
3
Deep Learning: Tools and Models
Brijesh K. Soni and Akhilesh A. Waoo*
Department of Computer Science and Technology, AKS University, Satna, MP, India
Abstract
Now in this modern era, we are exploring technology and science, in the same scenarios, we are also trying to explore a popular technology named “Deep-Learning”, which is a giant technology in the software industry around the world. Here in this chapter, we start with the basic concept of deep learning including the framework and library frequently used to develop such types of applications. Further, in the middle part various deep learning models were discussed with a practical approach using the MNIST dataset. These models are used for solving various complex problems in the domain of computer vision and natural language processing. At the end of this chapter, we are also trying to introduce some emerging and interdisciplinary domains associated with deep learning and artificial intelligence. However, this chapter contains only the core concept of deep learning technology, and it might be fruitful for a beginner in this area.
Keywords: Deep-learning, deep neural network, DBN, RNN, CNN, GAN, MNIST, Keras, TensorFlow, phenotyping, human visual system
3.1 Introduction
Deep learning is the most prominent technology nowadays in most industrial applications. Techniques and methods invented in this domain are broadly applicable in the software industry, automobile industry, gaming industry, agriculture industry, medical industry, telecom industry, etc. [1]. This manuscript covers the core components of deep learning technology. Two concepts are precisely described here, the first one is ‘TensorFlow: Keras’, and the second one is ‘Deep-Learning-Model’.
- Keras is a software development framework or sometimes also considered a library. Keras was initially designed for developing algorithms for natural language processing and computer vision using the python programming language [2].
- Deep-learning-Models are artificially implemented neural networks.
3.1.1 Definition
Deep learning can be observed in such a manner defined below –
“A way of artificial learning in machines by mimicking biological nervous system for solving complex problems”
Scientists and researchers all around the world believe that learning is the process of gaining skills in living creatures. Now in this modern era technologies are growing at an exponential rate; artificial intelligence is also one of them having huge applications in software industries. These hi-tech industries continuously develop more advanced software-enabled machines possessing self-learning capability [3]. Deep learning is the most significant and popular technique for developing such kinds of self-learning machines. Deep learning is the sub-domain of machine learning, which is further a sub-domain of artificial intelligence [4].
How a human mind solves critical problems, in the same manner, researchers trying to develop artificial models of the nervous system using software technologies in computerized machines with the intent of going more and more depth for solving critical problems. These models are known as artificial neural network that contains multiple numbers of artificial neuron units and appropriate transition paths. These artificial neuron units interact as a fully connected network on the transition path [5]. These artificial neurons are organized in a layered structure, having more than one layer in a single network. The number of layers depends on the problem size, which means for a more complex problem many numbers of layers are required. Ultimately the size of the network depends on the depth of the problem. Now it is understood that for solving more critical problems by going into more depth, a multilayered neural network (Multilayered Perceptron) is required to have the facility of deep learning [6]. These types of neural networks are known as deep neural networks or deep neural network models. These models are the core components of this chapter to be discussed in detail in Section 3.2.
3.1.2 Elements of Neural Networks
A deep learning model or deep neural network may have common building blocks and terminologies [7]. Some of them are briefly described here and are frequently used-
- Node – This is the artificial neuron for holding a value in a neural network. In a network, there may be multiple nodes available. Generally, these nodes are composed in the form of layers and every layer has one or more nodes.
- Connection – This is the transition path between neurons for transferring value from one node to another node, starting from the input node to the output node. Like nodes, connections are also used in multiple numbers for transferring appropriate values and relating nodes to each other.
- Layer – This is the most significant component of a neural network. Each layer has one or more neurons having similar or different values. Generally, layers are categorized as the input layer, hidden layer, and output layer. Primarily input and output layers must be single, and hidden layers may be in n-numbers. These multiple numbers of hidden layers create a deep neural network and facilitate the deep learning process [8].
- Input – This is the input value given to the model which will be further processed for generating appropriate output. Values may be random or predefined and are taken by nodes available in the input layer.
- Output – After processing, this is the final output generated by the model using the activation specified function. Ideally, the output will be equivalent to the target output, but in practice, it’s not possible to generate the exact targeted output. There might be a difference between actual output and target output, which will further deal with backpropagation.
- Weight – Weight is a numeric value multiplied by the input values received from the input layer. It will use for upgrading the input to propagate into the next layer. The weight value continuously changes during the training period for getting the targeted output at the output layer.
- Bias – This is the constant value applied during the processing of original inputs. This value will be ideal for all input values. Unlike weight value, this is the constant value and it never changes even during the training period.
- Activation – This is a very important function in a neural network model. Without this function whole model works like a simple pipeline. The activation function mathematically operates the summation of original inputs and a weight value, just before the final output is generated. Some common and frequently used activation functions are sigmoid, ReLU function, binary function, and linear function [9].
- Threshold – The threshold value is associated with the activation function which directly affects the output to be generated, whether the neuron fires or not fires. It will be decided according to the desired output.
3.1.3 Tool: Keras
This is the most frequently used tensor flow-based library tool for implementing deep learning models. This is originally developed by the world-renowned company Google.
Nowadays most popular companies are using this tool for developing artificially intelligent machines and models. Keras allows building, training, and evaluation of deep neural networks. [10] Here in this section, the fundamental architecture of Keras having three-pillar components (Figure 3.1) will be briefly described-
Models – Models are data structures in Keras. These models shape the core structure of a neural network model and specify internal connections among the neurons and the transition path of the model. In Keras, there are two types of models’ namely the sequential model and functional model which are briefly described below-
- Sequential API Model – This is the simplest data structure in Keras, where multiple layers are organized linearly or sequentially. That means there are not any direct connections between input and output in the case of a multilayer perceptron. This type of model can be easily created and understood.

Figure 3.1 Major components of Keras.
- Functional API Model – This is the advanced data structure in Keras, where all the layers of a network are randomly connected. This is a hybrid data structure where a network can have sequential and random connections. This is a very complex structure in nature; it couldn’t be easily implemented, unlike sequential structure [11].
Layers – Layers are core elements of a neural network that contains one or more neurons in the layered organization. Each layer is further connected to other layers of the same network. A simple network has two or more layers that are responsible for the complexity of the network. In Keras, multiple types of layers are available for solving problems in different types of network models. Some common categories and examples of Keras layers are briefly described here-
- Core-Layers – This is the fundamental category of Keras layers, where some important and frequently used layers are included. Without using these layers, it couldn’t be possible to implement any neural network. Some important core layers are Dense, Activation, Dropout, Flatten, Input, Reshape, Permute, Lambda, and Masking.
- Convolution-Layers – This is the category where important layers are included which are applicable in the convolutional neural network. The convolutional neural network is a very important and popular model for image processing. Conv1D and Conv2D layers are most frequently used in the convolutional neural network. These layers are used for convoluting or filtering the original input values for generating a more optimized output.
- Pooling-Layers – This is also a category where included layers are used in the convolutional neural network. MaxPooling1D, MaxPooling2D, and AveragePooling1D, AveragePooling2D, are popular layers that are used for resizing the original inputs in a convolutional neural network.
- Recurrent-Layers – This is the category having important layers frequently used in a recurrent neural network. A recurrent neural network is popular for text processing (NLP) among researchers and engineers around the world. Simple RNN and LSTM are two important layers applicable in a recurrent neural network for implementing its various variant models [12].
Modules – Modules are built-in APIs available in TensorFlow and Keras. Sometimes these APIs are also known as the library. By using these APIs, we can solve complex problems easily without paying more time and effort. These APIs or modules can be directly imported into our program and further functions and classes available in these imported APIs can be used in the program for processing data and generating appropriate output in different network models. Keras has multiple modules some of them are described here in this section:
- Losses – This module provides various loss functions to compute the quantity that a model should minimize during training. All losses are available both via a class handle and via a function handle. The class handles enable you to pass configuration arguments to the constructor and they perform reduction by default when used in a standalone way.
- Metrics – This module provides functions for the jugging performance of the neural network. Metric functions are similar to loss functions, except that the results from evaluating a metric are not used when training the model. Note that you may use any loss function as a metric.
- Utilities – This package provides utilities for Keras, such as model plotting utilities, Serialization utilities, Python & NumPy utilities, and Backend utilities.
- Backend – This module handles backend operations in Keras. Generally, Keras runs on the top of the TensorFlow backend. But if required it can be changed from TensorFlow to Theano or CNTK backend.
- Callback – This module provides functions to analyze immediate results. The callback can perform actions at various stages of training such as at the start or end of an epoch, before or after a single batch, etc.
- Activations – This module provides various activation functions for transforming summation input into the final output. These functions decide whether the neuron is active or inactive, which directly affects the final output.
- Constraints – This module provides functions to apply weight parameters during optimization.
- Initializers – This module provides functions to set the initial weight. During the training period weight will be assigned to each input value. This task is performed by the initializer functions available in this module.
- Optimizers – This module provides functions to change weight and learning rates for reducing loss. An optimizer is one of the two arguments required for compiling a Keras model. You can either instantiate an optimizer before passing it to model.compile(), as in the above example, or you can pass it by its string identifier. In the latter case, the default parameters for the optimizer will be used.
- Regularizers – This module provides functions for applying some penalties on the layers during the optimization. Regularization is a technique used in an attempt to solve the overfitting problem in statistical models. As the name implies, they use L1 and L2 norms respectively which are added to your loss function by multiplying it with parameter lambda. This penalizes the network’s aggressive pattern memorizing behavior which can be detrimental while training since the network will just learn to mimic the given data rather than learning to approximate any useful functions.
- Text Processing – This module provides functions to convert normal text input value into an array so that it can be easily processed. These functions are frequently used with recurrent neural networks for text processing and pattern recognition.
- Image Processing – This module provides a function to convert normal image input pixels into an array so that they can be simply analyzed. These functions are mostly used with a convolutional neural network for image processing and classification.
- Sequence Processing – This module provides functions for converting normal input values into time-based data. These functions can be used in data preparation [13].
3.2 Deep Learning Models
Deep Learning Models are artificially implemented neural networks inspired by the human nervous system.
This section elaborates on four fundamental deep learning models, explored with their practical implementation in the MNIST dataset using TensorFlow: Keras library and python programming language. These models are Deep Belief Network (DBN), Recurrent Neural Network (RNN), Convolutional Neural Network (CNN), and Gradient Adversarial Network (GAN) [14], shown in Figure 3.2.

Figure 3.2 Deep learning models.
3.2.1 Deep Belief Network [DBN]
This is a deep neural network model developed at an early age in deep learning. It has hybrid compositions of a set of Restricted Boltzmann Machines (RBN). That means multiple RBNs are stacked within a single network. These RBNs are working on the concept of probability applicable in belief networks. Each RBN has a visible layer and a hidden layer. This is a generative and unsupervised neural network. It uses a greedy unsupervised learning algorithm for the training of intermediate layers, but finally, the whole network will train using a supervised fine-tuning method. Nowadays Restricted Belief Machines and Deep Belief Networks are rarely used for data processing [15]. This section explores the simple architecture of the deep belief network.
3.2.1.1 Fundamental Architecture of DBN
There are two types of layers (Figure 3.3) available in deep belief network architecture. The overall network will be trained in two phases pre-training phase and fine-tuning phase.
- Visible Layer – This is the primary layer of Restricted Boltzmann Machines which will be further available in the Deep Belief Network. It looks like an input layer in a simple neural network. It takes input from external sources and further provides it to the next layer. There is only a single visible layer in an RBM, where each neuron is directly connected to each neuron of the hidden layer. There is no connection among neurons belonging to the same layer [16].

Figure 3.3 Layers in the deep belief network.
- Hidden-Layer – This is the next layer after the visible layer, which takes input from the visible layer. Like the visible layer, there is also a single hidden layer in an RBM. However, this layer is completely responsible for performing computations and generating the desired output, because there is no output layer separately in this type of machine model [17].
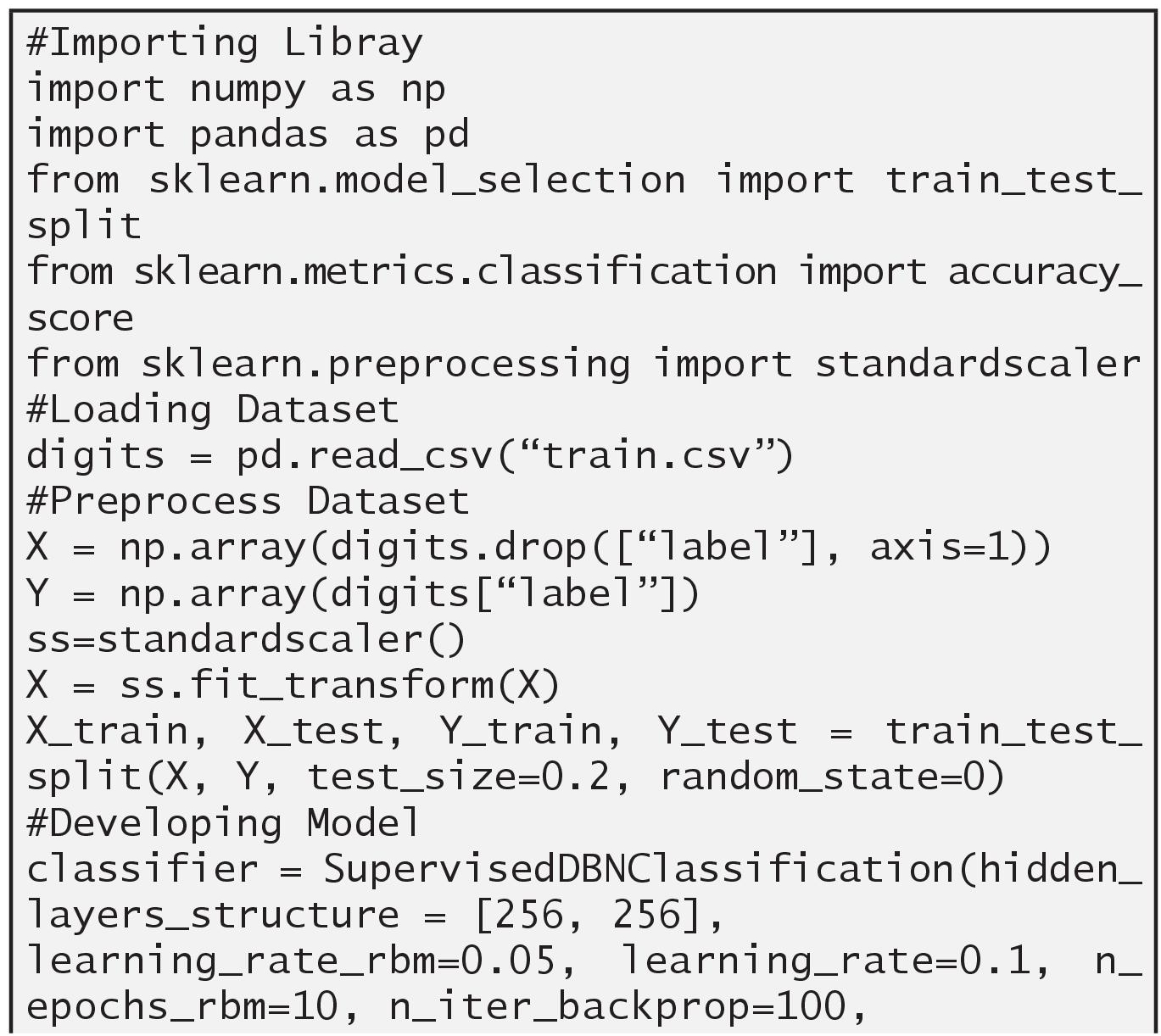
3.2.1.2 Implementing DBN Using MNIST Dataset

3.2.2 Recurrent Neural Network [RNN]
This is one of the most popular deep neural network models. Recurrent Neural Network was originally developed for text processing, but nowadays it has various other similar applications like speech recognition, handwriting recognition, and natural language processing. It can store the previous state in memory for predicting the next state, by using the backpropagation method [18].
3.2.2.1 Fundamental Architecture of RNN
This model has a traditional structure which means there are ordinary neurons and layers used for data computation. The key point which makes it unique is its recursive nature. Its hidden layer is responsible for the recursive process following the backpropagation method [19]. Here in this section basic layers as shown in Figure 3.4, are briefly described.
- Input-Layer – The input layer is responsible for receiving the inputs. These inputs can be loaded from an external source such as a web service or a CSV file. There must always be one input layer in a neural network. The input layer takes in the inputs, performs the calculations via its neurons, and then the output is transmitted onto the subsequent layers [20].
- Hidden-Layer – The introduction of hidden layers makes neural networks superior to most machine learning algorithms. Hidden layers reside in-between input and output layers and this is the primary reason why they are referred to as hidden. The word “hidden” implies that they are not visible to the external systems and are “private” to the neural network. There could be zero or more hidden layers in a neural network. Usually, each hidden layer contains the same number of neurons. The neurons simply calculate the weighted sum and add the bias, to execute an activation function [21].

Figure 3.4 Layers in RNN.
- Output-Layer – The output layer is responsible for producing the final result. There must always be one output layer in a neural network. The output layer takes in the inputs which are passed in from the layers before it, performs the calculations via its neurons, and then the output is computed. In a complex neural network with multiple hidden layers, the output layer receives inputs from the previously hidden layer [22].
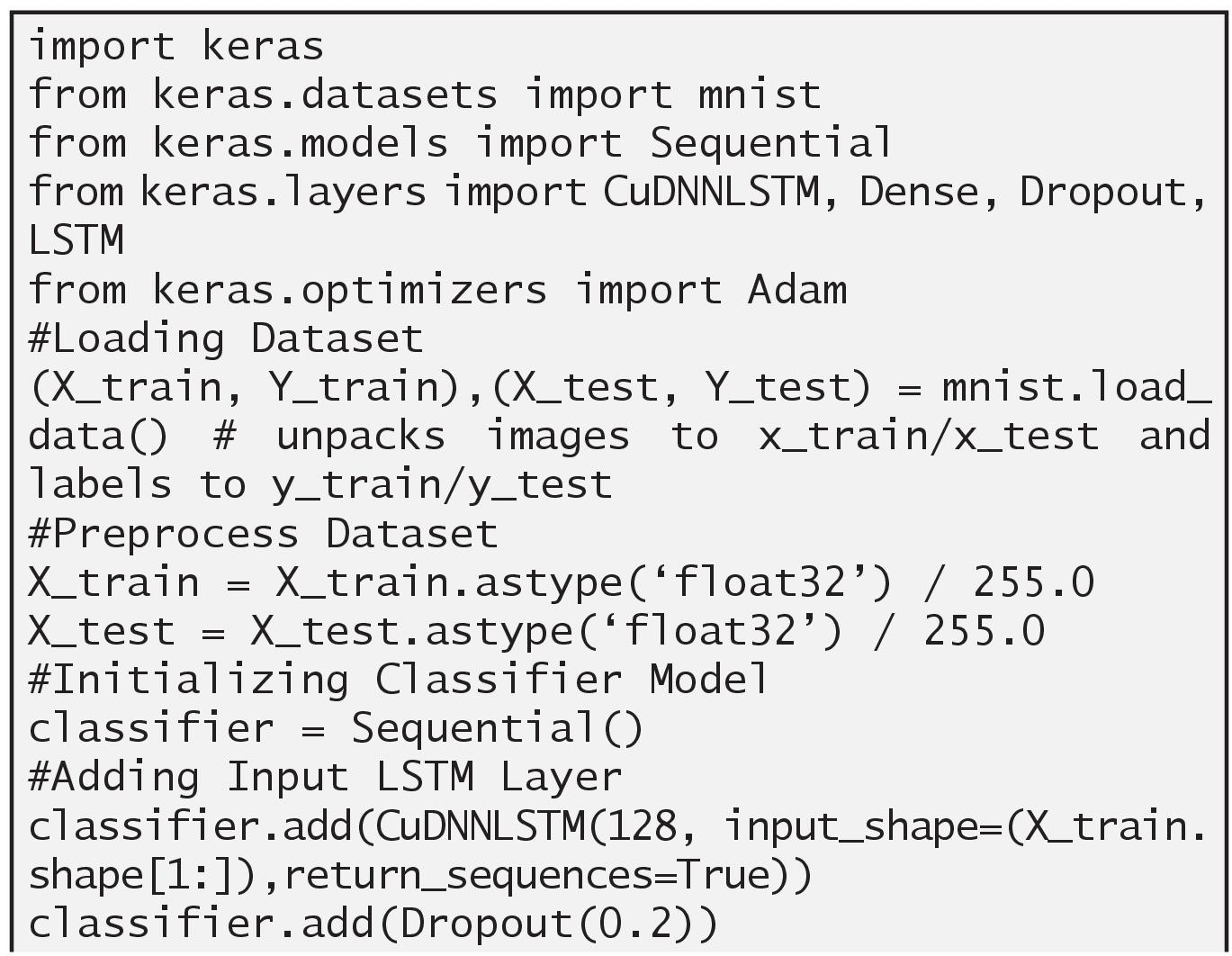
3.2.2.2 Implementing RNN Using MNIST Dataset

3.2.3 Convolutional Neural Network [CNN]
Convolutional Neural Network is another most important and popular deep neural network model. This is a feed-forward neural network. There are various applications of this model in the domain of image processing for analyzing visual imagery. Convolutional Neural Network is inspired by the human visual cortex [23].
3.2.3.1 Fundamental Architecture of CNN
This deep learning model has a unique and little complex architecture compared to a traditional neural network. It has three types of layers (Figure 3.5) a convolution layer, a pooling layer, and a fully connected or dense layer [24]. Here in this section, these layers will be briefly described.
- Convolution Layer – This layer is responsible for extracting features from the input image. Here inputs are small square pixel of an image, which relatively represents the features of that image. Mathematically, convolution is a function that takes two input items and produces an output item. Here, a matrix is used for containing image pixels that provide the first input; another input is taken from the filter or kernel matrix. The image pixel matrix and filter matrix are multiplied and produce an output matrix which is known as a feature map. Different types of filters deal with different features of the image such as edge detection blur and sharpen etc [25].
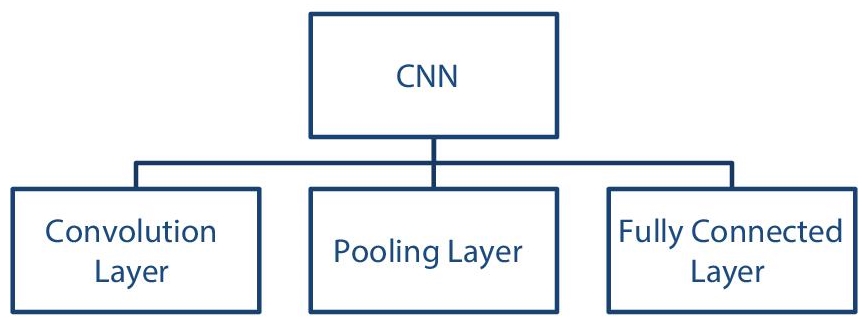
Figure 3.5 Layers in CNN.
- Pooling Layer – This layer is responsible for reducing the image parameters, which means it removes unnecessary features of the images and represents only essential features. A special type of pooling, spatial pooling which is also known as down-sampling or sub-sampling most frequently used in this type of deep learning model. Some common types of pooling are Max-Pooling, Average-Pooling, and Sum-Pooling [26].
- Fully Connected Layer – This is the next layer after the convolution and pooling layer. It takes input from the pooling layer and, analyzes and predicts the preferred pattern for final output. One more important work of this layer is to flatten input from the previous layer [27].
3.2.3.2 Implementing CNN Using MNIST Dataset

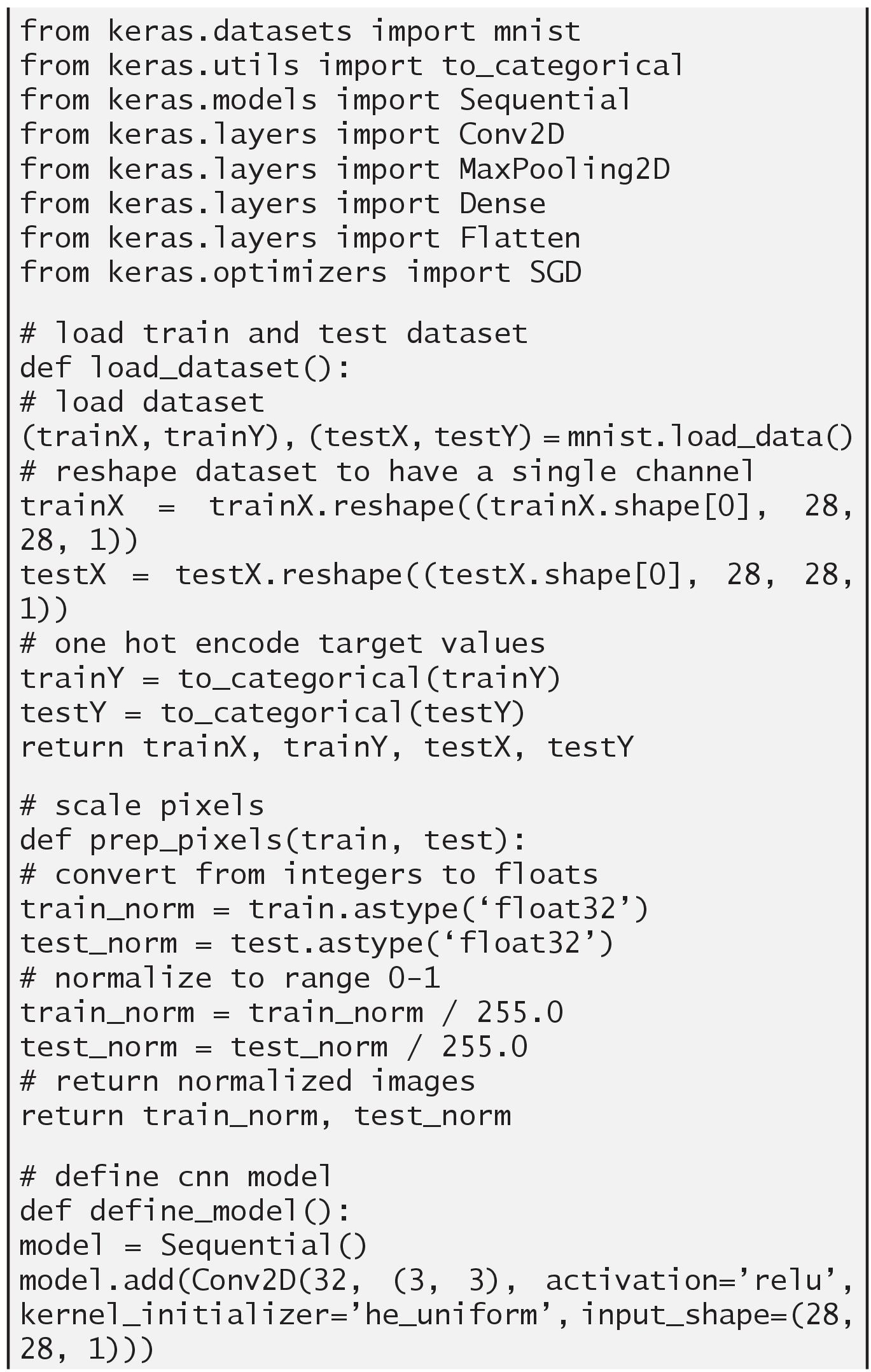


Figure 3.6 Layers in GAN.
3.2.4 Gradient Adversarial Network [GAN]
This is a relatively new member of the family of deep learning models. It is a hybrid system having two combined networks. These two network components are known as generative network and discriminative network, where the generative network generates output, and the discriminative network evaluates that output [28].
3.2.4.1 Fundamental Architecture of GAN
The overall architecture of the gradient adversarial network is divided into two parts (Figure 3.6) generative and discriminative. Mostly these parts are considered an individual network that works in combinations. However, by design generative network is a deconvolutional network whereas the discriminative network is a convolutional network [29].
- Generative-Network – The prime intention of this network is to generate plausible output. However, the generated output shows a negative impact on the discriminator [30].
- Discriminative-Network – The overall objective of this network is to work as a classifier and distinguish the generator’s fake output from the real output. Ultimately this network aims to realize the mistakes of the generator network. It also penalizes the generator network for producing implausible output [31].
3.2.4.2 Implementing GAN Using MNIST Dataset



3.3 Research Perspective of Deep Learning
The ideology of anything never being limited, in the same sense, there are some current research trends, where exploration is possible. This section deals with some latest research hypotheses in the domain of deep learning in brief.
3.3.1 Multi-Agent System: Argumentation
This is a research project in which researchers are trying to develop the Multi-agent System for argumentation among law professionals [32]. I believe this will very helpful for analyzing and handling criminal cases under the law and jurisdiction [33]. Researchers are using Conditional Probability and Bayesian-Network for implementing this model. They are trying to design and train a deep neural network in the domain of deep learning [34].
3.3.2 Image Processor: Phenotyping
In this project, researchers are trying to develop an algorithm that provides a better result in Phenotyping [35]. Most agriculture-based countries trying to improve crop quality and secure plants from various types of diseases [36]. They are trying to improve spatial resolution and pattern classification in the existing algorithm. Some researchers are using drones for taking real-time images for further processing [37].
3.3.3 Saliency Map: Visualization
There is a huge amount of opportunity in brain research associated with deep learning because the phenomenon of deep learning originated from the human nervous system [38]. This project is directly related to the human visual system, which means scientists are trying to apply the saliency technique for mapping visual stimuli [39]. Researchers striving to develop a model for the human visual cortex for mapping images artificially [40].
3.4 Conclusion
The human nervous system is fully responsible for how critically we can think and dive into the depth of the problem domain. It is well known that we have lots of alternative tools and technology for solving general problems, but we have to find a unique phenomenon for exploring the edge of unsolvable problems. Deep learning is one of those techniques by using which we can solve critical problems with more accuracy. This chapter covered most of the popular and important deep learning neural network models.
All the models described in this chapter are now pillars in the domain of deep learning. RNN and CNN are two siblings born from mother deep learning, where RNN is popular for text-processing and CNN is known for image-processing. GAN is the most significant and popular model among modern researchers and laboratories around the globe. This is comparable to a strategic technique between an expert and a novice mind in a particular domain for improving knowledge and experience. However, these are the only concepts, but if we want to convert them into the products, we must require a framework, that’s why we used TensorFlow and Keras with a python programming language for converting conceptual models into a software product, by taking an example dataset provided by Kaggle partner. The last section of this chapter provided some research ideology for future perspectives in this domain. There were three subdomains in my digital phenotyping in crops, argumentation using multiagent, and the last one is saliency mapping for visual signal processing in the human visual system. Finally, we tried to represent the fundamentals of deep learning having more emphasis on deep learning models.
References
- 1. Vargas, R. and Obudai Egyetem, Deep learning: Previous and present applications. J. Aware., 2, 12–17, 2017.
- 2. About Keras. Retrieved from Keras website: https://keras.io/about/.
- 3. Georgevici, A., II and Terblanche, M., Neural networks and deep learning: A brief introduction. Intensive Care Med., Springer Verlag, 45, 712–714, 2019.
- 4. Serokell, Artificial intelligence vs. Machine learning vs. Deep learning: What’s the difference, 2020. Retrieved from Medium website: https://medium.com/ai-in-plain-english/artificial-intelligence-vs-machine-learning-vs-deep-learning-whats-the-difference-dccce18efe7f.
- 5. Zhang, Z., A gentle introduction to artificial neural networks. Ann. Transl. Med. AME Publishing Company, 4, 370, 2016.
- 6. Neural network: Architecture, components & top algorithms, 2020. https://www.upgrad.com/blog/neural-network-architecture-components-algorithms.
- 7. Basheer, I.A. and Hajmeer, M.N., Artificial neural networks: Fundamentals, computing, design, and application. J. Microbiol. Methods Elsevier, 43, 3–31, 2001.
- 8. Smith, S.W., Neural network architecture, Hard Cover 1997, Soft Cover 2002, The Scientist and Engineer’s Guide to, Digital Signal Processing Published by Newnes, https://www.dspguide.com/ch26/2.htm.
- 9. Sharma, S., Activation functions in neural networks, 2017. https://towards-datascience.com/activation-functions-neural-networks-1cbd9f8d91d6.
- 10. Keras API reference, https://keras.io/api/.
- 11. Keras API reference: Models API, https://keras.io/api/models/.
- 12. Keras API reference: Layers API, https://keras.io/api/layers/.
- 13. Keras-modules, https://www.tutorialspoint.com/keras/keras_modules.htm.
- 14. Sk, S., Jabez, J., Anu, V.M., The power of deep learning models: Applications. Int. J. Recent Technol. Eng., 8, 3700–3704, 2019.
- 15. Hua, Y., Guo, J., Zhao, H., Deep belief networks and deep learning. International Conference on Intelligent Computing and Internet of Things, IEEE Xplore, 2015.
- 16. Restricted Boltzmann machines, http://docs.goodai.com/brainsimulator/guides/rbm/index.html.
- 17. Fischer, A. and Igel, C., An introduction to restricted Boltzmann machines. Iberoamerican Congress on Pattern Recognition, 2012.
- 18. Sherstinsky, A., Fundamentals of recurrent neural network (RNN) and long short-term memory (LSTM) network. Phys. D Nonlinear Phenom. Elsevier, 404, 1–43, 2020.
- 19. Nayak, M., Introduction to the architecture of recurrent neural networks (RNNs), 2019. https://medium.com/towards-artificial-intelligence/introduction-to-the-architecture-of-recurrent-neural-networks-rnns-a277007984b7.
- 20. Recurrent neural networks explanation. https://www.geeksforgeeks.org/recurrent-neural-networks-explanation/?ref=lbp.
- 21. Recurrent neural networks (RNN) with Keras. https://www.tensorflow.org/guide/keras/rnn.
- 22. Amidi, A. and Amidi, S., Recurrent neural networks cheatsheet. https://stanford.edu/~shervine/teaching/cs-230/cheatsheet-recurrent-neural-networks.
- 23. Teuwen, J. and Moriakov, N., Convolutional neural networks, Handbook of Medical Image Computing and Computer Assisted Intervention, Elsevier Inc., https://doi.org/10.1016/B978-0-12-816176-0.00025-9,2020,https://www.sciencedirect.com/topics/engineering/convolutional-neural-networks.
- 24. Gupta, D., Architecture of convolutional neural networks (CNNs) demystified, 2017. https://www.analyticsvidhya.com/blog/2017/06/architecture-of-convolutional-neural-networks-simplified-demystified.
- 25. Sakib, S.; Ahmed, N.; Kabir, A.J.; Ahmed, H. An Overview of Convolutional Neural Network: Its Architecture and Applications. Preprints 2018, 2018110546 (doi: 10.20944/preprints201811.0546.v4).
- 26. Jmour, N., Zayen, S., Abdelkrim, A., Convolutional neural networks for image classification. International Conference on Advanced Systems and Electric Technologies, 2018.
- 27. Chauhan, R., Ghanshala, K.K., Joshi, R.C., Convolutional neural network (CNN) for image detection and recognition. International Conference on Secure Cyber Computing and Communication, 2018.
- 28. Creswell, A. and White, T., Generative adversarial networks: An overview. IEEE Signal Process. Mag., 35, 1–14, 2017.
- 29. Pouget-Abadie, J. and Goodfellow, I., Generative adversarial networks, in: Advances in Neural Information Processing Systems, MIT, Proceedings of the 27th International Conference on Neural Information Processing Systems, 2, 2672–2680, 2014.
- 30. The generator. https://developers.google.com/machine-learning/gan/generator.
- 31. The discriminator. https://developers.google.com/machine-learning/gan/discreminator.
- 32. Maudet, N., Parsons, S., Rahwan, I., Argumentation in multi-agent systems: Context and recent developments. International Workshop on Argumentation in Multi-Agent Systems, 2006.
- 33. Chow, H.K.H. and Siu, W., An argumentation-oriented multi-agent system for automating the freight planning process. Expert Syst. Appl., Elsevier, 40, 3858–3871, 2013.
- 34. Panisson, A.R. and Meneguzzi, F., Towards practical argumentation-based dialogues in multi-agent systems. International Conference on Web Intelligence and Intelligent Agent Technology, IEEE Xplore, 2015.
- 35. Namin, S.T., Brown, T.B., Borevitz, J.O., Deep phenotyping: Deep learning for temporal phenotype/genotype classification. Plant Methods, Springer Nature, 14, 1–22, 2018.
- 36. Tsaftaris, S., Minervini, M., Scharr, H., Machine learning for plant phenotyping needs image processing. Trends Plant Sci. Elsevier, 21, 989–991, 2016.
- 37. Singh, A.K. and Ganapathysubramanian, B., Deep learning for plant stress phenotyping: Trends and future perspectives. Trends Plant Sci. Science Direct, 23, 883–898, 2018.
- 38. Weiden, M., Deepak, K., Keegan, M., Electroencephalographic detection of visual saliency of motion towards a practical brain-computer interface for video analysis. ACM International Conference on Multimodal Interaction, 2012.
- 39. Schreiber, A., Saliency maps for deep learning part 1: Vanilla gradient, 2019. https://medium.com/@thelastalias/saliency-maps-for-deep-learning-part-1-vanilla-gradient-1d0665de3284.
- 40. What is saliency map, 2000. https://www.geeksforgeeks.org/what-is-saliency-map.
Note
- *Corresponding author: [email protected]