The library provides a task scheduler, which is the engine that drives the algorithm templates. You may also call it directly. This is worth considering if your application meets the criteria described earlier that make the default task scheduler inefficient.
Tasks are logical units of computation. The scheduler maps these onto physical threads. The mapping is non-preemptive. Each thread has an execute() method. Once a thread starts running execute(), the task is bound to that thread until execute() returns. During that time, the thread services other tasks only when it waits on child tasks, at which time it may run the child tasks or—if there are no pending child tasks—service tasks created by other threads.
The task scheduler is intended for parallelizing computationally intensive work. Since task objects are not scheduled preemptively, they should not make calls that might block for long periods because, meanwhile, the blocked thread (and its associated processor) are precluded from servicing other tasks.
Warning
There is no guarantee that potentially parallel tasks actually execute in parallel, because the scheduler adjusts actual parallelism to fit available worker threads. For example, when given a single worker thread, the scheduler obviously cannot create parallelism. Furthermore, it is unsafe to use tasks in a producer/consumer relationship if the consumer needs to do some initialization or other work before the producer task completes, because there is no guarantee that the consumer will do this work (or even that it will run at all) while the producer is running. The pipeline algorithm in Threading Building Blocks, for instance, is designed not to require tasks to run in parallel.
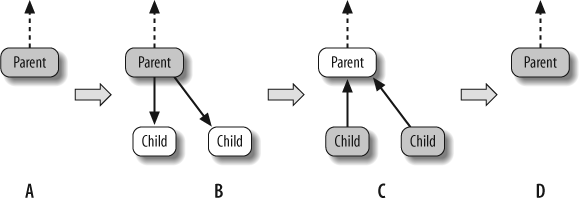
Potential parallelism is typically generated by a split/join pattern. Two basic patterns of split/join are supported. The most efficient is continuation passing, in which the programmer constructs an explicit “continuation” task rather than leaving it to the default scheduler to determine the next task. The steps are shown in Figure 9-1, and the running tasks (that is, the tasks whose execute methods are active) at each step are shaded.
In step A, the parent is created. In step B, the parent task spawns off child tasks and specifies a continuation task to be executed when the children complete. The continuation inherits the parent’s ancestor. The parent task then exits; in other words, it does not block on its children. In step C, the children run. In step D, after the children (or their continuations) finish, the continuation task starts running.
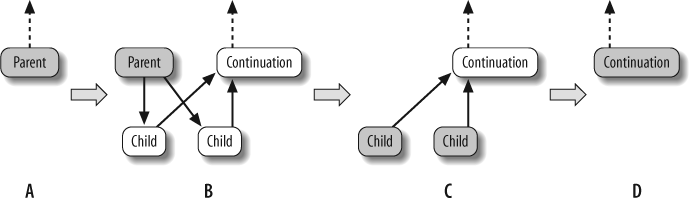
Explicit continuation passing is efficient because it decouples the thread’s stack from the tasks. However, it is more difficult to program. A second pattern is blocking style, which uses implicit continuations. It is sometimes less efficient in performance, but more convenient to program. In this pattern, the parent task blocks until its children complete, as shown in step C of Figure 9-2.
The convenience comes with a price. Because the parent blocks, its thread’s stack cannot be popped yet. The thread must be careful about what work it takes on because continual stealing and blocking could cause the stack to grow without bound. To solve this problem, the scheduler constrains a blocked thread such that it never executes a task that is less deep than its deepest blocked task. This constraint may impact performance because it limits available parallelism and tends to cause threads to select smaller (deeper) subtrees than they would otherwise choose.