
Chapter 6. Detailed Defense Approaches
We have seen how DDoS attacks are waged, starting with the first phase (recruitment of a large number of hosts through remote compromise and establishment of a command and control coordination infrastructure), then moving into the second phase, the actual DDoS attacks (wielding this set of refitted attack computers to implement a series of debilitating attacks on various network-attached computer systems).
In Chapter 5, we saw a high-level view of defense tactics that addresses both of these two phases. Right away it should start to become clear that there simply is no single “solution” that addresses both of these phases. There cannot be a single solution to such a diverse set of problems. There is, instead, an overlapping set of “solutions” (plural) that must be woven together in order to address all aspects of information assurance: the goals of integrity, availability, and confidentiality of information systems by operational implementation of protection, detection, and response capabilities.
6.1 Thinking about Defenses
Some of the defense approaches discussed in Chapter 5 are available for deployment in real networks today, as part of open source security applications and practices, as well as commercial DDoS defense systems. Other approaches are still being examined through research prototypes and simulations and are not available for immediate deployment. But the DDoS threat is here today and must be countered. What can you do to make your networks less susceptible to DDoS attacks? If your site is being used to attack someone else, how do you detect this and respond? And if you are a victim of such an attack, what can you do with the technology and tools available today to minimize your damages?
While the problem of defending against all possible DDoS attacks is indeed extremely hard, the majority of the attacks occurring today are very simple. The reason for this is the lack of awareness of the DDoS threat in many potential target networks, the poor level of preparation, and the absence of even simple defense measures. Since many potential targets are “sitting ducks,” there is no need for sophistication—simple attacks do as much damage and they are easily performed. A typical DDoS attack today can be quickly foiled by a few timely preparations, the use of some available tools, and quick intelligent action by network operations staff. All three components are necessary to achieve effective defense. Preparations close obvious security holes and minimize reaction time when an attack occurs, supplying already devised response procedures. Commercially available or homegrown DDoS defense tools fend off known or simple attacks. Informed and well-trained network staff are required to deal with stealthy attacks that bypass the first two defense measures.
This chapter gives you some guidelines on how to avoid falling prey to the gardenvariety DDoS attacks being launched today, and also tells you what to do if you do become the victim of a DDoS attack. Even though attackers are constantly improving their strategies, the defense measures described here will always improve your survival chances.
This book alone is not enough. In fact it is just the beginning of a long path of learning the tools and tactics of those who would attack you, and developing all the necessary skills—both technical skills with defensive tools and strategic and tactical thinking skills—that will allow you to operate within your attacker’s “OODA loop” [Boy] and gain the upper hand in an attack (as mentioned at the end of Chapter 4). Other resources that you may wish to consult in learning the tools and techniques of both attackers and responders include [Hon04], with chapters on Unix forensics, Windows forensics, network forensics, and reverse engineering; [Naz03] on strategies against worms with details on the relationship between worms and DDoS, as well as both network- and host-based detection and defense strategies that are shared with DDoS tools; [Bej04] on network security monitoring, which covers a plethora of network traffic analysis tools and techniques; and [Car04] describing Windows forensics tools and techniques in great depth, including tools written by its author.
In this chapter we will also mention many Unix and Windows commands and settings. Having on hand a good book on system administration and system tuning for your particular flavor of Unix or Windows, your routing hardware, etc., would also be advisable. You should also ask the vendors of your hardware and software products about security-specific resources they produce. Many vendors have security sections of their Web page that include security tools, online documents covering secure implementation and management practices, security feature lists and comparisons, and even multimedia security training CD-ROMs or DVDs.
While the majority of attacks are simple, there are still the more advanced attacks that must be dealt with, and these are occurring at a higher frequency due to advanced attack tools like Phatbot. Phatbot is an advanced “blended threat” that includes a vast array of features, which are described in detail in Chapter 4. Networks of tens of thousands of hosts can be easily set up, and detection and cleanup of these bots can be very difficult. Training, the use of network flow monitoring (or DDoS mitigation) tools, the information provided in this chapter, the books referenced above, and some practice will allow your site to deal with this threat.
DDoS defense is an arms race—new attacks produce better defenses, which in turn entice attackers to work harder. In the future, your network may need new defense mechanisms, but the ones presented in this chapter will never be obsolete. Consider them as the foundation of your resilience to DDoS attacks. Without these, sophisticated defense mechanisms you may purchase will be like a fancy roof on a house without a solid foundation—decorative, but providing little real protection.
As discussed in Chapter 5, the design of an effective DDoS defense involves several very hard challenges. A defense system must be able to differentiate between legitimate and attack traffic, so that its response can be selective. In simple attacks, the traffic is generally somewhat differentiable from legitimate traffic, but you must be prepared to find those differences, either manually or automatically. You must strike a balance between gathering enough information to characterize the attack and not overloading your logging and analysis capabilities.
Another obstacle to designing an effective defense is the variability of the threat. A good defense system must catch the majority of the attacks, while yielding low levels of false alarms. Nothing forces attackers to generate one type of packets, or use specific packet contents, limit spoofing to certain addresses or generate packets of only a certain length, or to set an “evil bit” [Bel03] in the header of their packets to warn firewalls that these are malicious. Anything is fair game, as long as it seems legitimate, or is simply too much to handle. In particular, if you stop a DDoS attack based on one type of traffic, an observant attacker might—and in many cases will—switch to another, or may even mix or randomize her attack. Be prepared to alter your defenses accordingly.
The distributed nature of the threat makes localized solutions ineffective against some possible attacks. However, these solutions are still very effective against many real-world attacks. In practice, with today’s technology most available defenses must be located close to the victim. Pushing the defenses further into the Internet core and closer to the attack sources potentially reduces collateral damage, but does not fit today’s typical business models for deploying network defenses. Remote networks are generally unwilling to deploy systems that do not bring them direct benefit. Furthermore, since the attack is distributed, many deployment points may be needed to handle it completely. Enforcing wide deployment of any service in the Internet is infeasible in the short term. Even if the service is cooperative (e.g., when tracing attack packets), this raises policy issues [Lip02].
Defensive systems located near the target can themselves be easily overwhelmed by a sufficiently large attack. Consider how much traffic your defense system can handle when determining if it will be sufficient for your needs, since any attacker who exceeds this capacity is likely to be successful, regardless of the sophistication and power of your defenses. To assist in constructing a layered defense, there are many common practices and defense techniques that have been very effective in increasing resilience to attacks, handling specific attack types, and minimizing damages. The report of the Distributed-Systems Intruder Tools Workshop [CER99] held in 1999 gives a useful listing of best security practices for managers, system administrators, Internet Service Providers (ISPs) and incident response teams.1 There are simple and straightforward steps you can take to fortify your network and make it robust and self-contained, so that it does not become easy prey. There are monitoring techniques that help you discover if you are a victim or a source of DDoS attack. If you have prepared in advance, there are approaches that will weather many DDoS attacks and minimize your damages. A determined attacker with a lot of time and resources may still be able to hinder your operation, but it will be much harder.
6.2 General Strategy for DDoS Defense
Regardless of whether your site is the victim of a DDoS attack, is being used as a stepping stone by attackers to anonymize their activity, or is hosting DDoS agents or handlers, the general defense strategies are the same. These strategies tend to fall into the classic Protect, Detect, and React categories, mirroring the general incident response life cycle [CERc, HMP+01]:
1. Preparation. It is important to understand how your network operates and have tools in place to perform both host- and network-level data capture and analysis, have procedures established in advance, and practice using the tools. Many preparation techniques that aim at understanding and strengthening your network will, in fact, protect you against simple attacks.
2. Detection. Not all attacks will cause your network to fail, so if complete failure is the only way to know when a problem exists, only the most severe problems will be detected and a larger percentage of incidents will go completely unrecognized. These unrecognized incidents can still be harming your operations and may also serve as a sign that you have an enemy out to get you. If he fails now, he might improve his attack and succeed later. Measures should be in place to detect a range of activities, with logs kept for a sufficient period of time to support forensic analysis tasks. Flow logging, for example, can also be used to detect stepping stones and multiple-system intrusions, and deal with a host of serious attacks on your network (we will discuss one tool, SiLK, in a moment). Intrusion Detection Systems (IDSs) can also add to the visibility of malicious activity on the network, and can be tuned in an emergency to watch for specific aspects of DDoS networks (e.g., command/control traffic, use of specific protocols or ports, or connections to/from specific suspect network blocks) [ACF+99].
3. Characterization. It often does not take very much captured traffic to determine the kind of DDoS tool in use. Many analyses exist of common tools [Ditf, Dith, CERb, Ditg, CER01b, DWDL, DLD00], which can guide incident response teams in understanding the role being played by hosts on their network, how the DDoS network functions, and how to efficiently communicate and cooperate with other sites. While removing agents from a specific network definitely helps DDoS response, the ultimate goal of characterization is to learn and share as much information about the attack as possible to help bring the entire DDoS network down. Any delay in gathering evidence and communicating it to law enforcement or other incident response teams and network providers can magnify the duration and significance of the damage inflicted by the attack.
Another aspect of characterization is to determine where the attack appears to be coming from. It may not be possible to trace the attack all the way back to even one of the agents, but it should be possible to trace the attack to ingress or egress points of your network and perhaps to peers or your upstream providers (or downstream customers, if you are an ISP). Provide the outside entities with as much of the information you have gathered to characterize the attack as possible, to help them do their own traceback and mitigation. They may be in a better position to get closer to the attacker, and this is critical information for law enforcement to use in their investigation, should it come to that.
4. Reaction. Your reaction may be to block traffic to stop the attack, identify compromised hosts and gather evidence, and do forensic analysis, or invoke contingency plans for dealing with a severe network outage. Having established procedures makes reaction easier and faster in a time of crisis, as well as establishing standards for investigation, documentation, and reporting. As mentioned earlier, use of detection capabilities to augment reaction will also produce a better result.
5. Postmortem analysis. After the attack, it is very important to review whether your procedures did or did not work, how well your network provider responded, which tools provided the best or worst assistance in responding, etc. Make sure that you integrate these lessons learned back into procedures, training of staff, and contract language for your provider. Do your best to understand how severe this attack was in relation to what it could have been, to identify potential weaknesses in your planning and mitigation procedures.
We will now look more closely at the tactics involved in preparing for and responding to DDoS attacks.
6.3 Preparing to Handle a DDoS Attack
As in any risk management activity, preparation is crucial. Understanding how your network is organized and how it works will help you identify weak spots that may be a target of the attack. Fortifying those weak spots and organizing your network to be robust and self-contained will hinder most simple attacks and minimize the damage that can be inflicted. Finally, preparing emergency procedures, knowing your contacts, and having multiple ways to reach them (including out-of-band, in terms of your network), will enable you to respond quickly to an ongoing attack and improve your chances of weathering it.
6.3.1 Understanding Your Network
The DoS effect usually manifests itself through large network delays and loss in connectivity. Depending on the targeted resource, your whole network may experience a DoS effect, or only specific services, hosts, or subnetworks may be unavailable. Understanding how your network functions will aid in risk assessment efforts by establishing:
• How important network connectivity is in your daily business operations
• How much it would cost to lose it
• Which services are more important than others
• The costs of added latency, or complete loss of connectivity, to your key services
Most businesses today rely on the public Internet for daily activities, such as e-mail, ordering supplies online, contacting customers, videoconferencing, providing Web content, and voice-over-IP services. Some of those activities may be critical for the company’s business, and may have no backup solutions. For instance, if supplies are ordered daily and must be ordered through online forms, or your company uses “voice-over-IP” exclusively for all business telephone calls, losing network connectivity may mean stalling the business for a few days. Other activities may have alternatives that do not require Internet access—e-mails can be replaced by telephone calls, videoconferencing by conference calls or live meetings; some activities can even be postponed for a few days. In this case, Internet access increases efficiency but is not critical for business continuity.
Some companies make their profit by conducting business over the Internet. Take, for example, a company that sells cat food through online orders. Certain products or services are at a higher risk of loss due to even short-duration DDoS attacks. These include:
• Products with a short shelf-life that must be sold quickly, such as flowers or specialized holiday foods
• Commodities that could easily be obtained from many sources, so customers would simply leave and go somewhere else if they cannot get immediate access, such as pornography
• Time-critical transactions, such as betting on sports events, stock trading, mortgage applications, news delivery and major media events, and event or transportation ticket sales
• Low-margin, high-volume purchases that require a constant transaction rate to maintain viability of the business, such as major online booksellers and airline ticket services
• Businesses that offer free services supported by advertising, such as search engines and portals
Network connectivity is a crucial asset in these business models, and losing connectivity means losing daily revenue (possiblya a lot of it). Additionally, if a company is well known, the fact that it was out of business for even a few hours can make headline news and damage its reputation—a fact that may lose them more business than a few hours of network outage.
The first step in risk assessment is making a list of business-related activities that depend on constant Internet access. Each item on the list should be evaluated for:
• Alternative solutions that do not require Internet access
• Frequency of the activity
• Estimated cost if the activity cannot be performed
In addition to costs relating directly to loss of connectivity, there may be hidden costs of a DDoS attack from handling extreme traffic loads, or diverting staff attention to mitigate the problem. In some cases, diverting attention and/or causing disruption of logging is a prime motivation of some DDoS attacks, overwhelming firewall or IDS logging to blind the victim to some other attack, or allowing a blatant action to go unnoticed. An attacker who wants to slip in “under the radar” can do so better if the radar screen is filled with moving dots.
For example, a DDoS attack may fill your logs. Logging traffic may amplify the DoS effect, clogging your internal network with warning messages. Understanding how your logging is set up will help you identify hot spots ahead of time and fortify them, for instance, by providing for more log space or sending log messages out of band.
Sophisticated DDoS attacks may manifest themselves not as abrupt service loss but as a persistent increase in incoming traffic load. This may lead you to believe that your customer traffic has increased and purchase more assets for handling additional load. Imagine your (or your stockholders’) disappointment when the truth finally becomes clear. You may be paying for something that is not even necessary due to the way your ISP charges you. If you pay per byte of incoming bandwidth, this cost will skyrocket in such a subtle, slowly increasing attack. Some ISPs will be willing to waive this cost, but others will not. Whether they do may depend on how long the situation existed before you noticed it. Understanding how conditions of your service agreement apply to the DDoS attack case ahead of time will enable you to negotiate the contract or change the provider. Other hidden costs include increased insurance premiums and legal costs for prosecuting the attacker. If your assets are misused to launch the attack on someone else, you may even face civil liability.
Once critical services are identified, it is important to understand how they depend on other services. For instance, e-mail service needs DNS to function properly. If e-mail is deemed critical, then DNS service is also critical and must be protected.
6.3.2 Securing End Hosts on Your Network
Preparation for dealing with both phases of DDoS attacks starts with addressing end-host security issues. These include reducing vulnerabilities that could result in compromise of systems, and tuning systems for high-performance and high-resilience against attack.
Reducing Vulnerabilities on End Hosts
While the most common strategy for creating the DoS effect is to generate excess traffic, if the target host has a software vulnerability, misusing it may take only a few packets that shut down the host and effectively deny service with much less effort and exposure to the attacker. There are many attacks that function this way. Additionally, all techniques for acquiring agent machines are based on exploiting some vulnerability to gain access. Fixing vulnerabilities on your systems not only improves your security toward many threats (worms, viruses, intrusions, denial of service), it also makes you a good network citizen who will not participate in attacks on other sites.
It is not uncommon today for applications and operating systems that run on end hosts and routers to have bugs that require regular patching and upgrading. Many vendors have an automatic update system to which you can subscribe. This system will inform you when new vulnerabilities have been discovered, and it will usually deliver patches and updates to your hosts, ready to be installed. For example, Microsoft maintains a Windows update Web site (http://www.windowsupdate.com) where users can have their machines scanned for vulnerabilities and obtain relevant patches and updates. Users subscribing to automatic Windows updates would have them delivered directly to their computer. Red Hat, a commercial Linux distributor, maintains a Web site with security alerts and bug fixes for current products at http://www.redhat.com/apps/support/errata/. Users can subscribe for automatic updates at http://www.redhat.com/software/rhn/update/. Other desktop systems, such as MacOS, also offer software update services.
Virus detection software needs to be frequently updated with new virus signatures. In many cases this can help detect and thwart intrusion attempts on your hosts and keep your network secure. Each major virus detection product comes with an option to enable automatic updates. If you enable this option, new virus signatures will be automatically downloaded to your machine. However, any kind of automatic action may inflict accidental damage to your computer because of incompatibility between the update and other installed software, or may be subverted by an attacker to compromise your computer. Automatic features should be carefully scrutinized and supported by a form of authentication and by backups and extra monitoring to quickly detect and react to failures.
Some protocols are asymmetric; they make one party commit more resources than the other party. These protocols are fertile ground for DDoS attacks, as they enable the attacker to create a heavy load at the target with only a few packets. The TCP SYN attack, discussed in Chapter 4, is one example, based on filling the victim’s connection table.
A modification of the TCP protocol, the TCP syncookie [Ber] patch (discussed in more detail in Chapter 5), successfully handles this attack by changing connection establishment steps so that server resources are allocated later in the protocol. This patch is compatible with the original protocol: Only the server side has to be updated. Linux, FreeBSD, and other Unix-based operating systems have deployed a TCP syncookie mechanism that can be enabled by the user (it is disabled by default). For instance, to enable TCP syncookies in Linux you should include “echo 1 > /proc/sys/net/ipv4/tcp_syncookies” in one of the system startup scripts. WindowsNT protects from SYN flood attacks by detecting the high number of half-open connections and modifying the retransmission and buffer allocation behavior, and timing of the TCP protocol. This option can be enabled by setting the parameter value HKLM→System→CurrentControlSet→Services→Tcpip→SynAttackProtect in the System Registry to 1 or 2. FreeBSD implements syncookie protection by default, but if you wanted to control this setting, you would use “sysctl -w net.inet.tcp.syncookies=1” to enable it.
An authentication protocol is another example of an asymmetric protocol. It takes a fairly long time to verify an authentication request, but bogus requests can be generated easily. Potential solutions for this problem involve generating a challenge to the client requesting authentication, and forcing him to spend resources to reply to the challenge before verifying his authentication request. Unfortunately, this requires clients that understand the challenge/response protocol, which might not always be possible. Other alternatives are to consider whether you really need to authenticate your clients or to perform a stepwise authentication by first deploying weak authentication protocols that provide for cheap verification and then deploying strong ones when you are further along in your interactions with the client. If you have a fixed client pool, a reasonable alternative is to accept authentication requests only from approved IP source addresses. In any case, strengthening your authentication service by providing ample resources and deploying several authentication servers behind a load balancer is a wise decision. Understanding how the protocols deployed on your network function, and keeping them as symmetric as possible, reduces the number of vulnerabilities that can be misused for DDoS attack.
Many operating system installations enable default services that your organization may never use. Those services listen on the open ports for incoming service requests and may provide a backdoor to your machine. It is prudent to disable all but necessary services by closing unneeded ports and filtering incoming traffic for nonexistent services. For instance, if a host does not act as a DNS server, there is no need to allow incoming DNS requests to reach it. This filtering should be done as close to the end host as possible. For example, ideally you would filter at the host itself, using host-based firewall features (such as iptables or pf on Unix systems or personal firewall products on Windows or MacOS). This is the easiest place, resource-wise, to do the filtering but has implications if you do not control the end hosts on your network. Filtering at the local area network router (i.e., using a “screened subnet” style of firewalling) would be a good backup and is one way of implementing a robust layered security model. If your network has a perimeter firewall (which is not always the case), traffic can be blocked there as well. Trying to block at the core of your network, or at your border routers, may not be possible if your network design does not provide for sufficient router processing overhead (and this also violates the spirit of the end-to-end network design paradigm). To discover services that are currently active on your hosts, you can look at list of processes or a list of open ports or do a ports can using, for instance, the nmap tool—an open source vulnerability scanner freely downloadable from http://www.insecure.org/nmap/index.html. If you opt for port scanning, be advised that some types of scans may harm your machines. Inform yourself thoroughly about the features your port scan tool of choice supports and use only the most benign ones that do not violate protocols and scan at moderate speed.
Many DDoS attacks employ IP spoofing, i.e., faking the source address in the IP header to hide the identity of actual attacking agents. This avoids detection of the agent and creates more work for the DDoS defense system. It is a good security measure to deploy both ingress and egress filtering [FS00] at your network perimeter to remove such spoofed packets. (Because “ingress/egress filtering” can be a confusing concept, please refer to the descriptions in Chapter 4 and Appendix A.) As seen by an edge network, antispoofing egress filters remove those outgoing packets that bear source addresses that do not belong to your network. The equivalent ingress filters similarly remove those incoming packets that bear source addresses that belong to your network. Both of those packet address categories are clearly fake, and many firewalls and routers can be easily configured to perform ingress/egress filtering (as well as other types of filtering). Advanced techniques for elimination of spoofed addresses include detecting source addresses from those network prefixes that are reserved and filtering them from your input stream, or using a list of live internal network addresses to allow only their traffic to get to the outside world.
In general, fixing vulnerabilities raises the bar for the attacker, making him work harder to deny service. It protects your network from specific, low-traffic-rate attacks. In the absence of vulnerabilities that could quickly disable network services, the attacker instead must generate a high traffic rate to overwhelm your resources.
Tuning System Parameters
Beyond just fixing vulnerabilities, one of the first things that should be done in cases in which a DDoS attack is affecting a service or end system—but is not large enough to cause noticeable network disruption—is to ensure that the target of the attack is adequately provisioned and tuned. Even in cases in which DDoS mitigation tools are in place at the perimeter of your network, and are functioning as they should to scrub incoming packets and ensure that only “legitimate” requests are coming in, the server may still be overwhelmed and cease to function.
Examples of things to look for include:
• Processor utilization. Programs like top, ps, and vmstat are useful for checking processor utilization. The uptime program also shows processor load averages. If those programs indicate a single application that is consuming an unusually high amount of CPU time (e.g., 90%) this may be a vulnerable application targeted by a DoS attack. You will need to keep a model of normal CPU utilization to quickly spot applications gone wild due to vulnerability exploits or specifically crafted attacks.
• Disk I/O performance. Disk I/O performance can be determined using programs like vmstat, iostat, and top. If you are using NFS, the nfsstat program should be used. Tuning of IDE drives can be accomplished on Linux systems using hdparm. If disk-monitoring programs, such as iostat, indicate unusually high disk activity, this may be a vulnerable application under attack. Again, you will need a model of normal disk activity to be able to spot anomalies.
• Network I/O performance. If the network interface is saturated or there are other problems on the Local Area Network (LAN) segment, you may see dropped packets or a high rate of collisions. You can see these using the statistics option of netstat. Network socket state information can also be seen with netstat. If netstat indicates that you are experiencing a significant number of dropped packets and collisions when no attack is under way, then you are already running close to capacity. An attacker can tip you over into an overload situation by adding a rather small quantity of traffic. You need to improve the bandwidth on the highly utilized links if you want to avoid falling easy prey to DDoS. This observation is most important for those links that are publicly accessible. A fairly congested link on a purely internal LAN that does not directly accept traffic from the outside network is less of a risk for a DDoS attack than the same situation on the main link between your subnetwork and your ISP.
• Memory utilization. If memory is low, use ps and top to determine which programs have the largest Resident State Sizes (RSS). You may need to kill some of them off to free up memory. Memory is very cheap these days, so make sure that you have as much as your motherboard and budget can afford. If you cannot increase memory, yet still have problems with memory utilization, consider upgrading your hardware.
• Swapping/paging activity. Paging is a normal activity that occurs when portions of a program that are necessary for execution must be brought in from disk. Swapping occurs when physical memory is low and least-recently used pages of programs are written out to disk temporarily. Because disk speed is far slower than memory, any reading or writing of the disk can have significant performance impacts. You can check on paging and swapping activity and swap utilization using vmstat, top, or iostat.
• Number of server processes. Web servers typically have one process responsible for listening for new connections, and several child processes to handle actual HTTP requests. If you have a very high rate of incoming requests, you may need to increase the number of server processes to ensure that you are not overloading the existing processes and delaying new requests. Use top, ps, and netstat to check for overloading of server processes.
Tuning system parameters will help protect your network from small- to moderaterate attacks, and in-depth monitoring of resource usage should ensure better detection of attacks that consume a large amount of resources.
6.3.3 Fortifying Your Network
In addition to securing the hosts on your network, there are also things you should do to improve the security of the network as a whole. These include how the network is provisioned and how it is designed and implemented.
Provisioning the Network
A straightforward approach to handle high traffic loads is to buy more resources, a tactic known as overprovisioning. This tactic is discussed in detail in Chapter 5. There are many ways in which overprovisioning can be used to mitigate the effects of a DDoS attack.
The problem here, from a cost perspective, is the asymmetry of resources. There is very little or no cost for an attacker to acquire more agent machines to overwhelm any additional resources that a victim may employ, while the victim must invest money and time to acquire these added resources. Still, this technique raises the bar for the attacker and will also accommodate increased network usage for legitimate reasons.2
One form of overprovisioning has to do with available network bandwidth for normal traffic. This approach is taken by many large companies that conduct business on the Internet. The attacker looking to overwhelm your network with a high traffic load will either target the network bandwidth by generating numerous large packets of any possible type and contents, or he will target a specific service by generating a high number of seemingly legitimate requests. Acquiring more network bandwidth than needed is sometimes affordable, and makes it less likely that bandwidth will be exhausted by the attack. A well-configured network-level defense system sitting on this highly provisioned link will then have a chance to sift through the packets and keep only those that seem legitimate
Another form of overprovisioning is to have highly resourced servers. This can be (1) keeping hosts updated with the fastest processors, network interfaces, disk drives, and memory; (2) purchasing as much main memory as possible; or (3) using multiple network interface cards to prevent network I/O bottlenecks. Further, duplicating critical servers and placing them in a server pool behind a load balancer multiplies your ability to handle seemingly legitimate requests. This may also prove useful for legitimate users in the long run—as your business grows your network will have to be expanded, anyway. Performing this expansion sooner than you may otherwise plan also helps withstand moderate DDoS attacks.
These two forms of overprovisioning can be combined in a holistic manner, ensuring fewer potential bottlenecks in the entire system. In the electric sector, for example, sites are required to have nominal utilization rates for the entire system that are no larger than 25% of capacity, to provide an adequate margin of unused processing capacity in the event of an emergency. This minimizes the chances that an emergency situation causes monitoring to fail, escalating the potential damage to the system as a whole.
If your network management and communication to the outside world is done in-band over the same network as potential DDoS targets, (e.g., if you use voice-over IP for your phone line), the DDoS attack may take out not only your services, but all means of communicating with your upstream provider, law enforcement, vendors, customers—in short everyone you need to communicate with in a crisis. The added cost of purchasing extra bandwidth can be viewed as a cheaper form of insurance.
Designing for Survivability
Since some DoS attacks send a high amount of seemingly legitimate requests for service, techniques that improve scalability and fault tolerance of network services directly increase your ability to weather DDoS attacks. Designing for survivability means organizing your network in such a way such that it can sustain and survive attacks, failures, and accidents (see [EFL+99, LF00]). Sometimes, adding survivability provisions has surprising benefits in protecting against unexpected events [Die01].
Survivability design techniques include:
• Separation of critical from noncritical services. Separating those services that are critical for your daily business from those that are not facilitates deployment of different defense techniques for each resource group and keeps your network simple. Separation can occur at many levels—you can provide different physical networks for different services, connect to different service providers, or use subnetting to logically separate networks. A good approach is to separate public from private services, and to split an n-tier architecture into host groups containing Web servers, application servers, database servers, etc. Once resources are separated into groups, communication between resource groups can be clearly defined and policed, for instance, by placing a firewall between each pair of groups.
• Segregating services within hosts. Rather than assigning several services to a single host, it is better to use single-purpose servers with well-defined functionality.
As an example of segregated services, having a dedicated mail server means that all but a few ports can be closed to incoming traffic and only a few well-defined packet types should be exchanged between the server and the rest of the network. It also means that monitoring server operation and detecting anomalies will be simplified. Having several services assigned to a single host not only makes monitoring and policing difficult, but finding and exploiting a vulnerability in any of these services may effectively deny all of them.
An advanced alternative for segmenting services that addresses just the issue of process separation is to use highly secure operating systems such as SELinux or TrustedBSD which implement Mandatory Access Control (MAC) for processes.3 This will not help very much for DDoS mitigation, however, unless these systems are also configured not just to use MAC, but to also limit particular services to maximum usage of particular system resources. If both a DNS service and a Web server are run on such a machine and the Web service receives many seemingly legitimate requests that take a long time to process, MAC will state that all of them should get service. After all, the Web server must be permitted to do such things in its legitimate operations. Only enforcement of QoS guarantees for the DNS server by the OS can prevent the Web requests from eating up all the machine’s resources and starving the DNS server.
• Compartmentalizing the network. Identifying bottlenecks in the risk assessment step should provide guidelines for reorganizing the network to avoid single points of failure. Dividing the network into self-contained compartments that communicate with the outside only when necessary enables your business to continue operation even when some portions of the network are down. For example, having a database server distributed across several physically disjoint networks that connect to the Internet via different ISPs may require a lot of management, but may enable you to continue serving database requests even if several servers are targeted by the attack or their incoming links are overwhelmed. Having a mail server for each department may mean that when the finance department is under attack, employees from the planning division can still send and receive e-mails. As always, decisions about which services to replicate and to what extent demand detailed cost/benefit analysis.
• Reducing outside visibility. If attackers are able to learn your network organization, they can also assess the risks and identify bottlenecks that can be targeted by the attack. There are numerous techniques that aid in hiding the internals of your network. Blocking ICMP replies to outside hosts prevents attackers from learning your routing topology. Using a split DNS effectively creates two separate DNS zones for your network with the same DNS names. One zone will contain a list of externally visible services that can be accessed through the firewall. Your external DNS server will serve this zone. Your external customers will be able to access only the external DNS server and will see only this list of services. Another zone will contain a list of internally accessible services that are available to your employees. This zone will be served by your internal DNS server. Your employees’ machines will be configured with the address of the internal DNS server and will access these services through your internal network. Separating this information minimizes the data you leak about your internal network organization. It also provides separate access paths for external and internal clients, enabling you to enforce different policies.
Network Address Translation (NAT) hides the internals of the network by providing a single address to the outside clients—that of the firewall. All outside clients send their requests for service to the firewall, which rewrites packets with address of the internal server and forwards the request. Replies are similarly rewritten with the firewall’s address. This technique creates a burden on the firewall and may make it a single point of failure, but this problem can be addressed by distributing firewall service among several routers. Generally, if attackers can only see a large, opaque network, they must either attack the ingress points (which are probably the most capable and highly provisioned spots, and thus the easiest to defend) or use e-mail or Web-based attacks to gain control of a host inside the perimeter and tunnel back out.
6.3.4 Preparing to Respond to the Attack
Having a ready incident response plan and defense measures that you can quickly deploy before the attack hits will make it easier to respond to the attack. Further, knowing who to contact for help will reduce your damages and downtime.
Responding to the attack requires fast detection and accurate characterization of the attack streams so that they can be filtered or rate limited. Devising detailed monitoring techniques will help you determine “normal” traffic behavior at various points in your network and easily spot anomalies. Detection, characterization, and response can be accomplished either by designing a custom DDoS defense system or by buying one of the available commercial products.
You should choose wisely how you configure and use a DDoS defense mechanism. For example, if you choose to make its actions fully automated, an attacker may be able to exploit the unauthenticated nature of most Internet traffic (at least traffic that does not use IPSec Authentication or Encapsulation features) to trick the DDoS defense system into acting incorrectly and producing a DoS effect that way. Assume an attacker knows that your site uses a DDoS defense mechanism that does not keep state for UDP flows, and that you have it configured to automatically block inbound UDP packet floods. She also knows that many of your users frequent Web sites that rely on some company’s distributed DNS caching service. The cache provider has thousands of DNS servers spread around the Internet, which the attacker can determine by having her bots all do DNS lookups for the same sites and storing the results. DNS typically uses UDP for simple requests. Putting these facts together, the attacker could forge bogus UDP packets with the source address of all of the DNS caching service’s servers, sending them all to random IP addresses at your site. Depending on how the DDoS defense system is programmed, it might assume that this is a distributed UDP flood attack and start filtering out all UDP traffic from these thousands of “agents” (really the caching DNS servers), preventing your users from getting to any Web sites served by this DNS cache provider, because their DNS replies are blocked as they come back.
Fully manual operation has its own problems. The reaction time can be significantly slowed, and in some cases a slow defense may cause more problems than it solves. The network operations and security operations staff should both well understand the capabilities and features of the DDoS mitigation system and how best to deploy and control it. Appendix B offers a detailed overview of some currently available commercial products. This should serve only as an introduction to a wide variety of security products that are currently available. The reader is advised to investigate the market thoroughly before making any buying decisions.
Creating your own DDoS defense system generally makes sense only for large organizations with sophisticated network security professionals on staff. If your organization has those characteristics, a careful analysis of your system’s needs and capacities might allow you to handcraft a better DDoS solution than that offered by a commercial vendor. Building a good defense solution from scratch will be an expensive and somewhat risky venture, however, so you should not make this choice lightly. If you do go in this direction, make sure you have a thorough understanding of all aspects of your network and systems and a deep understanding of DDoS attack tools and methods, as well as the pros and cons of various defensive approaches.
It is also important to balance the requirements of the network operations and security operations staff. Many sites separate these groups, often having an imbalance of staffing and resources dedicated to building and supporting the complex and expensive network infrastructure vis-à-vis handling security incidents and mitigation at the host level. Having these groups work closely together and share common goals improves the situation and causes less internal friction.
Many sites with large networks and high bandwidth costs are now purchasing or implementing traffic analysis tools, but often more with an eye toward cost containment and billing, as opposed to security. When an attack occurs, there is sometimes a distinct issue of not having visibility below the level of overall bandwidth utilization and router/switch availability statistics. There may not be flow- or packet content–monitoring tools in place, or the ability to preserve this data at the time of an attack to facilitate investigation or prosecution. Network traffic analysis is a critical component of response. It is said that one person’s DoS attack is another person’s physics experiment dataset.
There may also be a lack of tools, such as network taps, systems capable of logging packets at the network borders without dropping a high percentage of the packets, or traffic analysis programs. These tools, and the skills to efficiently use them, are necessary to dig down to the packet level, identify features of the attack and the hosts involved, etc. Many high-profile attacks reported by the press have been accompanied by conflicting reports of the DDoS tool involved, the type of attack, or even whether it was a single attack or multiple concurrent attacks. In some cases, sites have believed they were experiencing “Smurf” (ICMP Echo Reply flood) attacks inbound, because they saw a spike in ICMP packets. In fact, some host within their network was participating in an attack with an outbound SYN or UDP flood that was well within the normal bandwidth utilization of the site, and they were getting ICMP replies from the target’s closed port. In other cases “attacks” have turned out to be misconfigured Web servers, failed routers, or even a site’s own buggy client-side Web application that was flooding their own servers!4
Investing in backup servers and load balancers may provide you with assets that you can turn on in case of an emergency. Backup servers can take the load off the current server pool or can supplement hosts that are crashing. Of course, there is a cost to having spare equipment lying around, and an attack may be over by the time someone is able to reconfigure a server room and add in the spare hardware. If you provide static services, such as hosting Web pages or a read-only database, it may be possible to replicate your services on demand and thus distribute the load. Service replication can even help if you deliver dynamic content. Contracting with a service that will replicate your content at multiple network locations and transparently direct users to the nearest replica provides high resiliency in case of a DDoS attack. Since these services are themselves highly provisioned and distributed, even if they are successfully attacked at one location, the other replicas will still offer service to some of your clients. The downside to such highly provisioned and distributed services is an equally high cost. This option may be viable financially for only very large sites. Very careful risk analysis and cost/benefit calculations are necessary, as well as investigation of alternatives for a disruption of business operations, such as insurance coverage.5 Another consideration is that while replication services are highly provisioned, they may themselves be taken down by a sufficiently large attack, so this approach is not a panacea.
Another alternative is to consider gracefully degrading your services to avoid complete denial. For instance, when a high traffic load is detected, your server can go into a special mode of selectively processing incoming requests. Thus, some customers will still be able to receive service.
If the DDoS attack targets network bandwidth, no edge network defense will ameliorate the situation. Regardless of sophisticated solutions you may install, legitimate users’ packets will be lost because your upstream network link is saturated and packets are dropped before they ever reach your defense system. In this situation, you need all the help you can get from your upstream ISP, and perhaps also their peers, to handle the problem.
Cultivating a good relationship with your ISP ahead of time and locating telephone numbers and names of people to reach in case of a DDoS attack will speed up the response when you need it. Many ISPs will gladly put specific filters on your incoming traffic or apply rate limiting. Be aware of the information you need to provide in order to get maximum benefit from the filtering. Sometimes it may be necessary to trace the attack traffic and have filters placed further upstream to maximize the amount of legitimate traffic you are receiving.6 This usually involves contacting other ISPs that will generally be unwilling to help you, given that you are not their customer. If you have a good relationship with your ISP, they will be in a far better position to negotiate tracing with their upstream peers. Specifying the responsibilities and services your ISP is willing to offer in case of DDoS attack in a service agreement will also simplify things once an attack occurs.
6.4 Handling an Ongoing DDoS Attack as a Target
Handling an ongoing DDoS attack on your network requires you to detect it, characterize the attack streams, and apply mitigation techniques. Detecting the attack is usually automated either through standard network-monitoring software or through a commercial DDoS defense system. While the attack will undoubtedly be detected once your services are crippled, early detection will provide more time for response and may even make the occurrence of the attack transparent to your customers.
Choosing a set of parameters to monitor for anomalies directly affects detection accuracy. You can choose to monitor levels of the incoming network traffic, the number of external clients with active requests (to spot the occurrence of IP spoofing), client behavior, server load, server resources, etc. A properly chosen set of parameters will not generate too many false positives, while still detecting the majority of the attacks early.
Once detected, the attack should be characterized as narrowly as possible. This includes: identifying network protocols, applications, and hosts that the attack targets; identifying source addresses used in attack packets, packet length, contents, etc.; identifying detailed attack characteristics facilitates setup of precise filtering and rate-limiting rules. This is where the border-level network-monitoring tools and skills, mentioned in the previous section, really pay off.
Mitigation techniques involve contacting your ISP and providing attack characteristics, and deploying filtering and rate limiting at your border routers, DMZ router, or firewall (if the target is within a perimeter defense). Predeploying load balancers and having hardware available, in an emergency, to increase server capacity can also be of use but is expensive and may take hours or days to implement (depending on where the hardware and staff are located in relationship to the network being attacked). Redirection of traffic through routing configurations may ease such topology or resource allocation changes.
If you have purchased a commercial DDoS defense system, many of those will automatically devise appropriate filtering rules that your network operations staff can then choose to deploy. Some systems can even be instructed to respond autonomously, without human supervision. They will deploy filters and notify the system administrator after the fact. If you use one of these systems, it would be wise for your administrators to keep a careful eye on any filters that is reports deploying, both to be aware of actual attacks and to ensure that the system is not mistakenly filtering legitimate traffic, as described earlier. There is a distinct possibility that a self-inflicted denial of service could result from a skillful attack.
Taking a close look at the attack packets may reveal weaknesses in the attack that can be used for effective response. For example, do all attack packets target the same server? If so, it may be possible to change the IP address of the server.
Many DDoS attack tools are poorly designed and may omit DNS lookup and hardcode your server’s IP address in the attack script. A simple change of IP address will cause all the attack packets to be dropped at the last hop. Then, enlisting help from your ISP, a simple filtering rule deployed upstream should completely relieve your network of the flood. ISPs can further attempt to trace back the flood and stop it at the entry point to their network.
Realize, however, that this address mapping change technique may not work as desired if some clients have cached the mapping. This is likely to happen if the server’s IP address is listed in public DNS records. Clients that have cached these records will receive a mapping to the old address that is being attacked and will thus still suffer the DoS effect. Sometimes the application itself can get around the DNS caching issue (some Web application services can do this).
UUNET’s backbone security engineers claim to have had great success using a technique they have developed, called backscatter traceback [GMR01], for tracing flood traffic with forged source addresses back to its ingress points into UUNET’s network cloud. The technique leverages several “tricks of the trade” that may be adopted by other network service providers to implement a similar capability. (In a very abstract and succinct fashion, the technique works by injecting a fault into the network and observing the effects on the smallest set of traffic illustrated in Figure 6.3 as it bounces off the artificial fault.) Note that the examples provided by UUNET assume functionality provided by Cisco routers.
The first step is to keep a black hole route (“route to Null0”) installed on each of the network provider’s routers so that it can be invoked quickly as needed. For example, a single IP address out of the IANA special-use prefix TEST-NET, say 192.0.2.1, can be used for this purpose, as it will never appear as a valid address in the Internet. A static route is established on each router that sends all traffic destined for 192.0.2.1 to the Null0 interface, effectively dumping the traffic. Normally, no traffic follows this route.
The next step is to configure a BGP-speaking router so that it can be used to quickly disseminate a route update to all routers whenever the need arises to black hole a real network, whether a single address or a larger network address block. A route map is used to set the next hop of matching tagged routes to the null-routed address 192.0.2.1.
When an address needs to be black-holed, a static route for the target address is installed on the above router with a tag that causes it to be processed by the route map. This static route will be propagated via the BGP routing protocol to the rest of the service provider’s routers, who will now have Null0 as the next hop for the target address. Thus, all of the service provider’s routers will be instructed to drop all traffic to the target address at all ingress points, effectively black-holing the address at the network edge. Operationally, the main feature of all this is to allow a black-hole route on all edge routers to be remotely triggered from a single control point via BGP.
Another necessary step is to establish a sinkhole network (i.e., a router designed to withstand heavy flood traffic to which attack traffic can be redirected for study). Attached to this router should be a workstation (e.g., the sensor in Figure 6.2) of sufficient capacity to capture and analyze the redirected attack traffic.
As mentioned above, the sinkhole BGP router advertises TEST-NET as the next hop for the target address, causing all incoming traffic destined for the target to be redirected to the Null0 interface.
The final step is to configure the sinkhole router to advertise itself as the next hop for a block of unallocated IP address space. (UUNET recommends using 96.0.0.0/3, as it is the largest unallocated address block on the planet.) The assumption here is that the flood traffic’s forged source addresses will occasionally fall within this unallocated range, as they often do when the flood tool generates packets with randomly chosen source IPs. This route is advertised to all of the service provider’s other routers, constrained by BGP egress filtering to guarantee that the route does not leak outside of the service provider’s realm. This causes all the service provider’s routers to reflect any outbound traffic destined for the unallocated range back to the sinkhole network.
We now describe in detail the backscatter using Figure 6.1. When attack traffic has been noticed, the service provider performs the following steps:
1. The sinkhole router is configured to advertise a new route for the target machine with a next hop of the TEST-NET host address. The route propagates via BGP to all of the other routers, causing all incoming attack traffic to be (temporarily) blackholed at the network edge. This causes the target to be completely unreachable for the duration of this analysis. In practice, UUNET has found that redirecting the target’s traffic for 45 seconds is usually enough to capture sufficient evidence for a correct traceback to occur.
2. Another static route is added to the sinkhole router to redirect any 96.0.0.0/3 traffic to the sinkhole network. This route is also propagated to all of the other routers.
3. As the packets headed for the target, including both the legitimate packets and the spoofed attack packets, are dropped by the service provider’s edge, ICMP Unreachable messages are generated by the edge routers and sent to the source addresses. This is referred to as backscatter.
4. Any attack traffic entering the service provider’s network with a forged source address from the 96.0.0.0/3 block will cause the edge routers to generate ICMP Unreachable messages destined for the forged source addresses in 96.0.0.0/3.
5. The ICMP Unreachable messages destined for 96.0.0.0/3 will be redirected to the sinkhole network. The sinkhole network’s router is configured to log incoming ICMP Unreachable messages.
6. These log messages include the source address of the edge router that generated the ICMP Unreachable message (i.e., the ingress point of the flood traffic). The traceback to the service provider’s ingress point(s) is now complete. Figure 6.1 shows three such ingress points. Figure 6.2 shows further traffic analysis by a sensor.

Figure 6.1. Network with attack traffic. (Reprinted with permission of Barry Greene.)
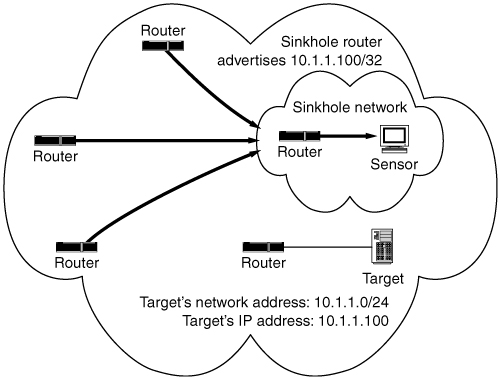
Figure 6.2. Attack traffic redirected to sink hole network. (Reprinted with permission of Barry Greene.)
The ISP now knows precisely which of its routers need to install defense measures (such as filtering or rate limiting) to control a long-term DDoS attack, while minimizing collateral damage to the victim and other nodes.
Note that this technique relies heavily on the assumption that the distribution of the attack traffic’s forged source addresses is spread randomly over the entire IP space. The technique will be thwarted by attack traffic crafted to avoid using the unallocated space being monitored by the sinkhole network. This avoidance can be mitigated by the service provider in some cases by analyzing the attack traffic for other patterns in source address distribution and redirecting a different unallocated address range accordingly. However, a clever attacker who chooses forged IP addresses only from the allocated range of IP addresses will be able to avoid this form of tracing entirely (see Figure 6.3 for an overview of traffic classes). The technique is thus imperfect, although in practice it may work successfully in the majority of cases.
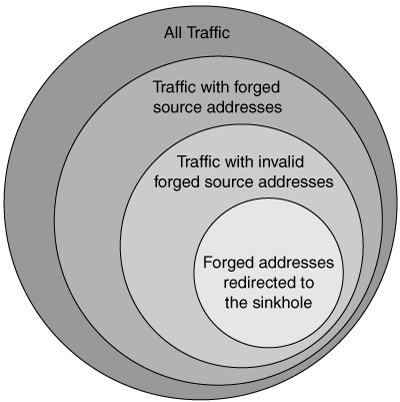
Figure 6.3. Classes of traffic directed at target
6.5 Handling an Ongoing DDoS Attack as a Source
Since DDoS attacks occur regularly, this indicates that either agent-hosting sites do not care enough about their machines participating in attacks to bother stopping them, or the bandwidth available to these sites may be so great that they may not even notice the flooding. Sites should care, however. Being a good network citizen will make everyone’s experience of the Internet better, and only if most online participants behave responsibly will the Internet continue to be useful. If that rationale does not sway you, consider that hosting an agent is a sure sign that your network has been compromised. In addition to participating in an attack on others, your own network and assets are at risk, and prudence dictates that you should investigate and clean up this problem.
Finally, there is a growing level of discussion of liability issues surrounding due care taken by those whose sites are used for an attack. If sufficient financial damage is incurred by a victim, and if the victim can trace the attacks back to one or more sites that are primarily responsible, then those sites may get sued. The liabilities range from failing to secure one’s computers from intrusion to failing to stop an attack in progress. The sites may be found negligent for not stopping an attack, regardless of whether the attack affects their own network availability. They may also be charged with obstruction of justice by destroying evidence if they have been informed of an attack and potential legal action, yet still wiped the disks of compromised hosts and reinstalled the operating system. (The topic of liability is discussed in more depth in Chapter 8.)
The first step in handling a DDoS attack as a source is to detect that it is happening. This can in general be done by triggering an alarm whenever you notice a high outgoing traffic rate targeting a single destination or a small set of machines. While the attacker may in principle deploy numerous agent machines, instructing each of them to generate only a few packets, typical DDoS agents flood with all their might and create large traffic loads. Thus, monitoring the outgoing traffic rate for each of your machines should catch the majority of the attacks. Detecting an attempt to use IP spoofing in outgoing traffic is also a likely sign that your network is being misused for malicious purposes and requires prompt investigation.
Even if you have set up ingress/egress filtering at your border to prevent spoofed packets from leaving your network, watching internally for spoofed packets using an IDS, a firewall, or router ACLs that count packets, may provide an early warning of trouble.
Your next step should be to determine how you can filter outgoing traffic to the target(s) and begin this filtering. While doing this, try to also take steps to identify agent machines, usually by monitoring various internal links. (Note that after you have placed filters on routers, you may no longer be able to use your network taps to gather any traffic, or to scan for handlers/agents.) Even a short sample of all network traffic to/from suspect hosts, or flows that have been identified by network monitoring tools as being DDoS-related, taken before you apply filters is helpful. Nobody can analyze traffic that you can no longer see, or hosts that are no longer reachable via the network. Of course, this needs to be balanced against the risk of continued damage, but if made a part of normal operating procedures for responding to a DDoS attack, it will not cause significant delays.
In the early days of DDoS, several host- or network-based DDoS agent scanning tools were available to make the task of identifying agent machines easier. In fact, the initial DDoS analyses done by David Dittrich, Sven Dietrich, Neil Long, and others in subsequent analyses over the following years included Perl-based scripts or other mechanisms that would expose and/or control the DDoS agents. (More on the historical DDoS analyses and identification of malware using scanners is found later in this chapter.)
The DDoS tool scanners mentioned above have their limitations, the major one being that tools they scan for are either obsolete or in use but with modified source code that will not be detected by file-system–level scanners or respond to networklevel scanners. For Windows-based DDoS tools, such as Knight/Kaiten compiled with Cygwin, anti-virus software is likely to be of more help.7 Sophisticated tools, such as Agobot/Phatbot, use code polymorphism and other techniques to (a) avoid detection by antivirus software, (b) detect when they are run under single-step debuggers or in a virtual machine environment, and (c) disable antivirus software as one of the first steps upon infecting the host. You should not fully trust any program you run on a system that has been compromised at the administrative level.
Once agent machines are found, they need to be taken off the network, their disk drives imaged (and the images preserved as evidence), examined for the attack code, and finally cleaned. Unfortunately, many DDoS attack toolkits change system directories and data to hide the presence of the code and restart the code whenever the machine is rebooted. Locating the attack code can be a long and painful process. Steps to fully clean such machines usually involve reinstallation of the operating system, and are generally similar to the procedures for cleaning up any compromised machine.
The bottom line here is that these tools will require careful analysis of the compromised host by a competent system administrator or incident responder who is familiar with forensic analysis as well as with anti-forensic techniques.
The one step in the action list just given that is most often not performed is the imaging of disk drives of attacking systems. If you have done sufficient analysis of the attack traffic, as recommended here, you will know who the victim or victims are and will have some idea of whether legal action may ensue. If the victim of the attack is, say, an online retailer, media outlet, or government agency (especially a military, intelligence, space agency, or a contractor to any of those agencies), it is highly advisable to preserve evidence before cleaning any attacking hosts. These cases also warrant notification of your own organization’s legal counsel, federal law enforcement agencies, and national incident coordination centers. A breakdown in timely communication of an attack, which may be national in scope, will complicate and slow down a nationallevel response. If this is a concerted attack by a terrorist organization or nation state, this failure may have national security implications.
Regardless of the pain involved, you should clean up any agent machines in your network. Apart from helping others, cleaning up those machines increases your security. An attacker who has turned your machine into an agent has broken into this machine first. She can also steal, alter, or destroy your critical information; use your machine to provide illegal services to others; or disrupt your operation. As long as she controls your computers, you are essentially at her mercy.
6.6 Agreements/Understandings with Your ISP
A recent development in several metropolitan governments is for the users to negotiate a new type of contract with their network providers that provide for specific services, and delineate responsibilities and time frames for action, in the event of attack. For example, you could negotiate some of the following services that the provider can guarantee in the event of an attack.
• Network address agility. Can the provider readdress portions of the network to counter an attack? This will not completely stop a DDoS attack but may be helpful in cases where an attacker is using DDoS as a masking activity to cover an existing penetration into your network. The assumption is that the attacker has done reconnaissance scanning of your network in the past, and by readdressing you are taking away her knowledge of your network and forcing her to rescan the network (and be easier to catch in the process).
• Topological changes. Can the provider facilitate compartmentalizing your network in order to keep some of your business functioning, even in the face of a DDoS attack?
• Traffic capture/analysis. Can your provider gather samples of network traffic upstream from your interface to them? This should be full-packet captures, not just headers-only or the output of tcpdump with its standard output captured to a file. Full-packet captures may be required to preserve evidence in case of legal action, or they may improve understanding of the attack itself. Of course, you should also have a way of capturing your own traffic inside your own network. However, if your provider uses some kind of DDoS defense mechanism, you will be unable to gather traffic on the other side of your provider’s defense system and therefore they will be the only one who can capture and examine attack packets. Beyond DDoS attacks, it may be necessary to determine whether your own routing infrastructure, firewalls, or internal/DMZ hosts have been compromised.
• Flow logging. Similar to traffic capture, flow logging is another thing that should be done both inside and outside of your network to provide unfiltered information and for comparison. Especially if you have DDoS mitigation tools in place, you will want to regularly compare internal traffic patterns with those external to the DDoS defense perimeter, to be assured that your defense works as expected. If your staff, or that of your network provider, are able to identify missed DoS traffic or novel DDoS attacks, these facts should be reported to both your DDoS defense vendor and organizations such as the CERT Coordination Center.
The CERT Coordination Center has an open-source, space-efficient flow logger named SiLK [CER04]. The SiLK netflow tools [GCD+04] contain both a collection system and an analysis system and were developed to provide analysis tools for very large installations, such as large corporations, government organizations, and backbone network service providers. For example, the SiLK toolset is designed to process approximately 80 million records in less than two minutes on a Sun Microsystems 4800. One of its applications is described in Section 7.13, and the tools are available from http://silktools.sourceforge.net/.
• Traffic blocking/null routing. During times of attack, your network infrastructure may be so overwhelmed that it falls on its face. Your provider, or other networks upstream of them, will be in a better position to filter out traffic, because they are better equipped to do so, and each router in their network will see a smaller percentage of traffic than you will at the aggregation point of all DDoS flows.
• Support for an out-of-band management network. When your primary (or secondary, etc.) network interfaces are flooded with traffic, you may lose all ability to communicate with your network devices from the broader Internet, which means you will be able to control them only through physical presence where your network equipment is located. If your provider is able to establish an out-of-band control mechanism, be it a network connection through one of their other peering points or even a DSL or ISDN line to a terminal server within your network perimeter, you can regain remote access and may be able to route critical traffic, such as e-mail, even if your main network paths are being attacked. Again, in cases beyond DDoS attacks that require severing your main Internet connection, this could be the only way to retain remote access to your network.
• Assistance in coordinating with their peers. Cases of DDoS that involve source address forgery and reflection of traffic off widely distributed servers (e.g, DNS reflection, SYN-ACK reflection off routers and firewalls) may require manual traceback through many networks to determine the source. The Register.com attack mentioned in Chapter 3 is one example where a reflection attack lasted over a week and came from just a small number of hosts. Getting cooperation of the peers of your upstream provider may be very difficult, and having your upstream provider commit to working with you, even if the problem is difficult, is the first step.
It is not clear how quickly such contracts will gain acceptance, and the above items will certainly be negotiation points that may not end up in final contracts. What is clear, though, is that to date these kinds of terms have not been in contracts for several reasons: (1) An ISP’s stating commitments creates a duty of performance; (2) guarantees of levels of service have a cost that is hard to calculate up front (but can mitigate losses when a crisis hits); and (3) many network providers, and many DDoS victims for that matter, have been able to ignore the issues of DDoS attacks because they have not experienced massive attacks in the past and have had no need to go through the incident response steps outlined in this chapter (but will eventually be forced to in a time of crisis). As the problem of DDoS gets more costly and damaging, which it is likely to do given the trends seen to date, these kinds of contracts will become more and more standard.
6.7 Analyzing DDoS tools
This section deals with the analysis of hosts that are suspected of being involved in a DDoS attack, including identification and analysis of malware artifacts associated with these DDoS attacks. We will start by looking at some past DDoS tool analyses that have been made public, and then move on to guiding someone in performing a similar analysis on his own. In general, one should follow the same kind of who, where, what, when, why, and how that a reporter would. Some of the goals are to explain, in sufficient detail for someone to act on this information, how the DDoS network looks and behaves, how it was set up, how an attacker uses it, and how to detect its constituent parts and tear it down.
Take a moment to study Figure 6.4. It diagrams the flow of command and control traffic, as well as DDoS attack traffic. Malware artifacts associated with the DDoS attack network are at sites A, B, C, and D, among other places.
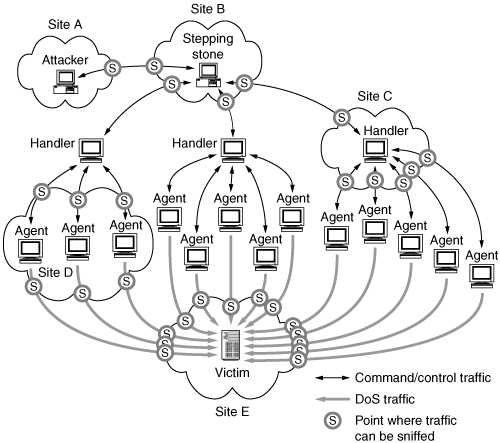
Figure 6.4. Illustration of all DDoS network traffic across all involved sites
During the attack, the victim site can detect only a huge flood of traffic or disruption in their servers’ activities. The victim site can capture and analyze the attack traffic but has no access to the control traffic exchanged by DDoS network members. Further, the attack traffic cannot be captured in full (the monitoring system’s hard drives would fill in minutes, if not seconds, at greater than gigabit per second speeds) but must be carefully sampled in short intervals. The compelling reason for capturing attack traffic is to understand and characterize the attack and devise appropriate selective responses. Another reason is to preserve some evidence of the attack for possible law enforcement activity. Analysis of traffic logs can prove bandwidth consumption rates, identify some of the attacking agents to do traceback, and can help verify that the attack tools the FBI may find on a suspect’s system actually match the traffic that was seen coming into the victim’s site. It will also help your own network engineers and incident response team or outside consultants in understanding what is going on and getting you back online quickly at a reasonable cost. There is nothing worse than paying a consultant hundreds of dollars an hour to try to guess what was happening on the network during the attack, which has stopped two hours before he arrived at your site, especially if the attack starts up again two hours, two days, or two weeks after he leaves.
Networks that host DDoS agents or handlers are in a much better position to gather evidence and identify the path leading to the attacker, since they can capture control traffic and malware artifacts.
6.7.1 Historical DDoS Analyses
The first public analyses of DDoS tools were performed by David Dittrich in 1999 and early 2000. Dittrich later collaborated with others, including Sven Dietrich, and Neil Long. While admittedly very technical, these analyses provide examples of all of the concepts that will be discussed below, along with references to the tools used and other related information. Anyone wanting to prepare to respond to the use of DDoS attack tools, whether at a victim site or a site hosting a DDoS handler or agent, should refer to documents on forensics, malware analysis, incident response, “Active Defense” and cyberwarfare, etc., found on Dave Dittrich’s Web site [Ditd], in addition to the books referenced in Section 6.1.
The motivation for analyzing these tools was to (1) provide detailed information for peers in the incident response community that would allow detection, identification, and mitigation to occur faster; (2) facilitate law enforcement and military efforts to investigate attacks using these tools, should they be directed against critical infrastructure hosts or networks; and (3) try to anticipate what would come next and make recommendations that would prevent more severe attacks in the future. While some of these goals were accomplished, the fact that DDoS is still a growing problem five years after its appearance on the scene, with many victims just learning about it for the first time, means that this success is by no means complete.
A by-product of these analyses was the development of IDS signatures and host- and network-oriented scanners. The prototypes included in the analyses of trinoo [Ditf], TFN [Dith], Stacheldraht [Ditg] and Shaft [DLD00] were rewritten in C by Dave Dittrich, with assistance from Marcus Ranum, David Brumley, and others, and new features such as scanning by CIDR block were added. Another network-based scanner was David Brumley’s RID.8 Those scanners send packets to potential remote DDoS agents or handlers and exploit vulnerabilities in DDoS tools to make them signal, “Hi, I’m here!,” thus identifying compromised machines. Mark “Simple Nomad” Loveless also developed a tool called Zombie Zapper,9 which not only allows detection, but also issues commands to shut down agent machines. Of course, some of the DDoS tools used passwords, and all of them could be reprogrammed to use another port, making it more difficult to find and control them.
Another way of detecting DDoS tools is to scan the file system from within the hosts themselves. In 2000, Mitre was contracted by the National Infrastructure Protection Center (NIPC) to write a signature-based detection tool for scanning file systems for several known DDoS tools (samples of which were provided by DDoS researchers and incident response teams). This tool, called find_ddos [NIP01], worked very well for identifying several DDoS handlers and agents, even if the original source code was modified prior to compiling. It must be run locally on a suspected compromised host using the system administrator account, and it is susceptible to being fooled by kernel level rootkits, which prevent it from seeing the malware in the first place. This may require that someone physically visit each potentially compromised host and boot first from trusted media to get a good scan. Using external network traffic analysis techniques, as described in this chapter, would help confirm beforehand if the host needed to be scanned or not. Network failures, reports from a victim of a DDoS attack that has identified the host, etc., can also trigger a more manually intensive internal file system scan.
6.7.2 Full Disclosure versus Nondisclosure
Before getting into details of analyzing a DDoS attack, let us digress into a brief discussion of the major points surrounding the disclosure and open discussion of computer security issues, including vulnerabilities, attack tools, and techniques. The debate involves two main positions surrounding computer security information: full disclosure (pro) versus nondisclosure (con). Without making any judgments, here are some of the main pros and cons regarding disclosure.
• Con: You do not want to tip off the attackers.
By not disclosing anything publicly, the attackers who are using a program have no idea that anyone knows of their tools, where and how they are using them, and whether an investigation may be under way.
This assumes that the attackers are monitoring whatever channels you report to, and that they can correlate the information you provide with their own tools and activities. It is not clear when this assumption is valid or invalid.
Regardless, there is still some necessity to use discretion in what gets published, when, and where. In some circumstances, where a new attack tool is seeing use in the underground, and no known defenses exist, notification of the CERT Coordination Center, and perhaps the FBI, is warranted to provide some lead time to law enforcement investigators and incident response organizations.
• Pro: Without knowledge of how DDoS tools work, how can you protect yourself or your network?
System administrators need to know how DDoS tools work, and how they appear and behave on their networks and computer systems, in order to find them and remove them. Without this knowledge, they are helpless to stop DDoS attacks or assist law enforcement.
Vendors of computer security products and services often provide just enough information to scare potential customers into buying their products, but not enough for anyone to take self-help actions. Some of the harshest criticism of partial disclosure comes from other vendors or those in the Open Source community, who may be excluded from the details that would allow them to produce response tools. There is a market advantage to control of information, and that market advantage can cloud the issues and create tremendous controversy.
Some individuals believe that the problem will not, and perhaps cannot, be solved by a small handful of vendors (even if they own the majority of the computer security market) because their products are not pervasive enough to provide a complete solution. Those who cannot afford the commercial products, or sites that cannot use these commercial products (like universities and ISPs), are left in a position of knowing there is a problem, but not knowing how to respond to it. These parties believe that the more widely the techniques and skills of DDoS defense are spread, the faster the overall response will be in mitigating emerging DDoS attacks.
• Con: You do not want to help the attackers learn how to use DDoS tools or learn to build better ones.
Sharing analyses of DDoS tools would enable novice attackers to learn where to find DDoS tools, understand how to use them, make them more effective and less buggy, and assist them in not getting caught.
This argument assumes that attackers do not already share information about how DDoS tools work, and that they are not capable of finding bugs and improving them on their own. It is probably true that the highest-skilled attackers have both information sharing and software engineering skills at their disposal, and it is probably also true that some unskilled attackers would not be able to learn how to use these tools if analyses were not public.
Counterarguments to this include mentioning all the thousands of “hacker” Web sites and chat channels where information is shared, as well as places where pirated software, credit cards, and shell accounts are traded, which allow even unskilled attackers to gain enough systems to perform DDoS attacks without understanding the technical details of what they are doing. Those putting forward this argument try to balance the availability of information in the attacker community (which cannot readily be assessed anyway, since some of it is truly in the underground) with the benefit to defenders having this same information for use in protecting their networks. This balance cannot be accurately measured.
• Pro: Software vendors will never discover and patch the vulnerable software or improve software writing skills if security problems are not understood.
Vendors of commercial software products for desktop computers, and server software for Web sites, etc., are not perfect. They produce code that contains bugs. There is no way around this, and every software product has bugs (some of which cause security problems). Unless vendors know where these security flaws are and how they can be exploited, they cannot fix them.
This is another claim that is hard to quantify. It is true that statistics show an increase in the number of vulnerabilities that are made public each year, and there are varying frequencies of patch and security advisory releases for various software and hardware products.
• Con: Users do not pay attention to details of attacker tools, so they do not take appropriate actions to secure their systems.
Very few users of computer programs take the time to study hacker tools and read hacker Web sites as a way to make purchasing decisions, or to learn how to properly configure their computers. Security researchers, who produce detailed analyses of things like DDoS tools, are not helping the average user in a meaningful way.
The sheer number of hosts compromised (to this day!) by worms like Nimda, Code Red, Slammer, W32/Blaster, and Nachi; and hosts infected by viruses like W32/Sobig, MyDoom, and others that require the user to click on attachments show that there is a large and growing population of users who do not have sufficient skills to protect or clean up their own computers.
Of course, detailed technical analyses of DDoS tools will not help this audience, and in fact this is very rarely the audience targeted by these analyses. The goal here is getting the technical information to the technical people, and then having organizational administrators and public policy makers understand the threat and develop policies that address the problems before they become critical.
This is a classic problem in diffusion of information and organizational behavior that will probably be around as long as humans survive as a species (providing these problems do not hasten the end by themselves.) How exactly does knowledge about security flaws get from the researchers who document the vulnerabilities to executives who make business decisions about how products are manufactured, to engineers who design these products, and finally to those who purchase and use them? In this case, the researchers are documenting the vulnerabilities being exploited by attackers (e.g., the problems of TCP/IP that allow denial of service). Consumers will continue to purchase products that have these vulnerabilities. They do not know any better to demand that vendors produce products that do not have these vulnerabilities, which means engineers will not design them differently. But at the same time, CEOs will not read the analyses produced by computer security researchers, so they will not be making decisions about hiring, training, or resource allocation toward better engineering and testing to minimize the problems.
But a question still remains. Will not discussing these issues change the situation any faster?
• Pro: Vendors and engineers of commercial products cannot design more robust products if they do not understand the failure modes.
Engineers themselves cannot design more secure products if they do not understand the vulnerabilities that exist in today’s products. This may be one of the biggest benefits to sharing of technical information about DDoS, especially to router manufacturers, network engineers, software engineers, protocol writers, and application designers.
The issue of robust software engineering may be the real key. Should consumers of software systems have to suffer for a sufficiently long and painful time with viruses, worms, computers that crash, or Web sites that cannot be reached, all in order to motivate them to change their own purchasing behavior? Do they have to be forced to change the way they configure and use their computers through legal liability, which may result from what some would argue is their own negligence? Or do millions of consumers have to have their identities stolen and bank accounts emptied before they start to demand more secure software products?
As noted above, many of these individual pro and con points are hard to fully evaluate, so obviously the argument on both sides will continue.
6.7.3 How to Analyze Malware Artifacts
The term malware artifact means a program or file associated with malicious software. This includes compiled executable programs, the source code that produced them, scripts, log files, libraries, or any other file associated with an intrusion being used by the attacker. DDoS tools found on a compromised computer are one form of malware artifact, as are lists of handlers/agents and other files these DDoS tools rely on to function.
We will now take a look at the strategic and tactical issues you should consider when analyzing DDoS tools (or any malware artifacts, for that matter). To follow this material or perform the recommended analysis steps, you will need moderate Unix and Windows system administration experience and familiarity with TCP/IP networking concepts.
It is important to note that attack tools can be customized to run only on a particular host, using tools such as Burneye and Shiva [Meh03]. In essence the tools are quasilicensed to that particular host (by “fingerprinting the host,”) and will not run on any other host. This has some consequences for DDoS tool analysis and forensics, as it slows down the analysis process. On the positive side for defenders, these tools are not in widespread use, partly because of the same problems that plague all uses of cryptography. These are not trivial. The encryption of attack tools leads to a typical key management problem: If the attacker uses the same password for all his agents, then the compromise of one agent key will compromise the entire network, but if different passwords are used, then many such keys need to be remembered. At the time of writing this book, no large deployment of such anti-analysis and anti-forensics tools was publicly known. Progress has been made in breaking tools such as Shiva [Eag03]. The recent (2003) follow-on to Burneye, objobf [Tes], shows that attackers are well aware of code obfuscation techniques such as the ones outlined in [Wan00] and [Wro02].
The discussion below assumes that there is no anti-forensics technique being used, such as binary encryption, advanced rootkits and kernel level concealment, log alteration, etc. If such techniques are being used, this significantly increases the difficulty and skill level required of the analyst. Always remember: Just because something is not seen, that does not mean it is not there. David Dittrich has a FAQ file on can help you understand them, and some ways to get around them at http://staff.washington.edu/dittrich/misc/faqs/rootkits.faq.
There are two things to consider at the start:
1. Preserve evidence to avoid altering it. Dominique Brezinski and Tom Killalea authored RFC3227, the Guidelines for Evidence Collection and Archiving [BK01] (also known as Best Current Practice number 55) to define the order and methods by which one should collect and preserve evidence. Other texts cover these issues as well, e.g., “Basic Steps in Forensic Analysis of Unix Systems” [Ditb], [IAA, CIPS], and several examples of detailed analyses of a compromised honeypot [Spi02, Pro04] were performed as part of the Honeynet Project “Forensic Challenge” [Pro].
2. Be very careful when analyzing malware. You should never run malware you find on a system unless you are using a secure, isolated, and contained environment. You should either use a newly installed system that you plan to wipe and reinstall after analysis, or use a virtual machine environment that does not allow write operations to the guest operating system’s file system. This way you do not run the risk of the malware getting loose (in the case of worms), or damaging your system if the attacker has booby-trapped it to do damage when run by someone other than the attacker. Having the host be isolated from your production network will prevent possible disruption from flooding, etc.
How Does the Malware Function?
In order to classify the malware, prioritize the response, and focus energies, it is helpful to know its purpose and function. Is it a scanner? Is it a remote exploit? How about a rootkit component or a log cleaner? If it is a DDoS tool, are you analyzing a handler, or an agent? Does it include features of a blended threat, where it can do DDoS, scanning, remote shell, self-upgrade, and serve you up the latest first-run movies in VCD (Video Compact Disc) format on an IRC channel platter?
The Internal Signature of the Malware
How can someone identify this malware artifact? It may have several different signatures. Try to identify and provide examples of as many of them as possible. These include:
File System Signature What directory was the malware artifact found in? What file name was used? When were the files created? What are the checksums or fingerprints of all components? If it is still running, what open file handles does it hold?
On Unix, use lsof (LiSt Open Files), which shows open file handles, sockets, current working directory, program that is running, etc. A Stacheldraht agent, seen with lsof, would look like this:
In this example, the name of the program is ttymon, although it may not show up that way in a process listing (programs can change their apparent name in Unix). One can identify the current working directory of the process (FD column, or file descriptor, with a value of cwd), which is /usr/lib/libx/.../. (Note the use of the directory name with three dots. This creates a hidden directory in Unix, which is a tactic intended to fool novice Unix administrators into not noticing the attacker’s files.) There may be other files related to the malware stored in this same directory, including perhaps a list of agents, if this node is serving as a DDoS handler. The example also indicates that the process is listening on port 32222/tcp (line with TCP *:32222 (LISTEN)), and that it has a raw socket open for sniffing (the column with TYPE of sock and unidentifiable protocol). The program itself is identified as ttymon (FD value of txt).
A somewhat similar Windows program to lsof would be Foundstone’s FPort program. A Power bot as seen with FPort would look like this:
![]()

The lines with the names winnt and nt in the Process column are associated with the bot’s functions. To identify what files were created around the same time, one can use forensics tools that reveal file Modify, Access, and Change (MAC times) time stamp history. For Unix there are free forensics tools such as The Coroner’s Toolkit (http://www.porcupine.org/forensics/) or Sleuthkit (http://www.sleuthkit.org/sleuthkit/docs/ref_timeline.html). Sleuthkit was written by Brian Carrier, originally as a research project that helped win him second place in the Honeynet Project “Forensic Challenge” [Pro]. This toolkit will help you construct a time line of file system modifications, recover deleted files, and otherwise do static analysis of a copy of a compromised host’s file system. To illustrate this, here is a time stamp listing from a host running the mstream [CER01b, DWDL] DDoS tool, generated by Sleuthkit (see instructions about creating file activity timelines with Sleuthkit at http://www.sleuthkit.org/sleuthkit/docs/ref_timeline.html):


From this listing, the following observations can be made:
• On April 13 at 16:02, /bin/chown was run (note .a. for access time stamp.)
Apr 13 2000 16:02:42 12060 .a. -rwxr-xr-x root/www root /bin/chown
• At the same time, /bin/login was modified (note m.. for modify time stamp).
12660 m.. -r-sr-xr-x root/www bin /bin/login
• Also at the same time, the compiler egcs and gcc was run and /bin/old and /bin/xstat were created.

• Simultaneous access to .h files in the system include directory /usr/src/linux/include/, indicates that the program being compiled uses network libraries.

• Next, the /etc/rc.d/rc.local file is replaced (note m.c for modify and i-node change time stamps).
Apr 13 100 16:02:44 702 m.c -rwxr-xr-x root/www root /etc/rc.d/rc.local
Further examination of this file (not shown in the example) revealed that the change was to include the line /usr/bin/rpc.wall at the end of the file, thus restarting the agent on each reboot.
• ncftp logging files were also replaced. Further analysis showed that they were deleted and turned into links to /dev/null to disable logging of file transfers over the network using ncftp program.

• The program /usr/bin/rpc.wall was modified, and C runtime libraries were loaded.

If anti-forensic techniques such as sophisticated rootkits or kernel changes are being employed, some of this file system information would not be available and it would not be as easy to infer what exactly occurred and in what order. The same holds for the situation in which the system is not examined right away, but instead used for a long time, thus overwriting file access information.
Surface Analysis Surface analysis of malware artifacts attempts to understand the purpose and behavior of the program by examining the files installed on the system by an attacker.
For example, strings embedded in the malware artifact or file types containing malware code (e.g., shell scripts, executable objects, libraries, as reported by programs such as file on Unix) contain useful information. Knowing the file type helps narrow the search while investigating files on the system. Scripts are easy to read, and may reveal how a toolkit works, how it was installed, and how it is hidden. Keep in mind that simply looking at executable files with a pager or editor is not a very good idea, as it can affect your terminal screen.
Also keep in mind that surface analysis alone is very unreliable. It can be easily defeated using simple techniques, and sometimes strings are embedded to trick the unwary analyst into thinking a program is something other than what it really is, or to waste the analyst’s time going down a blind alley.
For example, running file on malware artifacts associated with the ramen worm produces the following report:


The above output indicates that there are several Bourne shell scripts that make up the core of the worm (e.g., scan.sh, start.sh, start62.sh, and start7.sh) as well as a number of precompiled programs (the items identified as ELF 32-bit LSB executable, Intel 80386, version 1, dynamically linked (uses shared libs), stripped). Further examination of the executable files shows that they perform the scanning, the exploitation of remote vulnerabilities to spread the worm. Closer analysis of this worm kit revealed that the file td was a Stacheldraht agent!
Network State Signature What network connections does the malware create?
Noticing network connections will give you information about the “last hop” stepping stone from which the attacker broke into your machine, or if your machine is the stepping stone, it will also tell you where the attacker bounced to. Sockets in the ESTABLISHED state are active. The LISTEN state means that a server process (or peer-to-peer application) is waiting for new connections to be initiated.
On Unix, you can use either netstat (which will list all network sockets) or lsof. Here is what the output of netstat on a Linux system shows you on a sample agent machine:


In this case, one can tell by the lines showing Proto values of raw that some process has opened a raw socket. This by itself is suspicious as raw sockets bypass operating system handling of network communication and are frequently misused to send spoofed packets. There is also a process listening on port 12345/tcp (Proto equal to tcp and Local Address equal to 0.0.0.0:12345), and two established connections to ports 22/tcp and 2222/tcp. (Foreign Address of 10.10.10.10:32965 and 10.10.10.2:33354.) Further examination of suspicious processes on a given machine has indicated that there is an exploited SSH daemon, detailed in [Dit01]. The listening port on 12345/tcp resulted from the buffer overflow exploit on the vulnerable server.
Another suspicious sign is the program placing a network interface in promiscuous mode. Promiscuous mode allows a program to see all packets on the LAN segment, not just those that are supposed to be for the Network Interface Card (or NIC) of this particular computer, and is used for sniffing other users’ communications. One can use the ifconfig command on Unix to see if the NIC is in promiscuous mode. (Be aware that rootkits that replace the ifconfig command, or replace kernel-level process calls, will “lie” to you about the promiscuous mode flag in the NIC’s driver. You may still see system log messages showing the NIC entering/exiting promiscuous mode, or you may have to use other means to get around the rootkit.)
Process State Signature What processes are created by the malware, and how do they show up in process listings? Sometimes blended threats will include several programs that all run in the background: a backdoor shell, a file transfer server, an IRC bot, an IRC bouncer, a sniffer, and perhaps a DDoS agent. The parent–child relationships between these processes can tell you something about how they were started on the system (perhaps from a buffer overflow in a Web server, which might make them all share a common httpd parent process).
On Unix, you can use the ps (simple process listing), pstree (a tree version, showing parent–child–grandchild relationships between processes), and/or the top command (show processes continually, with those using the most resources at the top of the list).
System Log Signature What was logged by the system? On Unix, start with the syslog daemon and look at the files it keeps. This may (if the attacker has not wiped or deleted the log files) show some signs of his entry and activity. To illustrate this, here is a sample log file excerpt:
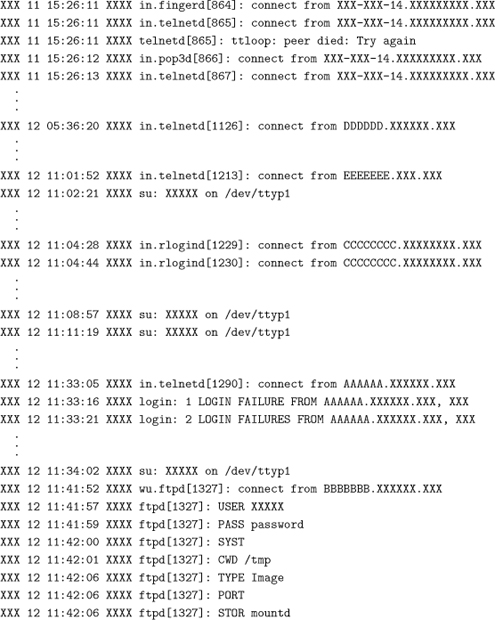

The entries from 15:26:11 to 15:26:13 show what appears to be a port scan. The lines with in.telnetd[1213] and in.telnetd[1290] show connections using telnet, followed by successful use of su to elevate privileges. The lines following the wu.ftpd[1327] FTP daemon connection show a login, and transfer of a file mountd (the attacker’s mount daemon exploit program) to the /tmp directory. This leads you to both the last hop point of entry information for the attacker, which can be correlated with other logs to find other systems the attacker may control, as well as a directory in which to start looking for evidence.
An attacker’s access attempts may also be logged in the application level logs, like Apache’s access_log and referrer_log files, Microsoft’s Internet Information Server (IIS), or the standard Windows Event Logs. Here is an example of a buffer overflow exploit attempt found in an Apache log file contained on a Unix system:

This shows the attempted exploitation of the Unicode directory traversal vulnerability in Windows IIS to run the ping.exe program to attack some site with a distributed ICMP Echo Request flood. It did not work in this case (note the 404HTTP failure error code) because Unix does not have a file called /winnt/system32/cmd.exe (or ping.exe for that matter), but the attacker blindly tried anyway.
The External Signature of the Malware
What TCP and UDP ports show up when scanned from the outside? Often, malware will include a backdoor, IRC bot, or other code, which will be listening on a TCP or UDP port. Performing a half-open scan (only sending SYN packets and seeing the response) is one way of detecting them.
You can use nmap, Nessus, or other port scanners to perform half-open scans from outside your network. Compare the information gathered this way with the information gathered from internal examination with programs like lsof on Unix, or FPort on Windows. Here is what a Windows host running the Power bot blended threat looks like when scanned with nmap:
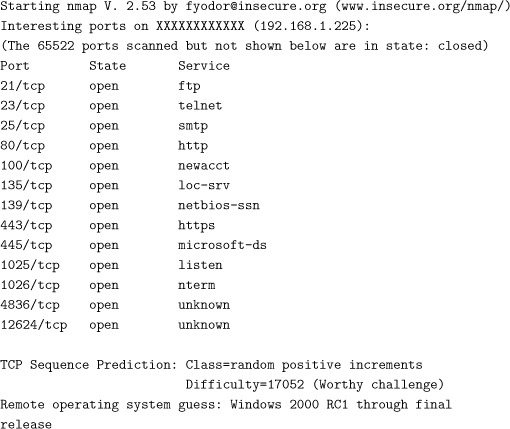
In this case, the last line shows there was a listening backdoor on port 12624/tcp, which gives the prompt “Password:” if you connect to it. Note here that one should be very careful about just randomly connecting to listening ports on an infected host! You have no idea how the program works, what it might do if you connect to it, whether it reports connections to the attacker, and so on. It is best to try to get copies of the program and analyze them on a safe, isolated, throw-away system, or to passively capture network traffic first and analyze it to determine how the program may function from what it exposes to you on the network.
This is where the anti-analysis features mentioned earlier come into play. The malware may be programmed to prevent you from tracing it, or dumping its memory. It may employ per-block in-memory decryption, so even if you can dump memory, it will be hard to determine any strings, passwords, or embedded IP addresses or domain names. If the malware also encrypts traffic on the network, it becomes extremely difficult to do runtime, or dynamic, analysis. If you run across anything that goes beyond your abilities to analyze, ask around for help (start with organizations like the CERT Coordination Center). If you determine that you do have a very advanced tool on your hands, make sure you also report this immediately to your local FBI or Secret Service office, and do your best to preserve as much evidence as you can about the intrusion [BK01].
Some programs do not have listening ports, instead watching for special packets using embedded commands in ICMP Echo Reply, UDP, or crafted TCP packets that are not part of any established connections. These are a form of covert channels when they are used for command and control. If they eventually open up a port for the attacker to connect to, they are called a closed port backdoor.
The Department of Defense defines covert channel to be any communication channel that can be exploited by a process to transfer information in a manner that violates the systems security policy. In the context of DDoS, this means using some protocol in a way that was not intended, for the purpose of command and control of DDoS handlers or agents. For example, Stacheldraht used ICMP Echo Reply packets sent between handler and agents to communicate that the agent was still alive. You can see the words “skillz” and “ficken” in these packets (which somewhat defeats the covertness of the communication, but using ICMP packets nonetheless is not something that a network operator or system owner would typically ever see if they were not looking for it). Following is the illustration of some ICMP packet contents captured as part of a Stacheldraht agent’s covert command and control channel:

A closed port backdoor might accept special UDP or ICMP packets, which tell it to “open up a listening TCP socket on 12345/tcp and bind a shell to it.” The attacker then has a small window of time (perhaps just seconds) to connect to the server port; otherwise, it closes again and goes back to waiting for another covert command. This makes it much harder to detect the backdoor from the network, but still allows the attacker full access whenever it is needed.
The Network Traffic Signature of the Malware
Get full packet captures of network traffic to/from the infected host. In a case in which the attacker is using anti-forensic techniques that would prevent you from restarting the program yourself in a closed environment, these traces must be gathered while the attacker is using the tool.
It is also best to collect the traffic as close to the suspect computer as possible (i.e., on the same LAN segment), or at least at the border of your network so you can capture all traffic in and out of the suspect computer. One factor that will complicate things is the use of fully switched networks, especially ones that are centrally managed and for which subnet owners are not provided with port mirroring (known on Cisco hardware as Switched Port Analyzer, or SPAN). Without this ability, the switch will provide only a subset of traffic that is associated with the IP addresses of devices on the same switch port, plus any broadcast Ethernet traffic. (Critical Networks maintains a Web page with information on sniffers and network taps that may be of use: http://www.criticalnets.com/resources/index.html).
Start by getting an overall view of the “scene of the crime” by gathering high-level statistics of network flows. One public domain program for Linux that works well is tcpdstat [Cho00]. A version modified by Dave Dittrich at the University of Washington [bDD02] ports the code to Linux and adds some new protocols and features (like peak bandwidth use). Here is a view of a traffic capture with [bDD02] to/from a suspected DDoS agent:

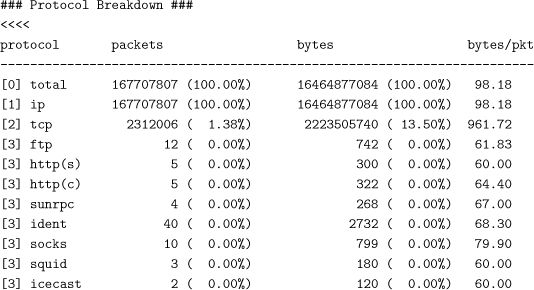

We can see from the StartTime: and EndTime: lines that the capture period was just under a day. The average traffic (AvgRate:) rate was 2.07 Mbps, with peaks (PeakRate:) going up to 12.16 Mbps. This one host alone could take out a 10-Mbps network! Looking further, we see that 98% of the traffic ([2] res_255) is not even a valid protocol! It is a reserved IP protocol value that is not supposed to be used. This would slip past some tools that expect only TCP, UDP, and ICMP, but provides nice ground for formulation of filtering rules. As attack traffic is using an invalid protocol number, filtering traffic based on this signature will inflict no collateral damage.
Another program that may work better (although it is slightly harder to read at first) is Aguri [CKK]. The following example includes real IP addresses, but they come from the author’s own published paper.

A paper on Aguri [CKK] explains the summary output this way: “In the address profile, each row shows an address entry and is indented by the prefix length. The first column shows the address and the prefix length of the entries. The second column shows the cumulative byte counts. The third column shows the percentages of the entry and its subtrees.”
This illustration shows that the “top talker” (by source address) is 209.1.225.217, with 4.77% of the total traffic. Aguri can read tcpdump files, so a packet capture taken using the libpcap format10 should quickly confirm which specific host may be involved in a DoS attack. (For example, if this host were sourcing a significant portion of the 14.91- Mbps average, that would be suspicious and may warrant further investigation.)
It has also happened before that worms like Slammer, or DDoS tools like mstream, will cause router instability because the source addresses they forge are in multicast address space, or otherwise force the router CPU to process them as part of egress filtering, which effectively erases or disables router settings. The lesson here is to never assume hardware will not fail or that a parameter that was set at one time is still set the same way at the present time.
Once you have isolated a suspect system, and you can filter out the attack traffic, start looking at other flows for command and control traffic. Trinoo, for example, was very obvious and chatty on the network. In the following code we show some trinoo communication captured with ngrep program.
You can see the commands the attacker types in the right column, including the password to connect to the handler (betaalmostdone), the password between the handler and agents (l44adsl), the prompts from the handler (trinoo>), and the commands the attacker types in (for example, msize 32000, dos 216.160.XX.Y and quit.) The leftmost column indicates the protocol (T for TCP, and U for UDP). The TCP stream is the command shell to the handler, and the UDP stream is the command and control channel between the handler and the agent(s).
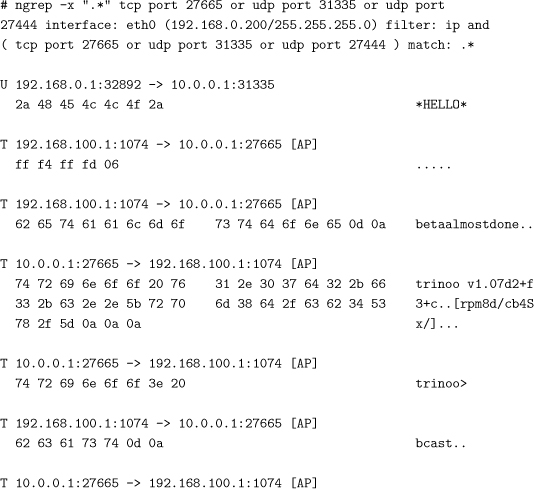



It was the simplicity of the protocol, and the lack of encryption or authentication of commands between the handler and agent, that allowed David Dittrich’s scanner and Zombie Zapper to detect and/or control trinoo agents. Not all DDoS tools are this easy to detect and manipulate.
Real-time monitoring of network traffic can sometimes be a controversial topic for two reasons. First, you are capturing electronic communication in real time, which is covered by state and federal wiretap (or electronic communication privacy) statutes. Be careful to understand the exemptions defined in these laws to know if you are complying with or violating them. Not just anybody can monitor traffic on any given network. Second, you are leaving a known compromised host in operation, and thus in the control of an attacker. If you are a network operator, your primary goal is to get the system off the network to make the network regain stability and have it cleaned as soon as possible. However, if you are an incident responder, researcher, or law enforcement agent investigating a crime, your primary goal is to get as much network traffic as possible, which implies keeping the infected host on the network. These two contradictory goals must be balanced, hopefully getting as much traffic as is reasonable before shutting off wall ports. Another option to collect a sufficient amount of malicious traffic while minimizing its bad effects is to use devices like the Honeynet Project’s “honeywall” (http://www.honeynet.org/tools/cdrom) or other layer two filtering bridges configured to block outbound traffic that exceeds specific bandwidth limits or uses specific ports and protocols. A device like the honeywall provides protection for the network infrastructure and makes logging traffic much easier.
The type of traffic that can be obtained by sniffing is determined by the role your site plays in the DDoS network. Does your site host a handler or an agent? Is it the victim of the DDoS attack? Are you just a transit provider, routing packets between other parties? Each of these situations provides a different perspective on the DDoS network and different opportunities to capture traffic for analysis or investigation by law enforcement authorities.
Figure 6.4 on page 184 illustrates a DDoS network in action. In this diagram, Site A is where the attacker is located. She uses a stepping stone at Site B, to connect to handlers at several locations, including Site C. There could be many, many different stepping stones used by the attacker. We depict only one stepping stone here. The handlers, in turn, relay attack commands to all of the agents they are controlling at numerous sites, one of which is shown as Site D. All of the agents then unleash a flood of packets toward the victim at Site E. That is the aggregation point for all traffic, and may be knocked out entirely by the flood.
As you can see, trying to relate the attack on the victim to the attacker requires tracing packet flows back from Site E, through all intermediary sites until you get back to Site A. If the attacker disconnects from the stepping stone at Site B, or switches to another stepping stone, the trail is broken. If she uses multiple stepping stones, instead of just the one depicted here, traceback gets harder. If logs are cleaned on each stepping stone, or they are used only once, traceback becomes even more challenging.
Now let us take a look at what traffic you can capture, based on your perspective in the network. In all of the figures in this section, the traffic that can be captured by sniffing at the network border is depicted by a circle with an “S” in it.
From the perspective of a network hosting agents, you can see the command and control traffic coming in from a handler (perhaps not all of them) to the agents at your site, and you can see the outbound DDoS attack traffic from this subset of agents going to the victim. This is shown in Figure 6.5.
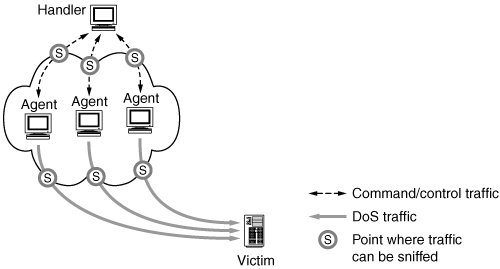
Figure 6.5. Illustration of attack and control traffic seen from site hosting agents
Most sites will fall into this category, since there are typically far more compromised hosts used as agents than there are handlers, stepping stones, or victims (usually combined). A site hosting agents has a responsibility to identify and clean up the compromised hosts, lest they be used over and over for continued attacks. At sites with small incident response teams, or none at all, the typical cleanup is “wipe the drive, reinstall the OS, get back online.” As discussed in Section 6.5, this has potential negative consequences. One consequence is that, unless you also patch the system to current levels, you will be placing the same vulnerability back on the system and it will be compromised again. Another is the destruction of evidence. At least some data collection and preservation is typically warranted in the case of large attacks. A better response is to restore the system from a recent, known clean backup that already has software patches installed. Alternatively, do the operating system installation and patching from CD-ROMs you have prepared while the system is disconnected from the network entirely. Ask the vendor or distributor of your operating system of choice how to produce a patch CD-ROM for such use. Windows users can try things like Microsoft’s Security Readiness Kit (found at http://www.microsoft.com/technet/security/readiness/default.mspx), or if you are using Red Hat Linux, by downloading and creating CDs from the packages in their errata Web pages http://www.redhat.com/errata/. Doing less than that can expose newly cleaned machines to repeated intrusions, sometimes nearly immediately. (Note that if you have a PC on the network of a large Internet 2 educational site, and you try to install a Windows 2000 or XP system from the original CD-ROMs distributed with your computer dating prior to 2003, that system has a high probability of being infected with W32/Blaster, Nachi, or some other currently active worm or bot in less than one minute, that is, before the installation is even complete!)
In some cases, the command and control traffic would expose all of the agents in the DDoS network. In other cases, DDoS handlers keep track of all the agents within a file. Knowing that your site is hosting agents, you can identify the victim and assist them in identifying all of the agents in the DDoS network by monitoring traffic at their site, and you can assist the site hosting the handler in recovering information about a large percentage of the agents and perhaps take down the entire network. Working with the site hosting the handler also gets one hop closer to the attacker.
Moving now to the site hosting the handler, one can capture only command and control traffic. The traffic rate will be much lower, and the view of the agents in a DDoS network provides more information because the handler communicates with agents at numerous sites. The view from the site hosting the handler is depicted in Figure 6.6.
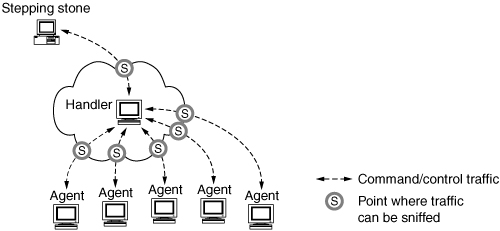
Figure 6.6. Illustration of control traffic seen from site hosting a handler
Note that now both parts of the command and control traffic are visible: the connection from the attacker to the handler’s user interface, as well as the traffic to/from a set of agents. Capture all packets to and from the handler, including the data portion of packets (not just headers). Keep these logs secure.
If the attacker is not using an encrypted channel, you also get to see the passwords, user account names, and command syntax of the DDoS tool. This alone may give you enough information to determine what tool is in use, just from watching traffic from outside the handler. Host-level forensics are also an option here for recovering even more information, and preservation of evidence should be carefully done in the event that law enforcement is involved later in the process. Note that you should consider very, very carefully any actions that would take control of the DDoS network in any way. The best advice is to get law enforcement involved as soon as you understand how the DDoS network functions and provide a report to them.
You also want to attempt to identify the stepping stones used for incoming connections to the handler. Keep track of all of them, and determine if there is more than one IP address or network block that is favored by the attacker. What time of day are connections most often made? Identify the sites involved, and very carefully attempt to contact them, perhaps by going through their upstream providers, to make sure that you do not end up reporting the DDoS network to the attacker or one of her friends! If you get cooperation from the other sites, they can then attempt to identify other upstream stepping stones, and maybe even other handlers in the network (or networks) being used by the attacker.
Now we will look at the site that is hosting the stepping stone. Here we have only a partial view of the command and control traffic between the attacker and the handlers. There is no more visibility beyond the handlers to agents. This is illustrated in Figure 6.7.
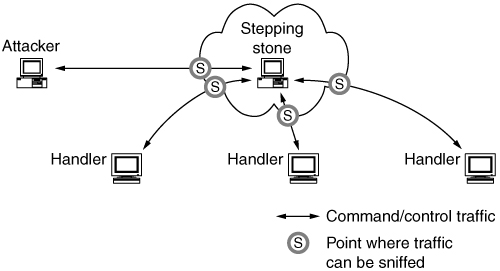
Figure 6.7. Illustration of control traffic seen from site hosting a stepping stone
Monitoring at the stepping stone may reveal more handlers, and following this trail may ultimately lead to identification of the attacker’s location, other stepping stones, or even more agents. Over time, a pattern of behavior of the attacker can be determined, and in some cases active connections to handlers can be identified during the point of an attack.
If law enforcement is involved, they are now able to use search warrants and subpoenas to get more information about accounts used by the attacker, perhaps even hitting upon the attacker’s own computers and accounts. At worst, they are able to identify the previous stepping stone in use by the attacker and continue to follow the chain backward toward the attacker.
As you may be seeing by now, the process of traceback is slow, tedious, and labor intensive. It requires some pretty detailed understanding of network capture and analysis tools and techniques, preestablished mechanisms to capture traffic at the network borders, knowledge of what kind of DDoS tool is being used, how the tool functions and presents itself on hosts and the network, and the skills to put all of this together. Taking out an entire DDoS network is a hard problem, but it can be done.
While doing this level of tracing requires many skills and is labor intensive, it has proven successful in the real world. One of the authors, David Dittrich, has personally used the techniques described in this chapter to take down entire DDoS networks, some numbering in the hundreds of hosts (see the time line of DDoS activity leading up to the February 2000 attacks referenced in Chapter 3). Of course, Dittrich wrote the analyses of several of these early tools, and intimately knows how they work. On the other hand, these analyses are freely available on many sites in the Internet to allow anyone who is motivated and resourceful to know everything publicly available about these same tools. Anyone can use the techniques described in these analyses to do the same. Many people have done just that, including some talented members of federal law enforcement in several countries, and DDoS attackers have been brought to justice using these methods of investigation. Similar analyses of newly discovered DDoS tools continue to be written by people around the world. Of course this effort takes skill, discipline, and time and generally makes a profit only for security companies who resell this public information or use it in products they sell. The upside is the reward that comes from knowing that you have contributed to improving the state of computer security on a global scale. Luckily for all, there is a large supply of people with these qualifications and who share this belief.
Malware Command and Control
What ports or protocols are used for command and control? Does the program use password protection or encrypt communications or files? What are the passwords or cryptographic keys, and where can they be found? How are agents identified to handlers (and vice versa) and can you get a complete list of them all?
Earlier, we discussed several examples of looking at network traffic. The analyses of trinoo [Ditf], TFN [Dith], Stacheldraht [Ditg], Shaft [DLD00], and Power [Dita] all provide further examples of how to identify DDoS agents on the network.
This is some of the most sensitive information, and you should think very carefully about how to disclose this, to whom, and when. It would be very inappropriate, and perhaps very dangerous and a potential legal liability, to provide information that allows another attacker to take over and use a large DDoS network. For example, if you explain that someone has established a bot network on the Dalnet IRC channel #NotARealChannel, and he is using a particular bot with a password of notapassword, then anyone with basic knowledge of the bot in question could take over the entire botnet and use it for his own purposes.
The Source Code Lineage of the Malware
Attack programs are often shared in the computer underground, in source code form and in compiled binary form. When source code is shared, features of two or more programs may be exactly the same (e.g., how IP header checksums are computed or shell code is injected into overfilled buffers in order to force execution of code on the stack). By knowing how program code is shared and changed from program to program, it is sometimes possible to trace a program back to its author, or to use an existing signature detection method to identify code variants. An entire class of programs may share the same set of known signatures, but a new program that appears on the scene for the first time may go undetected or get packets past existing DDoS mitigation tools. These are all reasons to want to understand how a program developed over time.
You may have only a compiled binary, not the source code, for the particular malware artifact in hand. This makes it harder to distinguish lineage, but not entirely impossible in all cases. There are still symbols that may exist in the symbol table, strings used for prompts and messages to the user, etc., that can be identified and compared to some well-known artifacts.
Many programs borrow heavily from others, be it specific attack features, exploit shell code, cryptographic libraries, etc. Some (like knight.c) were coded originally in C for Unix systems, but have been compiled under portable C compiler environments like Cygwin on Microsoft Windows. Some people will simply assume that if the program was originally written for Unix, it will not work on Windows and can not be easily ported to different operating systems.
Who Is Using the Malware?
Going back to 1999, DDoS was most often used for a sort of “drive-by shooting on the Information Superhighway.” Attackers were continuously fighting wars using DDoS to take down opponents’ machines and IRC channels. However, DDoS is now becoming a component of crime in the form of acts like extortion or rigging online bids. Sometimes a disgruntled ex-employee will attack her former company to exact revenge for a believed false termination. One day a terrorist organization or nation state may use DDoS as a force multiplier in an attack on another state’s critical infrastructure. Knowing who is attacking—attribution, in legal and military terminology—can be important.
This is another sensitive subject, though. While capturing traffic to and from suspected compromised hosts, you may get IP addresses of stepping stones, handlers/agents, or direct connections from the attacker’s main systems. Beginners have been known to connect from their parents’ PC on a DSL line that can be traced directly to a phone number by their ISP. Others have used stolen credit cards to dial in to “no charge” ISPs that do not even have accounts or caller-ID capable switches for their modem pools, resulting in near total anonymity from anywhere in the world. Knowing either of these things tells you something about the attacker (but even if she is connecting from an identifiable DSL or cable modem line, that still does not mean the attacker is sitting at that particular keyboard!).
To Whom Should You Provide the Analysis, and When?
Anyone who is involved in DDoS—either victims or sites whose computers were compromised and used as stepping stones or DDoS handlers or agents—has some responsibility to not only clean up his machines, but to report the incident to others and to help in mitigating the problem. As time goes on, and as DDoS attacks become more prevalent and more damaging, the legal situation may likely change in such a way that failing to act appropriately, not reporting participation, or not helping to stop DDoS attacks may incur liability on the part of those involved. Establishing policies and procedures before this becomes an issue is the best course of action, and the best time to start is right now.
In most cases, the DDoS attack will span multiple jurisdictions, within your own country or between several countries around the world. Many attacks these days involve the attackers spreading DDoS agents around the world, and using stepping stones in two or more countries before connecting to the DDoS handlers. This makes it much harder to attribute the attack and identify suspects. A good place to start is by contacting your local representatives of federal law enforcement agencies (in the United States that would include the FBI and the Secret Service). It is best to contact these agencies in advance, and get to know them (and let them get to know you) so that it is easier to reach out to the right person in a timely manner when an attack hits. Once law enforcement officers know who you are and understand your skill level and areas of expertise, they will trust your reports more and can prioritize their response appropriately.
Federal law enforcement agencies are (as Australians would say) “up to their armpits in alligators.” The more complete and readable your analysis, with an executive summary and high-level overview of the attack itself, the easier their job will be. Getting bit-image copies of compromised hosts used to attack, and full packet traces of network attack and command and control traffic (time stamped, cryptographically fingerprinted, and kept secure for chain-of-custody purposes, etc.) all help make a potential case.
You should also report the incident, in similar detail (but perhaps without some of the more sensitive information from your own site) to national-level incident response centers, such as the CERT Coordination Center in the United States. These organizations often have liaisons with federal law enforcement and other organizations with a larger view of the attack landscape. By correlating events across a larger population, they can identify and help prioritize national-level responses to very large events. Organizations like the CERT Coordination Center also have liaisons to similar institutions abroad and can facilitate cross-border incident response. Contact information for the CERT Coordination Center is provided in Chapter 9.
If you are a network service provider, it would be good to notify your customers if they are victims, or sources, of DDoS attacks. Many ISPs see DDoS as being more of a bandwidth problem, opting to simply add capacity to prevent the network from becoming unstable. Their support staffing can be stretched thin, and it can be very time-consuming trying to explain to a customer (who may know very little about network administration) that his computer was compromised and is being used to attack others, and to assist in the cleaning process. Some ISPs gain notorious status for being unresponsive to DDoS problems.
Lastly, ISPs and NSPs should likewise report large DDoS events to law enforcement and incident response organizations, as described above. For the same reasons, but at a higher level, they have a responsibility to report events, especially if they see these events as being widespread through their association with other network providers. Consult your legal staff to establish policies and procedures for reporting.
What to Keep Private
As mentioned earlier, there are many pieces of information that you should think twice, or even five times, about releasing.
Some pieces of information, like your own internal IP addresses of compromised production hosts, you may never want to release. It may be best to anonymize these, but leave the times and source addresses of attacking hosts intact for investigators. If the event does end in court, you or your company may be required to release the information at that point for use in court. In order to accommodate this, the anonymization must be reversible with a key so that information is preserved and can be released during a trial.
Keep in mind, however, that IP addresses are not authenticated and can easily be spoofed, so they do not serve as a completely reliable source of information identifying a particular computer, let alone an individual. Attackers can, and do, control DNS servers that allow them to also map IP addresses to DNS names at will, so it is important to do reverse mappings to show how DNS names translate at a given point in time. (Provide both IP address and current DNS mapping in your reports, showing the time and time zone to which the mapping corresponds.) It is necessary to have several sources of information, preferably authentication logs used to obtain the IP address in the first place, to help correlate and ensure proper identification.
During your investigation, you may determine that one or more of your own computers are attacking someone, or you may obtain IRC traffic or command/control traffic from a DDoS handler or agent that identifies victims of DDoS attacks. You do not want to be responsible for providing information that opens other hosts up to abuse because you have essentially given account/password information allowing their remote control, or for them to be trivially taken over by someone else. Of course, someone else may find them and take them over anyway before you release information, but at least you could not be accused of providing the means. The IP addresses of victims are another thing that you want to consider carefully before releasing, and then you may want to talk to the victim sites and allow them to release their own information.
Names of individuals involved (especially if suspected of performing a DDoS attack) should be held closely, but provided to law enforcement. Releasing names of suspects, or making statements about them and their skill level publicly, can sometimes result in their attacking you in retaliation. Perhaps worse, if you cannot prove your allegations you might be sued for libel.