
In order to understand the usefulness of programmable Digital Signal Processing, I will first draw an analogy and then explain the special environments where DSPs are used.
A DSP is really just a special form of microprocessor. It has all of the same basic characteristics and components; a CPU, memory, instruction set, buses, and so on. The primary difference is that each of these components is customized slightly to perform certain operations more efficiently. We’ll talk about specifics in a moment, but in general, a DSP has hardware and instruction sets that are optimized for high-speed numeric processing applications and rapid, real-time processing of analog signals from the environment. The CPU is slightly customized, as is the memory, instruction sets, buses, and so forth.
I like to draw an analogy to society. We, as humans, are all processors (cognitive processors) but each of us is specialized to do certain things well; engineering, nursing, finance, and so forth. We are trained and educated in certain fields (specialized) so that we can perform certain jobs efficiently. When we are specialized to do a certain set of tasks, we expend less energy doing those tasks. It is not much different for microprocessors. There are hundreds to choose from and each class of microprocessor is specialized to perform well in certain areas. A DSP is a specialized processor that does signal processing very efficiently. And, like our specialty in life, because a DSP specializes in signal processing, it expends less energy getting the job done. DSPs, therefore, consume less time, energy, and power than a general-purpose microprocessor when carrying out signal processing tasks.
When you specialize a processor, it is important to specialize those areas that are commonly and frequently put to use. It doesn’t make sense to make something efficient at doing things that are hardly ever needed! Specialize those areas that result in the biggest bang for the buck!
However, before I go much further, I need to give a quick summary of what a processor must do to be considered a digital signal processor. It must do two things very well. First, it must be good at math and be able to do millions (actually billions) of multiplies and adds per second. This is necessary to implement the algorithms used in digital signal processing.
The second thing it must do well is to guarantee real time. Let’s go back to our real-life example. I took my kids to a movie recently, and when we arrived, we had to wait in line to purchase our tickets. In effect, we were put into a queue for processing, standing in line behind other moviegoers. If the line stays the same length and doesn’t continue to get longer and longer, then the queue is real-time in the sense that the same number of customers are being processed as there are joining the queue. This queue of people may get shorter or grow a bit longer but does not grow in an unbounded way. If you recall the evacuation from Houston as Hurricane Rita approached, that was a queue that was growing in an unbounded way! This queue was definitely not real time and it grew in an unbounded way, and the system (the evacuation system) was considered a failure. Real-time systems that cannot perform in real time are failures.
If the queue is really big (meaning, if the line I am standing in at the movies is really long) but not growing, the system may still not work. If it takes me 50 minutes to move to the front of the line to buy my ticket, I will probably be really frustrated, or leave altogether before buying my ticket to the movies (my kids will definitely consider this a failure). Real-time systems also need to be careful of large queues that can cause the system to fail. Real-time systems can process information (queues) in one of two ways: either one data element at a time, or by buffering information and then processing the “queue.” The queue length cannot be too long or the system will have significant latency and not be considered real time.
If real time is violated, the system breaks and must be restarted. To further the discussion, there are two aspects to real time. The first is the concept that for every sample period, one input piece of data must be captured, and one output piece of data must be sent out. The second concept is latency. Latency means that the delay from the signal being input into the system and then being output from the system must be preserved as immediate.
Keep in mind the following when thinking of real-time systems: producing the correct answer too late is wrong! If I am given the right movie ticket and charged the correct amount of money after waiting in line, but the movie has already started, then the system is still broke (unless I arrived late to the movie to begin with). Now go back to our discussion.
So what are the “special” things that a DSP can perform? Well, like the name says, DSPs do signal processing very well. What does “signal processing” mean? Really, it’s a set of algorithms for processing signals in the digital domain. There are analog equivalents to these algorithms, but processing them digitally has been proven to be more efficient. This has been a trend for many many years. Signal processing algorithms are the basic building blocks for many applications in the world; from cell phones to MP3 players, digital still cameras, and so on. A summary of these algorithms is shown in Table 8.1.
One or more of these algorithms are used in almost every signal processing application. Finite Impulse Response Filters and Infinite Impulse Response Filters are used to remove unwanted noise from signals being processed, convolution algorithms are used for looking for similarities in signals, discrete Fourier transforms are used for representing signals in formats that are easier to process, and discrete cosine transforms are used in image processing applications. We’ll discuss the details of some of these algorithms later, but there are some things to notice about this entire list of algorithms. First, they all have a summing operation, the function. In the computer world, this is equivalent to an accumulation of a large number of elements that is implemented using a “for” loop. DSPs are designed to have large accumulators because of this characteristic. They are specialized in this way. DSPs also have special hardware to perform the “for” loop operation so that the programmer does not have to implement this in software, which would be much slower.
The algorithms above also have multiplications of two different operands. Logically, if we were to speed up this operation, we would design a processor to accommodate the multiplication and accumulation of two operands like this very quickly. In fact, this is what has been done with DSPs. They are designed to support the multiplication and accumulation of data sets like this very quickly; for most processors, in just one cycle. Since these algorithms are very common in most DSP applications, tremendous execution savings can be obtained by exploiting these processor optimizations.
There are also inherent structures in DSP algorithms that allow them to be separated and operated on in parallel. Just as in real life, if I can do more things in parallel, I can get more done in the same amount of time. As it turns out, signal processing algorithms have this characteristic as well. Therefore, we can take advantage of this by putting multiple orthogonal (nondependent) execution units in our DSPs and exploit this parallelism when implementing these algorithms.
DSPs must also add some reality to the mix of these algorithms shown above. Take the IIR filter described above. You may be able to tell just by looking at this algorithm that there is a feedback component that essentially feeds back previous outputs into the calculation of the current output. Whenever you deal with feedback, there is always an inherent stability issue. IIR filters can become unstable just like other feedback systems. Careless implementation of feedback systems like the IIR filter can cause the output to oscillate instead of asymptotically decaying to zero (the preferred approach). This problem is compounded in the digital world where we must deal with finite word lengths, a key limitation in all digital systems. We can alleviate this using saturation checks in software or use a specialized instruction to do this for us. DSPs, because of the nature of signal processing algorithms, use specialized saturation underflow/overflow instructions to deal with these conditions efficiently.
There is more I can say about this, but you get the point. Specialization is really all it’s about with DSPs; these devices are specifically designed to do signal processing really well. DSPs may not be as good as other processors when dealing with nonsignal processing centric algorithms (that’s fine; I’m not any good at medicine either). Therefore, it’s important to understand your application and pick the right processor.
With all of the special instructions, parallel execution units, and so on designed to optimize signal-processing algorithms, there is not much room left to perform other types of general-purpose optimizations. General-purpose processors contain optimization logic such as branch prediction and speculative execution, which provide performance improvements in other types of applications. But some of these optimizations don’t work as well for signal processing applications. For example, branch prediction works really well when there are a lot of branches in the application. But DSP algorithms do not have a lot of branches. Much signal processing code consists of well-defined functions that execute off a single stimulus, not complicated state machines requiring a lot of branch logic.
Digital signal processing also requires optimization of the software. Even with the fancy hardware optimizations in a DSP, there is still some heavy-duty tools support required—specifically, the compiler—that makes it all happen. The compiler is a nice tool for taking a language like C and mapping the resultant object code onto this specialized microprocessor. Optimizing compilers perform a very complex and difficult task of producing code that fully “entitles” the DSP hardware platform.
There is no black magic in DSPs. As a matter of fact, over the last couple of years, the tools used to produce code for these processors have advanced to the point where you can write much of the code for a DSP in a high level language like C or C++ and let the compiler map and optimize the code for you. Certainly, there will always be special things you can do, and certain hints you need to give the compiler to produce the optimal code, but it’s really no different from other processors.
The environment in which a DSP operates is important as well, not just the types of algorithms running on the DSP. Many (but not all) DSP applications are required to interact with the real world. This is a world that has a lot of stuff going on; voices, light, temperature, motion, and more. DSPs, like other embedded processors, have to react in certain ways within this real world. Systems like this are actually referred to as reactive systems. When a system is reactive, it needs to respond and control the real world, not too surprisingly, in real-time. Data and signals coming in from the real world must be processed in a timely way. The definition of timely varies from application to application, but it requires us to keep up with what is going on in the environment.
Because of this timeliness requirement, DSPs, as well as other processors, must be designed to respond to real-world events quickly, get data in and out quickly, and process the data quickly. We have already addressed the processing part of this. But believe it or not, the bottleneck in many real-time applications is not getting the data processed, but getting the data in and out of the processor quickly enough. DSPs are designed to support this real-world requirement. High speed I/O ports, buffered serial ports, and other peripherals are designed into DSPs to accommodate this. DSPs are, in fact, often referred to as data pumps, because of the speed in which they can process streams of data. This is another characteristic that makes DSPs unique.
DSPs are also found in many embedded applications. I’ll discuss the details of embedded systems later in this chapter. However, one of the constraints of an embedded application is scarce resources. Embedded systems, by their very nature, have scarce resources. The main resources I am referring to here are processor cycles, memory, power, and I/O. It has always been this way, and always will. Regardless of how fast embedded processors run, how much memory can be fit on chip, and so on, there will always be applications that consume all available resources and then look for more! In addition, embedded applications are very application-specific, not like a desktop application that is much more general-purpose.
At this point, we should now understand that a DSP is like any other programmable processor, except that it is specialized to perform signal processing really efficiently. So now the only question should be; why program anything at all? Can’t I do all this signal processing stuff in hardware? Well, actually you can. There is a fairly broad spectrum of DSP implementation techniques, with corresponding trade-offs in flexibility, as well as cost, power, and a few other parameters. Figure 8.1 summarizes two of the main trade-offs in the programmable versus fixed-function decision: flexibility and power.

An application-specific integrated circuit (ASIC) is a hardware only implementation option. These devices are programmed to perform a fixed-function or set of functions. Being a hardware only solution, an ASIC does not suffer from some of the programmable von Neumann-like limitations, such as loading and storing of instructions and data. These devices run exceedingly fast in comparison to a programmable solution, but they are not as flexible. Building an ASIC is like building any other microprocessor, to some extent. It’s a rather complicated design process, so you have to make sure the algorithms you are designing into the ASIC work and won’t need to be changed for a while! You cannot simply recompile your application to fix a bug or change to a new wireless standard. (Actually, you could, but it will cost a lot of money and take a lot of time.) If you have a stable, well-defined function that needs to run really fast, an ASIC may be the way to go.
Field-programmable gate arrays (FPGAs) are one of those in-between choices. You can program them and reprogram them in the field, to a certain extent. These devices are not as flexible as true programmable solutions, but they are more flexible than an ASIC. Since FPGAs are hardware they offer similar performance advantages to other hardware-based solutions. An FPGA can be “tuned” to the precise algorithm, which is great for performance. FPGAs are not truly application specific, unlike an ASIC. Think of an FPGA as a large sea of gates where you can turn on and off different gates to implement your function. In the end, you get your application implemented, but there are a lot of spare gates laying around, kind of going along for the ride. These take up extra space as well as cost, so you need to do the trade-offs; are the cost, physical area, development cost, and performance all in line with what you are looking for?
DSP and μP (microprocessor): We have already discussed the difference here, so there is no need to rehash it. Personally, I like to take the flexible route: programmability. I make a lot of mistakes when I develop signal processing systems; it’s very complicated technology! Therefore, I like to know that I have the flexibility to make changes when I need to in order to fix a bug, perform an additional optimization to increase performance or reduce power, or change to the next standard. The entire signal-processing field is growing and changing so quickly—witness the standards that are evolving and changing all the time—that I prefer to make the rapid and inexpensive upgrades and changes only a programmable solution can afford.
The general answer, as always, lies somewhere in between. In fact, many signal processing solutions are partitioned across a number of different processing elements. Certain parts of the algorithm stream—those that have a pretty good probability of changing in the near future—are mapped to a programmable DSP. Signal processing functions that will remain fairly stable for the foreseeable future are mapped into hardware gates (either an ASIC, an FPGA, or other hardware acceleration). Those parts of the signal processing system that control the input, output, user interface, and overall management of the system heartbeat may be mapped to a more general-purpose processor. Complicated signal processing systems need the right combination of processing elements to achieve true system performance/cost/power trade-offs.
Signal processing is here to stay. It’s everywhere. Any time you have a signal that you want to know more about, communicate in some way, make better or worse, you need to process it. The digital part is just the process of making it all work on a computer of some sort. If it’s an embedded application you must do this with the minimal amount of resources possible. Everything costs money; cycles, memory, power—so everything must be conserved. This is the nature of embedded computing; be application specific, tailor to the job at hand, reduce cost as much as possible, and make things as efficient as possible. This was the way things were done in 1982 when I started in this industry, and the same techniques and processes apply today. The scale has certainly changed; computing problems that required supercomputers in those days are on embedded devices today!
This chapter will touch on these areas and more as it relates to digital signal processing. There is a lot to discuss and I’ll take a practical rather than theoretical approach to describe the challenges and processes required to do DSP well.
Nearly all real-world DSP applications are part of an embedded real-time system. While this chapter will focus primarily on the DSP-specific portion of such a system, it would be naive to pretend that the DSP portions can be implemented without concern for the real-time nature of DSP or the embedded nature of the entire system.
The next several sections will highlight some of special design considerations that apply to embedded real-time systems. I will look first at real-time issues, then some specific embedded issues, and finally, at trends and issues that commonly apply to both real-time and embedded systems.
A real-time system is a system that is required to react to stimuli from the environment (including the passage of physical time) within time intervals dictated by the environment. The Oxford Dictionary defines a real-time system as “any system in which the time at which output is produced is significant.” This is usually because the input corresponds to some movement in the physical world, and the output has to relate to that same movement. The lag from input time to output time must be sufficiently small for acceptable timeliness. Another way of thinking of real-time systems is any information processing activity or system that has to respond to externally generated input stimuli within a finite and specified period. Generally, real-time systems are systems that maintain a continuous timely interaction with their environment (Figure 8.2).

Figure 8.2. A Real-Time System Reacts to Inputs from the Environment and Produces Outputs that Affect the Environment
Correctness of a computation depends not only on its results but also on the time at which its outputs are generated. A real-time system must satisfy response time constraints or suffer significant system consequences. If the consequences consist of a degradation of performance, but not failure, the system is referred to as a soft real-time system. If the consequences are system failure, the system is referred to as a hard real-time system (for instance, antilock braking systems in an automobile).
A system function (hardware, software, or a combination of both) is considered hard real-time if, and only if, it has a hard deadline for the completion of an action or task. This deadline must always be met, otherwise the task has failed. The system may have one or more hard real-time tasks as well as other nonreal-time tasks. This is acceptable, as long as the system can properly schedule these tasks in such a way that the hard real-time tasks always meet their deadlines. Hard real-time systems are commonly also embedded systems.
Real-time systems are different from time-shared systems in the three fundamental areas (Table 8.2). These include predictably fast response to urgent events:
High degree of schedulability—. Timing requirements of the system must be satisfied at high degrees of resource usage.
Worst-case latency—. Ensuring the system still operates under worst-case response time to events.
Stability under transient overload—. When the system is overloaded by events and it is impossible to meet all deadlines, the deadlines of selected critical tasks must still be guaranteed.
Table 8.2. Real-Time Systems Are Fundamentally Different from Time-Shared Systems
Time-Shared Systems | Real-Time Systems | |
|---|---|---|
System capacity | High throughput | Schedulability and the ability of system tasks to meet all deadlines |
Responsiveness | Fast average response time | Ensured worst-case latency, which is the worst-case response time to events |
Overload | Fairness to all | Stability—When the system is overloaded, important tasks must meet deadlines while others may be starved |
Usually, DSP systems qualify as hard real-time systems. As an example, assume that an analog signal is to be processed digitally. The first question to consider is how often to sample or measure an analog signal in order to represent that signal accurately in the digital domain. The sample rate is the number of samples of an analog event (like sound) that are taken per second to represent the event in the digital domain. Based on a signal processing rule called the Nyquist rule, the signal must be sampled at a rate at least equal to twice the highest frequency that we wish to preserve. For example, if the signal contains important components at 4 kilohertz (kHZ), then the sampling frequency would need to be at least 8 KHz. The sampling period would then be:
T = 1/8000 = 125 microseconds = 0.000125 seconds |
This tells us that, for this signal being sampled at this rate, we would have 0.000125 seconds to perform all the processing necessary before the next sample arrives. Samples are arriving on a continuous basis, and the system cannot fall behind in processing these samples and still produce correct results—it is hard real-time.
The collective timeliness of the hard real-time tasks is binary—that is, either they will all always meet their deadlines (in a correctly functioning system), or they will not (the system is infeasible). In all hard real-time systems, collective timeliness is deterministic. This determinism does not imply that the actual individual task completion times, or the task execution ordering, are necessarily known in advance.
A computing system being hard real-time says nothing about the magnitudes of the deadlines. They may be microseconds or weeks. There is a bit of confusion with regards to the usage of the term “hard real-time.” Some relate hard real-time to response time magnitudes below some arbitrary threshold, such as 1 msec. This is not the case. Many of these systems actually happen to be soft real-time. These systems would be more accurately termed “real fast” or perhaps “real predictable.” However, certainly not hard real-time.
The feasibility and costs (for example, in terms of system resources) of hard real-time computing depend on how well known a priori are the relevant future behavioral characteristics of the tasks and execution environment. These task characteristics include:
timeliness parameters, such as arrival periods or upper bounds
deadlines
resource utilization profiles
worst-case execution times
precedence and exclusion constraints
ready and suspension times
relative importance, and so on
There are also pertinent characteristics relating to the execution environment:
system loading
service latencies
resource interactions
interrupt priorities and timing
queuing disciplines
caching
arbitration mechanisms, and so on
Deterministic collective task timeliness in hard (and soft) real-time computing requires that the future characteristics of the relevant tasks and execution environment be deterministic—that is, known absolutely in advance. The knowledge of these characteristics must then be used to preallocate resources so all deadlines will always be met.
Usually, the task’s and execution environment’s future characteristics must be adjusted to enable a schedule and resource allocation that meets all deadlines. Different algorithms or schedules that meet all deadlines are evaluated with respect to other factors. In many real-time computing applications, it is common that the primary factor is maximizing processor utilization.
Allocation for hard real-time computing has been performed using various techniques. Some of these techniques involve conducting an offline enumerative search for a static schedule that will deterministically always meet all deadlines. Scheduling algorithms include the use of priorities that are assigned to the various system tasks. These priorities can be assigned either offline by application programmers, or online by the application or operating system software. The task priority assignments may either be static (fixed), as with rate monotonic algorithms[1] or dynamic (changeable), as with the earliest deadline first algorithm.[2]
Real-time events fall into one of three categories: asynchronous, synchronous, or isochronous.
Asynchronous events are entirely unpredictable. An example of this is a cell phone call arriving at a cellular base station. As far as the base station is concerned, the action of making a phone call cannot be predicted.
Synchronous events are predictable and occur with precise regularity. For example, the audio and video in a camcorder take place in synchronous fashion.
Isochronous events occur with regularity within a given window of time. For example, audio data in a networked multimedia application must appear within a window of time when the corresponding video stream arrives. Isochronous is a subclass of asynchronous.
In many real-time systems, task and future execution environment characteristics are hard to predict. This makes true hard real-time scheduling infeasible. In hard real-time computing, deterministic satisfaction of the collective timeliness criterion is the driving requirement. The necessary approach to meeting that requirement is static (that is, a priori)[3] scheduling of deterministic task and execution environment characteristic cases. The requirement for advance knowledge about each of the system tasks and their future execution environment to enable offline scheduling and resource allocation significantly restricts the applicability of hard real-time computing.
Real-time systems are time critical, and the efficiency of their implementation is more important than in other systems. Efficiency can be categorized in terms of processor cycles, memory or power. This constraint may drive everything from the choice of processor to the choice of the programming language. One of the main benefits of using a higher level language is to allow the programmer to abstract away implementation details and concentrate on solving the problem. This is not always true in the embedded system world. Some higher-level languages have instructions that are an order of magnitude slower than assembly language. However, higher-level languages can be used in real-time systems effectively, using the right techniques.
A system operates in real time as long as it completes its time-critical processes with acceptable timeliness. Acceptable timeliness is defined as part of the behavioral or “nonfunctional” requirements for the system. These requirements must be objectively quantifiable and measurable (stating that the system must be “fast,” for example, is not quantifiable). A system is said to be real-time if it contains some model of real-time resource management (these resources must be explicitly managed for the purpose of operating in real time). As mentioned earlier, resource management may be performed statically, offline, or dynamically, online.
Real-time resource management comes at a cost. The degree to which a system is required to operate in real time cannot necessarily be attained solely by hardware over-capacity (such as, high processor performance using a faster CPU). To be cost effective, there must exist some form of real-time resource management. Systems that must operate in real time consist of both real-time resource management and hardware resource capacity. Systems that have interactions with physical devices require higher degrees of real-time resource management. These computers are referred to as embedded systems, which we spoke about earlier. Many of these embedded computers use very little real-time resource management. The resource management that is used is usually static and requires analysis of the system prior to it executing in its environment. In a real-time system, physical time (as opposed to logical time) is necessary for real-time resource management in order to relate events to the precise moments of occurrence. Physical time is also important for action time constraints as well as measuring costs incurred as processes progress to completion. Physical time can also be used for logging history data.
All real-time systems make trade-offs of scheduling costs versus performance in order to reach an appropriate balance for attaining acceptable timeliness between the real-time portion of the scheduling optimization rules and the offline scheduling performance evaluation and analysis.
Designing real-time systems poses significant challenges to the designer. One of these challenges comes from the fact that real-time systems must interact with the environment. The environment is complex and changing and these interactions can become very complex. Many real-time systems don’t just interact with one, but many different entities in the environment, with different characteristics and rates of interaction. A cell phone base station, for example, must be able to handle calls from literally thousands of cell phone subscribers at the same time. Each call may have different requirements for processing and be in different sequences of processing. All of this complexity must be managed and coordinated.
Real-time systems must respond to external interactions in the environment within a predetermined amount of time. Real-time systems must produce the correct result and produce it in a timely way. This implies that response time is as important as producing correct results. Real-time systems must be engineered to meet these response times. Hardware and software must be designed to support response time requirements for these systems. Optimal partitioning of the system requirements into hardware and software is also important.
Real-time systems must be architected to meet system response time requirements. Using combinations of hardware and software components, engineering makes architecture decisions such as interconnectivity of the system processors, system link speeds, processor speeds, memory size, I/O bandwidth, and so on. Key questions to be answered include:
Is the architecture suitable?—. To meet the system response time requirements, the system can be architected using one powerful processor or several smaller processors. Can the application be partitioned among the several smaller processors without imposing large communication bottlenecks throughout the system? If the designer decides to use one powerful processor, will the system meet its power requirements? Sometimes a simpler architecture may be the better approach—more complexity can lead to unnecessary bottlenecks that cause response time issues.
Are the processing elements powerful enough?—. A processing element with high utilization (greater than 90%) will lead to unpredictable run time behavior. At this utilization level, lower priority tasks in the system may get starved. As a general rule, real-time systems that are loaded at 90% take approximately twice as long to develop, due to the cycles of optimization and integration issues with the system at these utilization rates. At 95% utilization, systems can take three times longer to develop, due to these same issues. Using multiple processors will help, but the interprocessor communication must be managed.
Are the communication speeds adequate?—. Communication and I/O are a common bottleneck in real-time embedded systems. Many response time problems come not from the processor being overloaded but in latencies in getting data into and out of the system. On other cases, overloading a communication port (greater than 75%) can cause unnecessary queuing in different system nodes and this causes delays in messages passing throughout the rest of the system.
Is the right scheduling system available?—. In real-time systems, tasks that are processing real-time events must take higher priority. But, how do you schedule multiple tasks that are all processing real-time events? There are several scheduling approaches available, and the engineer must design the scheduling algorithm to accommodate the system priorities in order to meet all real-time deadlines. Because external events may occur at any time, the scheduling system must be able to preempt currently running tasks to allow higher priority tasks to run. The scheduling system (or real-time operating system) must not introduce a significant amount of overhead into the real-time system.
Real-time systems interact with the environment, which is inherently unreliable. Therefore, real-time systems must be able to detect and overcome failures in the environment. Also, since real-time systems are often embedded into other systems and may be hard to get at (such as a spacecraft or satellite) these systems must also be able to detect and overcome internal failures (there is no “reset” button in easy reach of the user!). In addition, since events in the environment are unpredictable, it’s almost impossible to test for every possible combination and sequence of events in the environment. This is a characteristic of real-time software that makes it somewhat nondeterministic in the sense that it is almost impossible in some real-time systems to predict the multiple paths of execution based on the nondeterministic behavior of the environment. Examples of internal and external failures that must be detected and managed by real-time systems include:
Processor failures
Board failures
Link failures
Invalid behavior of external environment
Interconnectivity failure
Real-time systems are becoming so complex that applications are often executed on multiprocessor systems distributed across some communication system. This poses challenges to the designer that relate to the partitioning of the application in a multiprocessor system. These systems will involve processing on several different nodes. One node may be a DSP, another node a more general-purpose processor, some specialized hardware processing elements, and so forth. This leads to several design challenges for the engineering team:
Initialization of the system—. Initializing a multiprocessor system can be very complicated. In most multiprocessor systems, the software load file resides on the general-purpose processing node. Nodes that are directly connected to the general-purpose processor, for example, a DSP, will initialize first. After these nodes complete loading and initialization, other nodes connected to them may then go through this same process until the system completes initialization.
Processor interfaces—. When multiple processors must communicate with each other, care must be taken to ensure that messages sent along interfaces between the processors are well defined and consistent with the processing elements. Differences in message protocol, including endianness, byte ordering, and other padding rules, can complicate system integration, especially if there is a system requirement for backwards compatibility.
Load distribution—. As mentioned earlier, multiple processors lead to the challenge of distributing the application, and possibly developing the application to support efficient partitioning of the application among the processing elements. Mistakes in partitioning the application can lead to bottlenecks in the system and this degrades the full capability of the system by overloading certain processing elements and leaving others under utilized. Application developers must design the application to be partitioned efficiently across the processing elements.
Centralized Resource Allocation and Management—. In systems of multiple processing elements, there is still a common set of resources including peripherals, cross bar switches, memory, and so on that must be managed. In some cases the operating system can provide mechanisms like semaphores to manage these shared resources. In other cases there may be dedicated hardware to manage the resources. Either way, important shared resources in the system must be managed in order to prevent more system bottlenecks.
An embedded system is a specialized computer system that is usually integrated as part of a larger system. An embedded system consists of a combination of hardware and software components to form a computational engine that will perform a specific function. Unlike desktop systems that are designed to perform a general function, embedded systems are constrained in their application. Embedded systems often perform in reactive and time-constrained environments as described earlier. A rough partitioning of an embedded system consists of the hardware that provides the performance necessary for the application (and other system properties, like security) and the software, which provides a majority of the features and flexibility in the system. A typical embedded system is shown in Figure 8.3.

Processor core—At the heart of the embedded system is the processor core(s). This can be a simple inexpensive 8 bit microcontroller to a more complex 32 or 64 bit microprocessor. The embedded designer must select the most cost sensitive device for the application that can meet all of the functional and nonfunctional (timing) requirements.
Analog I/O—D/A and A/D converters are used to get data from the environment and back out to the environment. The embedded designer must understand the type of data required from the environment, the accuracy requirements for that data, and the input/output data rates in order to select the right converters for the application. The external environment drives the reactive nature of the embedded system. Embedded systems have to be at least fast enough to keep up with the environment. This is where the analog information such as light or sound pressure or acceleration are sensed and input into the embedded system (see Figure 8.4).
Sensors and Actuators—Sensors are used to sense analog information from the environment. Actuators are used to control the environment in some way.
Embedded systems also have user interfaces. These interfaces may be as simple as a flashing LED to a sophisticated cell phone or digital still camera interface.
Application-specific gates—Hardware acceleration like ASICs or FPGA are used for accelerating specific functions in the application that have high performance requirements. The embedded designer must be able to map or partition the application appropriately using available accelerators to gain maximum application performance.
Software is a significant part of embedded system development. Over the last several years, the amount of embedded software has grown faster than Moore’s law, with the amount doubling approximately every 10 months. Embedded software is usually optimized in some way (performance, memory, or power). More and more embedded software is written in a high level language like C/C++ with some of the more performance critical pieces of code still written in assembly language.
Memory is an important part of an embedded system and embedded applications can either run out of RAM or ROM depending on the application. There are many types of volatile and nonvolatile memory used for embedded systems and we will talk more about this later.
Emulation and diagnostics—Many embedded systems are hard to see or get to. There needs to be a way to interface to embedded systems to debug them. Diagnostic ports such as a JTAG (joint test action group) port are used to debug embedded systems. On-chip emulation is used to provide visibility into the behavior of the application. These emulation modules provide sophisticated visibility into the runtime behavior and performance, in effect replacing external logic analyzer functions with onboard diagnostic capabilities.

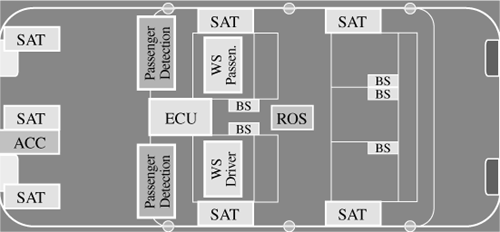
A typical embedded system responds to the environment via sensors and controls the environment using actuators (Figure 8.5). This imposes a requirement on embedded systems to achieve performance consistent with that of the environment. This is why embedded systems are referred to as reactive systems. A reactive system must use a combination of hardware and software to respond to events in the environment, within defined constraints. Complicating the matter is the fact that these external events can be periodic and predictable or aperiodic and hard to predict. When scheduling events for processing in an embedded system, both periodic and aperiodic events must be considered and performance must be guaranteed for worst-case rates of execution. This can be a significant challenge. Consider the example in Figure 8.6. This is a model of an automobile airbag deployment system showing sensors including crash severity and occupant detection. These sensors monitor the environment and could signal the embedded system at any time. The embedded control unit (ECU) contains accelerometers to detect crash impacts. In addition, rollover sensors, buckle sensors and weight sensors (Figure 8.8) are used to determine how and when to deploy airbags. Figure 8.7 shows the actuators in this same system. These include Thorax bags actuators, pyrotechnic buckle pretensioner with load limiters, and the central airbag control unit. When an impact occurs, the sensors must detect and send a signal to the ECU, which must deploy the appropriate airbags within a hard real-time deadline for this system to work properly.

Source: Courtesy of Texas Instruments
Figure 8.6. Airbag System: Possible Sensors (Including Crash Severity and Occupant Detection)

Source: Courtesy of Texas Instruments
Figure 8.7. Airbag System: Possible Sensors (Including Crash Severity and Occupant Detection)
The previous example demonstrates several key characteristics of embedded systems:
Monitoring and reacting to the environment—. Embedded systems typically get input by reading data from input sensors. There are many different types of sensors that monitor various analog signals in the environment, including temperature, sound pressure, and vibration. This data is processed using embedded system algorithms. The results may be displayed in some format to a user or simply used to control actuators (like deploying the airbags and calling the police).
Control the environment—. Embedded systems may generate and transmit commands that control actuators, such as airbags, motors, and so on.
Processing of information—. Embedded systems process the data collected from the sensors in some meaningful way, such as data compression/decompression, side impact detection, and so on.
Application-specific—. Embedded systems are often designed for applications, such as airbag deployment, digital still cameras, or cell phones. Embedded systems may also be designed for processing control laws, finite state machines, and signal processing algorithms. Embedded systems must also be able to detect and react appropriately to faults in both the internal computing environment as well as the surrounding systems.
SAT = satellite with serial communication interface |
ECU = central airbag control unit (including accelerometers) ROS = roll over sensing unit |
WS = weight sensor |
BS = buckle switch |
TB = thorax bag |
PBP = pyrotechnic buckle pretensioner with load limiter |
ECU = central airbag control unit |

Figure 8.9 shows a block diagram of a digital still camera (DSC). A DSC is an example of an embedded system. Referring back to the major components of an embedded system shown in Figure 8.3, we can see the following components in the DSC:
The charge-coupled device analog front-end (CCD AFE) acts as the primary sensor in this system.
The digital signal processor is the primary processor in this system.
The battery management module controls the power for this system.
The preview LCD screen is the user interface for this system.
The Infrared port and serial ports are actuators in this system that interface to a computer.
The graphics controller and picture compression modules are dedicated application-specific gates for processing acceleration.
The signal processing software runs on the DSP.
The antenna is one of the sensors in this system. The microphone is another sensor. The keyboard also provides aperiodic events into the system.
The voice codec is an application-specific acceleration in hardware gates.
The DSP is one of the primary processor cores that runs most of the signal processing algorithms.
The ARM processor is the other primary system processor running the state machines, controlling the user interface, and other components in this system.
The battery/temp monitor controls the power in the system along with the supply voltage supervisor.
The display is the primary user interface in the system.

Figure 8.10 shows another example of an embedded system. This is a block diagram of a cell phone. In this diagram, the major components of an embedded system are again obvious:
The antenna is one of the sensors in this system. The microphone is another sensor.
The keyboard also provides aperiodic events into the system.
The voice codec is an application-specific acceleration in hardware gates.
The DSP is one of the primary processor cores that runs most of the signal processing algorithms.
The ARM processor is the other primary system processor running the state machines, controlling the user interface, and other components in this system.
The battery/temp monitor controls the power in the system along with the supply voltage supervisor.
The display is the primary user interface in the system.

Many of the items that we interface with or use on a daily basis contain an embedded system. An embedded system is a system that is “hidden” inside the item we interface with. Systems such as cell phones, answering machines, microwave ovens, VCRs, DVD players, video game consoles, digital cameras, music synthesizers, and cars all contain embedded processors. A late model car contains more than 60 embedded microprocessors. These embedded processors keep us safe and comfortable by controlling such tasks as antilock braking, climate control, engine control, audio system control, and airbag deployment.
Embedded systems have the added burden of reacting quickly and efficiently to the external “analog” environment. That may include responding to the push of a button, a sensor to trigger an air bag during a collision, or the arrival of a phone call on a cell phone. Simply put, embedded systems have deadlines that can be hard or soft. Given the “hidden” nature of embedded systems, they must also react to and handle unusual conditions without the intervention of a human.
DSPs are useful in embedded systems principally for one reason: signal processing. The ability to perform complex signal processing functions in real time gives DSP the advantage over other forms of embedded processing. DSPs must respond in real time to analog signals from the environment, convert them to digital form, perform value added processing to those digital signals, and, if required, convert the processed signals back to analog form to send back out to the environment.
Programming embedded systems requires an entirely different approach from that used in desktop or mainframe programming. Embedded systems must be able to respond to external events in a very predictable and reliable way. Real-time programs must not only execute correctly, they must execute on time. A late answer is a wrong answer. Because of this requirement, we will be looking at issues such as concurrency, mutual exclusion, interrupts, hardware control, and processing. Multitasking, for example, has proven to be a powerful paradigm for building reliable and understandable real-time programs.
As mentioned earlier, an embedded system is a specialized computer system that is integrated as part of a larger system. Many embedded systems are implemented using digital signal processors. The DSP will interface with the other embedded components to perform a specific function. The specific embedded application will determine the specific DSP to be used. For example, if the embedded application is one that performs video processing, the system designer may choose a DSP that is customized to perform media processing, including video and audio processing. An example of an application specific DSP for this function is shown in Figure 8.11. This device contains dual channel video ports that are software configurable for input or output, as well as video filtering and automatic horizontal scaling and support of various digital TV formats such as HDTV, multichannel audio serial ports, multiple stereo lines, and an Ethernet peripheral to connect to IP packet networks. It is obvious that the choice of a DSP “system” depends on the embedded application.

In this chapter, we will discuss the basic steps to develop an embedded application using DSP.
In this section we will overview the general embedded system life cycle using DSP. There are many steps involved in developing an embedded system—some are similar to other system development activities and some are unique. We will step through the basic process of embedded system development, focusing on DSP applications.
Choosing a design solution is a difficult process. Often the choice comes down to emotion or attachment to a particular vendor or processor, inertia based on prior projects and comfort level. The embedded designer must take a positive logical approach to comparing solutions based on well defined selection criteria. For DSP, specific selection criteria must be discussed. Many signal processing applications will require a mix of several system components as shown in Figure 8.12.

Source: Courtesy of Texas Instruments
Figure 8.12. Most Signal Processing Applications Will Require a Mix of Various System Components
A typical DSP product design uses the digital signal processor itself, analog/mixed signal functions, memory, and software, all designed with a deep understanding of overall system function. In the product, the analog signals of the real world, signals representing anything from temperature to sound and images, are translated into digital bits—zeros and ones—by an analog/mixed signal device. Then the digital bits or signals are processed by the DSP. Digital signal processing is much faster and more precise than traditional analog processing. This type of processing speed is needed for today’s advanced communications devices where information requires instantaneous processing, and in many portable applications that are connected to the Internet.
There are many selection criteria for embedded DSP systems. Some of these are shown in Figure 8.13. These are the major selection criteria defined by Berkeley Design Technology Incorporated (bdti.com). Other selection criteria may be “ease of use,” which is closely linked to “time-to-market” and also “features.” Some of the basic rules to consider in this phase are:
For a fixed cost, maximize performance.
For a fixed performance, minimize cost.

In many systems, a general-purpose processor (GPP), field-programmable gate array (FPGA), microcontroller (mC) or DSP is not used as a single-point solution. This is because designers often combine solutions, maximizing the strengths of each device (Figure 8.14).

One of the first decisions that designers often make when choosing a processor is whether they would like a software-programmable processor in which functional blocks are developed in software using C or assembly, or a hardware processor in which functional blocks are laid out logically in gates. Both FPGAs and application specific integrated circuits (ASICs) may integrate a processor core (very common in ASICs).
Hardware gates are logical blocks laid out in a flow, therefore any degree of parallelization of instructions is theoretically possible. Logical blocks have very low latency, therefore FPGAs are more efficient for building peripherals than “bit-banging” using a software device.
If a designer chooses to design in hardware, he or she may design using either an FPGA or ASIC. FPGAs are termed “field programmable” because their logical architecture is stored in a nonvolatile memory and booted into the device. Thus, FPGAs may be reprogrammed in the field simply by modifying the nonvolatile memory (usually FLASH or EEPROM). ASICs are not field-programmable. They are programmed at the factory using a mask that cannot be changed. ASICs are often less expensive and/or lower power. They often have sizable nonrecurring engineering (NRE) costs.
In this model, instructions are executed from memory in a serial fashion (that is, one per cycle). Software-programmable solutions have limited parallelization of instructions; however, some devices can execute multiple instructions in parallel in a single cycle. Because instructions are executed from memory in the CPU, device functions can be changed without having to reset the device. Also, because instructions are executed from memory, many different functions or routines may be integrated into a program without the need to lay out each individual routine in gates. This may make a software-programmable device more cost efficient for implementing very complex programs with a large number of subroutines.
If a designer chooses to design in software, there are many types of processors available to choose from. There are a number of general-purpose processors, but in addition, there are processors that have been optimized for specific applications. Examples of such application specific processors are graphics processors, network processors, and digital signal processors (DSPs). Application specific processors usually offer higher performance for a target application, but are less flexible than general-purpose processors.
Within the category of general-purpose processors are microcontrollers (mC) and microprocessors (mP) (Figure 8.15).

Microcontrollers usually have control-oriented peripherals. They are usually lower cost and lower performance than microprocessors. Microprocessors usually have communications-oriented peripherals. They are usually higher cost and higher performance than microcontrollers.
Note that some GPPs have integrated MAC units. It is not a “strength” of GPPs to have this capability because all DSPs have MACs—but it is worth noting because a student might mention it. Regarding performance of the GPP’s MAC, it is different for each one.
A microcontroller is a highly integrated chip that contains many or all of the components comprising a controller. This includes a CPU, RAM and ROM, I/O ports, and timers. Many general-purpose computers are designed the same way. But a microcontroller is usually designed for very specific tasks in embedded systems. As the name implies, the specific task is to control a particular system, hence the name microcontroller. Because of this customized task, the device’s parts can be simplified, which makes these devices very cost effective solutions for these types of applications.

Some microcontrollers can actually do a multiply and accumulate (MAC) in a single cycle. But that does not necessarily make it a DSP. True DSPs can allow two 16x16 MACS in a single cycle including bringing the data in over the buses, and so on. It is this that truly makes the part a DSP. So, devices with hardware MACs might get a “fair” rating. Others get a “poor” rating. In general, microcontrollers can do DSP but they will generally do it slower.
An FPGA is an array of logic gates that are hardware-programmed to perform a user-specified task. FPGAs are arrays of programmable logic cells interconnected by a matrix of wires and programmable switches. Each cell in an FPGA performs a simple logic function. These logic functions are defined by an engineer’s program. FPGA contain large numbers of these cells (1000–100,000) available to use as building blocks in DSP applications. The advantage of using FPGAs is that the engineer can create special purpose functional units that can perform limited tasks very efficiently. FPGAs can be reconfigured dynamically as well (usually 100–1000 times per second depending on the device). This makes it possible to optimize FPGAs for complex tasks at speeds higher than what can be achieved using a general-purpose processor. The ability to manipulate logic at the gate level means it is possible to construct custom DSP-centric processors that efficiently implement the desired DSP function. This is possible by simultaneously performing all of the algorithm’s subfunctions. This is where the FPGA can achieve performance gains over a programmable DSP processor.
The DSP designer must understand the trade-offs when using an FPGA. If the application can be done in a single programmable DSP, that is usually the best way to go since talent for programming DSPs is usually easier to find than FPGA designers. In addition, software design tools are common, cheap, and sophisticated, which improves development time and cost. Most of the common DSP algorithms are also available in well packaged software components. It’s harder to find these same algorithms implemented and available for FPGA designs.
An FPGA is worth considering, however, if the desired performance cannot be achieved using one or two DSPs, or when there may be significant power concerns (although a DSP is also a power efficient device—benchmarking needs to be performed) or when there may be significant programmatic issues when developing and integrating a complex software system.
Typical applications for FPGAs include radar/sensor arrays, physical system and noise modeling, and any really high I/O and high-bandwidth application.
A DSP is a specialized microprocessor used to perform calculations efficiently on digitized signals that are converted from the analog domain. One of the big advantages of DSP is the programmability of the processor, which allows important system parameters to be changed easily to accommodate the application. DSPs are optimized for digital signal manipulations.
DSPs provide ultra-fast instruction sequences, such as shift and add, and multiply and add. These instruction sequences are common in many math-intensive signal processing applications. DSPs are used in devices where this type of signal processing is important, such as sound cards, modems, cell phones, high-capacity hard disks, and digital TVs (Figure 8.17).

The solution shown in Figure 8.18 allows each device to perform the tasks it’s best at, achieving a more efficient system in terms of cost/power/performance. For example, in Figure 8.18, the system designer may put the system control software (state machines and other communication software) on the general-purpose processor or microcontroller, the high performance, single dedicated fixed functions on the FPGA, and the high I/O signal processing functions on the DSP.

When planning the embedded product development cycle, there are multiple opportunities to reduce cost and/or increase functionality using combinations of GPP/uC, FPGA, and DSP. This becomes more of an issue in higher-end DSP applications. These are applications that are computationally intensive and performance critical. These applications require more processing power and channel density than can be provided by GPPs alone. For these high-end applications, there are software/hardware alternatives that the system designer must consider. Each alternative provides different degrees of performance benefits and must also be weighed against other important system parameters including cost, power consumption, and time-to-market.
The system designer may decide to use an FPGA in a DSP system for the following reasons:
A decision to extend the life of a generic, lower-cost microprocessor or DSP by offloading computationally intensive work to a FPGA.
A decision to reduce or eliminate the need for a higher-cost, higher performance DSP processor.
To increase computational throughput. If the throughput of an existing system must increase to handle higher resolutions or larger signal bandwidths, an FPGA may be an option. If the required performance increases are computational in nature, an FPGA may be an option.
For prototyping new signal processing algorithms; since the computational core of many DSP algorithms can be defined using a small amount of C code, the system designer can quickly prototype new algorithmic approaches on FPGAs before committing to hardware or other production solutions, like an ASIC.
For implementing “glue” logic; various processor peripherals and other random or “glue” logic are often consolidated into a single FPGA. This can lead to reduced system size, complexity, and cost.
By combining the capabilities of FPGAs and DSP processors, the system designer can increase the scope of the system design solution. Combinations of fixed hardware and programmable processors are a good model for enabling flexibility, programmability, and computational acceleration of hardware for the system.
In DSP system design, there are several things to consider when determining whether a functional component should be implemented in hardware or software:
Signal processing algorithm parallelism—. Modern processor architectures have various forms of instruction level parallelism (ILP). One example is the 64x DSP that has a very long instruction word (VLIW) architecture. The 64x DSP exploits ILP by grouping multiple instructions (adds, multiplies, loads, and stores) for execution in a single processor cycle. For DSP algorithms that map well to this type of instruction parallelism, significant performance gains can be realized. But not all signal processing algorithms exploit such forms of parallelism. Filtering algorithms such as finite impulse response (FIR) algorithms are recursive and are suboptimal when mapped to programmable DSPs. Data recursion prevents effective parallelism and ILP. As an alternative, the system designer can build dedicated hardware engines in an FPGA.
Computational complexity—. Depending on the computational complexity of the algorithms, these may run more efficiently on a FPGA instead of a DSP. It may make sense, for certain algorithmic functions, to implement in a FPGA and free up programmable DSP cycles for other algorithms. Some FPGAs have multiple clock domains built into the fabric, which can be used to separate different signal processing hardware blocks into separate clock speeds based on their computational requirements. FPGAs can also provide flexibility by exploiting data and algorithm parallelism using multiple instantiations of hardware engines in the device.
Data locality—. The ability to access memory in a particular order and granularity is important. Data access takes time (clock cycles) due to architectural latency, bus contention, data alignment, direct memory access (DMA) transfer rates, and even the type of memory being used in the system. For example, static RAM (SRAM), which is very fast but much more expensive than dynamic RAM (DRAM), is often used as cache memory due to its speed. Synchronous DRAM (SDRAM), on the other hand, is directly dependent on the clock speed of the entire system (that’s why they call it synchronous). It basically works at the same speed as the system bus. The overall performance of the system is driven in part by which type of memory is being used. The physical interfaces between the data unit and the arithmetic unit are the primary drivers of the data locality issue.
Data parallelism—. Many signal processing algorithms operate on data that is highly capable of parallelism, such as many common filtering algorithms. Some of the more advanced high-performance DSPs have single instruction multiple data (SIMD) capability in the architectures and/or compilers that implement various forms of vector processing operations. FPGA devices are also good at this type of parallelism. Large amounts of RAM are used to support high bandwidth requirements. Depending on the DSP processor being used, an FPGA can be used to provide this SIMD processing capability for certain algorithms that have these characteristics.
A DSP-based embedded system could incorporate one, two, or all three of these devices depending on various factors:
|
The trend in embedded DSP development is moving more towards programmable solutions as shown in Figure 8.19. There will always be a trade-off depending on the application but the trend is moving towards software and programmable solutions.

Source: Courtesy of Texas Instruments
Figure 8.19. Hardware/Software Mix in an Embedded System; the Trend Is Towards More Software
“Cost” can mean different things to different people. Sometimes, the solution is to go with the lowest “device cost.” However, if the development team then spends large amounts of time redoing work, the project may be delayed; the “time-to-market” window may extend, which, in the long run, costs more than the savings of the low-cost device.
The first point to make is that a 100% software or hardware solution is usually the most expensive option. A combination of the two is the best. In the past, more functions were done in hardware and less in software. Hardware was faster, cheaper (ASICs), and good C compilers for embedded processors just weren’t available. However, today, with better compilers, faster and lower-cost processors available, the trend is toward more of a software-programmable solution. A software-only solution is not (and most likely never will be) the best overall cost. Some hardware will still be required. For example, let’s say you have ten functions to perform and two of them require extreme speed. Do you purchase a very fast processor (which costs 3–4 times the speed you need for the other eight functions) or do you spend 1x on a lower-speed processor and purchase an ASIC or FPGA to do only those two critical functions? It’s probably best to choose the combination.
Cost can be defined by a combination of the following: A combination of software and hardware always gives the lowest cost system design.
One compelling reason to choose a DSP processor for an embedded system application is performance. Three important questions to understand when deciding on a DSP are:
What makes a DSP a DSP?
How fast can it go?
How can I achieve maximum performance without writing in assembly?
In this section, we will begin to answer these questions. We know that a DSP is really just an application specific microprocessor. They are designed to do a certain thing, signal processing, very efficiently. We mentioned the types of signal processing algorithms that are used in DSP. They are shown again in Figure 8.20 for reference.
Notice the common structure of each of the algorithms in Figure 8.20:
They all accumulate a number of computations.
They all sum over a number of elements.
They all perform a series of multiplies and adds.
These algorithms all share some common characteristics; they perform multiplies and adds over and over again. This is generally referred to as the sum of products (SOP).
DSP designers have developed hardware architectures that allow the efficient execution of algorithms to take advantage of this algorithmic specialty in signal processing. For example, some of the specific architectural features of DSPs accommodate the algorithmic structure described in Figure 8.20.
As an example, consider the FIR diagram in Figure 8.21 as an example DSP algorithm that clearly shows the multiply/accumulate and shows the need for doing MACs very fast, along with reading at least two data values. As shown in Figure 8.21, the filter algorithm can be implemented using a few lines of C source code. The signal flow diagram shows this algorithm in a more visual context. Signal flow diagrams are used to show overall logic flow, signal dependencies, and code structure. They make a nice addition to code documentation.
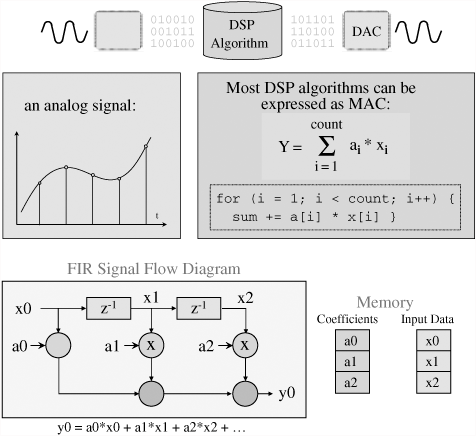
To execute at top speed, a DSP needs to:
read at least two values from memory (minimum),
multiply coeff * data,
accumulate (+) answer (an * xn) to running total ...,
. . . and do all of the above in a single cycle (or less).
DSP architectures support the requirements above (Figure 8.22):
High-speed memory architectures support multiple accesses/cycle.
Multiple read buses allow two (or more) data reads/cycle from memory.
The processor pipeline overlays CPU operations allowing one-cycle execution.

All of these things work together to result in the highest possible performance when executing DSP algorithms.
Other DSP architectural features are summarized in Figure 8.23.

There are two types of DSP processing models—single sample model and block processing model. In a single sample model of signal processing (Figure 8.24a), the output must result before next input sample. The goal is minimum latency (in-to-out time). These systems tend to be interrupt intensive; interrupts drive the processing for the next sample. Example DSP applications include motor control and noise cancellation.

In the block processing model (Figure 8.24b), the system will output a buffer of results before the next input buffer fills. DSP systems like this use the DMA to transfer samples to the buffer. There is increased latency in this approach as the buffers are filled before processing. However, these systems tend to be computationally efficient. The main types of DSP applications that use block processing include cellular telephony, video, and telecom infrastructure.
An example of stream processing is averaging data sample. A DSP system that must average the last three digital samples of a signal together and output a signal at the same rate as what is being sampled must do the following:
Input a new sample and store it.
Average the new sample with the last two samples.
Output the result.
These three steps must complete before the next sample is taken. This is an example of stream processing. The signal must be processed in real time. A system that is sampling at 1000 samples per second has one thousandth of a second to complete the operation in order to maintain real-time performance. Block processing, on the other hand, accumulates a large number of samples at a time and processes those samples while the next buffer of samples is being collected. Algorithms such as the fast Fourier transform (FFT) operate in this mode.
Block processing (processing a block of data in a tight inner loop) can have a number of advantages in DSP systems:
If the DSP has an instruction cache, this cache will optimize instructions to run faster the second (or subsequent) time through the loop.
If the data accesses adhere to a locality of reference (which is quite common in DSP systems) the performance will improve. Processing the data in stages means the data in any given stage will be accessed from fewer areas, and therefore less likely to thrash the data caches in the device.
Block processing can often be done in simple loops. These loops have stages where only one kind of processing is taking place. In this manner there will be less thrashing from registers to memory and back. In many cases, most if not all of the intermediate results can be kept in registers or in level one cache.
By arranging data access to be sequential, even data from the slowest level of memory (DRAM) will be much faster because the various types of DRAM assume sequential access.
DSP designers will use one of these two methods in their system. Typically, control algorithms will use single-sample processing because they cannot delay the output very long, such as in the case of block processing. In audio/video systems, block processing is typically used—because there can be some delay tolerated from input to output.
DSPs are used in many different systems including motor control applications, performance-oriented applications, and power sensitive applications. The choice of a DSP processor is dependent on not just the CPU speed or architecture but also the mix of peripherals or I/O devices used to get data in and out of the system. After all, much of the bottleneck in DSP applications is not in the compute engine but in getting data in and out of the system. Therefore, the correct choice of peripherals is important in selecting the device for the application. Example I/O devices for DSP include:
GPIO—. A flexible parallel interface that allows a variety of custom connections.
UART—. Universal asynchronous receiver-transmitter. This is a component that converts parallel data to serial data for transmission and also converts received serial data to parallel data for digital processing.
CAN—. Controller area network. The CAN protocol is an international standard used in many automotive applications.
SPI—. Serial peripheral interface. A three-wire serial interface developed by Motorola.
USB—. Universal serial bus. This is a standard port that enables the designer to connect external devices (digital cameras, scanners, music players, and so on) to computers. The USB standard supports data transfer rates of 12 Mbps (million bits per second).
McBSP—. Multichannel buffered serial port. These provide direct full-duplex serial interfaces between the DSP and other devices in a system.
HPI—. Host port interface. This is used to download data from a host processor into the DSP.
A summary of I/O mechanisms for DSP application class is shown in Figure 8.25.

Before choosing a DSP processor for a specific application, the system designer must evaluate three key system parameters as shown below:
|
With this knowledge, the system designer can scale the numbers to meet the application’s needs and then determine:
CPU load (% of maximum CPU).
At this CPU load, what other functions can be performed?
The DSP system designer can use this process for any CPU they are evaluating. The goal is the find the “weakest link” in terms of performance so that you know what the system constraints are. The CPU might be able to process numbers at sufficient rates, but if the CPU cannot be fed with data fast enough, then having a fast CPU doesn’t really matter. The goal is to determine the maximum number of channels that can be processed given a specific algorithm and then work that number down based on other constraints (maximum input/output speed and available memory).
As an example, consider the process shown in Figure 8.26. The goal is to determine the maximum number of channels that this specific DSP processor can handle given a specific algorithm. To do this, we must first determine the benchmark of the chosen algorithm (in this case, a 200-tap FIR filter). The relevant documentation for an algorithm like this (from a library of DSP functions) gives us the benchmark with two variables: nx (size of buffer) and nh (# coeffs)—these are used for the first part of the computation. This FIR routine takes about 106 K cycles per frame. Now, consider the sampling frequency. A key question to answer at this point is “How many times is a frame FULL per second?” To answer this, divide the sampling frequency (which specifies how often a new data item is sampled) by the size of the buffer. Performing this calculation determines that we fill about 47 frames per second. Next, is the most important calculation—how many MIPS does this algorithm require of a processor? We need to find out how many cycles this algorithm will require per second. Now we multiply frames/second times cycles/frame and perform the calculation using these data to get a throughput rate of about 5 MIPs. Assuming this is the only computation being performed on the processor, the channel density (how many channels of simultaneous processing can be performed by a processor) is a maximum of 300/5 = 60 channels. This completes the CPU calculation. This result can not be used in the I/O calculation.
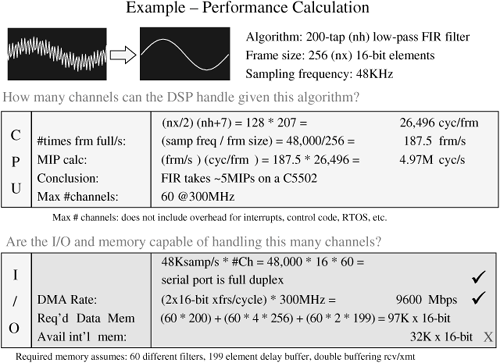
The next question to answer is “Can the I/O interface feed the CPU fast enough to handle 60 channels?” Step one is to calculate the “bit rate” required of the serial port. To do this, the required sampling rate (48 KHz) is multiplied by the maximum channel density (60). This is then multiplied by 16 (assuming the word size is 16—which it is given the chosen algorithm). This calculation yields a requirement of 46 Mbps for 60 channels operating at 48 KHz. In this example what can the 5502 DSP serial port support? The specification says that the maximum bit rate is 50 Mbps (half the CPU clock rate up to 50 Mbps). This tells us that the processor can handle the rates we need for this chosen application. Can the DMA move these samples from the McBSP to memory fast enough? Again, the specification tells us that this should not be a problem.
The next step considers the issue of required data memory. This calculation is somewhat confusing and needs some additional explanation.
Assume that all 60 channels of this application are using different filters—that is, 60 different sets of coefficients and 60 double-buffers (this can be implemented using a ping-pong buffer on both the receive and transmit sides. This is a total of 4 buffers per channel hence the *4 + the delay buffers for each channel (only the receive side has delay buffers ...) so the algorithm becomes:
Number of channels *2* delay buffer size | |
= 60*2*199 | |
This is extremely conservative and the system designer could save some memory if this is not the case. But this is a worst-case scenario. Hence, we’ll have 60 sets of 200 coefficients, 60 double-buffers (ping and pong on receive and transmit, hence the *4) and we’ll also need a delay buffer of number of coefficients—1 that is 199 for each channel. So, the calculation is:
(#Channels * #coefficients) + (#Channels * 4 * frame size) | |
+ (#Channels * #delay_buffers * delay_buffer_size) | |
= (60 * 200) + (60 * 4 * 256) + (60 * 26 * 199) = 97,320 bytes of memory | |
This results in a requirement of 97 K of memory. The 5502 DSP only has 32 K of on-chip memory, so this is a limitation. Again, you can redo the calculation assuming only one type of filter is used, or look for another processor.
Now we extend the calculations to the 2812 and the 6416 processors (Figure 8.27). The following are a couple of things to note.

The 2812 is best used in a single-sample processing mode, so using a block FIR application on a 2812 is not the best fit. However, for example purposes it is done this way to benchmark one processor versus another. Where block processing hurts the 2812 is in relation to getting the samples into on-chip memory. There is no DMA on the 2812 because in single-sample processing, it is not required. The term “beta” in the calculation is the time it takes to move (using CPU cycles) the incoming sampled signals from the A/D to memory. This would be performed by an interrupt service routine and it must be accounted for. Notice that the benchmarks for the 2812 and 5502 are very close.
The 6416 is a high performance machine when doing 16-bit operations—it can do 269 channels given the specific FIR used in this example. Of course, the I/O (on one serial port) can’t keep up with this, but it could with 2 serial ports in operation.
Once you’ve done these calculations, you can “back off” the calculation to the exact number of channels your system requires, determine an initial theoretical CPU load that is expected, and then make some decisions about what to do with any additional bandwidth that is left over (Figure 8.28).
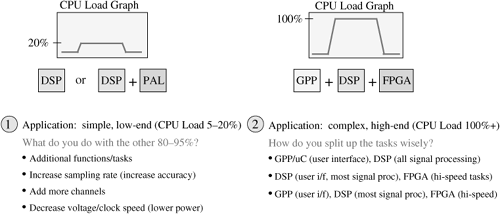
Source: Courtesy of Texas Instruments
Figure 8.28. Determining What to Do Based on Available CPU Bandwidth
Two sample cases that help drive discussion on issues related to CPU load are shown in Figure 8.28. In the first case, the entire application only takes 20% of the CPU’s load. What do you do with the extra bandwidth? The designer can add more algorithmic processing, increase the channel density, increase the sampling rate to achieve higher resolution or accuracy, or decrease the clock/voltage so that the CPU load goes up and you save lots of power. It is up to the system designer to determine the best strategy here based on the system requirements.
The second example application is the other side of the fence—where the application takes more processing power than the CPU can handle. This leads the designer to consider a combined solution. The architecture of this again depends on the application’s needs.
DSP software development is primarily focused on achieving the performance goals of the system. It’s more efficient to develop DSP software using a high-level language like C or C++, but it is not uncommon to see some of the high performance, MIPS intensive algorithms written at least partially in assembly language. When generating DSP algorithm code, the designer should use one or more of the following approaches:
Find existing algorithms (free code).
Buy or license algorithms from vendors. These algorithms may come bundled with tools or may be classes of libraries for specific applications (Figure 8.29).
Table 8.29. Reuse Opportunities Using DSP Libraries and Third Parties
May be bundled with tools and contains:
C-callable highly-optimized assembly routines
Documentation on each algorithm
Examples: FIR, IIR, FFT, convolution, min/max, log, etc.
Other libraries available for specific DSPs:
Image libraries
Other control-specific free libraries
Use third parties
Lists application software by platform, algorithm, and third party
Includes specs such as data/code size, performance, licensing fees
Write the algorithms in-house. If using this approach, implement as much of the algorithm as possible in C/C++. This usually results in faster time-to-market and requires a common skill found in the industry. It is much easier to find a C programmer than a 5502 DSP assembly language programmer. DSP compiler efficiency is fairly good and significant performance can be achieved using a compiler with the right techniques. There are several tuning techniques used to generate optimal code.
To fine-tune code and get the highest efficiency possible, the system designer needs to know three things:
The architecture.
The algorithms.
The compiler.
Figure 8.30 shows some ways to help the compiler generate efficient code. Compilers are pessimistic by nature, so the more information that can be provided about the system algorithms, where data is in memory, the better. The C6000 compiler can achieve 100% efficiency versus hand-coded assembly if the right techniques are used. There are pros and cons to writing DSP algorithms in assembly language as well, so if this must be done, these must be understood from the beginning (Figure 8.31).


All DSP systems have some basic needs—basic requirements for processing high performance algorithms. These include the following.
Input/Output
Input consists of analog information being converted to digital data.
Output consists of digital data converted back out to analog format.
Device drivers to talk to the actual hardware.
Processing
Algorithms that are applied to the digitized data, for example an algorithm to encrypt secure data streams or to decode an MP3 file for playback.
Control
Control structures with the ability to make system level decisions, for example to stop or play an MP3 file.
A DSP framework must be developed to connect device drivers and algorithms for correct data flow and processing (Figure 8.32).

A DSP framework can be custom developed for the application, reused from another application, or even purchased or acquired from a vendor. Since many DSP systems have similar processing frameworks as described above, reuse is a viable option. A framework is system software that uses standardized interfaces to algorithms and software. This includes algorithms as well as hardware drivers. The benefits of using a DSP framework include:
The development does not have to start from scratch.
The framework can be used as a starting point for many applications.
The software components within a framework have well defined interfaces and work well together.
The DSP designer can focus on the application layer that is usually the main differentiator in the product being developed. The framework can be reused.
An example DSP reference framework is shown in Figure 8.33. This DSP framework consists of:
I/O drivers for input/output.
Two processing threads with generic algorithms.
Split/join threads used to simulate/utilize a stereo codec.

This reference framework has two channels by default. The designer can add and remove channels to suit the applications needs.
An example complete DSP Solution is shown in Figure 8.34. There is the DSP as the central processing element. There are mechanisms to get data into and out of the system (the ADC and DAC components). There is a power control module for system power management, a data transmission block with several possible peripherals including USB, FireWire, and so on, some clock generation components and a sensor for the RF component. Of course, this is only one example, but many DSP applications follow a similar structure.

Many of today’s DSP applications are subject to real-time constraints. Many embedded DSP applications will eventually grow to a point where they are stressing the available CPU, memory or power resources. Understanding the workings of the DSP architecture, compiler, and application algorithms can speed up applications, sometimes by an order of magnitude. The following sections will summarize some of the techniques that can improve the performance of your code in terms of cycle count, memory use, and power consumption.
Optimization is a procedure that seeks to maximize or minimize one or more performance indices. These indices include:
Throughput (execution speed)
Memory usage
I/O bandwidth
Power dissipation
Since many DSP systems are real-time systems, at least one (and probably more) of these indices must be optimized. It is difficult (and usually impossible) to optimize all these performance indices at the same time. For example, to make the application faster, the developer may require more memory to achieve the goal. The designer must weigh each of these indices and make the best trade-off. The tricky part to optimizing DSP applications is understanding the trade-off between the various performance indices. For example, optimizing an application for speed often means a corresponding decrease in power consumption but an increase in memory usage. Optimizing for memory may also result in a decrease in power consumption due to fewer memory accesses but an offsetting decrease in code performance. The various trade-offs and system goals must be understood and considered before attempting any form of application optimization.
Determining which index or set of indices is important to optimize depends on the goals of the application developer. For example, optimizing for performance means that the developer can use a slow or less expensive DSP to do the same amount of work. In some embedded systems, cost savings like this can have a significant impact on the success of the product. The developer can alternatively choose to optimize the application to allow the addition of more functionality. This may be very important if the additional functionality improves the overall performance of the system, or if the developer can add more capability to the system such as an additional channel of a base station system. Optimizing for memory use can also lead to overall system cost reduction. Reducing the application size leads to a lower demand for memory, which reduces overall system cost. Finally, optimizing for power means that the application can run longer on the same amount of power. This is important for battery powered applications. This type of optimization also reduces the overall system cost with respect to power supply requirements and other cooling functionality required.
Generally, DSP optimization follows the 80/20 rule. This rule states that 20% of the software in a typical application uses 80% of the processing time. This is especially true for DSP applications that spend much of their time in tight inner loops of DSP algorithms. Thus, the real issue in optimization isn’t how to optimize, but where to optimize. The first rule of optimization is “Don’t!.” Do not start the optimization process until you have a good understanding of where the execution cycles are being spent.
The best way to determine which parts of the code should be optimized is to profile the application. This will answer the question as to which modules take the longest to execute. These will become the best candidates for performance-based optimization. Similar questions can be asked about memory usage and power consumption.
DSP application optimization requires a disciplined approach to get the best results. To get the best results out of your DSP optimization effort, the following process should be used:
Do your homework—. Make certain you have a thorough understanding of the DSP architecture, the DSP compiler, and the application algorithms. Each target processor and compiler has different strengths and weaknesses and understanding them is critical to successful software optimization. Today’s DSP optimizing compilers are advanced. Many allow the developer to use a higher order language such as C and very little, if any, assembly language. This allows for faster code development, easier debugging, and more reusable code. But the developer must understand the “hints” and guidelines to follow to enable the compiler to produce the most efficient code.
Know when to stop—. Performance analysis and optimization is a process of diminishing returns. Significant improvements can be found early in the process with relatively little effort. This is the “low hanging fruit.” Examples of this include accessing data from fast on-chip memory using the DMA and pipelining inner loops. However, as the optimization process continues, the effort expended will increase dramatically and further improvements and results will fall dramatically.
Change one parameter at a time—. Go forward one step at a time. Avoid making several optimization changes at the same time. This will make it difficult to determine what change led to which improvement percentage. Retest after each significant change in the code. Keep optimization changes down to one change per test in order to know exactly how that change affected the whole program. Document these results and keep a history of these changes and the resulting improvements. This will prove useful if you have to go back and understand how you got to where you are.
Use the right tools—. Given the complexity of modern DSP CPUs and the increasing sophistication of optimizing compilers, there is often little correlation between what a programmer thinks is optimized code and what actually performs well. One of the most useful tools to the DSP programmer is the profiler. This is a tool that allows the developer to run an application and get a “profile” of where cycles are being used throughput the program. This allows the developer to identify and focus on the core bottlenecks in the program quickly. Without a profiler, gross performance issues as well as minor code modifications can go unnoticed for long periods of time and make the entire code optimization process less disciplined.
Have a set of regression tests and use it after each iteration—. Optimization can be difficult. More difficult optimizations can result in subtle changes to the program behavior that lead to wrong answers. More complex code optimizations in the compiler can, at times, produce incorrect code (a compiler, after all, is a software program with its own bugs!). Develop a test plan that compares the expected results to the actual results of the software program. Run the test regression often enough to catch problems early. The programmer must verify that program optimizations have not broken the application. It is extremely difficult to backtrack optimized changes out of a program when a program breaks.
A general code optimization process (see Figure 8.35) consists of a series of iterations. In each iteration, the programmer should examine the compiler generated code and look for optimization opportunities. For example, the programmer may look for an abundance of NOPs or other inefficiencies in the code due to delays in accessing memory and/or another processor resource. These are the areas that become the focus of improvement. The programmer will apply techniques such as software pipelining, loop unrolling, DMA resource utilization, and so on, to reduce the processor cycle count (we will talk more about these specific techniques later). As a last resort the programmer can consider hand-tuning the algorithms using assembly language.
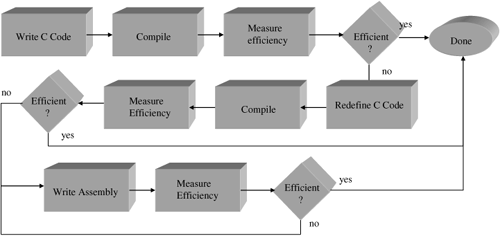
Many times, the C code can be modified slightly to achieve the desired efficiency, but finding the right “tweak” for the optimal (or close to optimal) solution can take time and several iterations. Keep in mind that the software engineer/programmer must take responsibility for at least a portion of this optimization. There have been substantial improvements in production DSP compilers with respect to advanced optimization techniques. These optimizing compilers have grown to be quite complex due to the advanced algorithms used to identify optimization opportunities and make these code transformations. With this increased complexity comes the opportunity for errors in the compiler. You still need to understand the algorithms and the tools well enough that you can supply the necessary improvements when the compiler can’t. In this chapter we will discuss how to optimize DSP software in the context of this process.
The fundamental rule in computer design as well as programming real-time DSP-based systems is “make the common case fast, and favor the frequent case.” This is really just Amdahl’s Law that says the performance improvement to be gained using some faster mode of execution is limited by how often you use that faster mode of execution. So don’t spend time trying to optimize a piece of code that will hardly ever run. You won’t get much out of it, no matter how innovative you are. Instead, if you can eliminate just one cycle from a loop that executes thousands of times, you will see a bigger impact on the bottom line. I will now discuss three different approaches to making the common case fast (by common case, I am referring to the areas in the code that consume the most resources in terms of cycles, memory, or power):
Understand the DSP architecture.
Understand the DSP algorithms.
Understand the DSP compiler.
DSP architectures are designed to make the common case fast. Many DSP applications are composed from a standard set of DSP building blocks such as filters, Fourier transforms, and convolutions. Table 8.3 contains a number of these common DSP algorithms. Notice the common structure of each of the algorithms:
They all accumulate a number of computations.
They all sum over a number of elements.
They all perform a series of multiplies and adds.

These algorithms all share some common characteristics; they perform multiplies and adds over and over again. This is generally referred to as the sum of products (SOP).
As discussed earlier, a DSP is, in many ways, an application specific microprocessor. DSP designers have developed hardware architectures that allow the efficient execution of algorithms to take advantage of the algorithmic specialty in signal processing. For example, some of the specific architectural features of DSPs to accommodate the algorithmic structure of DSP algorithms include:
Special instructions, such as a single cycle multiple and accumulate (MAC). Many signal processing algorithms perform many of these operations in tight loops. Figure 8.36 shows the savings from computing a multiplication in hardware instead of microde in the DSP processor. A savings of four cycles is significant when multiplications are performed millions of times in signal processing applications.
Large accumulators to allow for accumulating a large number of elements.
Special hardware to assist in loop checking so this does not have to be performed in software, which is much slower.
Access to two or more data elements in the same cycle. Many signal processing algorithms have multiple two arrays of data and coefficients. Being able to access two operands at the same time makes these operations very efficient. The DSP Harvard architecture shown in Figure 8.37 allows for access of two or more data elements in the same cycle.


The DSP developer must choose the right DSP architecture to accommodate the signal processing algorithms required for the application as well as the other selection factors such as cost, tools support, and so on.
DSP algorithms can be made to run faster using techniques of algorithmic transformation. For example, a common algorithm used in DSP applications is the Fourier transform. The Fourier transform is a mathematical method of breaking a signal in the time domain into all of its individual frequency components.[4] The process of examining a time signal broken down into its individual frequency components is also called spectral analysis or harmonic analysis.
There are different ways to characterize a Fourier transforms:
The Fourier transform (FT) is a mathematical formula using integrals:

The discrete Fourier transform (DFT) is a discrete numerical equivalent using sums instead of integrals which maps well to a digital processor like a DSP:

The fast Fourier transform (FFT) is just a computationally fast way to calculate the DFT which reduces many of the redundant computations of the DFT.
How these are implemented on a DSP has a significant impact on overall performance of the algorithm. The FFT, for example, is a fast version of the DFT. The FFT makes use of periodicities in the sines that are multiplied to perform the transform. This significantly reduces the amount of calculations required. A DFT implementation requires N 2 operations to calculate a N point transform. For the same N point data set, using a FFT algorithm requires N * log2(N) operations. The FFT is therefore faster than the DFT by a factor of N/log2(n). The speedup for a FFT is more significant as N increases (Figure 8.38).

Recognizing the significant impact that efficiently implemented algorithms have on overall system performance, DSP vendors and other providers have developed libraries of efficient DSP algorithms optimized for specific DSP architectures. Depending on the type of algorithm, these can downloaded from web sites (be careful of obtaining free software like this—the code may be buggy as there is no guarantee of quality) or bought from DSP solution providers.
Just a few years ago, it was an unwritten rule that writing programs in assembly would usually result in better performance than writing in higher level languages like C or C++. The early “optimizing” compilers produced code that was not as good as what one could get by programming in assembly language, where an experienced programmer generally achieves better performance. Compilers have gotten much better and today there are very specific high performance optimizations performed that compete well with even the best assembly language programmers.
Optimizing compilers perform sophisticated program analysis including intraprocedural and interprocedural analysis. These compilers also perform data and control flow analysis as well as dependence analysis and often employ provably correct methods for modifying or transforming code. Much of this analysis is to prove that the transformation is correct in the general sense. Many optimization strategies used in DSP compilers are also strongly heuristic.[5]
One effective code optimization strategy is to write DSP application code that can be pipelined efficiently by the compiler. Software pipelining is an optimization strategy to schedule loops and functional units efficiently. In modern DSPs there are multiple functional units that are orthogonal and can be used at the same time (Figure 8.39). The compiler is given the burden of figuring out how to schedule instructions so that these functional units can be used in parallel whenever possible. Sometimes this is a matter of a subtle change in the way the C code is structured that makes all the difference. In software pipelining, multiple iterations of a loop are scheduled to execute in parallel. The loop is reorganized in a way that each iteration in the pipelined code is made from instruction sequences selected from different iterations in the original loop. In the example in Figure 8.40, a five-stage loop with three iterations is shown. There is an initial period (cycles n and n+1), called the prolog when the pipes are being “primed” or initially loaded with operations. Cycles n+2 to n+4 is the actual pipelined section of the code. It is in this section that the processor is performing three different operations (C, B, and A) for three different loops (1, 2, and 3). There is a epilog section where the last remaining instructions are performed before exiting the loop. This is an example of a fully utilized set of pipelines that produces the fastest, most efficient code.

Figure 8.39. DSP Architectures May Have Orthogonal Execution Units and Data Paths Used to Execute DSP Algorithms more efficiently. In This Figure, Units L1, S1, M1, D1, and L2, S2, M2, and D2 Are all Orthogonal Execution Units that Can Have Instructions Scheduled for Execution by the Compiler in the Same Cycle if the Conditions Are Right

Figure 8.40. A Five-Stage Instruction Pipeline that Is Scheduled to Be Software Pipelined by the Compiler
Figure 8.41 shows a sample piece of C code and the corresponding assembly language output. In this case the compiler was asked to attempt to pipeline the code. This is evident by the piped loop prolog and piped loop kernel sections in the assembly language output. Keep in mind that the prolog and epilog sections of the code prime the pipe and flush the pipe, respectively, as shown in Figure 8.40. In this case, the pipelined code is not as good as it could be. You can spot inefficient code by looking for how many NOPs are in the piped loop kernel of the code. In this case the piped loop kernel has a total of five NOP cycles, two in line 16, and three in line 20. This loop takes a total of 10 cycles to execute. The NOPs are the first indication that a more efficient loop may be possible. But how short can this loop be? One way to estimate the minimum loop size is to determine what execution unit is being used the most. In this example, the D unit is used more than any other unit, a total of three times (lines 14, 15, and 21). There are two sides to a superscalar device, enabling each unit to be used twice (D1 and D2) per clock for a minimum two clock loop; two D operations in one clock and one D unit in the second clock. The compiler was smart enough to use the D units on both sides of the pipe (lines 14 and 15), enabling it to parallelize the instructions and only use one clock. It should be possible to perform other instructions while waiting for the loads to complete, instead of delaying with NOPs.
Table 8.41. C Example and the Corresponding Pipelined Assembly Language Output
1 void example1(float *out, float *input1, float *input2)
2 {
3 int i;
4
5 for(i = 0; i < 100; i++)
6 {
7 out[i] = input1[i] * input2[i];
8 }
9 }
1 _example1:
2 ;** ---------------------------------------------------------*
3 MVK .S2 0x64,B0
4
5 MVC .S2 CSR,B6
6 || MV .L1X B4,A3
7 || MV .L2X A6,B5
8 AND .L1X -2,B6,A0
9 MVC .S2X A0,CSR
10 ;** ---------------------------------------------------------*
11 L11: ; PIPED LOOP PROLOG
12 ;** ---------------------------------------------------------*
13 L12: ; PIPED LOOP KERNEL
14 LDW .D2 *B5++,B4 ;
15 || LDW .D1 *A3++,A0 ;
16 NOP 2
17 [ B0] SUB .L2 B0,1,B0 ;
18 [ B0] B .S2 L12 ;
19 MPYSP .M1X B4,A0,A0 ;
20 NOP 3
21 STW .D1 A0,*A4++ ;
22 ;** --------------------------------------------------------*
23 MVC .S2 B6,CSR
24 B .S2 B3
25 NOP 5
26 ; BRANCH OCCURS |
In the simple for loop, the two input arrays (array1 and array2) may or may not be dependent or overlap in memory. The same with the output array. In a language such as C/C++ this is something that is allowed and, therefore, the compiler must be able to handle this correctly. Compilers are generally pessimistic creatures. They will not attempt an optimization if there is a case where the resultant code will not execute properly. In these situations, the compiler takes a conservative approach and assumes the inputs can be dependent on the previous output each time through the loop. If it is known that the inputs are not dependent on the output, we can hint to the compiler by declaring input1 and input2 as “restrict,” indicating that these fields will not change. In this example, “restrict” is a keyword in C that can be used for this purpose. This is also a trigger for enabling software pipelining which can improve throughput. This C code is shown in Figure 8.42 with the corresponding assembly language.
Table 8.42. Corresponding Pipelined Assembly Language Output
1 void example2(float *out, restrict float *input1, restrict float *input2)
2 {
3 int i;
4
5 for(i = 0; i < 100; i++)
6 {
7 out[i] = input1[i] * input2[i];
8 }
9 }
1 _example2:
2 ;** ----------------------------------------------------------*
3 MVK .S2 0x64,B0
4
5 MVC .S2 CSR,B6
6 || MV .L1X B4,A3
7 || MV .L2X A6,B5
8
9 AND .L1X -2,B6,A0
10
11 MVC .S2X A0,CSR
12 || SUB .L2 B0,4,B0
13
14 ;** ---------------------------------------------------------*
15 L8: ; PIPED LOOP PROLOG
16
17 LDW .D2 *B5++,B4 ;
18 || LDW .D1 *A3++,A0 ;
19
20 NOP 1
21
22 LDW .D2 *B5++,B4 ;@
23 || LDW .D1 *A3++,A0 ;@
24
25 [ B0] SUB .L2 B0,1,B0 ;
26
27 [ B0] B .S2 L9 ;
28 || LDW .D2 *B5++,B4 ;@@
29 || LDW .D1 *A3++,A0 ;@@
30
31 MPYSP .M1X B4,A0,A5 ;
32 || [ B0] SUB .L2 B0,1,B0 ;@
33
34 [ B0] B .S2 L9 ;@
35 || LDW .D2 *B5++,B4 ;@@@
36 || LDW .D1 *A3++,A0 ;@@@
37
38 MPYSP .M1X B4,A0,A5 ;@
39 || [ B0] SUB .L2 B0,1,B0 ;@@
40
41 ;** ---------------------------------------------------------*
42 L9: ; PIPED LOOP KERNEL
43
44 [ B0] B .S2 L9 ;@@
45 || LDW .D2 *B5++,B4 ;@@@@
46 || LDW .D1 *A3++,A0 ;@@@@
47
48 STW .D1 A5,*A4++ ;
49 || MPYSP .M1X B4,A0,A5 ;@@
50 || [ B0] SUB .L2 B0,1,B0 ;@@@
51
52 ;** ---------------------------------------------------------*
53 L10: ; PIPED LOOP EPILOG
54 NOP 1
55
56 STW .D1 A5,*A4++ ;@
57 || MPYSP .M1X B4,A0,A5 ;@@@
58
59 NOP 1
60
61 STW .D1 A5,*A4++ ;@@
62 || MPYSP .M1X B4,A0,A5 ;@@@@
64 NOP 1
65 STW .D1 A5,*A4++ ;@@@
66 NOP 1
67 STW .D1 A5,*A4++ ;@@@@
68 ;** ---------------------------------------------------------*
69 MVC .S2 B6,CSR
70 B .S2 B3
71 NOP 5
72 ; BRANCH OCCURS |
There are a few things to notice in looking at this assembly language. First, the piped loop kernel has become smaller. In fact, the loop is now only two cycles long. Lines 44–47 are all executed in one cycle (the parallel instructions are indicated by the || symbol) and lines 48–50 are executed in the second cycle of the loop. The compiler, with the additional dependency information we supplied it with the “restrict” declaration, has been able to take advantage of the parallelism in the execution units to schedule the inner part of the loop very efficiently. The prolog and epilog portions of the code are much larger now. Tighter piped kernels will require more priming operations to coordinate all of the execution based on the various instruction and branching delays. But once primed, the kernel loop executes extremely fast, performing operations on various iterations of the loop. The goal of software pipelining is, like we mentioned earlier, to make the common case fast. The kernel is the common case in this example, and we have made it very fast. Pipelined code may not be worth doing for loops with a small loop count. However, for loops with a large loop count, executing thousands of times, software pipelining produces significant savings in performance while also increasing the size of the code.
In the two cycles the piped kernel takes to execute, there are a lot of things going on. The right hand column in the assembly listing indicates what iteration is being performed by each instruction. (Each “@” symbol is a iteration count. So, in this kernel, line 44 is performing a branch for iteration n+2, lines 45 and 46 are performing loads for iteration n+4, line 48 is storing a result for iteration n, line 49 is performing a multiply for iteration n+2, and line 50 is performing a subtraction for iteration n+3, all in two cycles!) The epilog is completing the operations once the piped kernel stops executing. The compiler was able to make the loop two cycles long, which is what we predicted by looking at the inefficient version of the code.
The code size for a pipelined function becomes larger, as is obvious by looking at the code produced. This is one of the trade-offs for speed that the programmer must make.
Software pipelining does not happen without careful analysis and structuring of the code. Small loops that do not have many iterations may not be pipelined because the benefits are not realized. Loops that are large in the sense that there are many instructions per iteration that must be performed may not be pipelined because there are not enough processors resources (primarily registers) to hold the key data during the pipeline operation. If the compiler has to “spill” data to the stack, precious time will be wasted having to fetch this information from the stack during the execution of the loop.
While DSP processors offer tremendous potential throughput, your application won’t achieve that potential unless you understand certain important implementation techniques. We will now discuss key techniques and strategies that greatly reduce the overall number of DSP CPU cycles required by your application. For the most part, the main object of these techniques is to fully exploit the potential parallelism in the processor and in the memory subsystem. The specific techniques covered include:
Direct memory access;
Loop unrolling; and
More on software pipelining.
Modern DSPs are extremely fast; so fast that the processor can often compute results faster than the memory system can supply new operands—a situation known as “data starvation.” In other words, the bottleneck for these systems becomes keeping the unit fed with data fast enough to prevent the DSP from sitting idle waiting for data. Direct memory access is one technique for addressing this problem.
Direct memory access (DMA) is a mechanism for accessing memory without the intervention of the CPU. A peripheral device (the DMA controller) is used to write data directly to and from memory, taking the burden off the CPU. The DMA controller is just another type of CPU whose only function is moving data around very quickly. In a DMA capable machine, the CPU can issue a few instructions to the DMA controller, describing what data is to be moved (using a data structure called a transfer control block [TCB]), and then go back to what it was doing, creating another opportunity for parallelism. The DMA controller moves the data in parallel with the CPU operation (Figure 8.43), and notifies the CPU when the transfer is complete.

Figure 8.43. Using DMA Instead of the CPU Can Offer Big Performance Improvements Because the DMA Handles the Movement of the Data while the CPU Is Buys Performing Meaningful Operations on the Data
DMA is most useful for copying larger blocks of data. Smaller blocks of data do not have the payoff because the setup and overhead time for the DMA makes it worthwhile just to use the CPU. But when used smartly, the DMA can result in huge time savings. For example, using the DMA to stage data on- and off-chip allows the CPU to access the staged data in a single cycle instead of waiting multiple cycles while data is fetched from slower external memory.
Because of the large penalty associated with accessing external memory, and the cost of getting the CPU involved, the DMA should be used wherever possible. The code for this is not too overwhelming. The DMA requires a data structure to describe the data it is going to access (where it is, where it’s going, how much, and so on). A good portion of this structure can be built ahead of time. Then it is simply a matter of writing to a memory-mapped DMA enable register to start the operation (Figure 8.44). It is best to start the DMA operation well ahead of when the data is actually needed. This gives the CPU something to do in the meantime and does not force the application to wait for the data to be moved. Then, when the data is actually needed, it is already there. The application should check to verify the operation was successful and this requires checking a register. If the operation was done ahead of time, this should be a one time poll of the register, and not a spin on the register, chewing up valuable processing time.
Table 8.44. Code to Set Up and Enable a DMA Operation Is Pretty Simple. The Main Operations Include Setting Up a Data Structure (called a TCB in the Example Above) and Performing a Few Memory Mapped Operations to Initialize and Check the Results of the Operation
-----------------------------------------------------------------------------------------
/* Addresses of some of the important DMA registers */
#define DMA_CONTROL_REG (*(volatile unsigned*)0x40000404)
#define DMA_STATUS_REG (*(volatile unsigned*)0x40000408)
#define DMA_CHAIN_REG (*(volatile unsigned*)0x40000414)
/* macro to wait for the DMA to complete and signal the status register */
#define DMA_WAIT while(DMA_STATUS_REG&1) {}
/* pre-built tcb structure */
typedef struct {
tcb setup fields
} DMA_TCB;
-----------------------------------------------------------------------------------------
extern DMA_TCB tcb;
/* set up the remaining fields of the tcb structure –
where you want the data to go, and how much you want to send */
tcb.destination_address = dest_address;
tcb.word_count = word_count;
/* writing to the chain register kicks off the DMA operation */
DMA_CHAIN_REG = (unsigned)&tcb;
Allow the CPU to do other meaningful work....
/* wait for the DMA operation to complete */
DMA_WAIT; |
The CPU can access on-chip memory much faster than off-chip or external memory. Having as much data as possible on-chip is the best way to improve performance. Unfortunately, because of cost and space considerations most DSPs do not have a lot of on-chip memory. This requires the programmer to coordinate the algorithms in such a way to efficiently use the available on-chip memory. With limited on-chip memory, data must be staged on- and off-chip using the DMA. All of the data transfers can be happening in the background, while the CPU is actually crunching the data. Once the data is in internal memory, the CPU can access the data in on-chip memory very quickly (Figure 8.46).
Smart layout and utilization of on-chip memory, and judicious use of the DMA can eliminate most of the penalty associated with accessing off-chip memory. In general, the rule is to stage the data in and out of on-chip memory using the DMA and generate the results on chip. Figure 8.45 shows a template describing how to use the DMA to stage blocks of data on and off chip. This technique uses a double-buffering mechanism to stage the data. This way the CPU can be processing one buffer while the DMA is staging the other buffer. Speed improvements over 90% are possible using this technique.

Table 8.46. With Limited On-chip Memory, Data Can Be Staged in and out of On-chip Memory Using the DMA and Leaving the CPU to Perform Other Processing
INITIALIZE TCBS
DMA SOURCE DATA 0 INTO SOURCE BUFFER 0
WAIT FOR DMA TO COMPLETE
DMA SOURCE DATA 1 INTO SOURCE BUFFER 1
PERFORM CALCULATION AND STORE IN RESULT BUFFER
FOR LOOP_COUNT =1 TO N-1
WAIT FOR DMA TO COMPLETE
DMA SOURCE DATA I+1 INTO SOURCE BUFFER [(I+1)%2]
DMA RESULT BUFFER[(I-1)%2] TO DESTINATION DATA
PERFORM CALCULATION AND STORE IN RESULT BUFFER
END FOR
WAIT FOR DMA TO COMPLETE
DMA RESULT BUFFER[(I-1)%2] TO DESTINATION DATA
PERFORM CALCULATION AND STORE IN RESULT BUFFER
WAIT FOR DMA TO COMPLETE
DMA LAST RESULT BUFFER TO DESTIMATION DATA |
Writing DSP code to use the DMA does have some cost penalties. Code size will increase, depending on how much of the application uses the DMA. Using the DMA also adds increased complexity and synchronization to the application. Code portability is reduced when you add processor specific DMA operations. Using the DMA should only be done in areas requiring high throughput.
As an example of this technique, consider the code in Figure 8.47. This code snippet sums a data field and computes a simple percentage before returning. The code in Figure 8.47 consists of 5 executable lines of code. In this example, the “processed_data” field is assumed to be in external memory of the DSP. Each access of a processed_data element in the loop will cause an external memory access to fetch the data value.
The code shown in Figure 8.48 is the same function shown in Figure 8.46 but implemented to use the DMA to transfer blocks of data from external memory to internal or on-chip memory. This code consists of 36 executable lines of code, but runs much faster than the code in Figure 8.46. The overhead associated with setting up the DMA, building the transfer packets, initiating the DMA transfers, and checking for completion are relatively small compared to the fast memory accesses of the data from on-chip memory. This code snippet was instrumented following the guidelines in the template of Figure 8.47. This code also performs a loop unrolling operation when summing the data at the end of the computation (we’ll talk more about loop unrolling later in Section 8.19). This also adds to the speedup of this code. This code snippet uses semaphores to protect the on-chip memory and DMA resources.
Table 8.48. The Same Function Enhanced to Use the DMA. This Function is 36 Executable Lines of Code but Runs Much Faster Than the Code in Figure 8.42
/*
** sum data fields to compute percentages
*/
sum0 = 0.0;
sum1 = 0.0;
sum2 = 0.0;
sum3 = 0.0;
sum4 = 0.0;
sum5 = 0.0;
sum6 = 0.0;
sum7 = 0.0;
for (i=0; i<BLOCK_SIZE; i+=8)
{
sum0 += internal_processed_data[i ];
sum1 += internal_processed_data[i + 1];
sum2 += internal_processed_data[i + 2];
sum3 += internal_processed_data[i + 3];
sum4 += internal_processed_data[i + 4];
sum5 += internal_processed_data[i + 5];
sum6 += internal_processed_data[i + 6];
sum7 += internal_processed_data[i + 7];
}
sum += sum0 + sum1 + sum2 + sum3 + sum4 +
sum5 + sum6 + sum7;
} /* block loop */
/* release on chip memory semaphore */
SEM_post(g_aos_onchip_avail_sem); |
The code in Figure 8.48 runs much faster than the code in Figure 8.47. The penalty is an increased number of lines of code, which takes up memory space. This may or may not be a problem, depending on the memory constraints of the system. Another drawback to the code in Figure 8.48 is that it is a bit less understandable and portable than the code in Figure 8.47. Implementing the code to use the DMA requires the programmer to make the code less readable, which could possibly lead to maintainability problems. The code is now also tuned for a specific DSP. Porting the code to another DSP family may require the programmer to rewrite this code to use the different resources on the new DSP.
The DMA can be considered a resource, just like memory and the CPU. When a DMA operation is in progress, the application can either wait for the DMA transfer to complete or continue processing another part of the application until the data transfer is complete. There are advantages and disadvantages to each approach. If the application waits for the DMA transfer to complete, it must poll the DMA hardware status register until the completion bit is set. This requires the CPU to check the DMA status register in a looping operation that wastes valuable CPU cycles. If the transfer is short enough, this may only require a few cycles to do and may be appropriate. For longer data transfers, the application engineer may want to use a synchronization mechanism like a semaphore to signal when the transfer is complete. In this case, the application will pend on a semaphore through the operating system while the transfer is taking place. The application will be swapped with another application that is ready to run. This swapping of tasks incurs overhead as well and should not be performed unless the overhead associated with swapping tasks is less than the overhead associated with simply polling on the DMA completion. The wait time depends on the amount of data being transferred.
Figure 8.50 shows some code that checks for the transfer length and performs either a DMA polling operation (if there are only a few words to transfer), or a semaphore pend operation (for larger data transfer sizes). The “break even” length for data size is dependent on the processor and the interface structure and should be prototyped to determine the optimal size.
Table 8.50. A Code Snippet that Pends on a Semaphore for DMA Completion
/* wait for port to become available */
while(g_io_channel_status[dir] & ACTIVE_MASK)
{
/* poll */
}
/* submittcb*/
*(g_io_chain_queue_a[dir]) = (unsigned int)tcb;
/* wait for transfer to complete */
sem_status = SEM_pend(handle, SYS_FOREVER); |
Table 8.51. A Code Snippet that Polls for DMA Completion
/* wait for port to become available */
while (g_io_channel_status[dir] & ACTIVE_MASK)
{
/* poll */
}
/* submittcb*/
*(g_io_chain_queue_a[dir]) = (unsigned int)tcb;
/* wait for transfer to complete by polling the
DMA status register */
status = *((vol_uint)*)g_io_channel_status[dir];
while ((status & DMA_ACTIVE_MASK) ==
DMA_CHANNEL_ACTIVE_MASK)
{
status = *((vol_uint*)g_io_channel_status[dir];
}
.
.
. |
The code for a pend operation is shown in Figure 8.50. In this case, the application will perform a SEM_pend operation to wait for the DMA transfer to complete. This allows the application to perform other meaningful work by temporarily suspending the currently executing task and switching to another task to perform other processing. When the operating system suspends one task and begins executing another task, a certain amount of overhead is incurred. The amount of this overhead is dependent on the DSP and operating system.
Figure 8.52 shows the code for the polling operation. In this example, the application will continue polling the DMA completion status register for the operation to complete. This requires the use of the CPU to perform the polling operation. Doing this prevents the CPU from doing other meaningful work. If the transfer is short enough and the CPU only has to poll the status register for a short period of time, this approach may be more efficient. The decision is based on how much data is being transferred and how many cycles the CPU must spend polling. If the poll takes less time than the overhead to go through the operating system to swap out one task and begin executing another, this approach may be more efficient. In that context, the code snippet below checks for the transfer length and, if the length is less than the breakeven transfer length, a function will be called to poll the DMA transfer completion status. If the length is greater than the predetermined cutoff transfer length, a function will be called to set-up the DMA to interrupt on completion of the transfer. This ensures the most efficient processing of the completion of each DMA operation.
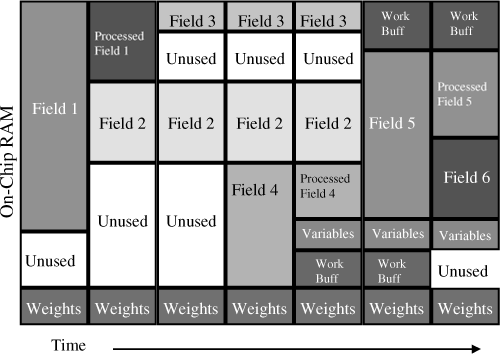
One of the most important resources for a DSP is its on-chip or internal memory. This is the area where data for most computations should reside because access to this memory is so much faster than off-chip or external memory. Since many DSPs do not have a data cache because of determinism unpredictability, software designers should think of a DSP internal memory as a sort of programmer managed cache. Instead of the hardware on the processor caching data for performance improvements with no control by the programmer, the DSP internal data memory is under full control of the DSP programmer. Using the DMA, data can be cycled in and out of the internal memory in the background, with little or no intervention by the DSP CPU. If managed correctly and efficiently, this internal memory can be a very valuable resource.
It is important to map out the use of internal memory and manage where data is going in the internal memory at all times. Given the limited amount of internal memory for many applications, not all the program’s data can reside in internal memory for the duration of the application timeline. Over time, data will be moved to internal memory, processed, perhaps used again, and moved to external memory when it is no longer needed. Figure 8.53 shows an example of how a memory map of internal DSP memory might look during the timeline of the application. During the execution of the application, different data structures will be moved to on-chip memory, processed to form additional structures on chip, and eventually be moved off-chip to external memory to be saved, or overwritten in internal memory when the data is no longer needed.
The standard rule when programming superscalar and VLIW devices is “Keep the pipelines full!” A full pipe means efficient code. In order to determine how full the pipelines are, you need to spend some time inspecting the assembly language code generated by the compiler.
To demonstrate the advantages of parallelism in VLIW-based machines, let’s start with a simple looping program shown in Figure 8.53. If we were to write a serial assembly language implementation of this, the code would be similar to that in Figure 8.54. This loop uses one of the two available sides of the superscalar machine. By counting up the instructions and the NOPs, it takes 26 cycles to execute each iteration of the loop. We should be able to do much better.
Table 8.54. Serial Assembly Language Implementation of C Loop
1 ; 2 ; serial implementation of loop (26 cycles per iteration) 3 ; 4 L1: LDW *B++,B5 ;load B[i] into B5 5 NOP 4 ; wait for load to complete 6 7 LDW *A++,A4 ; load A[i] into A4 8 NOP 4 ; wait for load to complete 9 10 MPYSP B5,A4,A4 ; A4 = A4 * B5 11 NOP 3 ; wait formult to complete 12 13 STW A4,*C++ ; store A4 in C[i] 14 NOP 4 ; wait got store to complete 15 16 SUB i,1,i ; decrement i 17 [i] B L1 ; if i != 0, gotoL1 18 NOP 5 ; delay for branch |
There are two things to notice in this example. Many of the execution units are not being used and are sitting idle. This is a waste of processor hardware. Second, there are many delay slots in this piece of assembly (20 to be exact) where the CPU is stalled waiting for data to be loaded or stored. When the CPU is stalled, nothing is happening. This is the worst thing you can do to a processor when trying to crunch large amounts of data.
There are ways to keep the CPU busy while it is waiting for data to arrive. We can be doing other operations that are not dependent on the data we are waiting for. We can also use both sides of the VLIW architecture to help us load and store other data values. The code in Figure 8.55 shows an implementation designed for a CPU with multiple execution units. While the assembly looks very much like conventional serial assembly, the run-time execution is very unconventional. Instead of each line representing a single instruction that is completed before the next instruction is begun, each line in Figure 8.55 represents an individual operation, an operation that might be scheduled to execute in parallel with some other operation. The assembly format has been extended to allow the programmer to specify which execution unit should perform a particular operation and which operations may be scheduled concurrently. The DSP compiler automatically determines which execution unit to use for an operation and indicates this by naming the target unit in the extra column that precedes the operand fields (the column containing D1, D2, and so on) in the assembly listing. To indicate that two or more operations may proceed in parallel, the lines describing the individual operations are “joined” with a parallel bar (as in lines 4 and 5 of Figure 8.55). The parallelism rules are also determined by the compiler. Keep in mind that if the programmer decides to program the application using assembly language, the responsibility for scheduling the instructions on each of the available execution units as well as determining the parallelism rules falls on the programmer. This is a difficult task and should only be done when the compiler generated assembly does not have the required performance.
Table 8.55. A More Parallel Implementation of the C Loop
1 ; using delay slots and duplicate execution units of the device 2 ; 10 cycles per iteration 3 4 L1: LDW .D2 *B++,B5 ;load B[i] into B5 5 || LDW .D1 *A++,A4 ;load A[i] into A4 6 7 NOP 2 ;wait load to complete 8 SUB .L2 i,1,i ;decrement i 9 [i] B .S1 L1 ;if i != 0, goto L1 10 11 MPYSP .M1X B5,A4,A4 ;A4 = A4 * B5 12 NOP 3 ;wait mpy to complete 13 14 STW .D1 A4,*C++ ;store A4 into C[i] |
The code in Figure 8.55 is an improvement over the serial version. We have reduced the number of NOPs from 20 to 5. We are also performing some steps in parallel. Lines 4 and 5 are executing two loads at the same time into each of the two load units (D1 and D2) of the device. This code is also performing the branch operation earlier in the loop and then taking advantage of the delays associated with that operation to complete operations on the current cycle.
The code in Figure 8.55 shows an implementation designed for a CPU with multiple execution units. While the assembly looks very much like conventional serial assembly, the run-time execution is very unconventional. Instead of each line representing a single instruction that is completed before the next instruction is begun, each line in Figure 8.55 represents an individual operation, an operation that might be scheduled to execute in parallel with some other operation. The assembly format has been extended to allow the programmer to specify which execution unit should perform a particular operation and which operations may be scheduled concurrently. The programmer specifies which execution unit to use for an operation by naming the target unit in the extra column that precedes the operand fields (the column containing D1, D2, and so on). To indicate that two or more operations may proceed in parallel, the lines describing the individual operations are “joined” with a parallel bar (as in lines 4 and 5 of Figure 8.55).
Loop unrolling is a technique used to increase the number of instructions executed between executions of the loop branch logic. This reduces the number of times the loop branch logic is executed. Since the loop branch logic is overhead, reducing the number of times this has to execute reduces the overhead and makes the loop body, the important part of the structure, run faster. A loop can be unrolled by replicating the loop body a number of times and then changing the termination logic to comprehend the multiple iterations of the loop body (Figure 8.56). The loops in Figures 8.56a and b each take four cycles to execute, but the loop in Figure 8.56b is doing four times as much work! This is illustrated in Figure 8.57. The assembly language kernel of this loop is shown in Figure 8.57a. The mapping of variables from the loop to the processor is shown in Figure 8.57b. The compiler is able to structure this loop such that all required resources are stored in the register file, and the work is spread across several of the execution units. The work done by cycle for each of these units is shown in Figure 6.57c.


Now look at the implementation of the loop unrolled four times in Figure 8.58. Again, only the assembly language for the loop kernel is shown. Notice that more of the register file is being used to store the variables needed in the larger loop kernel. An additional execution unit is also being used, as well as a several bytes from the stack in external memory (Figure 8.58b). In addition, the execution unit utilization shown in Figure 8.58c indicates the execution units are being used more efficiently while still maintaining a four cycle latency to complete the loop. This is an example of using all the available resources of the device to gain significant speed improvements. Although the code size looks bigger, it actually runs faster than the loop in Figure 8.56a.

Unrolling too much can cause performance problems. In Figure 8.59, the loop is unrolled eight times. At this point, the compiler cannot find enough registers to map all the required variables. When this happens, variables start getting stored on the stack, which is usually in external memory somewhere. This is expensive because instead of a single cycle read, it can now take many cycles to read each of the variables each time it is needed. This causes things to break down, as shown in Figure 8.59. The obvious problems are the number of bytes that are now being stored in external memory (88 versus 8 before) and the lack of parallelism in the assembly language loop kernel. The actual kernel assembly language was very long and inefficient. A small part of it is shown in Figure 8.59b. Notice the lack of “||” instructions and the new “NOP” instructions. These effectively stalls to the CPU when nothing else can happen. The CPU is waiting for data to arrive from external memory.

The drawback to loop unrolling is that it uses more registers in the register file as well as execution units. Different registers need to be used for each iteration. Once the available registers are used, the processor starts going to the stack to store required data. Going to the off-chip stack is expensive and may wipe out the gains achieved by unrolling the loop in the first place. Loop unrolling should only be used when the operations in a single iteration of the loop do not use all of the available resources of the processor architecture. Check the assembly language output if you are not sure of this. Another drawback is the code size increase. As you can see in Figure 8.58, the unrolled loop, albeit faster, requires more instructions and, therefore, more memory.
One of the best performance strategies for the DSP programmer is writing code that can be pipelined efficiently by the compiler. Software pipelining is an optimization strategy to schedule loops and functional units efficiently. In software pipelining, operations from different iterations of a software loop are performed in parallel. In each iteration, intermediate results generated by the previous iteration are used. Each iteration will also perform operations whose intermediate results will be used in the next iteration. This technique produces highly optimized code through maximum use of the processor functional units. The advantage to this approach is that most of the scheduling associated with software pipelining is performed by the compiler and not by the programmer (unless the programmer is writing code at the assembly language level). There are certain conditions that must be satisfied for this to work properly and we will talk about that shortly.
DSPs may have multiple functional units available for use while a piece of code is executing. In the case of the TMS320C6X family of VLIW DSPs, there are eight functional units that can be used at the same time, if the compiler can determine how to utilize all of them efficiently. Sometimes, subtle changes in the way the C code is structured can make all the difference. In software pipelining, multiple iterations of a loop are scheduled to execute in parallel. The loop is reorganized so that each iteration in the pipelined code is made from instruction sequences selected from different iterations in the original loop. In the example in Figure 8.60, a five-stage loop with three iterations is shown. As we discussed earlier, the initial period (cycles n and n+1), called the prolog, is when the pipes are being “primed” or initially loaded with operations. Cycles n+2 to n+4 are the actual pipelined section of the code. It is in this section that the processor is performing three different operations (C, B, and A) for three different loops (1, 2, and 3). The epilog section is where the last remaining instructions are performed before exiting the loop. This is an example of a fully utilized set of pipelines that produces the fastest, most efficient code.
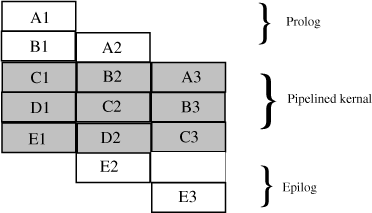
We saw earlier how loop unrolling offers speed improvements over simple loops. Software pipelining can be faster than loop unrolling for certain sections of code because, with loop unrolling, the prolog and epilog are only performed once (Figure 8.61).

Figure 8.61. Standard Loop Overhead versus Loop Unrolling and Software Pipelining. The Standard Loop Uses a Loop Check Each Iteration through the Loop. This Is Considered Overhead. Loop Unrolling Still Checks the Loop Count but Less often. Software Pipelining Substitutes the Loop Check with Prolog and Epilog Operations that Prime and Empty a Pipelined Loop Operation that Performs Many Iterations of the Loop in Parallel
To demonstrate this technique, let’s look at an example. In Figure 8.62, a simple loop is implemented in C. This loop simply multiplies elements from two arrays and stores the result in another array.
The assembly language output for this simple loop is shown in Figure 8.63. This is a serial assembly language implementation of the C loop, serial in the sense that there is no real parallelism (use of the other processor resources) taking place in the code. This is easy to see by the abundance of NOP operations in the code. These NOPs are instructions that do nothing but wait and burn CPU cycles. These are required and inserted in the code when the CPU is waiting for memory fetches or writes to complete. Since a load operation takes five CPU cycles to complete, the load word operation in line 4 (LDW) is followed by a NOP with a length of 4 indicating that the CPU must now wait four additional cycles for the data to arrive in the appropriate register before it can be used. These NOPs are extremely inefficient and the programmer should endeavor to remove as many of these delay slots as possible to improve performance of the system. One way of doing this is to take advantage of the other DSP functional resources.
Table 8.63. Assembly Language Output of the Simple Loop
1 ; 2 ; serial implementation of loop (26 cycles per iteration) 3 ; 4 L1: LDW *B++,B5 ;load B[i] into B5 5 NOP 4 ; wait for load to complete 6 7 LDW *A++,A4 ; load A[i] into A4 8 NOP 4 ; wait for load to complete 9 10 MPYSP B5,A4,A4 ; A4 = A4 * B5 11 NOP 3 ; wait formult to complete 12 13 STW A4,*C++ ; store A4 in C[i] 14 NOP 4 ; wait got store to complete 15 16 SUB i,1,i ; decrement i 17 [i] B L1 ; if i != 0, goto L1 18 NOP 5 ; delay for branch |
A more parallel implementation of the same C loop is shown in Figure 8.64. In this implementation, the compiler is able to use more of the functional units on the DSP. Line 4 shows a load operation, similar to the previous example. However, this load is explicitly loaded into the D2 functional unit on the DSP. This instruction is followed by another load into the D1 unit of the DSP. What is going on here? While the first load is taking place, moving data into the D2 unit, another load is initiated that loads data into the D1 register. These operations can be performed during the same clock cycle because the destination of the data is different. These values can be preloaded for use later and we do not have to waste as many clock cycles waiting for data to move. As you can see in this code listing, there are now only two NOP cycles required instead of four. This is a step in the right direction. The “||” symbol means that the two loads are performed during the same clock cycle.
Table 8.64. Assembly Language Output of the Simple Loop Exploiting the Parallel Orthogonal Execution Units of the DSP
1 ; using delay slots and duplicate execution units of the device 2 ; 10 cycles per iteration 3 4 L1: LDW .D2 *B++,B5 ;load B[i] into B5 5 || LDW .D1 *A++,A4 ;load A[i] into A4 6 7 NOP 2 ;wait load to complete 8 SUB .L2 i,1,i ;decrement i 9 [i] B .S1 L1 ;if i != 0, goto L1 10 11 MPYSP .M1X B5,A4,A4 ;A4 = A4 * B5 12 NOP 3 ;wait mpy to complete 13 14 STW .D1 A4,*C++ ;store A4 into C[i] |
Figure 8.65 shows the same sample piece of C code and the corresponding assembly language output. In this case, the compiler was asked (via a compile switch) to attempt to pipeline the code. This is evident by the piped loop prolog and piped loop kernel sections in the assembly language output. In this case, the pipelined code is not as good as it could be.
Table 8.65. C Example and the Corresponding Pipelined Assembly Language Output
1 void example1(float *out, float *input1, float *input2)
2 {
3 int i;
4
5 for(i = 0; i < 100; i++)
6 {
7 out[i] = input1[i] * input2[i];
8 }
9 }
1 _example1:
2 ;** -------------------------------------------------------*
3 MVK .S2 0x64,B0
4
5 MVC .S2 CSR,B6
6 || MV .L1X B4,A3
7 || MV .L2X A6,B5
8 AND .L1X -2,B6,A0
9 MVC .S2X A0,CSR
10 ;** -------------------------------------------------------*
11 L11: ; PIPED LOOP PROLOG
12 ;** -------------------------------------------------------*
13 L12: ; PIPED LOOP KERNEL
14 LDW .D2 *B5++,B4 ;
15 || LDW .D1 *A3++,A0 ;
16 NOP 2
17 [ B0] SUB .L2 B0,1,B0 ;
18 [ B0] B .S2 L12 ;
19 MPYSP .M1X B4,A0,A0 ;
20 NOP 3
21 STW .D1 A0,*A4++ ;
22 ;** ------------------------------------------------------*
23 MVC .S2 B6,CSR
24 B .S2 B3
25 NOP 5
26 ; BRANCH OCCURS |
Inefficient code can be located by looking for how many NOPs there are in the piped loop kernel of the code. In this case the piped loop kernel has a total of five NOP cycles, two in line 16, and three in line 20. This loop takes a total of ten cycles to execute. The NOPs are the first indication that a more efficient loop may be possible. But how short can this loop be? One way to estimate the minimum loop size is to determine what execution unit is being used the most. In this example, the D unit is used more than any other unit, a total of three times (lines 14, 15, and 21). There are two sides to this VLIW device, enabling each unit to be used twice (D1 and D2) per clock for a minimum two clock loop; two D operations in one clock and one D unit in the second clock. The compiler was smart enough to use the D units on both sides of the pipe (lines 14 and 15), enabling it to parallelize the instructions and only use one clock. It should be possible to perform other instructions while waiting for the loads to complete, instead of delaying with NOPs.
In the simple “for” loop, it is apparent that the inputs are not dependent on the output. In other words, there are no dependencies. But the compiler does not know that. Compilers are generally pessimistic creatures. They will not optimize something if the situation is not totally understood. The compiler takes the conservative approach and assumes the inputs can be dependent on the previous output each time through the loop. If it is known that the inputs are not dependent on the output, we can hint to the compiler by declaring the input1 and input2 as “restrict,” indicating that these fields will not change. This is a trigger for enabling software pipelining and saving throughput. This C code is shown in Figure 8.66 with the corresponding assembly language.
Table 8.66. Corresponding Pipelined Assembly Language Output
1 void example2(float *out, restrict float *input1, restrict float *input2)
2 {
3 int i;
4
5 for(i = 0; i < 100; i++)
6 {
7 out[i] = input1[i] * input2[i];
8 }
9 }
1 _example2:
2 ;** ----------------------------------------------------------*
3 MVK .S2 0x64,B0
4
5 MVC .S2 CSR,B6
6 || MV .L1X B4,A3
7 || MV .L2X A6,B5
8
9 AND .L1X -2,B6,A0
10
11 MVC .S2X A0,CSR
12 || SUB .L2 B0,4,B0
13
14 ;** ---------------------------------------------------------*
15 L8: ; PIPED LOOP PROLOG
16
17 LDW .D2 *B5++,B4 ;
18 || LDW .D1 *A3++,A0 ;
19
20 NOP 1
21
22 LDW .D2 *B5++,B4 ;@
23 || LDW .D1 *A3++,A0 ;@
24
25 [ B0] SUB .L2 B0,1,B0 ; |
There are a few things to notice in looking at this assembly language. First, the piped loop kernel has become smaller. In fact, the loop is now only two cycles long. Lines 44–47 are all executed in one cycle (the parallel instructions are indicated by the || symbol) and lines 48–50 are executed in the second cycle of the loop. The compiler, with the additional dependency information we supplied with the “restrict” declaration, has been able to take advantage of the parallelism in the execution units to schedule the inner part of the loop very efficiently. But this comes at a price. The prolog and epilog portions of the code are much larger now. Tighter piped kernels will require more priming operations to coordinate all of the execution based on the various instruction and branching delays. But once primed, the kernel loop executes extremely fast, performing operations on various iterations of the loop. The goal of software pipelining is, like we mentioned earlier, to make the common case fast. The kernel is the common case in this example, and we have made it very fast. Pipelined code may not be worth doing for loops with a small loop count. However, for loops with a large loop count, executing thousands of times, software pipelining is the only way to go.
In the two cycles the piped kernel takes to execute, there are a lot of things going on. The right hand column in the assembly listing indicates what iteration is being performed by each instruction. Each “@” symbol is a iteration count. So, in this kernel, line 44 is performing a branch for iteration n+2, lines 45 and 46 are performing loads for iteration n+4, line 48 is storing a result for iteration n, line 49 is performing a multiply for iteration n+2, and line 50 is performing a subtraction for iteration n+3, all in two cycles! The epilog is completing the operations once the piped kernel stops executing. The compiler was able to make the loop two cycles long, which is what we predicted by looking at the inefficient version of the code.
The code size for a pipelined function becomes larger, as is obvious by looking at the code produced. This is one of the trade-offs for speed that the programmer must make.
In summary, when processing arrays of data (which is common in many DSP applications) the programmer must inform the compiler when arrays are not dependent on each other. The compiler must assume that the data arrays can be anywhere in memory, even overlapping each other. Unless informed of array independence, the compiler will assume the next load operation requires the previous store operation to complete (as to not load stale data). Independent data structures allows the compiler to structure the code to load from the input array before storing the last output. Basically, if two arrays are not pointing to the same place in memory, using the “restrict” keyword to indicate this independence will improve performance. Another term for this technique is memory disambiguation.
The compiler must decide what variables to put on the stack (which take longer to access) and which variables to put in the fast on-chip registers. This is part of the register allocator of a compiler. If a loop contains too many operations to make efficient use of the processor registers, the compiler may decide to not pipeline the loop. In cases like that, it may make sense to break up the loop into smaller loops that will enable the compiler to pipeline each of the smaller loops (Figure 8.67).
The compiler will not attempt to software pipeline a loop when there are not enough resources (execution units, registers, and so on) to allow it, or if the compiler determines that it is not worth the effort to pipeline a loop because the benefit does not outweigh the gain (for example, the amount of cycles required to produce the prolog and epilog far outweighs the amount of cycles saved in the loop kernel). But the programmer can intervene in some cases to improve the situation. With careful analysis and structuring of the code, the programmer can make the necessary modification at the high language level to allow certain loops to pipeline. For example, some loops have so many processing requirements inside the loop that the compiler cannot find enough registers and execution units to map all the required data and instructions. When this happens, the compiler will not attempt to pipeline the loop. Also, function calls within a loop will not be pipelined because the compiler has a hard time resolving the function call. Instead, if you want a pipelined loop, replace the function call with an inline expansion of the function.
Because an interrupt in the middle of a fully primed pipe destroys the synergy in instruction execution, the compiler may protect a software pipelining operation by disabling interrupts before entering the pipelined section and enabling interrupts on the way out (Figure 8.68). Lines 11 and 69 of Figure 8.66 show interrupts being disabled prior to the prolog and enabled again just after completing the epilog. This means that the price of the efficiency in software pipelining is paid for in a nonpreemptible section of code. The programmer must be able to determine the impact of sections of nonpreemptible code on real time performance. This is not a problem for single task applications. But it may have an impact on systems built using a tasking architecture. Each of the software pipelined sections must be considered a blocking term in the overall tasking equation.

Not too long ago, it was an unwritten rule that writing programs in assembly would usually result in better performance than writing in higher level languages like C or C++. The early “optimizing” compilers solved the problem of “optimization” at too general and simplistic a level. The results were not as good as a good assembly language programmer. Compilers have gotten much better and today there are very specific high performance optimizations that compete well with even the best assembly language programmers.
Optimizing compilers perform sophisticated program analysis including intra-procedural and interprocedural analysis. These compilers also perform data flow and control flow analysis as well as dependence analysis and often require provably correct methods for modifying or transforming code. Much of this analysis is to prove that the transformation is correct in the general sense. Many optimization strategies used in DSP compilers are strongly heuristic.[6]
The general architecture of a modern compiler is shown in Figure 8.69. The front end of the compiler reads in the DSP source code, determines whether the input is legal, detects and reports errors, obtains the meaning of the input, and creates an intermediate representation of the source code. The intermediate stage of the compiler is called the optimizer. The optimizer performs a set of optimization techniques on the code including:
Control flow optimizations.
Local optimizations.
Global optimizations.
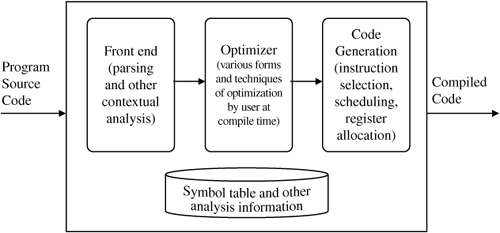
The back end of the compiler generates the target code from the intermediate code, performs the optimizations on the code for the specific target machine, and performs instruction selection, instruction scheduling and register allocation to minimize memory bandwidth, and finally outputs object code to be run on the target.
Compilers perform what are called machine independent and machine dependent optimizations. Machine independent optimizations are those that are not dependent on the architecture of the device. Examples of this are:
Branch optimization—. This is a technique that rearranges the program code to minimize branching logic and to combine physically separate blocks of code.
Loop invariant code motion—. If variables used in a computation within a loop are not altered within the loop, the calculation can be performed outside of the loop and the results used within the loop (Figure 8.70).
Loop unrolling—. In this technique, the compiler replicates the loop’s body and adjusts the logic that controls the number of iterations performed. Now the code effectively performs the same useful work with less comparisons and branches. The compiler may or may not know the loop count. This approach reduces the total number of operations but also increases code size. This may or may not be an issue. If the resultant code size is too large for the device cache (if one is being used), then the resulting cache miss penalty can overcome any benefit in loop overhead. An example of loop unrolling was discussed earlier in the chapter.
Common subexpression elimination—. In common expressions, the same value is recalculated in a subsequent expression. The duplicate expression can be eliminated by using the previous value. The goal is to eliminate redundant or multiple computations. The compiler will compute the value once and store it in a temporary variable for subsequent reuse.
Constant propagation—. In this technique, constants used in an expression are combined, and new constants are generated. Some implicit conversions between integers and floating-point types may also be done. The goal is to save memory by the removal of these equivalent variables.
Dead code elimination—. This approach attempts to eliminate code that cannot be reached or where the results are not subsequently used.
Dead store elimination—. This optimization technique will try to eliminate stores to memory when the value stored will never be referenced in the future. An example of this approach is code that performs two stores to the same location without having an intervening load. The compiler will remove the first store because it is unnecessary.
Global register allocation—. This optimization technique allocates variables and expressions to available hardware registers using a “graph coloring” algorithm.[7]
Inlining—. Inlining replaces function calls with actual program code (Figure 8.71). This can speed up the execution of the software by not having to perform function calls with the associated overhead. The disadvantage to inlining is that the program size will increase.
Table 8.71. Inlining Replaces Function Calls with Actual Code that Increases Performance but May Increase Program Size
do i = 1,n do i = 1,n j = k(i) j = k(i) call subroutine(a(i),j) temp1 = a(i) * y call subroutine(b(i),j) temp2 = a(i) / y call subroutine(c(i),j) temp3 = temp1 + temp2 ......... temp1 = b(i) * y temp2 = b(i) / y subroutine INL(x,y) temp3 = temp1 + temp2 temp1 = x * y temp1 = c(i) * y temp2 = x / y temp2 = c(i) / y temp3 = temp1 + temp2 temp3 = temp1 + temp2 endStrength reduction—. The basic approach with this form of optimization is to use cheaper operations instead of more expensive ones. A simple example of this is to use a compound assignment operator instead of an expanded one, since fewer instructions are needed:
Instead of: for ( i=0; i < array_length; i++) a[i] = a[i] + constant; Use: for ( i=0; i < array_length; i++) a[i] += constant;Another example of a strength reduction optimization is using shifts instead of multiplication by powers of two.
Alias disambiguation—. Aliasing occurs if two or more symbols, pointer references, or structure references refer to the same memory location. This situation can prevent the compiler from retaining values in registers because it cannot be certain that the register and memory continue to hold the same values over time. Alias disambiguation is a compiler technique that determines when two pointer expressions cannot point to the same location. This allows the compiler to freely optimize these expressions.
Inline expansion of runtime-support library functions—. This optimization technique replaces calls to small functions with inline code. This saves the overhead associated with a function call and provides increased opportunities to apply other optimizations.
The programmer has control over the various optimization approaches in a compiler, from aggressive to none at all. Some specific controls are discussed in the next section.
Machine dependent optimizations are those that require some knowledge of the target machine in order to perform the optimization. Examples of this type of optimization include:
Implementing special features—. This includes instruction selection techniques that produce efficient code, selecting an efficient combination of machine dependent instructions that implement the intermediate representation in the compiler.
Latency—. This involves selecting the right instruction schedules to implement the selected instructions for the target machine. There are a large number of different schedules that can be chosen and the compiler must select one that gives an efficient overall schedule for the code.
Resources—. This involves register allocation techniques that includes analysis of program variables and selecting the right combination of registers to hold the variables for the optimum amount of time, such that the optimal memory bandwidth goals can be met. This technique mainly determines which variables should be in which registers at each point in the program.
Instruction selection is important in generating code for a target machine for a number of reasons. As an example, there may be some instructions on the processor that the C compiler cannot implement efficiently. Saturation is a good example. Many DSP applications perform saturation checks on video and image processing applications. To manually write code to saturate requires a lot of code (check sign bits, determine proper limit, and so on). Some DSPs, for example, can do a similar operation in one cycle or as part of another instruction (i.e., replace a multiply instruction, MPY with a saturate multiply, SMUL=1). However, a compiler is often unable to use these algorithm-specific instructions that the DSP provides. Therefore, the programmer often has to force their use. To get the C compiler to use specific assembly language instructions like this, one approach is to use what are called intrinsics. Intrinsics are implemented with assembly language instructions on the target processor. Some examples of DSP intrinsics include:
short _abs(short src); absolute value
long _labs(long src); long absolute value
short _norm(short src); normalization
long _rnd(long src); rounding
short _sadd(short src1, short src2); saturated add
One benefit to using intrinsics like this is that they are automatically inlined. Since we want to run a processor instruction directly, we would not want to waste the overhead of doing a call. Since intrinsics also require things like the saturation flag to be set, they may be longer than one processor instruction. Intrinsics are better than using assembly language function calls since the compiler is ignorant of the contents of these assembly language functions and may not be able to make some needed optimizations.
Figure 8.72 is an example of using C code to produce a saturated add function. The resulting assembly language is also shown for a C5x DSP. Notice the amount of C code and assembly code required to implement this basic function.

Now look at the same function in Figure 8.73 implemented with intrinsics. Notice the significant code size reduction using algorithm specific special instructions. The DSP designer should carefully analyze the algorithms required for the application and determine whether a specific DSP or family of DSPs supports the class of algorithm with these special instructions. The use of these special instructions in key areas of the application can have a significant impact on the overall performance of the system.

The order in which operations are executed on a DSP has a significant impact on length of time to execute a specific function. Different operations take different lengths of time due to differences in memory access times, and differences in the functional unit of the processor (different functional units in a DSP, for example, may require different lengths of time to complete a specific operation). If the conditions are not right, the processor may delay or stall. The compiler may be able to predict these unfavorable conditions and reorder some of the instructions to get a better schedule. In the worst case, the compiler may have to force the processor to wait for a period of time by inserting delays (sometimes called NOP for “no operation”) into the instruction stream to force the processor to wait for a cycle or more for something to complete, such as a memory transfer.
Optimizing compilers have instruction schedulers to perform one major function: to reorder operations in the compiled code in an attempt to decrease its running time. DSP compilers have sophisticated schedulers that search for the optimal schedule (within reason; the compiler has to eventually terminate and produce something for the programmer!). The main goals of the scheduler are to preserve the meaning of the code (it can’t “break” anything), minimize the overall execution time (by avoiding extra register spills to main memory for example), and operate as efficiently as possible from a usability standpoint.
From a DSP standpoint, loops are critical in many embedded DSP applications. Much of the signal processing performed by DSPs is in loops. Optimizing compilers for DSP often contain specialized loop schedulers to optimize this code. One of the most common examples of this is the function of software pipelining.
An example of software pipelining was given earlier in the chapter. Software pipelining is the execution of operations from different iterations of a software loop in parallel. In each iteration, intermediate results generated by the previous iteration are used and operations are also performed whose intermediate results will be used in the next iteration. This produces highly optimized code and makes maximum use of the processor functional units. Software pipelining is implemented by the compiler if the code structure is suited to making these transformations. In other words, the programmer must produce the right code structure to the compiler such that it can recognize the conditions are right to pipeline the loop. For example, when multiplying two arrays inside a loop, the programmer must inform the compiler when the two arrays do not point to the same space in memory. (Compilers must assume arrays can be anywhere in memory, even overlapping one another. Unless informed of array independence, they will assume the next load requires the previous load to complete. By informing the compiler of this independent structure (something as simple as using a keyword in the C code) allows the compiler to load from the input array before storing last output, as shown in the code snippet below where the “restrict” keyword is used to show this independence.
void example (float *out, restrict float *input1, restrict float *input2) { int i; for (i=0; i<100; i++) { out[ i ] = input1[ i ] * input2[ i ]; } }
The primary goal of instruction scheduling is to improve running time of generated code. But be careful how this is measured. For example, measuring the quality of the produced code using a simple measure such as “Instructions per second” is misleading. Although this is a common metric in many advertisements, it may not be indicative of the quality of code produced for the specific application running on the DSP. That is why developers should spend time measuring the time to complete a fixed representative task for the application in question. Using industry benchmarks to measure overall system performance is not a good idea because the information is too specific to be used in a broad sense. In reality there is no single metric that can accurately measure quality of code produced by the compiler. We will discuss this more later.
On-chip DSP registers are the fastest locations in the memory hierarchy (see Figure 8.74). The primary responsibility of the register allocator is to make efficient use of the target registers. The register allocator works with the scheduled instructions generated by the instruction scheduler and finds an optimal arrangement for data and variables in the processors registers to avoid “spilling” data into main memory where it is more expensive to access (performance). By minimizing register spills the compiler will generate higher performing code by eliminating expensive reads and writes to main memory.

Figure 8.74. Processor Memory Hierarchy. On-chip Registers and Memory Are the Fastest Way to Access Data, Typically One Cycle per Access. Cache Systems Are Used to Increase the Performance When Requiring Data from Off-chip. Main External Memory Is the Slowest
Sometimes the code structure forces the register allocator to use external memory. For example, the C code in Figure 8.75 (which does not do anything useful) shows what can happen when too many variables are required to perform a specific calculation. This function requires a number of different variables, x0 . . . x9. When the compiler attempts to map these into registers, not all variables are accommodated and the compiler must spill some of the variables to the stack. This is shown in the code in Figure 8.76.
Table 8.75. C Code Snippet with a Number of Variables
int foo(int a, int b, int c, int d)
{
int x0, x1, x2, x3, x4, x5, x6, x7, x8, x9;
x0 = (a&0xa);
x1 = (b&0xa) + x0;
x2 = (c&0xb) + x1;
x3 = (d&0xb) + x2;
x4 = (a&0xc) + x3;
x5 = (b&0xc) + x4;
x6 = (c&0xd) + x5;
x7 = (d&0xd) + x6;
x8 = (a&0xe);
x9 = (b&0xe);
return (x0&x1&x2&x3)|(x4&x5)|(x6&x7&x8+x9);
} |

One way to reduce or eliminate register spilling is to break larger loops into smaller loops, if the correctness of the code can be maintained. This will enable the register allocator to treat each loop independently, thereby increasing the possibility of finding a suitable register allocation for each of the subfunctions. Figure 8.77 is a simple example of breaking larger loops into smaller loops to enable this improvement.
Table 8.77. Some Loops Are too Large for the Compiler to Pipeline. Reducing the Computational Load within a Loop May Allow the Compiler to Pipeline the Smaller Loops!
Instead of: Try:
for (expression) for (expression) {
{ Do A }
Do A for (expression) {
Do B Do B }
Do C for (expression) {
Do D Do C }
} for (expression) {
Do D } |
Eliminating embedded loops as shown below can also free up registers and allow for more efficient register allocation in DSP code.

Many DSP optimizing compilers offer several options for code size versus performance. Each option allows the programmer to achieve a different level of performance versus code size. These options allow more and more aggressive code size reduction from the compiler. DSP compilers support different levels of code performance. Each option allows the compiler to perform different DSP optimization techniques, for example:
First level of optimization—. Register level optimizations. This level of optimization may include techniques such as:
Second level of optimization—. Local optimization. This level of optimization may include techniques such as:
Local copy/constant propagation.
Removal of unused assignments.
Elimination of local common expressions.
Third level of optimization—. Global optimization. This level of optimization may include techniques such as:
Loop optimizations.
Elimination of global common subexpressions.
Elimination of global unused assignments.
Loop unrolling.
Highest level of optimization—. File optimizations. This level of optimization may include techniques such as:
Removal of functions that are never called.
Simplification of functions with return values that are never used.
Inlines calls to small functions (regardless of declaration).
Reordering of functions so that attributes of called function are known when caller is optimized.
Identification of file-level variable characteristics.
The different levels of optimization and the specific techniques used at each level obviously vary by vendor and compiler. The DSP programmer should study the compiler manual to understand what each level does and experiment to see how the code is modified at each level.
There will always be situations where the DSP programmer will need to get pieces of information from the compiler to help understand why an optimization was or was not made. The compiler will normally generate information on each function in the generated assembly code. Information regarding register usage, stack usage, frame size, and how memory is used is usually listed. The programmer can usually get information concerning optimizer decisions (such as to inline or not) by examining information written out by the compiler usually stored in some form of information file (you may have to explicitly ask the compiler to produce this information for you using a compiler command that should be documented in the users manual). This output file contains information as to how optimizations were done or not done (check your compiler—in some situations, asking for this information can sometimes reduce the amount of optimization actually performed).
Part of the job of an optimizing compiler is figuring out what the programmer is trying to do and then helping the programmer achieve that goal as efficiently as possible. That’s why well structured code is better for a compiler—it’s easier to determine what the programmer is trying to do. This process can be aided by certain “hints” the programmer can provide to the compiler. The proper “hints” allow the compiler to be more aggressive in the optimizations it makes to the source code. Using the standard compiler options can only get you so far towards achieving optimal performance. To get even more optimization, the DSP programmer needs to provide helpful information to the compiler and optimizer, using mechanisms called pragmas, intrinsics, and keywords. We already discussed intrinsics as a method of informing the compiler about special instructions to use in the optimization of certain algorithms. These are special function names that map directly to assembly instructions. Pragmas provide extra information about functions and variables to the preprocessor part of the compiler. Helpful keywords are usually type modifiers that give the compiler information about how a variable is used. Inline is a special keyword that causes a function to be expanded in place instead of being called.
Pragmas are special instructions to the compiler that tell it how to treat functions and variables. These pragmas must be listed before the function is declared or referenced. Examples of some common pragmas the TI DSP include:
Pragma | Description |
|---|---|
CODE_SECTION(symbol, “section name”) [;] | This pragma allocates space for a function in a given memory segment |
DATA_SECTION(symbol, “section name”) [;] | This pragma allocates space for a data variable in a given memory segment |
MUST_ITERATE(min, max, multiple) [;] | This pragma gives the optimizer part of the compiler information on the number of times a loop will repeat |
UNROLL (n) [;] | This pragma when specified to the optimizer, tells the compiler how many times to unroll a loop. |
An example of a pragma to specify the loop count is shown in Figure 8.78. The first code snippet does not have the pragma inserted and is less efficient than the second snippet, which has the pragma for loop count inserted just before the loop in the source code.

Modern optimizing compilers have special functions called intrinsics that map directly to inlined DSP instructions. Intrinsics help to optimize code quickly. They are called in the same way as a function call. Usually intrinsics are specified with some leading indicator such as the underscore (_).
As an example, if a developer were to write a routine to perform saturated addition[8] in a higher level language such as C, it would look similar to the code in Figure 8.79. The result assembly language for this routine is shown in Figure 8.80. This is quite messy and inefficient. As an alternative, the developer could write a simple routine calling a built in saturated add routine (Figure 8.81), which is much easier and produces cleaner and more efficient assembly code (Figure 8.82). Figure 8.83 shows some of the available intrinsics for the TMS320C55 DSP. Many modern DSPs support intrinsic libraries of this type.
Table 8.79. C Code to Perform Saturated Add
Int saturated_add(int a, int b)
{
int result;
result = a + b;
// check to see of a and b have the same sign
if (((a^b) & 0x8000) == 0)
{
// if a and b have the same sign, check for underflow or
// overflow
if ((result ^ a) & 0x8000)
{
// if the result has a different sign than a then
// underflow or overflow has occurred. If a is negative,
// result to max positive set result to max negative
// If a is positive, set result = ( a < 0) ?
0x8000 : 0x7FFF;
}
}
return result; |
Table 8.80. TMS320C55 DSP Assembly Code for the Saturated Add Routine
Saturated_add:
SP = SP – #1
; End Prolog Code
AR1 = T1 ; |5|
AR1 = AR1 + T0 ; |5|
T1 = T1 ^ T0 ; |7|
AR2 = T1 & #0x8000 ; |7|
if (AR2!=#0) goto L2 ; |7|
; branch occurs ; |7|
AR2 = T0 ; |7|
AR2 = AR2 ^ AR1 ; |7|
AR2 = AR2 & #0x8000 ; |7|
if (AR2==#0) goto L2 ; |7|
; branch occurs ; |7|
if (T0<#0) goto L1 ; |11|
; branch occurs ; |11|
T0 = #32767 ; |11|
goto L3 ; |11|
; branch occurs ; |11|
L1:
AR1 = #–32768 ; |11|
L2:
T0 = AR1 ; |14|
L3:
; Begin Epilog Code
SP = SP + #1 ; |14|
return ; |14|
; return occurs ; |14| |
Table 8.83. Some Intrinsics for the TMS320C55 DSP
Intrinsic | Description |
|---|---|
int _sadd(int src1, int src2); | Adds two 16–bit integers, with SATA set, producing a saturated 16–bit result. |
int _smpy(int src1, int src2); | Multiplies src1 and src2, and shifts the result left by 1. Produces a saturated 16–bit result. (SATD and FRCT set). |
int _abss(int src); | Creates a saturated 16–bit absolute value. _abss(0x8000) => 0x7FFF (SATA set) |
int _smpyr(int src1, int src2); | Multiplies src1 and src2, shifts the result left by 1, and rounds by adding 2 15 to the result. (SATD and FRCT set) |
int _norm(int src); | Produces the number of left shifts needed to normalize src. |
int _sshl(int src1, int src2); | Shifts src1 left by src2 and produces a 16-bit result. The result is saturated if src2 is less than or equal to 8. (SATD set) |
long _lshrs(long src1, int src2); | Shifts src1 right by src2 and produces a 32-bit result. Produces a saturated 32–bit result. (SATD set) |
long _laddc(long src1, int src2); | Adds src1, src2, and Carry bit and produces a 32-bit result. |
long _lsubc(long src1, int src2); | Optimizing C Code Subtracts src2 and logical inverse of sign bit from src1, and produces a 32-bit result. |
Source: Courtesy of Texas Instruments | |
Keywords are type modifiers that give the compiler information about how a variable is used. These can be very helpful in helping the optimizer part of the compiler make optimization decisions. Some common keywords in DSP compilers are:
Const—. This keyword defines a variable or pointer as having a constant value. The compiler can allocate the variable or pointer into a special data section that can be placed in ROM. This keyword will also provide information to the compiler that allows it to make more aggressive optimization decisions.
Interrupt—. This keyword will force the compiler to save and restore context and enable interrupts on exit from a particular pipelined loop or function.
Ioport—. This defines a variable as being in I/O space (this keyword is only used with global or static variables).
On-chip—. Using this keyword with a variable or structure will guarantee that that memory location is on-chip.
Restrict—. This keyword tells the compiler that only this pointer will access the memory location it points to (i.e., no aliasing of this location). This allows the compiler to perform optimization techniques, such as software pipelining.
Volatile—. This keyword tells the compiler that this memory location may be changed without compiler’s knowledge. Therefore, the memory location should not be stored in a temporary register and, instead, be read from memory before each use.
For small infrequently called functions it may make sense to paste them directly into code. This eliminates overhead associated with register storage and parameter passing. Inlining uses more program space, but speeds up execution, sometimes significantly. When functions are inlined, the optimizer can optimize the function and the surrounding code in new context. There are two types of inlining: static inlining and normal inlining. With static inlining the function being inlined is only placed in the code where it will be used. Normal inlining also has a function definition that allows the function to be called. The compiler, if specified, will automatically inline functions if the size is small enough. Inlining can also be definition controlled, where the programmer specifies which functions to inline.
When using a real-time operating system (RTOS) for task driven systems, there is overhead to consider that increases with the number of tasks in the system. The overhead in a task switch (or mailbox pend or post, semaphore operation, and so forth) can vary based on where the operating system structures are located. If the structures are in off-chip memory, the access time to perform the operation can be much longer than if the structure was in on-chip memory. The same holds true for the task stack space. If this is in off-chip memory, the performance suffers proportionally to the number of times the stack has to be accessed.
One solution is to allocate the stack in on-chip memory. If the stack is small enough, this may be a viable thing to do. However, if there are many tasks in the system, there will not be enough on-chip memory to store all of the task stacks. However, special code can be written to move the stack on chip when it is needed the most. Before the task (or function) is complete, the stack can be moved back off chip. Figure 8.84 shows the code to do this. Figure 8.85 is a diagrammatic explanation of the steps to perform this operation. The steps are as follows:
Compile the C code to get a .asm file.
Modify the .asm file with the code in the example.
Assemble the new .asm file.
Link the system.

You need to be careful when doing this. This type of modification should not be done in a function that calls other functions. Also, interrupts should be disabled when performing this type of operation. Finally, the programmer needs to ensure that the secondary stack in on-chip memory does not grow too large, overwriting other data in on-chip memory!
Compilers do their best to optimize applications based on the wishes of their programmers. Compilers also produce output that documents the decisions they were able to make or not make based on the specific source code provided to them by the programmer. (See Figure 8.86.) By analyzing this output, the programmer can understand the specific constraints and decisions and make appropriate adjustments in the source code to improve the performance of the compiler. In other words, if the programmer understands the thought process of the compilation process, they are then able to reorient the application to be more consistent with that thought process. The information below is an example of output generated by the compiler that can be analyzed by the programmer. This output can come in various forms, a simple text output file or a fancier user interface to guide the process of analyzing the compiled output.

Here is a summary of guidelines that the DSP programmer can use to produce the most highly optimized code for the DSP application. Many of these recommendations are general to all DSP compilers. The recommendation is to develop a list like the one below for whatever DSP device and compiler is being used. It will provide a useful reference for the DSP programming team during the software development phase of a DSP project.
General Programming Guidelines
Avoid removing registers for C compiler usage. Otherwise valuable compiler resources are being thrown away. There are some cases when it makes sense to use these resources. For example, it is acceptable to preserve a register for an interrupt routine.
To optimize functions selectively, place in separate files. This lets the programmer adjust the level of optimization on a file-specific basis.
Use the least possible number of volatile variables. The compiler cannot allocate registers for these, and also can’t inline when variables are declared with the volatile keyword.
Variable Declaration
Local variables/pointers are preferred instead of globals. The compiler uses stack-relative addressing for globals, which is not as efficient. If the programmer will frequently be using a global variable in a function, it is better to assign the global to a local variable and then use it.
Declare globals in file where they are used the most.
Allocate most often used elements of a structure, array or bit-field in the first element, lowest address or LSB; this eliminates the need for extra bytes to specify the address offset.
Use unsigned variables instead of int wherever possible; this provides a larger dynamic range and gives extra information to the compiler for optimization.
Variable Declaration (Data Types)
Pay attention to data type significance. The better the information provided to the compiler, the better the efficiency of the resulting code.
Only use casting if absolutely necessary, casting can use extra cycles, and can invoke wrong RTS functions if done wrong.
Avoid common mistakes in data type assumptions. Avoid code that assumes int and long are the same type. Also, use int for fixed-point arithmetic, since long requires a call to a library, which is less efficient. Also, avoid code that assumes char is 8 bits or long long is 64 bits for the same reasons.
May be more convenient to define your own data types. Int16 for 16-bit integer (int) and Int32 for 32-bit integer (long). Experiment and see what is best for your DSP device and application.
Initialization of Variables
Initialize global variables with constants at load time. This eliminates the need to have code copy values over at run-time.
When assigning the same values to global variables, rearrange code if it makes sense to do so. For example use a = b = c = 3; instead of a = 3; b = 3; c = 3. The first uses a register to store the same value to all, the second produces 3 separate long stores;
MOV #3, AR1 MOV #3, *(#_a) MOV AR1, *(#_a) MOV #3, *(#_b) MOV AR1, *(#_b) MOV #3, *(#_c) MOV AR1, *(#_c) (17 bytes) (18 bytes)
Memory alignment requirements and stack management.
Group all like data declarations together. The compiler will usually align a 32-bit data on even boundary, so it will pad an extra 16-bit word in if needed.
Use the .align linker directive to guarantee stack alignment on even address. Since the compiler needs 32-bit data aligned on an even boundary, it starts the stack on an even boundary.
Loops
Split up loops comprised of two unrelated operations.
Avoid function calls and control statements inside loops; the compiler needs to preserve loop context in case of a call to a function. By taking function calls and control statements outside a loop if possible, the compiler can take advantage of the special looping optimizations in the hardware (for example the localrepeat and blockrepeat in the TI DSP) to further optimize the loop (Figure 8.87).
Keep loop code small to enable compiler use of local repeat optimizations.
Avoid deeply nested loops; more deeply nested loops use less efficient types of looping.
Use an int or unsigned int instead of long for loop counter. DSP hardware generally uses a 16-bit register for a counter.
Use pragmas (if available) to give the compiler better information about loop counts.
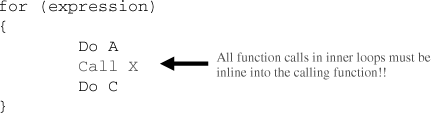
Control Code
The DSP compiler may generate similar code for nested if-then-else and switch-case statements if the number of cases is less than eight. If greater than eight, the compiler will generate a .switch label section.
For highly dense compare code, use switch statements instead of if-then-else.
Place the most common case at the start, since the compiler checks in order.
For single conditionals, it is always best to test against 0 instead of !0; For example, ‘if (a = = 0)’ produces more efficient code than ‘if (a! = 1)’.
Functions
When a function is only called by other functions in same file, make it a static function. This will allow the compiler to inline functions better.
When a global variable is only used by functions in the same file, make it a static variable.
Group minor functions in a single file with functions that use them. This makes file-level optimization better.
Too many parameters in function calls become inefficient. Once DSP registers are used up, the rest of the parameters go on the stack. Accessing variables from the stack is very inefficient.
Parameters that are used frequently in the subroutine should be passed in registers.
Intrinsics
There are some instructions on a DSP that the C compiler cannot implement efficiently. For example, the saturation function is hard to implement using standard instructions on many DSPs. To saturate manually requires a lot of code (check sign bits, determine proper limit, and so on). DSPs that support specific instrinsics like saturate will allow the DSP to execute the function much more efficiently.
When developing an application, it is very easy (and sometimes even required) to use generic routines to do various computations. Many time the application developer does not realize how much overhead can be involved in using these generic routines. Often times a more generalized version of an algorithm or function is used because of simple availability instead of creating a more specialized version that better fits the specific need. Creating large numbers of specialized routines is generally a bad programming style as well as a maintenance headache. But strategic use of specialized routines can greatly improve performance in high performance code segments.
Use Libraries
Some optimizations are more macro or global level optimizations. These optimizations are performed at the algorithm level. This is somewhat unique to DSP where there are many common routines such as FFT, FIR filters, IIR filters, and so on. Eventually, just about every DSP developer will be required to use one of these functions in the development of a DSP application. For common functions used in DSP, vendors have developed highly efficient implementations of these algorithms that can be easily reused. Many of these algorithms are implemented in C and are tested against standards and well documented. Examples include:
Although many of these algorithms are very common routines in DSP, they can be complex to implement. Writing one from scratch would require an in-depth knowledge of how the algorithm works (for example an FFT), in-depth knowledge of the DSP architecture in order to optimize the algorithm, possibly expertise at assembly coding, which is hard to find, and time to get everything working right and optimized.
Because there is a trade-off between code size and higher performance, it is often desirable to compile some functions in a DSP application for performance and others for code size. In fact, the ideal code size and performance for your application needs may be some combination of the different levels of optimization across all of the application functions. The challenge is in determining which functions need which options. In an application with 100 or more functions, each with five possible options, the number of option combinations starts to explode exponentially. Because of this, manual experimentation can take weeks of effort, and the DSP developer may rarely arrive at a solution close to optimal for the particular application needs. Profile-based compilation is one available technique that helps to solve this challenge by automating the entire process.
Profile-based compilation will automatically build and profile multiple compiler option sets. For example, this technique can build the entire application with the highest level of optimization and then profile each function to obtain its resulting code size and cycle count. This process is then repeated using the other compiler options at the remaining code-size reduction levels. The result is a set of different code size and cycle count data points for each function in the application. That data can then be plotted to show the most interesting combinations of functions and compiler options (Figure 8.88). The ideal location for the application is always at the origin of the graph in the lower left hand corner where cycle count and code size are both minimized.
Figure 8.88. Profile-based Compilation Shows the Various Trade-offs between Code Size and Performance
An advantage of a profile-based environment is the ability for the application developer to select a profile by selecting the appropriate point on the curve, depending on the overall system needs. This automatic approach saves many hours of experimenting manually. The ability to display profiling information (cycle count by module or function, for example) allows the developer to see the specifics of each piece of the application and work on that section independently, if desired (Figure 8.89).

One word of caution: Do not optimize programs that you intend to debug with a symbolic debugger. The compiler optimizer rearranges assembler-language instructions that makes it difficult to map individual instructions to a line of source code. If compiling with optimization options, be aware that this rearrangement may give the appearance that the source-level statements are executed in the wrong order when using a symbolic debugger.
The DSP programmer can ask the compiler to generate symbolic debugging information for use during a debug session. Most DSP compilers have an option for doing this. DSP compiler have directives that will generate symbolic debugging directives used by C source-level debugger. The downside to this is that it forces the compiler to disable many optimizations. The compiler will turn on the maximum optimization compatible with debugging. The best solution for debugging DSP code however, is first to verify the program’s correctness and then start turning on optimizations to improve performance.
Given that this chapter is about managing the DSP software development process, we must now expand our definition of the code optimization process first discussed at the beginning of the chapter. Figure 8.90 shows an expanded software development process for code optimization.
Although this process may vary based on the application, this process is a general flow for all DSP applications. There are 21 steps in this process that will be summarized below.
Step 1—. This step involves understanding the key performance scenarios for the application. A performance scenario is a path through the DSP application that will stress the available resources in the DSP. This could be performance, memory, and/or power. Once these key scenarios are understood, the optimization process can focus on these “worst case” performance paths. If the developer can reach performance goals in these conditions, all other scenarios should meet their goals as well.
Step 2—. Once the key performance scenarios are understood, the developer then selects the key goals for each resource being optimized. One goal may be to consume no more than 75% of processor throughput or memory, for example. Once these goals are established, there is something to measure progress towards as well as stopping criteria. Most DSP developers optimize until they reach a certain goal and then stop.
Step 3—. Once these goals are selected, the developer, if not done already, selects the DSP to meet the goals of the application. At this point, no code is run, but the processor is analyzed to determine whether it can meet the goals through various modeling approaches.
Step 4—. This step involves analyzing key algorithms in the system and making any algorithm transformations necessary to improve the efficiency of the algorithm. This may be in terms of performance, memory, or power. An example of this is selecting a fast Fourier transform instead of a slower discrete Fourier transform.
Step 5—. This step involves doing a detailed analysis of the key algorithms in the system. These are the algorithms that will run most frequently in the system or otherwise consume the most resources. These algorithms should be benchmarked in detail, sometimes even to the point of writing these key algorithms in the target language and measuring the efficiency. Given that most of the application cycles may be consumed here, the developer must have detailed data for these key benchmarks. Alternatively, the developer can use industry benchmark data if there are algorithms that are very similar to the ones being used in the application. Examples of these industry benchmarks include the Embedded Processor Consortium at eembc.org and Berkeley Design Technology at bdti.com.
Step 6—. This step involves writing “out of the box” C/C++ code, which is simply code with no architecture specific transformations done to “tune” the code to the target. This is the simplest and most portable structure for the code. This is the desired format if possible, and code should only be modified if the performance goals are not met. The developer should not undergo a thought process of “make it as fast as possible.” Symptoms of this thought process include excessive optimization and premature optimization. Excessive optimization is when a developer keeps optimizing code even after the performance goals for the application have been met. Premature optimization is when the developer begins optimizing the application before understanding the key areas that should be optimized (following the 80/20 rule). Excessive and premature optimization are dangerous because these consume project resources, delay releases, and compromise good software designs without directly improving performance.
Step 7—. This is the “make it work right before you make it work fast” approach. Before starting to optimize the application that could potentially break a working application because of the complexity involved, the developer must make the application work correctly. This is most easily done by turning off optimizations and debugging the application using a standard debugger until the application is working. To get a working application, the developer must also create a test regression that is run to confirm that the application is indeed working. Part of this regression should be used for all future optimizations to ensure that the application is still working correctly after each successive round of optimization.
Step 8—. This step involves running the application and collecting profiling information for each function of the application. This profiling information could be cycles consumed for each function, memory used, or power consumed. This data can then be pareto ranked to determine the biggest contributors to the performance bottlenecks. The developer can then focus on these key parts of the application for further optimization. If the goals are met, then no optimizations are needed. If the goals are not met the developer moves on to step 9.
Step 9—. In this step, the developer turns on basic compiler optimizations. These include many of the machine independent optimizations that compilers are good at finding. The developer can select options to reduce cycles (increase performance) or to reduce memory size. Power can also be considered during this phase.
Steps 10, 12, 14, 16, 18, and 20—. These steps involve re-running the test regression for the application and measuring performance against goals. If the goals are met then the developer is through. If not, the developer reprofiles the application and establishes a new pareto rank of top performance, memory, or power bottlenecks.
Step 13—. This step involves restructuring or tuning the C/C++ code to map the code more efficiently to the DSP architecture. Examples of this were discussed earlier in the chapter. Restructuring C or C++ code can lead to significant performance improvements but makes the code potentially less portable and readable. The developer should first attempt this where there are the most significant performance bottlenecks in the system.
Step 15—. In this step, the C/C++ code is instrumented with very specific information to help the compiler make more aggressive optimizations based on these “hints” from the developer. Three common forms of this instrumentation include using special instructions with intrinsics, pragmas, and keywords.
Step 17—. If the compiler supports multiple levels of optimization, the developer should proceed to turn on higher levels of optimization to allow the compiler to be more aggressive in searching for code transformations to yield more performance gains. These higher levels of optimization are advanced and will cause the compiler to run longer searching for these optimizations. Also, there is the chance that a more aggressive optimization will do something to break the code or otherwise cause it to behave incorrectly. This is where a regression test suite that is run periodically is so important.
Step 19—. As final resort, the developer rewrites the key performance bottlenecks in assembly language if result can yield performance improvements above what the compiler can produce. This is a final step, since writing assembly language reduces portability, increases maintainability, decreases readability, and it has other side effects. For advanced architectures, assembly language may mean writing highly complex and parallel code that runs on multiple independent execution units. This can be very difficult to learn to do well and generally there are not many DSP developers that can become expert assembly language programmers without a significant ramp time.
Step 21—. Each of the optimization steps described above are iterative. The developer may iterate through these phases multiple times before moving on to the next phase. If the performance goals are not being met by this phase, the developer needs to consider repartitioning the hardware and software for the system. These decisions are painful and costly but they must be considered when goals are not being met by the end of this optimization process.
As shown in Figure 8.91, when moving through the code optimization process, improvements become harder and harder to achieve. When optimizing generic “out of the box” C or C++ code, just a few optimizations can lead to significant performance improvements. Once the code is tuned to the DSP architecture and the right hints are given to the compiler in the form of intrinsics, pragmas, and keywords, additional performance gains are difficult to achieve. The developer must know where to look for these additional improvements. That’s why profiling and measuring are so important. Even assembly language programming cannot always yield full entitlement from the DSP device. The developer ultimately has to decide how far down the curve in Figure 8.91 the effort should go, as the cost/benefit ratio gets less justifiable given the time required to perform the optimizations at these lower levels of the curve.
Coding for speed requires the programmer to match the expression of the application’s algorithm to the particular resources and capabilities of the processor. Key among these fit issues is how data is staged for the various operations. The iterative nature of DSP algorithms also makes loop efficiency critically important. A full understanding of when to unroll loops and when and how to pipeline loops will be essential if you are to write high-performance DSP code—even if you rely on the compiler to draft most of such code.
Whereas, hand-tuned assembly code was once common for DSP programmers, modern optimizing DSP compilers, with some help, can produce very high performance code.
Embedded real-time applications are an exercise in optimization. There are three main optimization strategies that the embedded DSP developer needs to consider:
DSP architecture optimization—. DSPs are optimized microprocessors that perform signal processing functions very efficiently by providing hardware support for common DSP functions.
DSP algorithm optimization—. Choosing the right implementation technique for standard and often used DSP algorithms can have a significant impact on system performance.
DSP compiler optimization—. DSP compilers are tools that help the embedded programmer exploit the DSP architecture by mapping code onto the resources in such a way as to utilize as much of the processing resources as possible, gaining the highest level of architecture entitlement as possible.
TMS320C62XX Programmers Guide, Texas Instruments, 1997
Computer Architecture, A Quantitative Approach, by John L. Hennesey and David A. Patterson, copyright 1990 by Morgan Kaufmann Publishers, Inc., Palo Alto, CA
The Practice of Programming, by Brian W. Kernighan and Rob Pike, Addison Wesley, 1999
TMS320C55x_DSP_Programmer’s_Guide
TMS320C55xx Optimizing C/C++ Compiler User’s Guide (SPRU281C)TMS320C55x
DSP Programmer’s Guide (SPRU376A)
Generating Efficient Code with TMS320 DSPs: Style Guidelines (SPRA366)
How to Write Multiplies Correctly in C Code (SPRA683)
TMS320C55x DSP Library Programmer’s Reference (SPRU422)
[1] Rate monotonic analysis (RMA) is a collection of quantitative methods and algorithms that allow engineers to specify, understand, analyze, and predict the timing behavior of real-time software systems, thus improving their dependability and evolvability.
[2] A strategy for CPU or disk access scheduling. With EDF, the task with the earliest deadline is always executed first.
[3] Relating to or derived by reasoning from self-evident propositions (formed or conceived beforehand), as compared to a posteriori that is presupposed by experience (www.wikipedia.org).
[4] Brigham, E. Oren, 1988, The Fast Fourier Transform and Its Applications, Englewood Cliffs, NJ: Prentice-Hall, Inc., p. 448.
[5] Heuristics involves problem solving by experimental and especially trial-and-error methods or relating to exploratory problem-solving techniques that utilize self-educating techniques (as the evaluation of feedback) to improve performance.
[6] Heuristics involves problem solving by experimental and especially trial-and-error methods or relating to exploratory problem-solving techniques that utilize self-educating techniques (as the evaluation of feedback) to improve performance (Webster’s English Language Dictionary).
[7] The problem of assigning data values to registers is a key challenge for compiler engineers. This problem can be converted into one of graph-coloring. In this approach, attempting to color a graph with N colors is equivalent to attempting to allocate data into N registers. Graph coloring is then the partitioning of the vertices of a graph into a minimum number of independent sets.
[8] Saturated add is a process by which two operands are added together and, if the result is an overflow, the result is set to the maximum positive value. This is useful in certain multimedia applications where it is more desirable to have a result that is max positive instead of an overflow that effectively becomes a negative number that looks undesirable in an image, for example.