
The kNN is a popular classification method that is sometimes used in regression problems. It is one of the most natural approaches to classification. The essence of the method is to classify the current item by the most prevailing class of its neighbors. Formally, the basis of the method is the hypothesis of compactness: if the metric of the distance between the examples is clarified successfully, then similar examples are more likely to be in the same class. For example, if you don't know what type of product to specify in the ad for a Bluetooth headset, you can find five similar headset ads. If four of them are categorized as Accessories and only one as Hardware, common sense will tell you that your ad should probably be in the Accessories category.
In general, to classify an object, you must perform the following operations sequentially:
- Calculate the distance from the object to other objects in the training dataset.
- Select the k of training objects, with the minimal distance to the object that is classified.
- Set the classifying object class to the class most often found among the nearest k neighbors.
If we take the number of nearest neighbors k = 1, then the algorithm loses the ability to generalize (that is, to produce a correct result for data not previously encountered in the algorithm), because the new item is assigned to the closest class. If we set too high a value, then the algorithm may not reveal many local features.
The function for calculating the distance must meet the following rules:
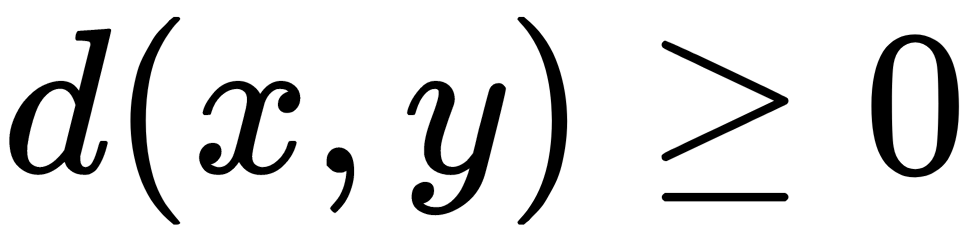
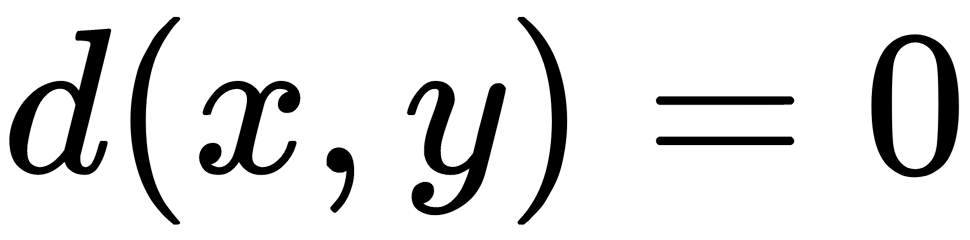 only when x = y
only when x = y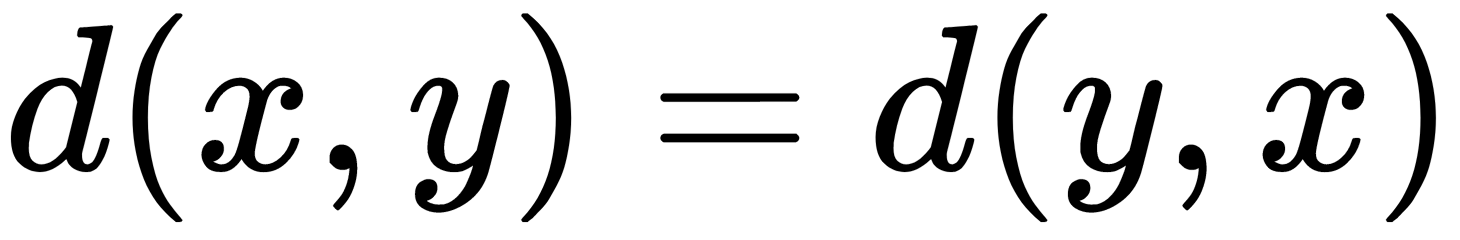
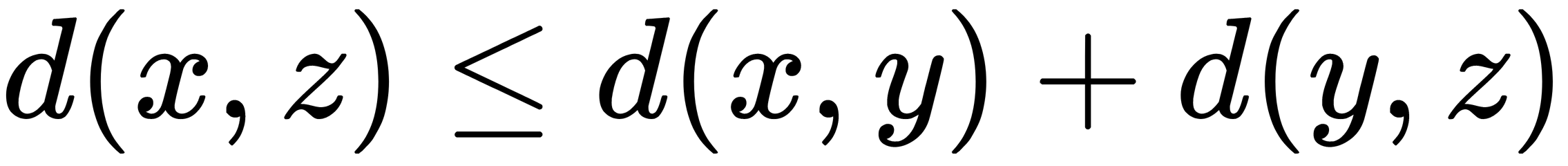 in the case when points x, y, z don't lie on one straight line
in the case when points x, y, z don't lie on one straight line
In this case, x, y, z are feature vectors of compared objects. For ordered attribute values, Euclidean distance can be applied, as illustrated here:
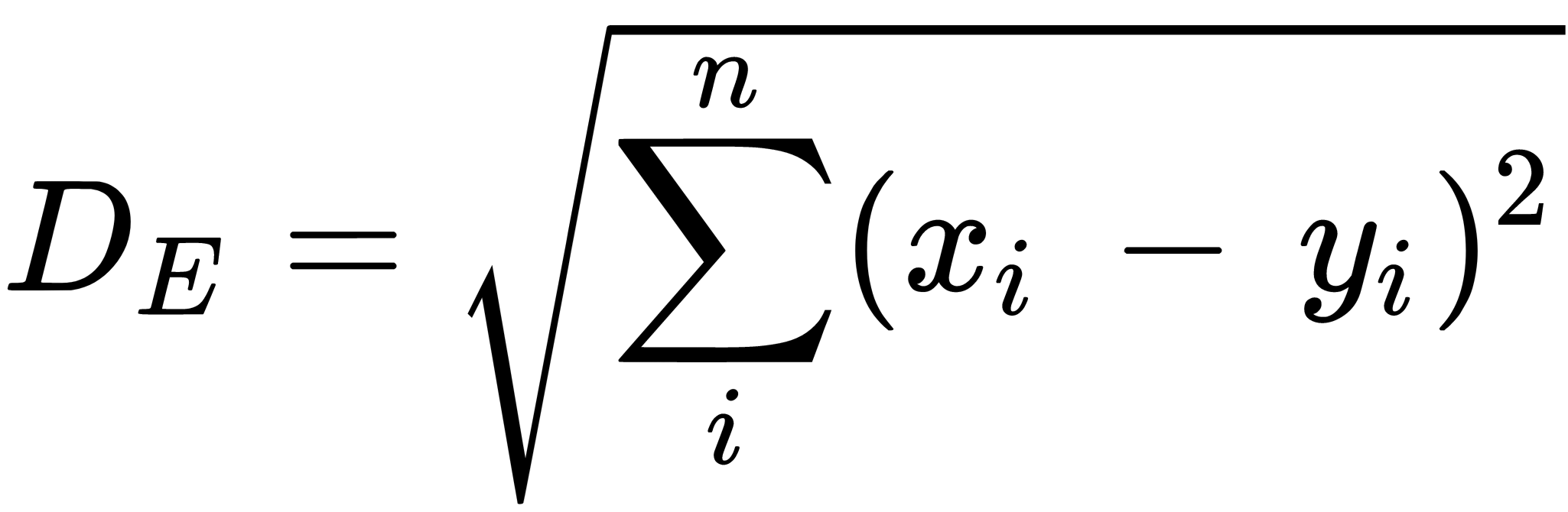
In this case, n is the number of attributes.
For string variables that cannot be ordered, the difference function can be applied, which is set as follows:
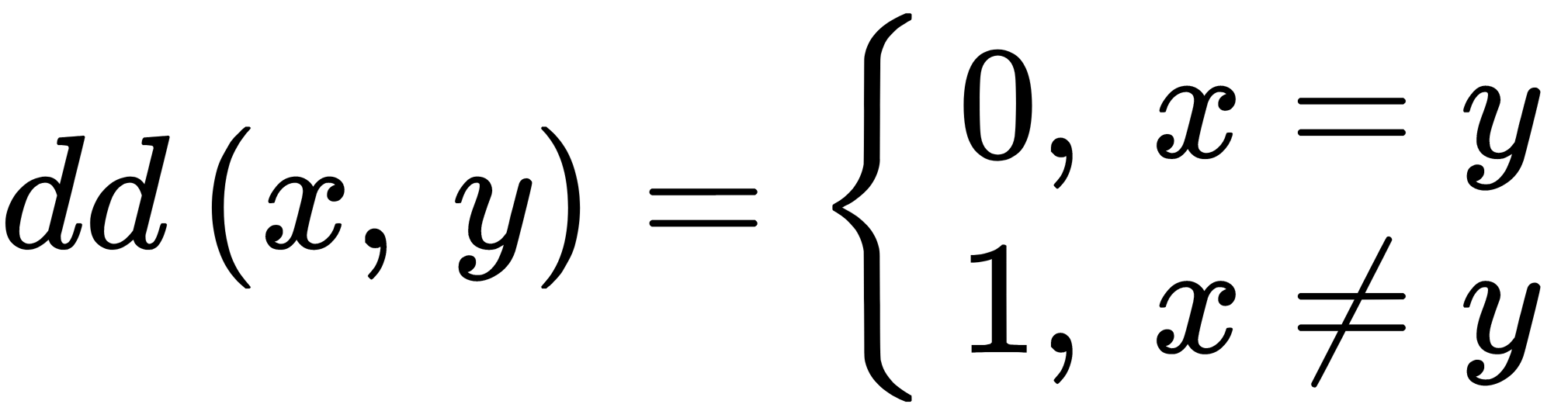
When finding the distance, the importance of the attributes is sometimes taken into account. Usually, attribute relevance can be determined subjectively by an expert or analyst, and is based on their own experience, expertise, and problem interpretation. In this case, each ith square of the difference in the sum is multiplied by the coefficient Zi. For example, if the attribute A is three times more important than the attribute  (
(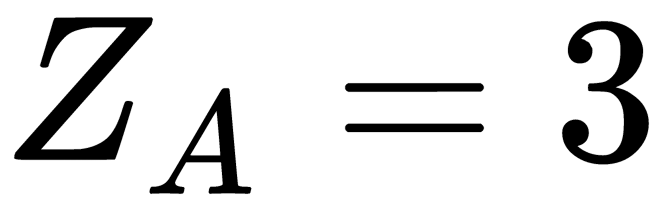 ,
, 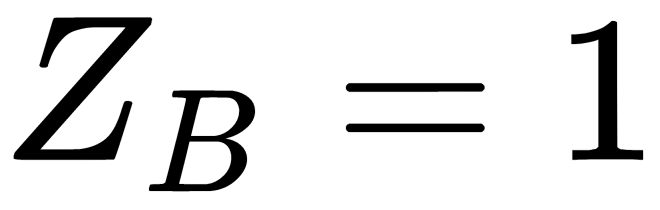 ), then the distance is calculated as follows:
), then the distance is calculated as follows:
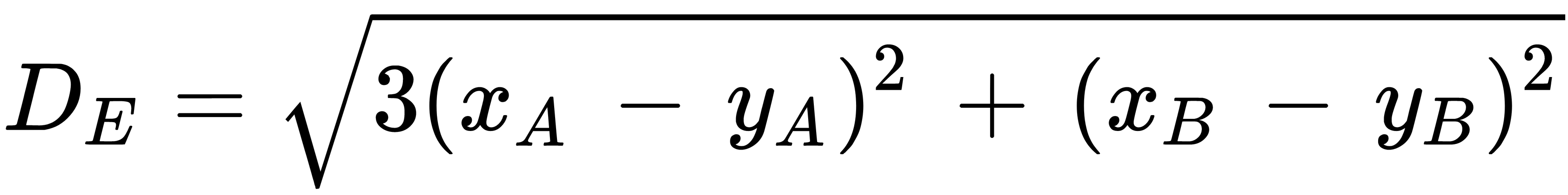
This technique is called stretching the axes, which reduces the classification error.
The choice of class for the object of classification can also be different, and there are two main approaches to make this choice: unweighted voting and weighted voting.
For unweighted voting, we determine how many objects have the right to vote in the classification task by specifying the k number. We identify such objects by their minimal distance to the new object. The individual distance to each object is no longer critical for voting. All have equal rights in a class definition. Each existing object votes for the class to which it belongs. We assign a class with the most votes to a new object. However, there may be a problem if several classes scored an equal number of votes. Weighted voting removes this problem.
During the weighted vote, we also take into account the distance to the new object. The smaller the distance, the more significant the contribution of the vote. The votes for the class (formula) is as follows:
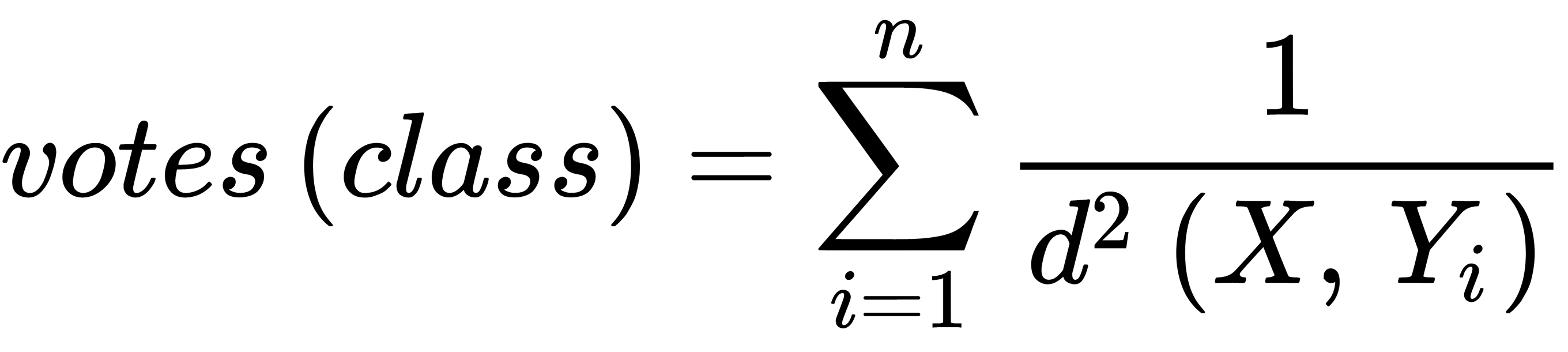
In this case, 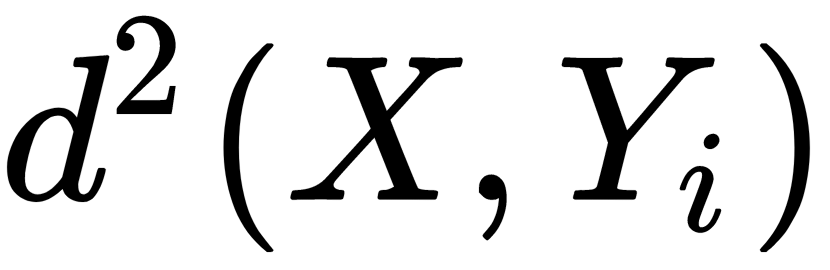 is the square of the distance from the known object
is the square of the distance from the known object 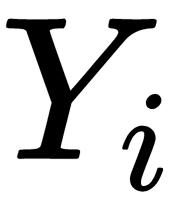 to the new object
to the new object 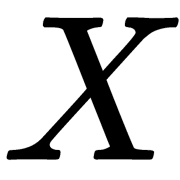 , while
, while 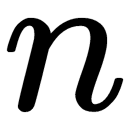 is the number of known objects of the class for which votes are calculated. class is the name of the class. The new object corresponds to the class with the most votes. In this case, the probability that several classes gain the same number of votes is much lower. When
is the number of known objects of the class for which votes are calculated. class is the name of the class. The new object corresponds to the class with the most votes. In this case, the probability that several classes gain the same number of votes is much lower. When 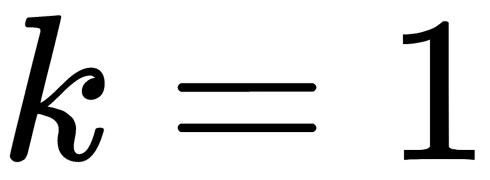 , the new object is assigned to the class of the nearest neighbor.
, the new object is assigned to the class of the nearest neighbor.
A notable feature of the kNN approach is its laziness. Laziness means that the calculations begin only at the moment of the classification. When using training samples with the kNN method, we don't simply build the model, but also do sample classification simultaneously. Note that the method of nearest neighbors is a well-studied approach (in machine learning, econometrics, and statistics, only linear regression is more well known). For the method of nearest neighbors, there are quite a few crucial theorems that state that on infinite samples, kNN is the optimal classification method. The authors of the classic book The Elements of Statistical Learning consider kNN to be a theoretically ideal algorithm, the applicability of which is limited only by computational capabilities and the curse of dimensionality.
kNN is one of the simplest classification algorithms, so it is often ineffective in real-world tasks. The KNN algorithm has several disadvantages. Besides a low classification accuracy when we don't have enough samples, the kNN classifier's problem is the speed of classification: if there are N objects in the training set and the dimension of the space is K, then the number of operations for classifying a test sample can be estimated as 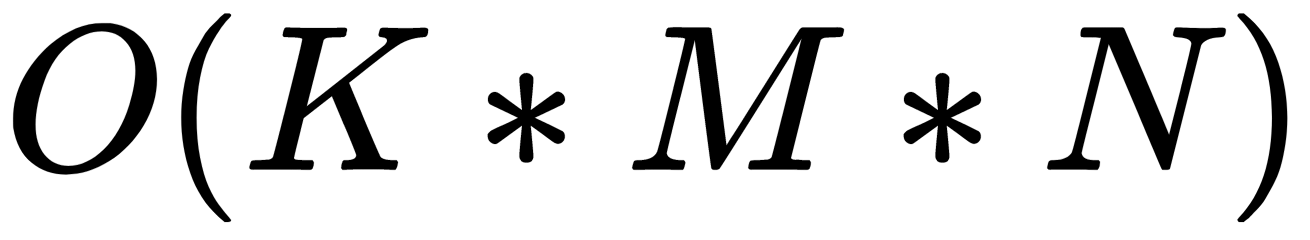 . The dataset used for the algorithm must be representative. The model cannot be separated from the data: to classify a new example, you need to use all the examples.
. The dataset used for the algorithm must be representative. The model cannot be separated from the data: to classify a new example, you need to use all the examples.
The positive features include the fact that the algorithm is resistant to abnormal outliers, since the probability of such a record falling into the number of kNN is small. If this happens, then the impact on the vote (uniquely weighted) with  is also likely to be insignificant, and therefore, the impact on the classification result is also small. The program implementation of the algorithm is relatively simple, and the algorithm result is easily interpreted. Experts in applicable fields, therefore, understand the logic of the algorithm, based on finding similar objects. The ability to modify the algorithm by using the most appropriate combination functions and metrics allows you to adjust the algorithm for a specific task.
is also likely to be insignificant, and therefore, the impact on the classification result is also small. The program implementation of the algorithm is relatively simple, and the algorithm result is easily interpreted. Experts in applicable fields, therefore, understand the logic of the algorithm, based on finding similar objects. The ability to modify the algorithm by using the most appropriate combination functions and metrics allows you to adjust the algorithm for a specific task.