
Chapter 5. An Overview of DDoS Defenses
How can we defend against the difficult problems raised by distributed denial-of-service attacks? As discussed in Chapter 4, there are two classes of victims of DDoS attacks: the owners of machines that have been compromised to serve as DDoS agents and the final targets of DDoS attacks. Defending against the former attack is the same as defending against any other attempt to compromise your machine. We will concentrate in this chapter on the issue of defending the final target of the DDoS attack—the machine or network that the attacker wishes to deny service to.
We will begin by discussing the aspects of DDoS attacks that make defending against them difficult. We will then discuss the types of challenges a DDoS defense solution must overcome, and then cover basic concepts of defense: prevention versus detection and reaction, the basic goals to be achieved by a defense system, and where to locate the defenses in the network.
In spite of several years of intense research, these attacks still inflict a large amount of damage to Internet users. Why are these attacks possible? Can we identify some feature in the Internet design or in its core protocols, such as TCP and IP, that facilitates DoS attacks? Can we then remove or modify this feature to resolve the problem? Like all histories, the history of DDoS attacks discussed in Chapter 3 does not represent a final state, but is merely the prelude to the future. We have presented publically known details on exactly how today’s attacks are perpetrated, which has set the stage for discussing what you must do to counter them. Remember, however, that the current DDoS attack trends suggest, more than anything else, continued and rapid change for the future. Early analyses of DDoS attack tools like trinoo, TFN, Stacheldraht, and Shaft all made predictions about future development trends based on past history. Attackers continued in the directions identified, as well as going in new directions (e.g., using IRC for command and control, and integration of several other malicious functions). We should expect both the number and sophistication of attack tools to grow steadily. Therefore, the tools attackers will use in upcoming years and the methods used to defend against them will progress from the current states we describe in this book, requiring defenders to keep up to date on new trends and defense methods.
Another big problem in the arms race between the attackers and the defenders is the imbalance of the effort needed to take another step. Developing DDoS solutions is costly and they usually work for a small range of attacks. The attacker needs only to change a few lines of code, or gather more agents (hardly any effort at all) to bypass or overwhelm the existing defenses. The defenders, on the other hand, spend an immense amount of time and resources to augment their systems for handling new attacks. It seems like an unfair competition. But does it have to be so, or is there something we have overlooked that could restore the balance?
5.1 Why DDoS Is a Hard Problem
The victim of a vulnerability attack (see Chapter 2) usually crashes, deadlocks, or has some key resource tied up. Vulnerability attacks need only a few packets to be effective, and therefore can be launched from one or very few agents. In a flooding attack, the resource is tied up as long as the attack packets keep coming in, and is reclaimed when the attack is aborted. Flooding attacks thus need a constant flow of the attack packets into the victim network to be effective.
Vulnerability attacks target protocol or implementation bugs in the victim’s systems. They base their success on much the same premise as intrusion attempts and worms do, relying on the presence of protocol and implementation bugs in the victim’s software that can be exploited for the attacker’s purpose. While intruders and worm writers simply want to break into the machine, the aim of the vulnerability attack is to crash it or otherwise cripple it. Future security mechanisms for defending against intrusions and worms and better software writing standards are likely to help address DDoS vulnerability attacks. In the meantime, patching and updating server machines and filtering malformed packets offer a significant immunity to known vulnerability attacks. A resourceful attacker could still bypass these defenses by detecting new vulnerabilities in the latest software releases and crafting new types of packets to exploit them. This is a subtle attack that requires a lot of skill and effort on the part of the attacker, and is not very common. There are much easier ways to deny service.
Flooding attacks target a specific resource and simply generate a lot of packets that consume it. Naturally, if the attack packets stood out in any way (e.g., they had a specific value in one of the header fields), defense mechanisms could easily filter them out. Since a flooding attack does not need any specific packets, attackers create a varied mixture of traffic that blends with the legitimate users’ traffic. They also use IP spoofing to create a greater variety of packet sources and hide agent identities. The victim perceives the flooding attack as a sudden flood of requests for service from numerous (potentially legitimate) users, and attempts to serve all of them, ultimately exhausting its resources and dropping any surplus traffic it cannot handle. As there are many more attack packets than the legitimate ones, legitimate traffic stands a very low chance of obtaining a share of the resource, and a good portion of it gets dropped. But the legitimate traffic does not lose only because of the high attack volume. It is usually congestion-responsive traffic—it perceives packet drops as a sign of congestion and reduces its sending rate. This decreases the chance of obtaining resources even further, resulting in more legitimate drops. The following characteristics of DDoS flooding attacks make these attacks very effective for the attacker’s purpose and extremely challenging for the defense:
• Simplicity. There are many DDoS tools that can be easily downloaded or otherwise obtained and set into action. They make agent recruitment and activation automatic, and can be used by inexperienced users. These tools are exceedingly simple, and some of them have been around for years. Still, they generate effective attacks with little or no tweaking.
• Traffic variety. The similarity of the attack traffic to legitimate traffic makes separation and filtering extremely hard. Unlike other security threats that need specially crafted packets (e.g., intrusions, worms, viruses), flooding attacks need only a high traffic volume and can vary packet contents and header values at will.
• IP spoofing. IP spoofing makes the attack traffic appear as if it comes from numerous legitimate clients. This defeats many resource-sharing approaches that identify a client by his IP address. If IP spoofing were eliminated, agents could potentially be distinguished from the legitimate clients by their aggressive sending patterns, and their traffic could be filtered. In the presence of IP spoofing, the victim sees a lot of service initiation requests from numerous seemingly legitimate users. While the victim could easily tell those packets apart from ongoing communications with the legitimate users, it cannot discern new legitimate requests for service from the attack ones. Thus, the victim cannot serve any new users during the attack. If the attack is long, the damage to victim’s business is obvious.
• High-volume traffic. The high volume of the attack traffic at the victim not only overwhelms the targeted resource, but makes traffic profiling hard. At such high packet rates, the defense mechanism can do only simple per-packet processing. The main challenge of DDoS defense is to discern the legitimate from the attack traffic, at high packet speeds.
• Numerous agent machines. The strength of a DDoS attack lies in the numerous agent machines distributed all over the Internet. With so many agents, the attacker can take on even the largest networks, and she can vary her attack by deploying subsets of agents at a time or sending very few packets from each agent machine. Varying attack strategies defeat many defense mechanisms that attempt to trace back the attack to its source. Even in the cases when the attacker does not vary the attacking machines, the mere number of agents involved makes traceback an unattractive solution. What if we knew the identities of 10,000 machines that are attacking our network? This would hardly get us any closer to stopping the attack. The situation would clearly be simplified if the attacker were not able to recruit so many agents. As mentioned above, the general increase of Internet hosts and, more recently, the high percentage of novice Internet users suggest that the pool of potential agents will only increase in the future. Furthermore, the distributed Internet management model makes it unlikely that any security mechanism will be widely deployed. Thus, even if we found ways to secure machines permanently and make them impervious to the attacker’s intrusion attempts, it would take many years until these mechanisms would be sufficiently deployed to impact the DDoS threat.1
• Weak spots in the Internet topology. The current Internet hub-and-spoke topology has a handful of highly connected and very well provisioned spots that relay traffic for the rest of the Internet. These hubs are highly provisioned to handle heavy traffic in the first place, but if these few spots were taken down by an attacker or heavily congested, the Internet would grind to a halt. Amassing a large number of agent machines and generating heavy traffic passing through those hot spots would have a devastating effect on global connectivity. For further discussion of this threat, see [GOM03] or [AJB00, Bar02].
Let’s face it: A flooding DDoS attack seems like a perfect crime in the Internet realm. Means (attack tools) and accomplices (agent machines) are abundant and easily obtainable. A sufficient attack volume is likely to bring the strongest victim to its knees and the right mixture of the attack traffic, along with IP spoofing, will defeat attack filtering attempts. Since numerous businesses rely heavily on online access, taking that away is sure to inflict considerable damage to the victim. Finally, IP spoofing, numerous agent machines and lack of automated tracing mechanisms across the networks guarantee little to no risk to perpetrators of being caught.
The seriousness of the DDoS problem and the increased frequency, sophistication and strength of attacks have led to the advent of numerous defense mechanisms. Yet, although a great effort has been invested in research and development, the problem is hardly dented, let alone solved. Why is this so?
5.2 DDoS Defense Challenges
The challenges in designing DDoS defense systems fall roughly into two categories: technical challenges and social challenges. Technical challenges encompass problems associated with the current Internet protocols and characteristics of the DDoS threat. Social challenges, on the other hand, largely pertain to the manner in which a successful technical solution will be introduced to Internet users, and accepted and widely deployed by these users.
The main problem that permeates both technical and social issues is the problem of large scale. DDoS is a distributed threat that requires a myriad of overlapping “solutions” to various aspects of the DDoS problem, which must be spread across the Internet because attacking machines may be spread all over the Internet. Clearly, attack streams can only be controlled if there is a point of defense between the agents and the victims. One approach is to place one defense system close to the victim so that it monitors and controls all of the incoming traffic. This approach has many deficiencies, the main one being that the system must be able to efficiently handle and process huge traffic volumes. The other approach is to divide this workload by deploying distributed defenses. Defense systems must then be deployed in a widespread manner to ensure effective action for any combination of agent and victim machines. As widespread deployment cannot be guaranteed, the technical challenge lies in designing effective defenses that can provide reasonable performance even if they are sparsely deployed. The social challenge lies in designing an economic model of a defense system in a manner that motivates large-scale deployment in the Internet.
5.2.1 Technical Challenges
The distributed nature of DDoS attacks, similarity of the attack packets to the legitimate ones, and the use of IP spoofing represent the main technical challenges to designing effective DDoS defense systems, as discussed in Section 5.1. In addition to that, the advance of DDoS defense research has historically been hindered by the lack of attack information and absence of standardized evaluation and testing approaches. The following list summarizes and discusses technical challenges for DDoS defense.
• Need for a distributed response at many points in the Internet. There are many possible DDoS attacks, very few of which can be handled only by the victim. Thus, it is necessary to have a distributed, possibly coordinated, response system. It is also crucial that the response be deployed at many points in the Internet to cover diverse choices of agents and victims. Since the Internet is administered in a distributed manner, wide deployment of any defense system (or even various systems that could cooperate) cannot be enforced or guaranteed. This discourages many researchers from even considering distributed solutions.
• Lack of detailed attack information. It is widely believed that reporting occurrences of attacks damages the business reputation of the victim network. Therefore, very limited information exists about various attacks, and incidents are reported only to government organizations under obligation to keep them secret. It is difficult to design imaginative solutions to the problem if one cannot become familiar with it. Note that the attack information should not be confused with attack tool information, which is publicly available at many Internet sites. Attack information would include the attack type, time and duration of the attack, number of agents involved (if this information is known), attempted response and its effectiveness, and damages suffered. Appendix C summarizes the limited amount of publicly available attack information.
• Lack of defense system benchmarks. Many vendors make bold claims that their solution completely handles the DDoS problem. There is currently no standardized approach for testing DDoS defense systems that would enable their comparison and characterization. This has two detrimental influences on DDoS research: (1) Since there is no attack benchmark, defense designers are allowed to present those tests that are most advantageous to their system; and (2) researchers cannot compare actual performance of their solutions to existing defenses; instead, they can only comment on design issues.
• Difficulty of large-scale testing. DDoS defenses need to be tested in a realistic environment. This is currently impossible due to the lack of large-scale test beds, safe ways to perform live distributed experiments across the Internet, or detailed and realistic simulation tools that can support several thousand nodes. Claims about defense system performance are thus made based on small-scale experiments or simulations and are not credible.
This situation, however, is likely to change soon. The National Science Foundation and the Department of Homeland Security are currently funding a development of a large-scale test bed and have sponsored research efforts to design benchmarking suites and measurement methodology for security systems evaluation [USC]. We expect that this will greatly improve quality of research in DDoS defense field. Some test beds are in use right now by DDoS researchers (e.g. PlanetLab [BBC+04] and Emulab/Netbed [WLS+02]).
5.2.2 Social Challenges
Many DDoS defense systems require certain deployment patterns to be effective. Those patterns fall into several categories.
• Complete deployment. A given system is deployed at each host, router, or network in the Internet.
• Contiguous deployment. A given system is deployed at hosts (or routers) that are directly connected.
• Large-scale, widespread deployment. The majority of hosts (or routers) in the Internet deploy a given system.
• Complete deployment at specified points in the Internet. There is a set of carefully selected deployment points. All points must deploy the proposed defense to achieve the desired security.
• Modification of widely deployed Internet protocols, such as TCP, IP or HTTP.
• All (legitimate) clients of the protected target deploy defenses.
None of the preceding deployment patterns are practical in the general case of protecting a generic end network from DDoS attacks (although some may work well to protect an important server or application that communicates with a selected set of clients). The Internet is extremely large and is managed in a distributed manner. No solution, no matter how effective, can be deployed simultaneously in hundreds of millions of disparate places. However, there have been quite a few cases of an Internet product (a protocol, an application, or a system) that has become so popular after release that it was very widely deployed within a short time. Examples include Kazaa, the SSH (Secure Shell) protocol, Internet Explorer, and Windows OS. The following factors determine a product’s chances for wide deployment:
• Good performance. A product must meet the needs of customers. The performance requirement is not stringent, and any product that improves the current state is good enough.
• Good economic model. Each customer must gain direct economic benefit, or at least reduce the risk of economic loss, by deploying the product. Alternately, the customer must be able to charge others for improved services resulting from deployment.
• Incremental benefit. As the degree of deployment increases, customers might experience increased benefits. However, a product must offer considerable benefit to its customers even under sparse partial deployment.
Development of better patch management solutions, better end-host integrity and configuration management solutions, and better host-based incident response and forensic analysis solutions will help solve the first phase of DDoS problems—the ability to recruit a large agent network. Building a DDoS defense system that is itself distributed, with good performance at sparse deployment, with a solid economic model and an incremental benefit to its customers, is likely to ensure its wide deployment and make an impact on second-phase DDoS threat—defending the target from an ongoing attack.
In the remainder of this chapter we discuss basic DDoS defense approaches at a high level. In Chapter 6, we get very detailed and describe what steps you should take today to make your computer, network, or company less vulnerable to DDoS attacks, and what to do if you are the target of such an attack. In Chapter 7, we provide deeper technical details of actual research implementations of various defense approaches. This chapter is intended to familiarize you with the basics and to outline the options at a high conceptual level.
5.3 Prevention versus Protection and Reaction
As with handling other computer security threats, there are two basic styles of protecting the target of a DDoS attack: We can try to prevent the attacks from happening at all, or we can try to detect and then react effectively when they do occur.
5.3.1 Preventive Measures
Prevention is clearly desirable, when it can be done. A simple and effective way to make it impossible to perform a DDoS attack on any Internet site would be the best solution, but it does not appear practical. However, there is still value in preventive measures that make some simple DDoS attacks impossible, or that make many DDoS attacks more difficult. Reasonably effective preventive defenses deter attackers: If their attack is unlikely to succeed, they may choose not to launch it, or at least choose a more vulnerable victim. (Remember, however, that if the attacker is highly motivated to hit you in particular, making the attack a bit more difficult might not deter her.)
There are two ways to prevent DDoS attacks: (1) We can prevent attackers from launching an attack, and (2) we can improve our system’s capacity, resiliency, and ability to adjust to increased load so that an ongoing attack fails to prevent our system from continuing to offer service to its legitimate clients.
Measures intended to make DDoS attacks impossible include making it hard for attackers to compromise enough machines to launch effective DDoS attacks, charging for network usage (so that sending enough packets to perform an effective DDoS attack becomes economically infeasible), or limiting the number of packets forwarded from any source to any particular destination during a particular period of time. Such measures are not necessarily easy to implement, and some of them go against the original spirit of the Internet, but they do illustrate ways in which the basis of the DoS effect could be undermined, at least in principle.
Hardening the typical node to make it less likely to become a DDoS agent is clearly worthwhile. Past experience and common sense suggest, however, that this approach can never be completely effective. Even if the typical user’s or administrator’s vigilance and care increase significantly, there will always be machines that are not running the most recently patched version of their software, or that have left open ports that permit attackers to compromise them. Nonetheless, any improvement in this area will provide definite benefits in defending against DDoS attacks, and many other security threats such as intrusions and worms. More effective ways to prevent the compromise of machines would be extremely valuable. Similarly, methods that might limit the degree of damage that an attacker can cause from a site after compromising it might help, provided that the damage limitation included preventing the compromised site from sending vast numbers of packets.
Hardening a node or an entire installation to protect it from swelling the ranks of a DDoS army is no different from hardening them to protect from other network threats. Essentially, this is a question of computer and network hygiene. Entire books are written on this subject, and many of the necessary steps depend very much on the particular operating system and other software the user is running. If the reader does not already have access to such a book, many good ones can be found on the shelves of a typical bookstore that stocks computer books. So other than reiterating the vital importance of making it hard for an attacker to take control of your node, for complete details we refer the reader to resources specific to the kinds of machines, operating systems, and applications deployed.
While perfectly secure systems are a fantasy, not a feature of the next release of your favorite operating system, there are known things that can be done to improve the security of systems under development. More widespread use of these techniques will improve the security of our operating systems and applications, thus making our machines less likely to be compromised. Again, these are beyond the scope of this book and are subjects worthy of their own extended treatment. Possible avenues toward building more secure systems that might help us all avoid becoming unwilling draftees in a DDoS army in the future include the following:
• Better programmer education will lead to a generally higher level of application and operating system security. There are well-known methods to avoid common security bugs like buffer overflows, yet such problems are commonplace. A bettereducated programmer workforce might reduce the frequency of such problems.
• Improvements in software development and testing tools will make it easier for programmers to write code that does not have obvious security flaws, and for testers to find security problems early in the development process.
• Improvements in operating system security, both from a code quality point of view and from better designed security models for the system, will help. In addition to making systems harder to break into, these improvements might make it harder for an attacker to make complete use of a system shortly after she manages to run any piece of code on it, by compartmentalizing privileges or by having a higher awareness of proper and improper system operations.
• Automated tools for program verification will improve in their ability to find problems in code, allowing software developers to make stronger statements about the security of their code. This would allow consumers to choose to purchase more secure products, based on more than the word and reputation of the vendor. Similarly, development of better security metrics and benchmarks for security could give consumers more information about the risks they take when using a particular piece of software.
Beyond hardening nodes against compromise, prevention measures may be difficult to bring to bear against the DDoS problem. Many other types of prevention measures have the unfortunate characteristic of fundamentally changing the model of the Internet’s operation. Charging for packet sending or always throttling or metering packet flows might succeed in preventing many DDoS attacks, but they might also stifle innovative uses of the Internet. Anything based on charging for packets opens the Internet to new forms of attacks based on emptying people’s bank accounts by falsely sending packets under their identities. From a practical point of view, these types of prevention measures are unrealistic because they would require wholesale changes in the existing base of installed user machines, routers, firewalls, proxies, and other Internet equipment. Unless they can provide significant benefit to some segments of the Internet with more realistic partial deployment, they are unlikely to see real use.
Immunity to some forms of DDoS attack can potentially be achieved in a number of ways. For example, a server can be so heavily provisioned that it can withstand any amount of traffic that the backbone network could possibly deliver to it. Or the server and its router might accept packets from only a small number of trusted sites that will not participate in a DDoS attack. Of course, when designing a solution based on immunity, one must remember that the entire path to your installation must be made immune. It does little good to make it challenging to overload your server if it is trivial to flood your upstream ISP connection.
Some sites have largely protected themselves from the DDoS threat by these kinds of immunity measures, so they are not merely theoretical. For example, during the DDoS attacks on the DNS root servers in October 2002, all of the DNS servers were able to keep up with the DNS requests that reached them, since they all were sufficiently provisioned with processing power and memory [Nar]. Some of them, however, did not have enough incoming bandwidth to carry both the attack traffic and the legitimate requests. Those servers thus did not see all of the DNS requests that were sent to them. Other root servers were able to keep up with both the DDoS traffic (which consisted of a randomized mixture of ICMP packets, TCP SYN requests, fragmented TCP packets, and UDP packets) and the legitimate requests because these sites had ample incoming bandwidth, had mirrored their content at multiple locations, or had hardware-switched load balancing that prevented individual links from being overloaded. A number of DDoS attacks on large sites have failed because they targeted companies’ sites that have high-bandwidth provisions to handle the normal periodic business demand for download of new software products, patches, and upgrades.
The major flaw to the immunity methods as an overall solution to the DDoS problem is that known immunity methods are either very expensive or greatly limit the functionality of a network node, often in ways that are incompatible with the node’s mission. For example, limiting the nodes that can communicate with a small business’s Web site limits its customer base and makes it impossible for new customers to browse through its wares. Further, many immunity mechanisms protect only against certain classes of attacks or against attacks up to a particular volume. An immunity mechanism that rejects all UDP packets does not protect against attacks based on floods of HTTP requests, for example, and investing in immunity by buying bandwidth equal to that of your ISP’s own links will be a poor investment if the attacker generates more traffic than the ISP can accept. If attackers switch to a different type of DDoS attack or recruit vastly larger numbers of agents, the supposed immunity might suddenly vanish.
5.3.2 Reactive Measures
If one cannot prevent an attack, one must react to it. In many cases, reactive measures are better than preventive ones. While there are many DDoS attacks on an Internet-wide basis, many nodes will never experience a DDoS attack, or will be attacked only rarely. If attacks are rare and the costs of preventing them are high, it may be better to invest less in prevention and more in reaction. A good reactive defense might incur little or no cost except in the rare cases where it is actually engaged.
Reaction does not mean no preparation. Your reaction may require you to contact other parties to enlist their assistance or to refer the matter to legal authorities. If you know who to contact, what they can do for you, and what kind of information they will need to do it, your reaction will be faster and more effective. If your reaction includes locally deployed technical mechanisms that expect advice or confirmation from your system administrators, understanding how to interact with them and the likely implications of following (or not following) their recommendations will undoubtedly pay off when an attack hits. Certainly, with the current state of DDoS defense mechanisms, your preparation should include some ability to analyze what’s going on in your network. As discussed in Chapter 6, many sites have assumed a DDoS attack when actually there was a different problem, and their responses have thus been slow, expensive, and ineffective. Being well prepared to detect and react to DDoS attacks will prove far more helpful than anything you can buy or install.
Unlike preventive measures, reactive measures require attack detection. No reaction can take place until a problem is noticed and understood. Thus, the effectiveness of reactive measures to DDoS attacks depends not only on how well they reduce the DoS effect once they are deployed, but also on the accuracy of the system that determines which defenses are required to deal with a particular attack, when to invoke them, and where to deploy them. False positives, signals that DDoS attacks are occurring when actually they are not, may be an issue for the detection mechanism, especially if some undesirable costs or inconveniences are incurred when the reactive defense is deployed. At the extreme, if the detection mechanism falsely indicates that the reactive defense needs to be employed all the time, a supposedly reactive mechanism effectively becomes a preventive one, probably at a higher cost than having designed it to prevent attacks in the first place.
Reactive defenses should take effect as quickly as possible once the detection mechanism requests them. Taking effect does not mean merely being turned on, but reaching the point where they effectively stop (or, at least, reduce) the DoS effect. Presuming that there is some cost to engaging the reactive defense, this defense should be turned off as soon as the DoS attack is over. On the other hand, the defense must not be turned off so quickly that an attacker can achieve the DoS effect by stopping his attack and resuming it after a brief while, repeating the cycle as necessary.
Regardless of the form of defense chosen, the designers and users of the defenses must keep their real aim in mind. Any DoS attack, including distributed DoS attacks, aims to cripple the normal operation of its target. The attack’s goal is not really to deliver vast numbers of attack packets to the target, but to prevent the target from servicing most or all of its legitimate traffic. Thus, defenses must not only stop the attack traffic, but must let legitimate traffic through. If one does not care about handling legitimate traffic, a wonderful preventive defense is to pull out the network cable from one’s computer. Certainly, attackers will not be able to flood your computer with attack packets, but neither can your legitimate customers reach you. A defensive mechanism that, in effect, “pulls the network cable” for both good and bad traffic is usually no better than the attack itself. However, in cases in which restoring internal network operations is more important than allowing continued connectivity to the Internet, pulling the cable, either literally or figuratively, may be the lesser of two evils.
5.4 DDoS Defense Goals
Whether our DDoS defense strategy is preventive, reactive, or a combination of both, there are some basic goals we want it to achieve.
• Effectiveness. A good DDoS defense should actually defend. It should provide either effective prevention that really makes attacks impossible or effective reaction ensuring that the DoS effect goes away. In the case of reactive mechanisms, the response should be sufficiently quick to ensure that the target does not suffer seriously from the attack.
• Completeness. A good DDoS defense should handle all possible attacks. If that degree of perfection is impossible, it should at least handle a large number of them. A mechanism that is capable of handling an attack based on TCP SYN flooding, but cannot offer any assistance if a ping flood arrives, is clearly less valuable than a defense that can handle both styles of attack. Thus, a preventive measure like TCP SYN cookies helps but is not sufficient unless coupled with other defense mechanisms. Completeness is also required in detection and reaction. If our detection mechanism does not recognize a particular pattern of incoming packets as an attack, presumably it will not invoke any response and the attack will succeed.
While completeness is an obvious goal, it is extremely hard to achieve, since attackers are likely to develop new types of attacks specifically designed to bypass existing defenses. Defensive mechanisms that target the fundamental basis of DoS attacks are somewhat more likely to achieve completeness than those targeted at characteristics of particular attacks, even if those are popular attacks. For example, a mechanism that validates which packets are legitimate with high accuracy and concentrates on delivering only as many such packets as the target can handle is more likely to be complete than a mechanism that filters out packets based on knowledge of how a particular popular DDoS toolkit chooses its spoofed source addresses. However, it is often easier to counter a particular attack than to close basic vulnerabilities in networks and operating systems. Virus detection programs have shown that fairly complete defenses can be built by combining a large number of very specific defenses. A similar approach might solve the practical DDoS problem, even if it did not theoretically handle all possible DDoS attacks.
• Provide service to all legitimate traffic. As mentioned earlier, the core goal of DDoS defense is not to stop DDoS attack packets, but to ensure that the legitimate users can continue to perform their normal activities despite the presence of a DDoS attack. Clearly, a good defense mechanism must achieve that goal.
Some legitimate traffic may be flowing from sites that are also sending attack traffic. Other legitimate traffic is destined for nodes on the same network as the target node. There may be legitimate traffic that is neither coming from an attack machine nor being delivered to the target’s network, but perhaps shares some portion of its path through the Internet with some of the attack traffic. And some legitimate traffic may share other characteristics with the attack traffic, such as application protocol or destination port, potentially making it difficult to distinguish between them. None of these legitimate traffic categories should be disturbed by the DDoS defense mechanism. Legitimate traffic dropped by a DDoS defense mechanism has suffered collateral damage. (Collateral damage is also used to refer to cases where a third party who is not actually the target of the attack suffers damage from the attack.) Since DDoS attackers often strive to conceal their attack traffic in the legitimate traffic stream, it is common for legitimate traffic to closely resemble the attack packets, so the problem of collateral damage is real and serious.
Consider a DDoS defense mechanism that detects that a DDoS attack stream is coming from a local machine and then shuts down all outgoing traffic from that machine. Assuming high accuracy and sufficient deployment, such a mechanism would indeed stop the DDoS attack, but it would also stop much legitimate traffic. As mentioned early in this chapter, many machines that send DDoS attack streams are themselves victims of the true perpetrators of the attacks. It would be undesirable to shut down their perfectly legitimate activities simply because they have been taken over by a malicious adversary.2
If a DDoS defense mechanism develops some form of signature by which it distinguishes attack packets from nonattack packets, then unfortunate legitimate packets that happen to share that signature are likely to suffer at the hands of the DDoS defense mechanism. For example, a Web server might be flooded by HTTP request packets. If a DDoS defense mechanism decides that all HTTP request packets are attack packets, using that as the signature to determine which packets to drop, not only will the packets attacking the Web server be dropped, but so will all of the server’s legitimate traffic.
Many proposed DDoS defenses inflict significant collateral damage in some situations. While all collateral damage is bad, damage done to true third parties, who are neither at the sending nor receiving end of the attack, is probably the worst form of collateral damage. Any defense mechanism that deploys filtering, rate limiting, or other technologies that impede normal packet handling in the core of the network must be carefully designed to avoid all such third-party collateral damage.
• Low false-positive rates. Good DDoS defense mechanisms should target only true DDoS attacks. Preventive mechanisms should not have the effect of hurting other forms of network traffic. Reactive mechanisms should be activated only when a DDoS attack is actually under way. False positives may cause collateral damage in many cases, but there are other undesirable properties of high false-positive rates. For example, when a reactive system detects and responds to a DDoS attack, it might signal the system administrator of the targeted system that it is taking action. If most such signals prove to be false, the system administrator will start to ignore them, and might even choose to turn the defense mechanism off. Also, reactive mechanisms are likely to have costs of some sort. Perhaps they use some fraction of a system’s processing power, perhaps they induce some delay on all packets, or, in the longer term, perhaps a sufficiently frequent occurrence of reactions demands investment in a more powerful piece of defensive equipment. If these costs are frequently paid when no attack is under way, then the costs of running the defense system may outweigh the benefits achieved in those rare cases when an attack actually occurs.
• Low deployment and operational costs. DDoS defenses are meant to allow systems to continue operations during DDoS attacks, which, despite being very harmful, occur relatively rarely. The costs associated with the defense system must be commensurate with the benefits provided by it. For commercial solutions, there is an obvious economic cost of buying the hardware and software required to run it. Usually, there are also significant system administration costs with setting up new security equipment or software. Depending on the character of the DDoS defense mechanism, it may require frequent ongoing administration. For example, a mechanism based on detecting signatures of particular attacks will need to receive updates as new attacks are characterized, requiring either manual or automated actions.
Other operational costs relate to overheads imposed by the defense system. A system that performs stateful inspection of all incoming packets may delay each packet, for example. Or a system that throttles data streams from suspicious sources may slow down any legitimate interactions with those sources. Unless such costs are extremely low or extremely rarely paid, they must be balanced against the benefits of achieving some degree of protection against DDoS attacks.
You must further remember that part of the cost you will need to pay to protect yourself against DDoS attacks will not be in delays or CPU cycles, nor even in money spent to purchase a piece of hardware or software. Nothing beats preparation, and preparation takes time. You need to spend time carefully analyzing your network, developing an emergency plan, training your employees to recognize and deal with a DDoS attack, contacting and negotiating with your ISP and other parties who may need to help you in the case of an attack, and taking many other steps to be ready. The cost of any proposed DDoS solution must take these elements into account.
5.5 DDoS Defense Locations
The DDoS threat can be countered at different locations in the network. A DDoS attack consists of several streams of attack packets originating at different source networks. Each stream flows out of a machine; through a server or router into the Internet; across one or more core Internet routers; into the router, server, or firewall machine that controls access to the target machine’s network; and finally to the target itself. Defense mechanisms can be placed at some or all of these locations. Each possible location has its strengths and weaknesses, which we discuss in this section.
Figure 5.1 shows a highly simplified network with several user machines at different locations, border routers that attach local area networks to the overall network, and a few core routers. This figure will be used to illustrate various defensive locations. In this and later figures, the node at the right marked T is the target of the DDoS attack, and nodes A1, A2, and A3 are sources of attack streams.
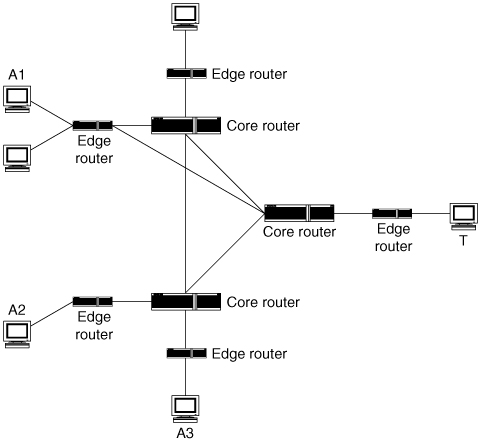
Figure 5.1. A simplified network
5.5.1 Near the Target
The most obvious location for a DDoS defense system is near the target (the area surrounded by a dashed rectangle in Figure 5.2). Defenses could be located on the target’s own machine, or at a router, firewall, gateway, proxy, or other machine that is very close to the target. Most existing defense mechanisms that protect against other network threats tend to be located near the target, for very good reasons. Many of those reasons are equally applicable to DDoS defense. Nodes near the target are in good positions to know when an attack is ongoing. They might be able to directly observe the attack, but even if they cannot, they are quite close to the target and often have a trust relationship with that target. The target can often tell them when it is under attack. Also, the target is the single node in the network that receives the most complete information about the characteristics of the attack, since all of the attack packets are observed there. Mechanisms located elsewhere will see only a partial picture and might need to take action based on incomplete knowledge.
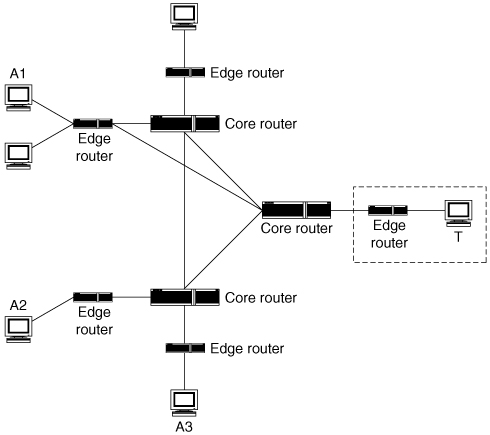
Figure 5.2. Deployment near the attack’s target
Another advantage of locating a defense near the target is deployment motivation. Those who are particularly worried about the danger of DDoS attacks will pay the price of deploying such a defense mechanism, while those who are unaware or do not care about the threat need not pay. Further, the benefit of deploying the mechanism accrues directly to the entity that paid for it. Historically, mechanisms with these characteristics (such as firewalls and intrusion detection systems) have proved to be more widely accepted than mechanisms that require wide deployment for the common good (such as ingress/egress filtering of spoofed IP packets).
A further advantage of deployment near the target is maximum control by the entity receiving protection. If the defense mechanism proves to be flawed, perhaps generating large numbers of false positives, the target machine that suffers from those flaws can turn off or adjust the defense mechanism fairly easily. Similarly, different users who choose different trade-offs between the price they pay for defense and the amount of protection they receive can independently implement those choices when the defense mechanisms are close to them and under their control. (Note that this advantage assumes a rather knowledgeable and careful user. It is far more common for users to install a piece of software or hardware using whatever defaults it specifies, and then never touch it again unless problems arise.)
But there are also serious disadvantages to defense mechanisms located close to the target. A major disadvantage is that a DDoS attack, by definition, overwhelms the target with its volume. Unless the defense mechanism can handle this load more cheaply than the target, or is much better provisioned than the target, it is in danger of being similarly overloaded. Instead of spending a great deal of money to heavily provision a defense box whose only benefit is to help out during DDoS attacks, one might be better off spending the same money to increase the power of the target machine itself. In some cases where the defense mechanism is just a little bit upstream of the potential target, we may gain advantages by sharing the defense mechanism among many different potential targets, somewhat lessening this problem, since several entities can pool the resources they are willing to devote to DDoS defense on a more powerful mechanism.
A less obvious problem with this location is that the target may be in a poor position to perform actions that require complex analysis and differentiation of legitimate and attack packets. The defense mechanism in this location is, as noted above, itself in danger of being overwhelmed. Unless it is very heavily provisioned, it will need to perform rather limited per-packet analysis to differentiate good packets from attack traffic. Such mechanisms are thus at risk of throwing away the good packets with the bad.
A further potential disadvantage is that, unless the solution is totally automated and completely effective, some human being at the target will have to help in the analysis and defense deployment. If you do not have a person on your staff capable of doing that, you will have to enlist the assistance of others who are not at your site, which limits the advantages of the defense being purely local. Further, if the flood is large and the necessary countermeasures are not obvious, many of your local resources could well be overwhelmed, not least of which are the human resources you need to adjust your defenses to the attack. This problem may not be too serious for very large sites that maintain many highly trained system and network administrators, but it could be critical for a small site that has few or no trained computer professionals on its regular staff.
A final disadvantage is that deployment near each potential target benefits only that target. Every edge network that needs protection must independently deploy its own defense, gaining little benefit from any defense deployed by other edge networks. The overall cost of protecting all nodes in the Internet using this pattern of deployment might prove higher than the costs of deploying mechanisms at other locations that provide protection to wider groups of nodes.
5.5.2 Near the Attacker
Figure 5.3 illustrates the option of deploying a defense mechanism near attack sources. Such a defense could be statically deployed at most or all locations from which attacks could possibly originate or could be dynamically created at locations close to where streams belonging to a particular ongoing attack actually are occurring. The multiple dotted rectangles in Figure 5.3 suggest one important characteristic of locating the defense near the attacker. An effective defense close to the attacker must actually be located close to all or most of the attackers. If the attack is coming from A1 and A2, but the defense is deployed only at A3, it will not be able to stop this attack. Even if it is deployed also at A2, the attack streams coming out of A1 will not be affected by the defense.
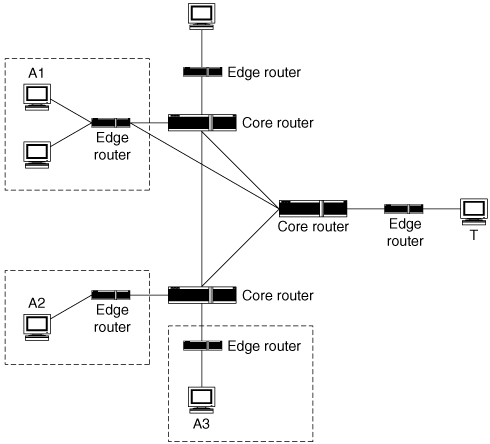
Figure 5.3. Deployment near attack sources
One advantage of this deployment location is that DDoS attack streams are not highly aggregated close to the source, unlike close to the attack’s target. They are of a much lower volume, allowing more processing to be devoted to detecting and characterizing them than is possible close to the target. This low volume and lack of aggregation may also prove helpful in separating the packets participating in an attack from those that are innocent traffic.
There are also disadvantages. Typically, a host that originates a DDoS attack stream suffers little direct adverse effect from doing so.3 Its attack stream is a tiny fraction of the huge flood that will swamp the target, and thus will rarely cause problems to its own network. A DDoS defense system located close to a source might have trouble determining that there is an attack going on. Even if it does know that an attack is being sent out of its network, the defense mechanism must determine which of its packets belong to attack streams. Existing research has shown that some legitimate traffic can be differentiated from attack traffic at this point, but it is not clear that all traffic can be confidently characterized as legitimate or harmful.
The second disadvantage is deployment motivation. A DDoS defense node close to a source will provide its benefits to other nodes and networks, not to the node where the attack originates or to its local network. Thus, there are few direct economic advantages to deploying a DDoS defense node of this kind, leading to a variant on the tragedy of the commons.4 While everyone might be better off if all participants deployed an effective DDoS defense system at the exit point of their own network, nobody benefits much from his own deployment of such a system. The benefits derive from the overall deployment by everyone, with no incremental benefit accruing to the individual who must perform each deployment.
If there were advantages to deploying a source-end defense system, then this problem might be overcome. Proponents of these kinds of solutions have thus devoted some effort to finding such advantages. One possible advantage is that a target-end defense might form a trust relationship with the source-end network that polices its own traffic. During an attack, this trust relationship may bring privileged status to this source-end network, delivering its packets despite the DDoS attack. Another possible advantage is that one might avoid legal liability by preventing DDoS flows from originating in one’s network, though it is unclear if existing law would impose any such liability. Finally, there is the advantage that accrues from being known as a good network citizen. However, these motivations have not been sufficient to ensure widespread deployment of other defense mechanisms with a similar character. For example, egress filtering at the exit router of the originator’s local network can detect most packets with spoofed IP source addresses before they get outside that network (see Chapter 4 for details on ingress and egress filtering). However, despite the feature’s being available on popular routing platforms and recommendations from knowledgeable sources to enable it, many installers do not turn it on.5 DDoS defense mechanisms designed to operate close to potential sources would need to overcome similar reluctance.
The reluctance will be even greater if the defense mechanism does not have superb discrimination. If the defense’s ability to separate attack traffic from good traffic is poor, it will harm many legitimate packets. Assuming that the mechanism either drops or delays packets that it classifies as part of the attack, anyone who chooses to deploy the mechanism will suddenly see some of her legitimate traffic being harmed. Perhaps the defense mechanism will even start dropping good packets when no attack stream is actually coming out of the local network. If so, it would be quickly turned off and discarded.
A final disadvantage is the deployment scale required for this approach to be effective. If attack streams emanate from 10,000 sources to converge on one poor victim, this style of defense mechanism would need to be deployed close to a significant fraction of those 10,000 sources to do much good. A DDoS defense mechanism that is only applied to 5 to 10% of the attack packets will very likely do no good. The attacker would merely need to recruit 5 to 10% more machines to perform his attack, not a very challenging task. Unless the defense mechanism in question is located near a large fraction of all possible sites, it would not have enough coverage to be effective.
5.5.3 In the Middle
Deployments in the middle of the network generally refer to defenses living at core Internet routers (depicted in Figure 5.4). As a rule, such defenses are deployed at more than one core router, as the figure suggests. However, deployment “in the middle” might also refer to routers and other network nodes that are close to the target but not part of the target’s network, such as an ISP. At some point, “middle” blends into “edges,” and the deployment location is really near the target or near the attacker, having the characteristics of those locations. For true core deployments, there are obvious advantages and disadvantages.
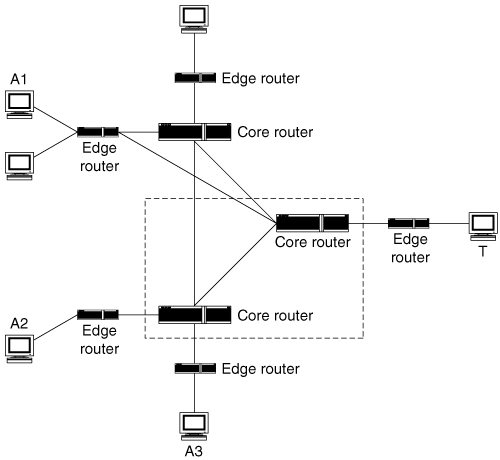
Figure 5.4. Deployment in the middle of the Internet
The vast bulk of the Internet’s traffic goes through a relatively small number of core Autonomous Systems (ASs), each of which deploys a large, but not immense, number of routers to carry that traffic. Thus, any defense located at a reasonably large number of well-chosen ASs can get excellent coverage. To the degree that the defense is effective, it can provide its benefit to practically every node attached to the Internet. In Figure 5.4, if the defense is located at the two routers shown, all traffic coming from the three attack sources will pass through it. Further, even if there were a different victim (say T1, located in the same network as A3), the same two deployment points would offer protection to that victim against all attack traffic except that originating in its own network. (Core defenses inherently cannot protect against attacks that do not traverse the core; most attacks do, however.) If core defenses were effective, accurate, cheap, and easy to deploy, they could thus completely solve the problem of DDoS attacks.
These caveats suggest the disadvantages of deploying DDoS defense in the middle of the network. First, routers at core ASs are very busy machines. They cannot devote any substantial resources to handling or analyzing individual packets. Thus, a core defense mechanism cannot perform any but the most cursory per-packet inspection, and cannot perform any serious packet-level analysis to determine the presence, characteristics, or origins of a DDoS attack, even assuming we had analysis methods that could do so.
The basic problem in DDoS defense is, again, separating the huge volume of DDoS traffic from the relatively tiny volume of legitimate traffic. DDoS defenses at core routers cannot afford to devote many resources to making such differentiation decisions. They must have simple, cheap rules for dealing with the vast majority of the packets they see.
A second problem arises because core routers could inflict massive collateral damage if they are not exceptionally accurate in discriminating DDoS traffic from legitimate traffic. If they make mistakes at a rate that might be acceptable for a victim-side deployment, they could easily drop a huge amount of legitimate traffic. Those running core routers consider dropping legitimate traffic as extremely undesirable. Combined with their lack of resources to perform careful examination of packets, we thus would require the core defense to provide high accuracy with little analysis, a very challenging task.
Another problem with this deployment location is that core routers are unlikely to notice DDoS attacks. They themselves are unlikely to be overwhelmed, and they cannot afford to keep statistics on packets coming through on a per-destination basis. Perhaps they can afford to look for DDoS attacks by a statistical method that examines a tiny fraction of the total packets, looking for suspiciously high numbers of packets to a single destination, but one node’s overwhelming DDoS attack is another node’s ordinary daily business. There is ongoing research on using measurements of entropy in packet traffic to detect DDoS attacks in the core. However, proven methods applied at core routers are not likely to pinpoint all DDoS attacks without generating unacceptable levels of false positives.
Deployment incentives are also problematic for core-located DDoS defense mechanisms. By and large, the routers comprising the Internet backbone are not likely targets of DDoS attacks. They are heavily provisioned, are designed to perform well under high load, and are not easy to send packets to directly. Attackers are likely to need to deduce which network paths pass through such a router if they want to target it, which is not always easy. Thus, the companies running these machines would probably not receive direct benefit from deploying DDoS defenses. They would receive indirect benefit, since they typically try to minimize the time a packet travels through their system (and quickly dropping a packet because it is part of a DDoS flow certainly minimizes that time), and because their business ultimately depends on the usability of the Internet as a whole. On the other hand, their equipment is expensive and must operate correctly even under conditions of heavy strain, so they are generally little inclined to install unproven hardware and software. A very compelling case for the need for a particular defense mechanism, its correctness, and the acceptability of its performance would be required before there would be any hope of deployment in the core.
If a core router defense performs badly, many users would be affected. Yet, unlike defenses located in their own domains (whether source-side or victim-side), users would have no power to turn the defense mechanisms off or adjust them. Those running the Internet backbone cannot afford to field calls from every ISP or, worse, every user who is having her legitimate packets dropped by a core-deployed DDoS defense mechanism.
A final point against this form of defensive deployment is based on the respected end-to-end argument, which states that network functionality should be deployed at the endpoints of a network connection, not at nodes in the middle, unless it cannot be achieved at the endpoints or is so ubiquitously required by all traffic that it clearly belongs in the middle. While the end-to-end argument should not be regarded as the final deciding word in any discussion of network functionality, its careful application is arguably an important factor in the success of the Internet. Core-deployed DDoS defense mechanisms tend to run counter to the end-to-end argument, unless one can make a strong case for the impossibility of achieving similar results at the endpoints.
5.5.4 Multiple Deployment Locations
Some researchers have argued that an inherently distributed problem like DDoS requires a distributed solution. In the most trivial sense, we must have distributed solutions, unless someone comes up with a scheme that protects all potential targets against all possible attacks by deploying something at only one machine in the Internet. Most commercial solutions are, in this trivial sense, distributed, since each network that wants protection deploys its own solution. There are actually nontrivial distributed system problems related to this kind of deployment for other cyberdefenses, as exemplified by the issue of updating virus protection databases. Similarly, updating all target-side deployments to inform them of a new DDoS toolkit’s signatures would be such a distributed system problem even for this trivial form of distribution.
Some source end solutions operate purely autonomously to control a single network’s traffic, and these are distributed in the same trivial sense. All other types of defense schemes suggested to date are distributed in a less trivial sense. Some of those require defense deployment at the source and at the victim, with the defense systems communicating during an attack. Others require deployment at multiple core routers, which may also cooperate among themselves. Some require defense nodes scattered at the edge networks to cooperate. All these schemes will be discussed in more detail in Chapter 7.
There’s a simple argument for why distributed solutions are necessary. Source-side nondistributed deployments just will not happen at a high enough rate to solve the problem. Target-side deployments cannot handle high-volume flooding attacks. There is no single location in the network core where one can capture all attacks, since not all packets pass any single point in the Internet. What is left? A solution that is deployed in more than one place, or multiple cooperating solutions at different places. Hence, a distributed solution.
Perhaps each instance of such a solution can work independently, rendering its distributed nature nearly trivial. However, this seems unlikely, since the common characteristic of the flooding attacks that force distributed solutions is that you cannot observe all the traffic except at a point where there is too much of it to do anything with. Unless each instance can independently, based on its own local information, reach a conclusion on the character of the attack that is generally the same as the conclusion reached by other instances, independent defense points might not engage their defenses against enough attack traffic. Most likely, some information exchange between instances will be required to reach a common agreement on the presence and character of attacks and the nature of the response, leading to true distributed characteristics.
With a good design, a distributed defense could exploit the strong points of each defense location while minimizing its weaknesses. For example, locations at aggregation points near the target are in a good position to recognize attacks. Locations near the attackers are well positioned to differentiate between good and bad packets. Locations in the center of the network can achieve high defensive coverage with relatively few deployment points. One approach to solving the DDoS problem is stitching together a defensive network spanning these locations. One such distributed deployment is shown in Figure 5.5. This approach must avoid the pitfall of accumulating the weaknesses of the various defensive locations, in addition to their strengths. For example, if locations near potential attackers are reluctant to deploy defensive mechanisms because they see no direct benefit and core router owners hesitate because they are unwilling to take the risk of damaging many users’ traffic, a defense mechanism requiring deployments in both locations might be even less likely to be installed than one requiring deployment in only one of these locations.
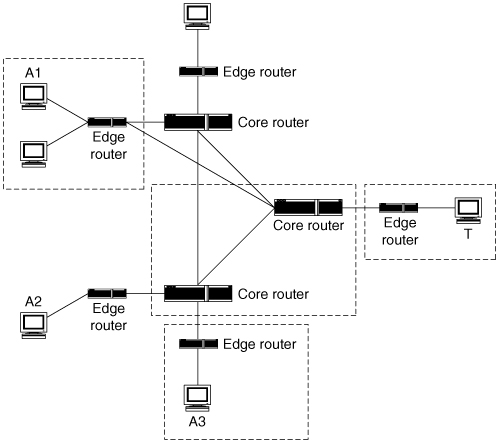
Figure 5.5. Distributed deployment
Generally speaking, a defensive scheme that deploys cooperating mechanisms at multiple locations requires handling the many well-known difficulties of properly designing a distributed system. Distributed systems, while potentially powerful, are notorious for being bug-ridden and prone to unpredicted performance problems. Given that a distributed DDoS defense scheme is likely to be a tempting target for attackers, it must carefully resolve all distributed system problems that may create weak points in the defense system. These problems include standard distributed system issues (such as synchronization of various participants and behavior in the face of partial failures) and security concerns of distributed systems (such as handling misbehavior by some supposedly legitimate participants).
5.6 Defense Approaches
Given the basic dichotomy between prevention and reaction, the goals of DDoS defense, and the three types of locations where defenses can be located, we will now discuss the basic options on how to defend against DDoS attacks that have been investigated, to date. The discussion here is at a high level, with few examples of actual systems that have been built or actions that you can take, since the purpose of this material is to lay out for you the entire range of options. Doing so will then make it easier for you to understand and evaluate the more detailed defense information presented in subsequent chapters.
Some DDoS defenses concentrate on protecting you against DDoS. They try to ensure that your network and system never suffer the DDoS effect. Other defenses concentrate on detecting attacks when they occur and responding to them to reduce the DDoS effect on your site. We will discuss each in turn.
Most of these approaches are not mutually exclusive, and one can build a more effective overall defense by combining several of them. Using a layered approach that combines several types of defenses, at several different locations, can be more flexible and harder for an attacker to completely bypass. This layering includes host-level tuning and adequate resources, close-proximity network-level defenses, as well as border- or perimeter-level network defenses.
5.6.1 Protection
Some protection approaches focus on eliminating the possibility of the attack. These attack prevention approaches introduce changes into Internet protocols, applications and hosts, to strengthen them against DDoS attempts. They patch existing vulnerabilities, correct bad protocol design, manage resource usage, and reduce the incidence of intrusions and exploits. Some approaches also advocate limiting computer versatility and disallowing certain functions within the network stack (see, for example, [BR00, BR01]). These approaches aspire to make the machines that deploy them impervious to DDoS attempts. Attack prevention completely eliminates some vulnerability attacks, impedes the attacker’s attempts to gain a large agent army, and generally pushes the bar for the attacker higher, making her work harder to achieve a DoS effect. However, while necessary for improving Internet security, prevention does not eliminate the DDoS threat.
Other protection approaches focus on enduring the attack without creating the DoS effect. These endurance approaches increase and redistribute a victim’s resources, enabling it to serve both legitimate and malicious requests during the attack, thus canceling the DoS effect. The increase is achieved either statically, by purchasing more resources, or dynamically, by acquiring resources at the sign of a possible attack from a set of distributed public servers and replicating the target service. Endurance approaches can significantly enhance a target’s resistance to DDoS—the attacker must now work exceptionally hard to deny the service. However, the effectiveness of endurance approaches is limited to cases in which increased resources are greater than the attack volume. Since an attacker can potentially gather hundreds of thousands of agent machines, endurance is not likely to offer a complete solution to the DDoS problem, particularly for individuals and small businesses that cannot afford to purchase the quantities of network resources required to withstand a large attack.
Hygiene Hygiene approaches try to close as many opportunities for DDoS attacks in your computers and networks as possible, on the generally sound theory that the best way to enhance security is to keep your network simple, well organized, and well maintained.
Fixing Host Vulnerabilities Vulnerability DDoS attacks target a software bug or an error in protocol or application design to deny service. Thus, the first step in maintaining network hygiene is keeping software packages patched and up to date. In addition, applications can also be run in a contained environment (for instance, see Provos’ Systrace [Pro03]), and closely observed to detect anomalous behavior or excess resource consumption.
Even when all software patches are applied as soon as they are available, it is impossible to guarantee the absence of bugs in software. To protect critical applications from denial of service, they can be duplicated on several servers, each running a different operating system and/or application version akin to biodiversity. This, however, greatly increases administrative requirements.
As described in Chapters 2 and 4, another major vulnerability that requires attention is more social than technical: weak or no passwords for remotely accessible services, such as Windows remote access for file services. Even a fully patched host behind a good firewall can be compromised if arbitrary IP addresses are allowed to connect to a system with a weak password on such a service. Malware, such as Phatbot, automates the identification and compromise of hosts that are vulnerable due to such password problems. Any good book on computer security or network administration should give you guidance on checking for and improving the quality of passwords on your system.
Fixing Network Organization Well-organized networks have no bottlenecks or hot spots that can become an easy target for a DDoS attack. A good way to organize a network is to spread critical applications across several servers, located in different subnetworks. The attacker then has to overwhelm all the servers to achieve denial of service. Providing path redundancy among network points creates a robust topology that cannot be easily disconnected. Network organization should be as simple as possible to facilitate easy understanding and management. (Note, however, that path redundancy and simplicity are not necessarily compatible goals, since multiple paths are inherently more complex than single paths. One must make a trade-off on these issues.)
A good network organization not only repels many attack attempts, it also increases robustness and minimizes the damage when attacks do occur. Since critical services are replicated throughout the network, machines affected by the attack can be quarantined and replaced by the healthy ones without service loss.
Filtering Dangerous Packets Most vulnerability attacks send specifically crafted packets to exploit a vulnerability on the target. Defenses against such attacks at least require inspection of packet headers, and often even deeper into the data portion of packets, in order to recognize the malicious traffic. However, data inspection cannot be done with most firewalls and routers. At the same time, filtering requires the use of an inline device. When there are features of packets that can be recognized with these devices, there are often reasons against such use. For example, a lot of rapid changes to firewall rules and router ACLs is often frowned upon for stability reasons (e.g., what if an accident leaves your firewall wide open?) Some types of Intrusion Prevention Systems (IPS), which act like an IDS in recognition of packets by signature and then filter or alter them in transit, could be used, but may be problematic and/or costly on very high bandwidth networks.
Source Validation
Source validation approaches verify the user’s identity prior to granting his service request. In some cases, these approaches are intended merely to combat IP spoofing. While the attacker can still exhaust the server’s resources by deploying a huge number of agents, this form of source validation prevents him from using IP spoofing, thus simplifying DDoS defense.
More ambitious source validation approaches seek to ensure that a human user (rather than DDoS agent software) is at the other end of a network connection, typically by performing so-called Reverse Turing tests.6 The most commonly used type of Reverse Turing test displays a slightly blurred or distorted picture and asks the user to type in the depicted symbols (see [vABHL03] for more details). This task is trivial for humans, yet very hard for computers. These approaches work well for Web-based queries, but could be hard to deploy for nongraphical terminals. Besides, imagine that you had to decipher some picture every time you needed to access an online service. Wouldn’t that be annoying? Further, this approach cannot work when the communications in question are not supposed to be handled directly by a human. If your server responds directly to any kind of request that is not typically generated by a person, Reverse Turing tests do not solve your problem. Pings, e-mail transfers between mail servers, time synchronization protocols, routing protocol updates, and DNS lookups are a few examples of computer-to-computer interactions that could not be protected by Reverse Turing tests.
Finally, some approaches verify the user’s legitimacy. In basic systems, this verification can be no more than checking the user’s IP address against a list of legitimate addresses. To achieve higher assurance, some systems require that the user present a certificate, issued by some well-known authority, that grants him access to the service, preferably for a limited time only. Since certificate verification is a cryptographic activity, it consumes a fair amount of the server’s resources and opens the possibility for another type of DDoS attack. In this attack, the attacker generates many bogus certificates and forces the server to spend resources verifying them.
Note that any agent machine that is capable of proving its legitimacy to the target will pass these tests. If nothing more is done by the target machine, once the test is passed an agent machine can perpetrate the DDoS attack at will. So an attacker who can recruit sufficient legitimate clients of his target as agents can defeat such systems. If you run an Internet business selling to the general public, you may have a huge number of clients who are able to prove their legitimacy, making the attacker’s recruitment problem not very challenging.
This difficulty can perhaps be addressed by requiring a bit more from machines that want to communicate with your site, using a technique called proof of work.
Proof of Work
Some protocols are asymmetric—they consume more resources on the server side than on the side of the client. Those protocols can be misused for denial of service. The attacker generates many service requests and ties up the server’s resources. If the protocol is such that the resources are released after a certain time, the attacker simply repeats the attack to keep the server’s resources constantly occupied.
One approach to protect against attacks on such asymmetric protocols is to redesign the protocols to delay commitment of the server’s resources. The protocol is balanced by introducing another asymmetric step, this time in the server’s favor, before committing the server’s resources. The server requires a proof of work from the client.
The asymmetric step should ensure that the client has spent sufficient resources for the communication before the server spends its own resources. A commonly used approach is to send a client some puzzle to solve (e.g., [JB99, CER96]). The puzzle is such that solving it takes a fair amount of time and resources, while verifying the correctness of the answer is fast and cheap. Such puzzles are called one-way functions or trapdoor functions [MvOV96]. For example, a server could easily generate a large number and ask the client to factor it. Factoring of large numbers is a hard problem and it takes a lot of time. Once the client provides the answer, it is easy to multiply all the factors and see that they produce the number from the puzzle. After verifying the answer, the server can send another puzzle or grant the service request. Of course, the client machine runs software that automatically performs the work requested of it, so the human user is never explicitly aware of the need to solve the puzzle.
The use of proof-of-work techniques ensures that the client has to spend a lot more resources than the server before his request is granted. The amount of work required must not be sufficiently onerous for legitimate clients to mind or even usually notice, but it must be sufficient to slow down DDoS agents very heavily, making it difficult or perhaps impossible for them to send enough messages to the target to cause a DDoS effect.
At best, proof-of-work techniques make attacks using spoofed source addresses against handshake protocols less effective from small- to moderate-sized attack networks. (The exact efficiency of these techniques is not clear.) DDoS attacks are still feasible if the attacker uses much larger attack networks. Beyond simple flooding, there are two possible ways to use spoofed packets to perform an attack against a proof-of-work system. One way is for the agents to generate a lot of requests, then let the server send out puzzles to many fake addresses, thus exhausting its resources. Since puzzle generation consumes very few resources, the attacker would have to amass many agents to make this attack effective. The other way is for agents to generate a lot of false solutions to puzzles with spoofed source addresses (with or without previously sending in spoofed requests). Since the server spends some resources to verify the reply, this could be a way to tie up the server’s resources and deny service. However, puzzle verification is also cheap for the server, and the attacker needs a huge number of agents to make this attack effective. (Keep in mind that some of today’s attackers do, indeed, already have a huge number of agents.) The only “economical” way to deny service is for agents to act like legitimate clients, sending valid service requests and providing correct solutions for puzzles, to lead the server to commit his resources. Spoofing cannot be used in this attack, since the agent machine must receive the puzzles from the target to solve them. If the requests are spoofed, the puzzle will be delivered to another machine and the agent will not be able to provide the desired answer.
Elimination of IP spoofing facilitates use of other DDoS defenses that may help in the latter case. Thus, proof-of-work techniques would best be combined with other defensive techniques.
There are several requirements to make the proof-of-work approach practical and effective. First, it would be good if the approach were transparent to the clients and deployed only by the server. Popular services have no way to ensure that their vast client population simultaneously upgrades the software. For these services, a proof-of-work solution will be practical only if it can be unilaterally deployed. For instance, imagine a protocol that goes as follows:
1. Client sends a request to the server.
2. Server allocates some resources and sends a reply back to the client.
3. Client allocates some resources and sends a reply back to the server.
4. Server grants the request.
This protocol can be balanced unilaterally by modifying steps 2 and 4. In step 2, the server does not allocate any resources. Instead, he embeds some information from the request in the reply he sends to the client. When the client replies, the server recreates the original request information in step 4 and allocates resources. The proof of work on the client side consists not in solving some puzzle, but in allocating resources, just like the original protocol prescribes. For this solution to work, the client must repeat the embedded information in his reply, so that the server can use it in step 4.
Consider the TCP protocol as an example. TCP performs a three-way handshake at connection establishment. In its original form, this was an asymmetric protocol that required the server to commit resources early in the protocol. The server allocates resources (transmission control blocks from a fixed length table) upon receipt of a connection request (SYN packet). If the client never completes the connection, the server’s resources remain allocated for a fairly long time. TCP SYN attacks, described in Chapter 4, allowed attackers to use this characteristic to perform a DoS attack with a relatively low volume of requests.
The TCP SYN cookie approach [Ber] modifies this protocol behavior to require the client to commit his resources first. The server encodes the information that would normally be stored in the transmission control block in the server’s initial sequence number value. The server then sends this value in the connection reply packet (SYN-ACK) to the client and does not preserve any state. If the client completes the connection (and allocates its own transmission control block locally), the server retrieves encoded information from client’s connection-completion packet and only then allocates a transmission control block. If the client never completes the connection, the server never allocates resources for this connection.
The second requirement for proof-of-work solutions is that the required work has to be equally hard for all clients, regardless of their hardware. Otherwise, an attacker who has compromised a powerful machine might be able to solve puzzles very quickly, thus generating enough requests to overwhelm the server despite solving all the puzzles. This requirement is hard to meet in the case of protocols that send out puzzles, because puzzle solving is computationally intensive and much easier for faster processors. Unless the amount of work is reasonable for even the least powerful legitimate client, a proof-of-work solution causes performance degradations even when no attack is ongoing. Some recent research [LC04] suggests that proofs hard enough to cause problems for attackers are so hard that many legitimate clients are hurt.
The third requirement states that theft or replay of answers must be prevented. In other words, a client himself must do the work. He cannot save and reuse old answers, and he cannot steal somebody else’s answer. Puzzle-generation techniques usually meet these requirements by generating time-dependent puzzles, and making them depend on the client identity.
Ultimately, proof-of-work systems cannot themselves defend against attacks that purely flood network bandwidth. Until the server machine establishes that the incoming message has not provided the required proof of work for a particular source, messages use up network resources. Similarly, putative (but false) proofs of work use up resources until their deception is discovered. Lastly, these techniques only work on protocols involving session setup (not UDP services, for example).
Resource Allocation
Denial of service is essentially based on one or more attack machines seizing an unfair share of the resources of the target. One class of DDoS protection approaches based on resource allocation (or fair resource sharing) approaches seeks to prevent DoS attacks by assigning a fair share of resources to each client. Since the attacker needs to steal resources from the legitimate users to deny service, resource allocation defeats this goal.
A major challenge for resource allocation approaches is establishing the user’s identity with confidence. If the attacker can fake his identity, he can exploit a resource allocation scheme to deny service. One attack method would be for the attacker to fake a legitimate user’s identity, and take over this user’s resources. Another attack method is to use IP spoofing to create a myriad of seemingly legitimate users. Since there are not enough resources to grant each user’s request, some clients will have to be rejected. Because fake users are much more numerous than the legitimate ones, they are likely to grab more resource slots, denying the service.
The common approach for establishing the user’s identity is to couple resource allocation with source validation schemes. Another approach is to combine resource allocation with a proof of work. Once the client submits the correct proof of work, the server is assured not only of the client’s identity but also of his commitment to this communication. Resource allocation can then make sure that no client can monopolize the service.
Bear in mind that the attacker can still perform a successful attack, in spite of a strong resource allocation scheme. Just like with proof-of-work or source validation approaches, a large number of attack agents can overload the system if they behave like the legitimate users. However, resource allocation significantly raises the bar for the attacker. He needs a lot more agents than before that can only send with a limited rate, and they must abstain from IP spoofing to pass the identity test. This makes the game much more balanced for the defenders than before.
However, unless resource allocation schemes are enforced throughout the entire Internet, the attacker can still attempt to flood the point at which resource allocations are first checked. Most such schemes are located near the target, often at its firewall or close to its connection to the Internet. At that point, the function that determines the owner of each message and performs accounting can reject incoming messages that go beyond their owners’ allocations, protecting downstream entities from flooding. But it cannot prevent itself from being flooded. A resource allocation defense point that can only handle 100 Mbps of incoming traffic can be overwhelmed by an attacker who sends 101 Mbps of traffic to it, even if he has not been allocated any downstream resources at all.
A further disadvantage of this approach is that it requires users to divulge their identities in verifiable ways, so that their resource usage can be properly accounted for. Many users are understandably reluctant to provide these kinds of identity assurances when not absolutely necessary. A DDoS solution that requires complete abandonment of all anonymous or pseudonymous interactions [DMS04] in the Internet has a serious downside. Some researchers are examining the use of temporary pseudonyms or other identity-obscuring techniques that might help solve this problem, but it is unclear if they would simultaneously prevent an attacker from obtaining as many of these pseudonyms as he needs to perpetrate his attack.
Hiding
None of the above approaches protect the server from bandwidth overload attacks that clog incoming links with random packets, creating congestion and pushing out the legitimate traffic. Hiding addresses this problem. Hiding obscures the server’s or the service’s location. As the attacker does not know how to access the server, he cannot attack it anymore. The server is usually hidden behind an “outer wall of guards.” Client requests first hit this wall, and then clients are challenged to prove their legitimacy. Any source validation or proof-of-work approach can be used to validate the client. The legitimacy test has to be sufficiently reliable to weed out attack agent machines. It also has to be distributed, so that the agents cannot crash the outer-wall guards by sending too many service requests. Legitimate clients’ requests are then relayed to the server via an overlay network. In some approaches, a validated client may be able to send his requests more directly, without going through the legitimacy test for every message or connection. In the extreme, trusted and preferred clients are given a permanent “passkey” that allows them to take a fast path to the service without ever providing further proof of legitimacy. There are clear risks to that extreme. An example hiding approach is SOS [KMR02], discussed in more detail in Chapter 7.
A poor man’s hiding scheme actually prevented one DDoS attack. The Code Red worm carried, among its other cargo, code intended to perform a DDoS attack on the White House’s Web site. However, the worm contained a hard-coded IP address for the victim’s Web site. When the worm was captured and analyzed, this IP address was identified and the target was protected simply by changing its IP address. By sending out routing updates that caused packets sent to the old address to be dropped, the attack packets would not even be delivered to the White House’s router. Had the worm instead used a DNS name to identify its victim, a DNS name resolution lookup would have occured. This would mean both worms and legitimate clients would be directed to any new IP address (thus making a change of the DNS host name to IP address mapping an ineffective solution.)7 This approach is not generally going to help you against a reasonably intelligent DDoS attacker, but it illustrates the basic idea.
Hiding approaches show a definite promise, but incur high cost to set up the overlay network and distribute guard machines all over the Internet. Further, client software is likely to need modification for various legitimacy tests. All this extra cost makes hiding impractical for protection of public and widely accessed services, but well suited for protection of corporate or military servers. A major disadvantage of hiding schemes is that they rely on the secrecy of the protected server’s IP address. If this secret is divulged, attackers can bypass the protection by sending packets directly to that address, and the scheme can become effective again only by changing the target’s address.
Some hiding solutions have been altered to provide defense benefits even when the protected target’s address is not a secret. More details can be found in Chapter 7, but, briefly, the target’s router is configured to allow messages to be delivered to the target only if they originate from certain hosts in a special overlay network. Legitimate users must prove themselves to the overlay network, while attackers trying to work through that network are filtered out. Whether this scheme can provide effective protection is uncertain at this time. At the least, flooding attacks on the router near the target will be effective if they can overcome that router’s incoming bandwidth.
Overprovisioning
Overprovisioning ensures that excess resources that can accommodate both the attack and the legitimate traffic are available, thus avoiding denial of service. Unlike previous approaches that deal with attack prevention, overprovisioning strengthens the victim to withstand the attack.
The most common approach is purchasing abundant incoming bandwidth and deploying a pool of servers behind a load balancer. The servers may share the load equally at all times, or they may be divided into the primary and backup servers, with backup machines being activated when primary ones cannot handle the load. Overprovisioning not only helps withstand DDoS attacks, but also accommodates spikes in the legitimate traffic due to sudden popularity of the service, so-called flash crowds. For more information on flash crowds and their similarity to DDoS attacks see [JKR02] and the discussion in Chapter 7.
Another approach is to purchase content distribution services from an organization that owns numerous Web and database servers located all over the Internet. Critical services are then replicated over these distributed servers. Client requests are redirected to the dedicated content distribution server, which sends them off to the closest or the least loaded server with the replicated service for processing. The content distribution service may dynamically increase its replication degree of a user’s content if enough requests are generated, possibly keeping ahead of even rapidly increasing volumes of DDoS requests.
After the attack on the DNS root servers in October 2002, many networks operating these services set up extra mirror sites for their service at geographically distributed locations. For example, ISC, which runs the DNS root server designated as the F server, expanded its mirroring to 20 sites on five continents, as of this writing, with plans to expand even further. The fairly static nature of the information stored at DNS root servers makes them excellent candidates for this defense technique.
Overprovisioning is by far the most widely used approach for DDoS defense. It raises the bar for the attacker, who must generate a sufficiently strong attack to overwhelm abundant resources. However, overprovisioning does not work equally well for all services. For instance, content distribution is easily implemented for static Web pages, but can be quite tricky for pages with dynamic content or those that offer access to a centralized database. Further, the cost of overprovisioning may be prohibitive for small systems. If a system does not usually experience high traffic volume, it needs modest resources for daily business. Purchasing just a bit more will not help fend off many DDoS attacks, while purchasing a lot more resources is wasteful, as they rarely get used. Finally, while it is more difficult to perpetrate a successful attack against a well-provisioned network, it is not impossible. The attacker simply needs to collect more agents—possibly a trivial task with today’s automated tools for malicious code propagation. With known attack networks numbering 400,000 or more, and some evidence suggesting the existence of million-node armies (see http://www.ladlass.com/archives/001938.html), one might question whether it is sufficient to prepare for DDoS attacks by overprovisioning.
5.6.2 Attack Detection
If protection approaches cannot make DDoS attacks impossible, then the defender must detect such attacks before he can respond to them. Even some of the protection approaches described above require attack detection. Certain protection schemes are rather expensive, and some researchers have suggested engaging them only when an attack is taking place, which implies the need for attack detection.
Two major goals of attack detection are accuracy and timeliness.
Accuracy is measured by how many detection errors are made. A detection method can err in two ways. It can falsely detect an attack in a situation when no attack was actually happening. This is called a false positive. If a system generates too many false positives, this may have dire consequences, as discussed in Section 5.3.2 The other way for a detection method to err is to miss an attack. This is called a false negative. While any detection method can occasionally be beaten by an industrious and persistent attacker, frequent false negatives signify an incomplete and faulty detection approach.
As the attack detection drives the engagement of the response, the performance of the whole DDoS defense system depends on the timeliness of the detection. Attacks that are detected and handled early may even be transparent to ordinary customers and cause no unpleasant disruptions. Detection after the attack has inflicted damage to the victim fails to prevent interruptions, but minimizes their duration by quickly engaging an appropriate response.
The difficulty of attack detection depends to a great extent on the deployment location and the desired detection speed. Detecting an attack at the victim site is trivial after the DoS effect becomes pronounced. It is like detecting that the dam has broken once your house is underwater. Usually, the network is either swamped by a sudden traffic flood or some of its key servers are slow or have crashed. This situation is so far from the desired that the crudest monitoring techniques can spot it and raise an alert. However, denial of service takes a toll on network resources and repels customers. Even if the response is promptly engaged, the disruption is bad for business. It is therefore desirable to detect an attack as early as possible, and respond to it, preventing the DoS effect and maintaining a good face to your customers. Although agent machines are usually synchronized by commands from a central authority and engaged all at once, the attack traffic will take some time (several seconds to a few minutes) to build up and consume the victim’s resources. This is the window where early detection must operate. What is desired is to detect that the water is seeping through a dam and evacuating the houses downstream minutes before the dam breaks.
The sensitivity and accuracy of attack detection deteriorate as monitoring is placed farther away from the victim. This is mostly due to incomplete observations, as monitoring techniques at the Internet core or close to attack sources cannot see all traffic that a victim receives, and cannot closely observe the victim’s behavior to spot problems. This is like trying to guess whether a dam will break by checking for leaks at a single spot in the dam. It may happen that the other places leak profusely while the one we are monitoring is dry and safe. It also may happen that all observed places leak very little and seem innocuous, but the total amount of water leaked is enough to flood the houses downstream.
Core-based detection techniques must be very crude, as core router resources are limited. This further decreases the accuracy. On the other hand, source-based detection techniques can be quite complex. Fortunately, since sources see only moderate traffic volumes even during the attack, they can afford to engage in extensive statistics gathering and sophisticated profiling.
Since target-based detection is clearly superior to core- and source-based attempts, why do we have detection techniques located away from the target? The reason lies in the fact that autonomous DDoS defense is far simpler and easier to secure than a distributed defense. DDoS response near the source is most effective and incurs the least collateral damage, and co-locating a detection module with the response builds an autonomous defense at the spot. Similarly, core-based response has the best yield, since a core deployment at a few response points can control a vast number of attack streams, irrespective of the source and victim locations. Adding a detection mechanism to core-based response builds autonomous and stable defense in the Internet core. Balancing the advantages and disadvantages of various detection locations is another complex task for defenders.
Once the attack has been successfully detected, the next crucial task is attack characterization. The detection module must be able to precisely describe the offending traffic, so that it can be sifted from the rest by the response module. Legitimate and attack traffic models used in detection, sometimes coupled with additional statistics and profiling, guide the attack characterization. The goal is to obtain a list of parameters from the packet header and contents, along with a range of values that indicate a legitimate or an attack packet. Each incoming packet is then matched against the list, and the response is selectively applied to packets deemed to be a likely part of an attack. Attack characterization is severely hindered by the fact that the attack and legitimate traffic look alike. However, good attack characterization is of immense importance to DDoS defense, as it determines the amount of collateral damage and the effectiveness of the response.
Three main approaches to attack detection are signature, anomaly, and misbehavior detection.
Signature Detection
Signature detection builds a database of attack characteristics observed in the past incidents—attack signatures. All incoming packets are compared against this database, and those that match are filtered out. Consequently, the signature must be carefully crafted to precisely specify the attack, but also, ensure that no legitimate traffic generates a match. The goal is reach a zero false-positive rate, but the effectiveness of signature detection is limited to those attacks that involve easy-to-match packet attributes. For example, the Land DoS attack [CER98a] sends packets whose source IP address and source port are the same as their destination IP address and port, causing some TCP/IP implementations to crash. As no legitimate application will ever need to send a similarly crafted packet, a check for equality of source and destination IP address and port can form a valid attack signature. This kind of check is so simple that it should always be performed. Other signatures can be much more complex.
Since vulnerability attacks can be successful with very few packets, signature detection that accurately pinpoints these packets (and helps filtering mechanisms to surgically remove them from the input stream) is an effective solution. On the other hand, signature detection cannot help with flooding DDoS attacks that generate random packets similar to legitimate traffic.
In addition to victim-end deployment, signature detection can be used at the source networks to identify the presence of agent machines. One approach is to monitor control traffic between agent machines and their handlers to look for telltale signs of DDoS commands. Most DDoS tools will format their control messages in a specific manner, or will embed some string in the messages. This can be used as a signature to single out DDoS control traffic. For example, one of the popular DDoS tools, TFN2K [CERb], pads all control packets with a specific sequence of ones and zeros. Modern DDoS tools use encrypted channels for control messages or use polymorphic techniques, both of which defeat signature-based detection of control traffic.
Another approach is to look for listening network ports used for control. Some DDoS tools using the handler/agent model require agents to actively listen on a specific port. While this open port can easily be changed by an attacker, there are a handful of widely popular DDoS tools that are usually deployed without modification. Hence, a tool-specific port can frequently make a good signature for agent detection. Detecting open ports requires port scanning suspected agent machines. Most of the modern DDoS tools evade port-based detection through use of IRC channels (sometimes encrypted) for control traffic. All agents and the attacker join a specific channel to send and receive messages. While the mere use of IRC does not provide a signal that a machine is involved in a DDoS attack, if the DDoS agents use cleartext messages on the channel (as many actually do), signature detection can be performed by examining the messages sent over IRC channels. If the use of IRC is prohibited on your machines (making the presence of IRC traffic a clear signal of problems), the attacker can instead embed commands in HTTP traffic or other forms of traffic that your network must permit.
A more sophisticated detection approach is to monitor flows to and from hosts on the network and to detect when a host that formerly acted only as a client (i.e., establishing outbound connections to servers) suddenly starts acting like a server and receiving inbound connections. Similarly, you can check if a Web server that has only received incoming connections to HTTP and HTTPS service ports suddenly behaves like an IRC server or a DNS server. Some of these techniques step across the boundaries of signature detection into the realm of anomaly detection, discussed later in this section. Stepping stones may also be detected using these techniques (by correlating inbound and outbound flows of roughly equal amounts). Note that some attacker toolkits do things like embed commands in other protocols (e.g., using ICMP to tunnel commands and replies), or may use TCP as a datagram protocol, fooling some defense tools into thinking that the fact that there was never an established TCP connection implies that no communication is occurring.
Finally, it is possible to detect agents by examining each machine, looking for specific file names, contents, and locations. All popular and widely used DDoS tools have been carefully dissected and the detailed description of the tool-specific ports, control traffic features, and file signatures can be found at the CERT Coordination Center Web page [CERe] or at Dave Dittrich’s DDoS Web page [Ditd]. Of course, one cannot look for file details on machines one does not own and control. Also, attackers may try to avoid detection by installing a rootkit at the subverted machine to hide the presence of malicious files and open ports.
Intrusion Detection Systems (IDSs) can also be used to detect compromises of potential agent machines. They examine the incoming traffic looking for known compromise patterns and drop the suspicious packets. In addition to preventing subversion for DDoS misuse, they protect the network from general intruders and promote security [ACF+99]. One major drawback of simple IDS solutions is that they often have a high alert rate, especially false-positive alerts. Newer IDSs employ combinations of operating system detection and service detection, correlating them with attack signatures to weed out obvious false alarms, such as a Solaris/SPARC-based attack against a DNS server that is directed at an Intel/Windows XP desktop that never had a DNS server in the first place.
Anomaly Detection
Anomaly detection takes the opposite approach from signature detection. It acknowledges the fact that malicious behaviors evolve and that a defense system cannot predict and model all of them. Instead, anomaly detection strives to model legitimate traffic and raise an alert if observed traffic violates the model. The obvious advantage of this approach is that previously unknown attacks can be discovered if they differ sufficiently from the legitimate traffic. However, anomaly detection faces a huge challenge. Legitimate traffic is diverse—new applications arise every day and traffic patterns change. A model that specifies legitimate traffic too tightly will generate a lot of false positives whenever traffic fluctuates. On the other hand, a loose model will let a lot of attacks go undetected, thus increasing the possibility of false-negatives. Finding the right set of features and a modeling approach that strikes a balance between false positives and false negatives is a real challenge.
Flow monitoring with correlation, described in a previous section, is another form of anomaly detection, which also combines features of behavioral models.
Behavioral Models Behavioral models select a set of network parameters and learn the proper value ranges of these parameters by observing network traffic over a long interval. They then use this baseline model to evaluate current observations for anomalies. If some parameter in the observed traffic falls out of the baseline range by more than a set threshold, an attack alert is raised. The accuracy and sensitivity of a behavioral model depend on the choice of parameters and the threshold value. The usual approach is to monitor a vast number of parameters, tuning the sensitivity (and the false-positive rate) by changing threshold values. To capture the variability of traffic on a daily basis (for instance, traffic on weekends in the corporate network will have a different behavior than weekday traffic), some detection methods model the traffic with a time granularity of one day.
Behavioral models show definite promise for DDoS detection, but they face two major challenges:
1. Model update. As network and traffic patterns evolve over time, models need to be updated to reflect this change. A straightforward approach to model update is to use observations from the past intervals when no attack was detected. However, this creates an opportunity for the attacker to mistrain the system by a slow attack. For instance, suppose that the system uses a very simple legitimate traffic model, recording just the incoming traffic rate. By sending the attack traffic just below the threshold for a long time, the attacker can lead the system to believe that conditions have changed and increase the baseline value. Repeating this behavior, the attacker will ultimately overwhelm the system without raising the alert.
While these kinds of training attacks are rare in the wild, they are quite possible and easy to perpetrate. A simple fix is to sample the observations at random times and derive model updates from these samples. Another possible fix is to have a human review the updates before they are installed.
2. Attack characterization. Since the behavioral models generate a detection signal that simply means “something strange is going on,” another set of techniques is necessary for traffic separation. One possible and frequently used approach is to profile incoming packets looking for a set of features that single out the majority of packets. For instance, assume that our network is suddenly swamped by traffic, receiving 200 Mbps instead of the usual 30 Mbps. Through careful observation we have concluded that 180 Mbps of this traffic is UDP traffic, carrying DNS responses. Using UDP/DNS-response characterization to guide filtering, we will get rid of the flood, but likely lose some legitimate DNS responses in the process. This is the inherent problem of behavioral models, but it can be ameliorated to a great extent by a smart choice of the feature set for traffic separation. Another possible approach is to create a list of legitimate clients’ source addresses, either based on past behavior or through some offline mechanism. This approach will let some attack traffic through when the attacker spoofs an address from the list.
Standard-Based Models Standard-based models use standard specifications of protocol and application traffic to build legitimate models. For example, the TCP protocol specification describes a three-way handshake that has to be performed for TCP connection setup. An attack detection mechanism can use this specification to build a model that detects half-open TCP connections or singles out TCP data traffic that does not belong to an established connection. If protocol and application implementations follow the specification, standard-based models will generate no false positives. Not all protocol and application implementations do so, however, as was pointed out by Ptacek and Newsham [PN98].
The other drawback of the standard-based models is their granularity. Since they model protocol and application traffic, they have to work at a connection granularity. This potentially means a lot of observation gathering and storage, and may tax system performance when the attacker generates spoofed traffic (thus creating many connections). Standard-based models must therefore deploy sophisticated techniques for statistics gathering and periodic cleanup to maintain good performance.
While standard-based models protect only from those attacks that clearly violate the standard, they guarantee a low false-positive rate and need very little maintenance for model update, except when a new standard is specified. The models can effectively be used for traffic separation by communicating the list of misbehaving connections to the response system.
Misbehavior Modeling
Instead of trying to model normal behavior and match ongoing behavior to those models, one can model misbehavior and watch for its occurrence. The simple method of detecting DDoS attacks at the target is misbehavior modeling at its most basic: The machine is receiving a vast amount of traffic and is not capable of keeping up. Yep, that’s a DDoS attack. At one extreme, misbehavior modeling is the same as signature-based detection: Receiving a sufficiently large number of a particular type of packet on a particular port with a particular pattern of source addresses may be both a misbehavior model and a signature of the use of a particular attack toolkit. But misbehavior modeling can be defined in far more generic terms that would not be recognized as normal signatures. At the other extreme, misbehavior modeling is no different than anomaly modeling: If it is not normal, it is DDoS. But misbehavior modeling, by trying to capture the characteristics of only DDoS attacks, characterizes all other types of traffic, whether they have actually been observed in the past or not, as legitimate. True misbehavior modeling falls in the range between these extremes.
The challenge in misbehavior modeling is finding characteristics of traffic that are nearly sure signs that a DDoS attack is going on, beyond the service actually failing under high load. Perhaps a sufficiently large ramp-up in traffic over a very short period of time could signal a DDoS attack before the machine was actually overwhelmed, but perhaps it signals only a surge in interest in the site or a burst of traffic that was delayed somewhere else in the network and has suddenly been delivered in bulk. Perhaps a very large number of different addresses sending traffic in a very short period of time signals an attack, but perhaps it only means sudden widespread success of your Web site. It is unclear if it is possible to model DDoS behavior sufficiently well to capture it early without falsely capturing much legitimate behavior. (Such mischaracterization could be either harmless or disastrous, depending on what you do when a DDoS attack is signaled.)
5.6.3 Attack Response
The goal of attack response is to improve the situation for legitimate users and mitigate the DoS effect. There are three major ways in which this is done:
1. Traffic policing. The most straightforward and desirable response to a DoS attack is to drop offending traffic. This makes the attack transparent both to the victim and to its legitimate clients, as if it were not happening. Since attack detection and characterization are sometimes inaccurate, the main challenge of traffic policing is deciding what to drop and how much to drop.
2. Attack traceback. Attack traceback has two primary purposes: to identify agents that are performing the DDoS attack, and to try to get even further back and identify the human attacker who is controlling the DDoS network. The first goal might be achievable, but is problematic when tens of thousands of agents are attacking. The latter is nearly impossible today, due to the use of stepping stones. These factors represent a major challenge to traceback techniques. Compounding the problem is the inability of law enforcement to deal with the tens, or hundreds of thousands, of compromised hosts scattered across the Internet, which also means scattered across the globe. Effective traceback solutions probably need to include components that automatically police traffic from offending machines, once they are found. See Chapter 7 for detailed discussion of traceback techniques.
3. Service differentiation. Many protection techniques can be turned on dynamically, once the attack is detected, to provide differentiated service. Clients are presented with a task to prove their legitimacy, and those that do receive better service. This approach offers a good economic model. The server is generally willing to serve all the requests. At times of overload, the server preserves its resources and selectively serves only the VIP clients (those who are willing to prove their legitimacy) and provides best-effort service to the rest. A challenge to this approach is to handle attacks that generate a large volume of bogus legitimacy proofs. It may be necessary to distribute the legitimacy verification service to avoid the overload.
As each response has its own set of limitations, it is difficult to compare them to each other. Service differentiation creates an opportunity for the legitimate users to actively participate in DDoS defense and prove their legitimacy. This is the most fair to the customers, as they control the level of service they receive, not relying on (possibly faulty) attack characterization at the victim. On the other hand, service differentiation requires changes in the client software, which may be impractical for highly popular public services. Traceback requires a lot of deployment points in the core, but places the bulk of complexity at the victim and enables response long after the attack has ended. Traffic policing is by far the most practical response, as its minimum number of deployment points is one—in the vicinity of the victim. However, traffic policing relies on sometimes inaccurate attack characterization and is bound to inflict collateral damage.
Finally, there is no need to select a single response approach. Traceback and traffic policing can be combined to drop offending traffic close to its sources. Traffic policing can work with service differentiation, offering different policies for different traffic classes. Traceback can bring service differentiation points close to the sources, distributing and reducing the server load.
Traffic Policing
Two main approaches in traffic policing are filtering and rate limiting. Filtering drops all the packets indicated as suspicious by the attack characterization, while rate limiting enforces a rate limit on all suspicious packets. The choice between these two techniques depends on the accuracy of attack characterization. If the accuracy is high, dropping the offending traffic is justified and will inflict no collateral damage. When the accuracy is low, rate limiting is definitely a better choice, as some legitimate packets that otherwise would have been dropped are allowed to proceed to the victim. This will reduce collateral damage and facilitate prompt recovery of legitimate traffic in the case of false positives. Signature detection techniques commonly invoke a filtering response, as the offending traffic can be precisely described, while anomaly detection is commonly coupled with rate limiting as a less restrictive response.
The main challenge of traffic policing is to minimize legitimate traffic drops—one form of collateral damage. There are two sources of inaccuracy that lead to this kind of collateral damage: incorrect attack characterization and false positives. If the attack characterization cannot precisely separate the legitimate from the attack traffic, some legitimate packets will be dropped every time the response is invoked. The greater the inaccuracy, the greater the collateral damage. False positives needlessly trigger the response. The amount of the collateral damage again depends on the characterization accuracy, but false alarms may mislead the characterization process and thus increase legitimate drops.
How bad is it to drop a few legitimate packets? At first glance, we might conclude that a small rate of legitimate drops is not problematic, as the overwhelming majority of Internet communication is conducted using TCP. Since TCP is a reliable transmission protocol, dropped packets will be detected and retransmitted shortly after they were lost, and put in order at the receiving host. The packet loss and the remedy process should be transparent to the application and the end user. This works very well when there are only a few drops, once in a while. The mechanisms ensuring reliable delivery in the TCP protocol successfully mask isolated packet losses. However, TCP performance drops drastically in the case of sustained packet loss, even if the loss rate is small. The reason for this lies in the TCP congestion control mechanism, which detects packet loss as an early sign of congestion. TCP’s congestion control module responds by drastically reducing the sending rate in the effort to alleviate the pressure at the bottleneck link. The rate is reduced exponentially with each loss and increased linearly in the absence of losses. Several closely spaced packet drops can thus quickly reduce the connection rate to one packet per sending interval. After this point, each loss of the retransmitted packet exponentially increases the sending interval. Overall, sustained packet loss makes the connection send less and with a reduced frequency.
While very effective in alleviating congestion, this response severely decreases the competitiveness of legitimate TCP traffic in case of a DoS attack. In the fight for a shared resource, more aggressive traffic has a better chance to win. The attack traffic rate is usually unrelenting, regardless of the drops, while the legitimate traffic quickly decreases to a trickle, thus forfeiting its fighting chance to get through. Rate limiting for DDoS response introduces another source of drops in addition to congestion, trying to tip the scale in favor of the legitimate traffic. If the rate limiting is not sufficiently selective, packet drops due to collateral damage will have the same ill effect on the legitimate connection as congestion drops did. Even if the congestion is completely resolved (the response has successfully removed the attack traffic), those legitimate connections that had severe drops will take a long time to recover and may be aborted by the application. It is therefore imperative to eliminate as many legitimate drops as possible, not only by making sure that the response is promptly engaged, but also by increasing its selectiveness.
The traffic-policing component can be placed anywhere on the attack path. Placing the response close to the victim ensures the policing of all attack streams with a single response node, but may place substantial burden on the DDoS defense system when the victim is subjected to a high-volume flood. Victim-end deployment also maximizes the chances for collateral damage, if rate limiting is the response of choice, as imperfect drop decisions affect all traffic reaching the victim. Better performance can be achieved by identifying those network paths that likely carry the attack traffic and pushing the rate limit along those paths as close to the sources as possible. This localizes the effect of erroneous drops only to those legitimate clients who share the path to the victim with an attacker. Unfortunately, this approach causes the number of the response points needed to completely control the attack to grow, as a response node must be installed on each identified path.
One technique currently used to counter large attacks that last for a long time is to start by trying to filter locally. If that is not sufficient, the victim then contacts his upstream network provider to request the installation of filters there. In principle, this manual pushing of filters back further into the network could continue indefinitely, but since each step requires human contact and intervention, it rarely is done too far into the network. One example of successful use of this technique occurred during the DDoS attack on the DNS root servers. One root server administrator contacted his backbone provider to install filters to drop certain types of packets in the attack stream, thus reducing the attack traffic on the link leading to his root server. The manual approach has some strong limitations, however. One must carefully characterize the packets to avoid collateral damage, and not all network providers will respond quickly to all customers’ requests to install filters. This issue is discussed in more detail in Chapter 6.
Attack Traceback
Attack traceback has two primary purposes: to identify (and possibly shut down) agents that are implementing the actual DDoS attack, and to try to get even further back and identify the human attacker who is controlling the DDoS network. Traceback would thus be extremely helpful not only in DDoS defense, but also in cases of intrusions and worm infections when the attack is inconspicuous, contained in a few packets, and may be detected long after the attack ends. Traceback techniques enable the victim to reassemble the path of the attack, with help of the core routers. In packet-marking techniques [SPS+01, DFS01, SWKA00], routers tag packets with extra information stating, “The packet has passed through this router.” In ICMP traceback [BLT01], additional control information is sent randomly to the victim, indicating that packets have passed through a given router. The victim uses all such information it receives to deduce the paths taken by attack packets. In hash-based traceback [SPS+01], routers remember each packet they have seen for a short time and can retrieve this knowledge in response to a victim’s queries. Obviously, all these approaches place a burden on the intermediate routers, either to generate additional traffic, or to rewrite a portion of the traffic they forward, or to dedicate significant storage to keep records of packets they have seen. More overhead is incurred by the victim when it tries to reassemble the attack path. This process may be very computationally intensive and lead to additional control traffic between the victim and the core routers. As the attack becomes more distributed, the cost of the traceback increases.
Another drawback is tracing precision. It is impossible to identify the actual subverted machine. Rather, several networks in the vicinity of the attacking machine are identified. In a sparse deployment of traceback support at core routers, the number of suspect networks is likely to be very high. While this information is still beneficial if, for instance, we want to push a traffic-policing response closer to the sources, it offers little assistance to law enforcement authorities or to filtering rule generation.
An open issue is what action to take when tracing is completed. An automatic response, such as filtering or rate limiting, is the best choice, as the number of suspect sites is likely to be too large for human intervention. In this case, suspected networks that are actually innocent (i.e., networks that do not host agents but share a path with a network that does) will have their packets dropped. This is hardly fair. Another point worth mentioning is that even a perfect tracing approach up to the sending machine is useless in a reflector DoS attack. In this case, the machine sending problematic traffic is simply a public server that responds to seemingly legitimate queries. Since such servers will not themselves spoof their IP address, identification of them is trivial and no tracing is needed.
As noted in Chapter 4, even a workable traceback scheme has two other significant problems. First, in the face of traceback of DDoS flood traffic, it gets you only to the agents, not all the way back to the actual attacker (through all her handlers, IRC proxies, or login stepping stones). This may offer some opportunity to relieve the immediate attack but does not necessarily help catch the actual attacker or prevent her from making future attacks on you. Second, if a successful attack can be waged using only a few hundred or even a few thousand hosts, yet the attacker can gain access to 400,000 hosts, she can simply cycle through attack networks and force the victim to repeat the traceback and flood mitigation steps. Because these actions occur on human timescales today, the attacker would consume not only computer resources of the victim, but also human resources. Even at future automated speeds, the difficulties and costs of dealing with this sort of cycling attack could be serious. Having some kind of understanding of how a particular attack is being waged would help the victim to know when such a tactic is in use and to adjust its response accordingly.
Service Differentiation
As mentioned above, some of the protection approaches can be engaged dynamically, when an attack is detected, to provide differentiated service to those clients who can prove their legitimacy. A dynamic deployment strategy has an advantage over static deployment, as operational costs are paid only when needed. There is an additional advantage in cases when the protection approach requires software changes at the client side. Were such approaches engaged statically, the server would lose all of its legacy clients. With dynamic engagement, legacy clients are impacted only when the attack is detected, and even then the effect is degradation of their service, since the protection mechanism favors those clients that deploy software changes. As the attack subsides, old service levels are restored.
Source validation approaches can be used to differentiate between preferred and ordinary clients, and to offer better service to the preferred ones during the attack. Proof-of-work approaches can be engaged to challenge users to prove their legitimacy, and resources can be dedicated exclusively to users whose legitimacy has been proven during the attack.