
The typical security architectures range from a generic layered approach, where only connected layers may communicate with each other, to complex source and destination zones, allowed protocols, and specific communication channels permitted per endpoint type to advanced models based on data risk. Data risk is comprised of understanding what data needs protection including from whom and what, based on loss probability.
The data-centric security architectures emphasize enterprise data, where it is stored, how it is transmitted, and the details of any data interaction. Once all pertinent enterprise data and associated systems are identified, the required security mechanisms can be designed and implemented. Placement of the systems may not be a concern if the security mechanisms are based on the risk profile built by the previously learned information. The next sections will cover how the components of the security architecture are developed.
In the previous chapter, we looked at a roadmap for securing the enterprise. To begin the process of properly securing the enterprise, a security architecture needs to be defined. The nature of architecture is principle based, therefore there is not a single one that fits into all security architecture concepts. Do not confuse architecture and design as they are fundamentally different disciplines. We have seen monumental shifts in how business is being conducted. The architecture(s) must consider these methods and be agile enough to provide security while enabling the business.
In order to sufficiently satisfy security interests and meet the needs of an ever-evolving enterprise, trust models need to be developed in such a way that they encompass all the interactions with the data they are designed to protect. It is important to note that the focus of a security architecture is not the network segment or the system; it is the data, which is the purpose for the network, and the system. As we look at the characteristics of the data access and determine who, what, why, and so on, patterns will emerge that will show the flexibility of a data-centric architecture versus the traditional network-based approach. We will then be able to drop a trust model on top of a network segment, system, and data type; do you see the pattern yet?
First, we will dive into defining each step in securing the enterprise roadmap presented in Chapter 1, Enterprise Security Overview. We will then present sample trust models that can be used as is or tailored to a specific situation. The next image depicts the determination of trust and hos risk dictates trust and trust influences policies and standards.
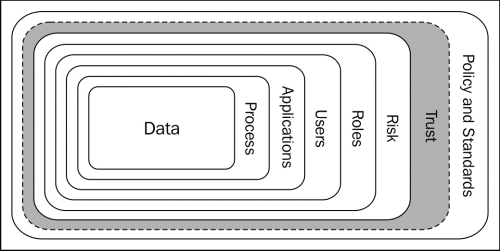
The typical security architecture will look at the data in the last step to decide how to securely provide access to it. This often occurs well after a significant investment has been made to enable the business function that requires data access. This is also where we see compromise of the intended security architecture, because security will have technically been an after thought.
The lack of flexibility offered by network-centric architecture is the Achilles heel of the model. An enterprise must understand what data exists, why the data exists, data sensitivity, and data criticality. This can all be assessed without thinking about the data location. Data is the "what" portion of the data interaction. If it is determined that the data or "what" being accessed has little value or risk associated with it, then security mechanisms may be reduced or become non-existent. Enterprise data may be processed, stored, and transmitted during its lifecycle. The following image is a simple depiction of typical enterprise data interactions:
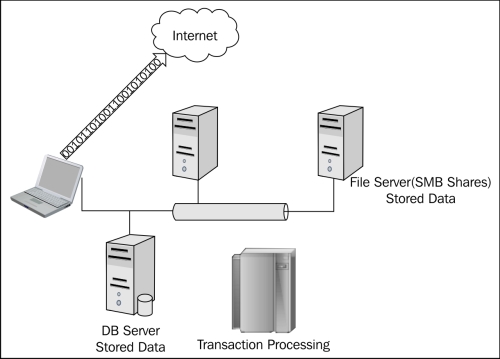
Typical locations of data can be determined by understanding business processes—another phase in the roadmap. But if they are not well defined, then an enterprise can begin by looking at databases and network shares for data at rest. This process should identify a majority of the enterprise data. Some applications may have a local database and this needs to be identified, but a few outliers will not impede proper data identification and classification to build the trust models.
During the discovery of enterprise data, be sure to include end-point devices to look for local database instances and data stored in typical desktop processing applications. Laptops are one location that has been a significant cause of data breaches, because critical and high-risk data was stored on a laptop with no protection, and was stolen.
Essentially, there are two states data can be: transient and stored. Transient data is the data that is processed by an application on a system and transmitted over a network. Stored data resides in a database or a network share for a period of time beyond a single transaction. Depending on the type of business, the industry vertical will directly relate to the expected data types. For instance, a clothing retailer will more than likely have credit card numbers as a form of data in both transient and stored network locations, whereas a technology firm may have patented trade secrets. Risk associated with the data types may come from business criticality (in relation to impact), regulatory compliance, and legal mandates. Once the risk is understood, appropriate security mechanisms can be implemented.
Typical data loss prevention solutions have data discovery capabilities. These tools can aid in the discovery of stored data across all enterprise systems. Data may be stored in text files, spreadsheets, log files, and databases, to name the most common file types. Similar tools exist to capture data in transit on the network, alerting security personnel when a triggered event has occurred.
|
Defining data types, value, and regulatory responsibilities per industry | ||||
|---|---|---|---|---|
|
Industry |
Data type |
Data purpose |
Data value |
Regulatory/legal responsibility |
|
Retail |
Credit card numbers |
Product sales |
High |
PCI |
|
Healthcare |
Patient information PII |
Patient care and billing |
High |
HIPAA |
|
Banking |
Credit card numbers PII |
Service Offerings |
High |
PCI, FTC, and SEC |
The preceding table gives examples of data types for common industries, including possible purposes of the data, perceived data value, applicable laws, and regulatory responsibilities for the data.
How does the enterprise conduct business? This will start the discovery necessary to understand the systems of highest criticality and require the most attention when it comes to securing the infrastructure. The previous section covered defining the enterprise data that needs protection. If the data is unknown, start with the current business processes; this should lead you to the most critical data. I highly recommend using a discovery tool to find data in storage, as the most sensitive data seems to find its way into the most insecure locations of the network.
A defined process may be the method to take an online payment for a product or service, or some other "method" used by the enterprise to conduct business. This is the "why" of the data interaction. Something as simple as an e-mail is also a process. The user uses an e-mail application to access messages, some containing attachments, which is all data.
Interviewing system and application owners is an affective method to identify business and technical processes, if not commonly known. Identification of data transfer systems such as, extract , transform , load (ETL), and Enterprise Information Integration (EII) are a good starting point for finding automation and critical business processes within the enterprise. Once processes have been identified, opportunities should be taken to correct any process that introduces risks to the enterprise, as processes are primarily data-centric with direct data access and manipulation capabilities.
Now that we have defined the enterprise data and processes, we need to define the applications that transmit, process, or store the defined data. As we build our definitions, we will begin to see the picture of "use and access", I sometimes call interactions, which will serve as our guide to determine the proper security mechanisms for implementation. Applications can literally be any application in the enterprise from e-mail clients to complex sales processing applications.
In a retail environment, the point of sale application would need to be defined as a method to interact with enterprise data, possibly used by a person or other automated methods, such as scripts. The methods in which the applications interact with the data become the factors defining users, roles, and ultimately the security mechanisms required.
In some cases, applications and protocols can represent the same thing as in the e-mail example. We are not looking to necessarily define the different e-mail clients that the user is running to access e-mails. Rather, POP3 and SMTP are the protocols leveraged to access the e-mails in the enterprise e-mail servers. The e-mail client in the previous scenario may come into play based on the features that define the enterprise data interaction by the user.
A user interacts with an application that has access to data; the user may be a person, script, system, or another application. Not all users will require the same level of access. It is critical to identify as many users as possible and also the types of interactions with the enterprise data that is required for each user. Users can be discovered by thoroughly defining the processes in the enterprise.
Assessing enterprise job functions, such as departmental affiliation, will help to define more granular groups. For instance, a user may be in the Information Technology department, and also a UNIX administrator within this department. This is not the same as defining a role, which is applying the user's interaction with enterprise's data for a specific purpose. If the UNIX administrator was to perform backups of data, this may be a role associated with this user for that specific set of data. What is to be accomplished at this stage is to know that the UNIX administrator exists.
There are also high-level distinctions for users such as:
- Internal (employee): This individual uses employee-owned equipment to interact with enterprise data. This may be blurred with a BYOD implementation; this will be addressed in the BYOD section.
- External (non-employee): This individual uses some non-enterprise system to interact with the enterprise applications and/or enterprise data.
- Business partner: A contractual relationship binds the enterprise and the business partner for the purposes of conducting business. Access to enterprise data may be significant to the business relationship and from systems not owned by the enterprise.
- Contractor: A person or business entity that is hired contractually to work for the enterprise in the capacity of an internal employee. They may use some combination of employee-owned assets, personal assets, or issued assets by their direct employer (contractor firm).
Each user type should influence at some level the trust applied to the interaction with enterprise data. This cannot be the primary factor but should be a good and generic indicator of trust on an objective scale from "no trust" to "trusted".
The outcome of this exercise will have significance when we begin the trust decision process for each high-level user type, taking into consideration the type of data and access level to the data. An enterprise may have as many user definitions as necessary to complete this exercise.
An important part of defining users is to identify the interactions that the users will have with the data including how the access will be facilitated—whether through an application, shell, script, or direct. This is where roles come into the picture and must be defined.
Using our example of the UNIX administrator, what does the user need access to, why is the access needed, and how is the access facilitated? We should know this information by now if we have properly defined the data, processes, applications, and users. If the role of the UNIX administrator is to simply perform system support and not interact with the data on the system, then it is possible to state that access to enterprise data must be denied and access attempts to the data should be monitored. This is a simple example of defining user roles based on information learned versus simply by departmental role. Interviewing users and teams may provide more information for granular role definition.
High-level user roles:
- Application user: Users of an application may input data, read data, and modify data through the application.
- Application owner: Responsible for the functional and operational aspects of the application, maybe coding the application if homegrown.
- System owner: Provides operation support for the underlying operating system and the hardware where the application and data reside.
- Data owner: Responsible for data input, read, modified, or processed by enterprise applications, systems, and users. The data owner may use the data for various functions or simply provide the data to other functions within or outside the enterprise.
- Automation: These include scripts and applications that run with no human interaction to process, transfer, and manipulate data for the purpose of business operations.
Each defined role may have requirements to interact with the same data, however, in differing methods. The roles listed are the most generic containers and common to most enterprises. Using these high-level roles is the starting point for defining user roles within your organization. I only caution you from creating too many user roles as this can lead to confusion, and more than likely the duplication of roles. If this is the case, reconsider making the role more generic to truly meet the needs of the enterprise.
The last components that must be defined are the policies that will guide a secure access and use of the enterprise data, and the standards that ensure a consistent application of policy. There typically are no lack of policies and standards in most enterprises, but the application and enforcement of both are the challenges that most enterprises fail. If there are no policies, the second component, standards, becomes what policies should we have been.
Fortunately, compliance bodies such as the PCI Council require the creation and implementation of a security policy, acceptable use policy, operational security policy, and so on. This can serve as a good place for the start of policy development. There are also other resources available on the Internet to help develop the relevant policies for your industry, see Appendix B, Risk Analysis, Policy and Standard, and System Hardening Resources, for further information.
Think of policies and standards as the law and enforcement of the security architecture. They may be written in response to a new business process or request, and are a requirement to communicate the security strategy and safe computing expectations to the employees, business partners, and anyone else doing business with the enterprise.
We have identified all the components that will help us define our trust models, which can be overlayed wherever necessary in the network—on systems, in the cloud, in applications, or anywhere applicable, as determined by the enterprise. Trust models may comprise more than the human element of data interaction as exhibited in the process definition section. Depending on the trust that is given to each combination of data, process, application, and user, determination of the required security mechanisms can be defined. It is important to understand this is not a simple trust/no trust approach. There are going to be degrees of trust depending not only on the user type, but also on the criticality of the data and associated risk. Another way to think of this is to assign allowed trust levels depending on roles. Any user type with a certain assigned trust level can access data according to the permissions associated with that assigned trust level. To make the determination manageable, it is recommended to use a small scale, such as 1 to 3—1 as not trusted, 2 as median trusted, and 3 as trusted.
We will cover the following trust models:
- Application user (external)
- Application owner (business partner)
- System owner (contractor)
- Data owner (internal)
- Automation (scripts, non-human interaction)
Let's build a table to correlate the data that we have gathered about the types of users that may exist along with the other building blocks of a trust model, such as data types, processes, applications, and roles. I will be using sample data, but you can input real data from your discovery exercises. The more time spent on these discovery and documentation exercises, the better developed and applicable the trust models will be for the enterprise. This can be repeated until an accurate representation of what exists is documented and understood. This should be an iterative process whenever a change occurs. I recommend running each new implementation through these exercises.
|
Sample trust model building blocks | |||||
|---|---|---|---|---|---|
|
Data |
Process |
Applications |
Users |
Roles |
Policies and standards |
|
Credit card numbers |
Application for a new service |
Web application |
External, non-employee |
Application user |
Acceptable use Secure access |
|
Credit card numbers |
Fraud detection |
Fraud software |
Business partner |
Application owner |
Data protection standard |
|
Credit card numbers |
Storage |
Database |
Contractor |
System owner |
Data protection standard |
|
Credit card numbers |
Loyalty tracking |
Business intelligence |
Internal, employee |
Data owner |
Data protection standard |
|
Credit card numbers |
Order processing |
Credit authorization and settlement |
Automation |
Automation |
Data protection standard |
Defining a trust model for an external user should focus on the fact that the enterprise does not know the security posture of the end system. Generally speaking, external users should be the least trusted. An enterprise is not for example responsible nor in the position to update the anti-virus signatures on the external system or make sure that the end system is patched. The point here is that the enterprise scope of responsibility starts wherever the end system is connecting to it. So, the level of trust should be none with the highest level of monitoring and protection implemented.
|
User type |
External |
|---|---|
|
Trust level |
|
|
Allowed access |
Tier 1 DMZ only, least privilege |
|
Required security mechanisms |
FW, IPS, and Web App Firewall |
In a scenario where a third party has access to a system on the internal network and the data it processes, there must be a level of trust. After all, the enterprise more than likely signed a business contract to enable this relationship. Because there is a mutual relationship in place, the enterprise has some level of influence for how the business partner is to interact with their systems and data. With a contract in place, there are legal protections provided for the enterprise.
|
User type |
External |
|---|---|
|
Trust level |
|
|
Allowed Access |
Tier 1 and 2, least privilege |
|
Required security mechanisms |
FW, IPS, Web App Firewall, and data loss prevention |
This scenario is similar to a business partner, however, the contractor may seem more like an employee because they reside on-site and perform the job functions of a full-time staff member. In this case, a contractor is the same as an associate; however, notice that the more access granted, the more security mechanisms must be in place to reduce the risk of elevated privileges.
|
User type |
External |
|---|---|
|
Trust level |
|
|
Allowed access |
Least privilege |
|
Required security mechanisms |
FW, IPS, Web App Firewall, and file integrity monitoring |
The data owner has a significant level of access to the enterprise data. As an internal employee, the trust level is 3—the most trusted. With this access level, there is great responsibility not only for the data owner, but also for the enterprise. If the data is decided to have little value, then the security mechanisms can be reduced.
|
User type |
External |
|---|---|
|
Trust Level |
|
|
Allowed access |
Anywhere, least privilege |
|
Required security mechanisms |
FW, IPS, and Web App Firewall depending on the type of data that is being interacted with |
Automation through scripts and applications are unique, since there is no human interaction. In this implementation, however, many times the permissions are incorrectly configured and allow scripts the ability to launch interactive logons, and shell access equivalent to a standard user. Another contributing factor to their uniqueness is if authentication is required the credentials are sometimes embedded in the script. These factors contribute to the trust level of the script and automation. Scripts can be trusted, but not like an internal user.
|
User Type |
Automation |
|---|---|
|
Trust level |
|
|
Allowed access |
Least privilege |
|
Required security mechanisms |
FW, IPS, Web App Firewall, file integrity monitoring, and data loss prevention depending on the data that is being interacted with |
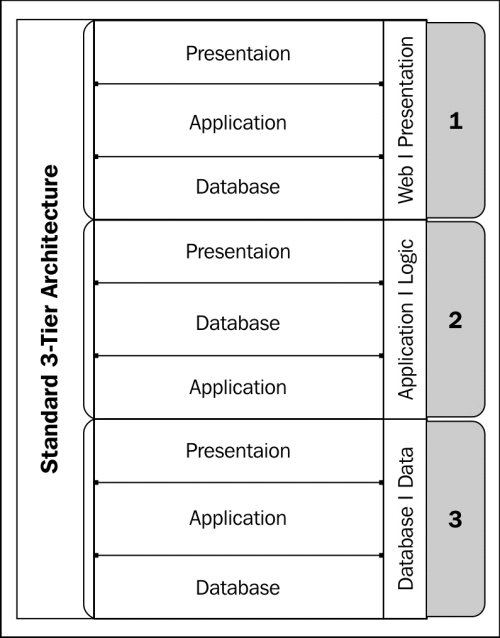
A micro architecture is architecture within architecture. An example may be the logical three-tier DMZ architecture implemented within a single layer of the standard three-tier architecture. This type of architecture is more network-centric, but can play a part in the overall data-centric security architecture of an enterprise.
This method may be used in a cloud-based solution, where an enterprise desires to maintain the three-tier approach, but the cloud solution itself is some shade of gray in the standard three-tier model. It is trusted, but coming from a semi-trusted source, traversing the untrusted Internet, possibly landing in the web/presentation layer of the enterprise DMZ. Micro architectures may reside on a single system, especially if we consider cloud-based virtualized solutions. A simple representation of a micro architecture is as follows:
Virtualization has had a unique effect on the security architecture implementation. In order to enforce the correct presentation, application, and database tiers, there should essentially be three distinct physical systems segmented by a firewall. Now, with the ability to host all three hosts on a single physical system, the lines of segmentation have been blurred. The segmentation happens at a lower physical hardware layer below the virtualized system's operating system, yet above the traditional physical network segmentation of network switches, routers, and firewalls. In some cases, the aforementioned segmentation cannot occur below the virtualized infrastructure. This limitation requires a separation of hardware and implementation of security appliances as separate virtual systems leveraging routing to force traffic through the required security mechanisms. This is suboptimal, as the cost benefits of virtualization cannot be realized if more physical systems need to be deployed for separation.
Another common use of micro architectures are in the DMZ, when there are collapsed tiers of the three-tier model. This may literally be implemented in a single system. The challenge then becomes properly segmenting the tiers, securing them, and limiting the scope of compromise. Feature-rich web applications are sometimes implemented in a collapsed-tier model to reduce system overhead and to increase performance.
I have already introduced the concept of risk as a key factor of any security architecture. Ultimately, systems and applications exist because there is data to be generated, processed, transmitted, and stored. The risk introduced in an enterprise is significantly data-driven. Therefore, we as security architects must consider this as the primary reason to implement a security solution. This does not mean that we only protect enterprise data; we still need to protect the network that makes data access possible.
What does data risk-centric mean? To answer this question, let's understand how a business functions and what information is used to make the business a business. If I were a retailer, then I have a product to sell, market to reach my buyers, and store customer data including credit card numbers. Of these items a few are data, and of these the most important would be top-secret marketing data and the customer data including credit card numbers. From the perspective of the security architecture, I need to focus on the data with the most risk to the business; meaning, if the data is lost, stolen, or manipulated, it would cause adverse implications for the enterprise. The risk could equate to fines, lost sales, marred reputation, or worse; business failure.
I presented trust models as a generic method of placing certain user types in buckets. These buckets should be further defined by a risk assessment. The risk rating for the data interaction should be based on the defined data, business value, regulatory compliance, user type, and user role. Understanding enterprise processes and applications will serve as a source of knowledge that can be leveraged to properly implement and maintain the security of the data and implementation.
Bring your own laptop, cell, and tablet are a few of the new initiatives that are throwing security teams for a loop on how to properly secure not only the device, but also the network it connects to and the data that it will have to access and possibly store. Thanks to the incredible marketing of manufacturers and decent functionality of the new portable consumer products, such as tablets, rapid consumerization of corporate networks is occurring at a faster rate than the time required to properly secure them. This model, being used by some enterprises to reduce the IT budget, has introduced some challenges not only to security but also to the legality of properly securing the devices while connected to the enterprise network.
Data access typically occurs through systems owned by the enterprise. Some of the data is day-to-day seemingly benign data, such as an e-mail discussing lunch plans. However, an e-mail can contain very important information in its body. We can also add attachments to an e-mail. Literally, any type of file can be attached to an e-mail, such as a customer list, compensation spreadsheets, acquisition documents, credit card numbers, and social security numbers. The use of non-employer assets changes the game when the data that is being interacted with has a real value.
A challenge faced with securing the "bring your gadgets" is that the enterprise does not own the endpoint, the phone, laptop, tablet, or whatever the end user has brought to work that day. The data that we allow the user to access must be protected, but where are the ownership lines drawn and how is protection enforced? There have been several security manufacturers developing products to "secure" these devices, but each seems to fall short of meeting acceptable enterprise security requirements, while allowing the functionality expected by the end user. Data is either intertwined with everything else on the device or is completely compartmentalized to the point of extremely limited use.
Let's look at some of the common BYOD initiatives and discuss considerations when applying trust models and to attempt securing the data accessed, transmitted, and stored on these consumer end points.
One of the first bring in your own plans was based on allowing the end user to bring their own cell phone. Of course, there are few plain cell phones; we also have smart phones with the ability to e-mail and manage calendars among other things. In fact, this was the first thing the end users started to configure, so everything could be managed and accessed from one device. The primary benefits for the enterprise are no more cell phone hardware expense and management, and policing to keep the bills reasonable.
It is hard to find a cell phone that is just a cell phone. Mostly, every brand and model available is a smartphone with significant processing capabilities. I know this seems like a known fact but I am emphasizing the need to treat the cell phone as a computing device that has an always on Internet connection through 3G, 4G, GSM, or wireless. Would you rethink connecting the device to the network if it did not have to traverse any of the implemented security mechanisms, such as proxy servers, Firewalls, data loss prevention, and intrusion prevention; probably not.
In most cases, cell phones just showed up at work as the cell phone owner learned about all the cool applications that could be used for work; they even figured out how to get the device on the network. The already strained security team in the typical enterprise environment did not anticipate this, so it went undetected. It is next to impossible to know what data the users are putting on the devices and what online services they are uploading enterprise data to without a management solution in place.
The security team must assess the capabilities and use cases for consumer technology products that are or can be connected to the network, and interact with data they must protect. A quick and easy fix is to throw a mobile device management solution at the problem; however, this does not address the security architecture that should serve as the framework for securing this access.
A common mobile device management (MDM) solution will generically solve the security issues of having a consumer, employee-owned device on the network. However, determining what exact data the device has access to will be up to you to solve. Keep in mind that some cell phone platforms require the devices and the MDM solution to communicate with their data centers. Let's take a look at a common MDM implementation:
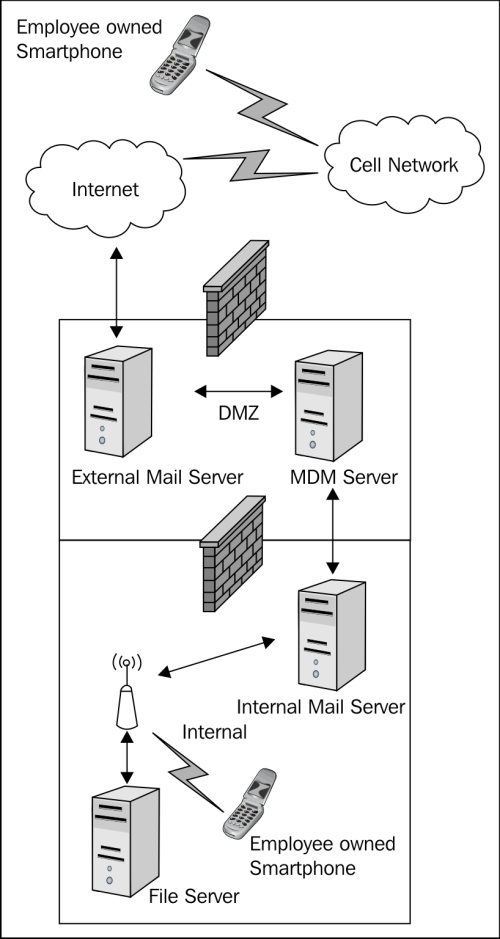
There are levels of application control and security policy that can be enforced with most MDM solutions. However, these are focused more on the device itself than the data the device is accessing. From a network perspective, this implementation is not a real deviation except for the fact that the smartphone can be dually connected to the cell network and the internal trusted wireless infrastructure. While on the internal wireless network, the smartphone would have access to any network asset available to an employer owned asset. The diagram depicts the most common feature requested, which is e-mail and calendar. Eventually, the end user will want to do more with enterprise data because there are several options for word processing and other business functions.
The enterprise will have to map the interaction to a defined trust model or develop one to meet this request. If the access is too risky, the enterprise needs to support the correct security posture based on the risk. I focused on the cell phone, but this will also cover tablets that are running the same operating systems as smartphones. The next section will cover "bring your own computer" type initiatives.
Bring your own PC is a slightly more complicated initiative to secure though still a BYOD initiative. Enterprises are realizing the tremendous cost savings of allowing employees to bring their laptops to work to perform their jobs. The issue with securing the devices and protecting the network are a challenge, because maintaining a device by the enterprise that is not owned by the enterprise may cross some privacy and/or technical boundaries. The lines of responsibility are easily blurred and many times not worth the idea.
In order to mitigate the obvious security issues, some enterprises are leveraging virtualization in a "trust no one" model where the only way to access anything is through a virtual desktop environment. This model is very secure, but comes at a cost to build a robust enough infrastructure to support.
Some enterprises are allowing employees to bring their own PCs to access enterprise assets, with no virtualization and balancing access with risk. This must be implemented very methodically with the utmost attention paid to the data interaction, to properly assign a realistic risk to the model, providing a trust model to which the policy can be applied. In this scenario, the best solution is to limit the access to all the data that has been assessed at a risk level of high and above, or to a level the enterprise's risk tolerance will allow.