
Chapter 9. Thesauri, Controlled Vocabularies, and Metadata
| What we’ll cover: |
| Definitions of metadata and controlled vocabularies |
| Overview of synonym rings, authority files, classification schemes, and thesauri |
| Hierarchical, equivalence, and associative relationships |
| Faceted classification and guided navigation |
A web site is a collection of interconnected systems with complex dependencies. A single link on a page can simultaneously be part of the site’s structure, organization, labeling, navigation, and searching systems. It’s useful to study these systems independently, but it’s also crucial to consider how they interact. Reductionism will not tell us the whole truth.
Metadata and controlled vocabularies present a fascinating lens through which we can view the network of relationships between systems. In many large metadata-driven web sites, controlled vocabularies have become the glue that holds the systems together. A thesaurus on the back end can enable a more seamless and satisfying user experience on the front end.
In addition, the practice of thesaurus design can help bridge the gap between past and present. The first thesauri were developed for libraries, museums, and government agencies long before the invention of the World Wide Web. As information architects we can draw upon these decades of experience, but we can’t copy indiscriminately. The web sites and intranets we design present new challenges and demand creative solutions.
But we’re getting ahead of ourselves. Let’s begin by defining some basic terms and concepts. Then we can work back toward the big picture.
Metadata
When it comes to definitions, metadata is a slippery fish. Describing it as “data about data” isn’t very helpful. The following excerpt from Dictionary.com takes us a little further:
In data processing, meta-data is definitional data that provides information about or documentation of other data managed within an application or environment. For example, meta-data would document data about data elements or attributes (name, size, data type, etc.) and data about records or data structures (length, fields, columns, etc.) and data about data (where it is located, how it is associated, ownership, etc.). Meta-data may include descriptive information about the context, quality and condition, or characteristics of the data.
While these tautological explanations could lead us into the realms of epistemology and metaphysics, we won’t go there. Instead, let’s focus on the role that metadata plays in the practical realm of information architecture.
Metadata tags are used to describe documents, pages, images, software, video and audio files, and other content objects for the purposes of improved navigation and retrieval. The HTML keyword meta tag used by many web sites provides a simple example. Authors can freely enter words and phrases that describe the content. These keywords are not displayed in the interface but are available for use by search engines.
<meta name="keywords" content="information architecture, content management, knowledge management, user experience">
Many companies today are using metadata in more sophisticated ways. Leveraging content management software and controlled vocabularies, they create dynamic metadata-driven web sites that support distributed authoring and powerful navigation. This metadata-driven model represents a profound change in how web sites are created and managed. Instead of asking, “Where do I place this document in the taxonomy?” we can now ask, “How do I describe this document?” The software and vocabulary systems take care of the rest.
Controlled Vocabularies
Vocabulary control comes in many shapes and sizes. At its most vague, a controlled vocabulary is any defined subset of natural language. At its simplest, a controlled vocabulary is a list of equivalent terms in the form of a synonym ring, or a list of preferred terms in the form of an authority file. Define hierarchical relationships between terms (e.g., broader, narrower) and you’ve got a classification scheme. Model associative relationships between concepts (e.g., see also, see related) and you’re working on a thesaurus. Figure 9-1 illustrates the relationships between different types of controlled vocabularies.
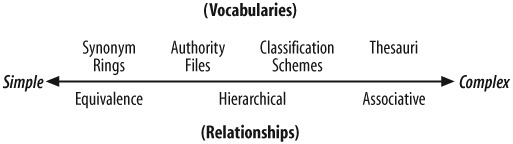
Since a full-blown thesaurus integrates all the relationships and capabilities of the simpler forms, let’s explore each of these building blocks before taking a close look at the “Swiss Army Knife” of controlled vocabularies.
Synonym Rings
A synonym ring (see Figure 9-2) connects a set of words that are defined as equivalent for the purposes of retrieval. In practice, these words are often not true synonyms. For example, imagine you’re redesigning a consumer portal that provides ratings information about household products from several companies.
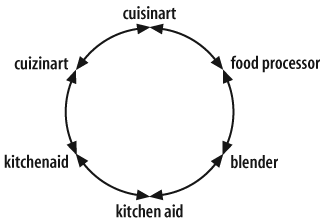
When you examine the search logs and talk with users, you’re likely to find that different people looking for the same thing are entering different terms. Someone who’s buying a food processor may enter “blender” or one of several product names (or their common misspellings). Take a look at the content, and you’re likely to find many of these same variations.
There may be no preferred terms, or at least no good reason to define them. Instead, you can use the out-of-the-box capabilities of a search engine to build synonym rings. This can be as simple as entering sets of equivalent words into a text file. When a user enters a word into the search engine, that word is checked against the text file. If the word is found, then the query is “exploded” to include all of the equivalent words. For example, in Boolean logic:
(kitchenaid) becomes (kitchenaid or "kitchen aid" or blender or "food processor" or cuisinart or cuizinart)
What happens when you don’t use synonym rings? Consider Figure 9-3, which shows the results of a search for “pocketpc.” Pretty discouraging, huh? Looks like we might have to look elsewhere. But look what happens when we put a space between “pocket” and “pc” (Figure 9-4).

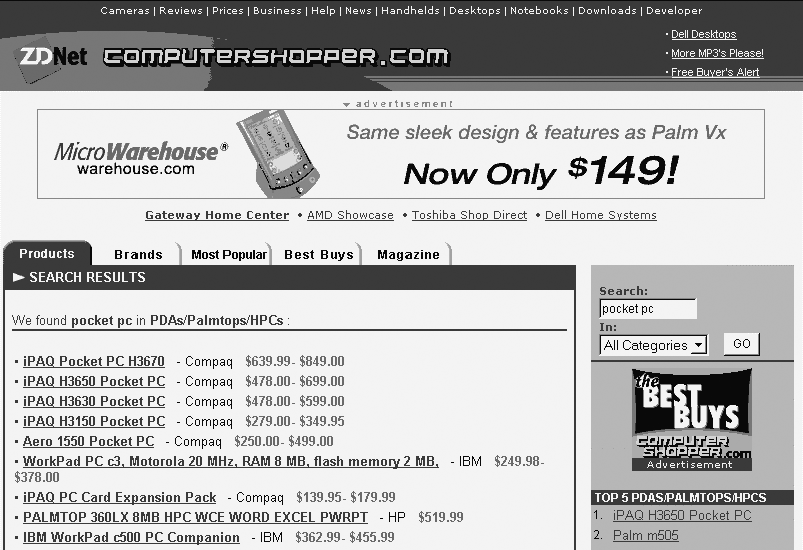
Suddenly, the site has oodles of information about the Pocket PC. A simple synonym ring linking “pocketpc” and “pocket pc” would solve what is a common and serious problem from both user and business perspectives.
However, synonym rings can also introduce new problems. If the query term expansion operates behind the scenes, users can be confused by results that don’t actually include their keywords. In addition, the use of synonym rings may result in less relevant results. This brings us back to the subject of precision and recall.
As you may recall from Chapter 8, precision refers to the relevance of documents within a given result set. To request high precision, you might say, “Show me only the relevant documents.” Recall refers to the proportion of relevant documents in the result set compared to all the relevant documents in the system. To request high recall, you might say, “Show me all the relevant documents.” Figure 9-5 shows the mathematics behind precision and recall ratios.

While both high precision and high recall may be ideal, it’s generally understood in the information retrieval field that you usually increase one at the expense of the other. This has important implications for the use of controlled vocabularies.
As you might guess, synonym rings can dramatically improve recall. In one study conducted at Bellcore in the 1980s,[1] the use of synonym rings (they called it “unlimited aliasing”) within a small test database increased recall from 20 to 80 percent. However, synonym rings can also reduce precision. Good interface design and an understanding of user goals can help strike the right balance. For example, you might use synonym rings by default but order the exact keyword matches at the top of the search results list. Or, you might ignore synonym rings for initial searches but provide the option to “expand your search to include related terms” if there were few or no results.
In summary, synonym rings are a simple, useful form of vocabulary control. There is really no excuse for the conspicuous absence of this basic capability on many of today’s largest web sites.
Authority Files
Strictly defined, an authority file is a list of preferred terms or acceptable values. It does not include variants or synonyms. Authority files have traditionally been used largely by libraries and government agencies to define the proper names for a set of entities within a limited domain.
As shown in Figure 9-6, the Utah State Archives & Records Service has published a listing of the authoritative names of public institutions in the state of Utah. This is primarily useful from content authoring and indexing perspectives. Authors and indexers can use this authority file as the source for their terms, ensuring accuracy and consistency.
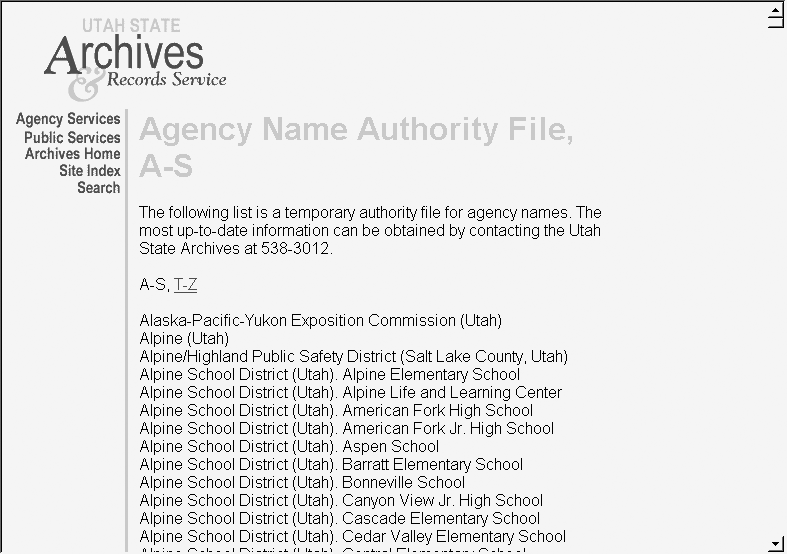
In practice, authority files are commonly inclusive of both preferred and variant terms. In other words, authority files are synonym rings in which one term has been defined as the preferred term or acceptable value.
The two-letter codes that constitute the standard abbreviations for U.S. states as defined by the U.S. Postal Service provide an instructive example. Using the purist definition, the authority file includes only the acceptable codes:
AL, AK, AZ, AR, CA, CO, CT, DE, DC, FL, GA, HI, ID, IL, IN, IA, KS, KY, LA, ME, MD, MA, MI, MN, MS, MO, MT, NE, NV, NH, NJ, NM, NY, NC, ND, OH, OK, OR, PA, PR, RI, SC, SD, TN, TX, UT, VT, VA, WA, WV, WI, WY.
However, to make this list useful in most scenarios, it’s necessary to include, at a minimum, a mapping to the names of states:
AL Alabama AK Alaska AZ Arizona AR Arkansas CA California CO Colorado CT Connecticut . . .
To make this list even more useful in an online context, it may be helpful to include common variants beyond the official state name:
CT Connecticut, Conn, Conneticut, Constitution State
At this point, we run into some important questions about the use and value of authority files in the online environment. Since users can perform keyword searches that map many terms onto one concept, do we really need to define preferred terms, or can synonym rings handle things just fine by themselves? Why take that extra step to distinguish CT as the acceptable value?
First, there are a couple of backend reasons. An authority file can be a useful tool for content authors and indexers, enabling them to use the approved terms efficiently and consistently. Also, from a controlled vocabulary management perspective, the preferred term can serve as the unique identifier for each collection of equivalent terms, allowing for more efficient addition, deletion, and modification of variant terms.
There are also a number of ways that the selection of preferred terms can benefit the user. Consider Figure 9-7, where Drugstore.com is providing a mapping between the equivalent term “tilenol” and the authoritative brand name, “Tylenol.” By showing users the preferred terms, you can educate them. In some cases, you’ll be helping them to correct a misspelling. In others, you may be explaining industry terminology or building brand recognition.
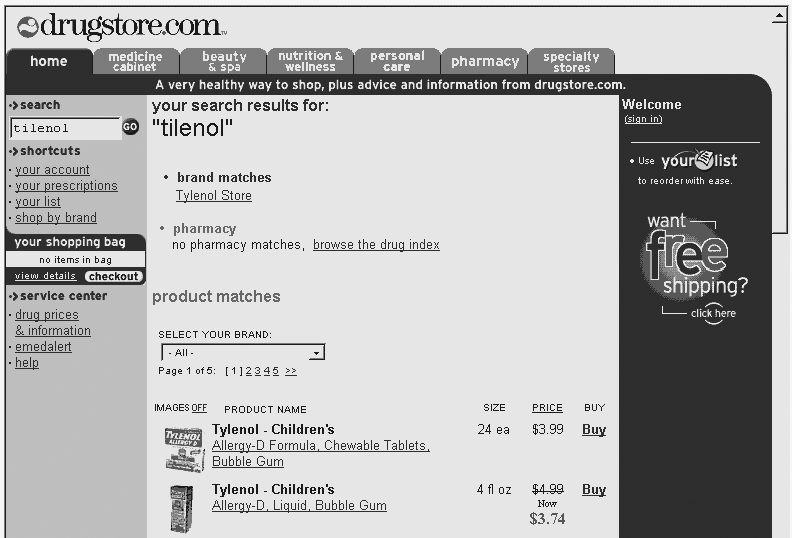
These “lessons” may be useful in very different contexts, perhaps during the next telephone conversation or in-store interaction a customer has with your organization. It’s an opportunity to nudge everyone toward speaking the same language, without assuming or requiring such conformity within the search system. In effect, the search experience can be similar to an interaction with a sales professional, who understands the language of the customer and translates it back to the customer using the company or industry terminology.
Preferred terms are also important as the user switches from searching to browsing mode. When designing taxonomies, navigation bars, and indexes, it would be messy and overwhelming to present all of the synonyms, abbreviations, acronyms, and common misspellings for every term.
At Drugstore.com, only the brand names are included in the index (see Figure 9-8); equivalent terms like “tilenol” don’t show up. This keeps the index relatively short and uncluttered, and in this example, reinforces the brand names. However, a trade-off is involved. In cases where the equivalent terms begin with different letters (e.g., aspirin and Bayer), there is value in creating pointers:
Aspirin see Bayer
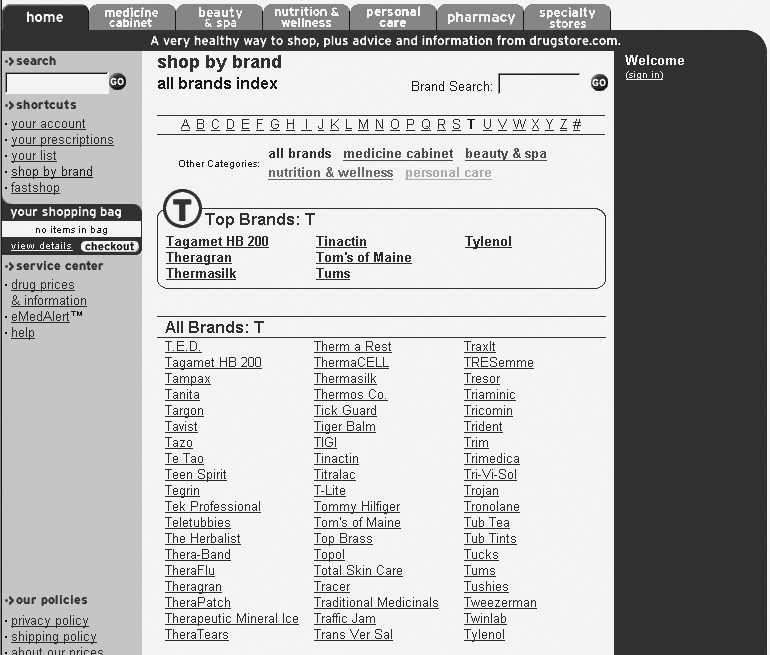
Otherwise, when users look in the index under A for aspirin, they won’t find Bayer. The use of pointers is called term rotation. Drugstore.com doesn’t do it at all. To see a good example of term rotation used in an index to guide users from variant to preferred terms, we’ll switch to the financial services industry.
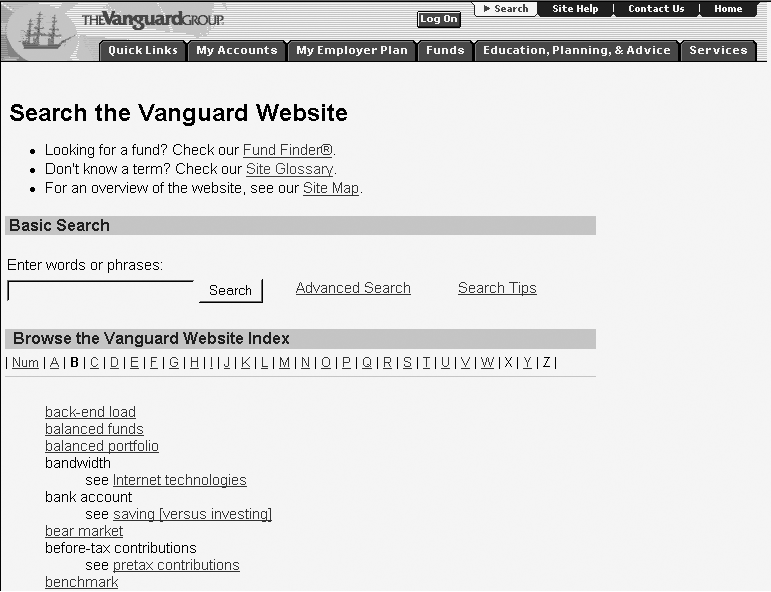
In Figure 9-9, users looking for “before-tax contributions” are guided to the preferred term “pretax contributions.” Such integration of the entry vocabulary can dramatically enhance the usefulness of the site index. However, it needs to be done selectively; otherwise, the index can become too long, harming overall usability. Once again, a careful balancing act is involved that requires research and good judgment.
Classification Schemes
We use classification scheme to mean a hierarchical arrangement of preferred terms. These days, many people prefer to use taxonomy instead. Either way, it’s important to recognize that these hierarchies can take different shapes and serve multiple purposes, including:
A frontend, browsable Yahoo-like hierarchy that’s a visible, integral part of the user interface
A backend tool used by information architects, authors, and indexers for organizing and tagging documents
Consider, for example, the Dewey Decimal Classification (DDC). First published in 1876, the DDC is now “the most widely used classification scheme in the world. Libraries in more than 135 countries use the DDC to organize and provide access to their collections.”[2] In its purest form, the DDC is a hierarchical listing that begins with 10 top-level categories and drills down into great detail within each.
000 Computers, information, & general reference 100 Philosophy & psychology 200 Religion 300 Social sciences 400 Language 500 Science 600 Technology 700 Arts & recreation 800 Literature 900 History & geography
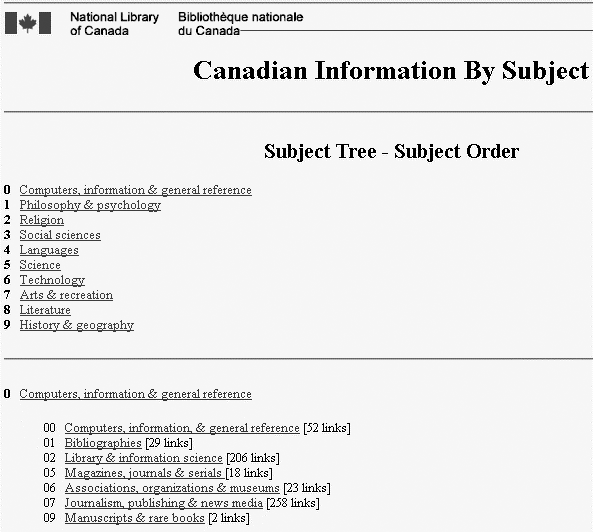
For better or worse, the DDC finds its way into all sorts of interface displays. As Figure 9-10 shows, the National Library of Canada uses it as a browsable hierarchy.
Classification schemes can also be used in the context of searching. Yahoo! does this very effectively. You can see in Figure 9-11 that Yahoo!’s search results present “Category Matches,” which reinforces users’ familiarity with Yahoo!’s classification scheme.
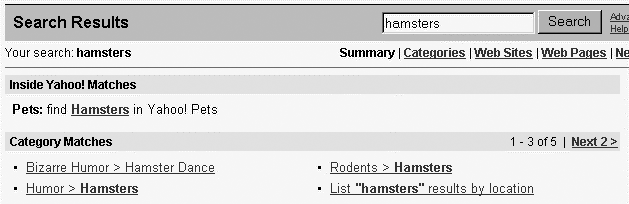
The important point here is that classification schemes are not tied to a single view or instance. They can be used on both the back end and the front end in all sorts of ways. We’ll explore types of classification schemes in more detail later in this chapter, but first let’s take a look at the “Swiss Army Knife” of vocabulary control, the thesaurus.
Thesauri
Dictionary.com defines thesaurus as a “book of synonyms, often including related and contrasting words and antonyms.” This usage hearkens back to our high school English classes, when we chose big words from the thesaurus to impress our teachers.
Our species of thesaurus, the one integrated within a web site or intranet to improve navigation and retrieval, shares a common heritage with the familiar reference text but has a different form and function. Like the reference book, our thesaurus is a semantic network of concepts, connecting words to their synonyms, homonyms, antonyms, broader and narrower terms, and related terms.
However, our thesaurus takes the form of an online database, tightly integrated with the user interface of a web site or intranet. And though the traditional thesaurus helps people go from one word to many words, our thesaurus does the opposite. Its most important goal is synonym management—the mapping of many synonyms or word variants onto one preferred term or concept—so the ambiguities of language don’t prevent people from finding what they need.
So, for the purposes of this book, a thesaurus is:
A controlled vocabulary in which equivalence, hierarchical, and associative relationships are identified for purposes of improved retrieval.[3]
A thesaurus builds upon the constructs of the simpler controlled vocabularies, modeling these three fundamental types of semantic relationships.
As you can see from Figure 9-12, each preferred term becomes the center of its own semantic network. The equivalence relationship is focused on synonym management. The hierarchical relationship enables the classification of preferred terms into categories and subcategories. The associative relationship provides for meaningful connections that aren’t handled by the hierarchical or equivalence relationships. All three relationships can be useful in different ways for the purposes of information retrieval and navigation.

Technical Lingo
If you’re working with controlled vocabularies and thesauri, it’s useful to know the core terminology used by experts in the field to communicate definitions and relationships. This specialized technical language can provide efficiency and specificity when communicating among experts. Just don’t expect your users to recognize these terms. In the web environment, you can’t require that users take a library science class before they use your information system.
- Preferred Term (PT)
Also known as the accepted term, acceptable value, subject heading, or descriptor. All relationships are defined with respect to the Preferred Term.
- Variant Term (VT)
Also known as entry terms or non-preferred terms, Variant Terms have been defined as equivalent to or loosely synonymous with the Preferred Term.
- Broader Term (BT)
The Broader Term is the parent of the Preferred Term. It’s one level higher in the hierarchy.
- Narrower Term (NT)
A Narrower Term is a child of the Preferred Term. It’s one level lower in the hierarchy.
- Related Term (RT)
The Related Term is connected to the Preferred Term through the associative relationship. The relationship is often articulated through use of See Also. For example, Tylenol See Also Headache.
- Use (U)
Traditional thesauri often employ the following syntax as a tool for indexers and users: Variant Term Use Preferred Term. For example, Tilenol Use Tylenol. Many people are more familiar with See, as in Tilenol See Tylenol.
- Used For (UF)
This indicates the reciprocal relationship of Preferred Term UF Variant Term(s). It’s used to show the full list of variants on the Preferred Term’s record. For example, Tylenol UF Tilenol.
- Scope Note (SN)
The Scope Note is essentially a specific type of definition of the Preferred Term, used to deliberately restrict the meaning of that term in order to rule out ambiguity as much as possible.
As we’ve seen, the preferred term is the center of its own semantic universe. Of course, a preferred term in one display is likely to be a broader, narrower, related, or even variant term in another display (see Figure 9-13).
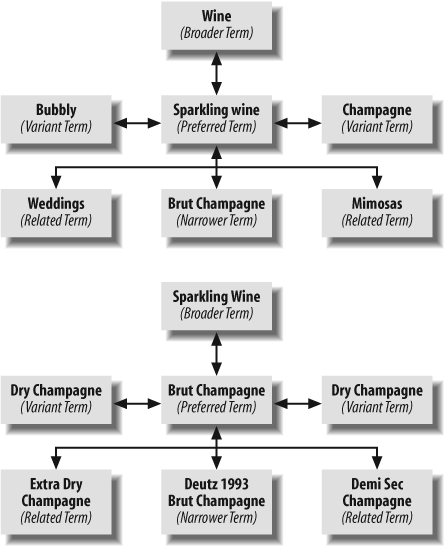
Depending upon your experience with the classification of wines, you may already be questioning the selection of preferred terms and semantic relationships in this example. Should sparkling wine really be the preferred term? If so, why? Because it’s a more popular term? Because it’s the technically correct term? And aren’t there better related terms than weddings and mimosas? Why were those chosen? The truth is that there aren’t any “right” answers to these questions, and there’s no “right” way to design a thesaurus. There will always be a strong element of professional judgment informed by research. We’ll come back to these questions and provide some guidelines for constructing “good” answers, but first let’s check out a real thesaurus on the Web.
A Thesaurus in Action
It’s not so easy to find good examples of public web sites that leverage thesauri. Until recently, not many teams have had the knowledge or support to make this significant investment. We expect this to change in the coming years as thesauri become a key tool for dealing with the growing size and importance of web sites and intranets. Another barrier to finding good examples is that it’s often not obvious when a site is using a thesaurus. When it’s well integrated, a thesaurus can be invisible to the untrained eye. You have to know what you’re looking for to notice one. Think back to the Tilenol/Tylenol example. How many users even realize when the site adjusts for their misspelling?
One good example that will serve throughout this chapter is PubMed, a service of the National Library of Medicine. PubMed provides access to over 16 million citations from MEDLINE and additional life science journals. MEDLINE has been the premier electronic information service for doctors, researchers, and other medical professionals for many years. It leverages a huge thesaurus that includes more than 19,000 preferred terms or “main subject headings” and provides powerful searching capabilities.
PubMed provides a simpler public interface with free access to citations, but without access to the full text of the journal articles. Let’s first take a look at the interface, and then dive beneath the surface to see what’s going on.
Let’s say we’re studying African sleeping sickness. We enter that phrase into the PubMed search engine and are rewarded with the first 20 results out of 2,778 total items found (Figure 9-14). So far, there’s nothing apparently different about this search experience. For all we know, we might have just searched the full text of all 16 million journal articles. To understand what’s going on, we need to look deeper.

In fact, we didn’t search the full-text articles at all. Instead, we searched the metadata records for these articles, which include a combination of abstracts and subject headings (Figure 9-15).

When we select another item from our search results, we find a record with subject headings (“MeSH Terms”) but no abstract (Figure 9-16).

When we scroll down to look through the full list of terms, we see no entry for African sleeping sickness. What’s going on? Why was this article retrieved? To answer that question, we need to switch gears and take a look at the MeSH Browser, an interface for navigating the structure and vocabulary of MeSH (Figure 9-17).

The MeSH Browser enables us to navigate by browsing the hierarchical classification schemes within the thesaurus or by searching. If we try a search on “African sleeping sickness,” we’ll see why the article “Wolbachia. A tale of sex and survival” was retrieved in our search. “African sleeping sickness” is actually an entry term for the preferred term or MeSH heading, “Trypanosomiasis, African.” (See Figure 9-18.) When we searched PubMed, our variant term was mapped to the preferred term behind the scenes. Unfortunately, PubMed doesn’t go further in leveraging the underlying MeSH thesaurus. It would be nice, for example, to turn all of those MeSH terms in our sample record into live links and provide enhanced searching and browsing capabilities, similar to those provided by Amazon, as shown in Figure 9-19.


In this example, Amazon leverages the hierarchical classification scheme and subject headings to provide powerful options for searching and browsing, allowing users to iteratively refine their queries. This surely could be a useful enhancement to PubMed.
One of the advantages to using a thesaurus is that you have tremendous power and flexibility to shape and refine the user interface over time. You can’t take advantage of all the capabilities at once, but you can user-test different features, learning and adjusting as you go. PubMed may not have leveraged the full power of the MEDLINE thesaurus so far, but it’s nice to have that rich network of semantic relationships to draw upon as design and development continues.
Types of Thesauri
Should you decide to build a thesaurus for your web site, you’ll need to choose from among three types: a classic thesaurus, an indexing thesaurus, and a searching thesaurus (Figure 9-20). This decision should be based on how you intend to use the thesaurus, and it will have major implications for design.
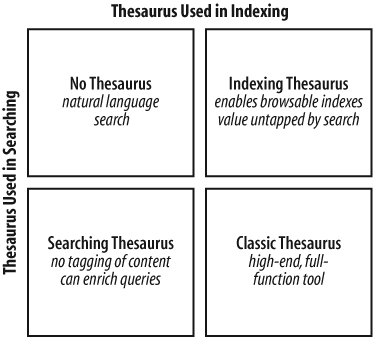
Classic Thesaurus
A classic thesaurus is used at the point of indexing and at the point of searching. Indexers use the thesaurus to map variant terms to preferred terms when performing document-level indexing. Searchers use the thesaurus for retrieval, whether or not they’re aware of the role it plays in their search experience. Query terms are matched against the rich vocabulary of the thesaurus, enabling synonym management, hierarchical browsing, and associative linking. This is the full-bodied, fully integrated thesaurus we’ve referred to for much of this chapter.
Indexing Thesaurus
However, building a classic thesaurus is not always necessary or possible. Consider a scenario in which you have the ability to develop a controlled vocabulary and index documents, but you’re not able to build the synonym-management capability into the search experience. Perhaps another department owns the search engine and won’t work with you, or perhaps the engine won’t support this functionality without major customization.
Whatever the case, you’re able to perform controlled vocabulary indexing, but you’re not able to leverage that work at the point of searching and map users’ variant terms to preferred terms. This is a serious weakness, but there are a few reasons why an indexing thesaurus may be better than nothing:
It structures the indexing process, promoting consistency and efficiency. The indexers can work as an integrated unit, given a shared understanding of preferred terms and indexing guidelines.
It allows you to build browsable indexes of preferred terms, enabling users to find all documents about a particular subject or product through a single point of access.
Such consistency of indexing can provide real value for information systems with captive audiences. When dealing with an intranet application that’s used by the same people on a regular basis, you can expect these users to learn the preferred terms over time. In such an environment, indexing consistency begins to rival indexing quality in value.
And finally, an indexing thesaurus positions you nicely to take the next step up to a classic thesaurus. With a vocabulary developed and applied to your collection of documents, you can focus your energies on integration at the user interface level. This may begin with the addition of an entry vocabulary to your browsable indexes and will hopefully bring searching into the fold, so the full value of the thesaurus is used to power the searching and browsing experience.
Searching Thesaurus
Sometimes a classic thesaurus isn’t practical because of issues on the content side of the equation that prevent document-level indexing. Perhaps you’re dealing with third-party content or dynamic news that’s changing every day. Perhaps you’re simply faced with so much content that manual indexing costs would be astronomical. (In this case, you may be able to go with a classic thesaurus approach that leverages automated-categorization software, as described in Chapter 16.) Whatever the case, there are many web and intranet environments in which controlled vocabulary indexing of the full document collection just isn’t going to happen. This doesn’t mean that a thesaurus isn’t still a viable option to improve the user experience.
A searching thesaurus leverages a controlled vocabulary at the point of searching but not at the point of indexing. For example, when a user enters a term into the search engine, a searching thesaurus can map that term onto the controlled vocabulary before executing the query against the full-text index. The thesaurus may simply perform equivalence term explosion, as we’ve seen in the case of synonym rings, or it may go beyond the equivalence relationship, exploding down the hierarchy to include all narrower terms (traditionally known as “posting down”). These methods will obviously enhance recall at the expense of precision.
You also have the option of giving more power and control to the users—asking them whether they’d like to use any combination of preferred, variant, broader, narrower, or associative terms in their query. When integrated carefully into the search interface and search result screens, this can effectively arm users with the ability to narrow, broaden, and adjust their searches as needed.
A searching thesaurus can also provide greater browsing flexibility. You can allow your users to browse part or all of your thesaurus, navigating the equivalence, hierarchical, and associative relationships. Terms (or the combination of preferred and variant terms) can be used as predefined or “canned” queries to be run against the full-text index. In other words, your thesaurus can become a true portal, providing a new way to navigate and gain access to a potentially enormous volume of content. A major advantage of the searching thesaurus is that its development and maintenance costs are essentially independent of the volume of content. On the other hand, it does put much greater demands on the quality of equivalence and mapping.
If you’d like to learn more about searching thesauri, try these articles:
Anderson, James D. and Frederick A. Rowley. “Building End User Thesauri From Full Text.” In Advances in Classification Research, Volume 2; Proceedings of the Second ASIS SIG/CR Classification Research Workshop, October 27, 1991, eds. Barbara H. Kwasnik and Raya Fidel, 1–13. Medford, NJ: Learned Information, 1992.
Bates, Marcia J. “Design For a Subject Search Interface and Online Thesaurus For a Very Large Records Management Database.” In American Society for Information Science. Annual Meeting. Proceedings, v. 27, 20–28. Medford, NJ: Learned Information, 1990.
Thesaurus Standards
As we explained earlier, people have been developing thesauri for many years. In their 1993 article “The evolution of guidelines for thesaurus construction,” David A. Krooks and F.W. Lancaster suggested that “the majority of basic problems of thesaurus construction had already been identified and solved by 1967.”
This rich history lets us draw from a number of national and international standards, covering the construction of monolingual (single-language) thesauri. For example:
In this book, we draw primarily from the original U.S. standard, ANSI/NISO Z39.19 (1998), which is very similar to the International standard, ISO 2788. The ANSI/NISO standard is entitled “Guidelines for the Construction, Format and Management of Monolingual Thesauri.” The term “guidelines” in the title is very telling. Consider what software vendor Oracle has to say about its interpretation of this standard:
The phrase . . . thesaurus standard is somewhat misleading. The computing industry considers a “standard” to be a specification of behavior or interface. These standards do not specify anything. If you are looking for a thesaurus function interface, or a standard thesaurus file format, you won’t find it here. Instead, these are guidelines for thesaurus compilers—compiler being an actual human, not a program.
What Oracle has done is taken the ideas in these guidelines and in ANSI Z39.19 . . . and used them as the basis for a specification of our own creation . . . So, Oracle supports ISO-2788 relationships or ISO-2788 compliant thesauri.
As you’ll see when we explore a few examples, the ANSI/NISO standard provides simple guidelines that are very difficult to apply. The standard provides a valuable conceptual framework and in some cases offers specific rules you can follow, but it absolutely does not remove the need for critical thinking, creativity, and risk-taking in the process of thesaurus construction.
We strongly disagree with the suggestion by Krooks and Lancaster that the basic problems in this area have been solved, and we often disagree with guidelines in the ANSI/NISO standard. What’s going on here? Are we just being difficult? No, what’s really behind these tensions is the disruptive force of the Internet. We’re in the midst of a transition from the thesaurus in its traditional form to a new paradigm embedded within the networked world.
Traditional thesauri emerged within the academic and library communities. They were used in print form and were designed primarily for expert users. When we took library science courses back in the 80s and 90s, a major component of online information retrieval involved learning to navigate the immense volumes of printed thesauri in the library to identify subject descriptors for online searching of the Dialog information service. People had to be trained to use these tools, and the underlying assumption was that specialists would use them on a regular basis, becoming efficient and effective over time. The whole system was built around the relatively high cost of processor time and network bandwidth.
Then the world changed. We’re now dealing with totally online systems. We can’t ask our customers to run to the library before using our web site. We’re typically serving novice users with no formal training in online searching techniques. They’re likely to be infrequent visitors, so they’re not going to build up much familiarity with our site over time. And we’re operating in the broader business environment, where the goals may be very different from those of academia and libraries.
Within this new paradigm, we’re being challenged to figure out which of the old guidelines do and do not apply. It would be an awful waste to throw out valuable resources like the ANSI/NISO standard that are built upon decades of research and experience. There’s a great deal that’s still relevant. However, it would also be a mistake to follow the guidelines blindly, akin to using a 1950s map to navigate today’s highways.
Advantages to staying close to the standard include:
There’s good thinking and intelligence baked into these guidelines.
Most thesaurus management software is designed to be compliant with ANSI/NISO, so sticking with the standard can be useful from a technology-integration perspective.
Compliance with the standard will provide a better chance of cross-database compatibility, so when your company merges with its competitor, you might have an easier time merging the two sets of vocabularies.
Our advice is to read the guidelines, follow them when they make sense, but be prepared to deviate from the standard when necessary. After all, it’s these opportunities to break the rules that make our lives as information architects fun and exciting!
Semantic Relationships
What sets a thesaurus apart from the simpler controlled vocabularies is its rich array of semantic relationships. Let’s explore each relationship more closely.
Equivalence
The equivalence relationship (Figure 9-21) is employed to connect preferred terms and their variants. While we may loosely refer to this as “synonym management,” it’s important to recognize that equivalence is a broader term than synonymy.
Our goal is to group terms defined as “equivalent for the purposes of retrieval.” This may include synonyms, near-synonyms, acronyms, abbreviations, lexical variants, and common misspellings; for example:
- Preferred term
Palm m505
- Variant terms (equivalents)
Palm, Palm Pilot, Palm 505, Palm505, Palm V, Handheld, Pocket PC, Handspring Visor
In the case of a product database, it may also include the names of retired products and of competitors’ products. Depending on the desired specificity of your controlled vocabulary, you may also fold more general and more specific terms into the equivalence relationship to avoid extra levels of hierarchy. The goal is to create a rich entry vocabulary that serves as a funnel, connecting users with the products, services, and content that they’re looking for and that you want them to find.
Hierarchical
The hierarchical relationship (Figure 9-22) divides up the information space into categories and subcategories, relating broader and narrower concepts through the familiar parent-child relationship.

There are three subtypes of hierarchical relationship:
- Generic
This is the traditional class-species relationship we draw from biological taxonomies. Species B is a member of Class A and inherits the characteristics of its parent. For example, Bird NT Magpie.
- Whole-part
In this hierarchical relationship, B is a part of A. For example, Foot NT Big Toe.
- Instance
In this case, B is an instance or example of A. This relationship often includes proper names. For example, Seas NT Mediterranean Sea.
At first blush, the hierarchical relationship sounds pretty straightforward. However, anyone who’s ever developed a hierarchy knows that it isn’t as easy as it sounds. There are many different ways to hierarchically organize any given information space (e.g., by subject, by product category, or by geography). As we’ll explain shortly, a faceted thesaurus supports the common need for multiple hierarchies. You also need to deal with the tricky issues of granularity, defining how many layers of hierarchy to develop.
Once again, we need to ground our work in the ultimate goal of enhancing the ability of our users to find what they need. The card-sorting methodologies (discussed in Chapter 10) can help you begin to shape your hierarchies based on user needs and behaviors.
Associative
The associative relationship (Figure 9-23) is often the trickiest, and by necessity is usually developed after you’ve made a good start on the other two relationship types. In thesaurus construction, associative relationships are often defined as strongly implied semantic connections that aren’t captured within the equivalence or hierarchical relationships.

There is the notion that associative relationships should be “strongly implied.” For example, hammer RT nail. In practice, however, defining these relationships is a highly subjective process.
The ANSI/NISO thesaurus discusses many associative relationship subtypes. For example:
In the world of e-commerce, the associative relationship provides an excellent vehicle for connecting customers to related products and services. Associative relationships allow what marketing folks call “cross-selling,” allowing an e-commerce site, for example, to say “Hey, nice pants! They’d go great with this shirt.” When done well, these associative relationships can both enhance the user experience and further the goals of the business.
Preferred Terms
Terminology is critical. The following sections examine some aspects of terminology in detail.
Term Form
Defining the form of preferred terms is something that seems easy until you try it. All of a sudden, you find yourself plunged into heated arguments over grammatical minutiae. Should we use a noun or a verb? What’s the “correct” spelling? Do we use the singular or plural form? Can an abbreviation be a preferred term? These debates can suck up large amounts of time and energy.
Fortunately, the ANSI/NISO thesaurus standard goes into great detail in this area. We recommend following these guidelines, while allowing for exceptions when there’s a clear benefit. Some of the issues covered by the standard include:
Term Selection
Of course, selection of a preferred term involves more than the form of the term; you’ve got to pick the right term in the first place. The ANSI/NISO standard won’t help too much here. Consider the following excerpts:
Section 3.0. “Literary warrant (occurrence of terms in documents) is the guiding principle for selection of the preferred (term).”
Section 5.2.2. “Preferred terms should be selected to serve the needs of the majority of users.”
This tension between literary warrant and user warrant can be resolved only by reviewing your goals and considering how the thesaurus will be integrated with the web site. Do you want to use preferred terms to educate your users about the industry vocabulary? Will you be relying on preferred terms as your entry vocabulary (e.g., no variants in the index)? You’ll need to answer these questions before deciding on the primary source of authority for term selection.
Term Definition
Within the thesaurus itself, we’re striving for extreme specificity in our use of language. Remember, we’re trying to control vocabulary. Beyond the selection of distinctive preferred terms, there are some tools for managing ambiguity.
Parenthetical term qualifiers provide a way to manage homographs. Depending on the context of your thesaurus, you may need to qualify the term “Cells” in some of the following ways:
| Cells (biology) |
| Cells (electric) |
| Cells (prison) |
Scope notes provide another way to increase specificity. While they can sometimes look very much like definitions, scope notes are a different beast. They are intended to deliberately restrict meaning to one concept, whereas definitions often suggest multiple meanings. Scope notes are very useful in helping indexers to select the right preferred term. They can sometimes be leveraged in searching or results display to assist users as well.
Term Specificity
The specificity of terms is another difficult issue that all thesaurus designers must face. For example, should “knowledge management software” be represented as one term, two terms, or three terms? Here’s what the standards have to say:
ANSI/NISO Z39.19. “Each descriptor . . . should represent a single concept.”
ISO 2788. “It is a general rule that . . . compound terms should be factored (split) into simple elements.”
Once again, the standards don’t make your life easy. ANSI/NISO leaves you arguing over what constitutes a “single concept.” ISO leads you toward uniterms (e.g., knowledge, management, software), which would probably be the wrong way to go in this example.
You need to strike a balance based on your context. Of particular importance is the size of the site. As the volume of content grows, it becomes increasingly necessary to use compound terms to increase precision. Otherwise, users get hundreds or thousands of hits for every search (and every preferred term).
The scope of content is also important. For example, if we’re working on a web site for Knowledge Management magazine, the single term “knowledge management software” or perhaps “software (knowledge management)” may be the way to go. However, if we’re working on a broad IT site like CNET, it may be better to use “knowledge management” and “software” as independent preferred terms.
Polyhierarchy
In a strict hierarchy, each term appears in one and only one place. This was the original plan for the biological taxonomy. Each species was supposed to fit neatly into one branch of the tree of life.
kingdom:
phylum:
sub-phylum:
class:
order:
family:
speciesHowever, things didn’t go according to plan. In fact, biologists have been arguing for decades over the correct placement of various species. Some organisms have the audacity to exhibit characteristics of multiple categories.
If you’re a purist, you can attempt to defend the ideal of strict hierarchy within your web site. Or, if you’re pragmatic, you can allow for some level of polyhierarchy, permitting some terms to be cross-listed in multiple categories. This is shown in Figure 9-24.

When you’re dealing with large information systems, polyhierarchy is unavoidable. As the number of documents grows, you need a greater level of precoordination (using compound terms) to increase precision, which forces polyhierarchy. For example, Medline cross-lists viral pneumonia under both virus diseases and respiratory tract diseases (Figure 9-25).

Yahoo! is another large site that makes prolific use of polyhierarchy (Figure 9-26). The @ signs are used to note categories that are cross-listed under other branches within the hierarchy. In the classification and placement of physical objects, polyhierarchy causes a problem. Physical objects can typically be in only one place at one time. The Library of Congress classification scheme was developed so that each book in a library could be placed (and found) in one and only one location on the shelves. In digital information systems, the only real challenge introduced by polyhierarchy is representing the navigational context. Most systems allow for the notion of primary and secondary locations within the hierarchy. Yahoo!’s @ signs lead users from the secondary to the primary locations.

Faceted Classification
In the 1930s, an Indian librarian by the name of S. R. Ranganathan created a new type of classification system. Recognizing the problems and limitations of these top-down single-taxonomy solutions, Ranganathan built his system upon the notion that documents and objects have multiple dimensions, or facets.
The old model asks the question, “Where do I put this?” It’s more closely tied to our experience in the physical world, with the idea of one place for each item. In contrast, the faceted approach asks the question, “How can I describe this?”
Like many librarians, Ranganathan was an idealist. He argued that you must build multiple “pure” taxonomies, using one principle of division at a time. He suggested five universal facets to be used for organizing everything:
Personality
Matter
Energy
Space
Time
In our experience, the faceted approach has great value, but we don’t tend to use Ranganathan’s universal facets. Instead, common facets in the business world include:
Topic
Product
Document type
Audience
Geography
Price
Still confused about facets? See Figure 9-27. All we’re really doing is applying the structure of a fielded database to the more heterogeneous mix of documents and applications in a web site. Rather than the one-taxonomy-fits-all approach of Yahoo!, we’re embracing the concept of multiple taxonomies that focus on different dimensions of the content.

Wine.com provides a simple example of faceted classification. Wine has several facets that we commonly mix and match in our selection process at restaurants and grocery stores:
| Facet | Sample controlled vocabulary values |
| Type | Red (Merlot, Pinot Noir), White (Chablis, Chardonnay), Sparkling, Pink, Dessert |
| Region (origin) | Australian, Californian, French, Italian |
| Winery (manufacturer) | Blackstone, Clos du Bois, Cakebread |
| Year | 1969, 1990, 1999, 2000 |
| Price | $3.99, $20.99, < $199, Cheap, Moderate, Expensive |
Note that some facets are flat lists (e.g., price) whereas some must be represented hierarchically (e.g., type). When we look for a moderately priced Californian Merlot, we’re unconsciously defining and combining facets. Wine.com leverages a faceted classification to enable this experience online. The main shopping page in Figure 9-28 presents three ways to browse, providing multiple paths to the same information.

The Power Search, shown in Figure 9-29, provides the ability to combine facets into the rich type of query we usually express in natural language.

The results page (Figure 9-30) has our list of moderately priced Californian Merlot wines. Note that we’re not only able to leverage facets in the search, but we can also use the facets to sort results. Wine.com has added ratings from several magazines (WE = Wine Enthusiast, WS = Wine Spectator) as yet another facet.
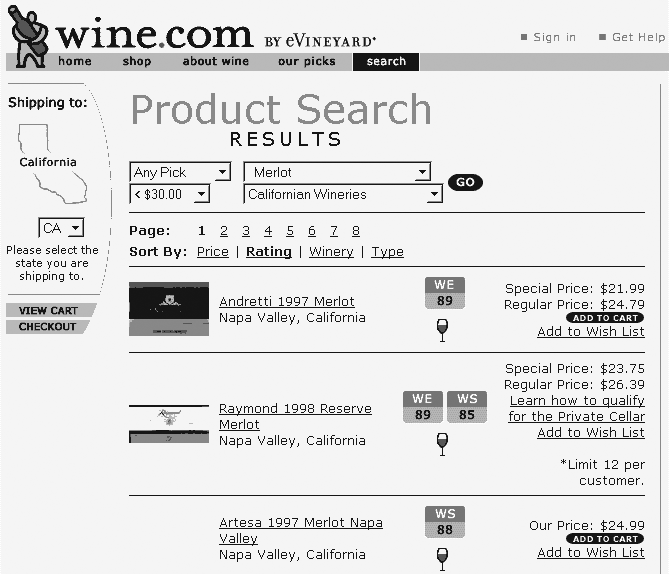
The information architects and designers at Wine.com have made decisions throughout the site about how and when to leverage facets within the interface. For example, you can’t browse by price or rating from the main page. Hopefully, these are informed decisions made by balancing an understanding of user needs (how people want to browse and search) and business needs (how eVineyard can maximize sales of high-margin items).
The nice thing about a faceted classification approach is that it provides great power and flexibility. With the underlying descriptive metadata and structure in place, information architects and interface designers can experiment with hundreds of ways to present navigation options. The interface can be tested and refined over time, while the faceted classification provides an enduring foundation.
In recent years, search solutions built atop faceted classifications have really come into their own, thanks in part to search vendor Endeca and its “Guided Navigation” model (Figures 9-31 and 9-32), which encourages users to refine or narrow their searches based on metadata fields and values.

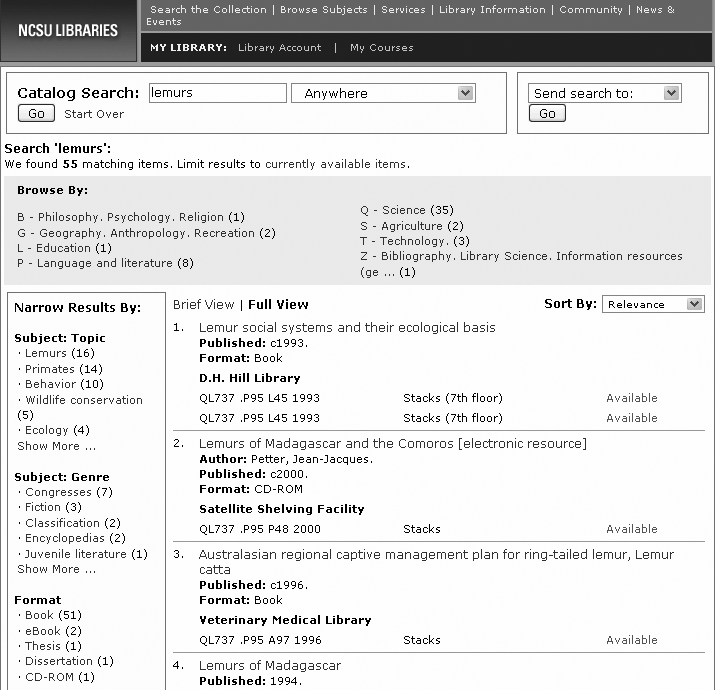
Guided navigation was quickly embraced in the online retail arena, where there’s a clear link between findability and profitability. More recently, this hybrid search/browse model has been widely adopted across industry, government, healthcare, publishing, and education. As Figure 9-32 shows, guided navigation is even being used to improve library catalogs. Ranganathan would be proud.
In addition to the increasing mainstream implementation of controlled vocabularies, we’re also enjoying a growing wealth of resources to support these efforts. Here are just a few:
- ANSI-NISO Z-39.19-2005
Guidelines for the Construction, Format, and Management of Monolingual Controlled Vocabularies. Completely rewritten (and renamed) in 2005; http://www.niso.org/standards/standard_detail.cfm?std_id=814
- Controlled Vocabularies: A Glosso-Thesaurus
Written by Fred Leise, Karl Fast, and Mike Steckel; http://www.boxesandarrows.com/view/controlled_vocabularies_a_glosso_thesaurus
- Dublin Core Metadata Initiative
- Flamenco Search Interface Project
- Glossary of Terms Relating to Thesauri
- Taxonomy Warehouse
- ThesauriOnline
Metadata, controlled vocabularies, and thesauri are increasingly becoming the building blocks of most major web sites and intranets. Single-taxonomy solutions are giving way to more flexible, faceted approaches. Put simply, if you’re an information architect, we see facets in your future![4]
[1] The Trouble with Computers: Usefulness, Usability, and Productivity, by Thomas K. Landauer (MIT Press).
[2] From OCLC’s Introduction to the Dewey Decimal Classification at http://www.oclc.org/dewey/about/about_the_ddc.htm.
[3] Guidelines for the Construction, Format, and Management of Monolingual Thesauri. ANSI/NISO Z39.19–1993 (R1998).
[4] For more about Yahoo!, Wine.com, and faceted classification, see http://www.semanticstudios.com/publications/semantics/speed.html.