
Securing enterprise data can be a daunting task without knowing where the data is stored, processed, and how it is transmitted. Developing and enforcing a data classification model is a foundational component to securing enterprise data. This chapter will focus on the steps required to develop functional data classification and how to protect high-value data in the enterprise. Data discovery and protection tool types, placement, and implementation challenges for each will be presented. The emphasis is balancing the proper amount of protection and risk tolerance for access to enterprise data.
This chapter covers the following:
- Data identification and discovery
- Classifying enterprise data
- Data loss prevention methods and techniques
- Data protection methods and techniques such as encryption, hashing, and access controls
Data classification is a process where enterprise data is identified across the enterprise and it is given a classification that requires specific handling methods when interacting with the classified data. It is important that during the classification exercise data owners are assigned, enterprise criticality scored, and supporting processes developed to ensure confidentiality, availability, and integrity. The ultimate goal of the data classification exercise is to discover all enterprise data and protect or destroy it based on its importance and impact potential. Impact potential is of importance when considering the impact of enterprise data compromise, loss, and legal limits for data retention.
A common perception is that all enterprise data is both stored in a database or network system and the presence of such data stores is known. The reality is with the changes to the network edge presented in Chapter 1, Enterprise Security Overview and Chapter 2, Security Architectures, this is commonly not the case, as data resides in many unknown and unprotected locations.
To begin the process of identifying enterprise data, a simple exercise of understanding the types of data the enterprise uses to function as a business is a good start. Once this has been documented the next step will be to understand the locations in which the data resides, both inside the network and elsewhere. These steps will form the basis for a detailed data classification model and ultimately serve as input to data handling policies, standards, and guidelines. The classification must be easy to understand and allow for simple identification of the data types within the classification model to ensure the process is followed and enterprise data is handled in a secure manner.
There are many data types that may exist in order for the business to operationally function. Depending on the industry, the data may consist of patented and trademarked intellectual property, regulated data, or other categories of data that must be identified, accounted for, and protected in accordance with internal policies and external regulatory bodies, laws, and mandates.
A careful examination of the data types present in the enterprise will lead to required controls that must be implemented in technology and process, and these must be auditable. Each enterprise, regardless of the previously mentioned data types, will have some level of employee personal data (human resources), network diagrams, application architecture diagrams, and more data types that may not seem to be critical to the business, but certainly have a risk associated with their compromise or loss. It is not always cut and dry what data has the most significance until all business processes are known. Business processes should lead to all enterprise data types that are interacted with directly or indirectly through the various processes.
- Employee human resources data
- Company private data (business plans, acquisition strategies, brands, and so on)
- Company confidential data (locations, network diagrams, and so on)
- Company public data (product releases, press releases)
- Consumer data (PII, credit cards, and so on)
- Medical data (HIPAA regulated)
Data can be located in multiple places both internal and external to the enterprise network, including in employer-owned and employee-owned assets. This fact was presented in earlier chapters as a primary reason for the blurring of the enterprise network perimeter. The enterprise network edge has previously been emphasized as the primary data boundary because typically enterprise data would reside only within the network boundary defined by firewalls and other network equipment. Additionally, all enterprise data was intended to only reside on enterprise-owned assets. Because there has been a shift over time, due to data sharing requirements and convenience, data can reside literally anywhere.
An example is an employee making a decision to work on a task at home and uploading enterprise data to an online storage service or e-mailing the data to a personal e-mail account. It is understood that the employee is trying to be efficient and accomplish more work, but this simple act results in enterprise data residing on systems and in applications not owned or controlled by the enterprise.
Without technologies implemented to prevent this behavior and well-communicated policies, data locations will continue to be disparate and expose enterprise data to unnecessary and unexpected risk.
Typical data locations include:
- Network shares
- Document repositories
- File transfer systems
- Business partner and third-party systems
- Employer and employee laptops/desktops
- Employee-owned tablets/cell phones
- Employee/employer-owned portable storage (for example, USB drives)
- Online storage services
- Personal e-mail services
- Databases
- Backup media
- Replaced/failed system drives
Many of these data locations were presented in previous chapters and only represent the most common locations used by business users. Each enterprise should go through the exercise of identifying all the data locations within their network including approved and unapproved devices and services.
Third-party storage of enterprise data may require additional verbiage in business partner contracts, permitting the enterprise to require enforcement of protection mechanisms of enterprise data transmitted, processed, and stored by business partners and third parties. It is recommended that the enterprise perform a business partner risk assessment that would include data handling.
The discovered data locations will have more impact on the required data protection mechanisms than classification itself. Many of the data locations listed previously may not have a direct method to protect the data, so other methods will be required to ensure proper protection. This can be mapped directly to the classification model and may involve building new capabilities to enforce protection, preventing the underlying technology gaps from allowing unprotected interaction with the data.
The following diagram depicts the typical data interaction types of transmission, storage, and processing with pertinent data locations:
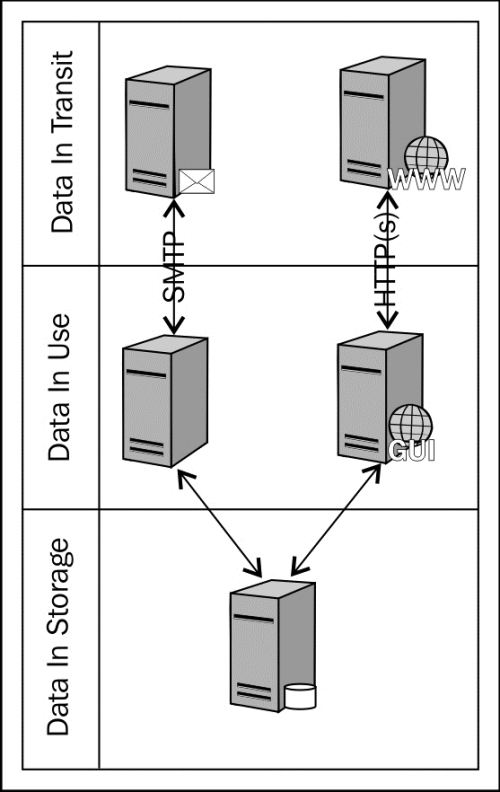
An example of a data interaction that may require additional protection methods is e-mail. Simple Mail Transfer Protocol (SMTP)—the protocol used for sending e-mail—is one example of an insecure method to transmit data, which requires additional protection for transmitting sensitive data. A tool that can provide encryption for e-mail is one option to provide protection over this medium. Additionally, the enterprise can make the decision to not allow e-mailing data that requires protection per a data classification policy. This method could be deemed as the protection mechanism, as long as it can be enforced.
Each one of these uses of data will have a unique set of challenges to provide the protection dictated by the classification model. A reasonable path to resolution is to first identify all data types and locations, gain an understanding of the technologies in use such as database types, and then determine the methods available for protection. Care must be taken to understand the total cost of ownership of any new feature or solution decided upon to provide the protection.
Reducing locations where protected data resides can reduce the complexity of implementing controls and reduce risk to the enterprise. After data is located it may be assessed that there are duplicate stores of data or that the data is no longer needed and can be removed from enterprise assets. This is a sound practice as it is a common method to reduce scope for compliance standards such as the Payment Card Industry Data Security Standard (PCI DSS).
Locating data can be a very involved and manual process without the use of tools specifically designed to "discover" data matching the unique criteria in an automated manner. As presented in the previous section there are multiple locations where data may reside, both in enterprise controlled and uncontrolled locations. Because data can be stored, processed, and transmitted, finding a tool that can detect pertinent data in these categories of use is essential to finding not only known data and processes, but unknown data types and processes that need to be understood, classified properly, and have associated controls implemented.
Discovering enterprise data within the controlled assets of the enterprise is much easier to accomplish than data discovery involving employee assets in an approved or unapproved implementation as observed in bring your own device (BYOD) scenarios. Detection at the network layer will be feasible but applying a mechanism to discover data residing on an employee or third-party asset becomes a challenge of privacy versus privilege to use the non-enterprise asset for business. To alleviate the concern in this scenario it may be wise to enforce a strict policy not allowing the use of non-enterprise assets to transmit, store, or process enterprise data. Another approach may be to leverage virtualization and allow access through secured virtual hosts. This allows interaction with enterprise assets and data through a strictly controlled environment and not directly by the non-enterprise employee asset.
The process of assigning data owners is essential and must be completed for classification efforts to be successful. Assigning data owners brings accountability and can take a lot of guesswork out of data discovery. If it is possible to assign data owners prior to data discovery, it may save time; it is common for data to be discovered first and then hunt for the data owner.
It will be imperative to get input from the data owners on the data their processes encompass and to understand what it is, who uses it, how is it used, and where it is located. Knowing these characteristics of the data will help classify it and ensure the correct protection mechanisms are implemented. Data owners may have to involve other teams to understand how the data is stored and transmitted. For example, if the data is stored in a database, the owner may need to contact the database administrator to gain understanding of how the data is stored, permissions on the database, and what protection is implemented.
The data owners will have a vested interest in the proper protection of the data for which they are responsible within the enterprise. For new business processes and data requirements, classifying data and assigning owners at the design stage will significantly reduce the efforts to protect data and reduce associated risks introduced with the project. This early involvement will increase buy-in and may lead to a better way of doing business. In some cases, the various data owners do not communicate with each other and are unaware of how their data may be used by other teams. This exercise may bring these disconnects to light and the overall data classification purpose to the forefront of how all data is handled, allowing less IT security policing and more cooperation from data owners.
Data classification is the act of assigning a label to identified data types that indicate required protection mechanisms, as driven by business risk and value. Data classification can be a simple chart or a complex solution that enforces data classification at its creation. Because data management has been mostly nonexistent, it may be difficult to implement a complex solution until other more simple processes are developed and implemented.
Once all data types have been identified, a simple table of the data types, along with the assigned classification and high-level protection, can be developed and communicated. Ideally, the table would have references to defined policies, standards, and procedures that provide a roadmap to proper use and protection of enterprise data. An example of a simple data classification model is shown as follows:
|
Restricted confidential(Level 1) |
Confidential(Level 2) |
Public(Level 3) | |
|---|---|---|---|
|
Data type |
Customer:
Employee:
Company:
|
Customer:
Employee:
Company:
|
|
|
Data protection |
Data encryption, hashing, or tokenization |
Restricted access permissions |
None |
After a classification model has been created, it has to be communicated and adopted by the entire enterprise, not just data owners and IT Security. It is good to have the data owners as the place where last checks occur and involve IT Security for guidance, but it is ultimately the responsibility of each person within the enterprise to protect enterprise data.
It is common for various departments within the enterprise to manage their own processes and interactions with third parties. In order to enforce data classification these various departments need to understand how their data is labeled in the classification model and at a minimum know where to go for help on how to implement protection mechanisms. It is understood that the marketing team or some other non-IT departments do not understand the nuts and bolts of data protection; the goal with the classification model is to cause enterprise users to think about the data they interact with and to question if they are handling it correctly. IT Security should always be accessible and their contact information readily available in the event their guidance is needed.
Typically, data classification fails due to lack of communication, users not understanding what data they are interacting with the data value to the enterprise, and the in ability to enforce. To get an understanding of how well data classification is understood, provide a survey to learn if user education is needed. If a process is not following the classification model, this is not a retaliatory opportunity but an educational opportunity. Proper communication of the data classification model and methods to ensure proper data handling will go a long way towards reducing the risk of data compromise and loss.