
Chapter 7. Web Browsers
Chapters 5 and 6 covered what can be learned about a web site and the server that hosts it. This chapter takes a look at things from the other side: what the server can learn about us.
What Your Browser Reveals
A web server needs to know certain things about a browser to return the requested page successfully. First and foremost is the IP address of the machine that is sending the request. Without that, the server doesn’t know where to send the data. Next are the capabilities of the browser. Not all browsers can handle all types of content, and all common browsers will tell the server what they can and can’t accept.
A basic HTTP transaction, fetching a simple web page, starts out with the browser sending a request to the server. That contains the name of the document to be returned, along with the version of the http protocol and the method that should be used to service the request. Also included are a number of headers that convey ancillary information that can help the server tailor its response to the request. Table 7-1 shows a set of these headers that accompanied an example request.
Header | Value |
| 208.12.16.2 |
| |
| GET |
| text/xml application/xml application/xhtml+xml text/html;q=0.9 text/plain;q=0.8 image/png */*;q=0.5 |
| ISO-8859-1 utf-8;q=0.7 *;q=0.7 |
| gzip deflate |
| en-us en;q=0.5 |
| keep-alive |
| www.craic.com |
| 300 |
| Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.7.5) Gecko/2004 1107 Firefox/1.0 |
These are only some of the possible headers. Additional background can be found in this document: http://www.w3.org/Protocols/HTTP/HTRQ_Headers.html.
Implicit in a transaction, and so not needing its own header, is
the IP address of the requesting browser. The type of browser that is
making the request is specified in the User-Agent string, declaring it to be Mozilla
Firefox running under Linux, for example.
The browser also has to inform the server what types of content it can accept. Most browsers will in fact accept anything the server chooses to send. But there is a difference between accepting the content and knowing what to do with it. If the browser can’t display video, for example, you will typically get a pop up asking if you want to save the page to a file. But most browsers use this header to let the server know what type of content they prefer, given the choice. This lets the server choose one form of content over another. These days, the major browsers can handle all the common formats, so its use is less important. The exception to that, however, comes from mobile phone browsers. These are highly constrained due to small screen size and limited bandwidth, so a server that delivers content to these devices will make good use of the Accept header and return, perhaps, a WML page rather than standard HTML or an error message if a certain type of phone requests a large MPEG movie.
Alongside the Accept header are
optional headers that tell the server what language the content should
be sent in along with the related content encoding, whether or not
alternatives are available, and what compression schemes can be handled
if the server can send compressed data to conserve bandwidth. These
headers are often ignored but can be very useful if your site has
versions in multiple languages, for example. In some of the headers that
list alternatives, you will often see a semicolon followed by q= and a value between 0 and 1. For
example:
ACCEPT: text/html;q=0.9,text/plain;q=0.8,*/*;q=0.5
These are called quality, or sometimes degradation, values, and they are used to help the server decide which alternative form of content should be returned. You can think of them as quantifying the client browser’s preference, given a choice. So in this example the browser would prefer to receive HTML text rather than plain text, but in a pinch it will accept anything. The gory details can be found in this document: http://www.w3.org/Protocols/HTTP/Negotiation.html.
The Host header is an extremely
important piece of information. This is the hostname that the browser is
trying to connect to. You might think that this is inherent in the URL
used to initiate the transaction, but servers often host multiple web
sites. This header lets the server direct the request to the correct
virtual host.
The headers also include a Connection line and perhaps a Keep-Alive line. These tell the server to keep
the connection between it and the browser open for a period of time once
the requested page has been sent. Users often look at several pages on
any given site and keeping the connection open allows subsequent
requests to be serviced more efficiently.
If the request was initiated by clicking on a link on a web page,
as opposed to typing a URL into the browser directly, then a Referer header will be included that tells the
server the URL of the page that you came from. This is invaluable to
commerce sites that want to track where their customers found out about
their services.
Warning
Throughout this chapter, you will see the term Referer, used as a http header to identify
the URL of the page that contained a link to the current page. The
correct spelling is Referrer, but somewhere along
the line an R was dropped. This error managed to sneak into the
official http specification and now lives forever in every browser and
web server on the Net.
To see what your browser is telling the world about your system you need to visit a site that reflects that information back to you. There are many of these out there on the Net. Two that are available at the time of writing are http://ats.nist.gov/cgi-bin/cgi.tcl/echo.cgi and http://www.ugcs.caltech.edu/~presto/echo.cgi. Alternatively you can set up the Perl script shown in Example 7-1 on your own server.
#!/usr/bin/perl -w
# Echo the environment variables that are sent from the browser
use CGI;
my $cgi = new CGI;
print "Content-type: text/html
";
print "<html>
<head>
";
print "<title>Browser Information</title>
";
print "</head>
<body>
";
print "Information sent by your browser:<br>
";
printf "Remote Host: %s<br>
", $cgi->remote_host();
printf "Refering Page: %s<br>
", $cgi->referer();
printf "Request Method: %s<br>
", $cgi->request_method();
foreach my $type (sort { $a cmp $b } $cgi->http()) {
printf "%s: %s<br>
", $type, $cgi->http($type);
}
print "</body>
</html>
";Go to that URL from your browser and you should see output similar to this:
Information available to this server from your browser:
Remote Host: 208.12.16.2
Refering Page:
Request Method: GET
HTTP_ACCEPT: text/xml,application/xml,application/xhtml+xml,
text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
HTTP_ACCEPT_CHARSET: ISO-8859-1,utf-8;q=0.7,*;q=0.7
HTTP_ACCEPT_ENCODING: gzip,deflate
HTTP_ACCEPT_LANGUAGE: en-us,en;q=0.5
HTTP_CACHE_CONTROL: max-age=0
HTTP_CONNECTION: keep-alive
HTTP_HOST: www.craic.com
HTTP_KEEP_ALIVE: 300
HTTP_USER_AGENT: Mozilla/5.0 (X11;U;Linux i686;en-US;rv:1.7.5)
Gecko/20041107 Firefox/1.0Apache Web Server Logging
Let’s now look at how Apache can be configured to log information about the requests it services and how you, as the operator of a server, can extract specific information from what can become huge log files.
Logging in Apache can be set up in several different ways. For most purposes the default configuration works fine and serves as a good compromise between logging useful information while keeping the log files from filling all available disk space. The configuration options are detailed here: http://httpd.apache.org/docs/logs.html.
You will find the relevant directives buried deep in the configuration file httpd.conf. Look for a block like this (I’ve edited out some of the comments for readability):
# The following directives define some format nicknames for
# use with a CustomLog directive (see below).
LogFormat "%h %l %u %t "%r" %>s %b "%{Referer}i"
"%{User-Agent}i"" combined
LogFormat "%h %l %u %t "%r" %>s %b" common
LogFormat "%{Referer}i -> %U" referer
LogFormat "%{User-agent}i" agent
#
# The location and format of the access logfile.
[...]
# CustomLog /var/log/httpd/access_log common
CustomLog logs/access_log combined
#
# If you would like to have agent and referer logfiles,
# uncomment the following directives.
#CustomLog logs/referer_log referer
#CustomLog logs/agent_log agent
#
# If you prefer a single logfile with access, agent, and referer
# information (Combined Logfile Format) use the following directive.
#
#CustomLog logs/access_log combinedThe basic idea is simple. You define what information should go
into the log for each visit by creating a LogFormat record in the configuration file.
There are several of these predefined, as in the above example. Each
format is given a nickname, such as combined or common.
The syntax used on a LogFormat
record looks a bit like a C printf
format string. The URL http://httpd.apache.org/docs/mod/mod_log_config.html
describes the complete syntax, but the key elements are shown in Table 7-2.
Directive | Meaning |
%h | |
%l | |
%u | |
%d | |
%r | |
%>s | |
%b | |
%{NAME}i | The value of the NAME header line;
e.g., |
You then specify which format will be used and the name of the log
file in a CustomLog record. Several
common setups are predefined in httpd.conf, and you can simply uncomment the
one that suits your taste. Remember that when messing with Apache
configuration files you should always make a backup copy before you
start and add comment lines in front of any directives that you
modify.
The default level of logging is defined in the common LogFormat. So in a typical installation
these lines are all that you need:
LogFormat "%h %l %u %t "%r" %>s %b" common
[...]
CustomLog logs/access_log commonThe combined LogFormat extends
that to include the Referer and
User-Agent:
LogFormat "%h %l %u %t "%r" %>s %b "%{Referer}i"
"%{User-Agent}i"" combined
[...]
CustomLog logs/access_log combinedYou can choose between logs containing just IP addresses or the
full hostname by setting HostnameLookups to On or Off:
HostnameLookups On
Be aware that turning this on will trigger a DNS lookup for every page requested, which can add an unnecessary burden to busy web servers.
By default, all page requests will be logged,
which is probably not what you want. It results in a log record for
every image on every page. You
end up with massive log files that are much harder to trawl through than
they need to be. Fortunately we solve this by identifying pages that can
be ignored and then excluding these from the CustomLog directive. We define a specific
environment variable if the requested page matches any of a set of
patterns. The variable is called donotlog in this example but the name is
arbitrary. It gets set if the request is for a regular image, a
stylesheet, or one of those mini-icons that appear in browser address
windows. We apply a qualifier to the end of the CustomLog line, which means log this record if
donotlog is not
defined in the environment variables. Note the syntax of this (=!) is reversed from “not equal” in languages
such as Perl. That makes it easy to mistype and the error will prevent
Apache from restarting:
SetEnvIf Request_URI .gif donotlog
SetEnvIf Request_URI .jpg donotlog
SetEnvIf Request_URI .png donotlog
SetEnvIf Request_URI .css donotlog
SetEnvIf Request_URI favicon.ico donotlog
CustomLog logs/access_log combined env=!donotlogThis short block will lower the size of your log files dramatically with little or no loss of useful information.
Here are some examples of real log records. A simple page fetch as
recorded using the common LogFormat,
with HostnameLookups turned off,
looks like this:
66.134.177.170 - - [20/Feb/2004:15:34:13 -0800]
"GET /index.html HTTP/1.1" 200 13952With HostnameLookups turned
on:
h-66-134-177-170.sttnwaho.covad.net - -
[20/Feb/2004:15:37:50 -0800]
"GET /index.html HTTP/1.1" 200 13952And finally using the combined
format:
h-66-134-177-170.sttnwaho.covad.net - -
[20/Feb/2004:15:46:03 -0800]
"GET /index.html HTTP/1.1" 200 13952
"http://www.craic.com/index.html"
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.6)
Gecko/20040207 Firefox/0.8"Consider the last example. http://h-66-134-177-170.sttnwaho.covad.net is the
hostname of the machine making the request. This would just be the IP
address if hostname lookups were turned off. The two dashes that follow
are placeholders for logname and username information that is not
available in this request, as is the case with most that you will come
across. Next is the timestamp, followed by the first line of the actual
request. "GET /index.html HTTP/1.1"
reads as a request for the document index.html, to be delivered using the GET
method as it is interpreted in Version 1.1 of the http protocol. The two
numbers that follow signify a successful transaction, with status code
200, in which 13,952 bytes were sent to the browser. This request was
initiated by someone clicking on a link on a web page, and the URL of
that referring page is given next in the record. If the user had typed
in the URL directly into a browser then this would be recorded simply as
a dash.
Finally there is the User-Agent
header. This is often the most interesting item in the whole record. It
tells us in considerable detail what browser was used to make the
request, often including the type of operating system used on that
computer. This example tells us the browser was Firefox Version 0.8
running under the Linux operating system on a PC:
"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.6)
Gecko/20040207 Firefox/0.8"This one identifies the browser as Safari running under Mac OS X on a PowerPC Macintosh:
"Mozilla/5.0 (Macintosh; U; PPC Mac OS X; en) AppleWebKit/125.5.6
(KHTML, like Gecko) Safari/125.12"Notice that the version numbers are very specific. If I were so inclined, I might use those to look up security vulnerabilities on that system that might help me break in to it over the network. You might not want to pass all this information on to every site that you visit.
Even more specific are User-Agent strings like these:
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;
ESB{837E7A43-A894-47CD-8B49-6C273A84BE29}; SV1)"
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1;
{A0D0A528-5BFC-4FB3-B56C-EC45BCECC088}; SV1; .NET CLR)"These are two examples of Microsoft Internet Explorer Version 6.0
running on Windows 2000 systems. More importantly, they appear to have a
unique identifier string embedded in the User-Agent—for example, {A0D0A528-5BFC-4FB3-B56C-EC45BCECC088}. Every
example of this that I have seen is different so it cannot be a product
number and not all Windows 2000 browsers have a string like this. It
appears to be a serial number that either
identifies that copy of Windows or that copy of Explorer. I have to
admit that I don’t fully understand this one, but if it is a unique ID
then it could be used to trace a visit to a specific web site all the
way back to a specific computer. That may very well be its purpose.
Companies concerned about their staff leaking confidential information
or visiting inappropriate web sites might want to identify the precise
source of any web page request.
Other User-Agent strings tell
us that we are being visited by web robots, also known as crawlers or
spiders. Here are the strings for the robots from MSN, Yahoo!, and
Google:
msnbot/1.0 (+http://search.msn.com/msnbot.htm)
Mozilla/5.0 (compatible; Yahoo! Slurp;
http://help.yahoo.com/help/us/ysearch/slurp)
Googlebot
/2.1 (+http://www.google.com/bot.html)When you combine the information present in a log record with some
simple dig and whois searches, you can learn a lot about the
person making the request. Here is someone based in India, on a Windows
98 PC, looking at my resume, which they found by running a Google search
on the name of my Ph.D. supervisor:
221.134.26.74 - - [02/Feb/2005:07:24:25 -0800]
"GET /pdf_docs/Robert_Jones_CV.pdf HTTP/1.1" 206 7801
"http://www.google.com/search?hl=en&ie=ISO-8859-1&q=R.L.+Robson"
"Mozilla/4.0 (compatible; MSIE 5.0; Windows 98; DigExt)"The next example involves a browser on a mobile phone, specifically a Nokia 3650. Not only that, I know that they use ATT Wireless as their carrier, because the IP address maps to the host http://pnupagt11.attwireless.net:
209.183.48.55 - - [20/Feb/2004:15:47:46 -0800] "GET / HTTP/1.1"
200 904 "-" "Nokia3650/1.0 SymbianOS/6.1 Series60/1.2
Profile/MIDP-1.0 Configuration/CLDC-1.0 UP.Link/5.1.2.9"You can while away many a happy hour looking through server logs like this. It’s both fascinating to see what you can uncover and chilling to realize what other people can uncover about you.
Server Log Analysis
Individual log records can be revealing but often even greater insights come from looking through access logs over a period of time and finding patterns in the data. There is a whole industry devoted to log analysis of large sites involved in news or e-commerce, trying to assess what visitors are most interested in, where they are coming from, how the server performs under load, and so on. I’m going to take a much simpler approach and use the tools that I have at hand to uncover some very interesting needles hidden in my haystack. Hopefully these examples will inspire you to take a closer look at your own server logs.
Googlebot Visits
Given that Google is such a powerful player in the field of
Internet search, you might like to know how often they update their
index of your site. To see how often their web robot, or spider, pays
you a visit, simply search through the access log looking for a
User-Agent called GoogleBot. Do this using the standard Unix
command grep:
% grep -i googlebot access_log | grep 'GET / ' | moreThe first grep gets all
GoogleBot page visits and the second limits the output to the first
page of each site visit. Here is a sample of the output from my
site:
66.249.71.9 - - [01/Feb/2005:22:33:27 -0800] "GET / HTTP/1.0"
304 - "-" "Googlebot/2.1 (+http://www.google.com/bot.html)"
66.249.71.14 - - [02/Feb/2005:21:11:30 -0800] "GET / HTTP/1.0"
304 - "-" "Googlebot/2.1 (+http://www.google.com/bot.html)"
66.249.64.54 - - [03/Feb/2005:22:39:17 -0800] "GET / HTTP/1.0"
304 - "-" "Googlebot/2.1 (+http://www.google.com/bot.html)"
66.249.71.17 - - [04/Feb/2005:20:04:59 -0800] "GET / HTTP/1.0"
304 - "-" "Googlebot/2.1 (+http://www.google.com/bot.html)"We can see that Googlebot comes around every day. The IP address of the machine doing the indexing varies, as does the time, but every evening one of their swarm visits my server and looks for any changes. This is quite reassuring because it means any new pages that I post on the site should be picked up within 24 hours. The next step would be to post a new page and see when that actually shows up in a search for unique text on that page.
Bad Robots
Googlebot is a polite and well-behaved robot that indexes only
pages on my site that I want it to. The first thing it does when it
visits is check the file /robots .txt to see where it can and cannot crawl.
Furthermore it checks each page for the presence of a robots meta tag to see if that particular page is
not to be indexed. All robots are supposed to uphold this Robot Exclusion Standard , but not all do. Apache logs can help identify the
rogues.
Create a simple page in your web tree that you will use as bait. I call my file robots_test.html:
<html><head>
<title>You can't get here from there</title>
<meta name="ROBOTS" content="NOINDEX, NOFOLLOW">
</head><body>
<p>You can't get here from there...</p>
<p>This is a test page that helps identify web spiders
that do not adhere to the robots exclusion protocol. </p>
</body></html>Add an entry for this file in the robots.txt file that instructs robots that it should not be copied:
Disallow: /robots_test.html
Place a link to the bait page on your home page, but do not
enter any text between the <a> and </a> tags. This will make it invisible
to the casual viewer but the robots will find it.
<a href="robots_test.html"></a>
Let it sit there for a week or so and then look for the filename in your logs. You might not have to wait long.
% grep -i robots_test access_log
220.181.26.70 - - [08/Feb/2005:10:16:31 -0800]
"GET /robots_test.html HTTP/1.1" 200 447 "-" "sohu-search"This tells us that a robot called sohu-search found it on the 8th of February.
The file was placed there on the 7th! Further investigation tells me
that this is a search engine for http://sohu.com, a portal site in China.
Google Queries
An interesting search is to look for visits that originated as Google searches. Your visitor entered a specific query into Google and was led to your site. What exactly were they looking for?
This sounds like an impossible task because the search took place on Google’s site, not your’s. But when they click on a link in a Google results page, its URL is passed on as the referring page, which contains the search terms. Assuming you have been recording visits using the combined log format, you can use this command to pull out records that are the result of a link from Google:
% grep -i google access_log | grep '[&?]q='
[...]
194.47.254.215 - - [07/Feb/2005:01:54:17 -0800]
"GET /pdf_docs/oreillynet_bioinfo_compgen.pdf HTTP/1.1" 200 707249
"http://www.google.com/search?q=comparative+analysis+genomes+
%22complete+DNA+sequence%22+filetype:pdf&hl=en&lr=&as_qdr=all
&start=10&sa=N"
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2) Opera 7.54 [en]"
[...]
81.210.54.242 - - [07/Feb/2005:02:01:05 -0800]
"GET /mobile/ora/apache_config.html HTTP/1.1" 200 1324
"http://www.google.pl/search?hl=pl&q=rewrite+apache+wap&lr="
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)"
[...]The first record is a request for a PDF file of an O’Reilly
Network article in response to the query comparative analysis genomes complete DNA
sequence, and the second is a request for a page on web
programming for mobile phone browsers in response to the query
rewrite apache wap. Manually
dissecting records is fine the first few times you try it but it is
too tedious for general use. Here are a couple of Perl scripts to make
this process easier.
The first one, shown in Example 7-2, will extract specific fields from a combined format log file. You can specify whether you want the hosts that requested the pages, the referring pages, or the user agent used to make the request. The script is set up so that it can open a file or it can be used in a pipeline of several commands, which is helpful when dealing with large log files.
#!/usr/bin/perl -w
die "Usage: $0 <field> <log file>
" unless @ARGV > 0;
$ARGV[1] = '-' if(@ARGV == 1);
open INPUT, "< $ARGV[1]" or
die "$0: Unable to open log file $ARGV[1]
";
while(<INPUT>) {
if(/^(S+).*(".*?")s+(".*?")s*$/) {
my $host = $1;
my $referer = $2;
my $user_agent = $3;
if($ARGV[0] =~ /host/i) {
print "$host
";
} elsif(($ARGV[0] =~ /refer/i) {
print "$referer
";
} elsif(($ARGV[0] =~ /user/i)
print "$user_agent
";
}
}
}
close INPUT;You can use it to extract the referring pages from Google using this pipe:
% grep -i google access_log | ./parse_apache_log referrer
[...]
http://www.google.com/search?q=comparative+analysis+genomes+
%22complete+DNA+sequence%22+filetype:pdf&hl=en&lr=&as_qdr=all
&start=10&sa=N
http://www.google.pl/search?hl=pl&q=rewrite+apache+wap&lr=
[...]That’s an improvement on the raw log file format, but it’s still pretty ugly. The script shown in Example 7-3 cleans things up further.
#!/usr/bin/perl -w
die "Usage: $0 <log file>
" unless @ARGV < 2;
$ARGV[0] = '-' if @ARGV == 0;
open INPUT, "< $ARGV[0]" or
die "$0: Unable to open log file $ARGV[0]
";
while(<INPUT>) {
if(/[?&]q=([^&]+)/) {
my $query = $1;
$query =~ s/+/ /g;
$query =~ s/\%([0-9a-fA-F][0-9a-fA-F])/chr hex $1/ge;
print "$query
";
}
}
close INPUT;Adding it to the previous pipeline produces output like this:
% grep -i google access_log | ./parse_apache_log referrer | ./parse_gooogle_queries.pl
[..]
comparative analysis genomes "complete DNA sequence" filetype:pdf
rewrite apache wap
[...]The output of this on a large log file can make for very interesting reading. The vast majority of queries to my site are interested in a single article I wrote on mobile phones but only a few are specifically interested in my company, which tells me I need to work on my marketing skills!
Protecting Your Privacy
Now you’ve seen how much information a web server can record about its visitors you might be feeling a little uneasy. Let’s turn the tables and discuss how you can control the information that your browser gives to the servers to which it connects.
There are many reasons why you might want not want a server to know anything about you. Seeing as you are reading this book, you might be investigating a dodgy web site and be concerned that the bad guys could identify you. You might be visiting sites that your government views as subversive and be worried about surveillance. Or you might be doing something illegal and not want to get caught.
The technology of the Internet, through its speed, ubiquity, and complete disdain for traditional national boundaries, has raised many complex issues involving civil liberties, censorship, law enforcement, and property laws. The technologies to protect or disguise your identity that are described here are at the heart of several of these debates. I encourage you to think about their ethical and political implications. The Electronic Frontier Foundation (EFF) (http://www.eff.org) is a vigorous champion of freedom on the Internet, and their site is an excellent resource.
If you want to disguise or hide your identity, then you have several choices, ranging from simple browser settings to sophisticated encryption and networking software.
Disguising Your Browser
The easiest approach is to modify the User-Agent string that your browser sends to the server. With some
browsers , this is trivial. Konqueror, for example, can be set
up to impersonate specific browsers on specific sites, or to send no
User-Agent string at all. If you
write you own Perl script to fetch web pages, using the LWP module, you can have it masquerade as
anything you want. You should give it a unique name so that it can be
identified, allowing a server to allow it access or not.
This sort of disguise can conceal the browser and operating system that you use, but that’s about it. In fact, it may work against you because some sites deliver browser-specific content. If you pretend to be using Internet Explorer when you are really using Safari, you may receive content that cannot be properly displayed.
Proxies
The next step is to use a Proxy that sits between your browser and the server you want to visit. A proxy is an intermediate server that takes your request, forwards it to the target server, accepts the content from that server, and passes that back to you. It has the potential to modify both the request you send and the content it receives. They come in many forms. Some are used to cache frequently requested pages rather than fetch them from the original site every time. Some companies funnel requests from internal users through a proxy to block visits to objectionable web sites. There are two types that are particularly relevant to our interests. The first is a local proxy that provides some of the privacy features that are lacking from most browsers. The second is an external proxy through which we send our requests and that can mask our IP address.
Privoxy
Privoxy is an example of a
local proxy that provides a wide range of filtering capabilities. It
can process the outgoing requests sent from your
browser to modify User-Agent and
other headers. It can also modify incoming
content to block cookies, pop ups, and ads.
The software is open source and is available from http://www.privoxy.org. You install it on your client
computer, rather than on a server, and then configure your browser to
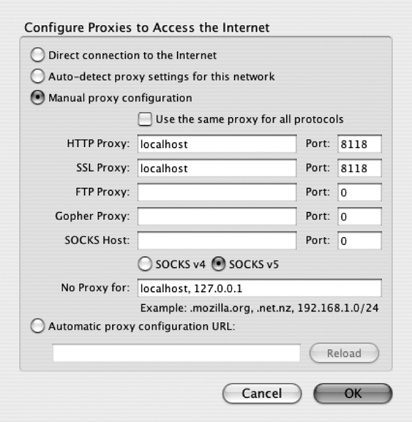
send all http and SSL requests to port 8118 on localhost. Figure 7-1 shows the
proxy configuration dialog box for Firefox running on Mac OS X. Other
browsers have a similar interface.
The software then applies a series of filters to the request
according to the actions that you have defined. You set these up by
going to the URL http://config.privoxy.org,
which is actually served by privoxy
running on your machine. Configuring the software is quite daunting
due to the large number of options. I’ll limit my description to just
a few of the more important ones.
To change the configuration, go to http://config.privoxy.org/show-status and click on the Edit button next to the default.action filename in the first panel of that page. This pulls up a confusing page that lists a great many actions, most of which apply to incoming content and can be safely ignored. Click on the first Edit button in the section entitled “Editing Actions File default.action”. This brings up a page of actions, each with radio buttons that can enable or disable that filter. You are strongly advised not to mess with any filters that you do not understand.
Perhaps the most useful of these is the hide-referrer action, which is enabled by
default. Normally your browser would forward the URL of the page that
contained the link to the current page. With this filter you can
remove this header completely, you can set it to a fixed arbitrary
URL, or you can set it to the root page for the target site. The
latter is the preferred option, as some sites will only serve images
if the request was referred from a page on their site. Earlier in this
chapter, I mentioned how query strings from Google searches can be
included in the referrer header and can then be logged by the target
site. Using this privoxy filter allows you to hide this information.
The hide-user-agent action can be
used to disguise the identity of the browser. Click on the enable
button next to this item. Below it will appear an entry box that
contains the string: Privoxy/3.0
(Anonymous). You don’t want to use this because it tells the
server that you are disguising your identity. Instead take the default
User-Agent string from your browser
and strip out the text that identifies the version of either the
browser or the operating system. For example, if the original string
was this:
Mozilla/5.0 (Macintosh; U; PPC Mac OS X Mach-O; en-US; rv:1.7.5)
Gecko/20041107 Firefox/1.0You would replace it with this abbreviated form:
Mozilla/5.0 (Macintosh) Firefox
This allows the server to figure what type of browser is being used and deliver appropriate content, while not revealing information that might be useful to an attacker. Figure 7-2 shows the relevant section of the configuration page.

You can check what privoxy is
actually doing to your requests by going to http://config.privoxy.org/show-request, which shows the
headers before and after it has modified them.
External Proxy Servers
Neither of these approaches do anything to hide the IP address of your computer. To do that, you need an external proxy that will forward your request to the target server and return the content to your browser. There are many sites on the Internet that have been set up to provide this service. Typically you go to their home page and type in the URL you want to view. In a basic proxy, the IP address of that site will appear in the log of the target server. Sites vary in their level of sophistication. Some will redirect requests among their own set of servers so that no one address is used all the time. Others maintain a list of active proxies elsewhere on the Net and redirect through these, adding further steps between yourself and the target server. A Google search will turn up many examples—these are a few that are active at the time of writing:
Sites like these are set up for various reasons. Some people believe strongly in Internet freedom and want to provide a service to the community. Others are set up to help people who want to view pornography or other questionable, but legal, material, perhaps making some money in the process by serving up ads to their users. Undoubtedly there are some, lurking in the back alleys of the Net, that cater for those interested in illegal material such as child pornography.
Proxies are a dual-use technology. They can just as well protect a whistle-blower or dissident as they can protect a pedophile downloading child pornography. That poses a serious liability for people that operate proxy sites. If their server is involved in illegal activity, whether they know it or not, it will be their door that the FBI will be knocking on. Many proxies have been set up with the best of intentions only to find their service abused. Some have been shut down by the authorities, some have shut themselves down, and, without wanting to sound too paranoid, you can bet that some them are honeypots, set up by the authorities, that exist solely to intercept and trace illegal traffic.
Proxy Networks
Proxy servers can protect the identity of an individual who
accesses a specific server. But they do nothing to protect someone
from a government that is able to monitor and trace traffic passing
through the network, either by packet sniffing or through the use of
compromised proxies. Truly anonymous browsing needs to use technology
at a whole other level of sophistication that combines proxies with
encryption. That technology, albeit in its infancy, is already
available to us. One of the front-runners in this field is Tor, a project started by the Free Haven
Project and the U.S. Naval Research Lab that was recently brought
under the wing of the EFF (http://tor.eff.org).
Tor uses a network of servers, or
nodes, dispersed across the Internet to implement what is called an
onion routing network. This paper
provides a detailed technical background to the project: http://tor.eff.org/cvs/tor/doc/design-paper/tor-design.pdf.
It works by redirecting a http request through multiple Tor nodes until finally sending it to the
target web server. All communication between nodes is encrypted in
such a way that no single node has enough information to decode the
messages. Each node is a proxy, but not in the simple sense that we’ve
been talking about thus far.
A Tor transaction starts with
a regular web browser making a request for a page on a remote web
server. The Tor client consults a
directory of available nodes and picks one at random as the first hop
towards the target server. It then extends the path from that node to
a second one, and so on until there are deemed to be enough to ensure
anonymity. The final node in the path is called the exit node. It will send the unencrypted
request to the target web server and pass the content back along the
same path to the client. All data sent between nodes on the network is
encrypted and each node has a separate set of encryption keys
generated for it by the client. The upshot is that any given node in
the system, other than the client, only knows about the node it
received data from and the one it sent data to. The use of separate
encryption keys prevents any node from eavesdropping on the data it
passes down the chain. This idea of building a path incrementally
through the network is conceptually like peeling away the layers of an
onion, hence the name onion routing.
The path selection and encryption prevents anyone observing the traffic passing through the network. The target web server sees only the IP address of the exit node, and it is impossible to trace a path back to the client. Furthermore, the lifespan of a path through the network is short—typically less than a minute—so that consecutive requests for pages from a single client will most likely come from different exit nodes.
Tor is available for Windows,
Mac OS X, and Unix. Installation as a client is straightforward.
Installing privoxy is recommended
alongside Tor, and happens
automatically with the Mac OS X installation. To use the network you
need to set your browser to use a proxy. That configuration is
identical to the one described earlier for privoxy.
Once you have it configured, the software works quietly in the
background. It does slow things down, sometimes significantly. This is
a function of the number of server nodes and the traffic going through
them at any one time. The Tor
project team encourages users of the system to contribute to its
success by setting up server nodes. The more servers there are, the
better the performance and the more secure the system.
Here is an example of some edited Apache log entries for a regular browser following a series of links from one page to another:
208.12.16.2 "GET /index.html HTTP/1.1"
208.12.16.2 "GET /mobile/ora/index.html HTTP/1.1"
208.12.16.2 "GET /mobile/ora/wurfl_cgi_listing.html HTTP/1.1"The owner of the web server can see a single machine and the
path they take through their site. Now look at the same path when run
through Tor:
64.246.50.101 "GET /index.html HTTP/1.1"
24.207.210.2 "GET /mobile/ora/index.html HTTP/1.1"
67.19.27.123 "GET /mobile/ora/wurfl_cgi_listing.html HTTP/1.1"Each page appears to have been retrieved from a separate browser, none of which is the true source of the request.
As it stands, Tor is a great
way to protect your communications from attempts at eavesdropping, and
it effectively shields your IP address from any site that you visit.
Of course, no system is perfect. Even though a site cannot determine
your IP address, it can still detect that someone is visiting their
site by way of the Tor network,
which might indicate that they are under investigation.
We can download the list of all the current active Tor nodes (http://belegost.seul.org/), and then look for their IP
addresses in our logs. At the time of this writing, there are only 134
of these so this is not difficult. Sets of log records with these IP
addresses, close together in time, would suggest that a site is being
accessed via the Tor network.
Looking at the collection of pages that were visited and, if possible,
the referring pages, could allow us to piece together the path taken
by that visitor. For this reason, it is especially important that you
set up privoxy in conjunction with
Tor and have it hide your referring
page.
Tor is a work in progress.
The technology behind it is sophisticated, well thought out, and well
implemented. It addresses most of the technical issues that face any
scheme for anonymous communication. While the network is still small,
it is growing and has solid backing from the EFF and others. How it
will deal with the inevitable problem of abuse remains to be seen.
Finding a technical solution to this social problem is probably
impossible.
As a practical matter, if you are going to be poking around web
sites that are involved in phishing or other shady business, then it
makes sense to hide your identity from them using Tor. It’s a simple precaution that can
prevent the outside possibility that someone will get upset with you
and flood you with spam or try and break into your machine.
On a lighter note, I do have to warn you about certain side
effects when you use Tor for
regular browsing. Some sites, such as Google, look at the IP address
that your request is coming from and deliver content tailored to that
part of the world. With Tor, you
cannot predict which exit node your request will finally emerge from.
It had me scratching my head for quite a while the first time my
Google search returned its results in Japanese!