement what is available in the OpenShift console for monitoring and management, and only presents a view that is very much in Cloud Pak for Data's usage context and only scoped to that Cloud Pak for Data installation.
Alerting
Kubernetes provides the concept of liveness probes and other primitives for it to recognize failing Pods and trigger automatic restarts. However, with complicated services, it may not be that simple to recognize failures that span multiple deployments or StatefulSets, nor would it be able to recognize any application-level semantics. To complement OpenShift's capabilities, Cloud Pak for Data introduces additional monitors, mechanisms to persistent events, and surface issues in the user experience.
The control plane includes a framework [27], powered by zen-watchdog, to monitor for events, recognize serious situations, and raise those problems as alerts. These alert messages are frequently sent as SNMP traps to configured Enterprise SNMP receivers.
The following diagram provides a high-level view of how the zen-watchdog service enables monitoring, the aggregation of events, and the raising of alerts:
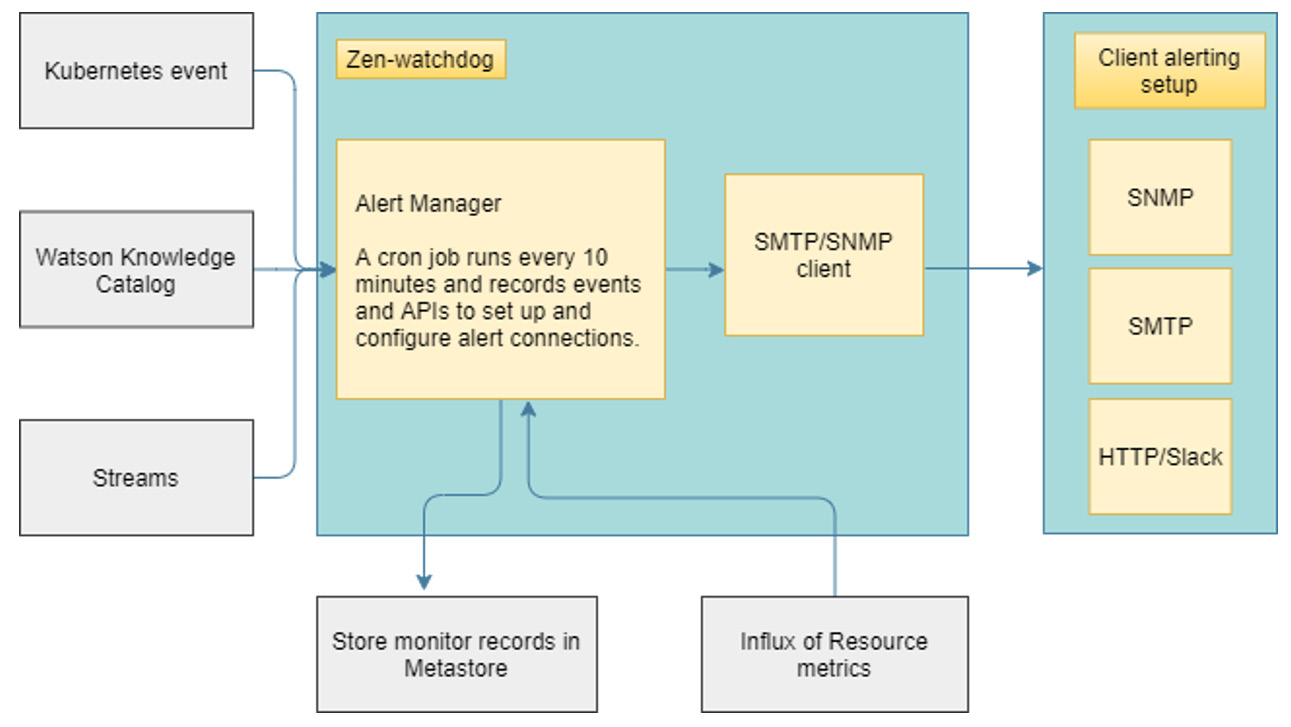
Figure 9.7 – Monitoring events and alert forwarding
Different targets can be configured to send alerts to, including via the SNMP protocol, or simply as SMTP emails as well as via HTTP.
Cloud Pak for Data's control plane itself includes a few generic out-of-the-box monitors, such as the following:
- check-pvc-status: Records a critical event if a PVC is unbound
- check-replica-status: Records a critical event if a StatefulSet or Deployment has unavailable replicas
- check-resource-status: Records a warning event if a service has reached the threshold and a critical event if it has exceeded the quota
Developers can introduce extensions to support custom monitoring needs as well. The documentation [28], using sample code, describes the procedure of introducing a custom container image to provide specialized monitoring functions and identify critical problems that merit an alert.
Provisioning and managing service instances
Many services in Cloud Pak for Data support the concept of "service instances," provisioned from the service catalog. These are individual copies of services that can be scaled out and configured independently, or often used to provide access to a selected group of users.
A service instance has the following characteristics:
- It represents Kubernetes workloads that are metered individually – usually provisioned in the same namespace as the control plane – but some services can also be provisioned in a "data plane" sidecar namespace that is tethered (from a management perspective) to the control plane namespace.
- It is provisioned by authorized end users with Create service instances permission via a provisioning experience and API:
End users provision instances without needing to have Kubernetes access or an in-depth understanding of Kubernetes primitives.
- It supports RBAC, in other words, users can be granted granular roles to access that resource.
- It enables secure programmatic client access, with instance-scoped API keys and service tokens.
For example, an authorized user may want to spin up an instance of a database for us by their team privately. Other users would not even be made aware that these instances even exist.
The following screenshot shows a sample provisioning experience to deploy a Db2 warehouse database instance.
The user is guided on setting up the instance, including assigning compute and storage appropriately:

Figure 9.8 – Example of a provisioning experience
After choosing the appropriate attributes for provisioning that instance, for example, as shown in the preceding screenshot, the user then triggers the creation of the instance. The creator of such an instance is then designated as the first administrator of that instance.
With the creation of such an instance (or generally whenever any specific operations are performed on that instance), audit records are automatically generated by the control plane.
Cloud Pak for Data platform administrators, apart from the creator of the instance, can also manage and monitor these instances. However, even platform administrators may be denied access to consume the instance in the first place. For example, while the Cloud Pak for Data platform administrator can perform maintenance tasks, or even de-provision that database instance, they may not have access to the data inside. This is critical from a regulatory compliance perspective to enable such separation of duties.
The following screenshot shows an example of how an authorized user (the admin of that instance or the Cloud Pak for Data platform administrator) can manage access rights. They can assign roles (including that of an admin) to other users and groups:

Figure 9.9 – Instance access management
It is also common for the platform administrator to retain the Create Service instance permission. These would be the only authorized users to provision such instances. However, once the instances have been provisioned, they can then grant the admin role on that instance to other users or groups of users, essentially delegating the day-to-day management of that instance. Newly added instance admins could then remove access from platform administrators (creators) to ensure compliance. The platform administrators can still rely on the monitoring interfaces to watch over such instances or diagnose and correct problems.
The cpd-cli service-instance command can also be used to manage such instances from the command line.
Storage volumes
The chapter on storage describes some of the fundamentals behind how persistence is enabled in Kubernetes and how Cloud Pak for Data leverages those. In this section, we will focus on a capability called storage volumes, a mechanism by which administrators enable end users to access shareable storage for the implementation of their use cases on the platform.
Authorized users, typically Cloud Pak for Data administrators, can provision additional persistent volumes or make available remote volumes for consumption by users in the platform [32]. This is usually for sharing data or any source code packages between different project teams and across different Kubernetes containers.
For example, a storage volume could be provisioned afresh in the cluster and end users, or groups of users could be granted access to that storage volume. These users can then access them inside projects, for example, inside multiple Jupyter or RStudio environment Pods, or for executing a Spark Job or generally via APIs [33].
The Cloud Pak for Data administrator can provision and manage such volumes via the user experience, as shown in the following screenshot:

Figure 9.10 – Managing storage volumes
The Storage volumes page enables users to view all the volumes they have access to as well as browse through the files in those volumes. The experience also supports rudimentary file uploads and downloads as well from these volumes.
Volumes are resources, too, and since they are likely to contain important data, the Cloud Pak for Data control plane provides mechanisms for the "owner" of the volume to grant access to other users and groups, as shown in the following screenshot:
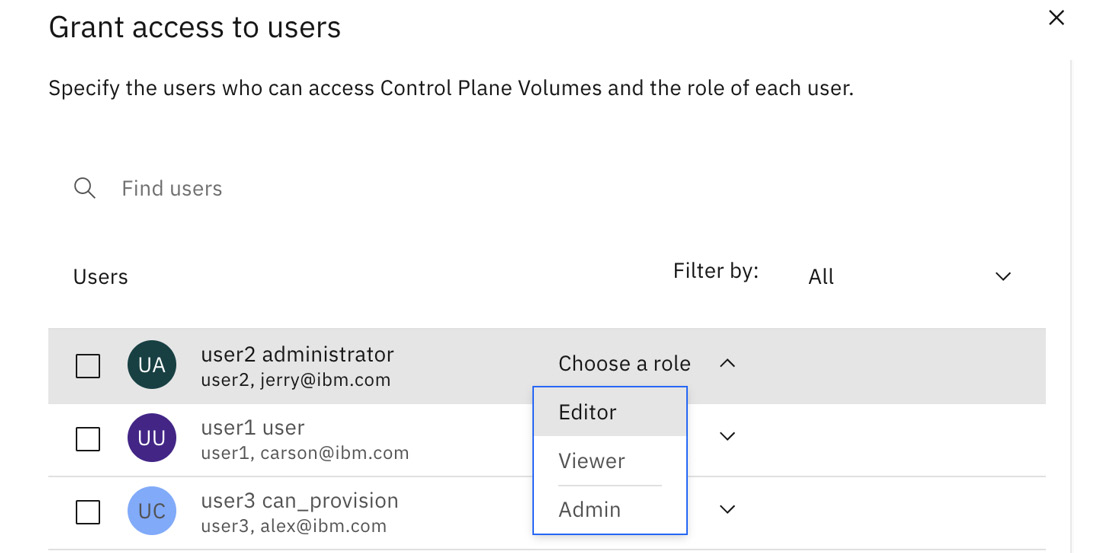
Figure 9.11 – Controlling access to a storage volume
Users may even be granted "admin" rights to an individual volume, allowing them full authority to the volume, including managing access and de-provisioning the volume. Others may be allowed write access, and others still just read access.
Cloud Pak for Data supports different ways of providing such shareable storage volumes, as shown in the following screenshot:
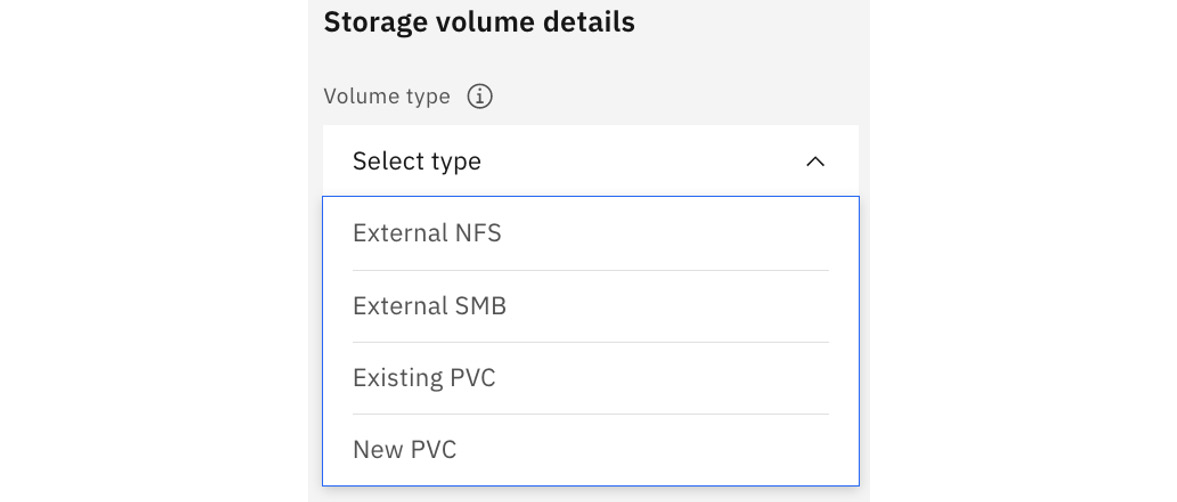
Figure 9.12 – Types of storage volumes
An administrator could decide to create a fresh volume using an existing Kubernetes storage class (RWX access mode) or point to an existing persistent volume or mount remote volumes using either the NFS or SMB protocols.
As an example, the following screenshot shows an administrator creating a fresh persistent volume using the cephfs storage class and identifying the expected mount point for that volume:
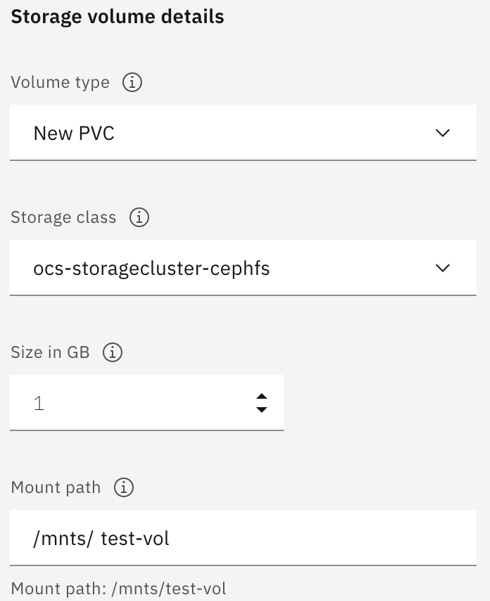
Figure 9.13 – Creation of a new storage volume
Note that the storage class must support the Read-Write-Many (RWX) access mode since these volumes are expected to be mounted by multiple Pods concurrently.
The following screenshot illustrates how a remote volume can be made available to users in a similar fashion:
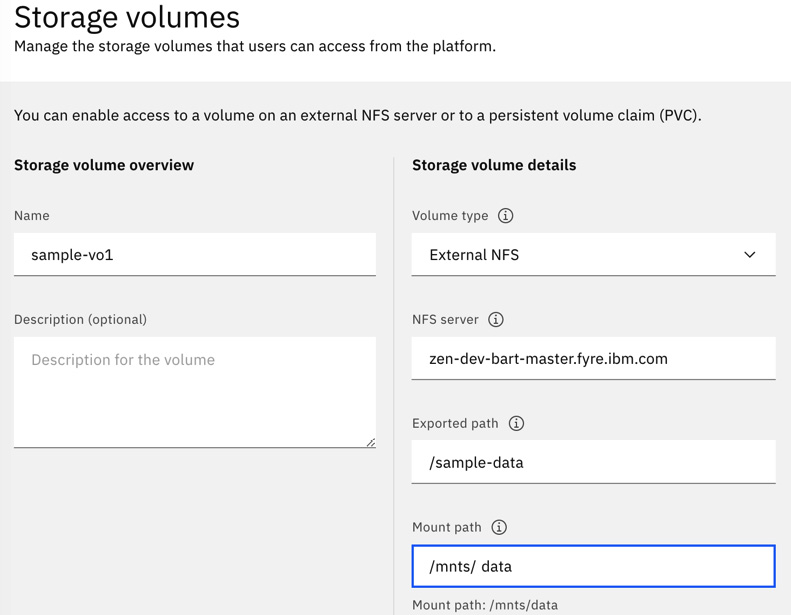
Figure 9.14 – Accessing a remote volume
This enables enterprises to use existing data volumes inside Cloud Pak for Data without the need to physically transfer them into the cluster. Similarly, the SMB protocol is also supported to mount remote SMB (CIFS) volumes, similar to how Microsoft Windows machines mount such shared volumes.
Multi-tenancy, resource management, and security
OpenShift clusters are considered shared environments in many mature enterprises. They expect to expand such clusters when needed to accommodate more workloads and re-balance available resources. It is far more cost-effective to share the same OpenShift cluster and consolidate management and operations rather than assign a separate cluster to each tenant. Since such clusters include different types of workloads from different vendors, and applications that require sophisticated access management and security practices, a focus on tenancy is important from the start.
The concept of tenancy itself is very subjective. In some situations, dev-test and production installations may be considered different tenants in the same cluster. In other cases, different departments, or different project use cases, may be treated as individual tenants. When this concept is extended to ISVs operating a cluster on behalf of their clients, each of those clients is likely to be different companies and there could be stricter requirements on tenancy compared with a case where all users are from the same company.
The chapter on multi-tenancy covers the tenancy approach and best practice recommendations with Cloud Pak for Data in greater detail. In this section, we will look at a high-level overview of tenancy requirements and how Cloud Pak for Data is deployed and managed in such shared Kubernetes clusters.
Let's first start with some key criteria that influence tenancy approaches:
- Isolation of tenants: There is a need to ensure that different tenants are fully unaware of each other on such shared systems. This could include the need to use completely different authentication mechanisms. Different LDAP groups or even different LDAP servers may be desired for different tenants.
Protecting resources via access authorizations and policies is absolutely necessary in general, but with multiple tenant users present, these assume an even more prominent role.
Isolation also extends to network isolations, even to the point of having completely different user experience and API hostname URLs and DNS domain names for each tenant, even if they physically share the same Kubernetes cluster.
Storage systems, consumed in the form of Kubernetes persistent volumes, also need to ensure that tenants do not have access to each other's volumes.
- Security: Note, however, that for cost reasons, some enterprises may end up permitting a lot more sharing between tenants. So, while isolation requirements provide some amount of separation between tenants, there are also specific security and regulatory compliance requirements that play a fundamental role in the Deployment topology. Authentication and authorization access management help to a great extent, but may not be sufficient.
For example, since OpenShift Kubernetes itself is shared, it would be unwise to grant access to any tenant to that operating environment. This also means that there needs to be an operations team or IT department solely tasked with managing the OpenShift cluster, including the security of the host nodes themselves, as well as the onboarding of tenants.
As with traditional, non-containerized applications, there could also be a need for network security. For example, two tenants could need to be firewalled off from each other or strict policies set to ensure that no breach occurs.
Security requirements could extend to even needing different encryption keys for storage volumes for different tenants.
From a regulatory compliance perspective, different tenants may have different requirements. There may not be any need to have auditing for dev-test or ephemeral tenants, but more thoroughness may be required for production tenants. Some tenants, because of the nature of their work with sensitive data, may require a lot more security hardening and audit practices than others. Hence, there is a need for the tenancy approach to support such diverse configuration requirements as well.
- Resource management: With a shared cluster offering a pool of compute, it is also imperative that the cluster is shared equitably. IT operation teams may need to support specific Service Level Agreements (SLAs) for individual tenants.
Hence, the tenancy mechanism must support controls where resource utilization is monitored, noisy neighbors are prevented or at least throttled, and importantly, compute usage limits can be enforced. In some organizations, chargebacks to tenants could also rely on the ability to measure compute utilization and/or set quotas.
- Supporting self-service management: It becomes operationally expensive for enterprises to have dedicated support for each tenant user. It is desirable to have each tenant self-serve themselves, even for provisioning services or scaling them out, or performing backups or upgrades on their own.
It is also usually the case for a tenant admin to decide on matters of access management (and compute resource quotas) on their own, without needing IT support.
It is preferable for monitoring and diagnostics or other maintenance tasks to be delegated to the tenant admins as well.
Approaches to tenancy should thus be able to support granting some level of management privileges to designated "tenant administrators" within their scope.
In this section, we looked at some common requirements that are placed on multi-tenancy approaches. The next section will introduce how the Cloud Pak for Data technology stack helps address these aspects of tenancy.
Isolation using namespaces
While it may be simpler to use different Kubernetes clusters or even dedicated host nodes for each tenant, it will not be cost-effective. Luckily, Kubernetes includes the concept of a namespace [34] that represents a virtual cluster to help sandbox different tenant workloads. OpenShift Container Platform extends namespaces with the concept of a project [35].
The most common approach is to have different installations of Cloud Pak for Data in different tenant instance namespaces. Each tenant is then assigned one such installation and works in relative privacy and isolation from one another. Cloud Pak for Data installations in each tenant namespace use their own OpenShift router, which allows for the customization per tenant of this access point, including external hostnames and URLs, as well as the ability to introduce different TLS certificates for each tenant.
Since persistent volume claims and network policies can be scoped to namespaces as well, isolation from storage and network access can also be guaranteed. Should a tenant user need access to Kubernetes (for example, to install or upgrade their services), that could be scoped to their namespace, too, with Kubernetes RBAC. OpenShift projects could also be mapped to dedicated nodes and this can provide for more physical separation, at an increased cost, to isolate Pods from various tenants from one another.
The chapter on multi-tenancy describes the various options of using namespaces to achieve isolation as well as options where two tenants may want to even share the same namespace.
Resource management and quotas
Cloud Pak for Data supports a wide variety of use cases and different types of users concurrently using an installation. Once a service is deployed, there would be some fixed set of Pods that provide APIs, repositories, and user experiences, as well as some supporting management aspects specific to that service. These are considered static workloads that are always running. When end users interact with these services, there typically would be dynamic workloads. Some of these may be long-running, such as a user-provisioned database instance, and others may simply be short-term workloads such as data science interactive environments, Spark jobs, and machine learning training jobs. If there are more users concurrently launching analytics environments or, say, initiating expensive model training simultaneously, they may end up competing for resources or starving other essential jobs.
All Pods in Cloud Pak for Data are labeled and annotated to identify the product it belongs to [25]. Pods also specify resource requests and limits needed [29] for operating in the Kubernetes environment. The request CPU and memory settings help Kubernetes pick a suitable worker node to schedule the Pod in, reserve the requested compute for that Pod, and use the limit settings to set an upper limit. Pods would thus be able to "burst" to the upper limit for a short duration and be able to support a sudden spike in workloads. This avoids the need to plan for the worst case and reserve more compute than typically needed, while allowing emergency, temporary growth, but only if additional resources are available in that worker node at that instant.
Resource management is a critical aspect to consider when working with such dynamic workloads and concurrent user activity. While the architecture elegantly supports elasticity and more compute resources can be added when needed, it is more practical and cost-effective to fully consume existing resources to the maximum extent before scaling out. An administrator would thus need to ensure that there is a fair and balanced use of resources and can transfer resources to workloads that urgently need it.
Kubernetes supports the concept of a ResourceQuota specification that can be used by cluster administrators to control compute allocations across all namespaces. In addition to this, the control plane includes the ability for a Cloud Pak for Data tenant administrator, without needing Kubernetes privileges, to define compute resource thresholds per service (product) in their installation. While this is still subject to the overall namespace ResourceQuota set by the Kubernetes cluster admin, it allows some flexibility to the Cloud Pak for Data administrator to self-manage the resources that have been granted.
The following screenshot illustrates how such a tenant administrator can set boundaries on both CPU and memory for the Watson Knowledge Catalog Service within that Cloud Pak for Data instance namespace:

Figure 9.15 – Resource quota definition
Any violations on the thresholds are highlighted in the monitoring user experience as well as raised as alerts, if configured.
Beyond just reporting on threshold breaches, Cloud Pak for Data includes an optional scheduling service [26] that can be used to enforce assigned resource quotas. The scheduling service is configured based on the choices made by the administrator per service.
The scheduling service extends the default Kubernetes scheduler, and monitors all start up requests for Pods and Jobs. It uses the same labels that zen-watchdog also uses to identify the Pods and the service/products that the Pod belongs to. It then aggregates resource requests and limits across all Pods that are currently running for that service and decides whether to permit the startup. A Pod that would violate the defined resource quota threshold is prevented from even being started.
Enabling tenant self-management
The approach of using different namespaces for each tenant also elegantly solves the problem of self-management with Cloud Pak for Data.
Each Cloud Pak for Data installation, in its own namespace, can be independently configured and assigned to be administered by a tenant user. That tenant administrator has access to all the monitoring and alerting capabilities, in addition to resource management as described in the previous sections.
Each such tenant instance can have different Cloud Pak for Data services and versions deployed completely independently from other tenants. This also enables each tenant administrator to make a decision regarding upgrading and patching, too, on their own terms.
Day 2 operations
Administrators of Cloud Pak for Data installations, including tenant administrators, can leverage utilities and best practices when it comes to the management of the Cloud Pak for Data platforms and services.
This section describes some of the operational considerations beyond just the initial installation, daily management activities, and monitoring.
Upgrades
With the adoption of the operator pattern, Cloud Pak for Data makes it possible for even individual tenant user to decide on their own an upgrade strategy that works for them. In certain cases, Cloud Pak for Data instances may be upgraded more frequently, even to the latest major release versions, such as with dev-test installations, whereas in other instances, such as production installations, there is frequently a need to stick to stable releases and only incremental changes (patches) may be tolerated.
In general, there are two distinct sets of components that you would need to consider from an upgrade perspective – the operators in the central namespace, and the individual operand service deployments in (tenant) Cloud Pak for Data instance namespaces. The typical procedure involves upgrading all the operators to the latest released version (or just the operators of immediate interest) and then deciding which operands to upgrade. The operator pattern enables both a fully automated upgrade and selected manual upgrades or even a mix as appropriate for different tenants.
With the installPlanApproval: Automatic specification in the operator subscriptions [36], operator deployments are typically set to be automatically upgraded when its catalog source is refreshed, A choice of a manual approval implies that a cluster admin manually decides when the upgrade is acceptable. Note that new versions of Cloud Pak for Data operators are expected to still tolerate currently existing installed versions of the operand deployments and support new versions at the same time. Hence, in the same cluster, a fresh installation of the new version of the service could be deployed, while another namespace continues to retain the old version, and both get managed by the same operator.
Operands can be set to be auto-upgraded as well. This would mean that when the operator is upgraded, as part of its reconcile loop, it automatically upgrades existing operands as well to the latest version supported by that operator.
The easiest approach is to configure the fully automated mechanisms and adopt the continuous delivery paradigm. With this approach, all the cluster administrator needs to do is to simply ensure that the catalog source is updated (manually if air-gapped). Operators introduced by that updated catalog service would then get automatically upgraded to the latest version and those operators would, in turn, automatically upgrade the operands they manage.
For situations where a specific version of an operand is required and upgrades need to be handled manually, a process called "pinning" can be adopted. Pinning operands to a version works even when the operator concerned has been upgraded. This is done by explicitly providing a version in the custom resource spec for that service in an instance namespace. Only when the version is manually altered would the operator trigger the upgrade of the operand deployments to the new version requested. If no version is specified, then the operator assumes that the operand deployments always need to be at the latest release level and automatically ensures that to be the case.
Scale-out
Out of the box, operand deployments of services are configured to use specific compute resources and replica settings. Most services support a T-shirt sizing configuration that provides for the scaling out and scaling up of the various Pod microservices. In many cases, scale-out is also done to improve high availability with multiple replicas for deployments and improved performance with increased load balancing.
The Cloud Pak for Data documentation [37] describes the service-specific configuration options for scaling. For the scale-out/up operation, the tenant administrator updates a scaleConfig parameter in the appropriate custom resource spec. For example, a medium scaleConfig would cause that service operator to alter (and maintain) the configuration of the operand deployments to the size represented by that scaleConfig. This could mean specific resource requests and limits per Pod [29], as well as different replica counts in Kubernetes Deployments and StatefulSets.
It is not necessary to scale out all Cloud Pak for Data services at the same time or to the same configuration within the same Cloud Pak for Data installation. You would only need to scale out based on expected workloads and the concurrency of specific use cases. You could choose to scale back down some services and release resources to scale out other services for a different set of use cases later. Different tenant installations of Cloud Pak for Data could also have a different set of services at different scale configurations.
Backup and restore
Cloud Pak for Data relies on the storage solution in that Kubernetes cluster for reliable persistence of data. Storage solutions provide for redundancy as well with block-level storage replication. Chapter 11, Storage describes the technological aspects and reliability in general.
Cloud Pak for Data includes a backup-and-restore utility [38] as part of cpd-cli that helps Kubernetes namespace administrators take point-in-time backups of data and metadata from that Cloud Pak for Data instance. This allows restoration in the same installation to restore to a previously known state as well as restoration in a different cluster as part of a disaster recovery procedure.
The common practice is to trigger a backup of data from all persistent volumes in a particular OpenShift Project/Kubernetes namespace and to persist that backup in a remote volume or an S3-compatible object store. In some cases, the selected storage solution may be limited and may not be able to guarantee consistency of the backup images since it could span many persistent volumes. In such a case, cpd-cli also provides a way to "quiesce" the services to prevent writes to the volumes, to essentially set that installation to a maintenance mode, and an "unquiesce" once the backup procedure is complete. The backup is simply a copy of all the persistent volume filesystems [39]. One disadvantage here is that the quiesce-backup-unquiesce flow may take a while, leading to that installation staying in a longer than acceptable maintenance mode. In other cases, where the storage solution has the necessary sophistication [40], Cloud Pak for Data services may put I/O in a write suspend mode for a short duration while all buffers are flushed to disk. Writes are held back while storage snapshots are taken, resulting in negligible disruption compared to a full quiesce.
Summary
Cloud Pak for Data is a platform for data and AI, built on top of a modern Kubernetes-based architecture. It leverages OpenShift Container Platform and Kubernetes to deliver a reliable, elastic, and cost-effective solution for data and AI use cases.
In this chapter, you were introduced to how Cloud Pak for Data is built, the different technology layers that form the stack that powers it, and the roles that the Cloud Pak foundational services and the control plane play. We also discussed the relevance of the operator pattern from the perspective of installation of the services and upgrades. Tenancy requirements and management of Cloud Pak for Data by individual tenant administrators, as well as approaches to resource management, were introduced. Day 2 operations were outlined as well.
In subsequent chapters, we will dive deeper into some of the key aspects introduced in this chapter, including storage, security, and multi-tenancy.
References
- What is Kubernetes?: https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
- Red Hat OpenShift Kubernetes for enterprises: https://www.openshift.com/learn/topics/kubernetes/
- Operator pattern: https://kubernetes.io/docs/concepts/extend-kubernetes/operator/
- Operators: https://operatorframework.io/what/
- Installing Cloud Pak for Data: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=installing-cloud-pak-data
- Operator life cycle manager: https://olm.operatorframework.io/
- RHEL CoreOS: https://docs.openshift.com/container-platform/4.6/architecture/architecture-rhcos.html
- CRI: Container Runtime Interface: https://github.com/kubernetes/community/blob/master/contributors/devel/sig-node/container-runtime-interface.md
- CRI-O: https://github.com/cri-o/cri-o
- Kubernetes cluster architecture: https://kubernetes.io/docs/concepts/architecture/
- Kubernetes components: https://kubernetes.io/docs/concepts/overview/components/
- Kubernetes Deployments: https://kubernetes.io/docs/concepts/workloads/controllers/deployment/
- Kubernetes StatefulSets: https://kubernetes.io/docs/concepts/workloads/controllers/statefulset/
- Kubernetes services: https://kubernetes.io/docs/concepts/services-networking/service/
- Networking: https://kubernetes.io/docs/concepts/services-networking/
- Configuring ingress: https://docs.openshift.com/container-platform/4.7/networking/configuring_ingress_cluster_traffic/overview-traffic.html
- Exposing a route: https://docs.openshift.com/container-platform/4.7/networking/configuring_ingress_cluster_traffic/configuring-ingress-cluster-traffic-ingress-controller.html#nw-exposing-service_configuring-ingress-cluster-traffic-ingress-controller
- Secured routes: https://docs.openshift.com/container-platform/4.7/networking/routes/secured-routes.html
- Using a custom TLS certificate: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=client-using-custom-tls-certificate
- Dynamic storage provisioning: https://kubernetes.io/docs/concepts/storage/dynamic-provisioning/
- Operand Deployment Lifecycle Manager: https://github.com/IBM/operand-deployment-lifecycle-manager
- Namespace scope operator: https://github.com/IBM/ibm-namespace-scope-operator
- Container Application Software for Enterprises (CASE) specification: https://github.com/IBM/case
- cpd-cli: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=administering-cpd-cli-command-reference
- Service labels and annotations: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=alerting-monitoring-objects-by-using-labels-annotations
- Cloud Pak for Data scheduler: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=service-installing-scheduling
- Alerting: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=platform-monitoring-alerting
- Custom monitors: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=alerting-custom-monitors
- Compute resources for containers in Kubernetes: https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
- Service operator subscriptions: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=tasks-creating-operator-subscriptions#preinstall-operator-subscriptions__svc-subcriptions
- Kubernetes namespace resource quotas: https://kubernetes.io/docs/tasks/administer-cluster/manage-resources/quota-memory-cpu-namespace/
- Storage volumes: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=platform-managing-storage-volumes
- Storage volumes API: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=resources-volumes-api
- Kubernetes namespaces: https://kubernetes.io/docs/concepts/overview/working-with-objects/namespaces/
- OpenShift projects: https://docs.openshift.com/container-platform/4.7/applications/projects/working-with-projects.html
- Operator subscription InstallPlans: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=tasks-creating-operator-subscriptions#preinstall-operator-subscriptions__install-plan
- Scaling services: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=cluster-scaling-services
- Backup and restore: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=cluster-backing-up-restoring-your-project
- Offline backup via filesystem copy: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=bu-backing-up-file-system-local-repository-object-store
- Backing up with a snapshot: https://www.ibm.com/docs/en/cloud-paks/cp-data/4.0?topic=up-backing-file-system-portworx