
3. More with Data Types
In Chapter 2, we covered all the C# predefined types and briefly touched on the topic of reference types versus value types. In this chapter, we continue the discussion of data types with further explanation of the categories of types.
In addition, we delve into the details of combining data elements together into tuples—a feature introduced in C# 7.0—followed by grouping data into sets called arrays. To begin, let’s delve further into understanding value types and reference types.
Categories of Types
All types fall into one of two categories: value types and reference types. The differences between the types in each category stem from how they are copied: Value type data is always copied by value, whereas reference type data is always copied by reference.
Value Types
Except for string, all the predefined types in the book so far have been value types. Variables of value types contain the value directly. In other words, the variable refers to the same location in memory where the value is stored. Because of this, when a different variable is assigned the same value, a copy of the original variable’s value is made to the location of the new variable. A second variable of the same value type cannot refer to the same location in memory as the first variable. Consequently, changing the value of the first variable will not affect the value in the second variable, as Figure 3.1 demonstrates. In the figure, number1 refers to a location in memory that contains the value 42. After assigning number1 to number2, both variables will contain the value 42. However, modifying either variable’s value will not affect the other.
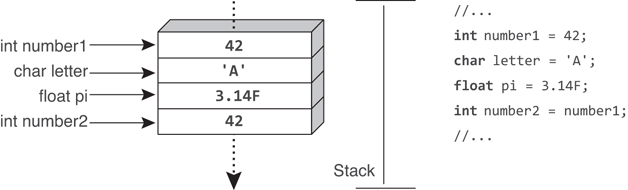
Figure 3.1: Value types contain the data directly
Similarly, passing a value type to a method such as Console.WriteLine() will result in a memory copy, and any changes to the parameter inside the method will not affect the original value within the calling function. Since value types require a memory copy, they generally should be defined to consume a small amount of memory; value types should almost always be less than 16 bytes in size.
Reference Types
By contrast, the value of a variable of reference type is a reference to a storage location that contains data. Reference types store the reference where the data is located instead of storing the data directly, as value types do. Therefore, to access the data, the runtime reads the memory location out of the variable and then “jumps” to the location in memory that contains the data, an operation known as dereferencing. The memory area of the data a reference type points to is called the heap (see Figure 3.2).

Figure 3.2: Reference types point to the heap
A reference type does not require the same memory copy of the data that a value type does, which makes copying reference types far more efficient than copying large value types. When assigning the value of one reference type variable to another reference type variable, only the reference is copied, not the data referred to. In practice, a reference is always the same size as the “native size” of the processor—a 32-bit processor will copy a 32-bit reference, a 64-bit processor will copy a 64-bit reference, and so on. Obviously, copying the small reference to a large block of data is faster than copying the entire block, as a value type would.
Since reference types copy a reference to data, two different variables can refer to the same data. If two variables refer to the same object, changing data in the object via one variable causes the effect to be seen when accessing the same data via another variable. This happens both for assignment and for method calls. Therefore, a method can affect the data of a reference type, and that change can be observed when control returns to the caller. For this reason, a key factor when choosing between defining a reference type or a value type is whether the object is logically like an immutable value of fixed size (and therefore possibly a value type), or logically a mutable thing that can be referred to (and therefore likely to be a reference type).
Besides string and any custom classes such as Program, all types discussed so far are value types. However, most types are reference types. Although it is possible to define custom value types, it is relatively rare to do so in comparison to the number of custom reference types.
Begin 8.0Begin 2.0Declaring Types That Allow null
Often it is desirable to represent values that are “missing.” When specifying a count, for example, what do you store if the count is unknown or unassigned? One possible solution is to designate a “magic” value, such as -1 or int.MaxValue. However, these are valid integers, so it can be ambiguous as to when the magic value is a normal int or when it implies a missing value. A preferable approach is to assign null to indicate that the value is invalid or that the value has not been assigned. Assigning null is especially useful in database programming. Frequently, columns in database tables allow null values. Retrieving such columns and assigning them to corresponding variables within C# code is problematic, unless the data type in C# can contain null as well.
You can declare a type as either nullable or not nullable, meaning you can declare a type to allow a null value or not, with the nullable modifier. (Technically, C# only includes support for the nullable modifier with value types in C# 2.0 and reference types in C# 8.0.) To enable nullability, simply follow the type declaration with a nullable modifier—a question mark immediately following the type name. For example, int? number = null will declare a variable of type int that is nullable and assign it the value null. Unfortunately, nullability includes some pitfalls, requiring the use of special handling when nullability is enabled.
8.0Dereferencing a null Reference
While support for assigning null to a variable is invaluable (pun intended), it is not without its drawbacks. While copying or passing a null value to other variables and methods is inconsequential, dereferencing (invoking a member on) an instance of null will throw a System.NullReferenceException—for example, invoking text.GetType() when text has the value null. Anytime production code throws a System.NullReferenceException, it is always a bug. This exception indicates that the developer who wrote the code did not remember to check for null before the invocation. Further exacerbating the problem, checking for null requires an awareness on the developer’s part that a null value is possible and, therefore, an explicit action is necessary. It is for this reason that declaring of a nullable variable requires explicit use of the nullable modifier—rather than the opposite approach where null is allowed by default (see “Nullability of Reference Types before C# 8.0” later in the section). In other words, when the programmer opts in to allow a variable to be null, he or she takes on the additional responsibility of being sure to avoid dereferencing a variable whose value is null.
Since checking for null requires the use of statements and/or operators that we haven’t discussed yet, the details on how to check for null appear in Advanced Topic: Checking for null. Full explanations, however, appear in Chapter 4.
2.0Nullable Value Types
Since a value type refers directly to the actual value, value types cannot innately contain a null because, by definition, they cannot contain references, including references to nothing. Nonetheless, we still use the term “dereferencing a value type” when invoking members on the value type. In other words, while not technically correct, using the term “dereferencing” when invoking a member, regardless of whether it is a value type, is common.1
1. Nullable value types were introduced with C# 2.0.
2.08.0Nullable Reference Types
Prior to C# 8.0, all reference types allowed null. Unfortunately, this resulted in numerous bugs because avoiding a null reference exception required the developer to realize the need to check for null and defensively program to avoid dereferencing the null value. Further exacerbating the problem, reference types are nullable by default. If no value is assigned to a variable of reference type, the value will default to null. Moreover, if you dereferenced a reference-type local variable whose value was unassigned, the compiler would (appropriately) issue an error, "Use of unassigned local variable 'text'", for which the easiest correction was to simply assign null during declaration, rather than to ensure a more appropriate value was assigned regardless of the path that execution mgiht follow (see Listing 3.2). In other words, developers would easily fall into the trap of declaring a variable and assigning a null value as the simplest resolution to the error, (perhaps mistakenly) expecting the code would reassign the variable before it was dereferenced.
Listing 3.2: Dereferencing an Unassigned Variable
#nullable eneable static void Main() { string? text; // ... // Compile error: Use of unassigned local variable 'text' System.Console.WriteLine(text.length); }
In summary, the nullability of reference types by default was a frequent source of defects in the form of System.NullReferenceExceptions, and the behavior of the complier led developers astray unless they took explicit actions to avoid the pitfall.
To improve this scenario significantly, the C# team introduced the concept of nullability to reference types in C# 8.0—a feature known as nullable reference types (implying, of course, that reference types could be non-nullable as well). Nullable reference types bring reference types on par with value types, in that reference type declarations can occur with or without a nullable modifier. In C# 8.0, declaring a variable without the nullable modifier implies it is not nullable.
Unfortunately, supporting the declaration of a reference type with a nullable modifier and defaulting the reference type declaration with no null modifier to non-nullable has major implications for code that is upgraded from earlier versions of C#. Given that C# 7.0 and earlier supported the assignment of null to all reference type declarations (i.e., string text = null), does all the code fail compilation in C# 8.0?
Fortunately, backward compatibility is extremely important to the C# team, so support for reference type nullability is not enabled by default. Instead, there are a couple of options to enable it: the #nullable directive and project properties.
First, the null reference type feature is activated in this example with the #nullable directive:
#nullable enable
The directive supports values of enable, disable, and restore—the last of which restores the nullable context to the project-wide setting. Listing 3.2 provides an example that sets nullable to enabled with a nullable directive. In so doing, the declaration of text as string? is enabled and no longer causes a compiler warning.
Alternatively, programmers can use project properties to enable reference type nullability. By default, a project file’s (*.csproj) project-wide setting has nullable disabled. To enable it, add a Nullable project property whose value is enable, as shown in Listing 3.3.
Listing 3.3: Enabling Nullable Project-wide In a csproj File
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.0</TargetFramework> <Nullable>enable</Nullable> </PropertyGroup> </Project>
All sample code for this book (available at https://github.com/EssentialCSharp) has nullable enabled at the project level. Alternatively, you can also set the project properties on the dotnet command line with the /p argument:
dotnet build /p:Nullable=enable
Specifying the value for Nullable on the command line will override any value set in the project file.
End 8.0Begin 3.0Implicitly Typed Local Variables
C# 3.0 added a contextual keyword, var, for declaring an implicitly typed local variable. If the code initializes a variable at declaration time with an expression of unambiguous type, C# 3.0 and later allow for the variable data type to be implied rather than stated, as shown in Listing 3.4.
Listing 3.4: Working with Strings
class 3.2->3.Uppercase { static void Main() { System.Console.Write("Enter text: "); var text = System.Console.ReadLine(); // Return a new string in uppercase var uppercase = text.ToUpper(); System.Console.WriteLine(uppercase); } }
This listing differs from Listing 2.18 in two ways. First, rather than using the explicit data type string for the declaration, Listing 3.4 uses var. The resultant CIL code is identical to using string explicitly. However, var indicates to the compiler that it should determine the data type from the value (System.Console.ReadLine()) that is assigned within the declaration.
Second, the variables text and uppercase are initialized by their declarations. To not do so would result in an error at compile time. As mentioned earlier, the compiler determines the data type of the initializing expression and declares the variable accordingly, just as it would if the programmer had specified the type explicitly.
Although using var rather than the explicit data type is allowed, consider avoiding such use when the data type is not obvious—for example, use string for the declaration of text and uppercase. Not only does this make the code more understandable, but it also allows the compiler to verify your intent, that the data type returned by the right-hand side expression is the type expected. When using a var-declared variable, the right-hand side data type should be obvious; if it isn’t, use of the var declaration should be avoided.
3.0End 3.0Begin 7.0Tuples
On occasion, you will find it useful to combine data elements together. Consider, for example, information about a country such as the poorest country in the world in 2019: South Sudan, whose capital is Juba, with a GDP per capita of $275.18. Given the constructs we have established so far, we could store each data element in individual variables, but the result would be no association of the data elements together. That is, $275.18 would have no association with South Sudan, except perhaps by a common suffix or prefix in the variable names. Another option would be to combine all the data into a single string, albeit with the disadvantage that to work with each data element individually would require parsing it out.
C# 7.0 provides a third option, a tuple. Tuples allow you to combine the assignment to each variable in a single statement, as shown here for the country data:
(string country, string capital, double gdpPerCapita) = ("South Sudan", "Juba", 275.18);
Tuples have several additional syntax possibilities, as shown in Table 3.1.
In the first four examples, and although the right-hand side represents a tuple, the left-hand side still represents individual variables that are assigned together using tuple syntax, a syntax involving two or more elements separated by commas and associated together with parentheses. (The term tuple syntax is used here because the underlying data type that the compiler generates on the left-hand side isn’t technically a tuple.) The result is that although we start with values combined as a tuple on the right, the assignment to the left deconstructs the tuple into its constituent parts. In example 2, the left-hand side assignment is to pre-declared variables. However, in examples 1, 3, and 4, the variables are declared within the tuple syntax. Given that we are only declaring variables, the naming and casing convention follows the guidelines we discussed in Chapter 1—“DO use camelCase for local variable names,” for example.
Note that although implicit typing (var) can be distributed across each variable declaration within the tuple syntax, as shown in example 4, you cannot do the same with an explicit type (such as string). Since tuples allow each item to be a different data type, distributing the explicit type name across all elements wouldn’t necessarily work unless all the item data types were identical (and even then, the compiler doesn’t allow it).
Table 3.1: Sample Code for Tuple Declaration and Assignment
Example |
Description |
Example Code |
1. |
Assign a tuple to individually declared variables. |
(string country, string capital, double gdpPerCapita) = ("South Sudan", "Juba", 275.18); System.Console.WriteLine( $@"The poorest country in the world in 2017 was { country}, {capital}: {gdpPerCapita}"); |
2. |
Assign a tuple to individually declared variables that are pre-declared. |
string country; string capital; double gdpPerCapita; (country, capital, gdpPerCapita) = ("South Sudan", "Juba", 275.18); System.Console.WriteLine( $@"The poorest country in the world in 2017 was { country}, {capital}: {gdpPerCapita}"); |
3. |
Assign a tuple to individually declared and implicitly typed variables. |
(var country, var capital, var gdpPerCapita) = ("South Sudan", "Juba", 275.18); System.Console.WriteLine( $@"The poorest country in the world in 2017 was { country}, {capital}: {gdpPerCapita}"); |
4. |
Assign a tuple to individually declared variables that are implicitly typed with a distributive syntax. |
var (country, capital, gdpPerCapita) = ("South Sudan", "Juba", 275.18); System.Console.WriteLine( $@"The poorest country in the world in 2017 was { country}, {capital}: {gdpPerCapita}"); |
5. |
Declare a named item tuple and assign it tuple values, and then access the tuple items by name. |
(string Name, string Capital, double GdpPerCapita) countryInfo = ("South Sudan", "Juba", 275.18); System.Console.WriteLine( $@"The poorest country in the world in 2017 was { countryInfo.Name}, {countryInfo.Capital}: { countryInfo.GdpPerCapita}"); |
6. |
Assign a named item tuple to a single implicitly typed variable that is implicitly typed, and then access the tuple items by name. |
var countryInfo = (Name: "South Sudan", Capital: "Juba", GdpPerCapita: 275.18); System.Console.WriteLine( $@"The poorest country in the world in 2017 was { countryInfo.Name}, {countryInfo.Capital}: { countryInfo.GdpPerCapita}"); |
7. |
Assign an unnamed tuple to a single implicitly typed variable, and then access the tuple elements by their item-number property. |
var countryInfo = ("South Sudan", "Juba", 275.18); System.Console.WriteLine( $@"The poorest country in the world in 2017 was { countryInfo.Item1}, {countryInfo.Item2}: { countryInfo.Item3}"); |
8. |
Assign a named item tuple to a single implicitly typed variable, and then access the tuple items by their item-number property. |
var countryInfo = (Name: "South Sudan", Capital: "Juba", GdpPerCapita: 275.18); System.Console.WriteLine( $@"The poorest country in the world in 2017 was { countryInfo.Item1}, {countryInfo.Item2}: { countryInfo.Item3}"); |
9. |
Discard portions of the tuple with underscores. |
(string name, _, double gdpPerCapita) = ("South Sudan", "Juba", 275.18); |
10. |
Tuple element names can be inferred from variable and property names (starting in C# 7.1). |
string country = "South Sudan"; string capital = "Juba"; double gdpPerCapita = 275.18; var countryInfo = (country, capital, gdpPerCapita); System.Console.WriteLine( $@"The poorest country in the world in 2017 was { countryInfo.country}, {countryInfo.capital}: { countryInfo.gdpPerCapita}"); |
|
||
In example 5, we declare a tuple on the left-hand side and then assign the tuple on the right. Note that the tuple has named items—names that we can then reference to retrieve the item values from the tuple. This is what enables the countryInfo.Name, countryInfo.Capital, and countryInfo.GdpPerCapita syntax in the System.Console.WriteLine statement. The result of the tuple declaration on the left is a grouping of the variables into a single variable (countryInfo) from which you can then access the constituent parts. This is useful because, as we discuss in Chapter 4, you can then pass this single variable around to other methods, and those methods will also be able to access the individual items within the tuple.
As already mentioned, variables defined using tuple syntax use camelCase. However, the convention for tuple item names is not well defined. Suggestions include using parameter naming conventions when the tuple behaves like a parameter—such as when returning multiple values that before tuple syntax would have used out parameters. The alternative is to use PascalCase, following the naming convention for members of a type (properties, functions, and public fields, as discussed in Chapters 5 and 6). I strongly favor the latter approach of PascalCase, consistent with the casing convention of all member identifiers in C# and .NET. Even so, since the convention isn’t broadly agreed upon, I use the word CONSIDER rather than DO in the guideline, “CONSIDER using PascalCasing for all tuple item names.”
Example 6 provides the same functionality as Example 5, although it uses named tuple items on the right-hand side tuple value and an implicit type declaration on the left. The items’ names are persisted to the implicitly typed variable, however, so they are still available for the WriteLine statement. Of course, this opens up the possibility that you could name the items on the left-hand side with different names than what you use on the right. While the C# compiler allows this, it will issue a warning that the item names on the right will be ignored, as those on the left will take precedence.
If no item names are specified, the individual elements are still available from the assigned tuple variable. However, the names are Item1, Item2, ..., as shown in Example 7. In fact, the ItemX names are always available on the tuple even when custom names are provided (see Example 8). However, when using integrated development environment (IDE) tools such as one of the recent flavors of Visual Studio (one that supports C# 7.0), the ItemX property will not appear within the IntelliSense dropdown—a good thing, since presumably the provided name is preferable. As shown in Example 9, portions of a tuple assignment can be discarded using an underscore—referred to as a discard.
The ability to infer the tuple item names as shown in example 10 isn’t introduced until C# 7.1. As the example demonstrates, the item name within the tuple can be inferred from a variable name or even a property name.
Tuples are a lightweight solution for encapsulating data into a single object in the same way that a bag might capture miscellaneous items you pick up from the store. Unlike arrays (which we discuss next), tuples contain item data types that can vary without constraint,2 except that they are identified by the code and cannot be changed at runtime. Also, unlike with arrays, the number of items within the tuple is hardcoded at compile time. Lastly, you cannot add custom behavior to a tuple (extension methods notwithstanding). If you need behavior associated with the encapsulated data, then leveraging object-oriented programming and defining a class is the preferred approach—a concept we begin exploring in depth in Chapter 6.
2. Technically, they can’t be pointers—a topic we introduce in Chapter 23.
Begin 8.0Arrays
One particular aspect of variable declaration that Chapter 1 didn’t cover is array declaration. With array declaration, you can store multiple items of the same type using a single variable and still access them individually using the index when required. In C#, the array index starts at zero. Therefore, arrays in C# are zero based.
8.0Arrays are a fundamental part of nearly every programming language, so they are required learning for virtually all developers. Although arrays are frequently used in C# programming, and necessary for the beginner to understand, most C# programs now use generic collection types rather than arrays when storing collections of data. Therefore, readers should skim over the following section, “Declaring an Array,” simply to become familiar with their instantiation and assignment. Table 3.2 provides the highlights of what to note. Generic collections are covered in detail in Chapter 15.
Begin 3.0Table 3.2: Array Highlights
Description |
Example |
Declaration Note that the brackets appear with the data type. Multidimensional arrays are declared using commas, where the comma+1 specifies the number of dimensions. |
string[] languages; // one-dimensional int[,] cells; // two-dimensional |
Assignment The If not assigned during declarations, the Arrays can be assigned without literal values. As a result, the value of each item in the array is initialized to its default. If no literal values are provided, the size of the array must be specified. (The size does not have to be a constant; it can be a variable calculated at runtime.) Starting with C# 3.0, specifying the data type is optional. |
string[] languages = { "C#", "COBOL", "Java", "C++", "TypeScript", "Pascal", "Python", "Lisp", "JavaScript"}; languages = new string[9]; languages = new string[]{"C#", "COBOL", "Java", "C++", "TypeScript", "Pascal", "Python", "Lisp", "JavaScript" }; // Multidimensional array assignment // and initialization int[,] cells = new int[3,3] { {1, 0, 2}, {1, 2, 0}, {1, 2, 1} }; |
Forward Accessing an Array Arrays are zero based, so the first element in an array is at index 0. The square brackets are used to store and retrieve data from an array. |
string[] languages = new string[]{ "C#", "COBOL", "Java", "C++", "TypeScript", "Visual Basic", "Python", "Lisp", "JavaScript"}; // Retrieve fifth item in languages array // (TypeScript) string language = languages[4]; // Write "TypeScript" System.Console.WriteLine(language); // Retrieve second item from the end (Python) language = languages[^3]; // Write "Python" System.Console.WriteLine(language); |
Reverse Accessing an Array Starting in C# 8.0, you can also index an array from the end. For example, item |
|
Ranges C# 8.0 allows you to identify and extract an array of elements using the range operator, which identifies the starting item up to but excluding the end item. |
System.Console.WriteLine($@"^3..^0: { // Python, Lisp, JavaScript string.Join(", ", languages[^3..^0]) }"); System.Console.WriteLine($@"^3..: { // Python, Lisp, JavaScript string.Join(", ", languages[^3..]) }"); System.Console.WriteLine($@" 3..^3: { // C++, TypeScript, Visual Basic string.Join(", ", languages[3..^3]) }"); System.Console.WriteLine($@" ..^6: { // C#, COBOL, Java string.Join(", ", languages[..^6]) }"); |
|
|
End 3.0In addition, the final section of this chapter, “Common Array Errors,” provides a review of some of the array idiosyncrasies.
End 8.0Declaring an Array
In C#, you declare arrays using square brackets. First, you specify the element type of the array, followed by open and closed square brackets; then you enter the name of the variable. Listing 3.7 declares a variable called languages to be an array of strings.
Listing 3.7: Declaring an Array
string[] languages;
Obviously, the first part of the array identifies the data type of the elements within the array. The square brackets that are part of the declaration identify the rank, or the number of dimensions, for the array; in this case, it is an array of rank 1. These two pieces form the data type for the variable languages.
Listing 3.7 defines an array with a rank of 1. Commas within the square brackets define additional dimensions. Listing 3.8, for example, defines a two-dimensional array of cells for a game of chess or tic-tac-toe.
Listing 3.8: Declaring a Two-Dimensional Array
// / / // ---+---+--- // / / // ---+---+--- // / / int[,] cells;
In Listing 3.8, the array has a rank of 2. The first dimension could correspond to cells going across and the second dimension to cells going down. Additional dimensions are added, with additional commas, and the total rank is one more than the number of commas. Note that the number of items that occur for a particular dimension is not part of the variable declaration. This is specified when creating (instantiating) the array and allocating space for each element.
Instantiating and Assigning Arrays
Once an array is declared, you can immediately fill its values using a comma-delimited list of items enclosed within a pair of curly braces. Listing 3.9 declares an array of strings and then assigns the names of nine languages within curly braces.
Listing 3.9: Array Declaration with Assignment
string[] languages = { "C#", "COBOL", "Java", "C++", "TypeScript", "Visual Basic", "Python", "Lisp", "JavaScript"};
The first item in the comma-delimited list becomes the first item in the array, the second item in the list becomes the second item in the array, and so on. The curly brackets are the notation for defining an array literal.
The assignment syntax shown in Listing 3.9 is available only if you declare and assign the value within one statement. To assign the value after declaration requires the use of the keyword new, as shown in Listing 3.10.
Listing 3.10: Array Assignment Following Declaration
string[] languages; languages = new string[]{"C#", "COBOL", "Java", "C++", "TypeScript", "Visual Basic", "Python", "Lisp", "JavaScript" };
Begin 3.0Starting in C# 3.0, specifying the data type of the array (string) following new is optional as long as the compiler is able to deduce the element type of the array from the types of the elements in the array initializer. The square brackets are still required.
End 3.0C# also allows use of the new keyword as part of the declaration statement, so it allows the assignment and the declaration shown in Listing 3.11.
Listing 3.11: Array Assignment with new during Declaration
string[] languages = new string[]{ "C#", "COBOL", "Java", "C++", "TypeScript", "Visual Basic", "Python", "Lisp", "JavaScript"};
The use of the new keyword tells the runtime to allocate memory for the data type. It instructs the runtime to instantiate the data type—in this case, an array.
Whenever you use the new keyword as part of an array assignment, you may also specify the size of the array within the square brackets. Listing 3.12 demonstrates this syntax.
Listing 3.12: Declaration and Assignment with the new Keyword
string[] languages = new string[9]{ "C#", "COBOL", "Java", "C++", "TypeScript", "Visual Basic", "Python", "Lisp", "JavaScript"};
The array size in the initialization statement and the number of elements contained within the curly braces must match. Furthermore, it is possible to assign an array but not specify the initial values of the array, as demonstrated in Listing 3.13.
Listing 3.13: Assigning without Literal Values
string[] languages = new string[9];
Assigning an array but not initializing the initial values will still initialize each element. The runtime initializes array elements to their default values, as follows:
Reference types—whether nullable or not (such as
stringandstring?)—are initialized tonull.Nullable value types are all initialized to
null.Non-nullable numeric types are initialized to
0.boolis initialized tofalse.charis initialized to�.
Nonprimitive value types are recursively initialized by initializing each of their fields to their default values. As a result, it is not necessary to individually assign each element of an array before using it.
Because the array size is not included as part of the variable declaration, it is possible to specify the size at runtime. For example, Listing 3.14 creates an array based on the size specified in the Console.ReadLine() call.
Listing 3.14: Defining the Array Size at Runtime
string[] groceryList; System.Console.Write("How many items on the list? "); int size = int.Parse(System.Console.ReadLine()); groceryList = new string[size]; // ...
C# initializes multidimensional arrays similarly. A comma separates the size of each rank. Listing 3.15 initializes a tic-tac-toe board with no moves.
Listing 3.15: Declaring a Two-Dimensional Array
int[,] cells = new int[3,3];
Initializing a tic-tac-toe board with a specific position could be done as shown in Listing 3.16.
Listing 3.16: Initializing a Two-Dimensional Array of Integers
int[,] cells = {
{1, 0, 2},
{1, 2, 0},
{1, 2, 1}
};
The initialization follows the pattern in which there is an array of three elements of type int[], and each element has the same size; in this example, the size is 3. Note that the sizes of each int[] element must all be identical. The declaration shown in Listing 3.17, therefore, is not valid.
Listing 3.17: A Multidimensional Array with Inconsistent Size, Causing an Error
// ERROR: Each dimension must be consistently sized int[,] cells = { {1, 0, 2, 0}, {1, 2, 0}, {1, 2} {1} };
Representing tic-tac-toe does not require an integer in each position. One alternative is to construct a separate virtual board for each player, with each board containing a bool that indicates which positions the players selected. Listing 3.18 corresponds to a three-dimensional board.
Listing 3.18: Initializing a Three-Dimensional Array
bool[,,] cells; cells = new bool[2,3,3] { // Player 1 moves // X | | { {true, false, false}, // ---+---+--- {true, false, false}, // X | | {true, false, true} }, // ---+---+--- // X | | X // Player 2 moves // | | O { {false, false, true}, // ---+---+--- {false, true, false}, // | O | {false, true, false} } // ---+---+--- // | O | };
In this example, the board is initialized and the size of each rank is explicitly identified. In addition to identifying the size as part of the new expression, the literal values for the array are provided. The literal values of type bool[,,] are broken into two arrays of type bool[,], size 3 × 3. Each two-dimensional array is composed of three bool arrays, size 3.
As already mentioned, each dimension in a multidimensional array must be consistently sized. However, it is also possible to define a jagged array, which is an array of arrays. Jagged array syntax is slightly different from that of a multidimensional array; furthermore, jagged arrays do not need to be consistently sized. Therefore, it is possible to initialize a jagged array as shown in Listing 3.19.
Listing 3.19: Initializing a Jagged Array
int[][] cells = { new int[]{1, 0, 2, 0}, new int[]{1, 2, 0}, new int[]{1, 2}, new int[]{1} };
A jagged array doesn’t use a comma to identify a new dimension. Rather, it defines an array of arrays. In Listing 3.19, [] is placed after the data type int[], thereby declaring an array of type int[].
Notice that a jagged array requires an array instance (or null) for each internal array. In the preceding example, you use new to instantiate the internal element of the jagged arrays. Leaving out the instantiation would cause a compile error.
Begin 8.0Using an Array
You access a specific item in an array using the square bracket notation, known as the array accessor. To retrieve the first item from an array, you specify zero as the index. In Listing 3.20, the value of the fifth item (using the index 4 because the first item is index 0) in the languages variable is stored in the variable language.
Listing 3.20: Declaring and Accessing an Array
string[] languages = new string[9]{ "C#", "COBOL", "Java", "C++", "TypeScript", "Visual Basic", "Python", "Lisp", "JavaScript"}; // Retrieve fifth item in languages array (TypeScript) string language = languages[4]; // Write "TypeScript" Console.WriteLine(language); // Retrieve third item from the end (Python) language = languages[^3]; // Write "Python" Console.WriteLine(language);
Starting with C# 8.0, you can also access items relative to the end of the array using the index from end operator, also known as the ^ (hat) operator. Indexing with ^1, for example, retrieves the last item in the array, whereas the first element using the index from end operator would be ^9 (where 9 is the number of items in the array). In Listing 3.20, ^3 specifies that the value stored in the third item from the end ("Python") in the languages variable is assigned to language.
Since item ^1 is the last element, item ^0 corresponds to one past the end of the list. Of course, there is no such element, so you can’t successfully index the array using ^0. Similarly, using the length of the array, 9 in this case, refers to an element off the end of the array. In addition, you can’t use negative values when indexing into an array.
There is seemingly a discrepancy between indexing from the beginning of the array with a positive integer and indexing from the end of the array using a ^ integer value (or an expression that returns an integer value). The first begins counting at 0 to access the first element, while the second starts at ^1 to access the last element. The C# design team chose to index from the beginning using 0 for consistency with other languages on which C# is based (C, C++, and Java, for example). When indexing from the end, C# followed Python’s precedence (since the C-based languages didn’t support an index from end operator) and started counting from the end with 1 as well. Unlike in Python, however, the C# team selected the ^ operator (rather than negative integers) to ensure there was no backward incompatibility when using the index operator on collection types (not arrays) that allow negative values. (The ^ operator has additional advantages when supporting ranges, as discussed later in the chapter.) One way to remember how the index from end operator works is to notice that when indexing from the end with a positive integer, the value begins with length – 1 for the last element, length – 2 for the second-to-last element, and so on. The integer subtracted from the length corresponds to the “last from end” index value—^1, ^2, and so on. Furthermore, with this approach the value of the index from the beginning of the array plus the value of the index from the end of the array will always total the length of the array.
Note that the index from end operator is not limited to a literal integer value. You can also use expressions such as
8.0languages[^langauges.Length]
which will return the first item.
The square bracket (array accessor) notation is also used to store data into an array. Listing 3.21 switches the order of "C++" and "Java".
Listing 3.21: Swapping Data between Positions in an Array
string[] languages = new string[]{ "C#", "COBOL", "Java", "C++", "TypeScript", "Visual Basic", "Python", "Lisp", "JavaScript"}; // Save "C++" to variable called language string language = languages[3]; // Assign "Java" to the C++ position languages[3] = languages[2]; // Assign language to location of "Java" languages[2] = language;
For multidimensional arrays, an element is identified with an index for each dimension, as shown in Listing 3.22.
Listing 3.22: Initializing a Two-Dimensional Array of Integers
int[,] cells = { {1, 0, 2}, {0, 2, 0}, {1, 2, 1} }; // Set the winning tic-tac-toe move to be player 1 cells[1,0] = 1;
Jagged array element assignment is slightly different because it is consistent with the jagged array declaration. The first element is an array within the array of arrays; the second index specifies the item within the selected array element (see Listing 3.23).
Listing 3.23: Declaring a Jagged Array
int[][] cells = { new int[]{1, 0, 2}, new int[]{0, 2, 0}, new int[]{1, 2, 1} }; cells[1][0] = 1; // ...
8.0Length
You can obtain the length of an array, as shown in Listing 3.24.
Listing 3.24: Retrieving the Length of an Array
Console.WriteLine(
$"There are { languages.Length } languages in the array.");
Arrays have a fixed length; they are bound such that the length cannot be changed without re-creating the array. Furthermore, overstepping the bounds (or length) of the array will cause the runtime to report an error. This can occur when you attempt to access (either retrieve or assign) the array with an index for which no element exists in the array. Such an error frequently occurs when you use the array length as an index into the array, as shown in Listing 3.25.
Listing 3.25: Accessing Outside the Bounds of an Array, Throwing an Exception
string languages = new string[9]; ... // RUNTIME ERROR: index out of bounds – should // be 8 for the last element languages[4] = languages[9];
Note
The Length member returns the number of items in the array, not the highest index. The Length member for the languages variable is 9, but the highest runtime allowable index for the languages variable is 8, because that is how far it is from the start.
With C# 8.0, the same problem occurs when accessing the ^0 item: Since ^1 is the last item, ^0 is one past the end of the array—and there is no such item.
To avoid overstepping the bounds on an array when accessing the last element, use a length check to verify that the array has a length greater than 0, and use ^1 (starting with C# 8.0) or Length – 1 in place of a hardcoded value when accessing the last item in the array. To use Length as an index, it is necessary to subtract 1 to avoid an out-of-bounds error (see Listing 3.26).
Listing 3.26: Using Length - 1 in the Array Index
string languages = new string[9]; ... languages[4] = languages[languages.Length - 1];
(Of course, first check for null before accessing the array if there is a chance there is no array instance in the first place.)
Length returns the total number of elements in an array. Therefore, if you had a multidimensional array such as bool cells[,,] of size 2 × 3 × 3, Length would return the total number of elements, 18.
For a jagged array, Length returns the number of elements in the first array. Because a jagged array is an array of arrays, Length evaluates only the outside containing array and returns its element count, regardless of what is inside the internal arrays.
Ranges
Another indexing-related feature added to C# 8.0 is support for array slicing—that is, extracting a slice of an array into a new array. The syntax for specifying a range is .., the range operator, which may optionally be placed between indices (including the indices from the end). Listing 3.27 provides examples.
8.0Listing 3.27: Examples of the Range Operator
string[] languages = new string[]{ "C#", "COBOL", "Java", "C++", "TypeScript", "Visual Basic", "Python", "Lisp", "JavaScript"}; System.Console.WriteLine($@" 0..3: { string.Join(", ", languages[0..3]) // C#, COBOL, Java }"); System.Console.WriteLine($@"^3..^0: { string.Join(", ", languages[^3..^0]) // Python, Lisp, JavaScript }"); System.Console.WriteLine($@" 3..^3: { string.Join(", ", languages[3..^3]) // C++, TypeScript, Visual Basic }"); System.Console.WriteLine($@" ..^6: { string.Join(", ", languages[..^6]) // C#, COBOL, Java }"); System.Console.WriteLine($@" 6..: { string.Join(", ", languages[6..]) // Python, Lisp, JavaScript }"); System.Console.WriteLine($@" ..: { // C#, COBOL, Java, C++, TypeScript, Visual Basic, Python, Lisp, JavaScript string.Join(", ", languages[..]) }");
The important thing to note about the range operator is that it identifies the items by specifying the first (inclusive) up to the end (exclusive). Therefore, in the 0..3 example of Listing 3.27, 0 specifies the slice to include everything from the first item up to, but not including, the fourth item (3 is used to identify the fourth item because the forward index starts counting at 0). In example 2, therefore, specifying ^3..^0 retrieves the last three items. The ^0 does not cause an error by attempting to access the item past the end of the array because the index at the end of the range does not include the identified item.
Specifying either the beginning index or “up to” (the end) index is optional, as shown in examples 4–6 of Listing 3.27. As such, if indices are missing entirely, it is equivalent to specifying 0..^0.
8.0Finally, note that indices and ranges are first-class types in .NET/C# (as described in the System.Index and System.Range advanced block). Their behavior is not limited to use in an array accessor.
More Array Methods
Arrays include additional methods for manipulating the elements within the array—for example, Sort(), BinarySearch(), Reverse(), and Clear() (see Listing 3.28).
Listing 3.28: Additional Array Methods
class ProgrammingLanguages { static void Main() { string[] languages = new string[]{ "C#", "COBOL", "Java", "C++", "TypeScript", "Visual Basic", "Python", "Lisp", "JavaScript"}; System.Array.Sort(languages); string searchString = "COBOL"; int index = System.Array.BinarySearch( languages, searchString); System.Console.WriteLine( "The wave of the future, " + $"{ searchString }, is at index { index }."); System.Console.WriteLine(); System.Console.WriteLine( $"{ "First Element",-20 } { "Last Element",-20 }"); System.Console.WriteLine( $"{ "-------------",-20 } { "------------",-20 }"); System.Console.WriteLine( $"{ languages[0],-20 } { languages[^1],-20 }"); System.Array.Reverse(languages); System.Console.WriteLine( $"{ languages[0],-20 } { languages[^1],-20 }"); // Note this does not remove all items from the array. // Rather, it sets each item to the type's default value. System.Array.Clear(languages, 0, languages.Length); System.Console.WriteLine( $"{ languages[0],-20 } { languages[^1],-20 }"); System.Console.WriteLine( $"After clearing, the array size is: { languages.Length }"); } }
The results of Listing 3.28 are shown in Output 3.2.
Output 3.2
The wave of the future, COBOL, is at index 2. First Element Last Element ------------- ------------ C# TypeScript TypeScript C# After clearing, the array size is: 9
Access to these methods is obtained through the System.Array class. For the most part, using these methods is self-explanatory, except for two noteworthy items:
Before using the
BinarySearch()method, it is important to sort the array. If values are not sorted in increasing order, the incorrect index may be returned. If the search element does not exist, the value returned is negative. (Using the complement operator,~index, returns the first index, if any, that is larger than the searched value.)The
Clear()method does not remove elements of the array and does not set the length to zero. The array size is fixed and cannot be modified. Therefore, theClear()method sets each element in the array to its default value (null,0, orfalse). This explains whyConsole.WriteLine()creates a blank line when writing out the array afterClear()is called.
End 8.0Array Instance Members
Like strings, arrays have instance members that are accessed not from the data type but directly from the variable. Length is an example of an instance member because access to Length occurs through the array variable, not the class. Other significant instance members are GetLength(), Rank, and Clone().
Retrieving the length of a particular dimension does not require the Length property. To retrieve the size of a particular rank, an array includes a GetLength() instance method. When calling this method, it is necessary to specify the rank whose length will be returned (see Listing 3.29).
Listing 3.29: Retrieving a Particular Dimension’s Size
bool[,,] cells; cells = new bool[2,3,3]; System.Console.WriteLine(cells.GetLength(0)); // Displays 2 System.Console.WriteLine(cells.Rank); // Displays 3
The results of Listing 3.29 appear in Output 3.3.
Output 3.3
2
Listing 3.29 displays 2 because that is the number of elements in the first dimension.
It is also possible to retrieve the entire array’s rank by accessing the array’s Rank member, cells. cells.Rank, for example, will return 3 (see Listing 3.29).
By default, assigning one array variable to another copies only the array reference, not the individual elements of the array. To make an entirely new copy of the array, use the array’s Clone() method. The Clone() method will return a copy of the array; changing any of the members of this new array will not affect the members of the original array.
Strings as Arrays
Variables of type string are accessible like an array of characters. For example, to retrieve the fourth character of a string called palindrome, you can call palindrome[3]. Note, however, that because strings are immutable, it is not possible to assign particular characters within a string. C#, therefore, would not allow palindrome[3]='a', where palindrome is declared as a string. Listing 3.30 uses the array accessor to determine whether an argument on the command line is an option, where an option is identified by a dash as the first character.
Listing 3.30: Looking for Command-Line Options
string[] args; ... if(args[0][0] == '-') { // This parameter is an option }
This snippet uses the if statement, which is covered in Chapter 4. In addition, it presents an interesting example because you use the array accessor to retrieve the first element in the array of strings, args. Following the first array accessor is a second one, which retrieves the first character of the string. The code, therefore, is equivalent to that shown in Listing 3.31.
Listing 3.31: Looking for Command-Line Options (Simplified)
string[] args; ... string arg = args[0]; if(arg[0] == '-') { // This parameter is an option }
Not only can string characters be accessed individually using the array accessor, but it is also possible to retrieve the entire string as an array of characters using the string’s ToCharArray() method. Using this approach, you could reverse the string with the System.Array.Reverse() method, as demonstrated in Listing 3.32, which determines whether a string is a palindrome.
Listing 3.32: Reversing a String
class Palindrome { static void Main() { string reverse, palindrome; char[] temp; System.Console.Write("Enter a palindrome: "); palindrome = System.Console.ReadLine(); // Remove spaces and convert to lowercase reverse = palindrome.Replace(" ", ""); reverse = reverse.ToLower(); // Convert to an array temp = reverse.ToCharArray(); // Reverse the array System.Array.Reverse(temp); // Convert the array back to a string and // check if reverse string is the same if(reverse == new string(temp)) { System.Console.WriteLine( $""{palindrome}" is a palindrome."); } else { System.Console.WriteLine( $""{palindrome}" is NOT a palindrome."); } } }
The results of Listing 3.32 appear in Output 3.4.
Output 3.4
Enter a palindrome: NeverOddOrEven "NeverOddOrEven" is a palindrome.
This example uses the new keyword; this time, it creates a new string from the reversed array of characters.
Common Array Errors
This section introduced the three types of arrays: single-dimensional, multidimensional, and jagged. Several rules and idiosyncrasies govern array declaration and use. Table 3.3 points out some of the most common errors and helps solidify the rules. Try reviewing the code in the Common Mistake column first (without looking at the Error Description and Corrected Code columns) as a way of verifying your understanding of arrays and their syntax.
Table 3.3: Common Array Coding Errors
Common Mistake |
Error Description |
Corrected Code |
int numbers[]; |
The square brackets for declaring an array appear after the data type, not after the variable identifier. |
int[] numbers; |
int[] numbers;
numbers = {42, 84, 168 }; |
When assigning an array after declaration, it is necessary to use the |
int[] numbers; numbers = new int[]{ 42, 84, 168 } |
int[3] numbers =
{ 42, 84, 168 }; |
It is not possible to specify the array size as part of the variable declaration. |
int[] numbers =
{ 42, 84, 168 }; |
int[] numbers = new int[]; |
The array size is required at initialization time unless an array literal is provided. |
int[] numbers = new int[3]; |
int[] numbers = new int[3]{} |
The array size is specified as |
int[] numbers = new int[3] { 42, 84, 168 }; |
int[] numbers = new int[3]; Console.WriteLine( numbers[3]); |
Array indices start at zero. Therefore, the last item is one less than the array size. (Note that this is a runtime error, not a compile-time error.) |
int[] numbers = new int[3]; Console.WriteLine( numbers[2]); |
int[] numbers = new int[3]; numbers[^0] = 42; |
Same as previous error. The index from end operator uses |
int[] numbers = new int[3]; numbers[^1] = 42; |
int[] numbers = new int[3]; numbers[numbers.Length] = 42; |
Same as previous error: 1 needs to be subtracted from the |
int[] numbers = new int[3]; numbers[numbers. Length-1] = 42; |
int[] numbers;
Console.WriteLine(
numbers[0]); |
numbers has not yet been assigned an instantiated array, so it cannot be accessed. |
int[] numbers = {42, 84};
Console.WriteLine(
numbers[0]); |
int[,] numbers =
{ {42},
{84, 42} }; |
Multidimensional arrays must be structured consistently. |
int[,] numbers =
{ {42, 168},
{84, 42} }; |
int[][] numbers =
{ {42, 84},
{84, 42} }; |
Jagged arrays require instantiated arrays to be specified for the arrays within the array. |
int[][] numbers = { new int[]{42, 84}, new int[]{84, 42} }; |
|
||
Summary
We began the chapter with a discussion of two different categories of types: value types and reference types. These fundamental concepts are important for C# programmers to understand because they change the underlying way a type behaves, even though that might not be obvious when reading through the code.
Before discussing arrays, we looked at two language constructs that were not initially part of C#. First, we introduced the nullable modifier (?), which value types supported in C# 2.0 and reference types supported in C# 8.0. The nullable modifier enables the declaration of nullability. (Technically, it enables value types to store null and reference types to specify explicitly the intent to store null or not.) Second, we introduced tuples and a new syntax introduced with C# 7.0 that provides language support for working with tuples without having to work explicitly with the underlying data type.
This chapter closed with coverage of C# syntax for arrays, along with the various means of manipulating arrays. For many developers, the syntax can seem rather daunting at first, so this section included a list of the common errors associated with coding arrays.
The next chapter looks at expressions and control flow statements. The if statement, which appeared a few times toward the end of this chapter, is discussed as well.