
8
IDP Healthcare Industry Use Cases
In the previous chapter, you understood what Fast Healthcare Interoperability Resources (FHIR) is and how Amazon HealthLake can help with FHIR. Moreover, we looked into how we can manage unstructured non-FHIR documents to store in a centralized data store with an Intelligent Document Processing (IDP) pipeline. We will now go into more detail about FHIR and see how it helps in healthcare interoperability, with various industry use cases. We will also check how Amazon IDP helps in healthcare industry use cases. You will learn how to build an IDP pipeline for the healthcare industry. Moreover, you will learn how to create a secure, compliant IDP solution.
We will navigate through the following sections in this chapter:
- Understanding IDP with healthcare prior authorization
- Learning IDP for pharmacy receipt automation
- Understanding healthcare claims processing and risk adjustment with IDP
Technical requirements
For this chapter, you will need access to an AWS account. Before getting started, we recommend that you create an AWS account by referring to the AWS account setup and Jupyter notebook creation steps in the Technical requirements section in Chapter 2, Document Capture and Categorization.
You can find Chapter-8 code sample in GitHub: https://github.com/PacktPublishing/Intelligent-Document-Processing-with-AWS-AI-ML-/tree/main/chapter-8. Also recommend to check availability of AI service in your AWS regions before using it.
Understanding IDP with healthcare prior authorization
In this section, we will see how to use AWS AI services to accelerate the healthcare prior authorization process, but before diving deep into AWS AI services, let’s learn about the healthc are prior authorization process.
An introduction to the healthcare prior authorization process
What is “prior authorization?" Prior authorization is a process to receive approval before any healthcare treatments, services, drugs, and so on. Most often, patients or providers request approval from a payer prior to any type of healthcare service so that the cost of it will be covered by the insurance plan. Healthcare insurance companies use the process of prior authorization to check for the right financial responsibility to keep healthcare cost-effective for patients. However, during the prior authorization process, there are many manual transactions of documents, making the process slow, time-consuming, and inefficient, resulting in a delay in receiving treatments, leading to patients not having the right value-based care. For example, during the prior authorization process, the provider manually enters data on a payer-specific portal, or exchanges documents by fax. Most often, manual data entry and the verification process require human effort, which becomes time-consuming and expensive. Can we help automate this prior authorization process with AWS IDP? To answer this, let’s look at the AWS infrastructure for data exchange and AWS AI services to find a solution for the prior authorization use case.
In the previous chapter, we looked into how the future of a healthcare data exchange depends on a common language, which can enable communication across different healthcare systems, such as a payer or provider. This seamless data exchange at a high level can be achieved with healthcare interoperability. The not-for-profit organization Health Level Seven (HL7) International has been a leader in defining healthcare data interoperability since 1987. HL7 has developed healthcare data modeling for Electronic Health Records (EHRs) to enable a meaningful exchange of healthcare information, with data kept confidential and secure. Its latest framework, FHIR, is a step forward to make the process seamless, with two broader categories. This includes a data model for healthcare information and a technology stack for application development. This was developed in collaboration with an open source community for wide adoption and access. Since 2012, FHIR has accelerated the development of healthcare data interoperability, allowing faster, easier healthcare data sharing. Health data is growing at a rapid pace. At the same time, technology is advancing at a rapid pace. This growing health data, with advanced technology, has created the requirement for consistent healthcare data interoperability across healthcare systems.
We have discussed how healthcare data interoperability (in Chapter 7, Accurate Extraction and Health Insights with Amazon HealthLake) can help with FHIR data exchange.
In 2018, the US Office of the National Coordinator for Health Information Technology launched a testing program called Inferno to support the adoption of FHIR. Inferno allows developers to verify that their FHIR standards are consistently implemented across systems. This will help ensure that developers adhere to FHIR standards and that communication remains consistent. Moreover, Centers for Medicare and Medicaid Services (CMS) released a rule on coverage transparency, helping the wider adoption of a healthcare data exchange.
Here is a link to dive into details about the health plan price transparency: https://www.cms.gov/healthplan-price-transparency, and here is a link to dive into details about FHIR: https://www.hl7.org/fhir/. Paired with cloud technologies, FHIR is turning real-time interoperability into a reality. Data centers that held key medical data were difficult to scale, maintain, and access. Now, with FHIR operating as a common language of a data exchange, we can implement a healthcare interoperability platform.
Community collaboration is also shaping a data exchange platform for healthcare. One such community, Da Vinci, has developed reference implementations for FHIR healthcare data interoperability (https://github.com/HL7-DaVinci). You can extend these reference implementations to find a solution for healthcare prior authorization use cases, with Coverage Requirements Discovery (CRD) as an implementation example. Automated prior authorization can help speed up processes, as well as reduce the burden on the provider of additional administrative work, resulting in increased value-based care for the patient. Let’s look at a quick architectural guidance for CRD for prior authorization use cases, as shown here.

Figure 8.1 – Healthcare prior authorization – block architecture
The preceding block architecture shows the communication of two components – in this case, a payer and provider healthcare data exchange with CDS hooks. It also describes the components required by the payer to implement the framework. In Figure 8.2, you can also check out a reference architecture to deploy this prior authorization interoperability platform on an AWS Cloud container platform.
The detailed implementation is out of the scope of this book. For additional information, we recommend that you check out the details here: https://aws.amazon.com/blogs/industries/healthcare-simplify-authorization-aws-hl7-fhir/.
You can find more details on CDS hooks here: https://cds-hooks.hl7.org/.

Figure 8.2 – An AWS prior authorization infrastructure – reference architecture
We just looked at reference architecture for prior authorization. Now, let’s see another example of automating the prior authorization form-filling process with the help of IDP.
Automate prior authorization form filling using Amazon HealthLake
We have listed the pain point of the healthcare prior authorization process in the An introduction to the healthcare prior authorization process section. Can we help accelerate this prior authorization process with innovation? The answer is yes. One such technical implementation will be illustrated in the example of automating the prior authorization form-filling process. To automate the form-filling process, we need to extract the required information from clinical data. Let’s now check out a sample prior authorization form, as shown here:

Figure 8.3 – A sample prior authorization form
To fill in this prior authorization form, we will use the following sample reference architecture:

Figure 8.4 – Prior authorization architecture
For this reference architecture, we are assuming that we have an FHIR resource such as Claim, Patient, Organization, or Condition in our Amazon HealthLake data store. Also, we have additional clinical information in a non-FHIR format, such as a provider note in a PDF format. We convert a RAW document to a DocumentReference FHIR resource, and store it in the same Amazon HealthLake data store. If you do not know how to generate a DocumentReference FHIR resource from a non-FHIR clinical document type, refer to Chapter 6, Review and Verification of Intelligent Document Processing. Once we have all the clinical information regarding a patient in an Amazon HealthLake data store, we can use Amazon analytics services such as Amazon Athena and AWS Glue for quick analysis. We can query to derive required information such as patient name, date-of-birth information from the Patient FHIR resource, the health plan from Claim, and health plan address from Organization FHIR resources. We can also validate the accuracy of these elements with the Document Reference FHIR resource.
Let’s look at a sample filled-in prior authorization form with these extracted elements:

Figure 8.5 – A sample filled prior authorization form
We went through the reference architecture of how we can leverage AWS AI services to automate the prior authorization form-filling process. Now, let’s look at IDP in another healthcare use case, pharmacy receipt processing. Note that I would recommend checking out the following links about designing a HIPAA-compliant architecture in AWS:
https://d1.awsstatic.com/Industries/HCLS/Resources/Architecting%20for%20HIPAA%20one-pager%202018.pdf
https://aws.amazon.com/compliance/hipaa-compliance/
Learning IDP for pharmacy receipt automation
Now, we will dive into a solution to extract the required information from a prescription, levering our AWS IDP pipeline. For this exercise, we will use the following sample pharmacy prescription:

Figure 8.6 – A sample prescription
Our goal is to find out the important information to be filled in on a medical prescription. We will answer some key questions to determine what goes into the medical prescription. We will leverage the Amazon Textract Queries feature to find the answer to our questions. Amazon Textract Queries leverages a combination of visual, spatial, and language contexts to provide answers to our natural language questions.
Let’s check out Amazon Textract Queries on the AWS Management Console for this sample prescription:
- Go to Amazon Textract on the AWS Management Console. Click on Try Amazon Textract:

Figure 8.7 – The AWS Management Console – Try Amazon Textract

Figure 8.8 – The Amazon Textract upload document screen
- Select Forms and Queries, and add queries to the Queries section, as shown in the following screenshot:
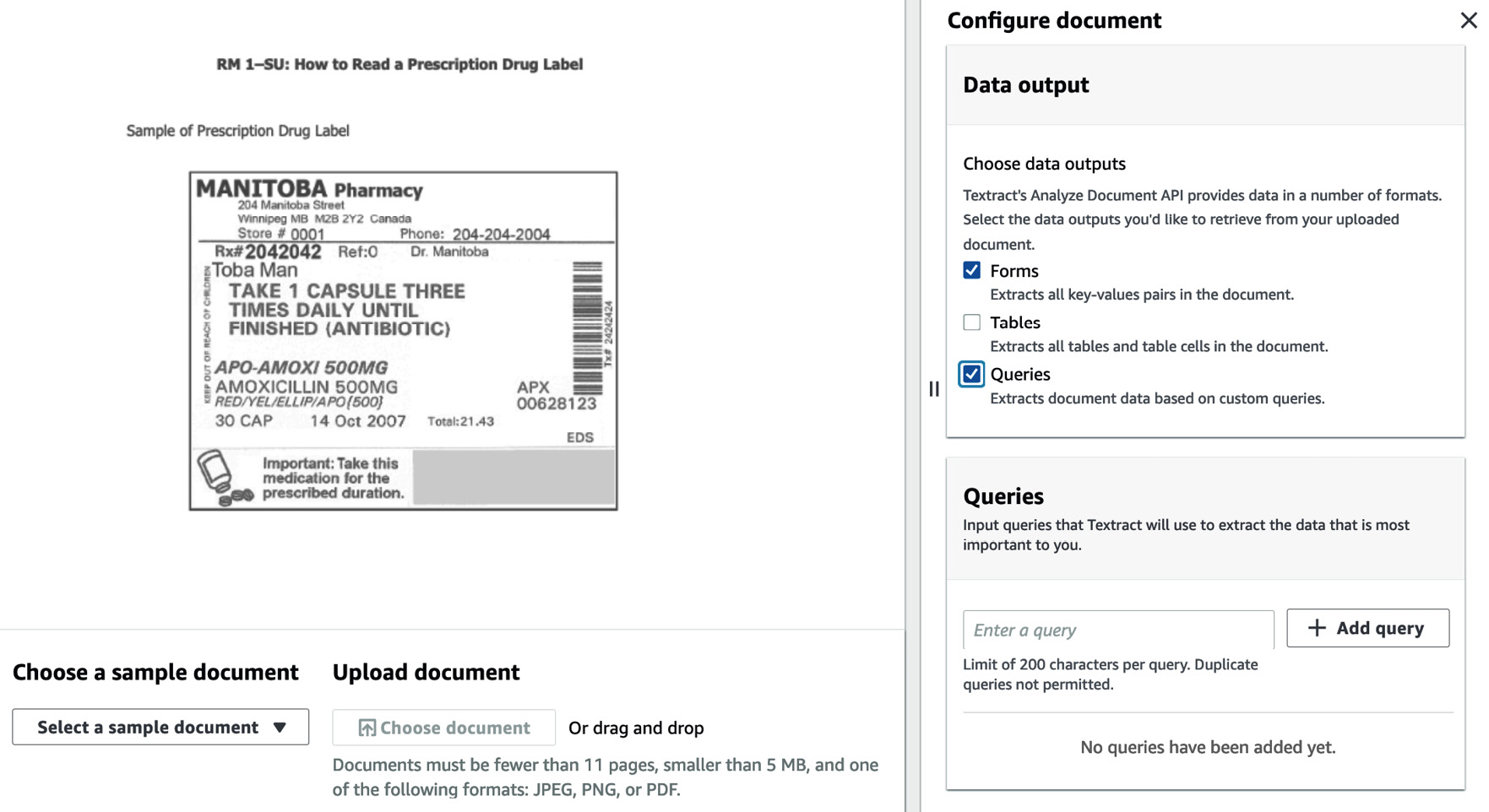
Figure 8.9 – Amazon Textract – Queries
Once you click Apply configuration, you can check the answers to our queries, as shown here:

Figure 8.10 – Textract Queries on the AWS Management Console
In the following screenshot, we ask questions, leveraging Textract’s Queries feature, about the physician’s name, the prescription number, and the main ingredient of the prescription, and gain responses:
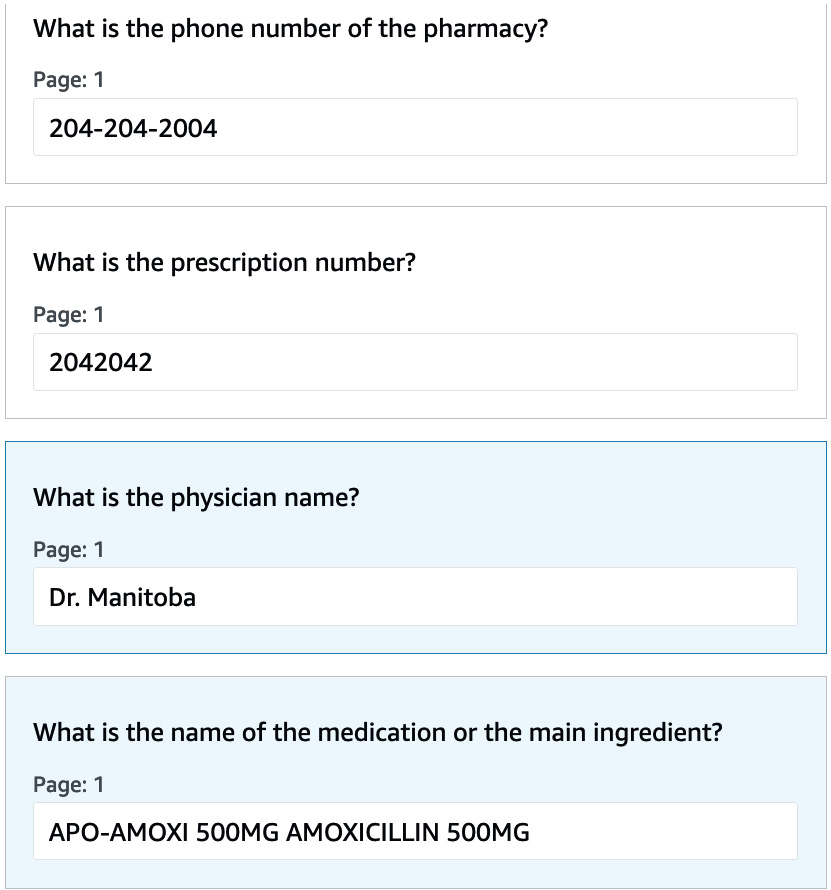
Figure 8.11– Additional Textract Queries responses on the AWS Management Console
In the following screenshot, we also ask questions, leveraging Textract Queries, about the date the prescription was filled, the dosage of the medication, and the directions to take it, and gain responses:

Figure 8.12 – An Amazon Textract Queries answer
We looked at how to leverage Textract Queries to extract information from a prescription document for drug refill. We will now run through the following sample code to automate the drug fill information from the prescription document programmatically.
You can have the full code walkthrough with the Notebook: https://github.com/PacktPublishing/Intelligent-Document-Processing-with-AWS-AI-ML-/blob/main/chapter-8/healthcare-08.ipynb:
- Import the required libraries to run the sample code for accurate extraction of the prescription:
import boto3
import json
import re
import io
from io import BytesIO
from pprint import pprint
from IPython.display import Image, display
from PIL import Image as PImage, ImageDraw
- Install the Textract response parser for an easier JSON response parse:
!pip install amazon-textract-response-parser
- We will use the prescription image from Figure 8.6. You can check the sample image with the following code:
from IPython.display import Image
image_filename = "prescription.png"
Image(filename=image_filename)
- Get the boto3 Textract client:
#create a Textract Client
textract = boto3.client('textract')
# Document
documentName = image_filename
- We will call the analyze_document API with the Textract FeatureTypes value as Queries and Forms. We will also pass in the required questions in QueriesConfig. For a full list of questions, check out the GitHub code:
response = None
with open(documentName, 'rb') as document:
imageBytes = bytearray(document.read())
# Call Textract
response = textract.analyze_document(
Document={'Bytes': imageBytes},
# new QUERIES Feature Type for Textract Queries
# We could add additional Feature Types like FORMS and/or TABLES
# FeatureTypes=["QUERIES", "FORMS", "TABLS"],
FeatureTypes=["QUERIES"],
QueriesConfig={
"Queries": [{
"Text": "What is the name of the pharmacy?",
"Alias": "PHARMACY_NAME"
},
{
"Text": "What is the address of the pharmacy?",
"Alias": "PHARMACY_ADDRESS"
},
{
"Text": "What is the store number of the pharmacy",
"Alias": "PHARMACY_STORE_NUM"
}
]
})
print(response)
- Now, we can see some sample extracted answers for our Textract Queries results:

Figure 8.13 – An Amazon Textract Queries response
We walked through some sample code to extract information from the prescription for automatic drug fill.
Understanding healthcare claims processing and risk adjustment with IDP
When a medical claim is submitted, the insurance provider (payer) must process the claim to determine their correct financial responsibility and that of the patient. The process is known as claims adjudication or claims processing. During this process, the claims go through various checks; one such check is coding-level validation. During this coding-level validation, we check for the accuracy of the medical diagnosis code. Most often, this step requires manual review by a medical professional. Can we automate this process by leveraging technology? The answer is yes.
We will use Amazon IDP for coding-level validation for accurate claims processing. For this exercise, we will use the CMS1500 claim form and also a doctor’s note. We will process these documents with Amazon Textract for the accurate extraction of elements along with the ICD-10-CM code. We will also process the doctor’s note to adhere to the ICD-10-CM code, and finally, we can check whether the code mentioned in the healthcare application form matches the code inferred from the doctor’s note. Now, let’s dive into the detailed implementation:
- We will use cms100-1.png as a sample document for this exercise. You can run the following code to check the sample image:
# Document
documentName = "cms1500-1.png"
display(Image(filename=documentName))
- Check the sample result of the CMS application form:

Figure 8.14 – The sample CMS1500 form
- We have defined a method name, calltextract, to call the Amazon Textract analyze_document method with RAW image bytes:
# process using image bytes
def calltextract(documentName):
client = boto3.client(service_name='textract',
region_name= 'us-east-1',
endpoint_url='https://textract.us-east-1.amazonaws.com')
with open(documentName, 'rb') as file:
img_test = file.read()
bytes_test = bytearray(img_test)
print('Image loaded', documentName)
# process using image bytes
response = client.analyze_document(Document={'Bytes': bytes_test}, FeatureTypes=['FORMS'])
return response
- Now, call the calltextract method defined in the preceding code block:
response= calltextract(documentName)
print(response)
- We have defined a method name, getformkeyvalue(), to extract key value information from the JSON response of Amazon Textract:
#Extract key values
# Iterate over elements in the document
from trp import Document
def getformkeyvalue(response):
doc = Document(response)
key_map = {}
for page in doc.pages:
# Print fields
for field in page.form.fields:
if field is None or field.key is None or field.value is None:
continue
key_map[field.key.text] = field.value.text
return key_map
- Now, call the getformkeyvalue method to parse the Textract JSON response to get all key-value pairs:
get_form_keys = getformkeyvalue(response)
print(get_form_keys)
- You can find the results of all the key-value pairs from the sample document of the CMS application form. Note that the ICD-10-CM code extracted from the application is K92.1:

Figure 8.15 – A sample Textract form response
- Now, we will process another document type, which is the doctor’s note. You can use the following code to check the image:
documentName = "doctornotes1.png"
display(Image(filename=documentName))
The following is a sample image of the RAW doctor’s note:

Figure 8.16 – A sample provider note
- We are calling into calltextract(), as defined in step 3 with the doctor’s note document type. We collected all the lines from the doctor’s note for further processing by Amazon Comprehend Medical:
response= calltextract(documentName)
# Print text
print(" Text ========")
text = ""
for item in response["Blocks"]:
if item["BlockType"] == "LINE":
print ('�33[94m' + item["Text"] + '�33[0m')
text = text + " " + item["Text"]
- We are creating a Boto3 comprehendmedical client and calling into the Comprehend Medical detect_entities API. We are passing in the Textract response in step 10 as input to this API. Amazon Comprehend Medical extracts all the medical entities from this document:
comprehend = boto3.client(service_name='comprehendmedical')
# Detect medical entities
cm_json_data = comprehend.detect_entities_v2(Text=text)
print(" Medical Entities ========")
for entity in cm_json_data["Entities"]:
print("- {}".format(entity["Text"]))
print (" Type: {}".format(entity["Type"]))
print (" Category: {}".format(entity["Category"]))
if(entity["Traits"]):
print(" Traits:")
for trait in entity["Traits"]:
print (" - {}".format(trait["Name"]))
print(" ")
- You can check out the Amazon Comprehend Medical-extracted entities from this provider note, as shown here:
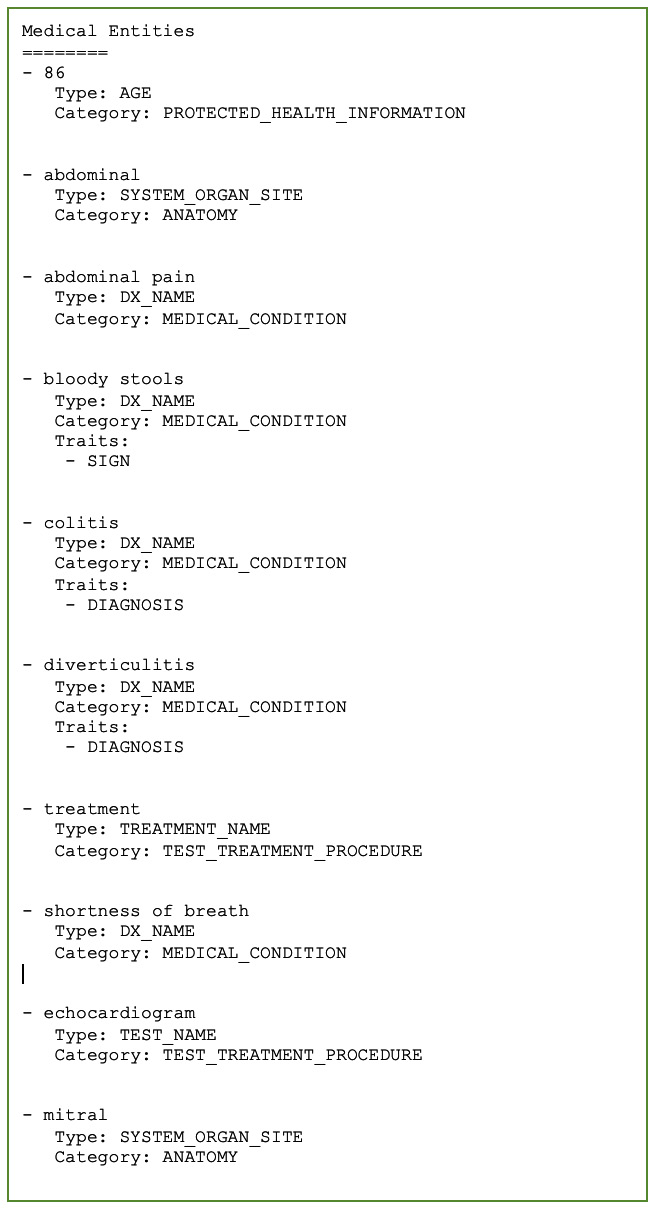
Figure 8.17 – An Amazon Comprehend Medical response
- We can leverage Amazon Comprehend Medical’s inferred _icd10_cm method to infer a possible ICD-10-CM code from the provider note. Amazon Comprehend Medical also gives a confidence score. We are using a confidence score threshold of 90% to filter the response:
cm_json_data = comprehend.infer_icd10_cm(Text=text)
print(" Medical coding ========")
for entity in cm_json_data["Entities"]:
for icd in entity["ICD10CMConcepts"]:
if (icd["Score"] >= 0.90):
code = icd["Code"]
print(code)
You can check out the extracted medical diagnosis code by Amazon Comprehend Medical here:

Figure 8.18 – Amazon Comprehend Medical coding
You can see from Amazon Comprehend Medical that one of the inferred ICD-10-M codes is K92.1, which matches the ICD-10-CM code mentioned in our CMS1500 application form. This can be used as a quick mechanism to validate medical code in claims processing use cases.
The inferred ICD-10-CM code can be further mapped to a Hierarchical Condition Category (HCC) code by taking into account additional demographic information. This can be useful in healthcare risk adjustment use cases.
Summary
In this chapter, we discussed the IDP pipeline and how this can apply to healthcare industry use cases, such as healthcare prior authorization, prescription automation, and healthcare claims processing with health risk adjustment.
We then dove deep into healthcare prior authorization use cases with a coverage requirement request and its reference architecture on AWS. We also discussed how to automate filling in a prior authorization form from a clinical data store. Moreover, we discussed how we can automate drug fill information by automating extraction from a prescription document. Finally, we looked at how to process a document for healthcare claims processing with a risk adjustment use case.
In the next chapter, we will extend IDP to additional industry use cases, such as insurance. Moreover, we will dive deep into insurance claims processing use cases and see how IDP can help to automate claims processing.