
4
Accurate Extraction with Amazon Comprehend
In the previous chapter, you learned about the challenges involved in the legacy document extraction process and how businesses can use Amazon Textract for the accurate extraction of elements from any type of document. We will now dive into detailed extraction using Amazon Comprehend for the extraction stage of the Intelligent Document Processing (IDP) pipeline. We will cover the following in this chapter:
- Using Amazon Comprehend for accurate data extraction
- Understanding document extraction – IDP with Amazon Comprehend
- Understanding custom entities extraction with Amazon Comprehend
Technical requirements
For this chapter, you will need access to an AWS account. Before getting started, we recommend that you create an AWS account by referring to AWS account setup and Jupyter notebook creation steps as mentioned in the Technical requirement section in Chapter 2, Document Capture and Categorization. You can find Chapter-3 code sample in GitHub: https://github.com/PacktPublishing/Intelligent-Document-Processing-with-AWS-AI-ML-/tree/main/chapter-4
Using Amazon Comprehend for accurate data extraction
Amazon Comprehend is a fully managed AWS AI service with pre-trained Machine Learning (ML) models for accurate data extraction and to derive insights from your documents. It is a managed solution, which means you call Amazon Comprehend’s API and pass in your input, and you will get a response back. Amazon Comprehend uses Natural Language Processing (NLP) to extract meaningful information about the content of unstructured, dense, text content. To use Comprehend, no ML experience is required. You can call its Application Programming Interfaces (APIs) to leverage the pre-trained ML model behind the scenes. Amazon Comprehend provides APIs that you can call through the serverless environment without the need to manage any kind of infrastructure. Once the document content is extracted, you can proceed with the subsequent stages of the IDP pipeline as required by your business.
Now let’s check out the core features and functionalities of Amazon Comprehend.
Amazon Comprehend enables you to examine your unstructured data, for example, unstructured text. It can help you gain various insights about content by using a number of pretrained models.
In Figure 4.1, you can see some of the key features of Amazon Comprehend for the document extraction phase of the IDP pipeline.
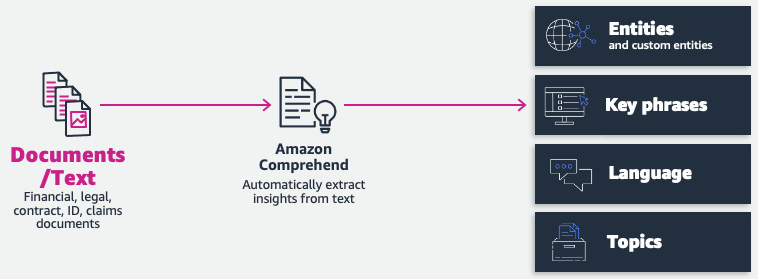
Figure 4.1 – Amazon Comprehend – key features for IDP
Now, let’s have a walk-through of these features on the AWS Management Console for Amazon Comprehend:
- Go to Amazon Comprehend. Click on Launch Amazon Comprehend:

Figure 4.2 – Amazon Comprehend on the AWS Management Console
- We will use the following sample text to analyze all of the features of Amazon Comprehend available through the AWS Management Console:

s
Figure 4.3 – Sample unstructured text
- Copy the preceding text and insert it into Real-time analysis → Input text, as shown in Figure 4.4, and click on Built-in and then Analyze:
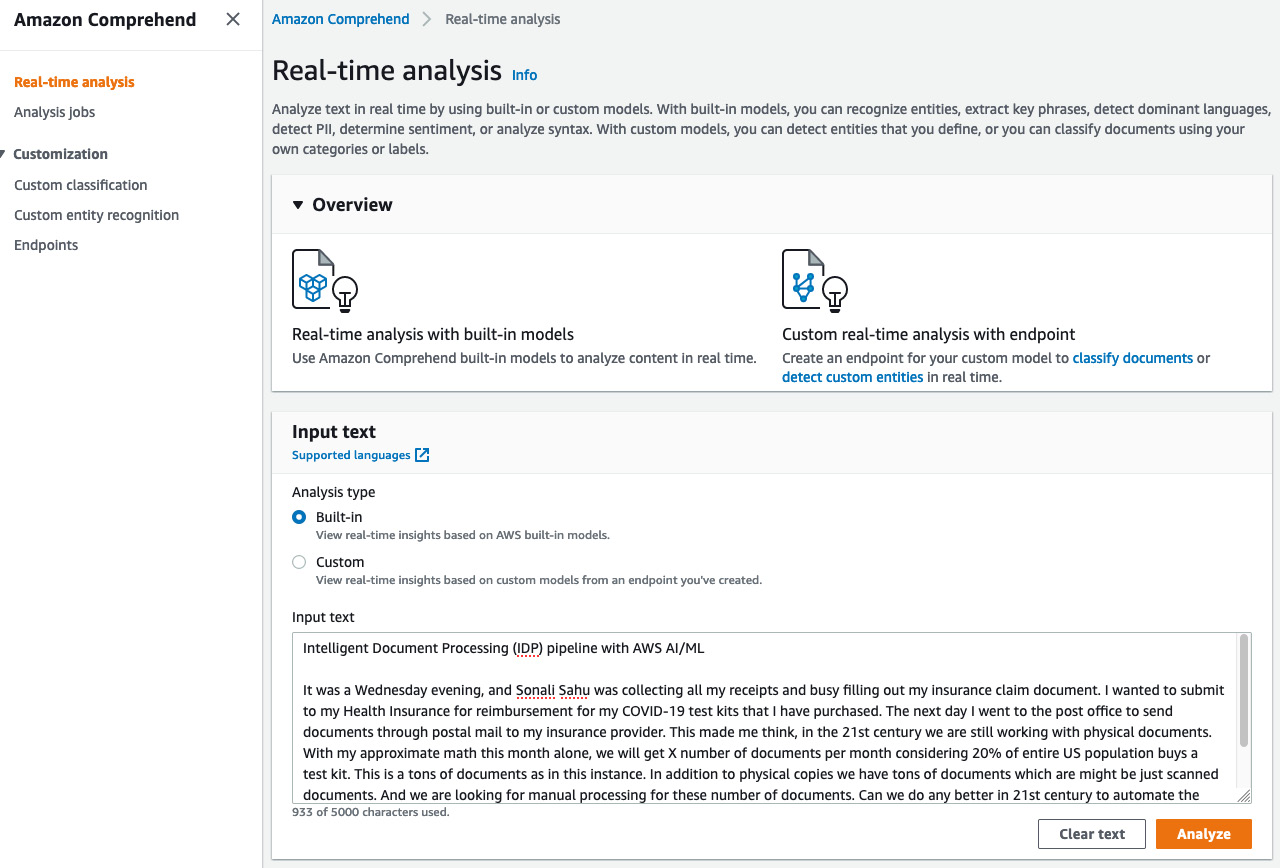
Figure 4.4 – Amazon Comprehend Real-time analysis
- Scroll down to see the insights.
Now, we will walk through each Insights API by changing each tab:
- Detecting entities: In Chapter 3, Accurate Document Extraction with Amazon Textract, we looked into how all the fields can be extracted from a document. But what if you are just interested in extracting only a few fields? For example, say you have a bank statement, and you might just be interested in extracting and reviewing the date and names from this document. In that case, you can call Amazon Comprehend’s pre-trained Detect Entities API to get only person’s name and dates from the bank statement document. Now let’s enter some sample text as in Figure 4.3 and call the Amazon Comprehend detect entities feature. You can see from the screenshot in Figure 4.5 that Amazon Comprehend was able to detect the highlighted entities from the text you entered. Some of the pre-trained entities are Person, Date, Location, Organization, and Date.
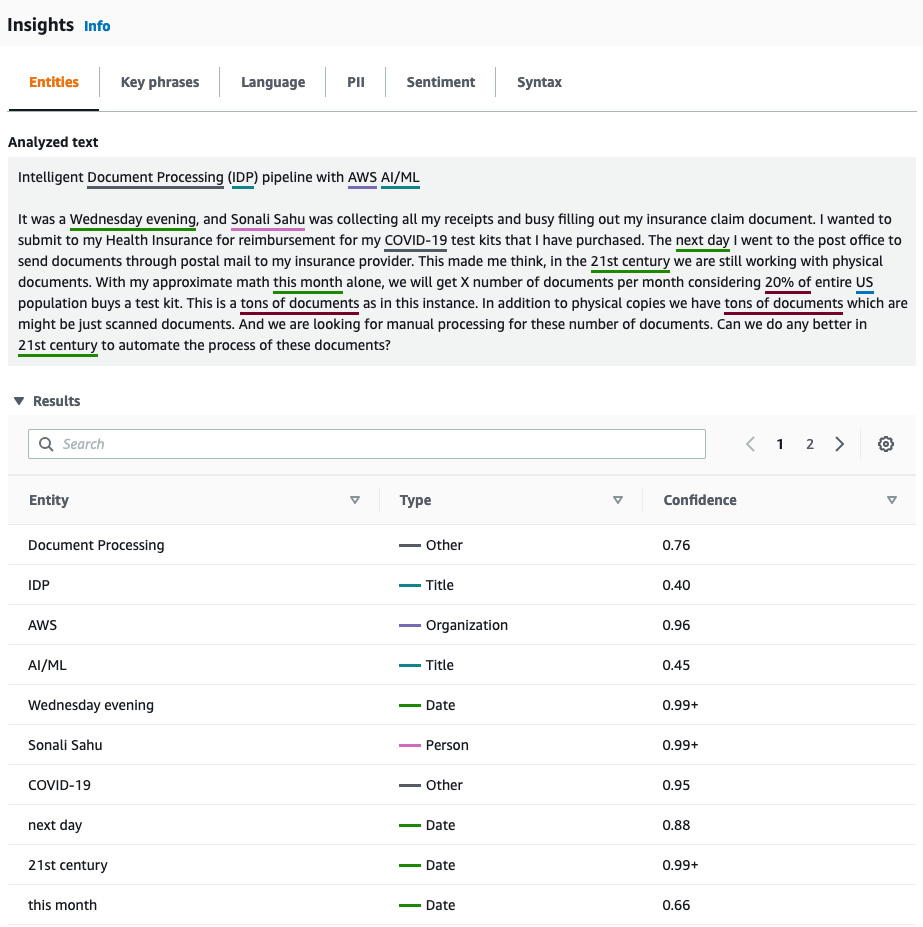
Figure 4.5 – Amazon Comprehend pre-trained detection entities
You can click on subsequent pages on the result screen to see the additional extracted entities. Following is the output from Amazon Comprehend pre-trained Named Entities Recognition additional output.
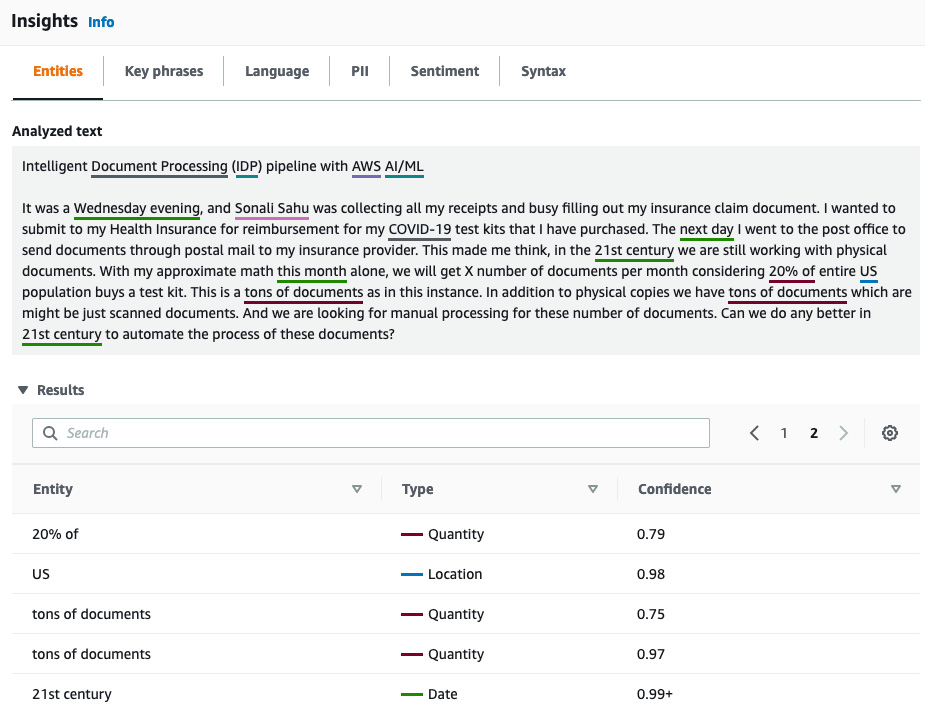
Figure 4.6 – Amazon Comprehend entities
- Detecting key phrases: Amazon Comprehend can detect key phrases in a paragraph of text. To detect key phrases, we will go to the Key phrases tab. In English, a key phrase consists of a noun phrase (noun plus modifier) that describes a particular thing. For the text in Figure 4.3, you can see the extracted key phrases here:
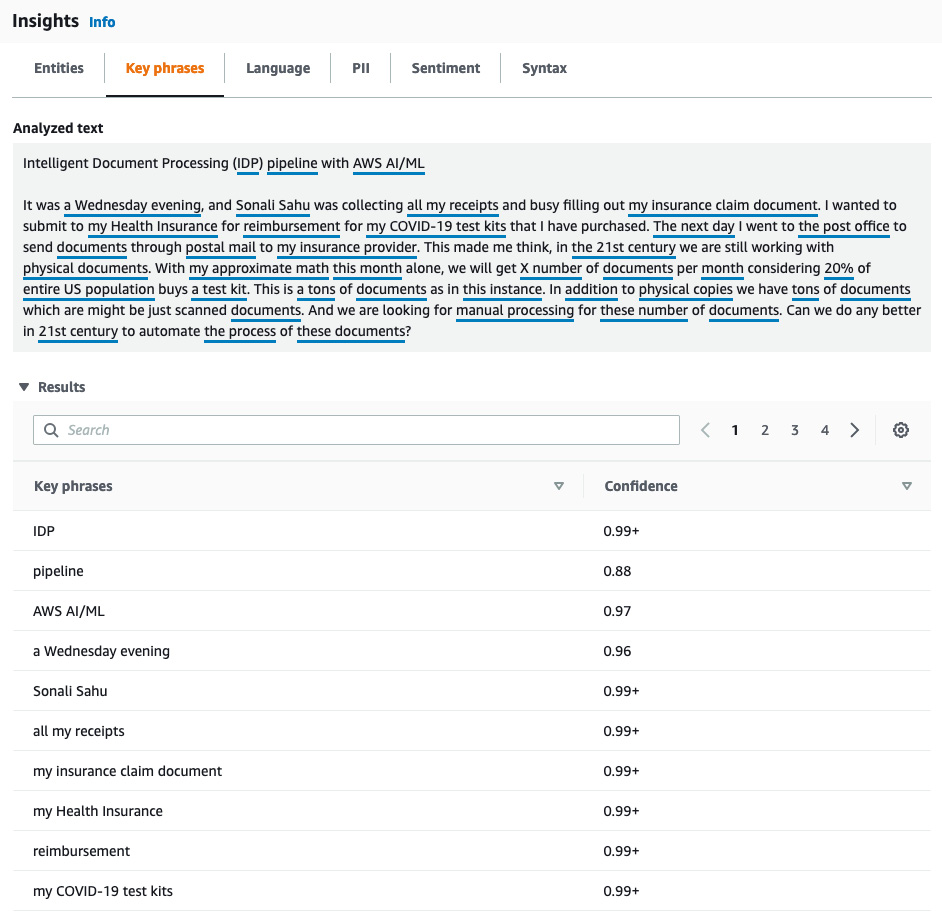
Figure 4.7 – Amazon Comprehend key phrases
At times, we get documents in different languages. We can identify the dominant language of the text.
- Detecting language: This is one of the most common requirements for businesses that process documents globally. I was speaking with a college transcripts processing customer, they get college applications and supporting documents from many different countries that can be in different languages, such as Spanish, German, Korean, and more. The first thing to find out is, does your extraction engine support the language in question? For example, Amazon Textract supports Spanish, Italian, German, and more, in addition to English. My recommendation is that you find an Optical Character Recognition (OCR) engine that supports your language. If your requirement is just to detect the language of some text for further downstream processing or just categorization based on the language, you can use Amazon Comprehend’s detect dominant language feature. In Figure 4.7, we have gone to the Language tab to see the dominant language identified by Amazon Comprehend:
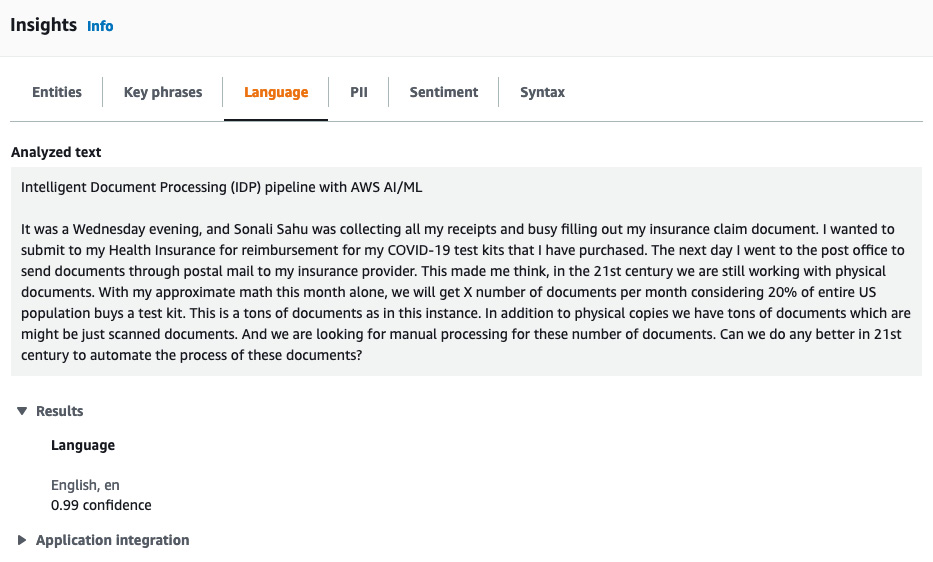
Figure 4.8 – Amazon Comprehend language detection
Another business-critical feature of Amazon Comprehend is PII detection. We will be covering this in detail in Chapter 6, Review and Verification of Intelligent Document Processing.
Now let’s see how key features of Amazon Comprehend can be extracted using APIs for the extraction stage of the IDP pipeline.
Understanding document extraction – the IDP extraction stage with Amazon Comprehend
In the preceding example for Amazon Comprehend’s extraction, the input required was of the text type.
How can we process documents and extract insights with Amazon Comprehend? For this solution, we will use Amazon Textract in conjunction with Amazon Comprehend for accurate data extraction.
See Figure 4.9 for an architecture that would serve as the extraction part of the IDP pipeline:
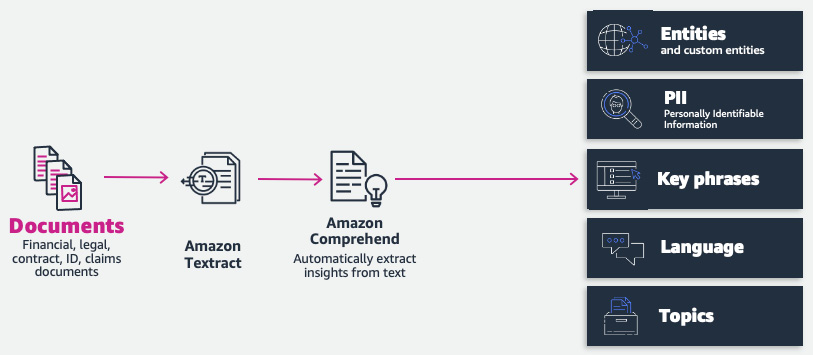
Figure 4.9 – Document extraction stage with Amazon Comprehend
We have walked through the key features of Amazon Comprehend on the AWS Management Console. But we can use Amazon Comprehend APIs to automate extraction programmatically. Now let’s walk through some sample code for extracting pre-trained entities from any type of document:
- Get the boto3 client for Amazon Textract and Amazon Comprehend:
s3=boto3.client('s3')
textract = boto3.client('textract', region_name=region)
comprehend=boto3.client('comprehend', region_name=region)
- We will use 04detectenttitiesdoc.png. Let’s check out the content of this document:
# Document
documentName = "04detectentitiesdoc.png"
display(Image(filename=documentName))

Figure 4.10 – Sample text for the Amazon Comprehend API
- Call the Amazon Textract detect_document_text() API for the extraction of text from the document. Then, we parse through each line of the JSON response and print the result as follows:
#Extract dense Text from scanned document
# Amazon Textract client
textract = boto3.client('textract')
# Read document content
with open(documentName, 'rb') as document:
imageBytes = bytearray(document.read())
# Call Amazon Textract
response = textract.detect_document_text(Document={'Bytes': imageBytes})
# Print detected text
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('�33[94m' + item["Text"] + '�33[0m')
text = text + " " + item["Text"]
You can see the result of all extracted lines from Amazon Textract in Figure 4.11:

Figure 4.11 – Lines extracted with Amazon Textract
- Now let’s pass the extracted text in the preceding step to Amazon Comprehend for further insights extraction. We are calling Amazon Comprehend’s detect_entities() API to extract pre-trained entities:
#detect entities
entities = comprehend.detect_entities(LanguageCode="en", Text=text)
#print(entities)
#Print pre-defined entities of type Person
print(" Persons identified")
for item in entities["Entities"]:
if item["Type"] == "PERSON":
print(item["Text"])
print(" Organization identified")
#print pre-defined entities of type Organization
for item in entities["Entities"]:
if item["Type"] == "ORGANIZATION":
print(item["Text"])
print(" Quantities identified")
#print pre-defined entities of type Quantity
for item in entities["Entities"]:
if item["Type"] == "QUANTITY":
print(item["Text"])
print(" Location identified")
#print pre-defined entities of type Location
for item in entities["Entities"]:
if item["Type"] == "LOCATION":
print(item["Text"])
- We are iterating through the JSON response and filtering for "PERSON", "ORGANIZATION", "QUANTITY", and "LOCATION". The results are as follows:
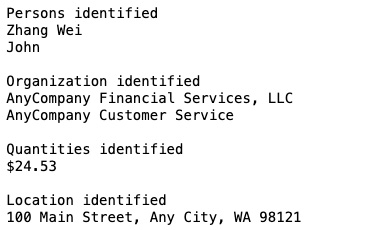
Figure 4.12 – Amazon Comprehend results
Here, we leveraged Amazon Textract and Amazon Comprehend for accurate document extraction.
Amazon Comprehend also supports custom entities extraction in addition to pre-trained entities extraction. Now let’s look at custom entities extraction and how it can be done accurately with Amazon Comprehend.
Understanding custom entities extraction with Amazon Comprehend
Sometimes, our key business terms don’t fall under the category of pre-defined entities. In those cases, we can train our custom entity recognizer to get insights from our document. Amazon Comprehend’s custom entity recognition allows you to bring in your own dataset (a list of documents) and train a custom model to extract custom entities from your documents. This is a two-step process:
- Train an entity recognizer by providing a small, labeled dataset. This entity recognizer uses automated ML (AutoML) and transfer learning to train a model based on your training dataset. It also offers evaluation/performance metrics, such as F1 score, precision, and recall. You can start training an Amazon Comprehend custom entity recognizer with single-digit sample documents. I recommend that you check the performance metrics of the trained model and include additional training samples to improve them. Also, you should check your model training for overfitting.
- Run asynchronous or real-time analysis on the trained model after you have trained a custom entity.
Now let’s walk through each step.
We are using Home Owner Association (HOA) documents for our sample and extracting custom entities such as “closing date,” “seller,” “address,” and “due amount.” HOA documents contain dense text along with additional semi-structured form-based information. Businesses want to extract only information or business terms that are critical to their use case. For example, from an HOA document, a business may want to extract closing dates and addresses for further review and comparison. You can also tag and index documents with such metadata to enable intelligent search. However, adding such search capabilities to the IDP pipeline is out of the scope of this book. Now, we will look into the extraction of custom entities from any type of document.
We will be using the following architecture for our Amazon Comprehend custom entity recognition model:
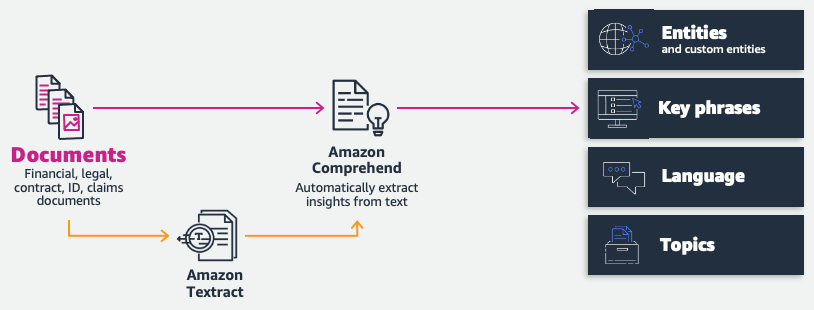
Figure 4.13 – Document extraction with Amazon Comprehend/Amazon Textract
Let’s go through the training of our Amazon Comprehend custom entity recognizer.
Training an Amazon Comprehend custom entity recognizer
Amazon Comprehend allows two types of training datasets. The simpler type is the entity list, where your training data consists of text and text type. This is easy to get started with, but for more accurate results, I recommend creating labeled training data with specific offsets. To give additional training context, we can use annotations and training documents with exact bounding boxes by using Begin Offset and End Offset.
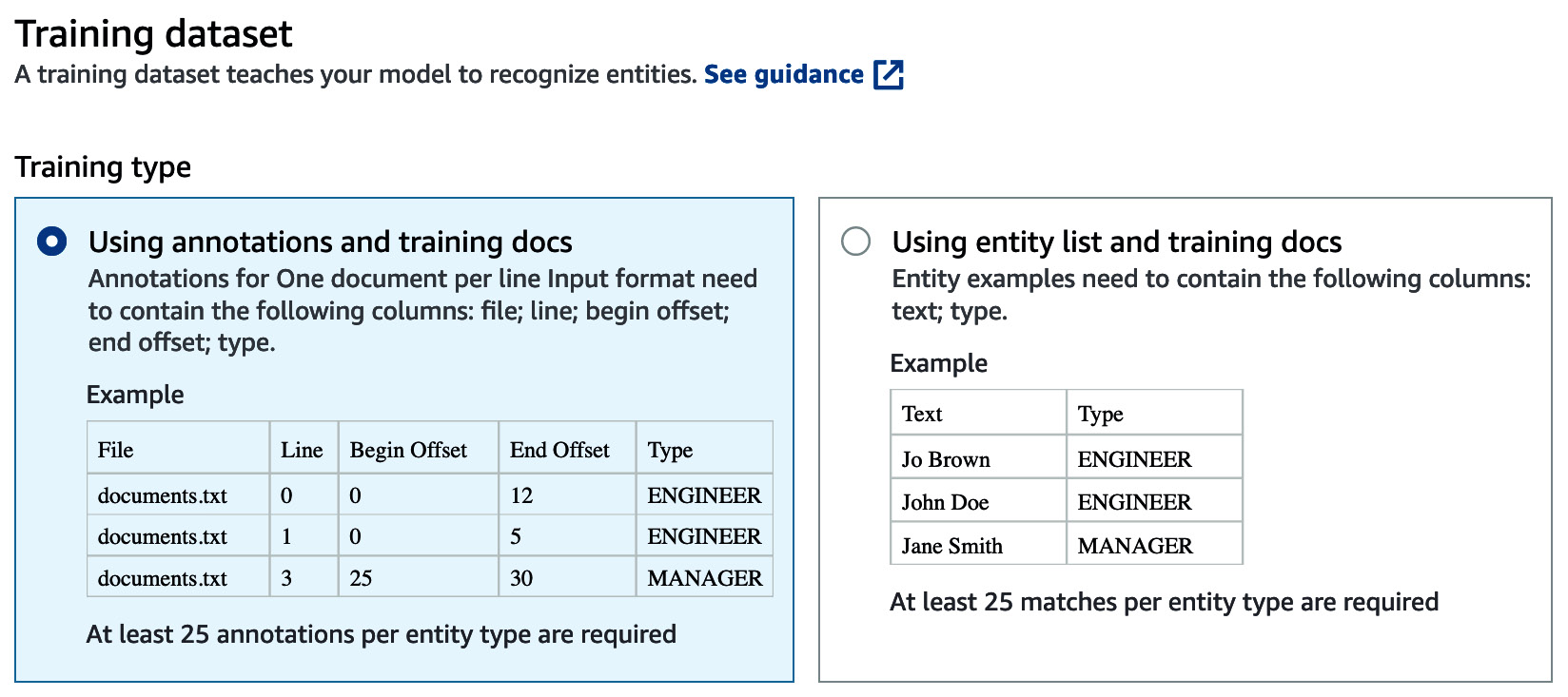
Figure 4.14 – Training dataset selection for Amazon Comprehend
For our example, we are using entity_list:
- Use the CSV file named entity_list.csv. We are also printing the custom entities that we want to derive from the documents:
entities_df = pd.read_csv('./chapter_4_training/entity_list.csv', dtype={'Text': object})
entities = entities_df["Type"].unique().tolist()
print(f'Custom entities : {entities}')
print(f' Total Custom entities: {entities_df["Type"].nunique()}')
display(HTML(entities_df.to_html(index=False)))
- Now let’s look at the labeled data in Figure 4.15:
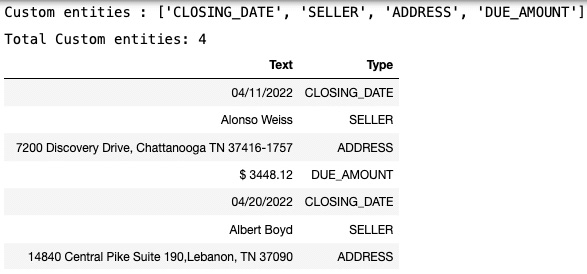
Figure 4.15 – Labeled data for Comprehend custom entities
- Now let’s upload our entity_list training dataset to Amazon S3. We are also uploading our training corpus (entity_training_corpus.csv https://github.com/PacktPublishing/Intelligent-Document-Processing-with-AWS-AI-ML-/blob/main/chapter-4/entity_training_corpus.csv) to the same S3 bucket:
#Upload entity list CSV to S3
entities_key='./chapter_4_training/entity_list.csv'
training_data_key='./chapter_4_training/entity_training_corpus.csv'
data_bucket = "bookidppackt123"
s3=boto3.client('s3')
s3.upload_file(Filename='./chapter_4_training/entity_list.csv',
Bucket=data_bucket,
Key=entities_key)
s3.upload_file(Filename='./chapter_4_training/entity_training_corpus.csv',
Bucket=data_bucket,
Key=training_data_key)
entities_uri = f's3://{data_bucket}/{entities_key}'
training_data_uri = f's3://{data_bucket}/{training_data_key}'
print(f'Entity List CSV File: {entities_uri}')
print(f'Training Data File: {training_data_uri}')
You can see the result for the labeled training dataset in Figure 4.16:
Figure 4.16 – Labeled data for our custom Comprehend NER model
- We are calling Comprehend’s create_entity_recognizer() API to create a custom Comprehend model. We are passing in a training data URI and an entity list URI as inputs:
# Create a custom entity recognizer
import sagemaker
entity_recognizer_name = 'Sample-Entity-Recognizer-IDPBook'
entity_recognizer_version = 'Sample-Entity-Recognizer-IDPBook-v1'
entity_recognizer_arn = ''
create_response = None
role = sagemaker.get_execution_role()
EntityTypes = [ {'Type': entity} for entity in entities]
try:
create_response = comprehend.create_entity_recognizer(
InputDataConfig={
'DataFormat': 'COMPREHEND_CSV',
'EntityTypes': EntityTypes,
'Documents': {
'S3Uri': training_data_uri
},
'EntityList': {
'S3Uri': entities_uri
}
},
DataAccessRoleArn=role,
RecognizerName=entity_recognizer_name,
VersionName=entity_recognizer_version,
LanguageCode='en'
)
entity_recognizer_arn = create_response['EntityRecognizerArn']
print(f"Comprehend Custom entity recognizer created with ARN: {entity_recognizer_arn}")
- It takes some time to train a custom Comprehend entity recognition model. You can check the status of your trained Comprehend model by going to Amazon Comprehend on the AWS Management Console or running API DescribeEntityRecognizer.
Now let’s check the performance of our trained model.
Checking the performance of a trained model
Within Amazon Comprehend in the AWS Management Console, click on Custom entity recognition and select the custom NER model that we trained in the previous steps. Click on the Performance tab to check the performance of the model:
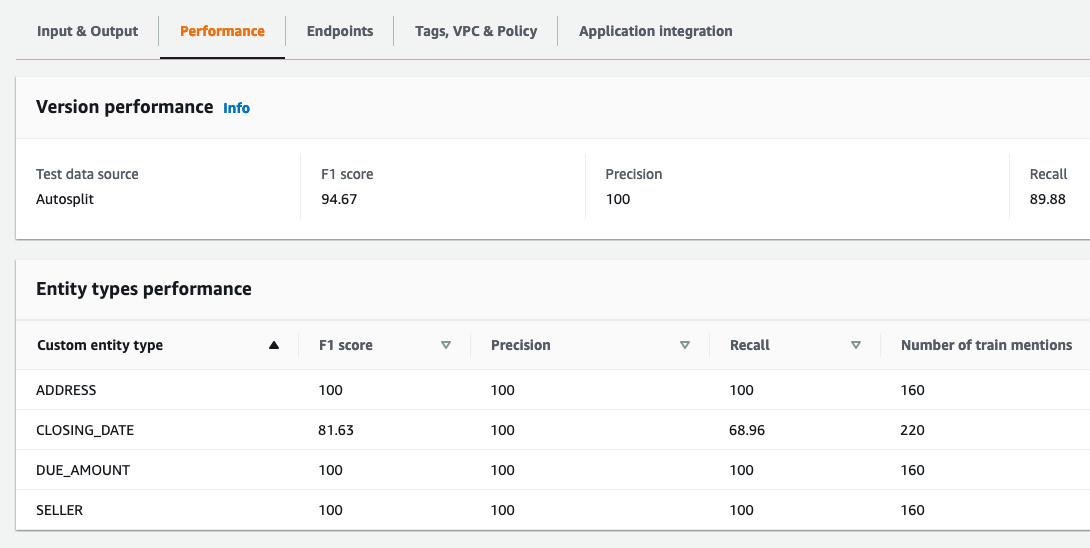
Figure 4.17 – Performance metrics for the Comprehend custom entities model
Inference result from the Amazon Comprehend custom entity recognizer
Now our Amazon Comprehend custom entity recognizer is trained. We will follow these steps to inspect the results of our trained custom NER model:
- Go to Amazon Comprehend in the AWS Management Console. Click on Analysis jobs on the left:
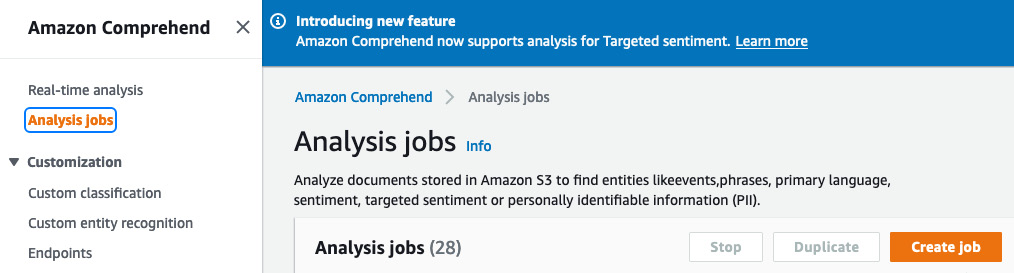
Figure 4.18 – Analysis jobs on the AWS Management Console
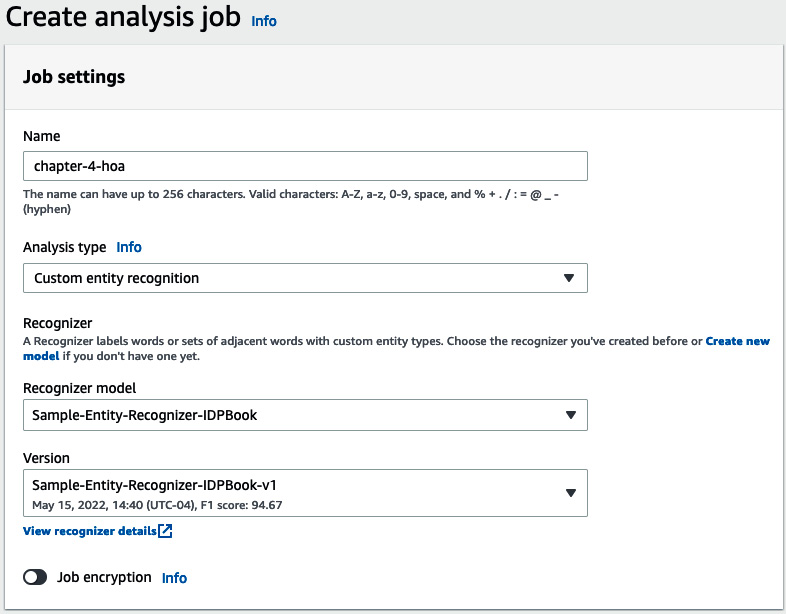
Figure 4.19 – Analysis job parameter setting
- As the input document, upload hoa_0.pdf to your Amazon S3 bucket, and give the path to this file in the Amazon S3 bucket.
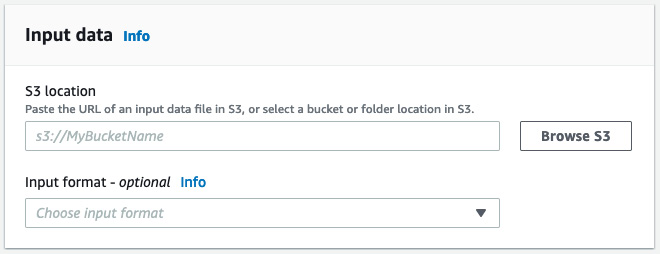
Figure 4.20 – Analysis job input data
- For Output data location, give the location of your Amazon S3 bucket.
- For Access permissions, select Create an IAM Role and provide the prefix as shown in the following screenshot:
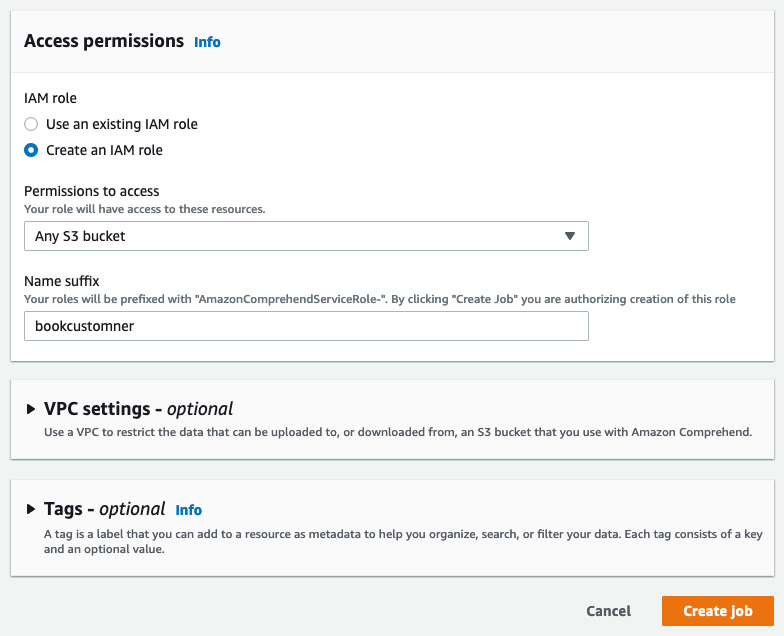
Figure 4.21 – Analysis job access permissions
- Then click on Create job. It will take some time to get the result.
- Once the analysis job is complete, you can go to your output location bucket and check the result.
A sample result follows:
{"Entities": [{"BeginOffset": 14, "EndOffset": 24, "Score": 0.9999934435319415, "Text": "04/04/2022", "Type": "CLOSING_DATE"}], "File": "hoa_0.txt", "Line": 6}
{"Entities": [{"BeginOffset": 8, "EndOffset": 18, "Score": 0.9999991059312681, "Text": "John Smith", "Type": "SELLER"}], "File": "hoa_0.txt", "Line": 7}
{"Entities": [{"BeginOffset": 25, "EndOffset": 60, "Score": 0.9999999850988398, "Text": "28777 Amos Lock, Markfurt, HI 71418", "Type": "ADDRESS"}], "File": "hoa_0.txt", "Line": 8}
{"Entities": [{"BeginOffset": 0, "EndOffset": 8, "Score": 0.9999828342970942, "Text": "$ 315.58", "Type": "DUE_AMOUNT"}], "File": "hoa_0.txt", "Line": 14}
- As you can see, we were able to accurately extract "CLOSING_DATE", "SELLER", "ADDRESS", and "DUE_AMOUNT" from our HOA document. We also got a confidence score. We can leverage confidence scores to set a threshold for the accurate extraction of elements.
We just saw how we can train our own custom Comprehend entity recognition model to extract entities from any type of document.
Note
Comprehend charges for trained models, so I recommend you delete your trained model and any datasets to avoid unexpected costs.
Summary
In this chapter, we discussed core features of Amazon Comprehend, including the extraction of pre-trained entities such as “Person,” “Date,” and “Location” from text. We then discussed how we can leverage Amazon Comprehend for the document extraction stage of the IDP pipeline. We also discussed how to use Amazon Textract to extract text from a document and pass it to Amazon Comprehend for entity extraction.
We then reviewed the need for custom entities extraction and how to train your own Comprehend custom entity recognizer model. We discussed the two-step process of training a custom entity recognizer and then created an analysis job for custom entities extraction from any type of document.
In the next chapter, we will extend the extraction and enrichment stage of the IDP pipeline using Amazon Comprehend Medical. You will be introduced to the enrichment stage of IDP and discover how to leverage Amazon Comprehend to enrich your documents.