
Chapter 3: Collect – Making Data Simple and Accessible
Enterprises are struggling with the proliferation of data in terms of both volume and variety. Data modernization addresses this key challenge and involves establishing a strong foundation of data by making it simple and accessible, regardless of where that data resides. Since data that's used in AI is often very dynamic and fluid with ever-expanding sources, virtualizing how data is collected is critical for clients. Cloud Pak for Data offers a flexible approach to address these modern challenges with a mix of proprietary, open source, and third-party services.
In this chapter, we will look at the importance of data and the challenges that occur with data-centric delivery. We will also look at what data virtualization is and how it can be used to simplify data access. Toward the end of this chapter, we will be looking at how Cloud Pak for Data enables data estate modernization.
In this chapter, we're going to cover the following main topics:
- Data – the world's most valuable asset
- Challenges with data-centric delivery
- Enterprise data architecture
- Data virtualization – accessing data anywhere
- Data estate modernization using Cloud Pak for Data
Data – the world's most valuable asset
The fact is, every company in the world is a data company. As the Economist magazine rightly pointed out in 2017, data (not oil) is the world's most valuable resource and unless you are leveraging your data as a strategic differentiator, you are likely missing out.
If you look at successful companies over time, all of them had sustainable competitive advantages – either economies of scale (Apple, Intel, AWS) or network effects (Facebook, Twitter, Uber, and so on). Data is the new basis for having a sustainable competitive advantage. Over 90% of the world's data cannot be googled, which means most of the world's valuable data is private to the organizations that own it. So, what can you do to unleash the potential that's inherent to your proprietary data?
As we discussed in Chapter 1, Data Is the Fuel that Powers AI-Led Digital Transformation, CEOs and business leaders know they need to harness digital transformation to jumpstart growth, speed up time to market, and foster innovation. In order to accelerate that transformation, they need to integrate processes across organizational boundaries by leveraging enterprise data as a strategic differentiator. It's critical to remember that your data is only accessible to you.
Data-centric enterprises
Let's look at a few examples of enterprises leveraging data as a strategic differentiator:
- Best Buy successfully transformed its business by embracing digital marketing, along with personalized assistance and recommendations based on customer data. This digital transformation took multiple years, but ultimately, it helped the company survive and thrive as opposed to its competitor, Circuit City, which filed for bankruptcy and liquidated all its stores.
- Uber is the world's largest taxi company, and the irony is that it doesn't own and operate a single taxi. The secret behind Uber's success is data. Uber employs its data as a strategic differentiator, driving all its business decisions, from prices to routes to determining driver bonuses. Consider Facebook, the world's most popular media owner that creates no content of its own; Alibaba, the world's most valuable retailer that has no inventory, and Airbnb, the world's largest accommodation provider with no real estate. The reason these companies are thriving and disrupting their competition is simple: they figured out a way to leverage data to drive their business decisions in real time.
- Tik Tok's popularity and exponential growth over the past few years can be directly attributed to its recommendation engine, which leverages user data such as interactions, demographic information, and video content to drive highly accurate, personalized recommendations. Amazon and Netflix followed the same approach over the past decade to formulate personalized suggestions, which had a significant impact on their growth (and hence market capitalization).
Next, we will cover the challenges associated with data-centric delivery.
Challenges with data-centric delivery
Now that we have established that data is everywhere and that the best businesses in the world today are data-driven, let's look at what data-centric means. Enterprises are collecting data from more and increasingly diverse sources to analyze and drive their operations, with those sources perhaps numbering in the thousands or millions.
Here is an interesting fact: according to Forrester (https://go.forrester.com/blogs/hadoop-is-datas-darling-for-a-reason/), up to 73% of the data you create in your enterprise goes unused. That's a very expensive and ineffective approach.
Note to Remember
Data under management is not the same as data stored. Data under management is data that can be consumed by the enterprise through a governed and common access point. This is something that hasn't really existed until today, but it is quickly becoming the leading indicator of a company's market capitalization.
And we are just getting started. Today, enterprises have roughly 800 terabytes of data under management. In 5 years, that number will explode to 5 petabytes. If things are complicated, slow, and expensive today, think about what will happen in 5 years.
The complexity, cost, time, and risk of error in collecting, governing, storing, processing, and analyzing that data centrally is also increasing exponentially. On the same note, the databases and repositories that are the sources of all of this data are more powerful, with abundant processing and data storage capabilities of their own available.
Historically, enterprises managed data through systems of record (mainframe and client/server applications). The number of applications was limited, and data that's generated was structured for the most part – relational databases were leveraged to persist the data. However, that paradigm is not valid anymore. With the explosion of mobile phones and social networks over the past decade, the number of applications and amount of data that's generated has increased exponentially. More importantly, the data is not structured anymore – relational databases, while still relevant for legacy applications, are not built to handle unstructured data produced in real time. This led to a new crop of data stores such as MongoDB, Postgres, CouchDB, GraphDB, and more, jointly referred to as NoSQL databases. These applications are categorized as systems of engagement:

Figure 3.1 – Mobile, social, the cloud, and big data are transforming the data landscape
While the evolution of systems of engagement has led to an exponential increase in the volume, velocity, and variety of data, it has also made it equally challenging for enterprises to tap into their data, given it is now distributed across a wide number and variety of data stores within the organization:

Figure 3.2 – Different workloads require different data stores
At the same time, business users are more sophisticated these days when it comes to creating and processing their own datasets, tapping into Excel and other desktop utilities to cater for their business requirements. Data warehouses and data lakes are unable to address the breadth and depth of the data landscape, and enterprises are beginning to look for more sophisticated solutions. To add to this challenge, we are beginning to see an explosion of smart devices in the market, which is bound to further disrupt the data architecture in industries such as manufacturing, distribution, healthcare, utilities, oil, gas, and many more. Enterprises must modernize and continue to reinvent to address these changing business conditions.
Before we explore potential solutions and how Cloud Pak for Data is addressing these challenges, let's review the typical enterprise data architecture and the inherent gaps that are yet to be addressed.
Enterprise data architecture
A typical enterprise today has several data stores, systems of record, data warehouses, data lakes, and end user applications, as depicted in the following diagram:

Figure 3.3 – Evolving enterprise data landscape
Also, these data stores are typically distributed across different infrastructures – a combination of on-premises and multiple public clouds. While most of the data is structured, increasingly, we are seeing unstructured and semi-structured datasets being persisted in NoSQL databases, Hadoop, or object stores. The evolving complexity and the various integration touchpoints are beginning to overwhelm enterprises, often making it a challenge for business users to find the right datasets for their business needs. This is represented in the following architecture diagram of a typical enterprise IT, wherein the data and its associated infrastructure is distributed, growing, and interconnected:
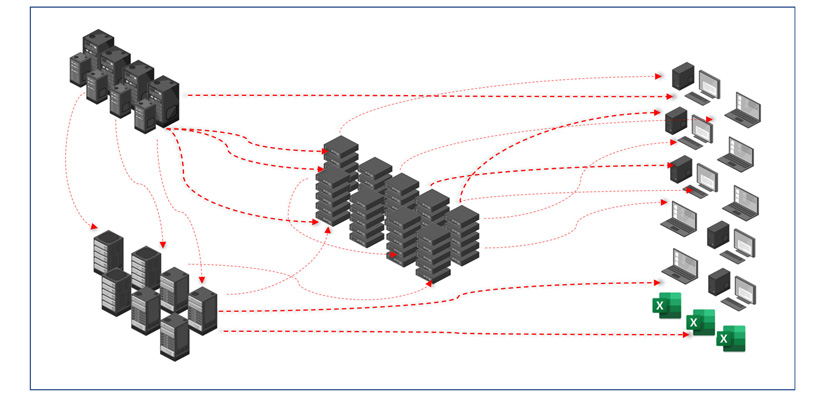
Figure 3.4 – Data-centric equates to increasing complexity
The following is a detailed list of all the popular data stores being embraced by enterprises, along with the specific requirements they address:
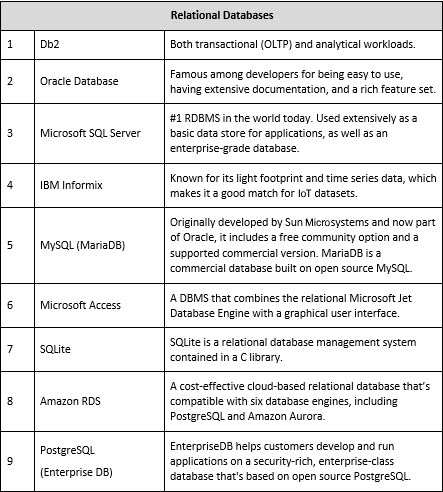
Figure 3.5 – Relational databases
The following is a detailed list of NoSQL data stores.

Figure 3.6 – NoSQL Datastores
The following is a detailed list of data warehouses and data lakes:

Figure 3.7 – Data warehouses and data lakes
Now that we have covered enterprise data architecture, let's move on to NoSQL data stores.
NoSQL data stores – key categories
NoSQL data stores can be broadly classified into four categories based on their architecture and usage. They are as follows:
- Document databases map each key with a complex data structure, called a document. Documents can be key-array pairs, key-value pairs, or even nested documents. Some of the most popular choices for document databases include MongoDB, CouchDB, Raven DB, IBM Domino, and MarkLogic.
- Key-value stores are the simplest form of NoSQL database. Every row is stored as a key-value pair. Popular examples include Redis, Memcached, and Riak.
- Wide-column stores, also known as columnar data stores, are optimized for making queries over large datasets, as well as to store columns of data together instead of as rows. Examples include Cassandra and HBase.
- Graph stores store information about graphs; networks, such as social connections; road maps; and transport links. Neo4j is the most popular graph store.
Next, we'll review some of the capabilities of Cloud Pak for Data that enable it to address some of the challenges and one of them is Data virtualization.
Data virtualization – accessing data anywhere
Historically, enterprises have consolidated data from multiple sources into central data stores, such as data marts, data warehouses, and data lakes, for analysis. While this is still very relevant for certain use cases, the time, money, and resources required make it prohibitive to scale every time a business user or data scientist needs new data. Extracting, transforming, and consolidating data is resource-intensive, expensive, and time-consuming and can be avoided through data virtualization.
Data virtualization enables users to tap into data at the source, removing complexity and the manual processes of data governance and security, as well as incremental storage requirements. This also helps simplify application development and infuses agility. Extract, Transform, and Load (ETL), on the other hand, is helpful for complex transformational processes and nicely complements data virtualization, which allows users to bypass many of the early rounds of data movement and transformation, thus providing an integrated, business-friendly view in near real time.
The following diagram shows how data virtualization connects data sources and data consumers, thereby enabling a single pane of glass to access distributed datasets across the enterprise:

Figure 3.8 – Data virtualization – managing all your data, regardless of where it resides
There are very few vendors that offer data virtualization. According to Tech Target, the top five vendors in the market for data virtualization are as follows:
- Actifio Sky
- Denodo
- IBM Cloud Pak for Data
- Informatica PowerCenter
- Tibco Data Virtualization
Among these, IBM stands out for its integrated approach and scale. Its focus on a unified experience of bringing data management, data governance, and data analysis into a single platform resonates with today's enterprise needs, while its unique IP enables IBM's data virtualization to scale both horizontally and vertically. Among other things, IBM leverages push-down optimization to tap into the resources of the data sources, enabling it to scale without constraints.
Data virtualization connects all the data sources to a single, self-balancing collection of data sources or databases, referred to as a constellation. No longer are analytics queries performed on data that's been copied and stored in a centralized location. The analytics application submits a query that's processed on the server where the data source exists. The results of the query are consolidated within the constellation and returned to the original application. No data is copied, and it only exists at the source.
By using the processing power of every data source and accessing the data that each data source has physically stored, latency from moving and copying data is avoided. In addition, all repository data is accessible in real time, and governance and erroneous data issues are virtually eliminated. There's no need for extract, transform, and load and duplicate data storage, accelerating processing times. This process brings real-time insights to decision-making applications or analysts more quickly and dependably than existing methods. It also remains highly complementary with existing methods and can easily coexist when it remains necessary to copy and move some data for historical, archival, or regulatory purposes:

Figure 3.9 – Data virtualization in Cloud Pak for Data
A common scenario in distributed data systems is that many databases store data in a common schema. For example, you may have multiple databases storing sales data or transactional data, each for a set of tenants or a region. Data virtualization in Cloud Pak for Data can automatically detect common schemas across systems and allow them to appear as a single schema in data virtualization – a process known as schema folding. For example, a SALES table that exists in each of the 20 databases can now appear as a single SALES table and can be queried through Structured Query Language (SQL) as one virtual table.
Data virtualization versus ETL – when to use what?
Historically, Data warehouses and data lakes are built by moving data in bulk using ETL. One of the leading ETL products in the market happens to be from IBM and is called IBM DataStage. So, it begs the question as to when someone should use data virtualization versus an ETL offering. The answer depends on the use case. If the intent is to explore and analyze small sets of data in real time and where data can change every few minutes or hours, data virtualization is recommended. Please note that the reference to small sets of data alludes to the actual data that's transferred, not the dataset that a query is performed on. On the flip side, if the use case requires processing huge datasets across multiple sources and where data is more or less static over time (historical datasets), an ETL-based solution is highly recommended.
Platform connections – streamlining data connectivity
Cloud Pak for Data also includes the concept of platform connections, which enable enterprises to define data source connections universally. These can then be shared by all the different services in the platform. This not only simplifies administration but enables users across different services to easily find and connect to the data sources. Cloud Pak for Data also offers flexibility to define connections at the service level to override platform connections. Finally, administrators can opt to either set user credentials for a given connection or force individual users to enter their respective credentials. The following is a screenshot of the platform connections capability of Cloud Pak for Data v4.0, which was released on June 23, 2021:
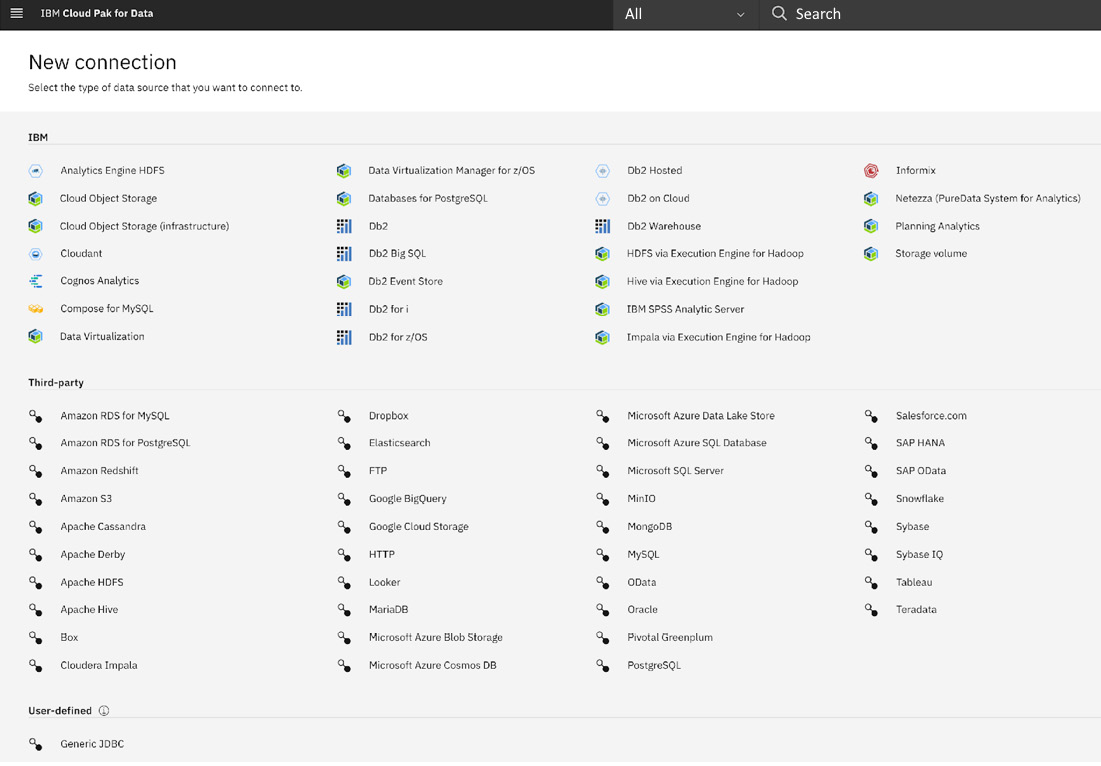
Figure 3.10 – Platform connections in IBM Cloud Pak for Data v4.0
Now that we have gone through the collect capabilities of Cloud Pak for Data, let's see how customers can modernize their data estates for Cloud Pak for Data and the underlying benefits of this.
Data estate modernization using Cloud Pak for Data
So far, we have seen the evolving complexity of the data landscape and the challenges enterprises are trying to address. Increasing data volumes, expanding data stores, and hybrid multi-cloud deployment scenarios have made it very challenging to consolidate data for analysis. IBM's Cloud Pak for Data offers a very modern solution to this challenge. At its core is the data virtualization service, which lets customers tap into the data in source systems without moving the data. More importantly, its integration with the enterprise catalog means that any data that's accessed is automatically discovered, profiled, and cataloged for future searches. Customers can join data from multiple sources into virtualized views and can easily enforce governance and privacy policies, making it a one-stop shop for data access. Finally, its ability to scale and leverage source system resources is extremely powerful.
IBM's data virtualization service in Cloud Pak for Data supports over 90% of the enterprise data landscape:
- Apache Hive
- IBM Big SQL
- Cloudera Impala
- Third-party custom JDBC drivers
- Db2 Event Store
- Db2 Warehouse
- Db2 Database
- Db2 for z/OS
- Hive JDBC
- Informix
- MariaDB
- Microsoft SQL Server
- MongoDB
- MySQL Community Edition
- MySQL Enterprise Edition
- Netezza
- Oracle
- PostgreSQL
- Teradata (requires Teradata JDBC drivers to connect)
- Sybase IQ
- Amazon Redshift
- Google BigQuery
- Pivotal Greenplum
- Salesforce.com
- SAP HANA and SAP ODATA
- Snowflake
While tapping into data without moving it is a great starting point, Cloud Pak for Data also enables customers to persist data on its platform. You can easily deploy, provision, and scale a variety of data stores on Cloud Pak for Data. The supported databases on Cloud Pak for Data are as follows:
- Db2 (both OLTP and analytical workloads)
- Db2 Event Store
- MongoDB
- Enterprise DB PostgreSQL
- Cockroach DB
- Crunchy DB PostgreSQL
- Support for object storage – separation of compute and storage
Cloud Pak for Data enjoys a vibrant and open ecosystem, and more data sources are scheduled to be onboarded over the next 1-2 years. This offers customers the freedom to embrace the data stores of their choice while continuing to tap into their existing data landscape. Finally, it's worth mentioning that all the data stores that are available on the platform are containerized and cloud-native by design, allowing customers to easily provision, upgrade, scale, and manage their data stores. Also, customers can deploy these data stores on any private or public cloud, which enables portability. This is critical in situations where data gravity and the co-location of data and analytics is critical.
Summary
Data is the world's most valuable resource and to be successful, enterprises need to become data-centric and leverage their data as a key differentiator. However, increasing data volumes, evolving data stores, and distributed datasets are making it difficult for enterprises and business users to easily find and access the data they need. Today's enterprise data architecture is fairly complex, with a plethora of data stores optimized for specific workloads. Data virtualization offers the silver bullet to address this unique challenge, and IBM's Cloud Pak Data is one of the key vendors in the market today. It is differentiated for its ability to scale and its integrated approach, which addresses data management, data organization, and data analysis requirements.
Finally, IBM's Cloud Pak for Data complements its data virtualization service with several containerized data stores that allow customers to persist data on the platform, while also allowing them to access their existing data without moving it.
In the next chapter, you will learn how to create a trusted analytics foundation and organize the data you collected across your data stores.