This chapter will guide the reader through the process of developing an enterprise monitoring strategy based on importance as determined by analyzing defined trust models. Examination of the critical data in the enterprise will help determine what should be monitored, who should monitored, and to what extent. Once a monitoring strategy has been developed and implemented, managing the data from disparate systems will be discussed using a Security Information and Event Management (SIEM) solution for event management, correlation, and alerting.
This chapter will cover the following topics:
- Monitoring based on trust models and network boundaries
- Privileged user monitoring
- Network security monitoring
- System monitoring
- Advanced monitoring tools
An enterprise that has matured into a security conscious organization with controlled data access and secured infrastructure driven by well-defined trust models will need to establish methods of monitoring assets and users. Traditional methods of monitoring are primarily driven by network boundaries defined logically and physically where networks of differing trust levels connect to each other. This paradigm of security trust levels is based more on control rather than data access, focusing the security monitoring only at these network boundaries. Unfortunately, the internal network is left insufficiently monitored for the most part regardless of who or what is accessing enterprise infrastructure.
In order to know what is happening on systems, the network, and who is accessing data, new monitoring strategies must be employed to detect and mitigate malicious and unintended behaviors.
A comprehensive monitoring approach may be overwhelming depending on the size of the network: servers, end user systems, applications, network equipment, and security mechanisms. There is the possibility of collecting too much data and essentially rendering the monitoring tools useless and ineffective. A systematic approach to developing the monitoring strategy is the key to implementing a usable and effective solution or set of solutions; solutions that provide the necessary data and intelligence to differentiate expected traffic patterns from abnormal patterns indicating a security incident is underway. The enterprise must agree on who and what is to be monitored and to what extent. A great place to start this analysis is the previously defined trust models that are built around data access and required security mechanisms.
While it is, and should remain a common practice to implement security monitoring at the network boundaries, there must be a method of validation for common threats typically observed at these control points. There is an expectation of detection and mitigation of attacks at the network boundaries via tools such as intrusion prevention and firewalls, but attacks that continue to be undetected to the intended target by these technologies must still be detected and/or mitigated at the host, application, or operating system. Not only is it necessary to have monitoring tools implemented, but also expertise is required to interpret the output and identify patterns in the output either manually or by an automated capability.
In the most likely implementation, security monitoring will be designed based on trust models, network boundaries, and network segments (unique environments within network boundaries). There are valid reasons to implement monitoring in this fashion as previously discussed. Applying new security architectures to existing environments will require transition phases and some "best practice" configurations will always remain. Firewalls, intrusion prevention, and web application firewalls may always reside at the network perimeters—both internal and external—as a first layer of defense mitigating the more common threats. Moving to a data-centric model for security is the necessary progression in order to maintain protection for data in the ever-changing physical environments. A combination of enterprise controlled environments and those not owned or controlled by the enterprise will be required.
Trust models are the basis for the security architecture presented in this book and the recommended foundation for enterprise security monitoring. Data-centric security and monitoring is the most effective, as it is specific to the data present and is as transient as the data itself. A matrix of data type trust models and required monitoring can be developed and re-used for each implementation of subsequent, same data types. This will ensure consistency no matter where the data resides, and is the best fit for enterprises leveraging cloud services and BYOD initiatives to reduce cost and increase the availability and resilience of critical systems, applications, and services.
Data criticality as defined by the enterprise trust models should be the primary dictator of the complexity of security monitoring required. This does not imply that no monitoring will exist for less critical data; but monitoring may be significantly more intricate with alerting and automated incident generation for critical data versus, for instance, a simple log entry at the application layer for non-critical business data. This is an oversimplified example, but there should be an exercise to determine required security monitoring for the defined data types that are input to the enterprise trust models.
The following table is an example of how the matrix may look for generic data sets with varying levels of criticality. It is important to note that risk may not play a significant role in developing security monitoring requirements; the criticality label implies risk.
|
Data set 1 |
Credit card numbers, SSN |
|
Criticality |
High |
|
Required security monitoring |
Data, Operating system, Application, Network, User |
While this table is a simple example, the details of how to monitor will be built out by the overall monitoring program and the selected methods to monitor at each tier of data access. The purpose of this exercise is to fully develop a data-centric security monitoring requirements matrix. The following sections are the monitoring points within the trust model that warrant further discussion and strategies to effectively monitor throughout the layers of the defined trust models.
Data, which is the center of our trust model, is the most valuable asset of the enterprise and where protection and monitoring should have the most focus. Access, modifications, additions, and deletions must be carefully controlled and monitored to detect intended and unintended actions taken on enterprise data. Tools such as file integrity monitoring can be leveraged to track all interactions with data in both structured (databases) and unstructured (documents, spreadsheets, and so on) formats.
A simple example of file integrity monitoring can be seen using the MD5 tool natively in Linux and Mac OS X. This tool performs a hash calculation on the file and provides an output. As long as this file is not changed, the MD5 output will remain unchanged. In the event that the file is modified, this MD5 hash will change. This is the principle used in file integrity monitoring solutions.
In the following screenshot, a secret file (secretfile) has been created with the text This is a secret file. inserted:

In the following lines, an MD5 hash is calculated for secretfile using the md5 command:
Macbook-pro$ md5 secretfile MD5 (secretfile) = 273cf6c54c2bdba56416942fbb5ec224
Now, the text in the file will be altered slightly and another MD5 hash performed:
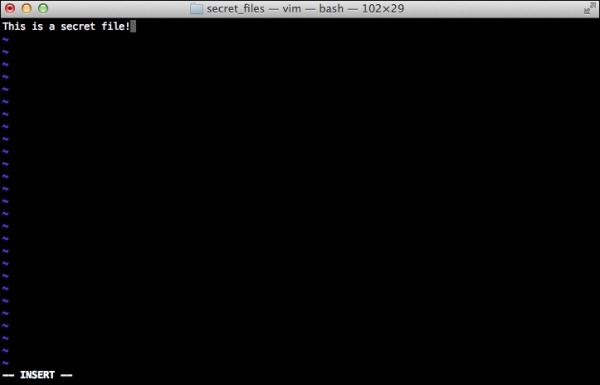
Macbook-pro$ md5 secretfile MD5 (secretfile) = f18c89748147fea87d3d8c7a4e0f4c93
A quick comparison of the before and after MD5 hashes indicates the file has been modified in some way from the original version.
- Initial file MD5:
273cf6c54c2bdba56416942fbb5ec224 - Modified file MD5:
f18c89748147fea87d3d8c7a4e0f4c93
Monitoring can also occur within systems where the data resides natively such as using database monitoring tools provided with the solution in addition to or disparately from third-party solutions. It is cautioned to rely solely on native tools that can be controlled by owners of the systems and may be a liability to the monitoring strategy.
The benefit of using a separate solution controlled by a third party within the enterprise such as IT security is the reduction in collusion and enforced separation of duties. Auditors of monitoring solutions will look for this to be the case to ensure that, for example, members of the database team are not in collusion with each other and making unapproved changes to data or inappropriately accessing the data residing on systems in their control.
Mature data monitoring solutions have the capability of not only detecting access and modification of data, but also determining by whom, allowing for a full audit trail of data activities. A process to analyze the data output from monitoring will need to be developed and tweaked as needed to maximize the benefit and adoption of the technology within the enterprise. Some solutions offer the option to auto-accept detected changes for the most common and insignificant changes. This is beneficial as the change is still captured but no human investigation is required unless there is a system incident.
Note
Data output from such tools can be significant and seem overwhelming. In order to minimize the amount of data, start with critical application directories and system files. The ability to decipher tools' output may be a collaboration between system administrators, application administrators, and IT security. As with any type of detection tool, fine-tuning is required to reduce the false positives and to capture the most significant and actionable data.
The primary attributes of data to monitor are:
- Timestamp (date and time).
- Who or what interacted with the data. This is captured by file metadata and other methods depending on the solution capabilities. Limit the integrity checks to the most significant files.
- What actions were taken on the data.
- Approval status for detected actions. It is recommended to have integration between change control systems and the file integrity monitoring solution for mapping of detected changes to approved changes.
These attributes should be captured within the solution; it is implied that any new detected actions will be considered unapproved until reviewed at which time the approval status can be updated accordingly unless automated. Essentially, the same fields are required for all technologies providing forensic data on detected events, and in common with intrusion prevention, firewalls, and logging. The data captured by such tools is a portion of the required information to form a complete picture of a security incident. It is essential to have the ability to reconstruct all activities involving data interaction for a complete data protection and monitoring program.
Enterprise processes are the reason for data creation, collection, and manipulation and many times actions occur in an automated fashion; the success and failure of these processes can be of significant impact to the enterprise. It is imperative to have complete and thorough monitoring of data processes for early detection of intended actions and anomalies that may be indicative of failure or malicious intent. On the other side of this is the monitoring of successful process runs and anomalies with successful access, indicative of malicious intent or erroneous process implementation and configuration.
All processes identified during the building of the trust models will need to be assessed for their level of criticality, based on type of data affected by the process and business criticality of the output of the process. Process monitoring, because it may be automated, will have different monitoring points than that of human-based data interaction. The trust level assigned to the process may determine the level and granularity of required monitoring.
Attributes of process monitoring are as follows:
- Timestamp (date and time)
- Process name
- Account the process runs on
- Success/failure
The exact attributes of a process to monitor are as unique as the process. The attributes that we presented are the recommended minimum attributes to monitor. There may also be a secondary process that validates data postprocessing and this may require more detailed monitoring attributes. Because automation is a significant portion of data processing, it is important to monitor access to the process itself and any configuration changes made to the process that may be indicative of planned, erroneous, or malicious changes. If the process is script based, a file integrity monitoring (FIM) solution can be used to monitor the script for changes; if it is job based, the monitoring may need to be configured on the system running the job and may be similar to application monitoring concept and configuration. The primary purpose of process monitoring is to ensure it is running as intended by data verification and there is no unintended modification to it, its function, and its intended output.
Application monitoring can be multifaceted depending on the environment the application resides in and access to varying data with varying levels of criticality. Each application in the enterprise will need to be defined per enterprise trust models and analyzed for unique attributes that need to be considered for monitoring. If the application has the capability to service authenticated and unauthenticated users, the monitoring strategy may differ depending on the authentication status of the application user. This is an attribute of applications in the e-commerce environments where the casual browsing client is not authenticated, but a customer with an account may login and have access to additional portions of the site with more application functions available.
An application needs to be monitored much like a process and supporting process scripts. An application serves as the interface between data and people so its functioning status is important to ensure critical business functions persist and customers and business users have the required access. In addition to the attributes monitored for processes, application availability must be monitored to meet service-level agreements and to reduce negative impact to the business. Application monitoring should be implemented for all business-critical applications. The extent of application monitoring will be determined by criticality and access level to sensitive data.
Attributes of application monitoring are as follows:
- Timestamp (data and time)
- Application name
- User authenticated/user unauthenticated
- Application up/down status
This can be achieved via multiple methods including application calls, application and system logs, and service TCP/UDP port checks. It is advisable to leverage a monitoring method that will provide the most accurate status. An example is a basic website. To ensure it is up, a simple probe of TCP port 80 could work; but what if the application was broken but the port was still listening? In this scenario, an HTTP GET of the website's main page would produce a better status than the simple port probe.
The example in the previous section describing a web application that supports unauthenticated and authenticated users will require monitoring of both, but the authenticated user will have access to more application functions. Additional monitoring of the authenticated user is required as they will have access to more data and data input functions of the application.
User monitoring is a requirement across all aspects of the trust models because users will interact with data, processes, and applications by various methods and an audit trail must exist for all actions. In the case of a web application, only the authenticated user has a name and other information; the browsing user is just an IP address and maybe a user-agent type in the logs. For internal applications with access to data, authentication is almost always going to be required; if it is not, then the application should be rewritten to enforce authentication to establish a reliable forensic audit trail.
User monitoring extends beyond applications to the network, systems, and data. All access in the just discussed scenarios must not only be monitored for audit trail purposes, but also for behaviors indicative of malicious intent, misuse, and erroneous configuration. Erroneous configuration may be the use of user credentials in scripts and other automation that is not generally a recommended behavior. In the case of detected user credentials in scripts, an alternative method such as public/private keys or a service account should be used for authentication. Data loss prevention tools can help detect this type of misconfiguration, both locally and as the credentials are passed over the network. This will also protect the user in the event that the credentials are compromised.
Attributes of user monitoring are as follows:
- Timestamp (data and time)
- User ID
- Actions
- Source and destination IP addresses
- Login and access attempt's success/failure
User monitoring at the network, system, and operating system level will produce unique pieces of data that when correlated create a complete picture of user actions. It is imperative to leverage user authentication where possible to ensure only authorized individuals are accessing enterprise assets.
Monitoring authenticated access can also detect possible credential misuse by an authorized individual or unauthorized use of credentials. Authentication provides non-repudiation for actions taken by a user and is a powerful and necessary protection for the enterprise in the event that malicious actions result in employee termination. Monitoring of user actions can also lead to discovering application configuration and design errors when actions detected are unintended and result in a success status from the application, but may lead to elevated privileges or erroneous access to sensitive data.
Without monitoring user actions, the enterprise will not truly know what user actions are being taken against its networks, systems, applications, processes, and data.
Security monitoring at the network boundary is a basic defense in depth tactic to mitigate the most common threats observed from low to high security network segments. The most common boundary is the enterprise Internet edge, and the best example of a low to high security network segmentation that should have monitoring in place for enterprise protection from the uncontrolled Internet. There are other network boundaries that may require monitoring such as business partner, subsidiary, virtual private network (VPN), and service provider connections. Each of these network boundaries connects a network uncontrolled by the enterprise to the enterprise network, and therefore the trust level is not as high as that of the internal trusted network. Because threats often come from other external networks, monitoring at these connections can provide valuable information about the security of the connecting network and allow the enterprise to implement the proper security mechanisms to protect enterprise assets and data.
Depending on the connecting network and the associated risks, the level of monitoring can be more or less complex. In the case of employee VPN from employer-owned devices that only allows connections with enterprise assets, the monitoring may be less than the business partner VPN, where the trust is less due to reduced or non-existent control over connecting networks and devices. In the case of BYOD, the VPN connection (if permitted) must be monitored as any other untrusted connection.
However there may be internal network boundaries wholly owned and controlled by the enterprise that, depending on the connecting segments, will require different monitoring approaches. Examples of internal boundaries are the boundary from the DMZ to the internal network and the internal network to a secure internal segment. Each of these may be treated as trusted, or the DMZ to internal may be treated as an external network and have monitoring like the Internet edge.
In order to ensure consistency, it is ideal to create labels for the boundary types defined by the enterprise and assign monitoring requirements accordingly. The following table is an example of assigning network boundary types a label and defining required security monitoring:
|
Network boundary type |
DMZ |
|
Trust level |
Low |
|
Required security monitoring |
Network, Operating system, Application |
In this previous example, the only variable being analyzed for trust is the network boundary and it is not user specific. Monitoring of users, applications, and operating systems should be implemented in scenarios especially when the user is simply known by IP address. Monitoring and mitigation may only occur using the network layer information of the transaction.
There are some network segments that have a higher value based on criticality to the business. These segments may require additional monitoring not only to adhere to regulatory compliance or other requirements, but also to ensure that the administrators, owners, and IT security are aware of what is happening in a particular segment of the network.
Each segment of the network should be assessed for value (typically determined by the assets located on the segment) to the business in order to determine the risk of negative impact to the segment, and thus the business. In order to identify segments of high value, use the discovered information from the trust model building exercises. This will primarily end up being a list of systems that may reside on various segments in the network both insecure and secured. There may be a decision to move a system or set of data to a protected segment during this analysis, in order to reduce the complexity of monitoring required for the identified segments. If providing a secured segment is not a priority, then developing a flexible monitoring strategy regardless of physical or logical location of the data and systems should become the focus; and this method of monitoring by segment should be abandoned.
All segments that are well defined should be labeled with a criticality level of low to critical. Required monitoring for each segment can be decided by using the scale of criticality. Building a matrix for monitoring will provide the standard for each segment providing a repeatable and consistent methodology.
The following table is a sample of what a matrix may look like for this type of exercise:
|
Segment name |
Criticality |
Required monitoring |
|---|---|---|
|
Segment_1 |
Low |
Network, Operating system |
|
Segment_2 |
Medium |
Network, Operating system, Application |
|
Segment_3 |
High |
Network, Operating system, Application, User |
|
Segment_4 |
Critical |
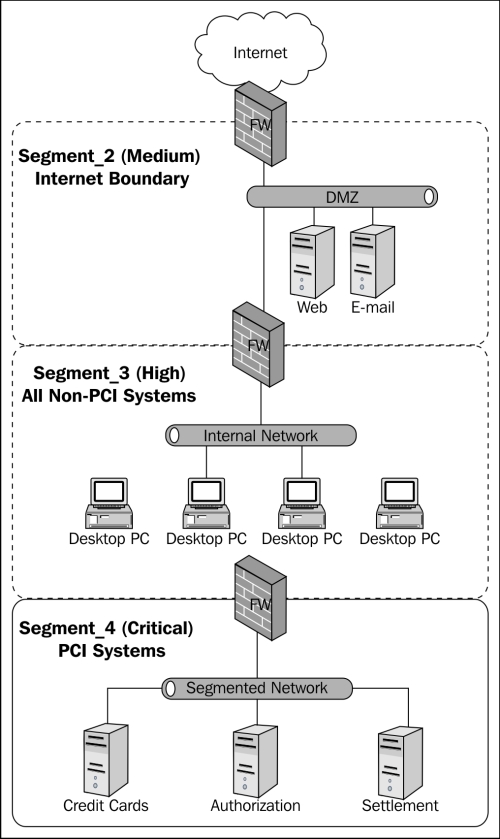
Network, Operating system, Application, User, Data |
Segments should be documented according to their purpose such as HR, PCI, e-mail, and so on, with all indications of naming, controls, and monitoring self-explanatory. It is advisable to leave publicly accessible segment information generic, but provide mapping in a protected manner to reduce confusion for internal IT. This method is only effective if the network has a clear demarcation of network segments where monitoring can be strategically located on the network and controlled. If the segments are not truly segmented, then data may be skewed with meaningless data from other segments. The following diagram is an example of an internally segmented network (Segment_4) for the purposes of PCI DSS scope reduction: