
7
Improvement of Computer Vision-Based Elephant Intrusion Detection System (EIDS) with Deep Learning Models
Jothibasu M.*, Sowmiya M., Harsha R., Naveen K. S. and Suriyaprakash T. B.
Department of ECE, PSG Institute of Technology and Applied Research, Coimbatore, India
Abstract
The expanding need of wild life behavior and partition of human-wild life strife has guided the researchers to the execution of counteraction and alleviation draws near. The division of boondocks grounds and separation of elephant populaces moves toward the essential driver of Human Elephant Collision (HEC). Human-elephant strife is a troublesome issue since which prompts to territory misfortune, destruction of agribusiness zones, environment misfortune. This demands an intelligent system which predicts and rest the conflict. In this work, Artificial Intelligent based device is developed to detect the presence of elephant into residential areas and provides a warning to the forest rangers. In this counterfeit intelligent gadget, the identification part comprises of the PIR sensor and seismic sensor. Both of the sensor yields trigger the camera module associated with the model created. The camera module catches a video for a specific span which may contain the nearness of the animal. At that point, the recordings are been coordinated to the trained AI algorithm. The AI algorithm forms the video in the succession of the casing and once if the presence of an elephant is available in the video, it triggers the cautioning system. An SSD, YOLO, and Faster RCNN algorithm has been accomplished to locate the ideal one. The model builds up a broad item to distinguish an economical arrangement.
Keywords: Deep learning, human elephant conflict, PIR sensor, YOLO, Faster RCNN
7.1 Introduction
In recent times our environment is influenced more regrettable because of numerous external factors. The wellspring of nourishment for creatures in the backwoods isn’t adequate as before because of ecological corruption, deforestation which drives the creatures to show up in human local locations. A few administration approaches have been rehearsed at various scales for human-elephant conflict. Elephants can be found in a variety of habitats, such as savannas, forests, deserts, and swamps. Generally, elephants were classified into two species, namely African elephants (Loxodonta africana) and Asian elephants (Elephas maximus). Under Asian elephants, Indian elephants have specific name Elephas maximus indicus. Elephants put through seasonal migration in search of food, water, and spouses. Due to over population and rapid urbanization, the need for land especially for human survival has tremendously increased. So, humans started invading forests. This leads to loss of habitat for the wildlife. The increase in the area of human settlements has resulted in the shrinkage of forests that serve as home for the elephants. Due to the loss of their habitat, the elephants may enter the human survival area that was once a natural habitat [15]. The shortage of food for elephants also leads to crop looting in the nearby farm lands. In recent times there have been several incidents of entry of elephants into residential areas. Every year many humans lose their lives due to human Elephant Conflicts and many elephants die on railway tracks after being hit by a train.
Even though many widespread avoidance techniques are available, still it provides temporary zone-specific solutions. This demands an intelligent system which predicts and rest the conflict. This system should be more efficient in detecting the presence of elephant in the area and alert the public nearby about the presence of the elephant and to perform some repulsive operations against the elephants which infringe into the residential as well as the farming areas [13, 16]. Our system is designed in such a way that once the motion is detected using a sensor, the camera is activated to capture a video of 10 seconds including the frames of object crossed. The captured video is divided into frames then fed to the Deep learning architecture which is pre trained with the images of the elephant. The Deep learning architecture forms feature maps by convolving throughout the frames of the video. The presence of elephant is predicted by classifying the feature maps based on the pre trained model and the accuracy is evaluated. If the accuracy is more and consistent throughout all the frames of the video, then the presence of elephant is confirmed. Once the presence of elephant is confirmed, the system switches over to the alerting and repulsive system which undergoes alarming and an instant message is sent to the forest officers.
7.2 Elephant Intrusion Detection System (EIDS)
7.2.1 Existing Approaches
Elephant detection method is developed using PIR and microwave radar sensors. The system contains two parts, elephant detector, and bee simulator. A bee stimulator contains a vibrating trigger was used to aggravate the bees. The elephants were extruded using the sound and sting of the bee. Wireless RF module is used for communication between the two parts. Ropes tied to a pole were used to trigger the sensor during the arrival of elephants [1].
Authors have proposed an automated unsupervised elephant intrusion detection system (EIDS) [2]. The elephant’s image is captured and processed using Haar wavelet and analyzed using image vision algorithms. A message is sent using GSM module indicating that an elephant has been detected in the forest border. Optimized distance metric concepts have been performed which retrieves more images with lesser retrieval time.
Occlusion is a major concern in the forest areas as elephants may be fully or partially hidden due to the plants, trees or any other occluding objects. Furthermore, the size and shape of elephants varies significantly which results in the inability to use shape and size as attributes [14]. Real time video input from the camera is converted into a sequence of images. These images are pre-processed to remove the distortion and noise using filters and enhance the features. The pre-processed image is further segmented to identify the region of interest (ROI), which may have elephant or otherwise. After feature extraction, SVM training is performed with a set of training images collected with two classes [3]. To emphasize the correctness of the detection of elephants in an image, further each of the image in class which contains elephant is considered and applied with color and texture features.
Elephant Intrusion system detect the elephant on the railway track and alerts the driver that the elephant is on the track. The transmitter and receiver start to communicate once the train starts to move, this communication take place only at the moment of the train. Here, prototype model for real-time elephant intrusion is developed and a design model to spot the elephant intrusion. The system automatically sends a SMS through GSM to the driver if an elephant is detected. Image processing techniques are used to detect whether the object detected is elephant or not [4].
A detection system using deep architectures [5] is developed for animal detection. The system used algorithms such as support vector machine (SVM), k-nearest neighbor (KNN) and ensemble tree for classification. The detection model provided an accuracy of 91.4% on standard camera-trap dataset.
7.2.2 Challenges
The real time detection of the elephant in the forest prone areas is a challenging task. The elephant in the forest may be closer or far from the camera so that when the camera is triggered to take the video, the image of the elephant in the video may differ in size when it moves far and near the camera. So, the same elephant may appear at different sizes in the same video which may lead to false detection. To solve this issue, we use deep learning architecture where the object at different scales and different aspect ratios are detected and there may be no chance for false detection.
Another issue is that, the elephants may enter the residential areas during night times, so that the quality of the captured video may be not clear which may also lead to false detection [6, 12]. As we use Pre trained Deep learning Architecture which is trained with plenty of elephant’s images which includes Gray scale, RGB images. So, that the system may perfectly predict the presence of elephant even in the average quality video of the camera.
Time taken for prediction and classification of elephant in the video is another aspect which should be considered [8]. The algorithms used in this system are more time efficient as they predict and classify the object in the video within a second. Processing time is faster and the delay in the system has been reduced.
7.3 Theoretical Framework
7.3.1 Deep Learning Models for EIDS
Deep learning is a subset of machine learning which uses neural networks to learn and perform operations, whereas machine learning is a subset of Artificial intelligence which learns from data and improves the system by experience. In EIDS, we used deep learning methods like Faster RCNN, SSD, YOLO to detect elephants from the surveillance areas. Figure 7.1 signifies the relation between AI, ML and DL.
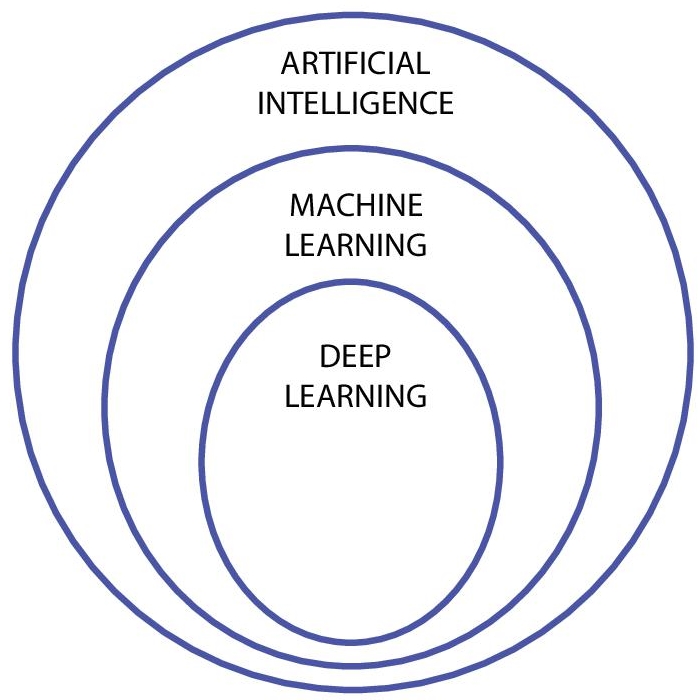
Figure 7.1 Relation between AI, ML, and DL.
7.3.1.1 Fast RCNN
Fast RCNN is one of the Object detection algorithms which takes input of image and feed the image to the CNN, which in turn generates the convolutional feature maps. The feature map generation is same as that of the Faster RCNN algorithm. Using these maps, the regions of proposals are extracted. The region proposals are extracted using the selective search method where the regions are proposed based on the texture, color, size, and shape compatibility. We then use a RoI pooling layer to reshape all the proposed regions and it can be fed into a fully connected network. A SoftMax layer and linear regression layer is used in this algorithm which classifies and bounds the object in the given input image. Since the Fast RCNN uses the selective search algorithm for region proposals, it takes nearly 2 seconds to detect the object in the given frame.
7.3.1.2 Faster RCNN
Faster RCNN is the efficient object detection algorithms which uses the Region proposal Networks to localize the object in the frame and classifies the object, thereby reducing the time consumption for processing the frame of the image [9]. It consists of two modules as shown in Figure 7.2. The first module is fully convolutional network which proposes regions in the image and the second module is the Fast RCNN which works on these proposed regions and detects the object.

Figure 7.2 Faster RCNN.
7.3.1.2.1 Region Proposal Network (RPN)
Region proposal network gets input of the convolutional feature map where the image is convolved with the sliding window. RPN consists of two stages. The first one is Region Proposal Generator and the second one is bounding box regressor and a classifier. RPN uses a separate network which generates region proposals, by sliding a small network over the convolutional feature map output by the last shared convolutional layer. This small network takes input of an n × n spatial window of the input convolutional feature map. Each sliding window is charted to a lower-dimensional feature. The bounding box regressor uses a relative method where the proposed region is made to actually bind the objects in the image. To ensure that the bounded region contains an object, the classifier is used. The classifier identifies the presence of object using SoftMax classification method. In SoftMax classification method, the confidential scores are normalized and if the output is high, it indicates that the bounding box detected the object on the other hand if the output is low, the bounding box does not bounded the object and the corresponding bounding region is eliminated.
7.3.1.2.2 Anchors
There may be some cases that, multiple objects occur on same sliding window frame. Multiple bounding boxes with object to bounding box ratio of 1:1 for the region proposals are used. These bounding boxes are called anchors. An important property of the anchor boxes is that the center points of all these boxes are same. Figure 7.3 shows the overlapping anchor boxes for a frame.
7.3.1.2.3 Loss Function
In Faster RCNN architecture, each anchor boxes are assigned with binary class label. The anchors with Intersection over Union (IoU) ratio above 0.7 are assigned as positive and the anchor with IoU ratio less than 0.3 is assigned as negative. Anchors with neither positive nor negative do not contribute to this function. Loss is calculated by,
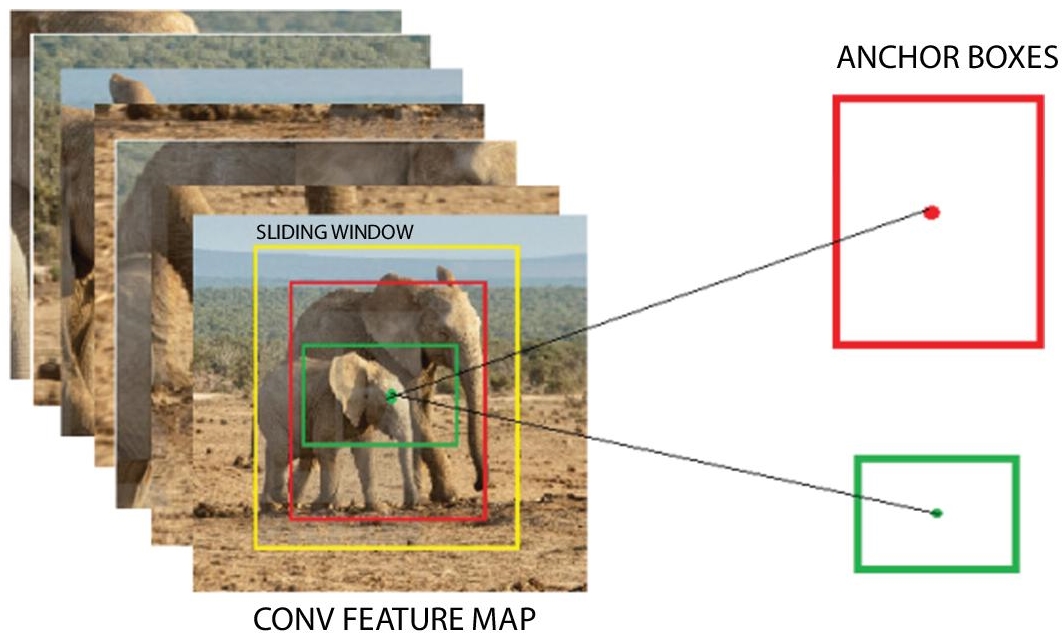
Figure 7.3 Anchor boxes.

Where,
- i – index of the anchor
- pi – predicted probability
 – ground truth label of pi
– ground truth label of pi- ti – vector representing co-ordinates of bounding boxes
 – ground truth values of the co-ordinates
– ground truth values of the co-ordinates- Ncls – normalized classification function
- Nreg – normalized regression function
- Lcls – classification loss over two classes
 Lreg – regression loss for positive anchor
Lreg – regression loss for positive anchor- ⋌ – balancing parameter
7.3.1.3 Single-Shot Multibox Detector (SSD)
Single Shot means that the tasks of object localization and classification are done in a single forward pass of the network. The SSD is a purely convolutional neural network that is organized into three parts,
- Base convolutions-derived from the input image classification architecture (VGG16) that will provide lower level feature maps.
- Auxiliary convolutions-added on the top of the base network that will provide higher-level feature maps.
- Prediction convolutions-it locates and identifies the objects on the feature maps.
7.3.1.3.1 Architecture
SSD is built on a VGG-16 Architecture without the fully connected layers which provides high quality image classification methods. In SSD, a set of auxiliary connected layers are used which enables the extraction of features at multiple scales and progressively decreasing the size of the input image at each layer. Multi box is a method used for fast class agnostic bounding box co-ordinate proposals [10]. Here, Inception type convolutional network is used. Figure 7.4 gives the comprehensive architecture of SSD. Multibox loss function consists of two components,
- Confidence loss – measures how confident the network detects the object
- Location loss – measures how far the predicted bounding boxes from the actual ground truth values
Features maps are a representation of the dominant features of the image at different scales, therefore running Multibox on multiple feature maps increases the likelihood of any object to be eventually detected, localized and appropriately classified.

Figure 7.4 SSD architecture.
7.3.1.3.2 Non-Maximum Suppression (NMS)
Given the large number of boxes generated during a forward pass of SSD at inference time, it is essential to prune most of the bounding box by applying a technique known as non-maximum suppression. Boxes with a confidence loss threshold less than ‘ct’ and IoU less than ‘lt’ are discarded, and only the top N predictions are kept. This ensures only the most likely predictions are retained by the network, while the noisy ones are removed.
7.3.1.4 You Only Look Once (YOLO)
Yolo architecture is more like FCNN (fully convolutional neural network) and passes the image (n x n) once through the FCNN and output is (m x m) prediction. Architecture will split the input image into m x m grid and for each grid, generate two bounding boxes and class probabilities for those bounding boxes.
A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes. YOLO trains on full images and directly optimizes detection performance. This unified model has several benefits over traditional methods of object detection. First, YOLO is extremely fast. Since frame detection as a regression problem, we don’t need a complex pipeline. We simply run our neural network on a new image at test time to predict detections. Our base network runs at 45 frames per second with no batch processing on a Titan X GPU and a fast version runs at more than 150 fps. This means we can process streaming video in real-time with less than 25 milliseconds of latency [11]. Figure 7.5 shows the detailed architecture of YOLO.

Figure 7.5 YOLO architecture.
7.3.1.4.1 Bounding Box Predictions
Each bounding box consists of 5 predictions: x, y, w, h, and confidence. As shown in Figure 7.6, the (x, y) coordinates represent the center of the box relative to the bounds of the grid cell. The width and height are predicted relative to the whole image. Finally, the confidence prediction represents the IOU between the predicted box and any ground truth box. Each grid cell also predicts C conditional class probabilities. These probabilities are conditioned on the grid cell containing an object. We only predict one set of class probabilities per grid cell, regardless of the number of boxes B.

Where, Pr (Classi |Object) -Conditional class probability
YOLO predicts multiple bounding boxes per grid cell. At training time, we want only one bounding box predictor to be responsible for each object. We assign one predictor to be responsible for predicting an object based on which the prediction has the highest current IOU with ground truth. This leads to specialization between the bounding box predictors. Each predictor gets better at predicting certain sizes, aspect ratios, class of an object, improving overall recall. Figure 7.7 shows the overview of bounding box and its class probability map in YOLO.

Figure 7.6 IOU.
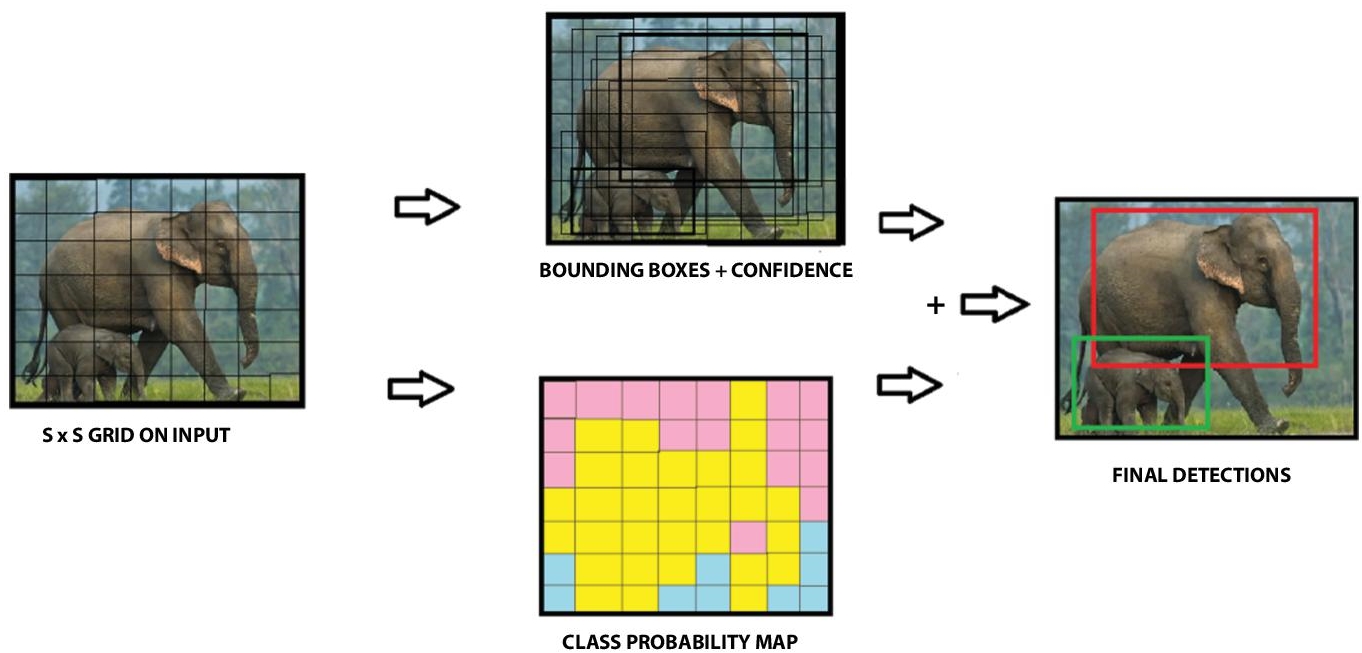
Figure 7.7 YOLO model.
7.3.2 Hardware Specifications
7.3.2.1 Raspberry-Pi 3 Model B
Image processing and Computer vision algorithms requires higher computation power, we choose Raspberry-Pi 3 as a microcontroller. Even it mounted micro SD card as a secondary memory and it is powered by high-quality 2.5A micro USB power supply. Figure 7.8 gives the specification of Raspberry-Pi3ModelB.
7.3.2.2 Night Vision OV5647 Camera Module
REES52 Raspberry Pi Night Vision OV5647 Camera module is chosen to capture video in night time also. It contains 2 Infrared LED Lights in the both side which help in night vision. Figure 7.9 gives the specification of OV5647 Camera module.

Figure 7.8 Specification of raspberry-Pi 3.

Figure 7.9 Specification of camera module.
7.3.2.3 PIR Sensor
Figure 7.10 gives the specification of PIR sensor. Since PIR detect the radiation from the living organisms in a range of 8-16 meters. It will be very useful to trigger the camera when human or animals are crossed [7].
7.3.2.4 GSM Module
Figure 7.11 shows the specification of GSM module. As there must be a communication between the checkpoints (Location of EIDS), the forest officers and local residencies. We use the GSM module to communicate between them. As the GSM module is available with the sim slot, we can use a sim to send message.
7.3.3 Proposed Work
The prototype uses a Passive Infra Red (PIR) sensor to detect the movement of the elephants. These sensors are mounted on trees in the border of the forest. PIR sensors are mounted in both high and low level from ground in order to detect living beings irrespective of their size. When elephant or any other living being comes within the range of sensor, the IR radiation level received by one half of sensor increases by another half. The sensor reacts to this change and makes the output HIGH. This output is used to activate the surveillance camera that is mounted on trees or high poles. The surveillance camera captures a short video clip. A video clip is captured instead of images that have a time delay between each image, so that elephants will not escape from being captured by camera.

Figure 7.10 Specification of PIR sensor.

Figure 7.11 Specification of GSM module.
The video clip is the input for image processing algorithms. The need to move towards image processing is that, the PIR sensor is sensitive to radiation emitted by all living beings. So, it is mandatory to check whether, it is elephant or some other non-dangerous animals (cow, dog, deer). In this prototype, we use Raspberry-Pi 3 model B which has four ARM Cortex A53 microprocessors. The captured video is divided into the sequence of images and processed under a machine learning algorithm namely FASTER R-CNN using Tensor-Flow backend which builds a pre-trained model for the detection of elephant which is stored in the memory of the processor. In the algorithm, the sequence of images is convolved by different filters to form the feature maps with the anchor boxes on the feature maps. Then the feature maps are converted to fully connected layer where SoftMax is performed to predict the object. The neural networks detect the object by predicting the co-ordinates of the bounding boxes and the confidence scores of the presence of object, while training the model the objects in the image are assigned to a class and labeled manually.
Once the Processor processes the video and if the object is detected, the processor triggers the input of GSM module. The GSM module which works on asynchronous full-duplex mode which is used to send the messages to the forest rangers.
7.4 Experimental Results
7.4.1 Dataset Preparation
In the implementation of Faster R-CNN algorithm, we need to train the model using large number of image data. We need to train the model with large number of elephant images with elephants in different positions, different locations (background), and various illumination and lighting conditions. Classifier for accurate detection requires a minimum number of classes. So, some of non-dangerous animals that can be found in the forest boundary such as cow, deer, monkey are also considered for classification purpose. Around 300 images of elephant are collected from internet and also 200 images for other classes. Then the images are manually checked for quality as they may also contain very bad images that may affect the accuracy of the model. The poor images are the filtered out manually. Figure 7.12 shows the CSV file of data storage and the entries CSV file looks as given below.
The dataset now contains images of different resolutions. So, all the images are resized to same dimension as 200 x 200 images. Dataset contains around 500 images of different classes and of same dimensions. The images may contain the objects (animals) of different sizes. So, the area of image with the animals should be marked and labeled accordingly. To do so, a graphical annotation tool namely labeling is used. The animals in each image are manually marked by a rectangular bounding box and labeled to its class.

Figure 7.12 Sample database of CSV file.
This is saved as XML file. The csv file is generated using these XML files. The csv file has details like filename, width, height, class, xmin, ymin, xmax, ymax. The xmin, ymin, xmax, ymax represent the coordinates of rectangular bounding box which covers the animal in that image. Figures 7.13 and 7.14 shows the identified cow and elephant image from the database.

Figure 7.13 Cow (3) image.

Figure 7.14 Elephant (11) image.
The dataset then needs to be divided into two sets – train and test dataset. The train data will be used by model for training purposes by which feature maps are created. Then the test data is used for self-validation by the model. The data is split in ratio of 4:1, test: train in a random fashion.
7.4.2 Performance Analysis of DL Algorithms
The labeled images in the train dataset is now fed to the FASTER RCNN NETWORK as input. The Conv Net generates feature map of each image. The feature map is based on the bounding box information it receives about that image. Region proposal network (RPN) is applied to the output feature maps. A sliding window convolutes over the feature map and maps lower dimensional feature maps. The bounding box regressor in another stage ensures the object to be classified is bounded as proposed. The ConvNet returns the object proposals to be classified and their object score. Then a RoI pooling layer convolves to the object proposals to produce a small feature map of fixed dimensions. The object proposals feature map is then passed onto a fully connected layer. The fully connected layer has a SoftMax layer and a linear regression layer. Here in this process, it classifies and outputs the bounding boxes for objects.
The SoftMax return class predictions based on confidence score. If the score is low, the corresponding bounding box is eliminated. The bounding box regressor returns bounding box offsets with correspondence to the object proposal RoIs. These intermediate values return by FASTER RCNN, is used to train the model. The test data is used for the self-validation. The feature vector obtained from the test data is classified and compared with the actual class. The loss is calculated based on difference between predicted output and actual output. The training process is carried out for several epochs to bring down the loss to a very minimal value and finally it generates a model.
This Classifier uses this pre trained to find the region of object and bounds it with a rectangular box. The object in the RoI is then classified to one of the classes by the classifier and precision score is also returned.
The initial trial for this work has been experimented by using the real time elephant attack video that happened at Periyanaickenpalayam in the year 2017. The video was given as input to the Elephant Detection Program. The video was sampled at a rate of 0.5 frames per sec and stored as images. Then these images are given as input to the classifier. The classifier localizes the region of elephant bounds it with a rectangular box and returns along with precision score. The following Figure 7.15 (Frame 1 to Frame 6) are some frames of the video which localizes the region where the elephant is present by bounding box and detects it as elephant.

Figure 7.15 Various frames of elephant video.
In the above experiment, the elephant in the video is spotted by convolving the frames of the video under Faster RCNN Algorithm and is classified using the SoftMax values and the accuracy percentage is found. With this accuracy percentage, the presence of elephant is confirmed. The Faster RCNN algorithm provides an efficient methodology which processes a frame of the video captured in 0.2 seconds which is much faster than previously proposed systems. In addition to that, Faster RCNN works on RPN so the accuracy is also much higher. This system uses a PIR sensor which detects the movement of elephants and then triggers the camera to capture a video, which saves the power consumption by operating camera whenever required and also confirms the movement of elephants. In case of elephant detection, our system alerts the public by messaging through mobile using GSM module, which is comparatively efficient and safe than existing systems.. Then the GSM module sends a message, “Elephant Detected” along with an image [the frame with highest matching percentage] to forest officers and nearby residents as shown in Figure 7.16.
In the above proposed method, we use the following algorithms based on their performance. The Mean average precision and the processing speed of the used algorithms are given in Table 7.1.
In the view of overall performance, faster RCNN is more efficient in predicting the elephant accurately since it has high mAP and average processing speed. It is strongly evident that the proposed system may be a great contribution to the society and the environment.
To analyze the performance of the algorithm, metrics such as mean average precision (mAP), time and frames per second (FPS) are considered which are shown in Figure 7.17.
From the Figure 7.17, we can see that Faster RCNN and SSD 300 has higher mAP than the other two models. Since mAP is very concerned in our application, we cannot prefer algorithms with lower mAP. Considering the time for response of the algorithms, Faster RCNN is the fastest among all. YOLO has is the second fastest and SSD is third. Even though YOLO has higher FPS than SSD and Faster RCNN, its mAP value is less and time for response is not much differing. So, YOLO V3 is not an optimal solution for our application.

Figure 7.16 SMS indication to forest ranger.
Table 7.1 Parameter comparison of DL algorithms.
| Parameters | Fast RCNN | Faster RCNN | YOLO | SSD |
|---|---|---|---|---|
| mAP | 70.0 | 76.4 | 63.4 | 74.3 |
| FPS | 0.5 | 5 | 45 | 46 |

Figure 7.17 Comparison of DL algorithms.
But to find the most optimal algorithm for our problem, we’re considering another metric namely accuracy. The accuracy of the algorithms for different size of objects is shown in Figure 7.18.
It is evident from the graph that the precision of both SSD 330 and Faster RCNN for larger objects is almost identical. But when the size of the object decreases, we can see a fall in the accuracy of the SSD 300 algorithm. Since we are detecting elephants from a far distance, we get items of smaller size as data. So, from this study, it is obvious that Faster RCNN is more optimal than SSD 300, for our application. In Figures 7.19−7.21 shows the Output of Faster RCNN, YOLO and SSD 300 networks.

Figure 7.18 Accuracy of DL algorithms.

Figure 7.19 Output with smaller object from Faster RCNN.


Figure 7.21 Output with smaller object from SSD 300.
It is shown that all three were able to detect the elephants, but the localization of bounding box and precision indicates that Faster RCNN is able to detect the elephants more efficiently in our application. So, by this we infer Faster RCNN as the most optimal algorithm for detection of elephants in forest border areas. The following Figures 7.22−7.24 describe the various loss functions of faster RCNN algorithm.
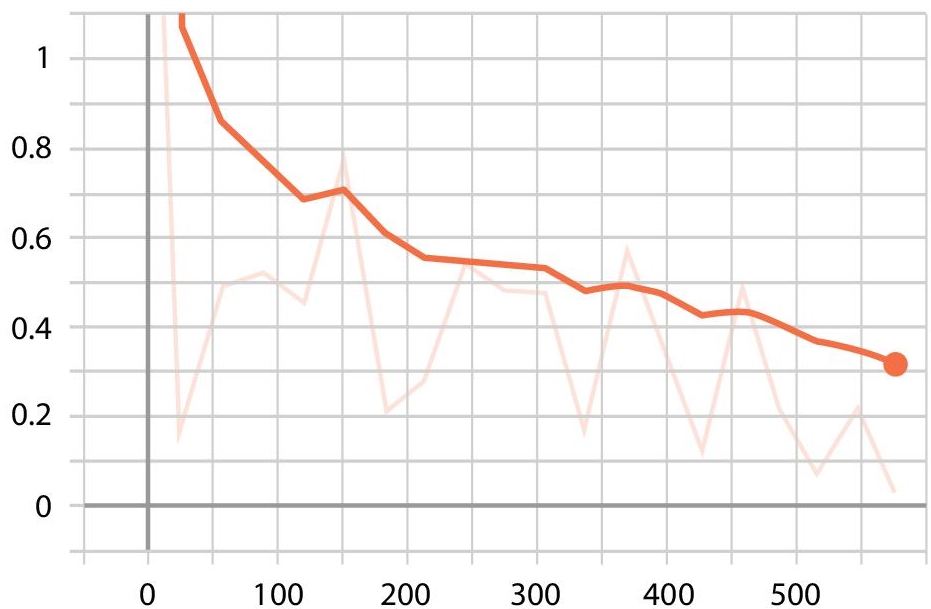
Figure 7.22 Classification loss.

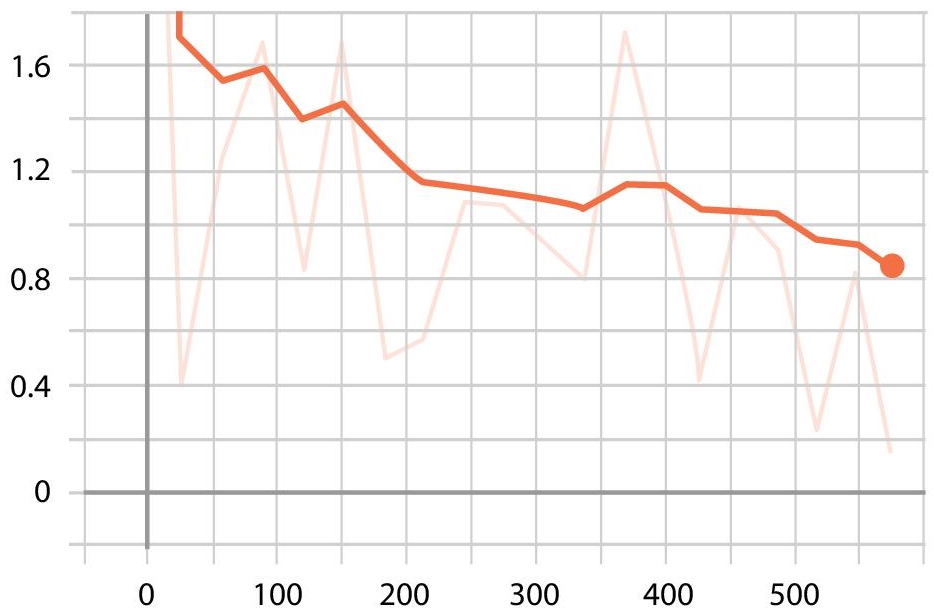
Figure 7.24 Total loss.
7.5 Conclusion
In the above concert, the suggested idea is likely to be a more sophisticated strategy where the identification of real time artifacts takes place. The elephant is correctly spotted by the Deep Learning model in the recorded footage, which is pre-trained by all available elephant images so that it is possible to reduce the possibility of false detection. In the recorded video and the accuracy percentage measurement, the Deep Learning Architectures is found to be a fantastic mechanism where the elephant is confined. The presence of the elephant is confirmed by setting a threshold value for the accuracy percentage. There are many algorithms that perform detection of objects. As the number of proposals for the completely linked layer in the algorithms used above is reduced, the model proposed is more time-efficient. After analyzing all DL architectures Faster RCNN, YOLO and SSD 300 were able to identify the elephants, but the localization of bounding box and accuracy signifies that Faster RCNN works more efficiently to detect the elephants. From this, we realized Faster RCNN as the most optimal algorithm for detection of elephants in forest border areas.
This Artificial Intelligence System functions all the more efficiently as the model is prepared on the basis of an analysis of the creatures found in the natural surroundings of the neighborhood. The approach can be used to identify the proximity of an elephant intrusion in real time. In order to achieve increasingly faster results from the various algorithms, the outputs are evaluated and find an effective way to deal with the distinction between the infringements of the animal.
References
- 1. Maulana, E., Nugroho, C.S., Dianisma, A.B., Animal presence detection for elephants and extruding method based on bee frequency. Electrical Power, Electronics, Communications, Controls and Informatics Seminar (EECCIS), 2018.
- 2. Sugumar, S.J. and Jayaparvathy, R., An improved real time detection system for elephant intrusion along the forest border areas. Sci. World J., Article ID 393958, 1–10, 2014.
- 3. Ramesh, G., Mathi, S., Pulari, S.R., Krishnamoorthy, V., An automated vision based method to detect elephants for mitigation of human-elephant conflicts. International Conference on Advances in Computing, Communications and Informatics (ICACCI), 2017.
- 4. Suganthi, N., Rajathi, N., Farithul Inzamam, M., Elephant intrusion detection and repulsive system. Int. J. Recent Technol. Eng., 07, 4, 307–310, 2018.
- 5. Verma, G.K. and Gupta, P., Wild animal detection from highly cluttered images using deep convolutional neural network. Proceedings of 2nd International Conference on Computer Vision & Image Processing, pp. 327–338.
- 6. Fazil, M. and Firdhous, M., IoT-enabled smart elephant detection system for combating human elephant conflict. 2018 3rd International Conference on Information Technology Research (ICITR).
- 7. Sahoo, K.C. and Pati, U.C., IoT based intrusion detection system using PIR sensor. 2017 2nd IEEE International Conference on Recent Trends in Electronics, Information & Communication Technology (RTEICT).
- 8. Shukla, P., Dua, I., Raman, B., Mittal, A., A computer vision framework for detecting and preventing human elephant collisions. 2017 IEEE International Conference on Computer Vision Workshops (ICCVW).
- 9. Ren, S., He, K., Girshick, R., Sun, J., Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, Jan. 6, 2016, arXiv: 1506.01497v3 [cs.CV].
- 10. Liu, W., Anguelov, D., Erhan, D., Szegedy, C., Reed, S., Fu, C.-Y., Berg, A.C., SSD: Single Shot MultiBox Detector, Springer International Publishing AG, 2016.
- 11. Maheshwari, R., Development of embedded based system to monitor elephant intrusion in forest border areas using internet of things. Int. J. Eng. Res., 5, 7, 594–598, July 2016.
- 12. Sugumar, S.J. and Jayaparvathy, R., Design of a quadruped robot for human-conflict elephant conflict mitigation. Artif. Life Robot., 18, 204–211, 2013.
- 13. Ashwiny, R., Mary, A., Annadurai, K., An efficient warning system for human elephant conflict. Int. J. Sci. Res. Sci. Eng. Technol., 2, 2, 344–349, 2016.
- 14. Perera, B.M.A.O., The human-elephant conflict: A review of current status and mitigation methods. Gajah: J. IUCN/SSC Asian Elephant Specialist Group, 30, 41–52, 2009.
- 15. Santiapillai, C., Wijeyamohan, S., Bandara, G., Athurupana, R., Dissanayake, N., Read, B., An assessment of the human-elephant conflict in Sri Lanka. Ceylon J. Sci. Biol. Sci., 39, 1, 21–33, 2010.
- 16. Sugumar, S.J. and Jayaparvathy, R., An early warning system for elephant intrusion along the forest border areas. Curr. Sci., 104, 11, 1515–1526, June 10, 2013.
Note
- *Corresponding author: [email protected]