
MAXQ Value Function Decomposition is one of the frequently used algorithms in HRL; let's see how MAXQ works. In MAXQ Value Function Decomposition, we decompose the value function into a set of value functions for each of the subtasks. Let's take the same example given in the paper. Remember the taxi problem we solved using Q learning and SARSA?
There are four locations in total, and the agent has to pick up a passenger at one location and drop them off at another location. The agent will receive +20 points as a reward for a successful drop off and -1 point for every time step it takes. The agent will also lose -10 points for illegal pickups and drops. So the goal of our agent is to learn to pick up and drop off passengers at the correct location in a short time without adding illegal passengers.
The environment is shown next, where the letters (R, G, Y, B) represent the different locations and a tiny, yellow-colored rectangle is the taxi driven by our agent:

Now we break our goal into four subtasks as follows:
- Navigate: Here the goal is to drive the taxi from the current location to one of the target locations. The Navigate(t) subtask should use the four primitive actions north, south, east, and west.
- Get: Here the goal is to drive the taxi from its current location to the passenger's location and pick up the passenger.
- Put: Here the goal is to drive the taxi from its current location to the passenger's destination location and drop off the passenger.
- Root: Root is the whole task.
We can represent all these subtasks in a directed acyclic graph called a task graph, shown as follows:

You can see in the preceding figure that all the subtasks are arranged hierarchically. Each node represents the subtask or primitive action and each edge connects the way in which one subtask can call its child subtask.
The Navigate(t) subtask has four primitive actions: east, west, north, and south. The Get subtask has a pickup primitive action and a navigate subtask; similarly Put subtask, has a putdown (drop) primitive action and navigate subtask.
In MAXQ decomposition, MDP  will be divided into a set of tasks such as
will be divided into a set of tasks such as 
 is the root task and
is the root task and  is the subtasks.
is the subtasks.
A subtask  defines the semi MDP with states
defines the semi MDP with states  , actions
, actions  , probability transition function
, probability transition function  , and expected reward function
, and expected reward function 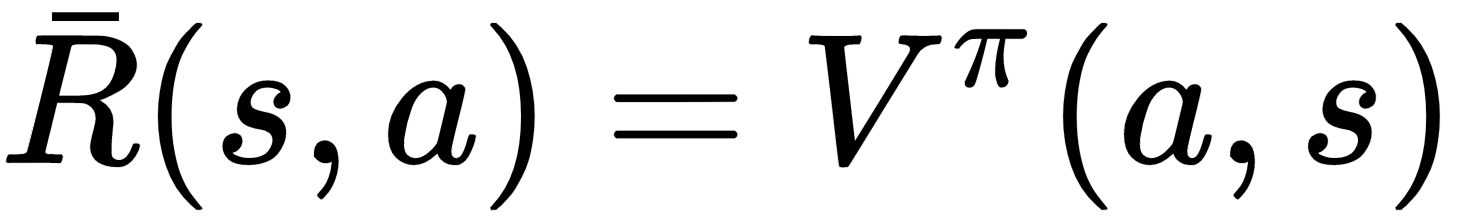 , where
, where  is the projected value function for the child task
is the projected value function for the child task  in state
in state  .
.
If the action a is a primitive action, then we can define  as an expected immediate reward of executing action a in the state s:
as an expected immediate reward of executing action a in the state s:

Now, we can rewrite the preceding value function in the Bellman equation form as follows:
 --(1)
--(1)We will denote the state-action value function Q as follows:
 -- (2)
-- (2)Now, we define one more function called a completion function, which is the expected discounted cumulative reward of completing a subtask  :
:
 -- (3)
-- (3)For equations (2) and (3), we can write the Q function as:

Finally we can redefine the value function as:

The previous equations will decompose the value function of the root task into value functions of the individual subtask tasks.
For efficient designing and debugging of MAXQ decompositions, we can redraw our task graphs as follows:

Our redesigned graph contains two special types of nodes: max node and Q nodes. The max nodes define the subtasks in the task decomposition and the Q nodes define the actions that are available for each subtask.