
Chapter 8. Advanced LINQ to SQL features
This chapter covers:
- Handling concurrency
- Working directly with the database using pass-through queries, stored procedures, and user defined functions
- Improving the business tier with compiled queries, partial classes, partial methods, and object inheritance
- Comparison of LINQ to SQL with LINQ to Entities
In the last couple of chapters, we discussed the core components of working with relational data using LINQ to SQL. We saw how the mapping metadata combined with the IQueryable interface and expression trees to enable us to apply the same LINQ to Objects query expressions to relational data stores. By leveraging common APIs, we can eliminate vast amounts of data plumbing code and focus more directly on the business needs.
In this chapter, we’re going to extend the basic concepts and see some of LINQ to SQL’s more advanced features. We’ll begin by expanding on our discussion of the object life cycle, focusing on concurrency and transaction issues. We’ll continue by exploring how we can work more directly with the database and take advantage of some of the more specific functionality offered by SQL Server. Moving beyond the data tier, we’ll look at options LINQ to SQL gives us to customize the business tier, including precompiling query expressions, using partial classes, and polymorphism via inheritance. We’ll conclude by briefly exploring the upcoming Entity Framework as an alternative to LINQ to SQL for accessing relational data.
8.1. Handling simultaneous changes
When designing systems for a single user, the developer doesn’t need to worry about how changes that one person makes affect other users. In actuality, it is rare for a production system to be used by only one user, as they typically grow and take on lives of their own. As the system grows to support multiple users, we need to take into account the conflicts that arise when two users try to change the same record at the same time. In general, there are two strategies to handle this: pessimistic concurrency, which locks a second user out of changing a record until the first user has released a lock, and optimistic concurrency, which allows two users to make changes. In the case of optimistic concurrency, the application designer needs to decide whether to retain the first user’s values, retain the last update, or somehow merge the values from both users. Each strategy offers different advantages and disadvantages.
8.1.1. Pessimistic concurrency
Prior to .NET, many applications maintained open connections to the database. With these systems, developers frequently wrote applications that would retrieve a record in the database and retain a lock on that record to prevent other users from making changes to it at the same time. This kind of locking is called pessimistic concurrency. Small Windows-based applications built with this pessimistic concurrency worked with few issues. However, as those systems needed to scale to larger user bases, the locking mechanisms caused systems to bog down.
At the same time the scalability issues started emerging, many systems began moving from client-server architectures toward more stateless, web-based architectures in order to alleviate deployment challenges. The demands of stateless web applications required that they no longer rely on long-held pessimistic locks.
As an attempt to keep developers from falling into the scalability and locking traps posed by pessimistic concurrency models, the .NET Framework was designed to target the disconnected nature of web-based applications. The data API for .NET, ADO.NET, was created without the capability to hold cursors to the tables and thus eliminated automated pessimistic concurrency options. Applications could still be designed to add a “checked out” flag on a record that would be evaluated when subsequent attempts were made to access the same record. However, these checked out flags were frequently not reset, as it became difficult to determine when the user was no longer using it. Due to these issues, the pessimistic concurrency model began to unravel in the disconnected environment.
8.1.2. Optimistic concurrency
As a result of the problems encountered in a disconnected environment, an alternative strategy was typically used. The alternative, optimistic concurrency model allowed any user to make changes to their copy of the data. When the values were saved, the program would check the previous values to see if they were changed. If the values were unchanged, the record would be considered unlocked, thus the record would be saved. If there was a conflict, the program would need to know whether to automatically overwrite the previous changes, throw away the new changes, or somehow merge the changes.
The first half of determining optimistic concurrency is relatively simple. Without a concurrency check, the SQL statement to the database would consist of the following syntax: UPDATE TABLE SET [field = value] WHERE [Id = value]. To add optimistic concurrency, the WHERE clause would be extended to not only include the value of the ID column, but also compare the original values of each column in the table. Listing 8.1 demonstrates a sample SQL statement to check for optimistic concurrency on our running example’s Book table.
Listing 8.1. SQL Update statement to perform optimistic concurrency on Book

Using the code in listing 8.1, we attempt to update a record and check the RowCount to see if the update succeeded. If it returns 1, we know that the original values did not change and the update worked. If it returns 0, we know that someone changed at least one of the values since they were last fetched, because we can’t find a record that still has the same values we originally loaded. In this case, the record is not updated. At that point, we can inform the user that there was a conflict and handle the concurrency violation appropriately. As with the rest of LINQ to SQL, handling concurrency issues is built in.
Configuring classes to support optimistic concurrency is extremely easy. In fact, by establishing the table and column mappings,
we’re already set to use optimistic concurrency. When calling SubmitChanges, the DataContext will automatically implement optimistic concurrency. To demonstrate the SQL generated for a simple update, let’s consider
an example where we get the most expensive book in our table ![]() and attempt to discount it by 10%
and attempt to discount it by 10% ![]() . (See listing 8.2.)
. (See listing 8.2.)
Listing 8.2. Default concurrency implementation with LINQ to SQL
Ch8DataContext context = new Ch8DataContext() Book mostExpensiveBook = (from book in context.Booksorderby book.Price descending select book).First(); decimal discount = .1M; mostExpensiveBook.Price -= mostExpensiveBook.Price * discount;
context.SubmitChanges();
This produces the SQL to select the book, as well as the following SQL to update:
UPDATE [dbo].[Book]
SET [Price] = @p8
FROM [dbo].[Book]
WHERE ([Title] = @p0) AND ([Subject] = @p1) AND ([Publisher] = @p2)
AND ([PubDate] = @p3) AND ([Price] = @p4) AND ([PageCount] = @p5)
AND ([Isbn] = @p6) AND ([Summary] IS NULL) AND ([Notes] IS NULL)
AND ([ID] = @p7)
When SubmitChanges is called on the DataContext ![]() , the Update statement is generated and issued to the server. If no matching record is found based on the previous values passed in the
WHERE clause, the context will recognize that no records are affected as part of this statement. When no records are affected,
a ChangeConflictException is thrown.
, the Update statement is generated and issued to the server. If no matching record is found based on the previous values passed in the
WHERE clause, the context will recognize that no records are affected as part of this statement. When no records are affected,
a ChangeConflictException is thrown.
Depending on the situation, the number of parameters needed to implement optimistic concurrency can cause performance issues. In those cases, we can refine our mappings to identify only the fields necessary to ensure that the values didn’t change. We can do this by setting the UpdateCheck attribute. By default, UpdateCheck is set to Always, which means that LINQ to SQL will always check this column for optimistic concurrency. As an alternative, we can set it to only check if the value changes (WhenChanged) or to never check (Never).
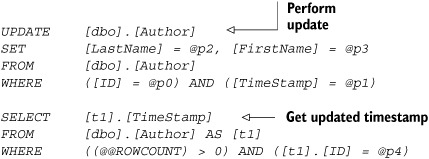
If we really want to draw on the power of the UpdateCheck attribute and have the ability to modify the table schema, we can add a RowVersion or TimeStamp column to each table. The database will automatically update the value of the RowVersion each time the row is changed. Concurrency checks only need to run on the combination of the version and ID columns. All other columns are set to UpdateCheck=Never and the database will assist with the concurrency checking. We used this scheme for the Author class mapping back in chapter 7. Listing 8.3 illustrates the revised Author class, applying the same change as we did in the previous example. Using the TimeStamp column, we can see a streamlined WHERE clause in the Update statement.
Listing 8.3. Optimistic concurrency with Authors using a timestamp column
Ch8DataContext context = new Ch8DataContext(); Author authorToChange = (context.Authors).First(); authorToChange.FirstName = "Jim"; authorToChange.LastName = "Wooley"; context.SubmitChanges();
This results in the following SQL:
In addition to changing the standard optimistic concurrency by setting all fields to check always or using a timestamp, there are a couple of other concurrency models available. The first option is to simply ignore any concurrent changes and always update the records, allowing the last update to be accepted. In that case, set UpdateCheck to Never for all properties. Unless you can guarantee that concurrency is not an issue, this is not a recommended solution. In most cases, it is best to inform the user that there was a conflict and provide options to remedy the situation.
In some cases, it is fine to allow two users to make changes to different columns in the same table. For example, in wide tables, we may want to manage different sets of columns with different objects or contexts. In this case, set the UpdateCheck attribute to WhenChanged rather than Always.
This is not recommended in all cases, particularly when multiple fields contribute to a calculated total. For example, in a typical OrderDetail table, columns may appear for quantity, price, and total price. If a change was made in either the quantity or price, the total price will need to be changed. If one user changes the quantity while another changes the price, the total price would not be modified properly. This form of automatic merge concurrency management does have its place. Business demands should dictate if it is appropriate in any given situation.
With LINQ to SQL, concurrency checking can be set on a field-level basis. The framework was designed to provide the flexibility to allow for various customized implementations. The default behavior is to fully support optimistic concurrency. So far, we’ve identified how to recognize when there is a conflict. The second part of the equation is what we do with the knowledge that there was a concurrency exception.
8.1.3. Handling concurrency exceptions
In using the Always or WhenChanged options for UpdateCheck, it is inevitable that two users will modify the same values and cause conflicts. In those cases, the DataContext will raise a ChangeConflictException when the second user issues an SubmitChanges request. Because of the likelihood of running into an exception, we need to make sure we wrap the updates inside a structured exception-handling block.
Once an exception is thrown, several options to resolve the exception exist. The DataContext helps discover not only the object(s) that are in conflict, but also which properties are different between the original value, the changed value, and the current value in the database. In order to provide this level of information, we can specify the RefreshMode to determine whether the conflicting record is first refreshed from the database to determine the current values. Once we have the refreshed values, we can determine whether we want to retain the original values, the current database values, or our new values. If we want to take the last option and make sure our values are the ones that are retained, we resolve the change conflicts of the context object specifying that we want to keep the changes. Listing 8.4 illustrates a typical try-catch block to make sure our changes are retained.
Listing 8.4. Resolving change conflicts with KeepChanges
try
{
context.SubmitChanges(ConflictMode.ContinueOnConflict);
}
catch (ChangeConflictException)
{
context.ChangeConflicts.ResolveAll(RefreshMode.KeepChanges);
context.SubmitChanges();
}
If we use the KeepChanges option, we don’t need to inspect the changed values. We assert that our values are correct and go ahead and force them into the appropriate row. This last-in-wins method can be potentially dangerous. Columns that we didn’t update will be refreshed from the current value in the database.
If the business needs demand it, we could merge the changes with the new values from the database; simply change RefreshMode to KeepCurrentValues. This way, we’ll incorporate the other user’s changes into our record and add our changes. However, if both users changed the same column, the new value will overwrite the value that the first user updated.
To be safe, we can overwrite the values that the second user tried to change with the current values from the database. In that case, use RefreshMode.OverwriteCurrentValues. At this point, it would not be beneficial to submit the changes back to the database again, as there would be no difference between the current object and the values in the database. We would present the refreshed record to the user and have them make the appropriate changes again.
Depending on the number of changes that the user made, they may not appreciate having to reenter their data. Since SubmitChanges can update multiple records in a batch, the number of changes could be significant. To assist with this, the SubmitChanges method takes an overloaded value to indicate how we wish to proceed when a record is in conflict. We can either stop evaluating further records or collect a listing of objects that were conflicted. The ConflictMode enumeration specifies the two options: FailOnFirstConflict and ContinueOnConflict.
With the ContinueOnConflict option, we’ll need to iterate over the conflicting options and resolve them using the appropriate RefreshMode. Listing 8.5 illustrates how to submit all of the nonconflicting records and then overwrite the unsuccessful records with the current values in the database.
Listing 8.5. Replacing the user’s values with ones from the database
try
{
context.SubmitChanges(ConflictMode.ContinueOnConflict);
}
catch (ChangeConflictException)
{
context.ChangeConflicts.ResolveAll(RefreshMode.OverwriteCurrentValues);
}
With this method, we can at least submit some of the values and then prompt the user to reenter his information in the conflicting items. This could still cause some user resentment, as he would need to review all of the changes to see what records need to be changed.
A better solution would be to present the user with the records and fields that were changed. LINQ to SQL not only allows access to this information, but also supports the ability to view the current value, original value, and database value for the conflicting object. Listing 8.6 demonstrates using the ChangeConflicts collection of the DataContext to collect the details of each conflict.
Listing 8.6. Displaying conflict details
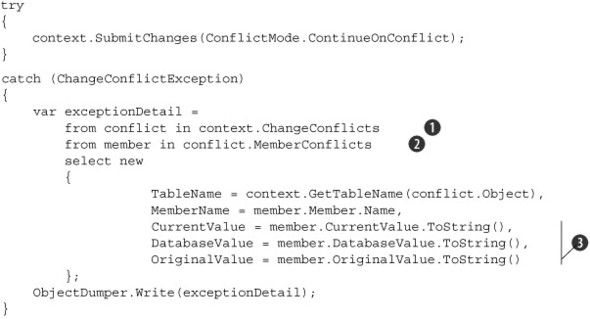
Each item in the ChangeConflicts collection ![]() contains the object that conflicted as well as a MemberConflicts collection
contains the object that conflicted as well as a MemberConflicts collection ![]() . This collection contains information about the Member, CurrentValue, DatabaseValue, and OriginalValue
. This collection contains information about the Member, CurrentValue, DatabaseValue, and OriginalValue ![]() . Once we have this information, we can display it to the user in whatever method we choose.
. Once we have this information, we can display it to the user in whatever method we choose.
Using this code, we can display details of the concurrency errors that the user creates. Consider the possibility where two users try to change the price of a book at the same time. If the first user were to raise the price by 2 dollars while a second tries to discount it by a dollar, what would happen? The first user to save the changes would have no problems. As the second user tries to commit her changes, a ChangeConflictException will be thrown. We could easily display the exceptionDetail list as shown in figure 8.1.
Figure 8.1. Displaying the original, current, and database value to resolve concurrency exceptions
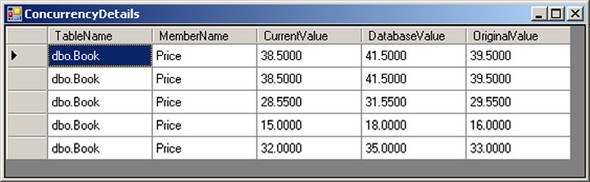
Once presented with the details of the conflicts, the second user can elect how she wants to resolve each record individually. The key point to realize is that the DataContext is more than a connection object. It maintains full change tracking and concurrency management by default. We have to do extra work to turn the optimistic concurrency options off.
In designing systems that allow for multiple concurrent users, we need to consider how to handle concurrency concerns. In most cases, it is not a matter of if a ChangeConflictException will be thrown. It is only a matter of when. By catching the exception, we can either handle it using one of the resolution modes or roll the entire transaction back. In the next section, we’ll look at options for managing transactions within LINQ to SQL.
8.1.4. Resolving conflicts using transactions
As we were discussing concurrency options, we noted that updating the database with SubmitChanges could update a single record or any number of records (even across multiple tables). If we run into conflicts, we can decide how to handle the conflict. However, we didn’t point out previously that if some effort is not made to roll back changes, any records that were successfully saved prior to the exception will be committed to the database. This could leave the database in an invalid state if some records are saved and others are not.
Why is it a bad thing to save some of the records and not others? Consider going to a computer store to purchase the components for a new computer. We pick up the motherboard, case, power supply, hard drives, and video card, and then head to the counter to check out. The astute salesperson notices the missing memory and processor. After looking around for a bit, he finds the store doesn’t have a compatible processor. At this point, we’re left with a decision: go ahead and purchase the pieces we picked out and hope to find the remaining pieces somewhere else, change the motherboard to one with a matching processor, or stop the purchase.
Now, consider that this computer is your database. The components are the records in the business objects that need to be updated and the salesperson is the DataContext. The salesperson noticing the problem can be compared to the DataContext throwing a ChangeConflictException. If we choose the first option (buy what we can now), we could use ConflictMode.ContinueOnConflict and then ignore the conflicts. Naturally, the DataContext needs to be told how to handle the conflicts before they arise. If we choose the third option (give up and go home), any changes would need to be rolled back (get your money back). If we choose the middle option, we would need to roll back the changes from the database, then decide what changes we need to make. Once the appropriate changes are made, we could try to submit the changes again.
LINQ to SQL offers three main mechanisms to manage transactions. In the first option, used by default, the DataContext will create and enlist in a transaction when SubmitChanges is called. This will roll back changes automatically depending on the selected ConflictMode option.
If we wish to manually maintain the transaction, the DataContext also offers the ability to use the transaction on the connection already maintained by the DataContext. In this case, we call BeginTransaction on DataContext.Connection before we try to submit the changes. After we submit the changes, we can either commit them or roll them back. Listing 8.7 demonstrates this alternative.
Listing 8.7. Managing the transaction through the DataContext
try
{
context.Connection.Open();
context.Transaction = context.Connection.BeginTransaction();
context.SubmitChanges(ConflictMode.ContinueOnConflict);
context.Transaction.Commit();
}
catch (ChangeConflictException)
{
context.Transaction.Rollback();
}
The downside of managing the transactions directly through the DataContext is that it cannot span multiple connections or multiple DataContext objects. As a third option, the System.Transactions.TransactionScope object that was introduced with the .NET 2.0 Framework was specifically designed to seamlessly span connections. To use it, add a reference to the System.Transactions library.
This object will automatically scale the transaction based on the objects that it covers. If the scope only covers a single database call, it will use a simple database transaction. If it spans multiple classes with multiple connections, it will automatically scale up to an enterprise transaction. Additionally, the TransactionScope doesn’t require us to explicitly begin the transaction or roll it back. The only thing you need to do is complete it. Listing 8.8 illustrates using the TransactionScope with LINQ to SQL.
Listing 8.8. Managing transactions with the TransactionScope object
using (System.Transactions.TransactionScope scope =
new System.Transactions.TransactionScope())
{
context.SubmitChanges(ConflictMode.ContinueOnConflict);
scope.Complete();
}
Unlike the other transaction mechanisms, we don’t need to wrap the code in a try-catch block solely to roll the transaction back. With the TransactionScope, the transaction will automatically get rolled back unless we call the Complete method. If an exception is thrown in SubmitChanges, the exception will bypass the Complete method. We don’t need to explicitly roll the transaction back. It still needs to be wrapped in an exception-handling block, but the exception handling can be done closer to the user interface.
The true joy of the TransactionScope object is that it automatically scales based on the given context. It works equally well with local transactions and with heterogeneous sources. Because of the flexibility and scalability, using the TransactionScope object is the preferred method of handling transactions with LINQ to SQL.
Managing transactions and concurrency are important tasks that most applications need to consider. Even though LINQ to SQL provides baseline implementations of these important concepts, it allows the programmer to customize the implementation to refine it to the customized business needs. The customizations do not end with transactions and concurrency. They extend to a number of database-specific capabilities that we can work with. Let’s continue by looking at some of these more advanced capabilities.
8.2. Advanced database capabilities
In many cases, the default mapping between tables and objects is fine for simple CRUD operations. But sometimes a direct relationship is not sufficient. In this section, we’ll explore some of the additional options LINQ to SQL provides to customize your data access. In each case, the programming model dramatically reduces the amount of custom plumbing code. We’ll start by looking at issuing statements directly to the database. We’ll continue by looking at how we can call upon the programmatic options of SQL Server, including stored procedures and user-defined functions.
8.2.1. SQL pass-through: Returning objects from SQL queries
Although the querying functionality in LINQ presents us with a revolutionary way of working with data, there is a major downside to the concept. The object-based query structures need to be compiled. In cases of ad hoc reporting or other user-defined data access, we often need more flexible models. To achieve this end, LINQ to SQL offers the ability to send dynamic SQL statements directly to the database without the need to compile them. To use this, we only need a DataContext object. From it, we can call the ExecuteQuery method passing the SQL string we want to execute. In listing 8.9, we ask the user to supply the fields they want to include and concatenate that value to the end of the SQL statement. We then display the results.
Listing 8.9. Dynamic SQL pass-through
string searchName;
string sql = @"Select ID, LastName, FirstName, WebSite, TimeStamp " +
"From dbo.Author " +
"Where LastName = '" + searchName + "'";
IEnumerable<Author> authors = context.ExecuteQuery<Author>(sql);
The amount of data access code is greatly reduced as compared to standard ADO.NET. When using the ExecuteQuery method, the source of the data is not important. All that is important is that the column names returned by the select statement match the names of the properties in the class. As long as these values match, the pass-through query can return the strongly typed objects that we specify.
Since the entire query is weakly typed when working with pass-through queries, special care needs to be taken to validate the user-supplied values. In addition, we also need to check the syntax. In listing 8.9, if the user enters a value for the SearchName that is not a valid field name, the framework will throw an exception. Even worse, a malicious user could easily initiate a SQL injection attack. For example, consider the results that would be returned if the user enters the following string in the textbox: Good' OR ''='. In this case, we would effectively be returning all records where the author last name is “Good” and any records where an empty string equals an empty string. Since the second clause would always return true, all authors would be returned rather than just the requested author.
As an alternative, the pass-through query can be constructed using the same curly notation that is used by the String.Format method. Follow the SQL string with a list of parameters that will be used by the query. In this case, the values are added into the statement as parameters rather than relying on string concatenation. Listing 8.10 extends the previous example with a parameter array replacing the inline concatenation. Rather than performing a direct String.Format method, which would result in a concatenation, the DataContext translates the expression into a parameterized query. In this case, we can thwart users trying to inject commands into the query string.
Listing 8.10. Dynamic SQL pass-through with parameters
string searchName = "Good' OR ''='";
Ch8DataContext context = new Ch8DataContext();
string sql =
@"Select ID, LastName, FirstName, WebSite, TimeStamp " +
"From dbo.Author " +
"Where LastName = {0}";
ObjectDumper.Write(context.ExecuteQuery<Author>(sql, SearchName));
Looking at the generated SQL, we can see that the query is now parameterized, which will prevent the dreaded SQL injection attack.
Select ID, LastName, FirstName, WebSite, TimeStamp From dbo.Author Where LastName = @p0
Dynamic SQL can be a powerful tool. It can also be dangerous if placed in the hands of the wrong users. Even for users who aren’t malicious, the dynamic SQL option can allow them to create queries that cause poor performance due to a lack of proper indexing for the query in question. Many database administrators will object to the overuse of dynamic SQL. While it definitely has its place, try to come up with other options before traversing down this route.
8.2.2. Working with stored procedures
At the opposite end of the spectrum from dynamic SQL lies the precompiled stored procedures that are included with SQL Server. Although standard LINQ to SQL methods can often be fine for simple CRUD operations, often business forces demand the use of stored procedures. The most typical reasons for reliance on stored procedures revolve around security, performance, auditing, or additional functionality.
In some cases, LINQ to SQL’s use of parameterized queries reduces the concerns from a performance and security perspective. From the performance perspective, the parameterized queries’ execution plans are evaluated once and cached, just as they are for stored procedures. From the security perspective, parameterized queries eliminate the possibility of SQL injection attacks. LINQ to SQL still requires server permissions at the table level, which some database administrators (DBAs) are reluctant to allow.
Also, stored procedures allow the DBA to control the data access and customize the indexing schemes. However, when using stored procedures, we can’t rely on the DataContext dynamically creating the CRUD SQL statements and limiting the number of properties that need to be updated. The entire object needs to be updated each time. Nonetheless, if the application requires stored procedures, they are relatively easy to use.
Reading data with stored procedures
When your environment requires stored procedures for accessing data, a bit more work is necessary as opposed to using just the basic LINQ query syntax. The first step is to create the stored procedure to return results. Once the procedure is set up in your database, we can access it the same as any other method call. Let’s consider a procedure to fetch a single book from the database based on a value passed in by the user. To demonstrate the kind of additional functionality we can do inside the stored procedure, we’ll add a bit of logging into an AuditTracking table. The sample project that comes with this book includes this table and the GetBook stored procedure that we’ll be using.
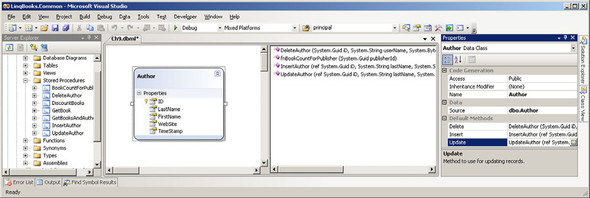
To add the stored procedure, we open the LINQ to SQL design surface that contains our Books class. Next, expand the Stored Procedures node of the Server Explorer and find the GetBook procedure. Drag the GetBook procedure onto the design surface and drop it on top of the Book class. The result is shown in figure 8.2.
Figure 8.2. Adding the GetBook stored procedure to the LINQ to SQL Designer
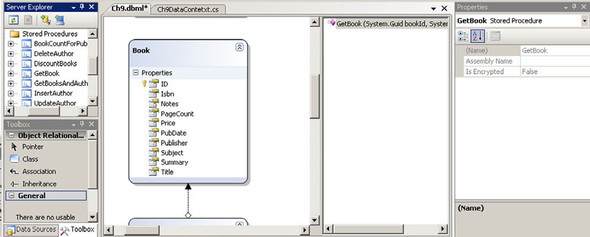
When we were working with tables, we mapped the tables directly to classes. When we query the data, we use extension methods or query syntax to define our queries. Stored procedures, on the other hand, are implemented as method calls that return objects. Since the designer defines the stored procedure as a method in the custom data context, we call it as shown in listing 8.11.
Listing 8.11. Using a stored procedure to return results
Guid bookId = new Guid("0737c167-e3d9-4a46-9247-2d0101ab18d1");
Ch8DataContext context = new Ch8DataContext();
IEnumerable<Book> query =
context.GetBook(bookId,
System.Threading.Thread.CurrentPrincipal.Identity.Name);
Returning results from a stored procedure is as easy as calling the generated method passing in the appropriate values. The values we pass in are strongly typed. As long as the column names returned in the stored procedure’s result set correspond to the destination object type, the values will be automatically matched up. Note that the results of the stored procedure are returned as an IEnumerable<T> rather than IQueryable<T> type. Because we cannot consume the results of stored procedures in other server-side queries, there is no need to worry about the expression tree parsing required by IQueryable. We can, however, consume the results on the client in a LINQ to Objects query if we want.
Before moving on, let’s take a quick peek under the covers and see how the DataContext actually calls into the stored procedure. If we look at the generated Ch8.designer.cs file, we can see the underlying generated method call, as shown in listing 8.12.
Listing 8.12. Generated GetBook code to call the stored procedure

Implementation of the stored procedure proxies requires us to not only import the System.Data.Linq namespace, but also System.Data.Linq.Mapping and System.Reflection. For this method, we want to get a book that uses the given ID. We name our method GetBook ![]() and pass two parameters, a Guid called BookId and a string called UserName
and pass two parameters, a Guid called BookId and a string called UserName ![]() . The method will return an object typed ISingleResult<Book>. ISingleResult does not return a single object, but rather a single list of objects. If our stored procedure returned multiple result sets,
we would use IMultipleResult.
. The method will return an object typed ISingleResult<Book>. ISingleResult does not return a single object, but rather a single list of objects. If our stored procedure returned multiple result sets,
we would use IMultipleResult.
In order to map our method to the stored procedure, we need to specify a number of attributes.[1] The first attribute maps the Function called dbo.GetBook to this method by specifying the Name parameter.
1 We could use an external mapping file here as well. Attributes are used to facilitate explanation for the purpose of the text. Chapter 7 includes a full discussion of mapping options available with LINQ to SQL.
Next, we need to identify how we’re going to map the method’s parameters to the stored procedure’s parameters. We do this by decorating each method with a System.Data.Linq.Mapping.Parameter attribute. Once we have the mappings in place, all we need to do is call the method.
In order to call a stored procedure, the DataContext class includes a method called ExecuteMethodCall ![]() . We can use this method to return result sets, scalar values, or issue a statement to the server. Since we’ve already created
our method inside a class that inherits from DataContext, we can call the ExecuteMethodCall directly by calling into the DataContext base class itself.
. We can use this method to return result sets, scalar values, or issue a statement to the server. Since we’ve already created
our method inside a class that inherits from DataContext, we can call the ExecuteMethodCall directly by calling into the DataContext base class itself.
ExecuteMethodCall takes three parameters. The first parameter is the DataContext object instance that is calling it. The second parameter is a reference to the information about the method that is calling it. Using reflection, the MethodInfo needs to be passed in order for the framework to recognize our attributes and map them appropriately. Typically we can just set the first parameter to this and the second to MethodInfo.GetCurrentMethod.
The final parameter is a parameter array that takes a list of values. These remaining parameters are the actual values that we’ll be sending to our stored procedure. The order of the parameters must match the order in which they appear in the Parameter attributes in the method’s declaration. If they don’t match, a runtime exception will be thrown. Figure 8.3 shows the interfaces that ExecuteMethodCall returns.
Figure 8.3. Interfaces return as a result of ExecuteMethodCall
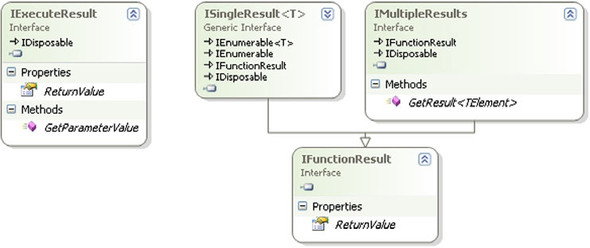
IExecuteResult exposes a ReturnValue of type Object and the ability to access parameter values to the parameters. If the procedure returns a list of objects that we can strongly
type, we’ll typically cast the ReturnValue as an ISingleResult<T> ![]() . If it can return different types based on internal processing, we would use the IMultipleResults implementation, which allows us to access a specific type via the generic GetResult<TElement> method.
. If it can return different types based on internal processing, we would use the IMultipleResults implementation, which allows us to access a specific type via the generic GetResult<TElement> method.
Retrieving data via stored procedures is not limited to returning tables and result sets. They can just as easily return scalar values. Listing 8.13 demonstrates consuming the BookCountForPublisher stored procedure to return the count of the books for a given publisher. We don’t return a result set, but rather rely on the return parameter, which contains the resulting count. As in the previous example, we call the procedure using the ExecuteMethodCall method of the DataContext.
Listing 8.13. Returning a scalar value
[Function(Name="dbo.BookCountForPublisher")]
public int BookCountForPublisher(
[Parameter(Name="PublisherId", DbType="UniqueIdentifier")]
System.Nullable<System.Guid> publisherId)
{
IExecuteResult result = this.ExecuteMethodCall(
this,
((MethodInfo)(MethodInfo.GetCurrentMethod())),
publisherId);
return ((int)(result.ReturnValue));
}
In this case, we retrieve our scalar value through the return parameter of our stored procedure. LINQ to SQL realizes that there are no result sets being sent back. Instead, it presents the value that the stored procedure returns as the ReturnValue of the result. All we need to do is cast the value to the appropriate type. The ReturnValue will change depending on what kinds of data the procedure returns. In listing 8.14, we consume this method as we would any other method.
Listing 8.14. Consuming a scalar stored procedure
Guid publisherId = new Guid("851e3294-145d-4fff-a190-3cab7aa95f76");
Ch8DataContext context = new Ch8DataContext();
Console.WriteLine(String.Format("Books found: {0}",
context.BookCountForPublisher(publisherId).ToString()));
The fetching examples shown here are admittedly rudimentary. In actuality, we could perform the same queries using standard LINQ to SQL and avoid the need to define our own custom stored procedures. Depending on the application’s business needs, directly accessing the table may be fine. Other business situations require the use of stored procedures for accessing data to meet security, performance, or auditing needs or to otherwise perform more advanced server-side processing before returning the results. Few changes are necessary to call stored procedures for these operations.
Updating data with stored procedures
Updating data is perhaps a more frequent use of stored procedures. Because a user making changes to data often requires more complex logic, security, or auditing, applications frequently rely on stored procedures to handle the remainder of the CRUD operations. As we’ve observed already, LINQ to SQL covers some of the same concerns that lead many applications to use stored procedures. In many cases, the dynamic SQL created by calling SubmitChanges on the DataContext is sufficient. In other cases, using stored procedures is still necessary.
If the use of stored procedures for updating data is required, using it is almost as easy as fetching records. However, we’ll no longer be able to take advantage of the dynamic optimization that LINQ provides by only updating changed columns. Additionally, we’ll be responsible for handling concurrency conflicts explicitly. Let’s take look at what we need to do to replace the standard LINQ update method for our Author class.
In listing 8.15 we see the definition of the stored procedure we can create to handle the update for the Author class. To illustrate how we can add additional functionality using stored procedures, this procedure will not only update the Author table, but also insert a record into the AuditTracking table.
Listing 8.15. Stored procedure to update an Author
CREATE PROCEDURE [dbo].[UpdateAuthor] @ID UniqueIdentifier output,-- Save values UPDATE dbo.Author
SET LastName=@LastName, FirstName=@FirstName, WebSite=@WebSite WHERE ID=@ID AND [TimeStamp]=@TimeStamp SELECT @RecordsUpdated=@@RowCount
IF @RecordsUpdated = 1 BEGIN
-- Add auditing record INSERT INTO dbo.AuditTracking (TableName, UserName, AccessDate) VALUES ('Author', @UserName, GetDate()) END RETURN @RecordsUpdated
This script is fairly standard. In it, we define a parameter for each value we’re going to update ![]() . Since we’re using a timestamp column
. Since we’re using a timestamp column ![]() , we don’t need to send the original values for each column as well. This will help to optimize our network bandwidth to the
server. We also declare an internal parameter called @RecordsUpdated that will help us track whether records were updated
, we don’t need to send the original values for each column as well. This will help to optimize our network bandwidth to the
server. We also declare an internal parameter called @RecordsUpdated that will help us track whether records were updated ![]() . If no records are updated, we’ll assume that there is a concurrency problem. Once we set up our values, we can try to call
the update method
. If no records are updated, we’ll assume that there is a concurrency problem. Once we set up our values, we can try to call
the update method ![]() . Immediately after calling the update, we need to get the number of rows that were changed
. Immediately after calling the update, we need to get the number of rows that were changed ![]() . If we wait, @@RowCount will not return a reliable result.
. If we wait, @@RowCount will not return a reliable result.
If records are updated, we add a record to our tracking table ![]() . We don’t care about tracking changes that aren’t successful. At the end, we make sure to return the number of rows updated
so that our client code can raise a concurrency exception if necessary
. We don’t care about tracking changes that aren’t successful. At the end, we make sure to return the number of rows updated
so that our client code can raise a concurrency exception if necessary ![]() .
.
With this code in place, we can create a method in our DataContext class that will consume the procedure (see listing 8.16). We can create this method manually or using the designer by dragging our stored procedure into the method pane. Here we see custom code that supplies additional information.
Listing 8.16. Consuming the update stored procedure using LINQ
[Function(Name="dbo.UpdateAuthor")]
The basic pattern we use in this update method is almost identical to the one we used when accessing data. We start by defining
our method, decorating it with the Function attribute ![]() and its parameters with the Parameter attribute
and its parameters with the Parameter attribute ![]() so that we can map them to our stored procedure and the stored procedure’s parameters. Since our procedure needs the name
of the current user in order to perform the logging, we include it as well. We check to see if it is populated, and if not,
set it to the currently logged-in user
so that we can map them to our stored procedure and the stored procedure’s parameters. Since our procedure needs the name
of the current user in order to perform the logging, we include it as well. We check to see if it is populated, and if not,
set it to the currently logged-in user ![]() .
.
The meat of the method follows. Here we call ExecuteMethodCall to access the database ![]() . As we did before, we pass the instance of the DataContext and the calling method’s MethodInfo so that ExecuteMethodCall will be able to determine the appropriate mappings. We follow that with a parameter array of the values that we’re sending to the database. Make sure to keep the order of the parameters in the method signature identical to the order
in the parameter array.
. As we did before, we pass the instance of the DataContext and the calling method’s MethodInfo so that ExecuteMethodCall will be able to determine the appropriate mappings. We follow that with a parameter array of the values that we’re sending to the database. Make sure to keep the order of the parameters in the method signature identical to the order
in the parameter array.
ExecuteMethodCall will return the return value from our stored procedure as part of its result. We check this ReturnValue, making sure to cast it to an integer ![]() . In order to check for concurrency issues, we determine whether any records were updated. If not, we throw a ChangeConflictException so that our client code can handle the concurrency exception. This first implementation of UpdateAuthor does the dirty work of calling the stored procedure.
. In order to check for concurrency issues, we determine whether any records were updated. If not, we throw a ChangeConflictException so that our client code can handle the concurrency exception. This first implementation of UpdateAuthor does the dirty work of calling the stored procedure.
If we want to automatically use this procedure in place of the run-time generated method whenever we update this table, we create a second method with a special signature as shown in listing 8.17.
Listing 8.17. UpdateT(T instance) method to replace the run-time implementation
private void UpdateAuthor(Author instance)
{
this.UpdateAuthor(instance.ID,
instance.LastName, instance.FirstName,
instance.WebSite, null, instance.TimeStamp);
}
}
In the UpdateAuthor(Author instance) method, we use a predefined signature designating that this method be used to update records on this object type rather than creating the update method dynamically. If we define methods in our DataContext with the following signatures, they will be used instead of the dynamic SQL: InsertT(T instance), UpdateT(T instance), and DeleteT(T instance). In this case, since we’re updating an Author instance, we define our method as UpdateAuthor(Author instance). If we have a method with this signature in the context attached to the objects we’re updating, it will be called when SubmitChanges is called on that DataContext instance rather than dynamically creating the update SQL statement.
So far, we’ve demonstrated coding the procedures manually. In many cases, it may be easier to at least start with the designer and then use the generated code to learn now to do it manually. In figure 8.4, we show the Visual Studio designer again. This time, pay attention to each of the four panes: the Server Explorer, both sides of the Method pane, and the Properties window. To generate a method from a stored procedure, we simply drag and drop the procedure in question from the Server Explorer into the Method pane. The generated method’s signature will appear.
Figure 8.4. LINQ to SQL Designer to map stored procedures to the data context as methods
Once we’ve added the stored procedures, we can configure the custom Insert, Update, and Delete methods. Click on the Author class in the Method pane and observe the Properties window. Entries for each of these custom procedure functions will appear. If we select the Update property, we can click on a button that opens the designer shown in figure 8.5. Alternatively, right-click the class in the designer and select Configure Behavior.
Figure 8.5. Update procedure designer window to assign the custom stored procedures with CRUD operations
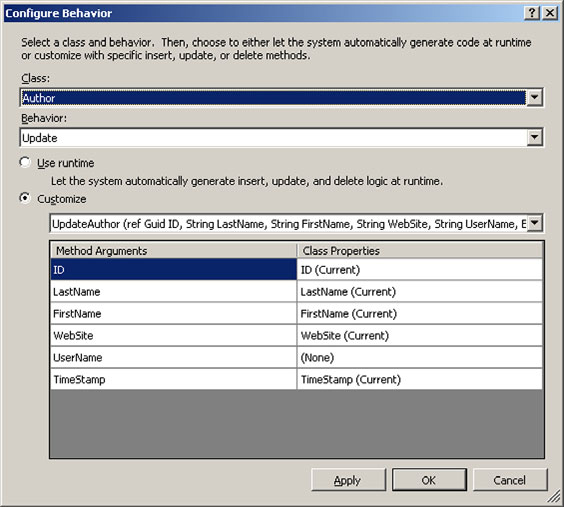
By default, the behavior for the methods is set to Use Runtime. As long as it is set to Use Runtime, the DataContext will dynamically generate the Insert, Update, and Delete methods and issue them directly against the tables. To change the functionality, select the Customize option for the behavior you wish to replace. From the drop-down option under Customize, select the desired method. If the stored procedures are already defined, they can be selected at this point. Once set, the mapping of the method arguments can be customized. In the case of this method, we’ll leave the class property for the UserName set to None and then set it in our actual implementing method.
Be aware that if we want to make changes to the implementation, they need to be done in the partial class and not in the designers. Any changes made to the .designer.cs file will be overwritten as the designers regenerate the code due to other changes. In this example, we did the implementation in a partial class definition of the data context in order to specify the user name based on the current thread’s identity.
Traditionally, stored procedures make up the bulk of the custom database code when working with SQL Server. In fact, there are a number of books and best practice guides that argue in favor of limiting all database access to go through stored procedures rather than allowing direct access to the underlying tables. Familiarity with the technology and business requirements will help determine whether stored procedures are still necessary for individual applications or whether the native LINQ to SQL behavior is sufficient.
The functionality offered by SQL server does not stop with stored procedures. It also offers the ability to define user-defined functions that can return both scalar values and tables. The next section explores the capabilities that these offer.
8.2.3. User-defined functions
Many data-centric applications currently limit themselves to tables and stored procedures for data access. An additional area that may offer benefits and is easier to use than stored procedures is user-defined functions. The two main flavors of user-defined functions are scalar and table-valued functions. Scalar functions return a single value, which is handy for quick lookup translations. Table-valued functions return results that can be consumed as if they were returned by the table directly. Similar to stored procedures, additional functionality can be added to the function within certain limitations. Unlike stored procedures, you can reuse the return results natively on the server as part of other server-side queries. When building new components and applications, consider how user-defined functions may offer additional functionality and flexibility over stored procedures for fetching results.
To see how we can use user-defined functions, let’s revisit our stored procedure from listing 8.13, which returned the count of books by publisher. To begin, we need to establish the function that we’re going to use. To avoid naming conflicts, we’ll name our database function fnBookCountForPublisher. (See listing 8.18.)
Listing 8.18. User-defined scalar function
CREATE FUNCTION dbo.fnBookCountForPublisher
( @PublisherId UniqueIdentifier )
RETURNS int
AS
BEGIN
DECLARE @BookCount int
SELECT @BookCount = count(*)
FROM dbo.Book
WHERE dbo.Book.Publisher=@PublisherId
Return @BookCount
END
The definition of the function is nearly identical to the one we used in listing 8.13. Most of the differences are syntactic. Instead of focusing on the differences in the server implementation, we’ll concentrate on the differences in the LINQ code. Luckily, the differences are relatively minor. Using the LINQ to SQL Designer, we can drag our new function onto the design surface and the function will appear in the right column. Once we save the changes in the designer, we can take a peek at the generated code, as shown in listing 8.19.
Listing 8.19. LINQ code generated for the scalar function
[Function(Name = "dbo.fnBookCountForPublisher",
IsComposable = true)]
public int? fnBookCountForPublisher1(
[Parameter(Name = "PublisherId")] Guid? publisherId)
{
return (int?)(this.ExecuteMethodCall(
this,
((MethodInfo)(MethodInfo.GetCurrentMethod())),
publisherId).ReturnValue);
}
Comparing the client code in listings 8.13 and 8.19, we see that they are very similar. We execute the function the same way we did with the stored procedure, using the ExecuteMethodCall of the DataContext instance and returning the ReturnValue.
The key change between functions and stored procedures is the use of the IsComposable attribute on the method signature. With functions, we set this to True. By doing this, we can use the function within a LINQ query and the call will be executed on the server. With the function translated to the server, consider the results of the sample in listing 8.20.
Listing 8.20. Using a scalar user-defined function in a query
var query =
from publisher in context.GetTable<Publisher>()
select new
{
publisher.Name,
BookCount = context.fnBookCountForPublisher(publisher.ID)
};
Checking the generated SQL statement, we can see that the function is translated to run directly on the server rather than the client as we iterate over each result.
SELECT Name, CONVERT(Int, dbo.fnBookCountForPublisher(ID)) AS value FROM Publisher AS t0
If it weren’t for the composability that LINQ and deferred execution offer, the query would need to return the list of publishers to the client and then issue separate function calls to the database to evaluate each row. Due to LINQ’s composability, the entire query is executed directly on the server. As a result, we minimize round-trips to the database and maximize performance due to optimized execution plans on the server.
Returning a table is similar. Consider a business situation where we want to horizontally partition our book table by publishers. Suppose we don’t want users to have direct access to fetch all records from the table, only the records for their publisher code. But we still want to work with the results as a table for query purposes. In that case, we could create different views for each publisher and configure security based on those views. Alternatively, our sample database includes a table-defined function to return the books based on their publisher ID. We consume this using the code shown in listing 8.21.
Listing 8.21. Defining and consuming a table-valued function
[Function(Name = "dbo.fnGetPublishersBooks",
IsComposable = true)]
public IQueryable<Book> fnGetPublishersBooks(
[Parameter(Name = "Publisher", DbType = "UniqueIdentifier")]
System.Nullable<System.Guid> publisher)
{
return this.CreateMethodCallQuery<Book>(
this,
((MethodInfo)(MethodInfo.GetCurrentMethod())),
publisher);
}
In this example, the SQL function returns a table rather than a single value. We send a single parameter—publisher—and return all books that are assigned to the given publisher. In order for LINQ to consume this function, we need to set up our familiar mappings for the function and the parameters. Instead of calling ExecuteMethodCall, we use a new method on the context—CreateMethodCallQuery<T>. The main distinction between these two methods is the fact that CreateMethodCallQuery returns an IQueryable rather than just IEnumerable, which allows us to compose larger expression trees. As a result, we can use this result just as we would any other LINQ to SQL table. Listing 8.22 illustrates how we can use both of our user-defined functions within a single LINQ query to return an anonymous type of the name of a book along with how many other books are published by that publisher.
Listing 8.22. Consuming user-defined functions
Guid publisherId = new Guid("855cb02e-dc29-473d-9f40-6c3405043fa3");
var query1 =
from book in context.fnGetPublishersBooks(publisherId)
select new
{
book.Title,
OtherBookCount =
context.fnBookCountForPublisher(book.Publisher) - 1
};
In this code, we consume both the fnPublishersBooks and the fnBookCountForPublisher methods that we set up previously. Executing this query results in the following SQL expression:
SELECT Title,
CONVERT(Int, dbo.fnBookCountForPublisher(Publisher)) - @p1 AS value
FROM dbo.fnGetPublishersBooks(@p0) AS t0
We can consume functions in much the same way as we consume data from tables. Functions offer the added benefit of allowing custom logic to be run on the server in conjunction with fetching the data. Functions also offer the added benefit that they can be used inside queries, both on the server and when using LINQ on the client. The power and flexibility of functions make them a viable alternative to stored procedures and views when designing LINQ-enabled applications.
At this point, we’ve explored how LINQ to SQL handles working with the major portions of the database engine. These capabilities allow us to perform operations on tables, views, stored procedures, and user-defined functions.
We’ve been focusing not on the database capabilities, but rather on alternative methods of programmatically accessing the data in a client or business tier. At this point, we’ll move from looking at LINQ to SQL in the database-centric mode and instead focus on the advanced options available from an object-oriented perspective on the business and/or client tier.
8.3. Improving the business tier
When working on the business tier, we begin to focus on areas of performance, maintainability, and code reuse. This section looks at some of the advanced functionality LINQ to SQL offers in these areas. We begin by focusing on improving performance by caching the frequently used query structures. We continue by looking at three options for improving maintainability and reuse through the use of partial classes, partial methods, and object inheritance. Obviously we’ll only be able to scratch the surface of the later topics, as they are often subjects of complete books in themselves.
8.3.1. Compiled queries
Any time complex layers are added, performance can potentially decrease. The architectural dilemma when designing systems is determining the trade-off between performance and maintainability. Working with LINQ is no exception. There is overhead in determining the translation between the LINQ query syntax and the syntax the database understands. This translation requires reflecting on the mapping metadata, parsing the query into an expression tree, and constructing a SQL string based on the results.
With queries that will be performed repeatedly, the structure can be analyzed once and then consumed many times. To define a query that will be reused, use the CompiledQuery.Compile method. We recommend using a static field and a nonstatic method to the data context. Instead of returning a value type or simple class, this method will return a generic function definition. Listing 8.23 demonstrates creating a precompiled query to return expensive books. In this case, we can pass in a threshold amount, which we’ll call minimumPrice. We can use this minimumPrice parameter to determine what constitutes an expensive book. The entire query structure will be precompiled with the exception of the value of the parameter. All the runtime will need to do is specify the DataContext instance and the value of the minimumPrice, and the compiled query will return the list of books that meet the criteria.
Listing 8.23. Precompiling a query
public static Func<CustomContext, decimal, IQueryable<Book>>
Listing 8.23 includes the two new members. The first, ExpensiveBooks, is a static field that contains the compiled query definition ![]() . The second method acts as a helper method to encapsulate the call to ExpensiveBooks, passing in the containing DataContext instance
. The second method acts as a helper method to encapsulate the call to ExpensiveBooks, passing in the containing DataContext instance ![]() . The real work is done in the first method. The function stored in ExpensiveBooks defines a signature that takes a Ch8DataContext and a decimal as input parameters and returns an object that implements the generic IQueryable<Book> interface.
. The real work is done in the first method. The function stored in ExpensiveBooks defines a signature that takes a Ch8DataContext and a decimal as input parameters and returns an object that implements the generic IQueryable<Book> interface.
We define the function as the result of System.Data.Linq.CompiledQuery. Compile. Compile takes a lambda expression defining our query. It evaluates the structure and prepares the function for use. Since the function is defined as static, it will be evaluated only once in the lifetime of our AppDomain. After that, we’re free to use it as much as we want without worrying about most of the evaluation overhead.
Any time we want to fetch the listing of expensive books, we can call the GetExpensiveBooks method. The framework no longer needs to reevaluate the mappings between the database and the objects, nor will it need to parse the query into an expression tree. This work has already been done.
If you’re unsure of the impact of using compiled queries, read the series of posts by Rico Mariani beginning with http://blogs.msdn.com/ricom/archive/2007/06/22/dlinq-linq-to-sql-performance-part-1.aspx. He shows how using a compiled query offers nearly twice the performance of noncompiled queries and brings the performance to within 93 percent of using a raw DataReader to populate objects. As LINQ continues to evolve, there will continue to be more performance enhancements.
The other business tier components that we’ll discuss are less focused on performance and more focused on code maintainability and reuse. The fine art of programming is all about making trade-offs between these two areas. Often a small performance penalty is outweighed by greatly increased maintainability.
8.3.2. Partial classes for custom business logic
Using object-oriented programming practices adds functionality to the business domain by taking base object structures and extending them to add the custom business logic. Prior to .NET 2.0, the main way to extend those structures was by inheriting from a base class. With .NET 2.0, Microsoft introduced the concept of partial classes. With partial classes, we can isolate specific functionality sets in separate files and then allow the compiler to merge them into a single class. The usefulness of partial classes is particularly evident when dealing with generated code.
By default, both of the automated generation tools we’ve explored (the designer and SqlMetal) generate the class definitions as partial classes. As a result, we can use either tool to dynamically generate our entities and enforce customized business logic in separate classes. Let’s explore a simple use case that will entail adding a property to concatenate and format the author’s name based on the existing properties in the Author object.
In chapter 7, we defined the mapped version of our Author class. When we defined it manually, we set it up as public class Author. When we later let the tools generate our Author class, they defined it as a partial class. Because it was created as a partial class, we can create a second class file to define the other part. Listing 8.24 shows the code to add functionality to our Author class by using a partial class definition.
Listing 8.24. Adding functionality with partial classes
public partial class Author
{
public string FormattedName
{
get { return this.FirstName + ' ' + this.LastName; }
}
}
The code in listing 8.24 is not earth-shattering, but shows how easy it is to add customized logic to an existing class in our project. This is particularly important if the mapping portion of the class is going to be regenerated by Visual Studio. Some other areas that already use the partial code methodology within Visual Studio include the WinForms and ASP.NET designers. In both cases, Microsoft split the functionality between two files to keep the development focused on the custom business logic and hide the details and fragility of the designer-generated code.
With the combined class, we can now create a LINQ query leveraging both the mapped class and our new FormattedName property as shown in listing 8.25. Be aware that you cannot project into an anonymous type containing an unmapped property. Thus we have to select the entire Author object in the Select clause when working with LINQ to SQL.
Listing 8.25. Querying with a property from the partial class
var partialAuthors = from author in context.Authors
select author;
Note that our client code is oblivious to the fact that the portions are defined in separate files. We just consume it as if it were defined as a standard class.
Partial classes are not limited to adding simple calculated fields. We can include much more functionality than that. As an example, consider the ability to extend a class by implementing an interface in the partial class. Listing 8.26 shows some sample code that we could use to implement the IDataErrorInfo interface.
Listing 8.26. Implementing IDataErrorInfo in the custom partial class
partial class Publisher : System.ComponentModel.IDataErrorInfo
{
private string CheckRules(string columnName)
{
//See the download samples for the implementation
//All rules are ok, return an empty string
return string.Empty;
}
#region IDataErrorInfo Members
public string Error
{
get { return CheckRules("Name") +
CheckRules("WebSite"); }
}
public string this[string columnName]
{
get { return CheckRules(columnName); }
}
#endregion
}
IDataErrorInfo is used by the ErrorProvider in WinForm applications to provide immediate feedback to the user that an object doesn’t meet a set of business logic. The implementation in this example is not intended to be a full-featured rules management application, only to demonstrate the possibilities that arise by leveraging the partial class implementation.
In this case, we can centralize the business logic of our class to a single CheckRules method ![]() . Then whenever the UI detects a change in the business object, it checks the validity of the object and the changing property.
If the resulting string returned from the Error or the column name indexer contains values, an error icon is displayed as shown in figure 8.6.
. Then whenever the UI detects a change in the business object, it checks the validity of the object and the changing property.
If the resulting string returned from the Error or the column name indexer contains values, an error icon is displayed as shown in figure 8.6.
Figure 8.6. DataGridView for editing Publishers implementing IDataErrorInfo in the partial class
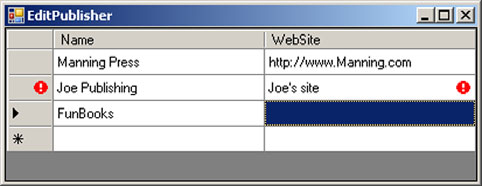
In this grid, the rules we place in the CheckRules method are checked as users change values. If the user-supplied value does not agree with the business rules, the user is shown a nonintrusive notification that he needs to change his value. The key thing to take away here is that we can use the LINQ to SQL Designer to generate our business class and put our logic in the partial class implementation.
When we need to regenerate our entities, the business functionality will be retained. When we compile our application, the compiler combines the generated code with our custom code into a single class definition.
Partial classes were introduced as a way to add physically separate methods into isolated files. If we want to optionally inject functionality within a given generated method, it does not give us the hooks that we could use. C# 3.0 and VB 9.0 include a new language feature called partial methods to allow injecting functionality within a method.
8.3.3. Taking advantage of partial methods
Typically when working with business entities, we need to provide additional processing as part of a constructor or during a property change. Prior to C# 3.0 and VB 9.0, we would need to create base abstract classes and allow our properties to be overridden by implementing classes. Such a class would then implement the desired custom functionality. As we’ll discuss briefly, using this form of inheritance can be problematic with LINQ to SQL due to the inheritance implementation model. Thankfully, C# 3.0 and VB 9.0 bring us the option of partial methods.
With partial methods, we can insert method stubs into our generated code. If we implement the method in our business code, the compiler will add the functionality. If we don’t implement it, the complier will remove the empty method. Listing 8.27 shows some of the partial methods that the LINQ to SQL Designer and SqlMetal insert into our class definitions and how we can take advantage of them.
Listing 8.27. Partial signature of the generated class including partial methods


For the Publisher object and most of the entities generated by the LINQ to SQL tools, you’ll find a number of method stubs that allow you to
inject functionality ![]() . In this example, if we wanted to perform some initialization on our properties, we could add that by implementing an OnCreated method as follows:
. In this example, if we wanted to perform some initialization on our properties, we could add that by implementing an OnCreated method as follows:
partial void OnCreated()
{
this.ID = Guid.NewGuid();
this.Name = string.Empty();
this.WebSite = string.Empty();
}
With the OnCreated method implemented, we can now make sure that we initialize our values as the object is being instantiated. If we wanted, we could also take the opportunity to hook the PropertyChanging and PropertyChanged events to a more robust rules engine or change-tracking engine (like the one the DataContext includes).
Speaking of property changing, the generated code offers two partial method stubs in each property set that allow us to perform actions both before and after a given property is changed. This would allow us to implement a change-tracking system or other business logic based on the user input.
Remember, if we don’t implement the partial methods, they will not clutter up the compiled business object with needless processing cycles. They are helpful otherwise to allow beneficial extensibility points for injecting custom business logic.
Partial classes and methods offer powerful abilities to extend otherwise generic entities. However, more defined customized logic for related object instances often requires a more polymorphic inheritance model. For example, in cases where we have different kinds of users, we would want to have a base user type and then inherit from that to provide the additional functionality of each specific user type. Naturally, LINQ to SQL offers this kind of polymorphic inheritance behavior.
8.3.4. Using object inheritance
As with .NET, LINQ has objects and OOP at its heart. One of the pillars of OOP is the ability to inherit from base classes and extend the functionality based on customized business needs. Frequently, inheriting objects extend base classes by exposing new properties. As long as the needed properties are contained in the same table as the base class, LINQ to SQL supports mapping the specialized objects. For this section, we’ll continue extending our running example. In this case, we’ll consider the users of the system.
When we started, we only had a single user object that contained the user name and an ID. We may find as we work that we want to have some specialized users with additional functionality. In particular, we may want to give Authors and Publishers special rights to be able to edit information that applies to them. Other users would have more restrictive rights. In order to link users with their roles, we could add columns to the User table to specify the Publisher’s and Author’s IDs. We’ll set both of these as Nullable, as users that are not one of the specialized types won’t have values in these fields. Figure 8.7 shows a representative set of the revised User table to support these specialized user types.
Figure 8.7. User table sample data to support inheritance based on the distinguishing UserType column
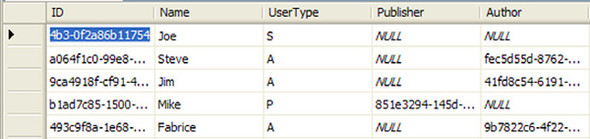
In our new table, we’ve added three columns. The last two columns contain the foreign key values of the ID columns in the Publisher and Author tables respectively. The additional column UserType identifies what kind of user the row represents. In our case, if the type is A, the user is an Author. If it is P the user is a Publisher. Standard users are designated with S as their UserType. In the sample data, the first user is a standard user and doesn’t have a publisher or author foreign key value. Mike is a publisher and has a Publisher foreign key. The other users are all authors and include the appropriate Author foreign key.
With this structure in mind, we can think about how we want to model our objects to reflect the new table structure. Since we have three types of users, we’ll have three classes to represent the different behavior of each user. We’ll call the standard user UserBase, as it will serve as the base user type for the other two types. The other users we’ll call AuthorUser and PublisherUser. Each of these custom user types will inherit from UserBase. Figure 8.8 shows the full object structure.
Figure 8.8. LINQ to SQL Designer with inherited users
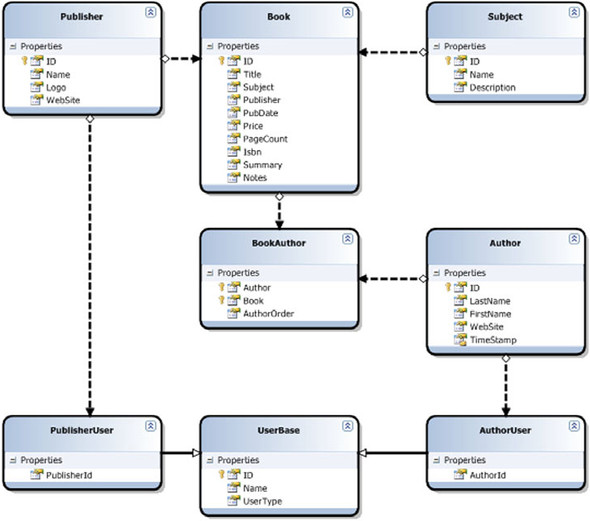
We begin building our structure by opening the LINQ to SQL Designer. In the designer, add the Publisher, Book, BookAuthor, and Author tables by dragging them from the Server Explorer to the design surface. To add the users, drag the modified User table to the design surface. Since our UserBase object will not include the fields for the customized objects, remove the Author and Publisher properties from the User object. From the Properties window, change the Name of the User object to UserBase.
Once our UserBase class is configured, we need to add our two customized user objects. To do this, drag two new objects onto the design surface from the toolbar. Name the first one PublisherUser and the second one AuthorUser. In the PublisherUser object, right-click the Properties heading and select Add, then Property. Set the Name of the property to PublisherId. Set the Source property to the Publisher column of the table. Do the same for the AuthorUser object, but this time, name the property AuthorId and set the source to the Author column.
With your classes defined, click on the Inheritance tool in the toolbox. Drag an inheritance line from the PublisherUser to the UserBase class. The inheritance arrow will appear in the designer. Do the same again to set up the inheritance between AuthorUser and UserBase.
We’re almost done setting up our inheritance model. At this point, we need to identify which object type we want to load for each row in our table. For example, if we load a User with a UserType of A, we should get an instance of the AuthorUser instead of just the simple UserBase instance. To do so, we need to enhance our mappings. We could do this by adding more attributes to our class definition indicating the InheritanceMapping value. Since we’re making these modifications using the designer, let’s see how we can do it from there.
To specify the mapping, select the inheritance arrow line between the PublisherUser and UserBase and open the Properties window. The Properties window has four values: Base Class Discriminator, Derived Class Discriminator, Discriminator Property, and Inheritance Default. Let’s start by setting the Discriminator Property. This will identify which property in our base class indicates which type of object to instantiate. Our UserBase class maintains this in the UserType property, so set the Discriminator Property to UserType. The Base Class Discriminator is used to indicate what value in the UserType will be used for objects of UserBase. In our case, that will be the Standard user, so we’ll add the value S. The next property is for the Derived Class Discriminator. Since we want to load the PublisherUser when the UserType is P, enter the value P for this property. From this window, we can also specify that the default class implementation is the UserBase class when no match can be found on the discriminator.
We have one final step. We need to identify under which circumstances we want to instantiate the AuthorUser object. Similar to PublisherUser, we click the arrow between the AuthorUser and UserBase classes and open the Properties window. Notice this time, since we already assigned the Base Class Discriminator, Discriminator Property, and Inheritance Default, these values are retained. All we need to do is set the Derived Class Code. Since we want AuthorUsers loaded when the type is A, enter the value A. With the inheritance mappings set, save the changes to the designer. Viewing the generated code in the .designer.cs file shows the attributes that were added to your class definition.
[InheritanceMapping(Code="S", Type=typeof(UserBase), IsDefault=true)]
[InheritanceMapping(Code="A", Type=typeof(AuthorUser))]
[InheritanceMapping(Code="P", Type=typeof(PublisherUser))]
[Table(Name="dbo.[User]")]
Public partial class UserBase
{
//Implementation code omitted
}
The runtime relies on the attributes (or the XML mapping file) to indicate which objects to load. In addition to the InheritanceMapping attributes defined on the class, there is one other parameter we set when we made the changes in the designer. The attribute in question is not on the table, but on the UserType’s Column attribute. Note that the IsDiscriminator parameter is now set to true.
[Column(Storage="_UserType", IsDiscriminator=true)] public char UserType
As we fetch records, LINQ to SQL will check the property decorated by the IsDiscriminator attribute. It will then compare the underlying value against the list of InheritanceMapping codes in the base class to determine which type to instantiate. With this value set, we’ve completed the necessary steps to create our inheritance trees.
Before we consume our new inherited objects, let’s use the designer to establish one more set of relationships. At this point, we can use the designer to assign associations between the Publisher and Author objects and our newly customized AuthorUser and PublisherUser objects. This will allow us to drill into the object hierarchies even though we don’t have foreign key indexes associated between the tables in our database. The designer makes adding this functionality a breeze. Select the Association tool from the toolbox. Click on the ID property of the Author class, followed by the AuthorId property of the AuthorUser. Do the same for the Publisher and PublisherUser. The designer should now look something like the illustration we started with in figure 8.4.
We’re done with the changes to our designer. Let’s move on to actually using our hard work. Listing 8.28 demonstrates several ways we can access our user lists.
Listing 8.28. Consuming inherited LINQ to SQL objects
var query =
In the first example ![]() , we can select all users from our user table regardless of the implementing type. We can iterate over the list even though
each row is represented by a different object type because each of the objects inherits from the same UserBase class. Here is the SQL that is generated for this first query:
, we can select all users from our user table regardless of the implementing type. We can iterate over the list even though
each row is represented by a different object type because each of the objects inherits from the same UserBase class. Here is the SQL that is generated for this first query:
SELECT [t0].[Name] FROM [dbo].[User] AS [t0]
In the second query, we limit the records we want to retrieve based on the object type. To fetch just the AuthorUser objects (where the UserType=A) we can use strong typing and specify we only want users where the implementing type is AuthorUser in the where clause ![]() . The final example illustrates another method of filtering. In this case, we use the OfType extension method to retrieve only objects that match the PublisherUser type
. The final example illustrates another method of filtering. In this case, we use the OfType extension method to retrieve only objects that match the PublisherUser type ![]() . Since we’re selecting just the user name, both of these queries result in the same generated SQL:
. Since we’re selecting just the user name, both of these queries result in the same generated SQL:
SELECT [t0].[Name] FROM [dbo].[User] AS [t0] WHERE [t0].[UserType] = @p0
One thing to keep in mind, if you have columns that apply to some derived classes but not others, they need to be marked as Nullable in the database. Otherwise, updating values in the table on objects that don’t implement those properties will throw an exception because the values were not supplied.
We’ve only scratched the surface of the capabilities that inheritance can offer. As long as the data is limited to a single table, implementing inheritance with LINQ to SQL is relatively painless. The InheritanceMapping attributes on the base class and Discriminator column on the table are all that we need.
The inheritance model supported by LINQ to SQL does suffer from a couple of weaknesses. First, the runtime requires that the base class of the object hierarchy include the definition for the base table mappings. Thus, using a base framework for business objects may limit the ability to define mappings in the base class implementation, as each object will likely come from a different table.
The second weakness in the LINQ to SQL inheritance model lies in the fact that the columns for the object’s properties cannot cross multiple tables. It is not uncommon to have a set of database entities where a portion of the data, like a postal address, is included in a referential table. This may be fine from a relational database perspective, but including the address information within the entity class may fit better with the business model. Alternatively, the address information could be included within the same table as the entity’s data, but having a shared Address class could offer better maintainability due to code reuse. In both cases (1 class encompassing 2 tables, and 2 classes pointing to the same table) LINQ to SQL fails to support a direct mapping structure at this time.
In those cases, we need to look beyond LINQ to SQL and investigate another portion of the new data access stack—the ADO.NET Entity Framework, which is scheduled to ship after the rest of the LINQ technologies. At this point, let’s take a brief diversion into what this technology will offer us for more advanced mapping relationships.
8.4. A brief diversion into LINQ to Entities
In many cases, LINQ to SQL may serve the need for CRUD operations in our applications. As we’ve already pointed out, direct table access can be insufficient. To accommodate this, LINQ to SQL allows access to extra processing power via stored procedures and user-defined functions in the database. Other times, the business model requires more complex entity structures than are available with one-to-one table to object data mappings.
Frequently with larger database structures, the database will perform better with a more normalized structure. That normalized structure may or may not represent an optimal structure for our business entities. In those cases, we can flatten our table structures by using database views. Figure 8.9 illustrates such a case. In this example, we add one more table to our running database structure. This new table stores addresses. With it, we can store addresses for any number of associated tables. In figure 8.9, we show how the Address table can store information for both the Author and Publisher.
Figure 8.9. Adding a shared address table for both the Author and Publisher tables
Note
We’re not arguing here whether the schema shown in figure 8.9 is the best. We’re using it as an example. You need to determine how your data is best stored in terms of normalization.
In this example, we may want to store our data with the address information normalized into a separate table. However, our business entity may want to combine the author, user, and address information into a single class to reflect the full information about the Author in a single class. If we only want to view this flattened information, we could easily create a server view. The view would isolate the business from needing to remember how to join the tables.
The challenge with a view is that once flattened, the metadata needed in order to update records in the original tables is lost. In 1976, Dr. Peter Chen wrote a seminal paper outlining the theory of an entity-relationship model.[2] In it, he outlines a separation between the physical model (from the database) and the logical model (in the objects) by inserting a conceptual model.
In some ways, this conceptual model is similar to a view in that it can consolidate information from multiple sources. It goes beyond a view in several ways. First, unlike a view, the conceptual Entity Data Model (EDM) includes information about the source of the data so that the tools have enough information about the creation. This metadata indicates where the values came from and consequently where they will go when updated. Additionally, the EDM includes the ability to store both objects and relationships necessary to create fully dynamic object hierarchies in a conceptual model.
At the same time that the language teams were designing LINQ, the Microsoft data teams were working on implementing this conceptual model to handle these more complex entity structures. They are calling this technology the ADO.NET Entity Framework (EF). The EF separates the physical from the logical models by using a series of XML-based mapping files (see figure 8.10).
Figure 8.10. Layers of the Entity Framework
In the EF, the physical database is mapped to a logical model using a one-to-one relationship between the tables and logical layer entities. The logical entities are defined through an XML-based Store Schema Definition Language (SSDL) file. These mappings are similar to those we defined in LINQ to SQL.
The EF moves beyond LINQ to SQL by using another XML-based file (Mapping Schema Language or MSL) to map the logical model to a conceptual model. The conceptual model is yet another XML file using a Conceptual Schema Definition Language (CSDL). These conceptual entities can be further converted into strongly typed objects if desired.
With the EDM established, we can query it with a string-based query language called Entity SQL. In addition, our LINQ knowledge can be applied against the EDM by using LINQ to Entities. Since the EDM represents a true abstraction layer between the application and database, we can modify our database and EDM mapping file and restructure the data store without having to recompile the application.
The separation of layers we get from the EDM allows for an increased separation between the physical and logical. This allows us to change our data model and mapping structures and leave our application intact. Additionally, since the EF is built on top of the existing ADO provider model, the EF can work against data stores other than SQL Server. If you can’t wait for native LINQ support for other databases, you may want to look into the LINQ to Entities and the EF for your data access tier.
As of the writing of this book, the EF is scheduled to be released after the official release of the LINQ technologies. Due to the release schedule and the scope of the project itself, we’re unable to cover it with the sufficient attention it deserves. More information about the entity framework is available at http://msdn2.microsoft.com/en-us/data/aa937723.aspx.
8.5. Summary
LINQ to SQL offers the capability to manage the interaction between relational data stores and application logic based in objects through the object’s full life cycle. We no longer need to manually write hundreds of lines of ADO.NET plumbing code. In fact, with the supplied tools, most of the code can be automatically generated. Once the objects and mapping structures are established, we can work with the data using the same query syntax used in LINQ to Objects.
Because we set up the metadata about the source and destination of the data, we can let the framework manage the entire life cycle. Let’s summarize what we’ve covered in the past three chapters by stepping through the typical object life cycle. See figure 8.11.
Figure 8.11. LINQ to SQL sequence diagram
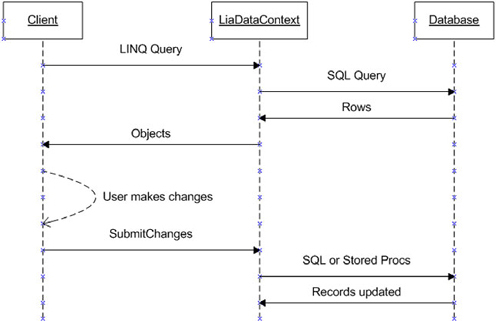
In the typical scenario, our objects are created when we first query them. The client defines a query using query syntax or method calls and passes the resulting expression tree to the DataContext. The DataContext parses the expression tree and translates it into a query syntax that the database understands. As we ask for results, the DataContext opens the connection to the database and fetches the rows. The rows returned from the database are translated into a collection of objects. As it evaluates the returned values, it checks them against the versions already in memory by checking the objects’ identities. If it has a copy of the object, it returns the copy the user has been working with. The resulting objects are then returned to our client to consume.
Note
In this case, we’re referring to the client in a generic sense. The client does not have to be a person or presentation layer. The client is anything that consumes the LINQ to SQL entities. This can include a SOA service or data access tier.
The process can end here by just displaying the resulting objects to the consumer. If necessary, the user can make changes to the objects and submit those changes back via the DataContext. The DataContext evaluates the submitted data and compares it against the change-tracking store to determine which values need to be sent back to the database. The DataContext packages these changes up and issues the appropriate statements back to the server either using parameterized queries or stored procedures. If it uses parameterized queries, it automatically manages concurrency control. If problems occur during the update, they are handled by the transaction mechanisms that are implicitly or explicitly defined. Once the data is committed, the cycle is ready to start all over again.
At this point, we should be equipped with the tools needed to use LINQ to work with relational data. As with any tool, the ability to use the tool will depend on how much it is used. We could spend several chapters going over numerous usage permutations, but it would be impossible to cover every situation. Before moving on to LINQ to XML in the next chapter, take some time to work with LINQ to SQL, try the examples included in this book, and then extend them to meet business needs. Increased familiarity will help you identify the capabilities of the tool and decide where it fits in your data access toolkit.