
Chapter 7. Survey of Research Defense Approaches
Immediately after the first large-scale attacks, much research was dedicated to the new problem of stopping, eliminating, and somehow filtering out DoS attacks targeted at end-host systems. While DDoS was a relatively new problem, related research existed in congestion control, mitigation of simple DoS attacks, fault tolerance, and survivability.
During the CERT Coordination Center’s Distributed System Intruder Tools (DSIT) Workshop [CER99] mentioned in Chapter 3, the initial ideas about DDoS defenses were formed. This workshop produced a report that laid out an array of defensive responses ranging from protection to detection and reaction, in a near-, mid-, and long-term time frame, for managers, researchers, system administrators, network operators, and incident response teams.
The DDoS attack networks at the time ranged from several hundred up to over 2,000 hosts, small by the standards of 2004, but viewed as extremely large at the time. (The first DDoS tools could only handle a dozen or so agents, so this was an increase of two orders of magnitude in size in just a few months. It took four more years to increase by two more orders of magnitude.) DDoS networks of only a few dozen to a few hundred hosts allowed for small(er) solutions in response to the threat.
Many research approaches attempted to solve smaller subproblems of a very complex problem. They are more varied than the commercial solutions discussed in Appendix B, but not necessarily realistic. Due to the sensitive nature of network traffic data and the complexity of the phenomenon, it is difficult to fully understand the effects of DDoS. Many prototypes are tested in lab-only environments without background or operational traffic. Some (falsely) assume that attack traffic is mostly spoofed, which is clearly untrue, and others assume certain knowledge about the topology of the network, or access to oracles that can tell whether given traffic is DDoS or not. Others require substantial modifications to the Internet infrastructure that would make it incompatible with existing protocols and client applications, or are impractical for technical, policy, or political reasons.
This book does not survey all the existing research approaches—there are a lot of them and the list keeps growing. We discuss a few of them in this chapter. Limitations of space and the frequent appearance of new systems prevent us from covering all DDoS defense research, and the inclusion or exclusion of a particular project in this chapter should not be considered either a recommendation or a criticism of that project.
7.1 Pushback
Pushback, proposed by Mahajan, et al. [MBF+02], emerged from discussions within the original DDoS research group at the CERT Coordination Center DSIT workshop [CER99]. The idea, taken from practice, is that network operators try to push back offending traffic toward the source, either crudely by unplugging a network cable in the router and watching whether the bad traffic stops, or by observing network traffic on monitoring equipment. Rate limits propagating outward from the victim (pushback) then alleviate the pressure on the victim, allowing it to exchange traffic and effectively survive for a moment while the offending sources are stopped or removed. This assumes that the offending traffic is not evenly distributed across all possible ingress points.
There are two techniques at play here: local Aggregate Congestion Control (ACC) and pushback. Local ACC detects the congestion at the router level and devises an attack signature, or more appropriately in this context, a congestion signature, that can be translated into a router filter. The signature defines a high-bandwidth aggregate, a subset of the network traffic, and local ACC determines an appropriate rate limit for this aggregate. Pushback propagates this rate limit for the aggregate to the immediate upstream neighbors that contribute the largest amount of the aggregate’s traffic. This mechanism works best against DDoS flooding-style attacks and flash crowds, as they share common traits, and tries to treat these phenomena from a congestion control point of view. Too broad a specification of the aggregate signature or policy can lead to benign traffic being limited, as shown in experiments [IB02], and too narrow a specification can allow attackers to bypass the protection. Pushing an imperfect response upstream limits collateral damage at the possible cost of catching less attack traffic. Generally, pushback seems to require contiguous deployment patterns in routers. Existing approaches cannot push the rate limit past a router that does not understand the pushback method. Pushback also requires routers to maintain state about traffic flows, which is an additional burden.
7.2 Traceback
Some of the first proposals for defending against DDoS included means to perform traceback to the agents of a DDoS network. The assumption is based on some DDoS tools spoofing the sources and relatively low numbers of agents (100–2,500). In the 1999–2000 time frame, it seemed inconceivable that larger networks with over 100,000 hosts [CER03] would exist in the near future.
An early proposal, ICMP Traceback by Bellovin, et al. [BLT01], was to send an ICMP packet, probabilistically every n (early proposals included n = 20,000) packets, containing a portion of the captured packet, from the observing router to the destination. The disadvantage is that under heavy attack, a target may miss those packets due to congestion of the network equipment, and some networks do not allow ICMP messages to travel across their border router. Even though the sampling of 1/n occurs, it does create additional traffic in the direction of the victim, which adds to the congestion.
Subsequent proposals used a technique called Probabilistic Packet Marking (PPM). Again, every 20,000 network packets to a destination, a router would mark a packet with a reference to itself.1 Such a low sampling frequency was chosen to avoid a heavy burden on the router infrastructure due to marking a high volume of traffic during a flooding attack. By analyzing several marked packets from a given source, the victim of the flood would try to build a path back to the attacker, or at least to the edge closest to the attacker on the marking infrastructure. The initial proposal by Savage et al. [SWKA00] did not have any provisions for authentication for those markings, but a later proposal added authentication and integrity checking [SP01]. Several techniques along these lines have been proposed, including single-bit techniques [Adl02]. One drawback is that a sufficiently spread DDoS attack network could stay below the limits of sampling. Some musings by Waldvogel [Wal02] on how PPM techniques could be fooled outline further problems PPM faces with regard to deception and denial of service techniques. One of the PPM schemes [SWKA00], at least, claims to provide some benefit without contiguous deployment, unlike the Pushback scheme. For an evaluation of Savage et al.’s packet-marking techniques, see Park et al. [PL01].
The hash-based traceback technique [SPS+01] asks participating routers to remember each packet they see, but for a limited time. This enables tracing of one-packet attacks such as “Ping of Death,” but only if the query is fast. The Source Path Isolation Engine (SPIE) remembers packets by computing hashes over the invariant portions of an IP header (e.g., TTL and checksums removed). For additional space trade-offs, weak hashes, rather than strong cryptographic hashes, are deployed in the form of Bloom filters [SPS+02]. This passive recording capability does not have to exist inside the router even though hardware design considerations for inclusion in routers were discussed [SPS+02]. The SPIE designers thought of a way to place a passive tap on each interface of the router. Some critics initially thought it would be too expensive to add one device per interface, so the SPIE device was extended to be a SPIEDER with multiple connections to each interface cable on the router. Although the weak hashes allow for false positives, they are quickly disambiguated through multiple hash functions applied at different routers as the distance increases from the victim. The victim initiates a traceback request through an alternate network (real or virtual) connecting the traceback manager, the data-generation agents, and the routers. Due to the high volume of traffic on backbone networks, the time between receipt of an offending packet and the request for a traceback should be on the order of a few minutes, depending on network capacity and traffic [SMS+01].
Dean et al. [DFS01] take an algebraic approach to the traceback problem. Similar to Savage et al. [SWKA00], this technique embeds partial tracing information into IP packets at the router level. This new scheme uses algebraic techniques to encode path information into packets and to reconstruct them at the victim site. The authors hope to gain more flexibility in the design and improvements in discarding attacker-generated noise and providing multiple-path traceback.
PPM and algebraic traceback schemes make several assumptions. We quote:
1. Attackers are able to send any packet.
2. Multiple attackers can act together.
3. Attackers are aware of the traceback scheme.
4. Attackers must send at least thousands of packets.
5. Routes between hosts are generally stable, but packets can be reordered or lost.
6. Routers cannot do much per-packet computation.
7. Routers are not compromised, but not all routers have to participate.
These assumptions clearly differentiate these techniques from a single-packet technique like hash-based traceback [SPS+02]. The authors of [DFS01] discuss efficiency compared to Savage et al., as space requirements vary between 18 and 21 bits. In some cases, they achieve slightly better results for path reconstruction, but the number of false positives remains high. Aside from packet marking, an out-of-packet scheme is considered, similar to Bellovin [BLT01]. The authors realize that further algorithm improvement is necessary, and trade-offs need to be explored. This concept needs further refining, but could develop into a promising concept in the long run.
Two serious problems exist for traceback solutions:
1. Traceback solutions often become unacceptably complex and expensive when there are large numbers of sources or when sources are well distributed.
2. Traceback, in and of itself, does nothing to stop an attack. If perfect, it identifies the edge networks containing all DDoS sources. Does one then cut them off? Persuade them to clean up the DDoS agents? Counterattack? There are no good answers, except those that presume that one can characterize the attack well enough to distinguish the attack packets from all other packets. If one can do that, traceback may no longer be needed, as offending packets can be filtered using the characterization. Lacking such a DDoS oracle, one option would be to dynamically deploy filters or rate limiters close to identified sources. This would localize collateral damage and stop the flood of attack traffic. However, this calls for a complex and distributed system with the potential to inflict high damage when wrong, so it is not likely to lead to real-life deployment.
7.3 D-WARD
D-WARD, proposed by Mirkovic et al. [Mir03, MPR02], was developed at UCLA under sponsorship by the DARPA Fault Tolerant Network (FTN) program, which sponsored several other DDoS projects. This source network–based system aims to detect attacks before or as they leave the network that the DDoS agent resides on. It is an inline system (transparent to the users on the network) that gathers two-way traffic statistics from the border router at the source network and compares them to network traffic models built upon application and transport protocol specifications, reflecting normal (legitimate), transient (suspicious), and attack behavior. Models are built at two granularities: for each communication with a single destination (called a “flow”) and for individual connections. Based on this three-tiered model (attack, suspicious, benign/normal), D-WARD applies rate limits at the router on all the outgoing traffic to a given destination, preferring legitimate connection traffic, slightly slowing down suspicious traffic, and severely slowing down (what it perceives as) attack connections. Rate limits are dynamic and change over time, based on the observation of the attack signal and policed traffic aggressiveness. Less aggressive traffic will be more lightly policed.
Like most research systems, D-WARD was tested with a homegrown set of DDoS benchmarks, and, again like most research systems, it performed well on those benchmarks. However, the D-WARD system also underwent extensive independent testing (also known as “red teaming”) toward the end of the DARPA FTN program cycle. Those experiments indicate that D-WARD has the ability to quickly detect those attacks that create anomalies in two-way traffic, such as heavy floods, including some on-off or pulsing attacks. D-WARD effectively controls all traffic, including the attack traffic, and has very low collateral damage and a low level of false positives. It promptly restores normal operations upon the end of the attack(s). By rate limiting the attack traffic rather than blocking it, this system quickly recovers from false positives. By design, it stops attacks at the source networks; thus, it requires wide deployment (covering a majority of actual sources) to achieve the desired effectiveness. Unless a penalty for hosting DDoS agents is imposed on source networks, this is not a system that network operators would eagerly deploy, as D-WARD does not provide a significant benefit to the deployer. However, it may be possible to integrate it with other defense mechanisms (such as COSSACK in Section 7.8) that require source network action, to provide selective response.
In summary, D-WARD’s advantage lies in the detection and control of attacks, assuming that attack traffic varies sufficiently from normal traffic models. Due to the fact that D-WARD selectively rate limits traffic, it has low collateral damage, and attack response is relatively fast. On the downside, attackers can still perform successful attacks from networks that are not equipped with this system.
7.4 NetBouncer
NetBouncer, proposed by O’Brien [O’B], also emerged from the DARPA FTN program. It is a client-legitimacy mechanism that sits on the network of a potential victim/target. Ideally, it gets positioned at the choke point of the network and aims to allow packets only from “legitimate” clients or users. Several tests for legitimacy are performed on the client, e.g., a ping (ICMP Echo request) test to see whether there is an actual client behind the packet that was received by the target, and also a Reverse Turing Test [vABHL03]. The reader may have seen such a test when registering for an e-mail account on the Yahoo e-mail service: The client is asked to enter a phrase or word displayed in a very noisy image, something that we assume only a human could do, not a machine.2 Other tests investigate whether an ongoing connection falls within the protocol specifications (for example, is it truly a real-time video streaming connection?) and, if not, NetBouncer terminates the connection.
Once the client has proven that he is indeed legitimate, he is added to the pool of legitimate clients and is given preferential treatment over the not-yet-legitimate clients. This pool is managed using Quality of Service techniques and guarantees fair sharing of resources between all the legitimate clients. To prevent an attacker from inheriting the credentials of a legitimate client, the legitimacy expires after a certain time and needs to be reassessed using the same or a different test.
Can such an approach work? It can defeat many spoofed attacks, since the challenge must reach the true source of the packet for the network transaction to complete. The available network resources are fairly shared among the clients that have proven their legitimacy. Because the legitimacy tests are stateless, the system itslf cannot be the target of state-consumption attacks.
However, NetBouncer assumes certain properties of clients, such as the ability to reply to pings (i.e., check the presence of a client), which not all clients support, especially those behind firewalls and home DSL routers with additional security features turned on. Although a client is legitimate, he is not protected against impersonation attacks, i.e., an attacker can abuse the fact that a legitimate client has done all the necessary work to prove his legitimacy to NetBouncer and then attack the network faking that legitimate client’s source IP address. Also, the system is not immune to resource exhaustion due to a large number of legitimate clients (a “flash crowd” effect). Further, like all target-side defenses, it can be overwhelmed by pure volume of packets on the incoming wire. A sufficiently large DDoS network can overwhelm NetBouncer and similar approaches, since the attackers can flood all but the most massive network connections in front of the defense system.
Like all the better DDoS defense schemes, NetBouncer has its advantages and limitations. On the positive side, it appears to provide good service to legitimate clients in the majority of cases. As it sits inline on the network, meaning that it does not have a visible presence on the network akin to a network bridge, it does not require modifications to the servers and clients on either protected network or the hosts connecting to the same. The deployment location is close to the victim and it does not require cooperation with other NetBouncers. On the negative side, attackers can perform successful attacks on the victim/target by impersonating legitimate clients or recruiting a large number of agents, both of which are easily achieved through spoofing and sufficient recruitment, respectively. Additionally, NetBouncer makes certain assumptions about the legitimate clients that are not always shared by all such clients and will cause them to be excluded from accessing the protected resources. The legitimacy tests put a significant burden on NetBouncer itself and can exhaust the resources of the defense mechanism.
7.5 Secure Overlay Services (SOS)
Keromytis et al. propose Secure Overlay Services (SOS) [KMR02] as a DDoS defense, with the goal of routing only good traffic to the servers. Traffic that has not been confirmed to originate from good users/clients is dropped. Clients must use an overlay network, essentially a network sitting on top of the existing network, to get authenticated and reach the servers.
Clients must first contact the access points of the overlay network, the gatekeepers that will check the legitimacy of each client before letting her into the network. These access points send the packets to a so-called beacon via a routing algorithm called Chord, which decides where packets go on this overlay network. The beacons, in turn, send the packets to secret servlets. The latter are the only nodes on the overlay network that can penetrate the firewall of the protected network. These secret servlets then tunnel the packets to the firewall, which will allow only the packets from the secret servlets’ source addresses to reach the protected network. The built-in redundancy of the overlay network assures that if a node should fail, other nodes will step forward and assume its role.
SOS is meant for communicating with a network protected with a firewall, e.g., a private enterprise network. The test for legitimacy of packets is pushed out to the access points on the overlay network, which leaves the firewall working on dropping attack packets and accepting connections from its trusted secret servlets. The built-in redundancy of the SOS network, as well as the secrecy of the path taken by the packets from the source to the final destination, contribute to the resistance against DoS attacks on SOS itself.
Like pure target-side solutions, SOS could potentially be overwhelmed by a bandwidth attack on the firewall that allows only approved packets through. Routing restrictions require core routers to check source addresses on packets before routing them. Routers do not currently do that very quickly, so, in practice, keeping the IP addresses of the target and firewall secret is the real answer. If attackers are unable to route traffic directly to the target machine or firewall (due either to routing restrictions or secrecy of their IP addresses), the only way to generate a flood at the firewall is by going through the overlay network. The overlay network will take careful steps to prevent bad traffic from being sent to the protected system. Only flooding attacks capable of overwhelming all of the entry points into the overlay network will succeed, and the defender can configure many of those and increase their numbers if necessary.
If routing restrictions or secrecy of the protected system’s addresses are not possible, however, attackers will be able to bypass the SOS overlay and send DDoS packets directly to the firewall. Should that happen, SOS offers no more protection against a flooding attack than any victim-end solution.
In summary, SOS does provide communication of a legitimate client with the protected, albeit private, server and/or network. It also offers resilience to node failure, as surviving nodes will assume the role of failed nodes, and resilience against denial of service on the system itself. On the other hand, the SOS system is designed to work with private services only, since it requires changes in client software and an extensive overlay infrastructure. There is also a WebSOS [CMK+03] variant that works with a public Web server and uses CAPTCHA [vABHL03] for legitimacy, which limits WebSOS’s use to human Web browsing. Clients must know of the access points in order to get to the protected services, and using CAPTCHA requires human presence. Also, the use of an overlay network by SOS and WebSOS redefines the routing topology and creates a longer or slower route to the destination. Recent research by Andersen et al. [ABKM01] has shown that careful construction and use of an overlay can sometimes actually offer better performance than use of standard Internet routing, so it is possible that there will be no significant loss in speed due to the use of SOS. Current results [KMR02], however, show twofold to tenfold slowdown.
7.6 Proof of Work
A different way to approach the DDoS problem is to consider the subproblem of the connection depletion attack. Many connections are initiated by an attacker to deplete the number of open connections a server can maintain. A defense goal is to preserve these resources during such an attack. As a defense, the server starts handing out challenges [SKK+97, JB99, WR03], not unlike the ones in NetBouncer, to the client requesting a connection. This happens at the TCP/IP protocol level, since the system aims at protecting the resources involving network connections. The server distributes a small cryptographic puzzle to its clients requesting a connection, and waits for a solution. If the client solves the puzzle within a certain time window, the appropriate resources are then allocated within the network stack (the portion of the operating system that handles network communication). Clients that fail to solve the puzzles have their connections dropped.
This is the proof-of-work approach explained in detail in Chapter 5. However, this approach will work only against connection depletion attacks, not other types of flooding attacks, such as UDP flooding attacks. Such attacks achieve their goal merely by placing packets on the target’s network link. Anything the target does upon receipt of them to check their validity is too late. Bandwidth has already been expended.
This approach forces the attacker to spend time and resources prior to achieving a successful connection to a server or target, and slows down the rate at which he can deplete the resources of the server from any given host/client. While this has a low overhead (the server still must generate and verify the puzzles), the actual TCP/IP protocol implementation on both ends (client and server) must be modified for this approach to work. This defense does not address problems such as distributed attacks in which the attacker generates sufficient requests to exhaust the server resources (by sheer number) or attacks that exhaust puzzle-generation resources and consume the capacity of the network pipe leading to the server, or flash crowd type of attacks.
By analogy, one can also consider using Reverse Turing Tests [vABHL03] for countering DDoS attacks, as proposed by Morein et al. [MSC+03].
7.7 DefCOM
DefCOM, proposed by Mirkovic et al. [MRR03], is pursued jointly at the University of California Los Angeles and the University of Delaware. It is a distributed system that combines source-end, victim-end, and core-network defenses. It detects an ongoing attack and responds by rate limiting the traffic, while still allowing legitimate traffic to pass through the system. It is composed of three types of nodes (routers or hosts): alert generators that detect an attack; rate limiters that enforce simple rate limits on all traffic going to the attack’s target; and classifiers that rate-limit traffic, separate legitimate packets from suspicious ones and mark each packet with its classification. Alert generator and classifier nodes are designed for edge-network deployment, while rate-limiter nodes are designed for core deployment.
In case of an attack, the likely detection point is at the alert generator within the victim network, and a likely classifier engagement point is close to the source networks. DefCOM traces the attack from victim to all active traffic sources (attack or legitimate) using an overlay network and exchanging statistics between defense nodes. The rate limit is deployed starting from the victim, and propagates to the leaves on the traffic tree (classifiers close to sources). Packet marks, injected by classifiers, convey information about the legitimacy of each packet to rate-limiting nodes. Rate limiters allocate limited bandwidth preferentially first to packets marked legitimate, then to those marked suspicious, and finally to nonmarked packets. This creates three levels of service, giving best service to legitimate packets.
Any firewall could assume alert generator functionality. Core routers would have to be augmented with a mark-observing capability to perform rate-limiter functionality. D-WARD was described as a likely candidate for classifier functionality. However, separation of legitimate from attack traffic does not need to be as good as D-WARD’s. A classifier node can simply mark traffic it deems important for the source network’s customers as legitimate. As long as classifiers obey rate-limit requests, this traffic will not hurt the victim.
In summary, DefCOM’s design is an interplay of detection at the target/victim network, rate limiting at the core, and blocking of suspicious/attack traffic at source networks. Using D-WARD as its initial classifier system, DefCOM also reaches further out into the core to handle attacks from networks not outfitted with classifiers watching for bad traffic. DefCOM claims to handle flooding attacks while inflicting little or no harm to legitimate traffic. Due to the overlay nature of the system, DefCOM lends itself to a scalable solution and does not require contiguous deployment thanks to the use of peer-to-peer architecture, but it does require a wider deployment than victim-end defenses. As a drawback, handling damaged or subverted nodes in the overlay network may be hard, and DefCOM is likely to operate badly if they are not handled. At the time of writing, DefCOM exists only as a design and fragments of an implementation, so it should be considered as a promising new idea rather than a complete, ready-to-deploy solution.
7.8 COSSACK
COSSACK, proposed by Papadopoulos et al. [PLM+03] and developed by the University of Southern California/ISI, aims to prevent attacks from ever leaving the source networks, i.e., the networks harboring the DDoS agents. So-called watchdogs, a plug-in to the free lightweight intrusion detection system Snort [Sou], detect a potential attack by analyzing and correlating traffic across the source networks. Based on the correlation (timing, type of traffic), the correlating entities are able to suppress the similar and simultaneous traffic as a group action.
This technique acts at the source network, triggered by a notification from the target of a DDoS attack, by filtering out the apparently offending traffic. However, if the legitimate traffic gets matched by the correlation engine, leading to a false positive, then that legitimate traffic will get dropped by COSSACK.
A major assumption of this technique is the deployment of watchdogs at the source networks. The source networks are being prevented from becoming attack sources, but a network without a watchdog can still participate in a DDoS attack. This drawback is common to systems requiring source-end deployments. No modifications are required at the protocol or application level for the source networks. The communication between the watchdogs is not scalable, as they use multicast communication.
7.9 Pi
Pi, proposed by Yaar et al. [YPS03], is a victim-based defense, building on previous packet-marking techniques [SP01], that inserts path identifiers into unused (or underused) portions of the IP packet header. The main idea is that these path identifiers or fingerprints are inserted by the routers along the network path. The target or victim would then reject packets with path identifiers matching those packets that have been clearly identified as part of an attack.
In the basic Pi marking scheme, each participating router marks certain bits in the IP identification field of the IP packet.3 The placement of the mark within this field is defined by the value of the packet’s TTL (time to live) field. A mark is a portion of the hash of the router’s IP address. Since the TTL value is decremented at each router, a contiguous path of the packet is built as it gets closer to the victim. One can decide to stop marking within a certain hop distance of the victim network to increase reachability of this scheme.
Pi filtering can take place once the marking scheme has been installed in the infrastructure. This scheme assumes that the victim knows how to identify the bulk of the attack traffic, for instance, by selecting a large portion of incoming traffic bearing the same mark. Filters then drop all traffic with the given mark. Inadvertently, some legitimate traffic sharing the mark with the attack (because it shares the path to the victim due to the fluctuating and adaptive nature of the network) will be dropped, too.
Pi claims to work after the first attack packet has been identified (if it can be identified by the target), to maintain IP fragmentation, work without inter-ISP cooperation, and with minimal deployment. Pi is likely to suffer the same problems from flooding attacks on the box running the defensive mechanism or its incoming network link as most other victim-side defenses.
7.10 SIFF: An End-Host Capability Mechanism to Mitigate DDoS Flooding Attacks
Yaar et al. [YPS04] propose to mitigate DDoS flooding attacks using an end-host capability mechanism that splits Internet traffic into two classes: privileged and unprivileged. End hosts can exchange capabilities that will be used in privileged traffic. Routers will then verify these capabilities statelessly. These capabilities are assigned in a dynamic fashion, so misbehaving (that is, attacking) hosts can have their capabilities revoked. Contrary to other approaches (e.g., in Section 7.5), this scheme does not require an overlay mechanism, but it does require a modification of the clients and servers, and also routers.
The end hosts would use a handshake protocol to exchange capabilities, and then that privileged traffic would be expedited by the network, in contrast to the unprivileged traffic which does not get precedence. There are provisions in place to prevent flooding with privileged traffic by an unauthorized user, e.g., by someone who tries to forge the capabilities (implemented by markings in each packet). Should an end host with capabilities start flooding, then the credentials for privileged traffic can be revoked for that end host.
The authors of this mechanism propose two avenues: a next-generation Internet incorporating these techniques and a retrofit for the current network protocols in IPv4. It is unclear that these avenues will prove fruitful.
In summary, this technique makes several assumptions, including the assumption that client and server update the TCP/IP protocol software to incorporate modifications necessary for the new capabilities. The advantage is that no inter-ISP or intra-ISP cooperation is necessary. However, it is also assumed that spoofing is limited, and processing and state maintenance are required at each router. The new network protocol requires marking space in the IP header, cooperation of clients and servers, that each router marks packets,4 and that routes between hosts on the network remain stable. These assumptions are quite restrictive, compared to what can happen in a real network.
7.11 Hop-Count Filtering (HCF)
Hop-Count Filtering, proposed by Jin et al. [JWS03], is a research project at the University of Michigan, aimed at defending against DDoS by observing the TTL value (time to live, the number of hops or routers a packet will travel before getting discarded to avoid network loops—the value gets decremented at each router the packet traverses) in inbound packets. Deployed at victim/target networks, it observes the proper TTL value for any given source address on the network that enters the victim/target network, attempts to infer a hop count (that is, the distance of the sender from the defense) and builds tables that bind a given IP to the hop count.
The system makes guesses of hop counts starting with the observed TTL value and guessing the initial TTL value that was placed in the packet at the sender. There are only a few such values that operating systems use and they are fairly different, which facilitates correct guesses. The hop count is then the difference between the initial TTL and the observed one.
Hop-count distributions follow the normal distribution (bell curve), as there is sufficient variability in the TTL values. If an attacker wanted to defeat this scheme, he would have to guess the correct TTL value to insert into a forged packet, so that the deduced hop count matches the expected one. Spoofing becomes difficult, as the attacker now has to spoof the correct TTL value associated with a given spoofed source address and, augmented by the appropriate difference in hop counts between attacking and spoofed address, malicious traffic becomes easier to model.
In the general operation, the hop-count filter is passive while it is analyzing traffic and matches it to the established incoming tables of assumed hop counts. If the number of mismatches crosses an established threshold, the scheme starts filtering. The incoming tables are constantly updated by examining a random established (e.g., successful) TCP connection to a site within the protected network. Note that this scheme tries to prevent spoofed traffic. Nothing prevents an attacker from launching an attack with true sources and carrying the correct TTL values, and thus attacks using large bot networks or worms with DDoS payloads, which do not need to spoof source addresses to be successful, will still be a problem. Since these types of attacks are easy today, attackers would simply adopt this method over source address forgery to get around such defenses.
Like other victim-side defenses, this approach cannot help defend against flooding attacks based on overwhelming the link coming into the machine that is checking the TTL values.
7.12 Locality and Entropy Principles
Two general and related themes are being investigated by several researchers. We will highlight the principles these themes are exploring—locality and entropy, which relate to self-similarity.
7.12.1 Locality
In his worm-throttling paper, Williamson [Wil02] discusses throttling a spreading worm by using the concept of locality: People communicate only with a fixed number of other people on a regular basis, read a limited number of similar Web pages per day (e.g., CNN, New York Times, Wired), and send mail to a given set of people. Behind this thought is the small-world model of social networks of Watts [Wat99]. McHugh and Gates extend this model in their locality approach for dealing with outsider threat [McH03]: Is there a model for attack behavior or, more to the point, is there a complement to good behavior that is based on small networks (tightly connected) of networked hosts? There may be some way of characterizing DDoS and worm behavior using this principle based on known worm and DDoS data; work continues in this area.
7.12.2 Entropy
Another way of looking at this problem is to consider the self-similarity of attack traffic. Kulkarni et al. [KBE01] propose to investigate whether the attack packets can be easily compressed when considered in a stream, as an indication that a machine-generated stream (the attacker generates repetitive packets aimed at one or more targets, with low entropy, low complexity, and high compressibility) is present rather than a human-generated stream (which tends to be more chaotic, with high entropy).
Similarly, a research project by Schnackenberg et al. [FSBK03] looks at the source address entropy of the network packets. Based on a study of DDoS data inserted into a collection of network traffic collected at the border of the New Zealand national network, it appears that the entropy of source addresses present during a DDoS attacks is significantly different from what is present in the rest of the traffic (and considered normal everyday traffic without attacks). A prototype for this approach exists.
7.13 An Empirical Analysis of Target-Resident DoS Filters
Collins and Reiter [CR04] present an empirical analysis of target-resident DoS filters, such as Pi (see Section 7.9), HFC (see Section 7.11), Static Clustering (SC), and Network-Aware Clustering (NAC). Both SC and NAC monitor the behavior of a range of source addresses and build a baseline model of this behavior. Under attack, traffic from these source addresses is compared against the baseline model to classify it as legitimate or attack. SC groups addresses into fixed-size ranges, while NAC uses ranges derived from routing tables.
With the help of replicated Internet topologies (obtained from CAIDA, among others), this analysis runs the filtering mechanisms against actual DDoS data collected using a space-efficient network flow data collection system, the System for internet-Level Knowledge (SiLK) [CER04, GCD+04], developed by the CERT Coordination Center.
In their summary for spoofed traffic (Figure 7.1), Collins and Reiter point out that even though HCF has a low false-negative rate, this is due to the assumption that the true hop count of each network packet can accurately be determined. This is clearly not the case, as compromised hosts can manipulate the TTL field of each sent packet, yielding a possible false hop count. Pi, SC, and NAC do reasonably well. Pi appears to be immune to spoofing. Both SC and NAC do well since the distribution of spoofed traffic allows for easier filtering versus “normal” traffic.
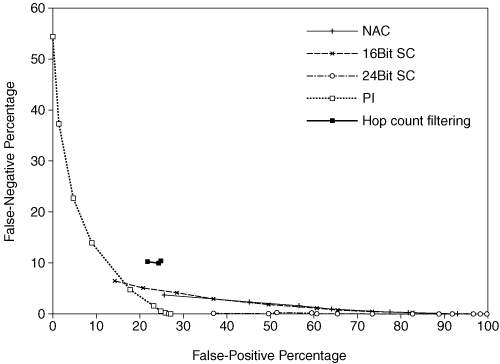
Figure 7.1. Summary of analyses of spoofed traffic. (Reprinted with permission of Michael Collins.)
In drastic contrast, the learning algorithms for attacker learning compared to normalcy learning allow for the superiority of SC and NAC in the nonspoofed traffic case (see Figure 7.2)
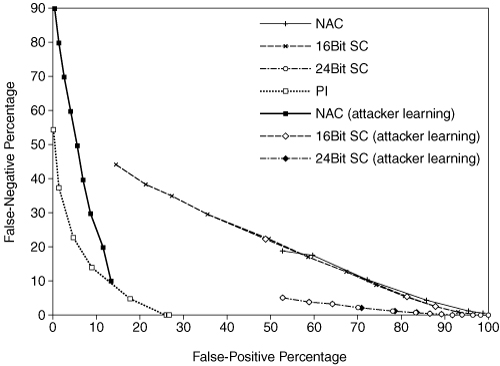
Figure 7.2. Summary of analyses for nonspoofed traffic. (Reprinted with permission of Michael
As Collins and Reiter emphasize, the results should not be overvalued, as this represents work in progress. These results do provide us, however, with insights into realistic analysis—with real-life and not simulated DDoS data—of the DDoS mitigation mechanisms outlined above.
7.14 Research Prognosis
There was a rich explosion of DDoS defense approaches immediately after the DDoS phenomenon became widely known. The results of this research include many of the projects discussed in earlier sections. As the preceding discussion suggests, and the similar discussion in Appendix B also indicates, the existing approaches have not solved the entire DDoS problem in provable ways. Some solutions clearly stop some attacks, and some solutions claim they will stop most attacks. What is the actual prognosis for future research in this field? Is there reason to believe that a more complete solution to the problem is on the horizon? Answering these questions requires better information about how proposed DDoS solutions perform.
A problem with the existing research is that there is no convincing evidence that any proposed approach actually works against broad classes of DDoS attacks. Most researchers have tested their systems against particular DDoS toolkits, with traces of real DDoS attacks, or with parameterized traffic generation capable of emulating a wide variety of attacks. A few researchers have had outsiders perform significant tests on their systems, though that approach is expensive and not necessarily convincing. But there is no known set of tests that everyone agrees represent the necessary and sufficient evidence that a DDoS solution works well enough to rely upon. Collins and Reiter [CR04] have made a start on comparing some DDoS defense systems against real attacks.
DDoS solutions that require major changes (such as altering behavior of core routers, changing fundamental Internet protocols, or deploying new software on all machines in the Internet) will never be implemented without far more convincing evidence that they would work if their price was paid. In particular, it would be depressing if major changes were made in the Internet to counter today’s DDoS attacks, only to discover that slightly altered attacks bypass the expensive new defenses. This issue points out one serious advantage that target end systems have: they typically cost less to deploy, so if they do not work, less has been lost. Overall, we need to have a far deeper understanding of the nature of the attacks and the characteristics of proposed defenses before we should accept anyone’s claim to possess a silver bullet against DDoS.
7.14.1 Slowing Innovation
One dispiriting fact is that few really new approaches have come out as of the time of writing. Researchers have brought older ideas to maturity and improved the systems that incorporate them, but most of the ideas being developed come from the original explosion of DDoS defense approaches.
Since this crop of approaches does not seem terribly likely to produce solutions capable of dealing with all DDoS attacks, a complete response to the DDoS threat would seem to depend on new approaches. The authors hope that some new approaches will be suggested in the future that invigorate the DDoS research field
Refinements/Combinations of Earlier Ideas
In the absence of new approaches, some researchers have investigated whether combinations of existing approaches can achieve more complete coverage of the DDoS problem. DefCOM [MRR03] is one such example. These systems offer some hope of dealing with the overall problem. The researchers postulate that the weaknesses of one portion of the system will be covered by the strengths of other parts. Of course, it is possible that exactly the opposite is true: The strengths of one may be undermined by the weaknesses of the others.
Until truly fresh approaches are found, however, the available choices are to improve one approach or to combine several approaches. Thus, we should expect to see more interesting and clever combinations of defenses in the future.
7.14.2 Several Promising Approaches
We should not be too pessimistic. Academic researchers quest for complete solutions at practically no cost. In the real world, something less is often good enough. For many people, solid implementations of some of the kinds of solutions described in this chapter and Appendix B may prove to offer sufficient protection from DDoS attacks at acceptable costs. For example, companies that do business with a limited set of trusted customers might get sufficient protection from a solution like SOS, or companies that can afford large bandwidth links into their defense nodes can be protected by certain sets of the victim-end solutions.
7.14.3 Difficult Deployment Challenges
Some of the most promising solutions depend on either widespread deployment or deployment at some key locations in the core of the Internet. Neither of these deployment patterns is easy to achieve. Widespread deployment most usually arises because the software in question is extremely attractive to users, and most of the solutions that require such deployment lack features that excite the ordinary user. In particular, software that helps protect other users’ computers, but does not help protect the installer, has had difficulty achieving much market penetration.
Approaches like traceback and pushback that require deployment in many nodes in the core face a different problem. The institutions that run the machines on which these deployments must occur have critical requirements for the performance of their systems. They cannot afford to pay heavy performance penalties on a per-packet basis, since they carry so many packets. Even more critical, they cannot afford to install features in their routers that decrease stability or cause other forms of disruption in normal service. There must be extremely compelling evidence of benefit, acceptable performance, and stability before there is any hope of installing functionality at these sites. Further, there is no real hope of installing it at all of them, so only solutions that provide significant benefit in partial deployments have any chance of real-world use.