
Chapter 8. Search Systems
Chapter 7 helped you create the best navigation system possible for your web site. This chapter describes another form of finding information: searching. Searching (and more broadly, information retrieval) is an expansive, challenging, and well-established field, and we can only scratch the surface here. We’ll limit our discussion to what makes up a search system, when to implement search systems, and some practical advice on how to design a search interface and display search results.
This chapter often uses examples of search systems from sites that allow you to search the entire Web in addition to site-specific search engines. Although these web-wide tools tend to index a very broad collection of content, it’s nonetheless extremely useful to study them. Of all search systems, none has undergone the testing, usage, and investment that web-wide search tools have, so why not benefit from their research? Many of these tools are available for use on local sites as well.
Does Your Site Need Search?
Before we delve into search systems, we need to make a point: think twice before you make your site searchable.
Your site should, of course, support the finding of its information. But as the preceding chapters demonstrate, there are other ways to support finding. And be careful not to assume, as many do, that a search engine alone will satisfy all users’ information needs. While many users want to search a site, some are natural browsers, preferring to forego filling in that little search box and hitting the “search” button. We suggest you consider the following questions before committing to a search system for your site.
- Does your site have enough content?
How much content is enough to merit the use of a search engine? It’s hard to say. It could be 5, 50, or 500 pages; no specific number serves as a standard threshold. What’s more important is the type of information need that’s typical of your site’s users. Users of a technical support site often have a specific kind of information in mind, and are more likely to require search than users of an online banking site. If your site is more like a library than a software application, then search probably makes sense. If that’s the case, then consider the volume of content, balancing the time required to set up and maintain a search system with the payoff it will bring to your site’s users.
- Will investing in search systems divert resources from more useful navigation systems?
Because many site developers see search engines as the solution to the problems users have when trying to find information in their sites, search engines become Band-Aids for sites with poorly designed navigation systems and other architectural weaknesses. If you see yourself falling into this trap, you should probably suspend implementing your search system until you fix your navigation system’s problems. You’ll find that search systems often perform better if they can take advantage of aspects of strong navigation systems, such as the controlled vocabulary terms used to tag content. And users will often benefit even more from using both types of finding if they work together well. Of course, your site’s navigation might be a disaster for political reasons, such as an inability among your organization’s decision-makers to agree on a site-wide navigation system. In such cases, reality trumps what ought to be, and search might indeed be your best alternative.
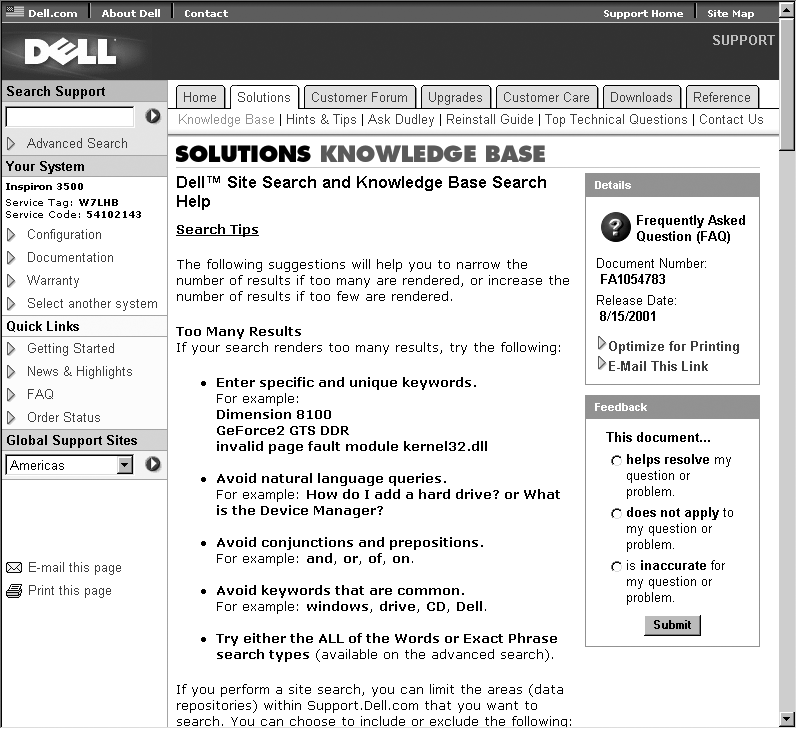
- Do you have the time and know-how to optimize your site’s search system?
Search engines are fairly easy to get up and running, but like many things on the Web, they are difficult to implement effectively. As a user of the Web, you’ve certainly seen incomprehensible search interfaces, and we’re sure that your queries have retrieved some pretty inscrutable results. This is often due to a lack of planning by the site developer, who probably installed the search engine with its default settings, pointed it at the site, and forgot about it. If you don’t plan on putting some significant time into configuring your search engine properly, reconsider your decision to implement it.
- Are there better alternatives?
Search may be a good way to serve your site’s users, but other ways may work better. For example, if you don’t have the technical expertise or confidence to configure a search engine or the money to shell out for one, consider providing a site index instead. Both site indexes and search engines help users who know what they’re looking for. While a site index can be a heck of a lot of work, it is typically created and maintained manually, and can therefore be maintained by anyone who knows HTML.
- Will your site’s users bother with search?
It may already be clear that your users would rather browse than search. For example, users of a greeting card site may prefer browsing thumbnails of cards instead of searching. Or perhaps users do want to search, but searching is a lower priority for them, and it should be for you as you consider how to spend your information architecture development budget.
Now that we’ve got our warnings and threats out of the way, let’s discuss when you should implement search systems. Most web sites, as we know, aren’t planned out in much detail before they’re built. Instead, they grow organically. This may be all right for smaller web sites that aren’t likely to expand much, but for ones that become popular, more and more content and functional features get piled on haphazardly, leading to a navigation nightmare. The following issues will help you decide when your site has reached the point of needing a search system.
- Search helps when you have too much information to browse
There’s a good analogy of physical architecture. Powell’s Books (http://www.powells.com), which claims to be the largest bookstore in the world, covers an entire city block (68,000 square feet) in Portland, Oregon. We guess that it started as a single small storefront on that block, but as the business grew, the owners knocked a doorway through the wall into the next storefront, and so on, until it occupied the whole block. The result is a hodgepodge of chambers, halls with odd turns, and unexpected stairways. This chaotic labyrinth is a charming place to wander and browse, but if you’re searching for a particular title, good luck. It will be difficult to find what you’re looking for, although if you’re really lucky you might serendipitously stumble onto something better.
Yahoo! once was a web version of Powell’s. At first, everything was there and fairly easy to find. Why? Because Yahoo!, like the Web, was relatively small. At its inception, Yahoo! pointed to a few hundred Internet resources, made accessible through an easily browsable subject hierarchy. No search option was available, something unimaginable to Yahoo! users today. But things soon changed. Yahoo! had an excellent technical architecture that allowed site owners to easily self-register their sites, but Yahoo!’s information architecture was not well planned and couldn’t keep up with the increasing volume of resources that were added daily. Eventually, the subject hierarchy became too cumbersome to navigate, and Yahoo! installed a search system as an alternative way of finding information in the site. Nowadays, far more people use Yahoo!’s search engine instead of browsing through its taxonomy, which indeed disappeared from Yahoo!’s main page eons ago.
Your site probably isn’t as large as Yahoo!, but it’s probably experienced a similar evolution. Has your content outstripped your browsing systems? Do your site’s users go insane trying to spot the right link on your site’s hugely long category pages? Then perhaps the time has come for search.
- Search helps fragmented sites
Powell’s room after room after room of books is also a good analogy for the silos of content that make up so many intranets and large public sites. As is so often the case, each business unit has gone ahead and done its own thing, developing content haphazardly with few (if any) standards, and probably no metadata to support any sort of reasonable browsing.
If this describes your situation, you have a long road ahead of you, and search won’t solve all of your problems—let alone your users’ problems. But your highest priority should be to set up a search system to perform full-text indexing of as much cross-departmental content as possible. Even if it’s only a stopgap, search will address your users’ dire need for finding information regardless of which business unit actually owns it. Search will also help you, as the information architect, to get a better handle on what content is actually out there.
- Search is a learning tool
Through search-log analysis, which we touched on in Chapter 6, you can gather useful data on what users actually want from your site, and how they articulate their needs (in the form of search queries). Over time you can analyze this valuable data to diagnose and tune your site’s search system, other aspects of its information architecture, the performance of its content, and many other areas as well.
- Search should be there because users expect it to be there
Your site probably doesn’t contain as much content as Yahoo!, but if it’s a substantial site, it probably merits a search engine. There are good reasons for this. Users won’t always be willing to browse through your site’s structure; their time is limited, and their cognitive-overload threshold is lower than you think. Interestingly, sometimes users won’t browse for the wrong reasons—that is, they search when they don’t necessarily know what to search for and would be better served by browsing. But perhaps most of all, users expect that little search box wherever they go. It’s a default convention, and it’s hard to stand against the wave of expectations.
- Search can tame dynamism
You should also consider creating a search system for your site if it contains highly dynamic content. For example, if your site is a web-based newspaper, you might be adding dozens of story files daily via a commercial newsfeed or some other form of content syndication. For this reason, you probably wouldn’t have the time each day to manually catalog your content or maintain elaborate tables of contents and site indexes. A search engine could help you by automatically indexing the contents of the site once or many times daily. Automating this process ensures that users have quality access to your site’s content, and you can spend time doing things other than manually indexing and linking the story files as they come in.
Search System Anatomy
On its surface, search seems quite straightforward. Look for the box with the search button, enter and submit your query, and mutter a little prayer while the results load. If your prayers are answered, you’ll find some useful results above the fold and can go on with your life.
Of course, there’s a lot going on under the hood. A search engine application has indexed content on the site. All of it? Some of it? As a user, you’ll probably never know. And what parts of the content? Usually the search engine can find the full text of each document. But a search engine can also index information associated with each document—like titles, controlled vocabulary terms, and so forth—depending on how it’s been configured. And then there’s the search interface, your window on the search engine’s index. What you type there is looked up in the index; if things go well, results that match your query are returned.
A lot is going on here. There are the guts of the search engine itself; aside from tools for indexing and spidering, there are algorithms for processing your query into something the software can understand, and for ranking those results. There are interfaces, too: ones for entering queries (think simple and advanced search) and others for displaying results (including decisions on what to show for each result, and how to display the entire set of results). Further complicating the picture, there may be variations in query languages (for example, whether or not Boolean operators like AND, OR, and NOT can be used) and query builders (like spell checkers) that can improve upon a query.
Obviously, there’s a lot to search that doesn’t meet the eye. Additionally, there’s your query, which itself usually isn’t very straightforward. Where does your query come from? Your mind senses a gap that needs to be filled—with information—but isn’t always sure how to express it. Searching is often iterative—not just because we don’t always like the results we retrieve, but often because it takes us a few tries to get the words right for our query. You then interact with a search interface, heading for the simple, Google-like box or, if you’re “advanced,” grappling with the advanced search interface. And finally, you interact with results, which hopefully help you quickly determine which results are worth clicking through, which to ignore, and whether or not you should go back and try modifying your search. Figure 8-1 shows some of these pathways.
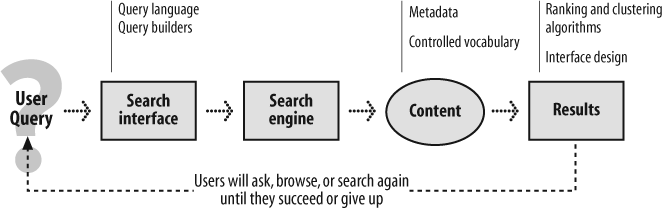
That’s the 50,000-foot view of what’s happening in a search system. Most of the technical details can be left to your IT staff; as an information architect, you are more concerned with factors that affect retrieval performance than with the technical guts of a search engine. But as we discuss in the following section, you don’t want to leave too much in the hands of IT.
Search Is Not an IT Thing
Search engines are the foundation of search systems, and search engines are software applications. And software applications aren’t your business; they’re something for the IT people to worry about, and select, and install, and control. Right? Well, not exactly.
Setting up a web server is an IT thing, too, but we don’t assign IT staff the tasks of writing a site’s content, designing its visual aspects, or developing its information architecture; ideally, those are the responsibilities of people with other kinds of expertise. Why should setting up a search system be any different? Yet, it’s all too common for information architects to be told that search is off-limits.
The reason is clear: a search engine is a complex piece of technology. It often requires someone who understands the technical issues—for example, load balancing for servers, platform limitations, and so on—to be involved in search engine selection and configuration.
But ultimately, search is there for users, and it’s the responsibility of the information architect to advocate for users. An information architect will typically understand more than an IT specialist about how a search engine might benefit users by leveraging metadata, how its interface could be improved, or how it should be integrated with browsing. Additionally, consider all the aspects of a search system that we covered above; the search engine is just one piece of the puzzle. There are a lot of other decisions that must be made for the whole thing to behave, well, as a system that works well for users.
Ideally, the information architect, IT specialist, and people with other types of expertise will determine their respective needs, discuss how these might impact one another, and ultimately present a unified set of requirements when evaluating search-engine applications. Unfortunately, this is not always possible for political and other reasons. That’s why the information architect must be prepared to argue strongly for owning at least an equal responsibility for selecting and implementing the search engine that will best serve users, rather than the one that runs on someone’s favorite platform or is written in someone’s favorite programming language.
Choosing What to Search
Let’s assume that you’ve already chosen a search engine. What content should you index for searching? It’s certainly reasonable to point your search engine at your site, tell it to index the full text of every document it finds, and walk away. That’s a large part of the value of search systems—they can be comprehensive and can cover a huge amount of content quickly.
But indexing everything doesn’t always serve users well. In a large, complex web environment chock-full of heterogeneous subsites and databases, you may want to allow users to search the silo of technical reports or the staff directory without muddying their search results with the latest HR newsletter articles on the addition of fish sticks to the cafeteria menu. The creation of search zones—pockets of more homogeneous content—reduces the apples-and-oranges effect and allows users to focus their searches.
Choosing what to make searchable isn’t limited to selecting the right search zones. Each document or record in a collection has some sort of structure, whether rendered in HTML, XML, or database fields. In turn, that structure stores content components: pieces or “atoms” of content that are typically smaller than a document. Some of that structure—say, an author’s name—may be leveraged by a search engine, while other parts—such as the legal disclaimer at the bottom of each page—might be left out.
Finally, if you’ve conducted an inventory and analysis of your site’s content, you already have some sense of what content is “good.” You might have identified your valuable content by manually tagging it or through some other mechanism. You might consider making this “good” stuff searchable on its own, in addition to being part of the site-wide search. You might even program your search engine to search this “good” stuff first, and expand to search the rest of the site’s content if that first pass doesn’t retrieve useful results. For example, if most of an e-commerce site’s users are looking for products, those could be searched by default, and the search could then be expanded to cover the whole site as part of a revised search option.
In this section, we’ll discuss issues of selecting what should be searchable at both a coarse level of granularity (search zones) and at the more atomic level of searching within documents (content components).
Determining Search Zones
Search zones are subsets of a web site that have been indexed separately from the rest of the site’s content. When a user searches a search zone, he has, through interaction with the site, already identified himself as interested in that particular information. Ideally, the search zones in a site correspond to his specific needs, and the result is improved retrieval performance. By eliminating content that is irrelevant to his need, the user should retrieve fewer, more relevant, results.
On Dell’s site (Figure 8-2), users can select search zones by audience type: home/home office, small business, and so on. (Note that “all” is the default setting.) These divisions quite possibly mirror how the company is organized, and perhaps each is stored in a separate filesystem or on its own server. If that’s the case, the search zones are already in place, leveraging the way the files are logically and perhaps physically stored.
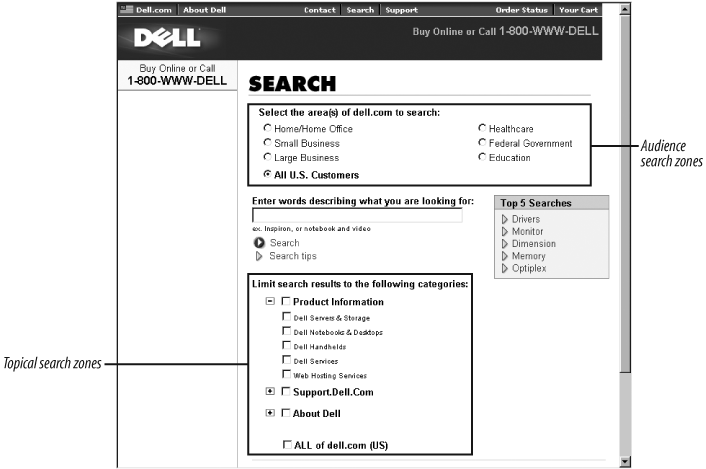
Additionally, users can select one or more of the site’s categories or subcategories. It’s probable that these pages come from the audience subsites, and that Dell allows its documents to be recombined into new search zones by indexing them by the keywords these zones represent. It’s expensive to index specific content, especially manually, but one of the benefits of doing so is flexible search-zone creation: each category can be its own search zone or can be combined into a larger search zone.
You can create search zones in as many ways as you can physically segregate documents or logically tag them. Your decisions in selecting your site’s organization schemes often help you determine search zones as well. So our old friends from Chapter 6 can also be the basis of search zones:
Content type
Audience
Role
Subject/topic
Geography
Chronology
Author
Department/business unit
And so on. Like browsing systems, search zones allow a large body of content to be sliced and diced in useful new ways, providing users with multiple “views” of the site and its content. But, naturally, search zones are a double-edged sword. Narrowing one’s search through search zones can improve results, but interacting with them adds a layer of complexity. So be careful: many users will ignore search zones when they begin their search, opting to enter a simple search against the index of the entire site. So users might not bother with your meticulously created search zones until they’re taking their second pass at a search, via an Advanced Search interface.
Following are a few ways to slice and dice.
Navigation versus destination
Most web sites contain, at minimum, two major types of pages: navigation pages and destination pages. Destination pages contain the actual information you want from a web site: sports scores, book reviews, software documentation, and so on. Navigation pages may include main pages, search pages, and pages that help you browse a site. The primary purpose of a site’s navigation pages is to get you to the destination pages.
When a user searches a site, it’s fair to assume that she is looking for destination pages. If navigation pages are included in the retrieval process, they will just clutter up the retrieval results.
Let’s take a simple example: your company sells computer products via its web site. The destination pages consist of descriptions, pricing, and ordering information, one page for each product. Also, a number of navigation pages help users find products, such as listings of products for different platforms (e.g., Macintosh versus Windows), listings of products for different applications (e.g., word processing, bookkeeping), listings of business versus home products, and listings of hardware versus software products. If the user is searching for Intuit’s Quicken, what’s likely to happen? Instead of simply retrieving Quicken’s product page, she might have to wade through all of these pages:
Financial Products index page
Home Products index page
Macintosh Products index page
Quicken Product page
Software Products index page
Windows Products index page
The user retrieves the right destination page (i.e., the Quicken Product page) but also five more that are purely navigation pages. In other words, 83 percent of the retrieval obstructs the user’s ability to find the most useful result.
Of course, indexing similar content isn’t always easy, because “similar” is a highly relative term. It’s not always clear where to draw the line between navigation and destination pages—in some cases, a page can be considered both. That’s why it’s important to test out navigation/destination distinctions before actually applying them. The weakness of the navigation/destination approach is that it is essentially an exact organization scheme (discussed in Chapter 6) that requires the pages to be either destination or navigation. In the following three approaches, the organization schemes are ambiguous, and therefore more forgiving of pages that fit into multiple categories.
Indexing for specific audiences
If you’ve already decided to create an architecture that uses an audience-oriented organization scheme, it may make sense to create search zones by audience breakdown as well. We found this a useful approach for the original Library of Michigan web site.
The Library of Michigan has three primary audiences: members of the Michigan state legislature and their staffs, Michigan libraries and their librarians, and the citizens of Michigan. The information needed from this site is different for each of these audiences; for example, each has a very different circulation policy.
So we created four indexes: one for each of the three audiences, and one unified index of the entire site in case the audience-specific indexes didn’t do the trick for a particular search. Here are the results from running a query on the word “circulation” against each of the four indexes:
| Index | Documents retrieved | Retrieval reduced by |
| Unified | 40 | - |
| Legislature Area | 18 | 55% |
| Libraries Area | 24 | 40% |
| Citizens Area | 9 | 78% |
As with any search zone, less overlap between indexes improves performance. If the retrieval results were reduced by a very small figure, say 10 or 20 percent, it may not be worth the overhead of creating separate audience-oriented indexes. But in this case, much of the site’s content is specific to individual audiences.
Indexing by topic
Ameriprise Financial employs loosely topical search zones with its site. For example, if you’re looking for information on investments that will help you achieve a financially secure retirement, you might preselect the “Individual” search zone, as shown in Figure 8-3.
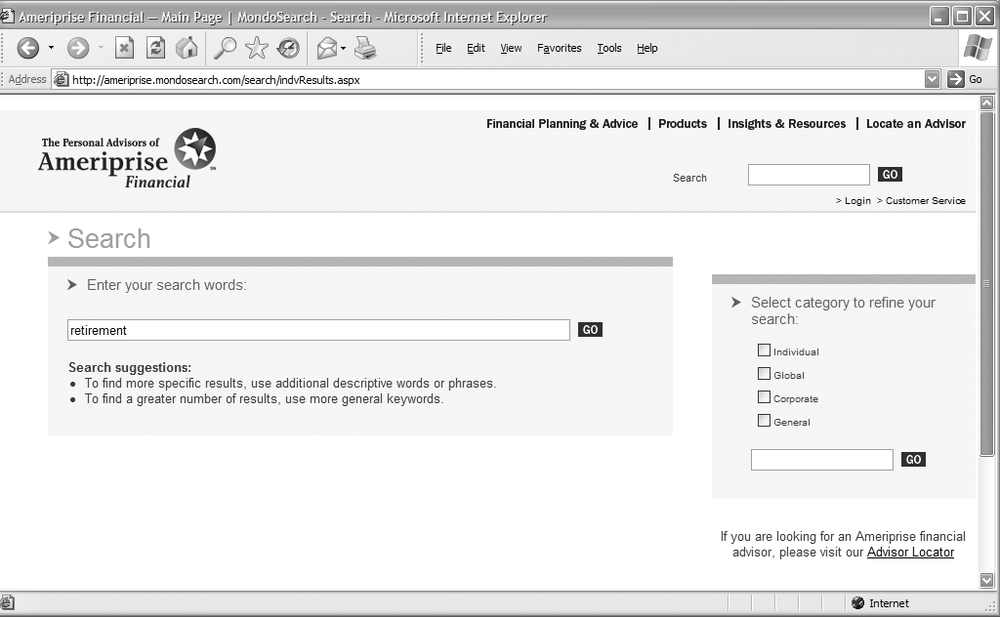
The 85 results retrieved may sound like a lot, but if you’d searched the entire site, the total would have been 580 results, many dealing with topic areas that aren’t germaine to personal retirement investing.
Indexing recent content
Chronologically organized content allows for perhaps the easiest implementation of search zones. (Not surprisingly, it’s probably the most common example of search zones.) Because dated materials aren’t generally ambiguous and date information is typically easy to come by, creating search zones by date—even ad hoc zones—is straightforward.
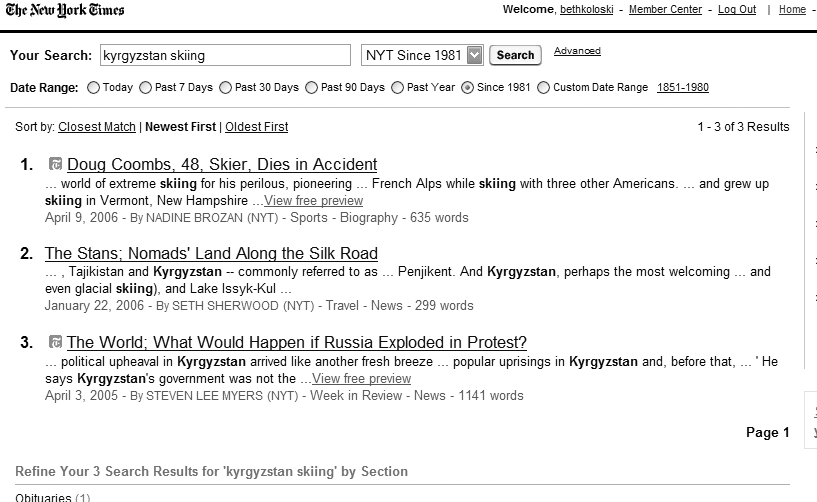
The advanced search interface of the New York Times provides a useful illustration of filtering by date range (Figure 8-4).
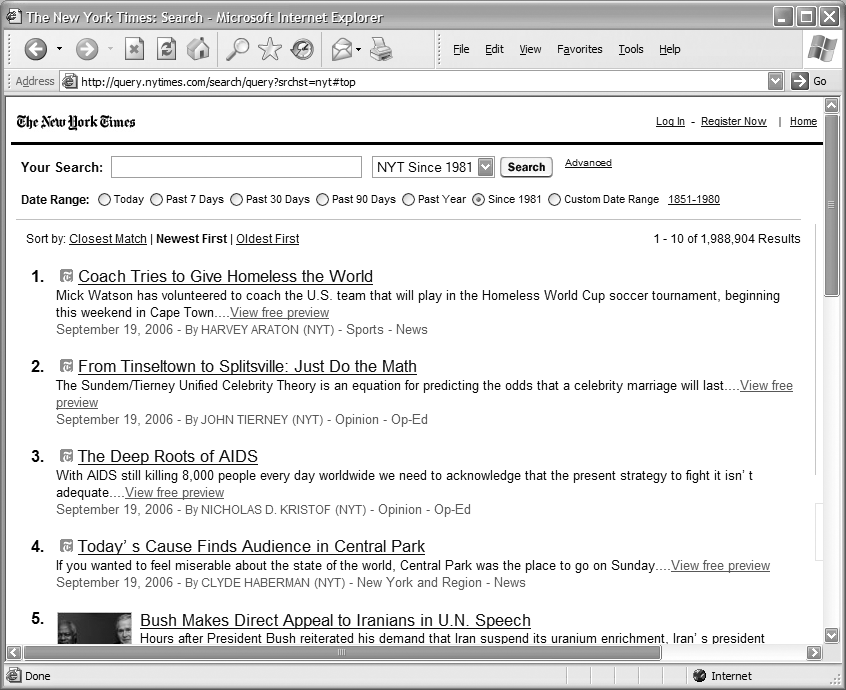
Regular users can return to the site and check up on the news using one of a number of chronological search zones (e.g., today’s news, past week, past 30 days, past 90 days, past year, and since 1996). Additionally, users who are looking for news within a particular date range or on a specific date can essentially generate an ad hoc search zone.
Selecting Content Components to Index
Just as it’s often useful to provide access to subsets of your site’s content, it’s valuable to allow users to search specific components of your documents. By doing so, you’ll enable users to retrieve more specific, precise results. And if your documents have administrative or other content components that aren’t especially meaningful to users, these can be excluded from the search.
In the article from Salon shown in Figure 8-5, there are more content components than meet the eye. There is a title, an author name, a description, images, links, and some attributes (such as keywords) that are invisible to users. There are also content components that we don’t want to search, such as the full list of categories in the upper left. These could confuse a user’s search results; for example, if the full text of the document was indexed for searching, searches for “comics” would retrieve this article about finding a translator in Egypt. (A great by-product of the advent of content management systems and logical markup languages like XML is that it’s now much easier to leave out content that shouldn’t be indexed, like navigation options, advertisements, disclaimers, and other stuff that might show up in document headers and footers.)
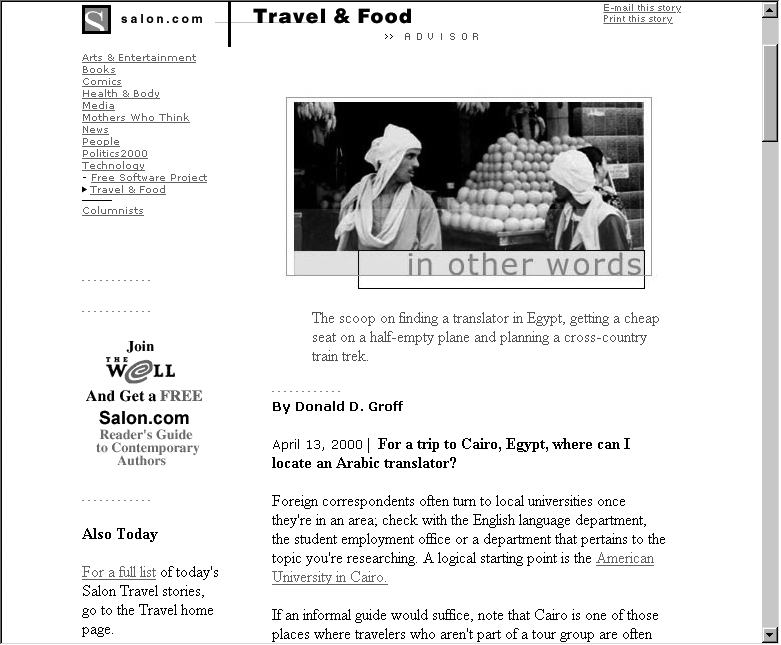
Salon’s search system allows users to take advantage of the site’s structure, supporting searches by the following content components:
Body
Title
URL
Site name
Link
Image link
Image alt text
Description
Keywords
Remote anchor text
Would users bother to search by any of these components? In Salon’s case, we could determine this by reviewing search-query logs. But what about in the case of a search system that hadn’t yet been implemented? Prior to designing a search system, could we know that users would take advantage of this specialized functionality?
This question leads to a difficult paradox: even if users would benefit from such souped-up search functionality, they likely won’t ever ask for it during initial user research. Typically users don’t have much understanding of the intricacies and capabilities of search systems. Developing use cases and scenarios might unearth some reasons to support this level of detailed search functionality, but it might be better to instead examine other search interfaces that your site’s users find valuable, and determine whether to provide a similar type of functionality.
There is another reason to exploit a document’s structure. Content components aren’t useful only for enabling more precise searches; they can also make the format of search results much more meaningful. In Figure 8-6, Salon’s search results include category and document titles (“Salon Travel | In other words”), description (“The scoop on finding a translator in Egypt...”), and URL. Indexing numerous content components for retrieval provides added flexibility in how you design search results. (See the later section “Presenting Results.”)

Search Algorithms
Search engines find information in many ways. In fact, there are about 40 different retrieval algorithms alone, most of which have been around for decades. We’re not going to cover them all here; if you’d like to learn more, read any of the standard texts on information retrieval.[1]
We bring up the topic because it’s important to realize that a retrieval algorithm is essentially a tool, and just like other tools, specific algorithms help solve specific problems. And as retrieval algorithms are at the heart of search engines, it’s important to note that there is absolutely no single search engine that will meet all of your users’ information needs. Remember that fact the next time you hear a search engine vendor claim that his product’s brand-new proprietary algorithm is the solution to all information problems.
Pattern-Matching Algorithms
Most retrieval algorithms employ pattern matching; that is, they compare the user’s query with an index of, typically, the full texts of your site’s documents, looking for the same string of text. When a matching string is found, the source document is added to the retrieval set. So a user types the textual query “electric guitar,” and documents that include the text string “electric guitar” are retrieved. It all sounds quite simple. But this matching process can work in many different ways to produce different results.
Recall and precision
Some algorithms return numerous results of varying relevance, while some return just a few high quality results. The terms for these opposite ends of the spectrum are recall and precision. There are even formulas for calculating them (note the difference in the denominators):
| Recall = # relevant documents retrieved / # relevant documents in collection |
| Precision = # relevant documents retrieved / # total documents in collection |
Are your site’s users doing legal research, learning about the current state of scientific research in a field, or performing due diligence about an acquisition? In these cases, they’ll want high recall. Each of the hundreds or thousands (or more?) results retrieved will have some relevance to the user’s search, although perhaps not very much. As an example, if a user is “ego-surfing,” she wants to see every mention of her name—she is hoping for high recall. The problem, of course, is that along with good results come plenty of irrelevant ones.
On the other hand, if she’s looking for two or three really good articles on how to get stains out of a wool carpet, then she’s hoping for high-precision results. It doesn’t matter how many relevant articles there are if you get a good enough answer right away.
Wouldn’t it be nice to have both recall and precision at the same time? Lots and lots of very high-quality results? Sadly, you can’t have your cake and eat it, too: recall and precision are inversely related. You’ll need to decide what balance of the two will be most beneficial to your users. You can then select a search engine with an algorithm biased toward either recall or precision or, in some cases, you can configure an engine to accommodate one or the other.
For example, a search tool might provide automatic stemming, which expands a term to include other terms that share the same root (or stem). If the stemming mechanism is very strong, it might treat the search term “computer” as sharing the same root (“comput”) as “computers,” “computation,” “computational,” and “computing.” Strong stemming in effect expands the user’s query by searching for documents that include any of those terms. This enhanced query will retrieve more related documents, meaning higher recall.
Conversely, no stemming means the query “computer” retrieves only documents with the term “computer” and ignores other variants. Weak stemming might expand the query only to include plurals, retrieving documents that include “computer” or “computers.” With weak stemming or no stemming, precision is higher and recall is lower. Which way should you go with your search system—high recall or high precision? The answer depends on what kinds of information needs your users have.
Another consideration is how structured the content is. Are there fields, rendered in HTML or XML or perhaps in a document record, that the search engine can “see” and therefore search? If so, searching for “William Faulkner” in the author field will result in higher precision, assuming we’re looking for books authored by Faulkner. Otherwise, we’re left with searching the full text of each document and finding results where “William Faulkner” may be mentioned, whether or not he was the author.
Other Approaches
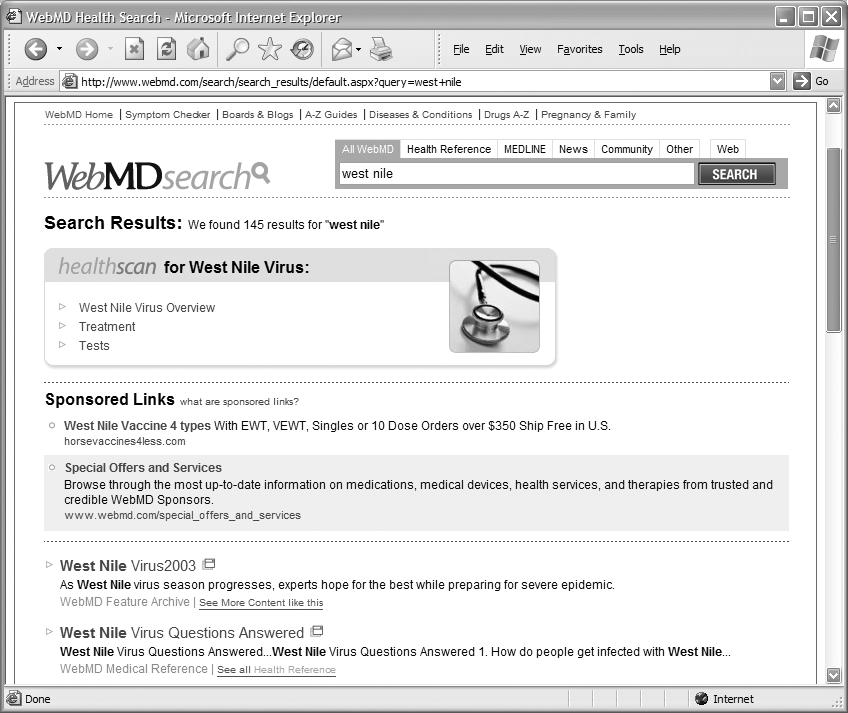
When you already have a “good” document on hand, some algorithms will convert that document into the equivalent of a query (this approach is typically known as document similarity). “Stop words,” like “the,” “is,” and “he” are stripped out of the good document, leaving a useful set of semantically rich terms that, ideally, represent the document well. These terms are then converted into a query that should retrieve similar results. An alternative approach is to present results that have been indexed with similar metadata. In Figure 8-7, the first of WebMD’s results for a search on “West Nile” is complemented by a link to “See More Content like this.”
Approaches such as collaborative filtering and citation searching go even further to help expand results from a single relevant document. In the following example from CiteSeer (see Figure 8-8), we’ve identified an article that we like: “Application Fault Level Tolerance in Heterogeneous Networks of Workstations.” Research Index automatically finds documents in a number of ways.
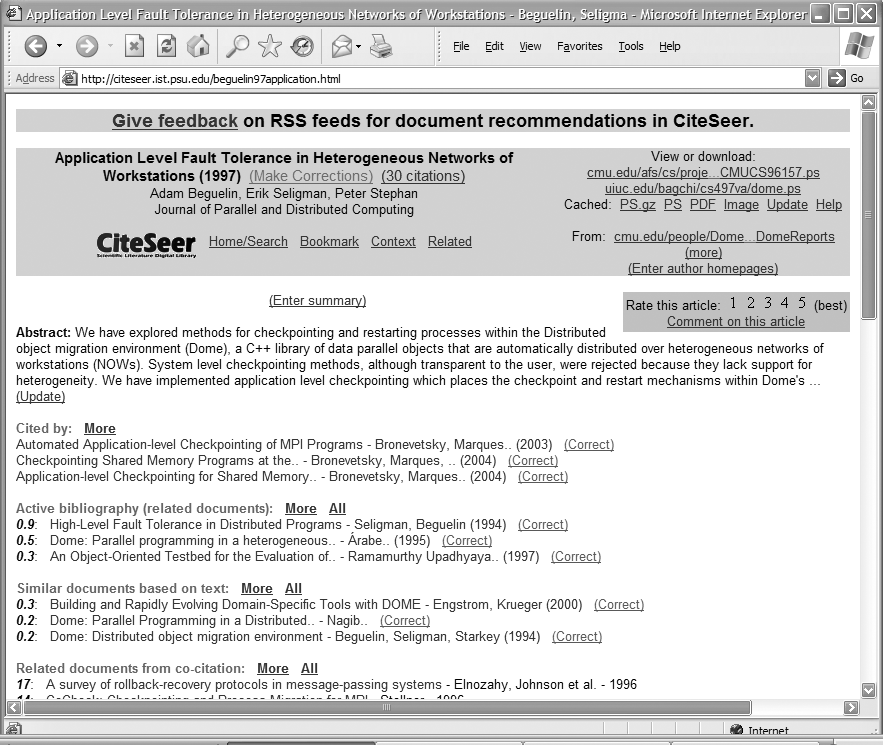
- Cited by
What other papers cite this one? The relationship between cited and citing papers implies some degree of mutual relevance. Perhaps the authors even know each other.
- Active bibliography (related documents)
Conversely, this paper cites others in its own bibliography, implying a similar type of shared relevance.
- Similar documents based on text
Documents are converted into queries automatically and are used to find similar documents.
- Related documents from co-citation
Another twist on citation, co-citation assumes that if documents appear together in the bibliographies of other papers, they probably have something in common.
There are other retrieval algorithms, more than we can cover here. What’s most important is to remember that the main purpose of these algorithms is to identify the best pool of documents to be presented as search results. But “best” is subjective, and you’ll need to have a good grasp of what users hope to find when they’re searching your site. Once you have a sense of what they wish to retrieve, begin your quest for a search tool with a retrieval algorithm that might address your users’ information needs.
Query Builders
Besides search algorithms themselves, there are many other means of affecting the outcome of a search. Query builders are tools that can soup up a query’s performance. They are often invisible to users, who may not understand their value or how to use them. Common examples include:
- Spell-checkers
These allow users to misspell terms and still retrieve the right results by automatically correcting search terms. For example, “accomodation” would be treated as “accommodation,” ensuring retrieval of results that contain the correct term.
- Phonetic tools
Phonetic tools (the best-known of which is “Soundex”) are especially useful when searching for a name. They can expand a query on “Smith” to include results with the term “Smyth.”
- Stemming tools
Stemming tools allow users to enter a term (e.g., “lodge”) and retrieve documents that contain variant terms with the same stem (e.g., “lodging”, “lodger”).
- Natural language processing tools
These can examine the syntactic nature of a query—for example, is it a “how to” question or a “who is” question?—and use that knowledge to narrow retrieval.
- Controlled vocabularies and thesauri
Covered in detail in Chapter 9, these tools expand the semantic nature of a query by automatically including synonyms within the query.
Spell-checkers correct for an almost universal problem among searchers and are well worth considering for your search system. (Look over your site’s search logs, and you’ll be amazed by the preponderance of typos and misspellings in search queries.) The other query builders have their pros and cons, addressing different information needs in different situations. Once again, a sense of your users’ information needs will help you select which approaches make the most sense for you; additionally, keep in mind that your search engine may or may not support these query builders.
Presenting Results
What happens after your search engine has assembled the results to display? There are many ways to present results, so once again you’ll need to make some choices. And as usual, the mysterious art of understanding your site’s content and how users want to use it should drive your selection process.
When you are configuring the way your search engine displays results, there are two main issues to consider: which content components to display for each retrieved document, and how to list or group those results.
Which Content Components to Display
A very simple guideline is to display less information to users who know what they’re looking for, and more information to users who aren’t sure what they want. A variant on that approach is to show users who are clear on what they’re looking for only representational content components, such as a title or author, to help them quickly distinguish the result they’re seeking. Users who aren’t as certain of what they’re looking for will benefit from descriptive content components such as a summary, part of an abstract, or keywords to get a sense of what their search results are about. You can also provide users some choice of what to display; again, consider your users’ most common information needs before setting a default. Figures 8-9 and 8-10 show a site that provides both options to users.

When it’s hard to distinguish retrieved documents because of a commonly displayed field (such as the title), show more information, such as a page number, to help the user differentiate between results.
Another take on the same concept is shown in Figure 8-11, which displays three versions of the same book. Some of the distinctions are meaningful; you’ll want to know which library has a copy available. Some aren’t so helpful; you might not care who the publisher is.

How much information to display per result is also a function of how large a typical result set is. Perhaps your site is fairly small, or most users’ queries are so specific that they retrieve only a small number of results. If you think that users would like more information in such cases, then it may be worth displaying more content components per result. But keep in mind that regardless of how many ways you indicate that there are more results than fit on one screen, many (if not most) users will never venture past that first screen. So don’t go overboard with providing lots of content per result, as the first few results may obscure the rest of the retrieval.
Which content components you display for each result also depends on which components are available in each document (i.e., how your content is structured) and on how the content will be used. Users of phone directories, for example, want phone numbers first and foremost. So it makes sense to show them the information from the phone number field in the result itself, as opposed to forcing them to click through to another document to find this information (see Figure 8-12).
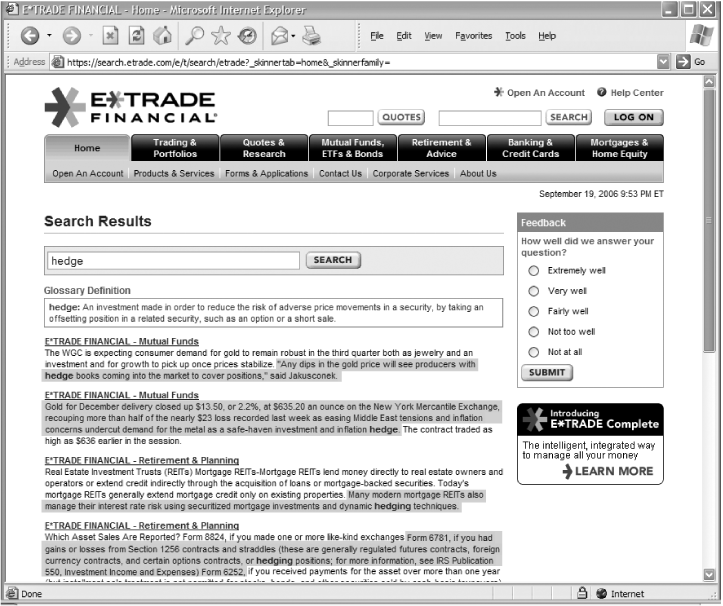
If you don’t have much structure to draw from or if your engine is searching full text, showing the query terms within the “context” of the document’s text is a useful variation on this theme (see Figure 8-13). In this example, E*Trade displays the query terms in bold—an excellent practice, as it helps the user quickly scan the results page for the relevant part of each result. E*Trade further augments this useful context by highlighting the surrounding sentence.
How Many Documents to Display
How many documents are displayed depends mostly on two factors. If your engine is configured to display a lot of information for each retrieved document, you’ll want to consider having a smaller retrieval set, and vice versa. Additionally, a user’s monitor resolution, connectivity speed, and browser settings will affect the number of results that can be displayed effectively. It may be safest to err toward simplicity—by showing a small number of results—while providing a variety of settings that the user can select based on his own needs.
We do suggest that you let users know the total number of retrieved documents so they have a sense of how many documents remain as they sift through search results. Also consider providing a results navigation system to help them move through their results. In Figure 8-14, ICON Advisers provides such a navigation system, displaying the total number of results and enabling users to move through the result set 10 at a time.
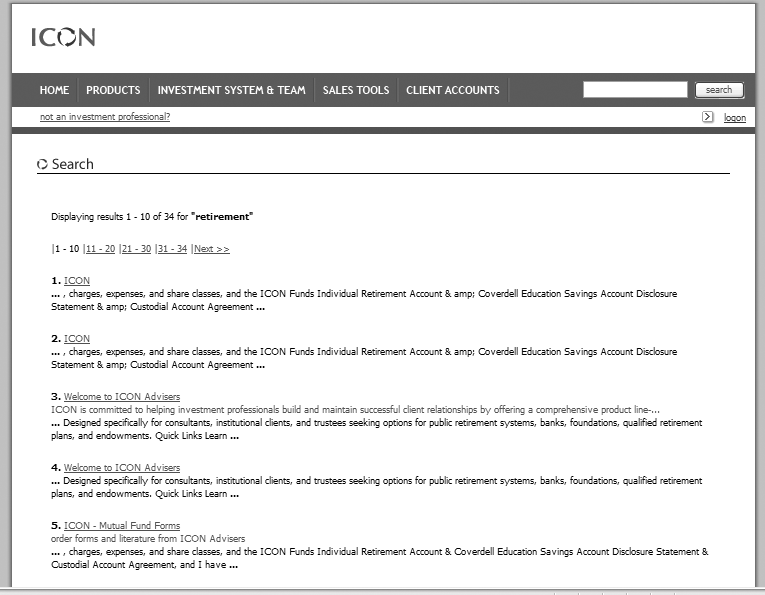
In many cases, the moment a user is confronted by a large result set is the moment he decides the number of results is too large. This is a golden opportunity to provide the user with the option of revising and narrowing his search. ICON Advisers could achieve this quite simply by repeating the query “retirement” in the search box in the upper right.
Listing Results
Now that you have a group of search results and a sense of which content components you wish to display for each, in what order should these results be listed? Again, much of the answer depends upon what kind of information needs your users start with, what sort of results they are hoping to receive, and how they would like to use the results.
There are two common methods for listing retrieval results: sorting and ranking. Retrieval results can be sorted chronologically by date, or alphabetically by any number of content component types (e.g., by title, by author, or by department). They can also be ranked by a retrieval algorithm (e.g., by relevance or popularity).
Sorting is especially helpful to users who are looking to make a decision or take an action. For example, users who are comparing a list of products might want to sort by price or another feature to help them make their choice. Any content component can be used for sorting, but it’s sensible to provide users with the option to sort on components that will actually help them accomplish tasks. Which ones are task-oriented and which aren’t, of course, depends upon each unique situation.
Ranking is more useful when there is a need to understand information or learn something. Ranking is typically used to describe retrieved documents’ relevance, from most to least. Users look to learn from those documents that are most relevant. Of course, as we shall see, relevance is relative, and you should choose relevance ranking approaches carefully. Users will generally assume that the top few results are best.
The following sections provide examples of both sorting and ranking, as well as some ideas on what might make the most sense for your users.
Sorting by alphabet
Just about any content component can be sorted alphabetically (see Figure 8-15). Alphabetical sorts are a good general-purpose sorting approach—especially when sorting names—and in any case, it’s a good bet that most users are familiar with the order of the alphabet! It works best to omit initial articles such as “a” and “the” from the sort order (certain search engines provide this option); users are more likely to look for “The Naked Bungee Jumping Guide” under “N” rather than “T.”
Sorting by chronology
If your content (or your user) is time-sensitive, chronological sorts are a useful approach. And you can often draw from a filesystem’s built-in dating if you have no other sources of date information.
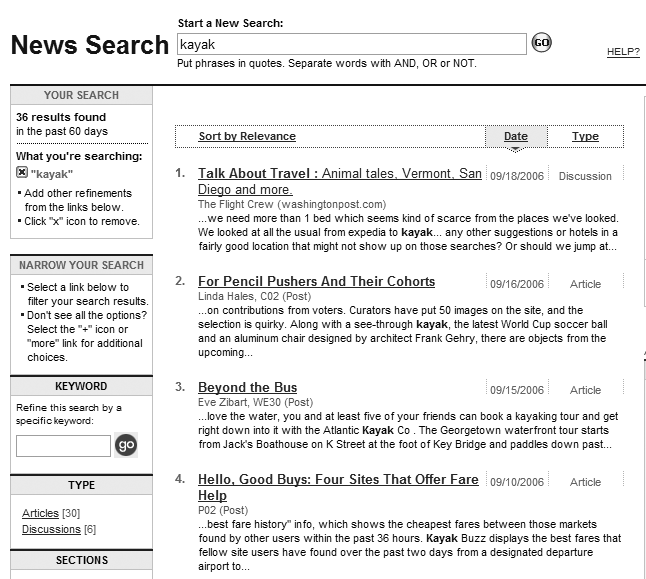
If your site provides access to press releases or other news-oriented information, sorting by reverse chronological order makes good sense (see Figures 8-16 and 8-17). Chronological order is less common and can be useful for presenting historical data.
Ranking by relevance
Relevance-ranking algorithms (there are many flavors) are typically determined by one or more of the following:
How many of the query’s terms occur in the retrieved document
How frequently those terms occur in that document
How close together those terms occur (e.g., are they adjacent, in the same sentence, or in the same paragraph?)
Where the terms occur (e.g., a document with the query term in its title may be more relevant than one with the query term in its body)
The popularity of the document where the query terms appear (e.g., is it linked to frequently, and are the sources of its links themselves popular?)
Different relevance-ranking approaches make sense for different types of content, but with most search engines, the content you’re searching is apples and oranges. So, for example, Document A might be ranked higher than Document B, but Document B is definitely more relevant. Why? Because while Document B is a bibliographic citation to a really relevant work, Document A is a long document that just happens to contain many instances of the terms in the search query. So the more heterogeneous your documents are, the more careful you’ll need to be with relevance ranking.
Indexing by humans is another means of establishing relevance. Keyword and descriptor fields can be searched, leveraging the value judgments of human indexers. For example, manually selected recommendations—popularly known as “Best Bets”—can be returned as relevant results. In Figure 8-18, the first set of results was associated with the query “monty python” in advance.
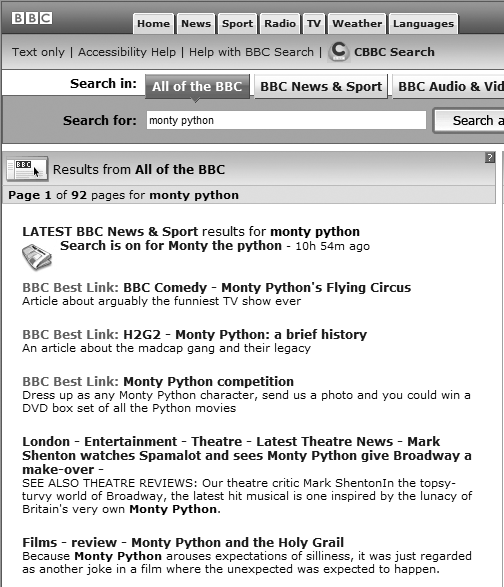
Requiring an investment of human expertise and time, the Best Bets approach isn’t trivial to implement and therefore isn’t necessarily suitable to be developed for each and every user query. Instead, recommendations are typically used for the most common queries (as determined by search-log analysis) and combined with automatically generated search results.
There are other concerns with relevance ranking. It’s tempting to display relevance scores alongside results; after all, those scores are what’s behind the order of the results. In Figure 8-19, we searched for “storage” at Computer Associates’ web site.
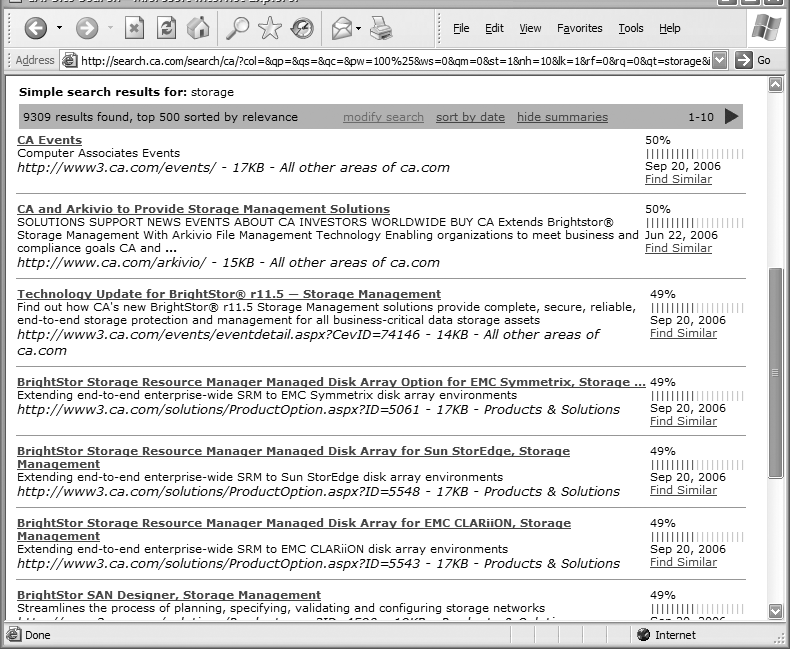
The first result does seem quite promising. But what exactly is the difference between a document with a relevance score of 50 percent and one with 49 percent? They are scored similarly, but the top result is CA’s events calendar—which covers CA events. Interestingly, the events calendar doesn’t even mention “storage.” Other results are a bit more relevant, but this is an excellent illustration of how relevancy algorithms do strange and complicated things behind the scenes. We don’t really know why the results are ranked this way. Showing scores only aggravates that sense of ignorance, so these should be used with caution; leaving out scores altogether is often a better approach.
Ranking by popularity
Popularity is the source of Google’s popularity.
Put another way, Google is successful in large part because it ranks results by which ones are the most popular. It does so by factoring in how many links there are to a retrieved document. Google also distinguishes the quality of these links: a link from a site that itself receives many links is worth more than a link from a little-known site (this algorithm is known as PageRank).
There are other ways to determine popularity, but keep in mind that small sites or collections of separate, nonlinked sites (often referred to as “silos”) don’t necessarily take advantage of popularity as well as large, multisite environments with many users. The latter have a wide scope of usage and a richer set of links. A smaller site isn’t likely to have enough variation in the popularity of different documents to merit this approach, while in a “silo” environment, little cross-pollination results in few links between sites. It’s also worth noting that, to calculate relevance, Google uses over 100 other criteria in addition to PageRank.
Ranking by users’ or experts’ ratings
In an increasing number of situations, users are willing to rate the value of information. User ratings can be used as the basis of retrieval result ordering. In the case of Digg (see Figure 8-20), these ratings—based on Digg users’ votes on the pages submitted by other Digg users—are integral to helping users judge the value of an item, and form the foundation of an entire information economy. Of course, Digg has a lot of users who don’t shrink from expressing their opinions, so there is a rich collection of judgments to draw on for ranking.
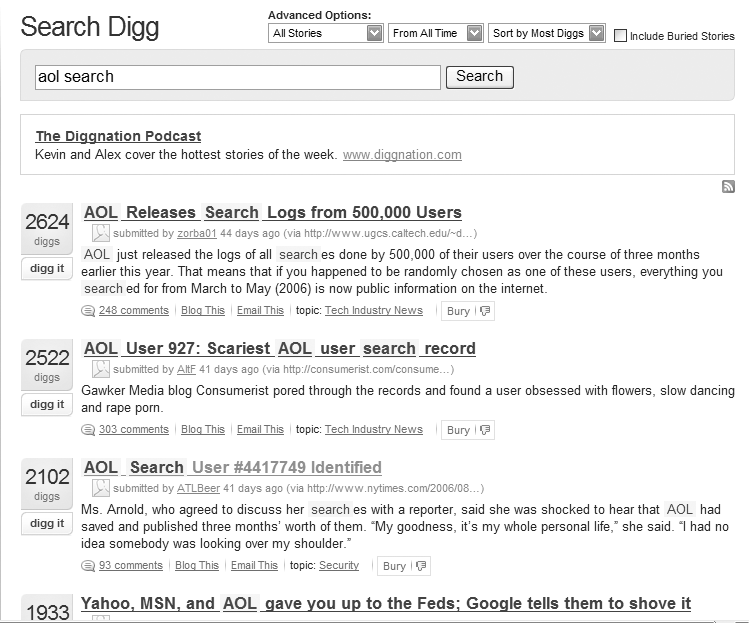
Most sites don’t have a sufficient volume of motivated users to employ valuable user ratings. However, if you have the opportunity to use it, it can be helpful to display user ratings with a document, if not as part of a presentation algorithm.
Ranking by pay-for-placement
As banner-ad sales are no longer the most viable economic model, pay-for-placement (PFP) is becoming increasingly common to web-wide searching. Different sites bid for the right to be ranked high, or higher, on users’ result lists. Yahoo! Search Marketing (Figure 8-21) is one of the most popular sites to take this approach.
If your site aggregates content from a number of different vendors, you might consider implementing PFP to present search results. Or if users are shopping, they might appreciate this approach—with the assumption that the most stable, successful sites are the ones that can afford the highest placement. This is somewhat like selecting the plumber with the largest advertisement in the yellow pages to fix your toilet.
Grouping Results
Despite all the ways we can list results, no single approach is perfect. Hybrid approaches like Google’s show a lot of promise, but you typically need to be in the business of creating search engines to have this level of involvement with a tool. In any case, our sites are typically getting larger, not smaller. Search result sets will accordingly get larger as well, and so will the probability that those ideal results will be buried far beyond the point where users give up looking.
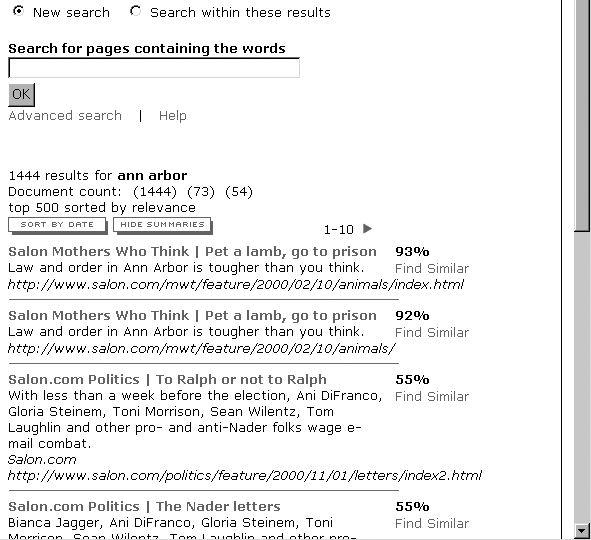
However, one alternative approach to sorting and ranking holds promise: clustering retrieved results by some common aspect. An excellent study[2] by researchers at Microsoft and the University of California at Berkeley show improved performance when results are clustered by category as well as by a ranked list. How can we cluster results? The obvious ways are, unfortunately, the least useful: we can use existing metadata, like document type (e.g., .doc, .pdf) and file creation/modification date, to allow us to divide search results into clusters. Much more useful are clusters derived from manually applied metadata, like topic, audience, language and product family. Unfortunately, approaches based on manual effort can be prohibitively expensive.
Some automated tools are getting better at approximating the more useful topical types of clustering that often serve users best. In Figures 8-22 and 8-23, Clusty and WiseNut contextualize the query “RFID” with such topics as “Privacy,” “Barcode,” and “RFID implementation.”
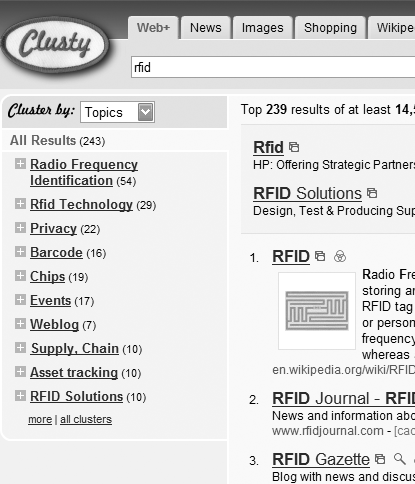
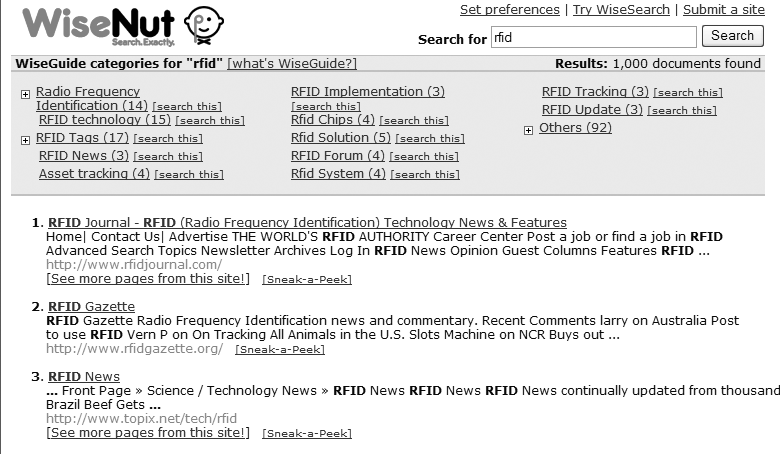
These clusters provide context for search results; by selecting the category that seems to fit your interest best, you’re working with a significantly smaller retrieval set and (ideally) a set of documents that come from the same topical domain. This approach is much like generating search zones on the fly.
Exporting Results
You’ve provided users with a set of search results. What happens next? Certainly, they could continue to search, revising their query and their idea of what they’re looking for along the way. Or, heavens, they might have found what they’re looking for and are ready to move on. Contextual inquiry and task-analysis techniques will help you understand what users might want to do with their results. The following sections discuss a few common options.
Printing, emailing, or saving results
The user has finally reached his destination. He could bookmark the result, but he likely doesn’t want to return to this document where it lives on the site. Instead, he wants to grab it and take it with him.
Obviously he can print it, but not all documents are designed to be printed—they may sport banner ads or be crowded with navigational options. If many of your users wish to print and your content isn’t print-friendly, consider offering a “print this document” option that provides a clearer, more printable version of the document. Alternatively, users may want a digital version of the file. And as so many of us use our email programs as personal information managers, providing an “email this document” function can come in handy as well. Both functions are shown in Figure 8-24.

The New York Times also allows users to save articles for future retrieval. We wonder if many users take advantage of “Save,” as most users rely on bookmarking options that aren’t specific to a single site. The Times also provides a “reprints” option and enables users to toggle between multiple- and single-page views of the article. For the most part, these options are conceived with a good understanding of what users might want to do next, now that they’ve found an article of interest.
Select a subset of results
Sometimes you want to take more than one document along with you. You want to “shop” for documents just like you shop for books at Amazon. And if you’re sorting through dozens or hundreds of results, you may need a way to mark the documents you like so you don’t forget or lose track of them.
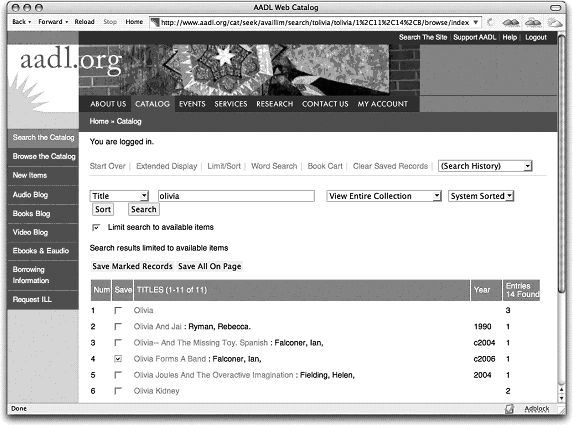
A shopping-cart feature can be quite useful in search-intensive environments such as a library catalog. In Figures 8-25 and 8-26, users can “save” a subset of their retrieval and then manipulate them in a “shopping basket” once they’re done searching.

Save a search
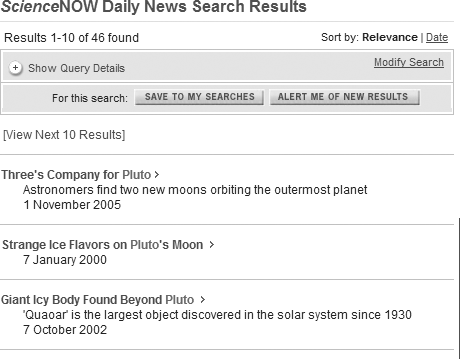
In some cases it’s the search itself, not the results, that you’re interested in “keeping.” Saved searches are especially useful in dynamic domains that you’d like to track over time; you can manually re-execute a saved search on a regular basis, or schedule that query to automatically be rerun regularly. Some search tools, like that of Science Magazine’s ScienceNOW service, allow both, as shown in Figure 8-27.
As search results become more “portable”—allowing users to access them without visiting the originating search system’s site—they can be syndicated using RSS or Atom. For example, you can save and automatically re-execute a search in Google using the Google Alerts service, shown in Figure 8-28, and the results of your saved query can be monitored via an RSS or Atom feed (as well as by email).

Designing the Search Interface
All the factors we’ve discussed so far—what to search, what to retrieve, and how to present the results—come together in the search interface. And with so much variation among users and search-technology functions, there can be no single ideal search interface. Although the literature of information retrieval includes many studies of search interface design, many variables preclude the emergence of a “right way” to design search interfaces. Here are a few of the variables on the table:
- Level of searching expertise and motivation
Are users comfortable with specialized query languages (e.g., Boolean operators), or do they prefer natural language? Do they need a simple or a high-powered interface? Do they want to work hard to make their search a success, or are they happy with “good enough” results? How many iterations are they willing to try?
- Type of information need
Do users want just a taste, or are they doing comprehensive research? What content components can help them make good decisions about clicking through to a document? Should the results be brief, or should they provide extensive detail for each document? And how detailed a query are users willing to provide to express their needs?
- Type of information being searched
Is the information made up of structured fields or full text? Is it navigation pages, destination pages, or both? Is it written in HTML or other formats, including nontextual? Is the content dynamic or more static? Does it come tagged with metadata, full of fields, or is it full text?
- Amount of information being searched
Will users be overwhelmed by the number of documents retrieved? How many results is the “right number”? That’s a lot to consider. Luckily, we can provide basic advice that you should consider when designing a search interface.
In the early days of the Web, many search engines emulated the functionality of the “traditional” search engines used for online library catalogs and CD ROM-based databases, or were ported directly from those environments. These traditional systems were often designed for researchers, librarians, and others who had some knowledge of and incentive for expressing their information needs in complex query languages. Therefore, many search systems at the time allowed the user to use Boolean operators, search fields, and so forth; in fact, users were often required to know and use these complex languages.
As the Web’s user base exploded, overall searching experience and expertise bottomed out, and the new breed of user wasn’t especially patient. Users more typically just entered a term or two without any operators, pressed the “search” button, and hoped for the best.
The reaction of search engine developers was to bury the old fancy tricks in “advanced search” interfaces, or to make them invisible to users by building advanced functionality directly into the search engine. For example, Google makes a set of assumptions about what kind of results users want (through a relevance algorithm) and how they’d like those results presented (using a popularity algorithm). Google makes some good assumptions for web-wide searching, and that’s why it’s successful. However, most search systems, web-wide or local, don’t work as well.
For that reason, the pendulum may eventually swing back to supporting users who, out of frustration, have become more search-literate and are willing to spend more time learning a complex search interface and constructing a query. But for now, it’s fair to assume that, unless your site’s users are librarians, researchers, or specialized professionals (e.g., an attorney performing a patent search), they won’t invest much time or effort into crafting well-considered queries. That means the burden of searching falls chiefly on the search engine, its interfaces, and how content is tagged and indexed; therefore, it’s best to keep your search interface as simple as possible: present users with a simple search box and a “search” button.
The Box
Your site is likely to have the ubiquitous search box, as shown in Figure 8-29.
Simple and clear. Type in some keywords (“directions Somers”) or a natural language expression (“What are the directions to the Somers offices?”), hit the “search” button, and the whole site will be searched and results are displayed.
Users make assumptions about how search interfaces work, and you may want to test for those as you design your own search system. Some common user assumptions include:
“I can just type terms that describe what I’m looking for and the search engine will do the rest.”
“I don’t have to type in those funny AND, OR, or NOT thingies.”
“I don’t have to worry about synonyms for my term; if I’m looking for dogs, I just type ‘dogs,’ not ‘canine’ or ‘canines.’”
“Fielded searching? I don’t have time to learn which fields I can search.”
“My query will search the entire site.”
If your users have those assumptions and are not especially motivated to learn more about how your site’s search works differently, then go with the flow. Give them the box. You certainly could provide a “help” page that explains how to create more advanced, precise queries, but users may rarely visit this page.
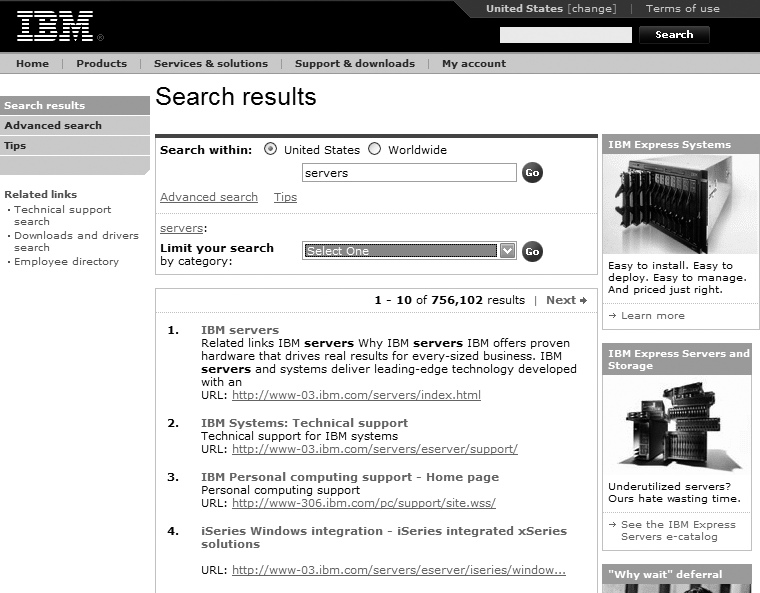
Instead, look for opportunities to educate users when they’re ready to learn. The best time to do this is after the initial search has been executed and the user reaches a point of indecision or frustration. The initial hope that the first try would retrieve exactly what they were looking for has now faded. And when users are ready to revise their searches, they’ll want to know how they can make those revisions. For example, if you search IBM’s site for “servers” (see Figure 8-30), you’ll likely get a few more results than you’d like.
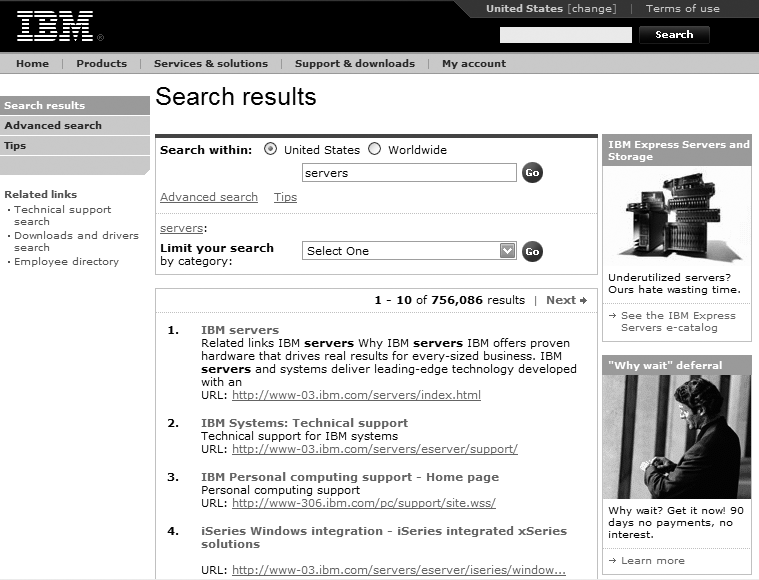
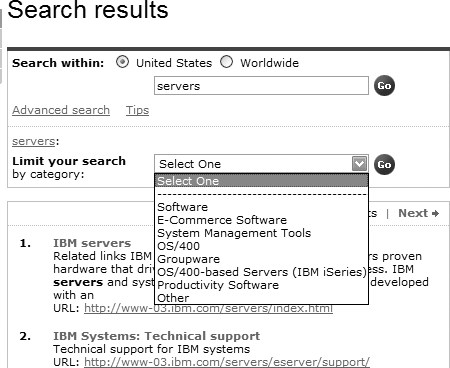
At this point, IBM’s search system goes beyond the box: it tells the user something to the effect of “Here are those 729,288 results that you asked for. Perhaps this is too many? If that’s the case, consider revising your search using our souped-up ‘advanced search’ interface, which allows you to narrow your search, as shown in Figure 8-31. Or learn how to search our site better from our ‘tips’ page.” Or, select from a list of categories (really search zones) to narrow your results further.
In general, too many or too few (typically zero) search results are both good indicators for users to revise their searches; we’ll cover more on this topic in the section “Supporting Revision” later in this chapter.
The box can cause confusion when it occurs alongside other boxes. Figure 8-32 shows a main page with many boxes, all of which come with the same “go” button, regardless of functionality. It’s a good bet that users won’t read the nice labels next to each box and will instead do all sorts of confounding things, like typing their search queries in the “password” box, not to mention URLs in the “search” box. (Search logs regularly turn up such “box bloopers.”)

A better approach is to place the search box nearer to the site-wide navigation system at the top of the page and relabel its “go” button as “search.” The other boxes could be made less prominent on the page or moved somewhere else altogether. Consistent placement of the search box alongside other site-wide navigation choices on every page in the site, along with the consistent use of a button labeled “search” that comes with that box, will go a long way toward ensuring that users at least know where to type their queries.
In Figure 8-33, the three search boxes could be reduced to one that searches a combined index of articles, comments, and users. This would save space and demand less of the user. The distinctions between the three types of search zones could always show up (and be made selectable) in a pull-down menu or advanced search interface.
Clearly, there are many assumptions behind that innocuous little search box, some made on the part of the user, and some by the information architect who decides what functionality will be hidden behind that box. Determining what your users’ assumptions are should drive the default settings that you set up when designing the simple search interface.
Advanced Search: Just Say No
Advanced search interfaces are where much of the search system’s functionality is “unveiled” to users. In stark contrast to The Box, advanced search interfaces allow much more manipulation of the search system and are typically used by two types of users: advanced searchers (librarians, lawyers, doctoral students, medical researchers), and frustrated searchers who need to revise their initial search (often users who found that The Box didn’t meet their needs).
Often, you find everything and the kitchen sink thoughtlessly stuffed into advanced search interfaces. Fielded searching, date ranges, search-zone selection, and specialized query languages all crop up here. In fact, these can often crowd the interface and make it difficult for users to know what to do. Gartner’s advanced search interface, shown in Figure 8-34, for example, doesn’t even fit on one page.
We won’t cover these functions in this chapter because we’ve found that, contrary to our original assumptions, few users ever take advantage of them. Therefore, because few users will ever visit your advanced search page, we don’t recommend investing much effort into its design. You’re better off looking for ways to enable users to revise when they need to—in other words, in the appropriate context. More on that below.
As for advanced search, it can’t be completely ignored, unfortunately. It is something of a convention, and many users will expect to see it. Perhaps a good rule of thumb is to unearth your search engine’s various heavy-duty search functions on the advanced page for those few users who want to have a go at them, but design your search system with the goal of making it unnecessary for the vast majority of searchers to ever need to go to the advanced search page.
Supporting Revision
We’ve touched on what can happen after the user finds what she’s looking for and the search is done. But all too often that’s not the case. Here are some guidelines to help the user hone her search (and hopefully learn a little bit about your site’s search system in the process).
Repeat search in results page
What was it I was looking for? Sometimes users are forgetful, especially after sifting through dozens of results. Displaying the initial search within the search box (as in Figure 8-35) can be quite useful: it restates the search that was just executed, and allows the user to modify it without re-entering it.
Explain where results come from
It’s useful to make clear what content was searched, especially if your search system supports multiple search zones (see Figure 8-36). This reminder can be handy if the user decides to broaden or narrow her search; more or fewer search zones can be used in a revised search.
Explain what the user did
If the results of a search are not satisfactory, it can be useful to state what happened behind the scenes, providing the user with a better understanding of the situation and a jumping-off point should she wish to revise her search.
“What happened” can include the two guidelines just mentioned, as well as:
Restate the query
Describe what content was searched
Describe any filters that might be in place (e.g., date ranges)
Show implicit Boolean or other operators, such as a default AND
Show other current settings, such as the sort order
Mention the number of results retrieved
In Figure 8-37, the New York Times site provides an excellent example of explaining to the user what just happened.
Integrate searching with browsing
A key theme in this book is the need to integrate searching and browsing (think of them together as “finding”), but we won’t belabor it here. Just remember to look for opportunities to connect your search and browse systems to allow users to easily jump back and forth.
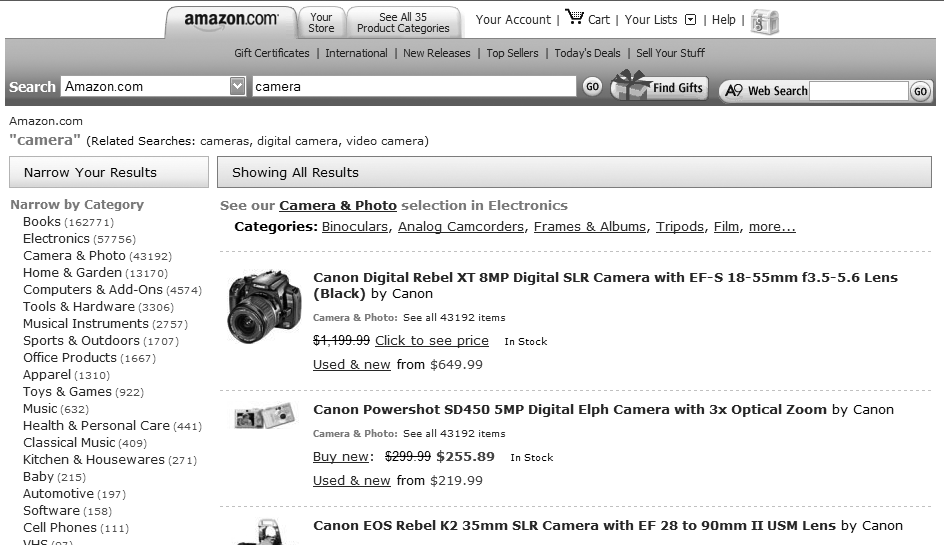
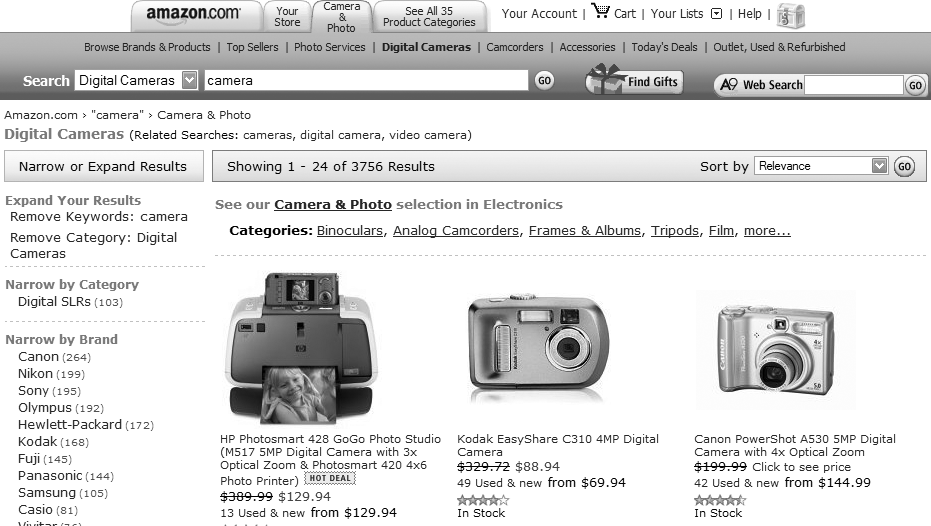
In Figures 8-38 and 8-39, Amazon.com provides this functionality in both directions.
When Users Get Stuck
You can strive to support iterative searching with fully integrated browsing and state-of-the-art retrieval and presentation algorithms, yet users still will fail time and time again. What should you do when presenting the user with zero results, or with way too many?
The latter case is a bit easier to address, because in most cases your search engine provides relevance ranked results. In effect, winnowing oversized result sets is a form of search revision, and often the user will self-select when he is ready to stop reviewing results. But it is still useful to provide some instruction on how to narrow search results, as shown in Figure 8-40.
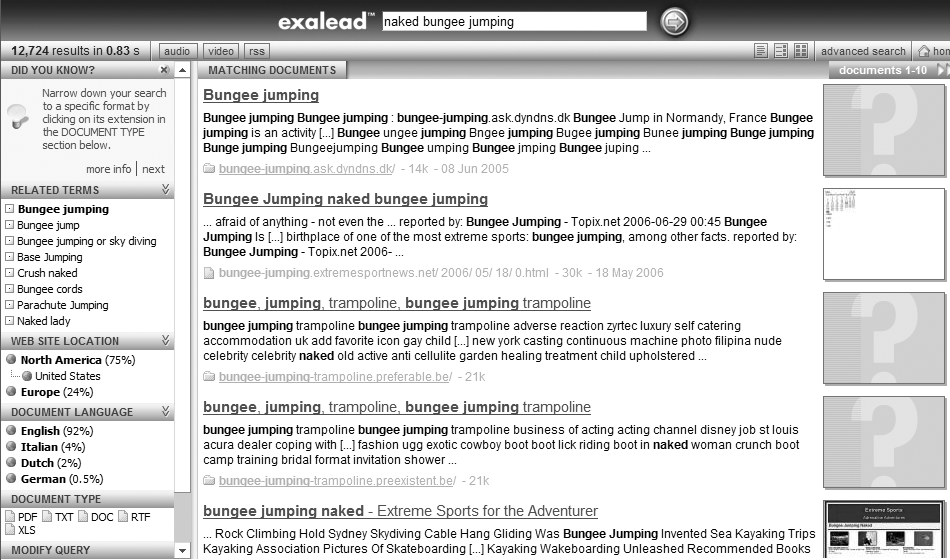
You can also help users narrow their results by allowing them to search within their current result set. In Figure 8-41, the initial search for “naked bungee jumping” retrieved over 9,000 documents; we can “search within these results” for “figure skating” to narrow our retrieval.
At the other end of the spectrum, zero hits is a bit more frustrating for users and challenging for information architects. We suggest you adopt a “no dead ends” policy to address this problem. “No dead ends” simply means that users always have another option, even if they’ve retrieved zero results. The options can consist of:
A means of revising the search
Search tips or other advice on how to improve the search
A means of browsing (e.g., including the site’s navigation system or sitemap)
A human contact if searching and browsing won’t work
It’s worth noting that we’ve seen few (if any) search systems that meet all these criteria.
Where to Learn More
Although this is the longest chapter in this book, we’ve covered only the tip of the search system iceberg. If this piqued your interest, you may want to delve further into the field of information retrieval. Three of our favorite texts are:
Modern Information Retrieval by Ricardo Baeza-Yates and Berthier Ribeiro-Neto (Addison-Wesley).
Concepts of Information Retrieval by Miranda Lee Pao (Libraries Unlimited). This title is out of print, but you may be able to find used copies on Amazon.
On Search, the Series by Tim Bray, an excellent collection of essays on search written by the father of XML (http://www.tbray.org/ongoing/When/200x/2003/07/30/OnSearchTOC).
If you’re looking for more immediate and practical advice, the most useful site for learning about search tools is, naturally, Searchtools.com (http://www.searchtools.com), Avi Rappoport’s compendium of installation and configuration advice, product listings, and industry news. Another excellent source is Danny Sullivan’s Search Engine Watch (http://www.searchenginewatch.com), which focuses on web-wide searching but is quite relevant to site-wide searching nonetheless.