
The MAB problem is one of the classical problems in RL. An MAB is actually a slot machine, a gambling game played in a casino where you pull the arm (lever) and get a payout (reward) based on a randomly generated probability distribution. A single slot machine is called a one-armed bandit and, when there are multiple slot machines it is called multi-armed bandits or k-armed bandits.
MABs are shown as follows:

As each slot machine gives us the reward from its own probability distribution, our goal is to find out which slot machine will give us the maximum cumulative reward over a sequence of time. So, at each time step t, the agent performs an action at, that is, pulls an arm from the slot machine and receives a reward rt, and the goal of our agent is to maximize the cumulative reward.
We define the value of an arm Q(a) as average rewards received by pulling the arm:
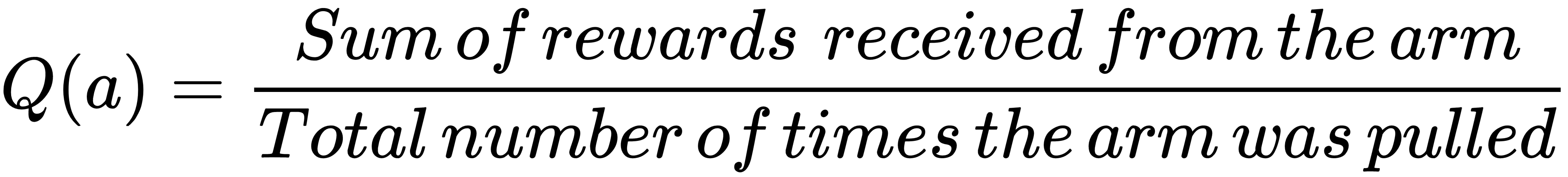
So the optimal arm is the one that gives us the maximum cumulative reward, that is:

The goal of our agent is to find the optimal arm and also to minimize the regret, which can be defined as the cost of knowing which of the k arms is optimal. Now, how do we find the best arm? Should we explore all the arms or choose the arm that already gave us a maximum cumulative reward? Here comes the exploration-exploitation dilemma. Now we will see how to solve this dilemma using various exploration strategies as follows:
- Epsilon-greedy policy
- Softmax exploration
- Upper confidence bound algorithm
- Thomson sampling technique
Before going ahead, let us install bandit environments in the OpenAI Gym; you can install the bandit environment by typing the following command in your Terminal:
git clone https://github.com/JKCooper2/gym-bandits.git
cd gym-bandits
pip install -e .
After installing, let us import gym and gym_bandits:
import gym_bandits
import gym
Now we will initialize the environment; we use an MAB with ten arms:
env = gym.make("BanditTenArmedGaussian-v0")
Our action space will be 10, as we have 10 arms:
env.action_space
The output is as follows:
10