
Atomic operations are a fast and relatively easy alternative to mutexes. They do not suffer from the deadlock and convoying problems described earlier, in the section “Lock Pathologies.” The main limitation of atomic operations is that they are limited in current computer systems to fairly small data sizes: the largest is usually the size of the largest scalar, often a double-precision floating-point number.
Atomic operations are also limited to a small set of operations supported by the underlying hardware processor. But sophisticated algorithms can accomplish a lot with these operations; this section shows a couple of examples. You should not pass up an opportunity to use an atomic operation in place of mutual exclusion.
The class atomic<T> implements atomic operations with C++ style.
A classic use of atomic operations is for thread-safe reference counting. Suppose x is a reference count of type int and the program needs to take some action when the reference count becomes zero. In single-threaded code, you could use a plain int for x, and write --x; if(x==0) action(). But this method might fail for multithreaded code because two tasks might interleave their operations, as shown in Figure 7-1, where ta and tb represent machine registers and time progresses downward.
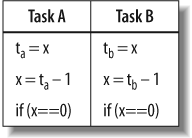
The problem shown in Figure 7-1 is a classic race condition. Although the code intends x to be decremented twice, x ends up being only one less than its original value. Also, another problem results because the test of x is separate from the decrement: if x starts out as 2, and both tasks decrement x before either task evaluates the if condition, both tasks will call action().
Note that simply writing if(--x==0) action() does not solve the problem—as long as x is a conventional variable—because at the machine code level, the decrement is still a separate instruction from the compare. Two tasks can still interleave their operations.
To correct this problem, you need to ensure that only one task at a time does the decrement and that the value checked by the if is the result of the decrement. You can do this by introducing a mutex, but it is much faster and simpler to declare x as atomic<int> and write if(--x==0) action(). The method atomic<int>::operator--acts atomically; no other task can interfere.
atomic<T> supports atomic operations on type T, which must be an integral or pointer type. Five fundamental operations are supported, with additional interfaces in the form of overloaded operators for syntactic convenience. For example, ++, --, -=, and += operations on atomic<T> are all forms of the fundamental operation fetch-and-add. Table 7-4 shows the five fundamental operations on a variable x of type atomic<T>.
Table 7-4. Fundamental operations on a variable x of type atomic<T>
|
Operation |
Description |
|---|---|
|
|
Read the value of x. |
|
|
Write the value of x, and return it. |
|
|
Execute |
|
|
Execute |
|
|
If x equals z, execute |
|
|
In either case, return the old value of x. |
Because these operations happen atomically, they can be used safely without mutual exclusion. Consider Example 7-2.
Example 7-2. GetUniqueInteger atomic example
atomic<unsigned> counter;
unsigned GetUniqueInteger() {
return counter.fetch_and_add(1);
}The routine GetUniqueInteger returns a different integer each time it is called, until the counter wraps around. This is true no matter how many tasks call GetUniqueInteger simultaneously.
The operation compare_and_swap is fundamental to many nonblocking algorithms. A problem with mutual exclusion is that if a task holding a lock is suspended, all other tasks are blocked until the holding task resumes. Nonblocking algorithms avoid this problem by using atomic operations instead of locking. They are generally complicated and require sophisticated analysis to verify. However, the idiom in Example 7-3 is straightforward and worth knowing. It updates a shared variable, globalx, in a way that is somehow based on its old value:
Example 7-3. compare_and_swap atomically
atomic<int> globalx;
int UpdateX() { // Update x and return old value of x.
do {
// Read globalx
oldx = globalx;
// Compute new value
newx = ...expression involving oldx....
// Store new value if another task has not changed globalX.
} while( globalx.compare_and_swap(newx,oldx)!=oldx );
return oldx;
}In some OS implementations, compare_and_swap can cause tasks to iterate the loop until no other task interferes, and this may seem less efficient in highly contended situations because of the repetition. But typically, if the update takes only a few instructions, the idiom is faster than the corresponding mutual-exclusion solution, so you should use compare_and_swap.
The update idiom (compare_and_swap) is inappropriate if the A-B-A problem (see sidebar) thwarts your intent. It is a frequent problem when trying to design a non-blocking algorithm for linked data structures.