
Chapter 5. Beyond basic in-memory queries
This chapter covers:
- LINQ to Objects common scenarios
- Dynamic queries
- Design patterns
- Performance considerations
After learning the basics of LINQ in part 1 of this book and gaining knowledge of in-memory LINQ queries in part 2, it’s time to have a break before discovering other LINQ variants. You’ve already learned a lot about LINQ queries and in particular about LINQ to Objects in chapter 4. You may think that this is enough to write efficient LINQ queries. Think again. LINQ is like an ocean where each variant is an island. We have taught you the rudiments of swimming, but you need to learn more before you can travel safely to all the islands. You know how to write a query, but do you know how to write an efficient query? In this chapter, we’ll expand on some of our earlier ideas to improve your skills of LINQ. We’re going to step back and look at how to make the most of what we’ve covered so far.
This chapter is important for anyone who plans on using LINQ. Most of what you’ll learn in this chapter applies not only to LINQ to Objects, but to other in-memory LINQ variants as well, such as LINQ to XML. One of our goals is to help you identify common scenarios for in-memory LINQ queries and provide you with ready-to-use solutions. Other goals are to introduce LINQ design patterns, expose best practices, and advise you on what to do and what to avoid in your day-to-day LINQ coding. We also want to address concerns you may have about the performance of in-memory queries.
Once you’ve read this chapter, you’ll be prepared to take the plunge into LINQ to SQL and LINQ to XML, which we’ll cover in detail in parts 3 and 4.
5.1. Common scenarios
We’re pretty sure that you’re eager to start using LINQ for real development now that you have some knowledge about it and have practiced with several examples. When you write LINQ code on your own, you’ll likely encounter some problems that weren’t covered in the usual examples. The short code samples used in the official documentation, on the Internet, or even in the previous chapters of this book focus on small tasks. They help you to get a grip on the technology but do not address everyday LINQ programming and the potential difficulties that come with it.
In this section, we show you some common scenarios for LINQ to Objects and provide solutions to get you up-to-speed faster with LINQ application programming. We start by showing how to query nongeneric collections. We then demonstrate how to group by multiple criteria in queries. We also give you an introduction to dynamic and parameterized queries. Finally, we finish the section with a demonstration of a fictitious flavor of LINQ named LINQ to Text Files, which shows how LINQ to Objects is powerful enough to work with many data sources without needing a specific flavor for each kind of data source.
5.1.1. Querying nongeneric collections
If you’ve read the preceding chapters attentively, you should now be able to query in-memory collections with LINQ to Objects. There is one problem, though. You may think you know how to query collections, but in reality you only know how to query some collections. The problem comes from the fact that LINQ to Objects was designed to query generic collections that implement the System.Collections.Generic.IEnumerable<T> interface. Don’t get us wrong: most collections implement IEnumerable<T> in the .NET Framework. This includes the major collections such as the System.Collections.Generic.List<T> class, arrays, dictionaries, and queues. The problem is that IEnumerable<T> is a generic interface, and not all classes are generic.
Generics have been available since .NET 2.0, but are still not adopted yet by everyone.[1] Moreover, even if you use generics in your own code, you may have to deal with legacy code that isn’t based on generics. For example, the most commonly used collection in .NET before the arrival of generics was the System.Collections.ArrayList data structure. An ArrayList is a nongeneric collection that contains a list of untyped objects and does not implement IEnumerable<T>. Does this mean that you can’t use LINQ with ArrayLists?
1 Those heathens!
If you try to use the query in listing 5.1, you’ll get a compile-time error because the type of the books ![]() variable is not supported:
variable is not supported:
Listing 5.1. Trying to query an ArrayList using LINQ to Objects directly fails

It would be too bad if we couldn’t use LINQ with ArrayLists or other nongeneric collections. As you can guess, there is a solution. Nongeneric collections aren’t a big problem with LINQ once you know the trick.
Suppose that you get results from a method that returns a nongeneric collection, such as an ArrayList object. What you need to query a collection with LINQ is something that implements IEnumerable<T>. The trick is to use the Cast operator, which gives you just that: Cast takes a nongeneric IEnumerable and gives you back a generic IEnumerable<T>. The Cast operator can be used each time you need to bridge between nongeneric collections and the standard query operators.
Listing 5.2 demonstrates how to use Cast to convert an ArrayList into a generic enumeration that can be queried using LINQ to Objects.
Listing 5.2. Querying an ArrayList is possible thanks to the Cast query operator
ArrayList books = GetArrayList();
var query =
from book in books.Cast<Book>()
where book.PageCount > 150
select new { book.Title, book.Publisher.Name };
dataGridView.DataSource = query.ToList();
Notice how simply applying the Cast operator to an ArrayList allows us to integrate it in a LINQ query! The Cast operator casts the elements of a source sequence to a given type. Here is the signature of the Cast operator:
public static IEnumerable<T> Cast<T>(this IEnumerable source)
This operator works by allocating and returning an enumerable object that captures the source argument. When the object returned by Cast is enumerated, it iterates the source sequence and yields each element cast to type T. An InvalidCastException is thrown if an element in the sequence cannot be cast to type T.
Note
In the case of value types, a null value in the sequence causes a NullReferenceException. In the case of reference types, a null value is cast without error as a null reference of the target type.
It’s interesting to note that thanks to a feature of query expressions, the code of our last example can be simplified. We don’t need to explicitly invoke the Cast operator! In a C# query expression, an explicitly typed iteration variable translates to an invocation of Cast. Our query can be formulated without Cast by explicitly declaring the book iteration variable as a Book. Listing 5.3 is equivalent to listing 5.2, but shorter.
Listing 5.3. Querying an ArrayList is possible thanks to type declarations in query expressions
var query =
from Book book in books
where book.PageCount > 150
select new { book.Title, book.Publisher.Name };
The same technique can be used to work with DataSet objects. For instance, here is how you can query the rows of a DataTable using a query expression:
from DataRow row in myDataTable.Rows where (String)row[0] == "LINQ" select row
Note
You’ll see in our bonus chapter how LINQ to DataSet offers an alternative for querying DataSets and DataTables.
As an alternative to the Cast operator, you can also use the OfType operator. The difference is that OfType only returns objects from a source collection that are of a certain type. For example, if you have an ArrayList that contains Book and Publisher objects, calling theArrayList.OfType<Book>() returns only the instances of Book from the ArrayList.
As time goes by, you’re likely to encounter nongeneric collections less and less because generic collections offer type checking and improved performance. But until then, if you want to apply your LINQ expertise to all collections including nongeneric ones, the Cast and OfType operators and explicitly typed from iteration variables are your friends!
Querying nongeneric collections was the first common scenario we wanted to show you. We’ll now introduce a completely different scenario that consists of grouping query results by composite keys. Although grouping by multiple criteria seems like a pretty simple task, the lack of a dedicated syntax for this in query expressions does not make how to do it obvious.
5.1.2. Grouping by multiple criteria
When we introduced grouping in chapter 4, we grouped results by a single property, as in the following query:
var query = from book in SampleData.Books group book by book.Publisher;
Here we group books by publisher. But what if you need to group by multiple criteria? Let’s say that you want to group by publisher and subject, for example. If you try to adapt the query to do this, you may be disappointed to find that the LINQ query expression syntax does not accept multiple criteria in a group clause, nor does it accept multiple group clauses in a query.
The following queries are not valid, for example:
var query1 = from book in SampleData.Books group book by book.Publisher, book.Subject; var query2 = from book in SampleData.Books group book by book.Publisher group book by book.Subject;
This doesn’t mean that it’s impossible to perform grouping by multiple criteria in a query expression. The trick is to use an anonymous type to specify the members on which to perform the grouping. We know this may sound difficult and several options are possible, so we’ll break it down into small examples.
Let’s consider that you want to group by publisher and subject. This would produce the following results for our sample data:
Publisher=FunBooks Subject=Software development Books: Title=Funny Stories PublicationDate=10/11/2004... Publisher=Joe Publishing Subject=Software development Books: Title=LINQ rules PublicationDate=02/09/2007... Books: Title=C# on Rails PublicationDate=01/04/2007... Publisher=Joe Publishing Subject=Science fiction Books: Title=All your base are belong to us PublicationDate=05/05/2006... Publisher=FunBooks Subject=Novel Books: Title=Bonjour mon Amour PublicationDate=18/02/1973...
To achieve this result, your group clause needs to contain an anonymous type that combines the Publisher and Subject properties of a Book object. In listing 5.4, we use a composite key instead of a simple key.
Listing 5.4. Grouping books by publisher and subject
var query =
from book in SampleData.Books
group book by new { book.Publisher, book.Subject };
This query results in a collection of groupings. Each grouping contains a key (an instance of the anonymous type) and an enumeration of books matching the key.
In order to produce a more meaningful result similar to the one we showed earlier, you can improve the query by adding a select clause, as in listing 5.5.
Listing 5.5. Using the into keyword in a group by clause

The into keyword ![]() is introduced to provide a variable we can use in select
is introduced to provide a variable we can use in select ![]() or other subsequent clauses. The grouping variable
or other subsequent clauses. The grouping variable ![]() we declare after into contains the key of the grouping, which is accessible through its Key property
we declare after into contains the key of the grouping, which is accessible through its Key property ![]() , as well as the elements in the grouping. The key represents the thing that we group on. The elements of each grouping can
be retrieved by enumerating the grouping variable
, as well as the elements in the grouping. The key represents the thing that we group on. The elements of each grouping can
be retrieved by enumerating the grouping variable ![]() , which implements IEnumerable<T>, where T is the type of what is specified immediately after the group keyword. Here, grouping is an enumeration of Book objects. Note that the grouping variable can be named differently if you prefer.
, which implements IEnumerable<T>, where T is the type of what is specified immediately after the group keyword. Here, grouping is an enumeration of Book objects. Note that the grouping variable can be named differently if you prefer.
To display the results, you can use the ObjectDumper class again:
ObjectDumper.Write(query, 1);
Reminder
ObjectDumper is a utility class we already used in several places, like in chapters 2 and 4. It’s provided by Microsoft as part of the LINQ code samples. You’ll be able to find it in the downloadable source code that comes with this book.
The result elements of a grouping do not need to be of the same type as the source’s elements. For example, you may wish to retrieve only the title of each book instead of a complete Book object. In this case, you would adapt the query as in listing 5.6.
Listing 5.6. Query that groups book titles, and not book objects, by publisher and subject
var query =
from book in SampleData.Books
group book.Title by new { book.Publisher, book.Subject }
into grouping
select new {
Publisher = grouping.Key.Publisher.Name,
Subject = grouping.Key.Subject.Name,
Titles = grouping
};
To go further, you may use an anonymous type to specify the shape of the resulting elements. In the following query, we specify that we want to retrieve the title and publisher name for each book in grouping by subject:
var query =
from book in SampleData.Books
group new { book.Title, book.Publisher.Name } by book.Subject
into grouping
select new {Subject=grouping.Key.Name, Books=grouping };
In this query, we use only the subject as the key for the grouping for the sake of simplicity, but you could use an anonymous type as in the previous query if you wish.
Note
Anonymous types can be used as composite keys in other query clauses, too, such as join and orderby.
Are you ready for another scenario? The next common scenario we’d like to address covers dynamic queries. You may wonder what we mean by this. This is something you’ll want to use when queries depend on the user’s input or other factors. We’ll show you how to create dynamic queries by parameterizing and customizing them programmatically.
5.1.3. Dynamic queries
There is something that may be worrisome when you start working with LINQ. Your first queries, at least the examples you can see everywhere, seem very static.
Let’s look at a typical query:
from book in books where book.Title = "LINQ in Action" select book.Publisher
This construct may give you the impression that a LINQ query can only be used for a specific search. In this section, we show you that the title used for the condition can be parameterized, and even further than that, the whole where clause can be specified or even omitted dynamically. We’ll show you that a query is not static at all and can be parameterized, enriched, or customized in several ways.
Let’s start by seeing how to change the value of a criterion in a LINQ to Objects query.
Parameterized query
If you remember what we demonstrated in chapter 3 when we introduced deferred query execution, you already know that a given query can be reused several times but produce different results each time. The trick we used in that chapter is changing the source sequence the query operates on between executions. It’s like using a cookie recipe but substituting some of the ingredients. Do you want pecans or walnuts? Another solution to get different results from a query is to change the value of some criteria used in the query. After all, you have the right to add more chocolate chips to your cookies!
Let’s consider a simple example. In the following query, a where clause is used to filter books by their number of pages:
int minPageCount = 200; var books = from book in SampleData.Books where book.PageCount >= minPageCount select book;
The criterion used in the where clause of this query is based on a variable named minPageCount. Changing the value of the minPageCount variable affects the results of the query. Your small “My top 50 cookie recipes” book and its 100 pages won’t appear in here.
In listing 5.7, when we change the value of minPageCount from 200 to 50 and execute the query a second time, the result sequence contains five books instead of three:
Listing 5.7. Using a local variable to make a query dynamic

Note
Applying the Count operator to the query contained in the books variable executes the query immediately. Count completely enumerates the query it’s invoked on in order to determine the number of elements.
This technique may not seem very advanced, but it’s good to remember that it’s possible and provide an example to demonstrate how to use it. Such small tricks are useful when using LINQ queries.
Let’s consider a variant of this technique. Often you’ll use queries in a method with parameters. If you use the method parameters in the query, they impact the results of the query.
The method in listing 5.8 reuses the same technique as in our last example, but this time a parameter is used to specify the minimum number of pages.
Listing 5.8. Using a method parameter to make a query dynamic
void ParameterizedQuery(int minPageCount)
{
var books =
from book in SampleData.Books
where book.PageCount >= minPageCount
select book;
Console.WriteLine("Books with at least {0} pages: {1}",
minPageCount, books.Count());
}
This technique is very common. It’s the first solution you can use to introduce some dynamism in LINQ queries. Other techniques can be used also. For example, we’ll now show you how to change the sort order used in a query.
Custom sort
Sorting the results of a query based on the user’s preference is another common scenario where dynamic queries can help. In a query, the sort order can be specified using an orderby clause or with an explicit call to the OrderBy operator. Here is a query expression that sorts books by title:
from book in SampleData.Books orderby book.Title select book.Title;
Here is the equivalent query written using the method syntax:
SampleData.Books .Orderby(book => book.Title) .Select(book => book.Title);
The problem with these queries is that the sorting order is hard-coded: the results of such queries will always be ordered by titles. What if we wish to specify the order dynamically?
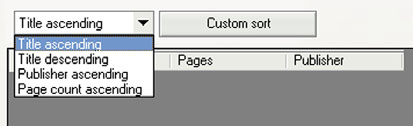
Suppose you’re creating an application where you wish to let the user decide how books are sorted. The user interface may look like figure 5.1.
Figure 5.1. A user interface that allows the user to choose the sort order he wants to see applied to a list of books
You can implement a method that accepts a sort key selector delegate as a parameter. This parameter can then be used in the call to the OrderBy operator. Here is the signature of the OrderBy operator:
OrderedSequence<TElement> OrderBy<TElement, TKey>( this IEnumerable<TElement> source, Func<TElement, TKey> keySelector)
This shows that the type of the delegate you need to provide to OrderBy is Func<TElement, TKey>. In our case, the source is a sequence of Book objects, so TElement is the Book class. The key is selected dynamically and can be a string (for the Title property for example) or an integer (for the PageCount property). In order to support both kinds of keys, you can use a generic method, where TKey is a type parameter.
Listing 5.9 shows how you can write a method that takes a sort key selector as an argument.
Listing 5.9. Method that uses a parameter to enable custom sorting
void CustomSort<TKey>(Func<Book, TKey> selector)
{
var books = SampleData.Books.OrderBy(selector);
ObjectDumper.Write(books);
}
The method can also be written using a query expression, as in listing 5.10.
Listing 5.10. Method that uses a parameter in a query expression to enable custom sorting
void CustomSort<TKey>(Func<Book, TKey> selector)
{
var books =
from book in SampleData.Books
orderby selector(book)
select book;
ObjectDumper.Write(books);
}
This method can be used as follows:
CustomSort(book => book.Title);
or
CustomSort(book => book.Publisher.Name);
One problem is that this code does not allow sorting in descending order. In order to support descending order, the CustomSort method needs to be adapted as shown in listing 5.11.
Listing 5.11. Method that uses a parameter to enable custom sorting in ascending or descending order
void CustomSort<TKey>(Func<Book, TKey> selector, Boolean ascending)
{
IEnumerable<Book> books = SampleData.Books;
books = ascending ? books.OrderBy(selector)
: books.OrderByDescending(selector);
ObjectDumper.Write(books);
}
This time, the method can be written only using explicit calls to the operators. The query expression cannot include the test on the ascending parameter because it needs a static orderby clause.
The additional ascending parameter allows us to choose between the OrderBy and OrderByDescending operators. It then becomes possible to use the following call to sort using a descending order instead of the default ascending order:
CustomSort(book => book.Title, false);
Finally, we have a complete version of the CustomSort method that uses a dynamic query to allow you to address our common scenario. All you have to do is use a switch statement to take into account the user’s choice for the sort order, as in listing 5.12.
Listing 5.12. Switch statement used to choose between several custom sorts
switch (cbxSortOrder.SelectedIndex)
{
case 0:
CustomSort(book => book.Title);
break;
case 1:
CustomSort(book => book.Title, false);
break;
case 2:
CustomSort(book => book.Publisher.Name);
break;
case 3:
CustomSort(book => book.PageCount);
break;
}
This produces the display shown in figure 5.2 for an ascending sort by title.
Figure 5.2. Books sorted by title in ascending order according to the user’s choice of a sort order
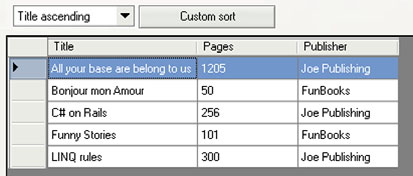
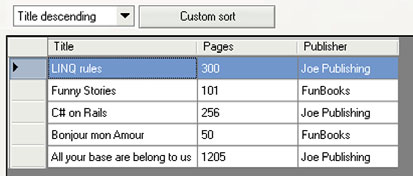
Figure 5.3 shows the display for a descending sort by title.
Figure 5.3. Books sorted by title in descending order according to the user’s choice of a sort order
After showing you how to parameterize the condition of a query’s where clause and use a dynamic sort order, we’d like to show you a more advanced scenario. This new example will demonstrate how to dynamically define a query, including or excluding clauses and operators depending on the context. This is something you’d want to achieve often, so queries can take into account the application’s context, settings, or the user’s input.
Conditionally building queries
The previous examples showed how to customize queries by changing the values they use as well as the sort order. A new example will show you how to add criteria and operators to a query dynamically. This technique allows us to shape queries based on user input, for example.
Let’s consider a common scenario. In most applications, data isn’t presented to the user directly as is. After being extracted from a database, an XML document, or another data source, the data is filtered, sorted, formatted, and so on. This is where LINQ is of great help. LINQ queries allow us to perform all these data manipulation operations with a nice declarative syntax. Most of the time, the data is filtered and dynamically shaped based on what the user specifies.
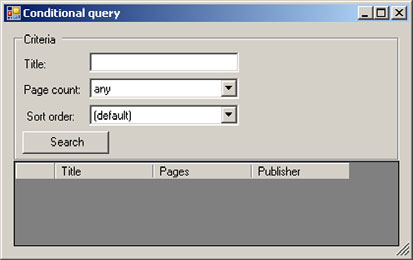
As an example, a typical search screen consists of an area where the user can input a set of criteria, combined with a grid or another list control that displays the results. Figure 5.4 shows such a screen.
Figure 5.4. A typical search screen with a criteria area used to filter books by page count and title, and to specify the results’ sort order
This is the dialog window we’ll use for our example. In order to take the user’s criteria into account, we can write a simple query that looks like listing 5.13.
Listing 5.13. Building a conditional query based on user input

For code reusability and clarity, it’s better to refactor the code to move this query to a dedicated method, as in listing 5.14.
Listing 5.14. Dynamic query refactored into a method
void ConditionalQuery<TSortKey>(
int minPageCount, String titleFilter,
Func<Book, TSortKey> sortSelector)
{
var query =
SampleData.Books
.Where(book => book.PageCount >= minPageCount.Value)
.Where(book => book.Title.Contains(titleFilter))
.OrderBy(sortSelector)
.Select(
book => new { book.Title,
book.PageCount,
Publisher=book.Publisher.Name });
dataGridView1.DataSource = query.ToList();
}
Here we use the explicit method syntax instead of a query expression because it will make the transition to the next version of the code. This method can be called using the code in listing 5.15.
Listing 5.15. Invoking the ConditionalQuery method according to user input
int? minPageCount;
string titleFilter;
minPageCount = (int?)cbxPageCount.SelectedValue;
titleFilter = txtTitleFilter.Text;
if (cbxSortOrder2.SelectedIndex == 1)
{
ConditionalQuery(minPageCount, titleFilter,
book => book.Title);
}
else if (cbxSortOrder2.SelectedIndex == 2)
{
ConditionalQuery(minPageCount, titleFilter,
book => book.Publisher.Name);
}
else if (cbxSortOrder2.SelectedIndex == 3)
{
ConditionalQuery(minPageCount, titleFilter,
book => book.PageCount);
}
else
{
ConditionalQuery<Object>(minPageCount, titleFilter, null);
}
This is all fine, but our example is not complete. We don’t have the flexible query we promised! In fact, we have a small problem. What will happen if the user doesn’t provide values for all the criteria? We won’t get the correct results, because the method was not created to handle blank values.
We need to take this into account and test whether we have values for the criteria. When there is no value for a criterion, we simply exclude the corresponding clause from the query. In fact, if you look at the new version of our method in listing 5.16, you’ll notice that we create the query on the fly by adding clauses one after another.
Listing 5.16. Complete version of the ConditionalQuery method that tests for the provided criteria
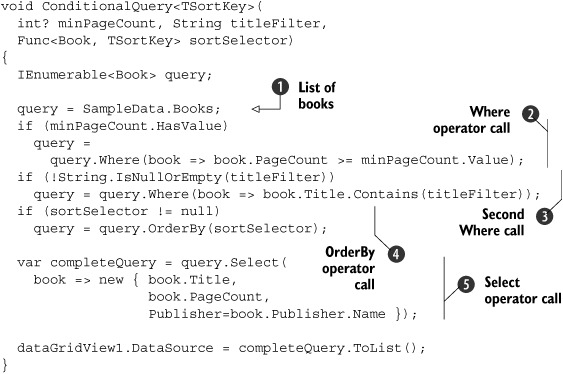
At the beginning, our query simply consists of the complete list of books ![]() . If the user specifies a value for the minimum page count, then we add a call to the Where operator to the query
. If the user specifies a value for the minimum page count, then we add a call to the Where operator to the query ![]() . If the user decides to filter the results based on the title of books, then we add another call to Where
. If the user decides to filter the results based on the title of books, then we add another call to Where ![]() . If a sort order is specified, we add the OrderBy operator to the mix
. If a sort order is specified, we add the OrderBy operator to the mix ![]() . Finally, we define the shape of the results by using the Select operator and an anonymous type
. Finally, we define the shape of the results by using the Select operator and an anonymous type ![]() .
.
Reminder
When we use something like query = query.Where(...), we’re actually chaining method calls and not creating a new query object. The fact that the query operators are extension methods (see chapters 2 and 3) allows us to use a temporary query variable to chain operations. We would not be able to write this kind of code without extension methods.
Armed with the technique we have just demonstrated, you should now be able to create rich dynamic queries. Yet, there is one more approach that can be used for advanced cases. We’ll now take some time to introduce this technique, which uses expression trees.
Creating queries at run-time
In the previous examples, we showed you how to create dynamic queries. These queries are dynamic because some of the values they use or even the clauses that make them are not decided at compile-time, but at run-time. The information these queries are based on is not available when the code is written because it can depend on the user or on the context. In more advanced scenarios, you may have to completely create queries on the fly. Imagine that your application needs to query data based on a description coming from an XML file, a remote application, or the user. In these cases, it’s possible to rely on expression trees.
Suppose the following XML fragment describes the criteria to apply to a collection of books in order to filter it:
<and> <notEqual property="Title" value="Funny Stories" /> <greaterThan property="PageCount" value="100" /> </and>
This XML stipulates that the Title property of a book should be different from “Funny Stories” and its PageCount property should be greater than 100. If we were to write a query that matches these conditions, it would look like this:
var query = from book in SampleData.Books where (book.Title != "Funny Stories") && (book.PageCount > 100) select book;
This is a typical query completely defined at compile-time. However, if the XML is provided to our application at run-time, we cannot write the query this way because the application is already compiled. The solution is to use expression trees.
As you’ve seen in chapter 3, the simplest way to create an expression tree is to let the compiler convert a lambda expression declared with the Expression<TDelegate> class into a series of factory method calls that will build the expression tree at run-time. In order to create dynamic queries, you can take advantage of another way of working with expression trees. You can “roll your own” expression tree by calling the factory methods—they’re static methods on the Expression<TDelegate> class—and compile the expression tree into a lambda expression at run-time.
Listing 5.17 dynamically creates a query at run-time that is equivalent to the preceding query expression.
Listing 5.17. Completely creating a query at run-time using an expression tree

The listing creates an expression tree that describes the filtering condition. Each statement augments the expression tree by adding new expressions to it. The last two statements convert the expression tree into code that forms an executable query. The query variable from the code can then be used like any other LINQ query.
Of course, the code from listing 5.17 uses hard-coded values such as “Title”, “Funny Stories”, “PageCount”, and “100”. In a real application, these values would come from our XML document or any other source of information that exists at run-time.
Expression trees represent an advanced topic. We won’t describe further how to use them in the context of dynamic queries, but they’re powerful once you master them. You can refer to the LINQ to Amazon example in chapter 13 to see another use of expression trees.
Note
Using dynamic queries with LINQ to SQL is another story because everything in the query needs to be translatable to SQL.
Tomas Petricek, a C# MVP, shows how to easily build dynamic LINQ to SQL queries at run-time in C# on his web site. See http://tomasp.net/blog/dynamic-linq-queries.aspx.
The last common scenario we’d like to cover in this chapter will show you how to write LINQ queries against text files. You know how to query collections in memory, but how can you query text files? The question is: do we need another variation of LINQ for this?
5.1.4. LINQ to Text Files
Varieties of LINQ exist to deal with several kinds of data and data structures. You already know the major “islands”: We have LINQ to Objects, LINQ to DataSet, LINQ to XML, LINQ to SQL. What if you’d like to use LINQ queries with text files? Is there a small island somewhere we didn’t let you know about yet? Should you create a new island, since LINQ’s extensibility allows this? You could code a few query operators to deal with file streams and text lines... . Wait a second; don’t jump straight to your keyboard to create LINQ to Text Files! We don’t need it. Let’s see how LINQ to Objects is enough for our scenario.
We’ll develop an example inspired by Eric White, a Microsoft programming writer who works on the LINQ to XML documentation among other things. Eric’s example[2] shows how to extract information from a CSV file.
2 See Eric White’s blog at http://blogs.msdn.com/ericwhite/archive/2006/08/31/734383.aspx.
Note
CSV stands for comma-separated values. In a CSV file, different field values are separated by commas.
The sample CSV file we’ll use is shown in listing 5.18.
Listing 5.18. Sample CSV document containing information about books
#Books (format: ISBN, Title, Authors, Publisher, Date, Price) 0735621632,CLR via C#,Jeffrey Richter,Microsoft Press,02-22-2006, 59.99 0321127420,Patterns Of Enterprise Application Architecture, Martin Fowler,Addison-Wesley, 11-05-2002,54.99 0321200683,Enterprise Integration Patterns,Gregor Hohpe, Addison-Wesley,10-10-2003,54.99 0321125215,Domain-Driven Design,Eric Evans, Addison-Wesley Professional,08-22-2003,54.99 1932394613,Ajax In Action,Dave Crane;Eric Pascarello;Darren James, Manning Publications,10-01-2005,44.95
This CSV contains information about books. In order to read the CSV data, the first step is to open the text file and retrieve the lines it contains. One easy solution to achieve this is to use the File.ReadAllLines method. ReadAllLines is a static method available on the System.IO.File class. This method reads all lines from a text file and returns them as a string array. The second step is to filter out comments. This can be done easily using a where clause.
Here is how to write the start of the query:
from line in File.ReadAllLines("books.csv")
where !line.StartsWith("#")
Here, we use the string array returned by File.ReadAllLines as the source sequence in our from clause, and we ignore the lines that start with #.
The next step is to split each line into parts. In order to do this, we can leverage the Split method available on string objects. Split returns a string array containing the substrings that are delimited by a character or a set of characters in a string instance. Here, we’ll split the string based on commas.
We need to refer to each part of the line in the rest of the query, but it’s important to perform the split operation only once. This is a typical situation in which the let clause is useful. A let clause computes a value and introduces an identifier representing that value. Here, we use the let clause to hold the parts contained in each line. Once we have a line split apart, we can wrap it into a new object using an anonymous type in a select clause.
Listing 5.19 shows is the complete query.
Listing 5.19. Querying information about books from a CSV file
from line in File.ReadAllLines("books.csv")
where !line.StartsWith("#")
let parts = line.Split(',')
select new { Isbn=parts[0], Title=parts[1], Publisher=parts[3] };
Here is the result you get if you use ObjectDumper with the query:
Isbn=0735621632 Title=CLR via C# Publisher=Microsoft Press Isbn=0321127420 Title=Patterns Of Enterprise Application Architecture Publisher=Addison-Wesley Isbn=0321200683 Title=Enterprise Integration Patterns Publisher=Addison-Wesley Isbn=0321125215 Title=Domain-Driven Design Publisher=Addison-Wesley Isbn=1932394613 Title=Ajax In Action Publisher=Manning Publications
That’s all you need to do to read simple CSV files using LINQ. With four lines of code, you get a query that produces a sequence of objects that contain a title, a publisher name, and an ISBN! This demonstrates that LINQ to Objects is enough to deal with several data sources. We don’t need a specific flavor of LINQ to query text files.
Warning
This example shows a naïve approach to parsing CSV files. It doesn’t deal with escaped commas or other advanced CSV features. You may want to strengthen the code or use another approach for dealing with CSV in your applications.
In addition, this version of the code can have bad performance implications. We’ll show you how it can be improved to solve this in section 5.3.1.
We have just seen common scenarios and how to deal with them. Without the kind of ready-to-use solutions we gave you, you’d have to search by yourself how to address each scenario. In order to optimize the development of common scenarios, design patterns are often created. The next section gives you an overview of design patterns that can be applied to LINQ. We’ll get started with a design pattern that is widely used in LINQ queries: the Functional Construction pattern.
Since the LINQ to Text Files example is nice, we’ll reuse it as the base for our introduction to this first pattern. We’ll also use it again in section 5.3.1, where we’ll discuss how to improve the query we wrote in the current section to save resources and increase performance.
5.2. Design patterns
Like with any other technology, with LINQ some designs are used again and again over time. These designs eventually become well documented as design patterns so they can be reused easily and efficiently. A design pattern is a general repeatable solution to a commonly occurring problem in software design. Design patterns gained popularity in computer science after the book Design Patterns from the Gang of Four (aka GoF) was published in 1994.[3] Design patterns were initially defined for object-oriented programming, but have since been used for domains as diverse as organization, process management, and software architecture.
3Design Patterns: Elements of Reusable Object-Oriented Software . By Erich Gamma, Richard Helm, Ralph Johnson, John Vlissides. Addison-Wesley; ISBN 0-201-63361-2
The patterns we cover here apply to LINQ contexts: Functional Construction and ForEach.
5.2.1. The Functional Construction pattern
The first design pattern we’ll present uses collection initializers and query composition. This pattern is widely used in LINQ queries, especially with LINQ to XML as you’ll see in part 4 of this book.
This pattern is named Functional Construction because it’s used to construct a tree or a graph of objects, with a code structure similar to what is used in functional programming languages such as Lisp.
In order to introduce the Functional Construction pattern, let’s reuse and extend the LINQ to Text Files example that we presented in the previous section. Here is the query we used:
from line in File.ReadAllLines("books.csv")
where !line.StartsWith("#")
let parts = line.Split(',')
select new { Isbn=parts[0], Title=parts[1], Publisher=parts[3] };
We conveniently left the authors out of the query since they require a little extra work. We’ll now handle them to get the following kind of results:
Isbn=0735621632 Title=CLR via C# Publisher=Microsoft Press Authors: FirstName=Jeffrey LastName=Richter Isbn=0321127420 Title=Patterns Of Enterprise Application Architecture Publisher=Addison-Wesley Authors: FirstName=Martin LastName=Fowler Isbn=0321200683 Title=Enterprise Integration Patterns Publisher=Addison-Wesley Authors: FirstName=Gregor LastName=Hohpe Isbn=0321125215 Title=Domain-Driven Design Publisher=Addison-Wesley Professional Authors: FirstName=Eric LastName=Evans Isbn=1932394613 Title=Ajax In Action Publisher=Manning Publications Authors: FirstName=Dave LastName=Crane Authors: FirstName=Eric LastName=Pascarello Authors: FirstName=Darren LastName=James
Unlike the other fields in our text file, there can be more than one author specified for a single book. If we go back and review the sample text file from listing 5.18, we see that the authors are delimited by a semicolon:
Dave Crane;Eric Pascarello;Darren James
As we did with the entire line, we can split the string of authors into an array, with each author being an individual element in the array. To be sure we get our fill of Split, we use it one final time to break the full author name into first and last names. Finally, we place the statements for parsing out the authors into a subquery and wrap the results of our many splits into each book’s Author property. Listing 5.20 shows the full query.
Listing 5.20. Declarative approach for parsing a CSV file, with anonymous types
var books =
from line in File.ReadAllLines("books.csv")
where !line.StartsWith("#")
let parts = line.Split(',')
select new {
Isbn = parts[0],
Title = parts[1],
Publisher = parts[3],
Authors =
from authorFullName in parts[2].Split(';')
let authorNameParts = authorFullName.Split(' ')
select new {
FirstName = authorNameParts[0],
LastName = authorNameParts[1]
}
};
ObjectDumper.Write(books, 1);
In the query, we use anonymous types for the results, but we could use regular types instead. Listing 5.21 shows how to reuse our existing Book, Publisher, and Author types.
Listing 5.21. Declarative for parsing a CSV file, with existing types
var books =
from line in File.ReadAllLines("books.csv")
where !line.StartsWith("#")
let parts = line.Split(',')
select new Book {
Isbn = parts[0],
Title = parts[1],
Publisher = new Publisher { Name = parts[3] },
Authors =
from authorFullName in parts[2].Split(';')
let authorNameParts = authorFullName.Split(' ')
select new Author {
FirstName=authorNameParts[0],
LastName=authorNameParts[1]
}
};
It’s interesting to note how the Authors property is initialized with a nested query. This is possible thanks to query compositionality. LINQ queries are fully compositional, meaning that queries can be arbitrarily nested. The result of the subquery is automatically transformed into a collection of type IEnumerable<Author>.
The Functional Construction pattern is sometimes called Transform pattern because it’s used to create a new object graph based on source objects graphs and sequences. It allows us to write code that is more declarative than imperative in nature. If you don’t use this pattern then in a lot of cases you have to write a lot of contrived imperative code.
Listing 5.22 is imperative code that is equivalent to listing 5.21.
Listing 5.22. Imperative approach for parsing a CSV file
List<Book> books = new List<Book>();
foreach (String line in File.ReadAllLines("books.csv"))
{
if (line.StartsWith("#"))
continue;
String[] parts = line.Split(','),
Book book = new Book();
book.Isbn = parts[0];
book.Title = parts[1];
Publisher publisher = new Publisher();
publisher.Name = parts[3];
book.Publisher = publisher;
List<Author> authors = new List<Author>();
foreach (String authorFullName in parts[2].Split(';'))
{
String[] authorNameParts = authorFullName.Split(' '),
Author author = new Author();
author.FirstName = authorNameParts[0];
author.LastName = authorNameParts[1];
authors.Add(author);
}
book.Authors = authors;
books.Add(book);
}
As you can see, the Functional Construction pattern offers a more concise style. Of course, the difference could be reduced if the Book, Publisher, and Author classes had constructors or if you used initializers. In fact, the real difference is elsewhere. Comparing the two pieces of code allows you to see how the Functional Construction pattern favors a declarative approach, in contrast to the imperative approach, which requires loops in our example. With a declarative approach, you describe what you want to achieve, but not necessarily how to achieve it.
One big advantage of the Functional Construction pattern is that the code often has the same shape as the result. We can clearly see the structure of the resulting object tree in listing 5.21 just by looking at the source code. This pattern is fundamental for LINQ to XML. In part 4, you’ll be able to see how this pattern is heavily used for creating XML.
Warning
If you plan to use a similar approach for querying text files, make sure you read section 5.3.1 to see how the call to ReadAllLines we use in the query should be replaced for better performance.
Let’s now see a second design pattern that can be used to iterate over a sequence in a query.
5.2.2. The ForEach pattern
The design pattern we present in this section allows you to write shorter code when you have a query immediately followed by an iteration of this query. Typical LINQ code you’ve seen in this book until now looks like listing 5.23.
Listing 5.23. Standard code used to execute and enumerate a LINQ query
var query =
from sourceItem in sequence
where some condition
select some projection
foreach (var item in query)
{
// work with item
}
We don’t know about you, but a question we had after seeing this pattern over and over is “Is there a way to perform the iteration within the query instead of in a separate foreach loop?” The short answer is that there is no query operator that comes with LINQ that can help you to do that. Our answer is that you can easily create one by yourself.
You can create the ForEach operator, which addresses this issue, with the code in listing 5.24.
Listing 5.24. ForEach query operator that executes a function over each element in a source sequence
public static void ForEach<T>(
this IEnumerable<T> source,
Action<T> func)
{
foreach (var item in source)
func(item);
}
ForEach is simply an extension method for IEnumerable<T>, similar to the one that already exists on List<T>, that loops on a sequence and executes the function it receives over each item in the sequence. The ForEach operator can be used in queries using the method syntax shown in listing 5.25.
Listing 5.25. Using the ForEach query operator using the method syntax
SampleData.Books .Where(book => book.PageCount > 150) .ForEach(book => Console.WriteLine(book.Title));
ForEach can also be used with the query syntax shown in listing 5.26.
Listing 5.26. Using the ForEach query operator with a query expression
(from book in SampleData.Books where book.PageCount > 150 select book) .ForEach(book => Console.WriteLine(book.Title));
In these examples, we use only one statement in ForEach. Thanks to the support lambda expressions offer for statement bodies (see chapter 2), it’s also possible to use multiple statements in a call to ForEach. Listing 5.27 is a small example in which we perform an update on the iterated object.
Listing 5.27. Using multiple statements in a ForEach call
SampleData.Books
.Where(book => book.PageCount > 150)
.ForEach(book => {
book.Title += " (long)";
Console.WriteLine(book.Title);
});
Using a query operator this way, instead of foreach or for loops, offers a better integration with queries. It follows the same general orientation as LINQ. It takes inspiration from functional programming. In fact, Eric White suggested this operator in his functional programming tutorial.[4] We recommend you take a look at Eric’s tutorial to get an introduction to how LINQ features relate to functional programming.
4 See http://blogs.msdn.com/ericwhite/pages/Programming-in-a-Functional-Style.aspx.
Warning
ForEach cannot be used in VB because it requires a statement lambda and VB.NET 9.0 does not offer support for statement lambdas.
The samples we have in C# cannot be converted to VB. Calls to ForEach in VB produce the following error at compile-time: Expression does not produce a value.
Now that we’ve covered common scenarios and design patterns, it’s time to focus on the second major topic of this chapter. So far, we have taught you how to use LINQ to Objects, first in simple queries and then in more advanced ones. But there’s one thing you need to pay attention to if you want to write LINQ queries you can actually use in production: performance. At this point, you know how to write simple LINQ queries and rich LINQ queries, but you still need to make sure that you write efficient queries. In the next section, we’ll give you an idea about performance overhead in LINQ to Objects and warn you about a number of pitfalls. All of which should help you write better LINQ applications.
5.3. Performance considerations
LINQ’s main advantage is not that it allows you to do new things, but it allows you to do things in new, simpler, more concise ways. The usual trade-off to get these benefits is performance. LINQ is no exception. The goal of this section is to make sure you know the performance implications of LINQ queries. We’ll show you how to get an idea of LINQ’s overhead and provide some figures. We’ll also highlight the main pitfalls. If you know where they are, you’ll be in a better position to avoid them.
As always, we have several ways to perform one task with the .NET Framework. Sometimes, the choice is only a matter of taste, other times it’s a matter of conciseness, but more often than not, making the right choice is critical and impacts the behavior of your program. Some methods are well adapted for LINQ queries and others should be avoided.
In this section, we’ll test the performance of several ways to use LINQ. We’ll also compare code written with LINQ and code written without LINQ. The goal is to compare the benefits for the developer in terms of productivity and code readability between the various options. We’ll make sure you understand the impact of each option in terms of performance.
To get started, we’ll get back to our LINQ to Text Files example one more time. It will be useful to demonstrate how it’s important to choose the right methods for reading text from a file in LINQ queries.
5.3.1. Favor a streaming approach
Let’s get back to our LINQ to Text Files example from sections 5.1.4 and 5.2.1. This example clearly demonstrates the ability of LINQ to Objects to query various data sources. As significant as this example is, we’d like to point out that it suffers from a potential problem: the use of ReadAllLines. This method returns an array populated with all the lines from the CSV file. This is fine for small files with few lines, but imagine a file with a lot of lines. The program can potentially allocate an enormous array in memory!
Moreover, the query somewhat defeats the standard deferred execution we expect with a LINQ query. Usually, the execution of a query is deferred, as we demonstrated in chapter 3. This means that the query doesn’t execute before we start to iterate it, using a foreach loop for example. Here, ReadAllLines executes immediately and loads the complete file in memory, before any iteration happens. Of course, this consumes a lot of memory, but in addition, we load the complete file while we may not process it completely.
LINQ to Objects has been designed to make the most of deferred query execution. The streaming approach it uses also saves resources, like memory and CPU. It’s important to walk down the same path whenever possible.
There are several ways to read text from a file using the .NET Framework. File.ReadAllLines is simply one. A better solution for our example is to use a streaming approach for loading the file. This can be done with a StreamReader object. It will allow us to save resources and give us a smoother execution. In order to integrate the StreamReader in the query, an elegant solution is to create a custom query operator, as Eric White suggests in his example.[5] See Listing 5.28.
5 See Eric White’s blog at http://blogs.msdn.com/ericwhite/archive/2006/08/31/734383.aspx.
Listing 5.28. Lines query operator that yields the text lines from a source StreamReader
public static class StreamReaderEnumerable
{
public static IEnumerable<String> Lines(this StreamReader source)
{
String line;
if (source == null)
throw new ArgumentNullException("source");
while ((line = source.ReadLine()) != null)
yield return line;
}
}
The query operator is implemented as an extension method for the StreamReader class. (You can see more examples of custom query operators in chapter 13.) It enumerates the lines provided by the StreamReader one by one, but does not load a line in memory before it’s actually needed. The integration of this technique into our query from listing 5.19 is easy; see listing 5.29.
Listing 5.29. Using the Lines query operator to use a streaming approach in CSV parsing
using (StreamReader reader = new StreamReader("books.csv"))
{
var books =
from line in reader.Lines()
where !line.StartsWith("#")
let parts = line.Split(',')
select new {Title=parts[1], Publisher=parts[3], Isbn=parts[0]}
ObjectDumper.Write(books, 1);
}
The main point is that this technique allows you to work with huge files while maintaining a small memory usage profile. This is the kind of thing you should pay attention to in order to improve your queries. It’s easy to write queries that are not optimal and consume a lot of memory.
Before moving on to another subject, let’s review what happens with the last version of our LINQ to Text Files query. The key is lazy evaluation. Objects are created on the fly, as you loop through the results, and not all at the beginning.
Let’s suppose we loop on the query’s results using foreach as follows—this is similar to what ObjectDumper.Write does in the previous code snippet:

The book object used in each iteration of the foreach loop exists only within that iteration. Not all objects are present in memory at the same time. Each iteration consists in reading a line from the file, splitting its content, and creating an object based on that information. Once we’re done with this object, another line is read, and so on.
It’s important that you try to take advantage of deferred execution so that fewer resources are consumed and less memory pressure happens. The next pitfall we’d like to highlight also has to do with deferred query execution or lack thereof.
5.3.2. Be careful about immediate execution
Most of the standard query operators are based on deferred execution through the use of iterators (see chapter 3). As we have seen in the previous section, this allows a lower resource burden. We’d like to draw your attention to the fact that some query operators defeat deferred execution. Indeed, some query operators iterate all the elements of the sequence they operate on as part of their behavior.
In general, the operators that do not return a sequence but a scalar value are executed immediately. This includes all the aggregation operators (Aggregate, Average, Count, LongCount, Max, Min, and Sum). This is not surprising because aggregation is the process of taking a collection and making a scalar. In order to compute their result, these operators need to iterate all the elements from the source sequence.
In addition, some other operators that return a sequence and not a scalar also iterate the source sequence completely before returning. Examples are OrderBy, OrderByDescending, and Reverse. These operators change the order of the elements from a source sequence. In order to know how to sort the elements in their result sequence, these operators need to completely iterate the source sequence.
Let’s elaborate what the problem is. Again, we’ll reuse our LINQ to Text Files example. We said in section 5.3.1 that it’s better to use a streaming approach to avoid loading complete files in memory. The code we used is shown in listing 5.30.
Listing 5.30. Code used to parse a CSV document

If you run this code, here is what happens:
- A loop starts, using the Lines operator to read a line from the file.
- If there are no more lines to deal with, the process halts.
- The Where operator executes on the line.
- If the line starts with #, it’s a comment so the line is skipped. Execution resumes at step 1.
- If the line is not a comment, the process continues.
- The line is split into parts.
- An object is created by the Select operator.
- Work is performed on the book object as specified in the body of the foreach statement.
- The process continues at step 1.
Note
You can clearly see these steps execute if you do step-by-step debugging of the code under Visual Studio. We highly encourage you to do so to get used to the way LINQ queries execute.
If you decide to process the files in a different order by introducing an orderby clause or a call to the Reverse operator in the query, the process changes. Let’s say you add a call to Reverse as follows:
... from line in reader.Lines().Reverse() ...
This time, the query executes as follows:
- The Reverse operator executes.
- Reverse loops on all lines, invoking the Lines operator immediately for each line.
- A loop starts by retrieving a line returned by Reverse.
- If there are no more lines to deal with, the process halts.
- The Where operator executes on the line.
- If the line starts with #, it’s a comment so the line is skipped. Execution resumes at step 1.
- If the line is not a comment, the process continues.
- The line is split into parts.
- An object is created by the Select operator.
- Work is performed on the book object as specified in the body of the foreach statement.
- The process continues at step 2.
You can see that the Reverse operator breaks the nice pipeline flow we had in the original version because it loads all lines in memory at the beginning of the process. Make sure you absolutely need to call this kind of operator before using them in your queries. At least, you need to be aware of how they behave; otherwise you may have bad performance and memory surprises when dealing with large collections.
Keep in mind that some conversion operators also exhibit the same behavior. These operators are ToArray, ToDictionary, ToList, and ToLookup. They all return sequences, but create new collections that contain all the elements from the source sequence they’re applied on, which requires immediately iterating the sequence.
Now that you’ve been warned about the behavior of some query operators, we’ll take a look at a common scenario that will show that you need to use LINQ and the standard query operators carefully.
5.3.3. Will LINQ to Objects hurt the performance of my code?
Sometimes LINQ to Objects does not provide what you need right from the box. Let’s consider a fairly common scenario that Jon Skeet, author of C# in Depth and a C# MVP, presents on his blog.[6] Imagine you have a collection of objects and you need to find the object that has the maximum value for a certain property. This is like having a box full of cookies and you want to find the one that has the most chocolate chips—not for you, but to offer it to your darling, of course. The box of cookies is the collection, and the number of chocolate chip’s is the property.
6 See http://msmvps.com/blogs/jon.skeet/archive/2005/10/02/68712.aspx.
At first, you might think that the Max operator, which is part of the standard query operators, is all you need. But the Max operator doesn’t help in this case because it returns the maximum value, not the object that has that value. Max can tell you the maximum number of chocolate chips on one cookie, but cannot tell you which cookie this is!
This is a typical scenario where we have the choice among several options, including using LINQ in one way or another or resorting to LINQ-free code and classical constructs. Like Jon Skeet, let’s review possible ways to find a replacement for the inadequate Max.
Options
A first option is to use a simple foreach loop, as in listing 5.31.
Listing 5.31. Using a foreach statement to find the book with the highest number of pages in a collection
Book maxBook = null;
foreach (var book in books)
{
if ((maxBook == null) || (book.PageCount > maxBook.PageCount))
maxBook = book;
}
This solution is pretty straightforward. It keeps a reference to the “maximum element so far”. It iterates through the list only once. It has a complexity of O(n), which is mathematically the best we can get without knowing something about the list.
A second option is to sort the collection and take the first element, as in listing 5.32.
Listing 5.32. Using sorting and First to find the book with the highest number of pages in a collection
var sortedList = from book in books orderby book.PageCount descending select book; var maxBook = sortedList.First();
In this solution, we use a LINQ query to sort the books in descending number of pages, and then take the first book in the resulting list. The disadvantage with this approach is that all the books are sorted before we can get the result. This operation is likely to be O(n log n).
A third option is to use a use a subquery, as in listing 5.33.
Listing 5.33. Using a subquery to find the book with the highest number of pages in a collection
var maxList = from book in books where book.PageCount == books.Max(b => b.PageCount) select book; var maxBook = maxList.First();
This goes through the list, finding every book whose number of pages is equal to the maximum, and then takes the first of those books. Unfortunately, the comparison calculates the maximum size on every iteration. This makes it an O(n2) operation.
A fourth option is to use two separate queries, like in listing 5.34.
Listing 5.34. Using two separate queries to find the book with the highest number of pages in a collection
var maxPageCount = books.Max(book => book.PageCount); var maxList = from book in books where book.PageCount == maxPageCount select book; var maxBook = maxList.First();
This is similar to the previous version, but solves the problem of the repeated calculation of the maximum number of pages by doing it before anything else. This makes the whole operation O(n), but it’s somewhat dissatisfying, as we have to iterate the list twice.
The last solution we’d recommend for its higher integration with LINQ is to create a custom query operator. Listing 5.35 shows how to code such an operator, which we’ll call MaxElement.
Listing 5.35. Creating a custom operator named MaxElement to find the object with the maximum value
public static TElement MaxElement<TElement, TData>(
this IEnumerable<TElement> source,
Func<TElement, TData> selector)
where TData : IComparable<TData>
{
if (source == null)
throw new ArgumentNullException("source");
if (selector == null)
throw new ArgumentNullException("selector");
Boolean firstElement = true;
TElement result = default(TElement);
TData maxValue = default(TData);
foreach (TElement element in source)
{
var candidate = selector(element);
if (firstElement ||
(candidate.CompareTo(maxValue) > 0))
{
firstElement = false;
maxValue = candidate;
result = element;
}
}
return result;
}
This query operator is easy to use:
var maxBook = books.MaxElement(book => book.PageCount);
Table 5.1 shows how the different options behave if you run a benchmark with 20 runs.
Table 5.1. Time measured for each MaxElement option
|
Option |
Average time (in ms) |
Minimum time (in ms) |
Maximum time (in ms) |
|---|---|---|---|
| foreach | 37 | 35 | 42 |
| OrderBy + First | 1724 | 1704 | 1933 |
| Sub-query | 37482 | 37201 | 45233 |
| Two queries | 66 | 65 | 69 |
| Custom operator | 56 | 54 | 73 |
These results[7] show that the performance can vary a lot between different solutions. It’s important to use correct LINQ queries! In particular, it’s definitely cheaper to iterate through the collection only once. The custom operator is not quite as fast as the non-LINQ way, but it’s still much better than most of the other options. It’s up to you to decide whether such a custom query operator can safely be used in place of the foreach solution. What we can say is that the custom query operator is an appealing solution for LINQ contexts, even if it comes with a performance cost.
7 Results measured with .NET 3.5 RTM on a machine with two Intel Xeon 2.4 GHz CPUs and 2 GB of RAM. The application was compiled with the Release configuration.
Note
You can easily experiment with other solutions by building on the complete example packaged with the code coming with this book.
Lessons learned
You need to think about the complexity of LINQ to Objects queries. Because we deal with lists and loops, it’s particularly important to try to spare CPU cycles if possible. Keep in mind that you should avoid writing queries that iterate collections more than once; otherwise your queries may perform poorly. In other words, you don’t want to waste your time counting chocolate chips again and again. Your goal is to find the cookie quickly, so you can attack the next one without delay.
You also need to take into account the context in which they will be executed. For example, the same scenario in the context of a LINQ to SQL query would be very different because LINQ to SQL interprets queries in its own way, which is dictated by what the SQL language supports.
The conclusion is that you should use LINQ to Objects wisely. LINQ to Objects is not the ultimate solution for all use cases. In some cases, it may be preferable to use traditional approaches, such as for and foreach loops. In other cases, you can stick to LINQ, but it’s better to create your own query operators for optimal performance. There’s a lesson from the Python philosophy: write everything in Python for simplicity, readability, and maintainability, and optimize what you need in C++. The analog here is: Write everything in LINQ, and optimize when you must using domain-specific operators.
In this section, we have mainly compared different solutions that use LINQ. In the next section, we’ll focus on comparing LINQ solutions to traditional ones. The goal is to give you an idea of LINQ’s overhead.
5.3.4. Getting an idea about the overhead of LINQ to Objects
LINQ to Objects is fantastic because it allows you to write code that is simpler to read and write. Coding some of the operations that LINQ to Objects allows on in-memory collections using classic constructs can be difficult. Often you’d have to use tedious code with a lot of nested loops and temporary variables. You’re probably convinced that LINQ to Objects is really nice, so we won’t to try to persuade you further. What we’ll do instead is closer to the opposite! Of course, our goal is not to deter you from using LINQ, but you need to know how much LINQ costs performance-wise. We’ll try to answer the question “Should I always use LINQ or are standard solutions better in some cases?”
Let’s determine the level of overhead you can expect with LINQ. We don’t want to provide you with figures straight off, first because performance can vary largely from one machine to another, and second because it’s better if you can perform tests by yourself. This is why we propose to show you what tests we did, and you’ll then be able to adapt and run them.
The simplest operation that a LINQ query can perform is a filter, such as in the one in listing 5.36.
Listing 5.36. Filtering a collection of books with a LINQ query
var results = from book in books where book.PageCount > 500 select book;
Let’s review how we can reproduce the same operation with alternative solutions. Listing 5.37 shows the equivalent code with a foreach statement.
Listing 5.37. Filtering a collection of books with a foreach loop
var results = new List<Book>()
foreach (var book in books)
{
if (book.PageCount > 500)
results.Add(book);
}
And listing 5.38 shows the same with a for statement.
Listing 5.38. Filtering a collection of books with a for loop
var results = new List<Book>()
for (int i = 0; i < books.Count; i ++)
{
Book book = books[i];
if (book.PageCount > 500)
results.Add(book);
}
This can also be achieved using List<T>.FindAll, as in listing 5.39.
Listing 5.39. Filtering a collection of books with the List<T>.FindAll method
var results = books.FindAll(book => book.PageCount > 500);
There are other possibilities, but the goal here is not list them all. You’ll be able to find the complete tests in the code accompanying this book, with other alternatives included.
To give you an idea of the performance of each option, we have run a benchmark with one million randomly initialized objects. Table 5.2 shows the results we got for 50 runs with a release build.
Table 5.2. Time measured for each search option executed 50 times using a condition on an int
|
Option |
Average time (in ms) |
Minimum time (in ms) |
Maximum time (in ms) |
|---|---|---|---|
| foreach | 68 | 47 | 384 |
| for | 59 | 42 | 383 |
| List<T>.FindAll | 62 | 51 | 278 |
| LINQ | 91 | 74 | 404 |
Surprised? Disappointed? LINQ to Objects seems to be almost 50 percent slower than the other options on average! But wait: don’t decide to stop using LINQ immediately after reading these results. We all know that tests and results need to be taken carefully, so follow us a bit more.
First of all, these are the results for one query. What if we change the query a little? For example, let’s change the condition in the where clause. Here we use a test on a string (Title) instead of an int (PageCount):
var results =
from book in books
where book.Title.StartsWith("1")
select book;
If we adapt the queries for all options and run the test 50 times again, we get the results in table 5.3.
Table 5.3. Time measured for each search option executed 50 times using a condition on a string
|
Option |
Average time (in ms) |
Minimum time (in ms) |
Maximum time (in ms) |
|---|---|---|---|
| foreach | 327 | 323 | 361 |
| for | 292 | 288 | 329 |
| List<T>.FindAll | 325 | 321 | 355 |
| LINQ | 339 | 377 | 377 |
What do we notice with these new results? The LINQ option takes approximately four times what was needed for the previous test with the condition on an int. This is because operations on strings are much more expensive than on integers/numbers. But the most interesting is that this time, the LINQ option is only around 10 percent slower than the fastest option. This clearly shows that the impact of LINQ does not always cause a big drop in performance.
Why do we see a difference between the two series of tests? When we changed the condition in the where clause from a test on an int to a test on a string, we increased the work to be performed each time the test executes. The additional time spent testing the condition affects each option, but LINQ’s overhead remains more or less the same. If we look at this the other way around, we could say that the less work there is to do in the query, the higher the overhead appears.
There are no surprises. LINQ does not come for free. LINQ queries cause additional work, object creations, and pressure on the garbage collector. The additional cost of using LINQ can vary a lot depending on the query. It can be as low as 5 percent, but can sometimes be around 500 percent.
In conclusion, don’t be afraid to use LINQ, but use it wisely. For simple operations that are executed extensively in your code, you may consider using the traditional alternatives. For simple filter or search operations, you can stick to the methods offered by List<T> and arrays, such as FindAll, ForEach, Find, ConvertAll, or TrueForAll. Of course, you can continue to use the classic for and foreach statements wherever LINQ would be overkill. For queries that are not executed several times per second, you can probably use LINQ to Objects safely. A query that is executed only once in a non–time-critical context won’t make a big difference if it takes 60 milliseconds to execute instead of 10. Don’t forget the benefits at the source code level in terms of clarity and maintainability.
Let’s take another example to compare code with LINQ and code without.
5.3.5. Performance versus conciseness: A cruel dilemma?
We have just seen that LINQ seems to impose a trade-off on performance versus conciseness and code clarity. We propose to look at a new example to confirm or refute this theory. This time, we’ll perform a grouping operation. Listing 5.40 shows a LINQ query that can be used for grouping books by publisher, with the resulting groups sorted alphabetically by publisher name.
Listing 5.40. Grouping with a LINQ query
var results = from book in SampleData.Books group book by book.Publisher.Name into publisherBooks orderby publisherBooks.Key select publisherBooks;
Listing 5.41 shows what would be required to perform the same grouping without LINQ.
Listing 5.41. Grouping without LINQ
var results = new SortedDictionary<String, IList<Book>>();
foreach (var book in SampleData.Books)
{
IList<Book> publisherBooks;
if (!results.TryGetValue(book.Publisher.Name,
out publisherBooks))
{
publisherBooks = new List<Book>();
results[book.Publisher.Name] = publisherBooks;
}
publisherBooks.Add(book);
}
There’s no doubt that the code without LINQ is longer and more complex. It remains accessible, but you can easily imagine that things can get more complicated with more complex queries. After all, we used a relatively simple LINQ query!
The main difference between the two code samples lies in the use of opposite approaches. The LINQ query follows a declarative approach, while the code without LINQ is imperative in nature. All the code written in C# or VB.NET before LINQ appeared is imperative because these languages were imperative. The code without LINQ completely indicates how the work is performed. The code that uses LINQ simply consists of a query that describes the results we want to get. Instead of describing in great detail how to deal with data, writing non-procedural code in LINQ is more akin to describing the results that you want. This is fundamental.
We already said that you’re probably convinced about the benefits of LINQ. So, what’s the point of this new example? If you run a performance benchmark of the two solutions, you’ll find that the LINQ solution is faster this time! In fact, it takes less than half the time to execute compared to the non-LINQ solution. In this case, we get all the benefits with LINQ!
Of course, you may wonder why the second solution is slower. We’ll let you investigate this on your own. Our point remains the same: if you want to achieve the same performance level without the LINQ query, you’ll have to write even more complex code.
Hints
SortedDictionary is an expensive data structure in terms of memory use and speed of insertion. In addition, we use TryGetValue during each loop iteration. The LINQ operators handle this scenario in a much more efficient way. The non-LINQ code can certainly be improved, but it will remain more complex in any case.
5.4. Summary
This chapter was an occasion to take a second look at in-memory LINQ queries.
We showed you how to handle common scenarios, such as querying nongeneric collections, grouping by multiple criteria, creating dynamic queries, or querying text files. We also introduced design patterns you can apply in your queries. The Functional Construction pattern, for example, is critical for LINQ to XML, as you’ll see in part 4 of the book.
The second major topic we covered in this chapter is performance. We drew your attention to performance problems that can happen with LINQ queries. This should help you to avoid writing suboptimal queries. We also carried out some testing to compare the performance of LINQ code to other more traditional solutions. This allowed you to see LINQ’s strengths and weaknesses.
In previous chapters, we introduced LINQ and showed you how to write queries quickly and easily. Like everything new, LINQ may have seemed delightful at first sight. In this chapter, we tried to disillusion you somewhat by looking beyond the shiny surface. Of course, our goal is not to draw you away from LINQ, but we wanted to make sure that you can handle advanced use cases and write efficient queries.
The conclusion is that life is not a fairy tale. Not everything is black or white. LINQ helps you greatly to query data in innovative ways. LINQ queries are also easier to read and maintain. However, performance-wise LINQ comes at a cost you have to bear in mind. In fact, in the future LINQ queries will help you to boost the performance of your code. Microsoft is working on PLINQ, which will allow you to implicitly use concurrency in LINQ to Objects-like queries. PLINQ hasn’t been released at the same time as the other LINQ technologies, but it should follow some time in 2008.
And now for something completely different. Now that you know so much about in-memory queries, it’s time to discover other LINQ flavors. In the next parts of this book, you’ll learn about LINQ to SQL and LINQ to XML. Since we discussed performance in this chapter, it may be a good place to recommend you take a look at the blog of Microsoft’s Rico Mariani.[8] You’ll find there a series of posts on the performance of LINQ to SQL. But maybe you should learn about LINQ to SQL first, so let’s jump right into this subject with the next chapter!
8 Visit the following URL to find Rico Mariani’s study about LINQ to SQL’s performance: http://blogs.msdn.com/ricom/archive/2007/06/22/dlinq-linq-to-sql-performance-part-1.aspx