
Chapter 8. File Contents
Internet forensics is not just about spam and fake web sites. This chapter shows how you can uncover information hidden in the files that you work with every day. Microsoft Word and Adobe Portable Document Format (PDF) files are two of the most common formats that are used to create and encapsulate important documents. Both formats are extremely rich in the sense that they can contain text with complex fonts and styling, images, hyperlinks, form elements, and a slew of other data types. These great features come at a cost, however, in that the formats become so complex and the files become so large that the only way to access them is through a specific application such as Word or Adobe Acrobat. The approach of opening the file in a plain text editor and reading the contents is simply not feasible in these cases.
That complexity becomes a liability when the applications store information that is hidden from the casual user. As the dramatic examples in this chapter show, it is all too easy to reveal more information than you realize. For those of us with an inquisitive eye, these documents are ideal subjects for our forensic attention.
Word Document Metadata
Microsoft Word is probably the most widely used word-processing software in the world. Although the vast majority of people only use its basic functions, it has many advanced capabilities. One of the more well known of these is Track Changes , a set of reviewing tools that allow multiple people to modify and comment on a document. This is incredibly useful for writers and their editors, as well as for those involved in preparing legal documents or press releases, which require significant review and approval by multiple parties.
When these tools are turned on, any text that is modified has a strikethrough line placed through it. The edits of different reviewers are recorded in different colors. Comments can be attached to any edit to justify the change or to convey information to the other reviewers. It is an invaluable feature that has been used extensively by my editor to keep me on the straight and narrow as I write this book.
The downside of Track Changes is that a heavily edited document can be very difficult to read. The solution is for the primary editor or author to accept or reject the changes to the text using one of the tools. This clears out the strikethrough text and produces a clean document. But that can be tedious and a much easier way to clean things up is to hide all the edits by turning off Track Changes.
The problem is that simply disabling the feature does not remove the changes from the document. Anyone who subsequently receives a copy can turn the feature back on and see all the previous edits and associated comments. This can be a very serious problem. Figure 8-1 shows a fictitious example of how Track Changes can display internal information that you might want to conceal from the final recipient of the document.

Often people modify existing documents rather than writing them from scratch. For example, I might use a business proposal for one client as the starting point for a different client’s proposal, changing the names and parts of the content as appropriate. If Track Changes has been used and the edits have been hidden, but not removed, then the recipient of the new document may discover who else I have been working with, and perhaps how much I was charging them.
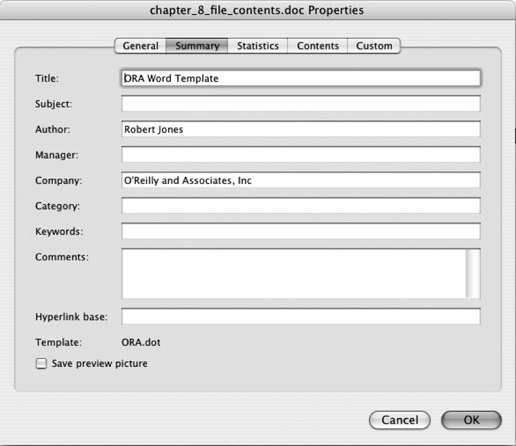
These comments and edits are examples of metadata that augment the basic content of a document in various ways, and Microsoft Word documents can be packed with metadata. Open up the Properties window for a Word document, under the File menu. The Summary tab shows a series of text fields that can be filled in. The owner of the software is usually listed as the author, and perhaps the Company field is filled in. The rest of the fields are often blank. A whole range of other data can be entered under the Custom tab. These fields are used in companies that use a formal procedure for document approval. Any information entered into any of these fields is stored in the Word document as metadata. By default that information is visible to any recipient of the document. They just need to know where to look. Even if you never touch any of these fields, the Author field will carry the name of the owner of the software. Figure 8-2 shows the Summary window for this chapter of the book as I write it. Word has recorded my name, from when I first installed the software, and my apparent company, which it has pulled from the Word template file provided by O’Reilly. This information will be stored as metadata in the document and will be retained whenever the document is transferred and copied. This may not seem like a big deal but as we shall see, simply recording the author can cause a lot of problems.
Often metadata results in the inadvertent disclosure of information. Most are merely embarrassing for the authors but some can have significant consequences.
SCO Lawsuit Documents
One notable example was a Word document that contained a lawsuit by the SCO Group against the car company DaimlerChrysler, accusing it of infringing SCO’s patents. SCO contends that the Linux operating system contains some proprietary source code and intellectual property belonging to SCO. Their lawyers have been filing suits against a number of large companies that use Linux.
A copy of the suit against DaimlerChrysler was passed to reporters at CNET, an online technology news service, in March 2004 (http://news.com.com/2102-7344_3-5170073.html). Seeing that the document was in Word format, they turned on the Track Changes feature and scored a journalistic coup. It turns out that the document originally referred to Bank of America as the defendant, not DaimlerChrysler. The references to the bank were quite specific, including one comment asking, “Did BA receive one of the SCO letters sent to Fortune 1500?,” referring to an earlier mailing of letters to large corporations informing them about SCO’s claims.
They could tell that at 11:10 a.m. on February 18, 2004, the text “Bank of America, a National Banking Association” was replaced with “DaimlerChrysler Corp.” as the defendant in the lawsuit. Comments relating to Bank of America were deleted and the state in which the suit would be heard was changed from California to Michigan.
Other text that was deleted from the lawsuit before it was actually filed included specific mention of Linus Torvalds as being involved in the copying of their intellectual property and detailed some of the specific relief that SCO sought in the case.
“(C)ertain of plaintiff’s copyrighted software code has been materially or exactly copied by Linus Torvalds and/or others for inclusion into one or more distributions of Linux with the copyright management information intentionally removed.”
“... statutory damages under the Third Cause of Action in a sum not less than $2,500 and not more than $25,000 for each and every copy and/or distribution of Linux made by Defendant.”
Inadvertent disclosures such as these are remarkable. Not only do they serve as a very public embarrassment for the people who prepared the document, but they also reveal important details about their legal strategy. You can be sure that the lawyers at Bank of America were extremely interested in these revelations.
Other Examples
There are many examples of people being tripped up by Word metadata. Alcatel, a maker of communications and networking equipment, fell victim in 2001 when they issued a press release regarding their DSL modem. At face value, the release deflected criticisms of their modem by a computer security organization, remarking that all DSL modems were subject to the vulnerability in question. Enabling Track Changes in the Word document that contained the release revealed an entire discussion between Alcatel staff regarding the best way to handle the security issue. Comments such as “What are you doing to provide a legitimate fix?” and “Why don’t we switch on firewalls by default for all of our customers?” did not inspire confidence in the company’s response to its customers.
In his New Year’s speech in January 2004, Danish Prime Minister Anders Fogh Rasmussen made bold statements about Denmark becoming one of the world’s more technologically advanced countries. Unfortunately for him, the Word document containing the speech identified the original author as Christopher Arzrouni, a senior member of the Association of Danish Industries and a well-known proponent of relatively extreme political views. This revelation did nothing to help Rasmussen’s attempt to distance himself from such views.
In March 2004, the attorney general of California, Bill Lockyer, circulated a draft letter to his fellow state attorneys general in which he described peer-to-peer (P2P) file-sharing software as a “dangerous product” and argued that such software should include a warning to users about the legal and personal risks they might face as a result of using it. Failure to include such a warning would constitute a deceptive trade practice. The tone of the letter was extremely strong.
The draft was distributed as a Word document, which showed the
username of the original author to be stevensonv. It so happened that Vans
Stevenson was the senior vice president for state legislative affairs
of the Motion Picture Association of America (MPAA) at the time. Given
the MPAA’s vigorous campaign against P2P software, this coincidence,
and the failure of anyone involved to offer an alternate explanation,
raised more than a few eyebrows in the P2P community.
Even Microsoft is not immune to this problem. Michal Zalewski (http://lcamtuf.coredump.cx/strikeout/) has trawled through many publicly available documents on Microsoft web sites and uncovered numerous examples where comments and edits in marketing documents can be recovered by enabling Track Changes.
U.K. Government Dossier on Iraq
Even when care is taken to remove the comments and modified text, other data may remain hidden in the dark corners of a Word document, which can still reveal more than its authors would prefer.
This was the case with a dossier prepared by the office of U.K. Prime Minister Tony Blair in February 2003, detailing the impact of Iraq’s intelligence and security services on the United Nations weapons inspections that were taking place at the time. The document was used to support the argument that inspections were not working and that military action against Iraq was justified. Such an important document was bound to attract close scrutiny.
Glen Rangwala, a faculty member at Cambridge University, thought the text looked familiar. After some cross-checking in the library, he discovered that large sections of the text had been lifted from an article published in September 2002, by Ibrahim al-Marashi, a graduate student in the United States. Text had clearly been cut and pasted from the original work, as evidenced by the grammatical errors of the author being carried through to the dossier. Some sentences had been modified, but in all of these the new version was more strongly worded. Additional text had been taken from two other authors. None of the copied text was attributed to the original author. Rangwala’s original analysis (http://www.casi.org.uk/discuss/2003/msg00457.html) makes for very interesting reading.
The report of such blatant plagiarism caught the attention of Richard M. Smith in the United States. He noticed that the dossier had been posted on the 10 Downing Street web site as a Microsoft Word document. There was an outside chance that it might contain some clues about the people involved in its preparation, so he downloaded a copy and started poking around. The file is available on his web site: http://www.computerbytesman.com/privacy/blair.doc.
Opening it up in Word showed that it had been properly sanitized. No evidence was left from the Track Changes feature and no comments could be retrieved. But Smith decided to delve a little deeper. He happened to know that a Word document contains a hidden revision log that represents its history, including the names of the people who worked on it and the names of the files that it was saved as. He was able to extract the log from the dossier, as shown here:
Rev. #1: "cic22" edited file "C:DOCUME~1phamillLOCALS~1Temp
AutoRecovery save of Iraq - security.asd"
Rev. #2: "cic22" edited file "C:DOCUME~1phamillLOCALS~1Temp
AutoRecovery save of Iraq - security.asd"
Rev. #3: "cic22" edited file "C:DOCUME~1phamillLOCALS~1Temp
AutoRecovery save of Iraq - security.asd"
Rev. #4: "JPratt" edited file "C:TEMPIraq - security.doc"
Rev. #5: "JPratt" edited file "A:Iraq - security.doc"
Rev. #6: "ablackshaw" edited file "C:ABlackshawIraq - security.doc"
Rev. #7: "ablackshaw" edited file "C:ABlackshawA;Iraq - security.doc"
Rev. #8: "ablackshaw" edited file "A:Iraq - security.doc"
Rev. #9: "MKhan" edited file "C:TEMPIraq - security.doc"
Rev. #10: "MKhan" edited file "C:WINNTProfilesmkhanDesktopIraq.doc"This short block of text is a treasure trove of information that
he and Rangwala were able to dissect (http://www.computerbytesman.com/privacy/blair.htm).
cic22 is a reference to a government
office called the Communications Information Centre. The word phamill in the first three file paths looks
like the name of a person; and JPratt, ablackshaw, and MKhan are clearly names. It took only a few
calls to news reporters to figure out the role of each individual. Paul
Hamill was a Foreign Office official, John Pratt worked in 10 Downing
Street, Alison Blackshaw was the personal assistant to Blair’s Press
Secretary, and Murtaza Khan was a junior press officer in Downing
Street. So not only was the document full of plagiarized text, but there
was clear evidence that the Prime Minister’s press office had played a
major role in its preparation.
The affair of the so-called dodgy dossier became a major embarrassment for the government. The foreign secretary was hauled in front of a House of Commons select committee, where even he admitted that the affair was a complete Horlicks (a colorful British euphemism). Things quickly went from bad to worse with a controversial piece of reporting from the BBC alleging that Downing Street’s press officers had changed the original intelligence assessments to suit their political agenda. The tragic suicide of a senior government scientist involved in the report, and the subsequent public inquiry, ensured that the dossier remained in the headlines for months, even as the events of the war itself unfolded.
The revision log tells us one more thing. The file paths indicate
that the documents were edited on Windows systems, which is not
surprising. However, note that several of the paths begin with A:. This is the default drive ID for a floppy
disk drive. We can see that Pratt and Blackshaw both accessed the
document on a floppy, perhaps preparing for transfer to another
individual. Thanks to the select committee hearings we now know the
recipient of that disk was none other than Colin Powell, U.S. Secretary
of State, who used the dossier in his address to the United Nations as
justification for the invasion of Iraq.
These seemingly mundane details in a file revision log reflect actions at the highest level of government that eventually led nations to war. This is a dramatic illustration of the power of Internet forensics and how simple tools can have an immense impact.
Extracting Word Revision Logs
Word documents use a proprietary format that is extremely complex. It has to represent not just the text of a document but also the details of how it is formatted. It can include images, embedded spreadsheets, and a host of other objects. Somewhere in the midst of all that is the revision log. Rather than try and recover that specific information, I will show you a general approach that will extract most text strings in a document. Look through that output; it is usually easy to spot the revision log.
The approach is to use the standard Unix program strings, which I discuss in Chapter 3 in the context of
dissecting email attachments. Running strings on a Word document will display the
text of the document along with various other pieces of information.
Here is the output from a very simple Word document, with a few
duplicate lines edited out:
% strings HelloWord.doc
jbjbq
Hello Word
Hello Word
Robert Jones
Normal
Robert Jones
Microsoft Word 10.1
Craic Computing LLC
Hello Word
Title
Microsoft Word Document
NB6W
Word.Document.8That reveals the content of the document: the phrase “Hello
Word,” along with the author’s name, the organization that owns the
software, the title, and the version of Word that was used. But it
does not include anything that looks like a filename. By default,
strings will only look for ASCII
characters that are encoded as single 7-bit
bytes, which is the standard way of encoding regular text
in binary documents. For various reasons, mostly to do with
representing characters from non-ASCII alphabets, Word saves certain
text in different encodings. In recent versions of strings, you can specify alternate encodings
using the -e option. Read the
man page on your system to see if
you have this capability. By running strings
-eb, for example, you can reveal any text encoded in
16-bit little endian format. To
save you the hassle of running the program multiple times with
different options, I have written a Perl script that does that for you
and that presents the resulting text in the proper order. This is
shown in Example
8-1.
#!/usr/bin/perl -w
die "Usage: $0 <word doc>
" unless @ARGV == 1;
my %hash = ();
foreach my $encoding ('s', 'b', 'B', 'l', 'L') {
my $text = `strings -td -e$encoding $ARGV[0]`;
foreach my $line (split /
/, $text) {
if($line =~ /^s*(d+)s+(.*)$/) {
$hash{$1} = $2;
}
}
}
foreach my $offset (sort { $a <=> $b } keys %hash) {
printf "%s
", $hash{$offset};
}Running this on my example document produces about twice as many lines of output. Most of these are related to document formatting, but included among them is the following:
Robert JoneseMacintoshHD:Users:jones:Documents:Craic:Writing:
Forensics:Examples:HelloWord.docThis is the path to the example document on the Macintosh that I am using to write this book. The output that results from running the script on the Iraq dossier includes this block:
cic22JC:DOCUME~1phamillLOCALS~1TempAutoRecovery save of
Iraq - security.asd
cic22JC:DOCUME~1phamillLOCALS~1TempAutoRecovery save of
Iraq - security.asd
cic22JC:DOCUME~1phamillLOCALS~1TempAutoRecovery save of
Iraq - security.asd
JPratt C:TEMPIraq - security.doc
JPratt A:Iraq - security.doc
ablackshaw!C:ABlackshawIraq - security.doc
ablackshaw#C:ABlackshawA;Iraq - security.doc
ablackshaw A:Iraq - security.doc
MKhan C:TEMPIraq - security.doc
MKhan(C:WINNTProfilesmkhanDesktopIraq.docWith the exception of an arbitrary character between each the username and file path on each line, this block is identical to the revision log shown in the previous section. Try running the script on your own Word documents, or more interestingly, on those that you have received as email attachments.
If you want to look further afield, Google can supply you with a
wide variety of source material. Including the phrase filetype:doc in your query will limit the
results to Word documents. The number of these that are publicly
available is astounding. The query press
release filetype:doc reports around 695,000 matches. This
combination of Google searches and revision log parsing could be very
productive for investigative journalists with a basic knowledge of
Unix.
Discovering Plagiarism
Plagiarism is a widespread problem that has benefited greatly from the growth of the Internet and the capabilities of search engines. It involves college students copying essays from Internet sites, scientists trying to pass off the results of other researchers as their own in grant applications and papers, and journalists stealing content from their colleagues to include in their own dispatches. The Iraq dossier is an unusually bold example given its high profile and its brazen copying of text from other sources without attribution.
Detecting plagiarism is difficult. The Iraq dossier was only revealed because Glen Rangwala was familiar with the area and recognized the text from another paper. Automated detection in the most general sense is extremely difficult. Some success has been achieved in the area of college papers, due in part to the volume of examples that are available. Several companies, such as http://Turnitin.com, offer online services that screen all papers submitted by students of subscribing institutions. The risk that attempted plagiarism will be detected can be an effective deterrent, regardless of how well the detection software might perform on any given example.
On a more basic level, you can use Google to identify similar
documents on the Web. The related:
syntax lets you search for content that is similar to a specific page.
A search of related:http://www.computerbytesman.com/privacy/blair.doc
returns around 30 pages. Most of these include quotes from the dossier
or they describe the copying of content from elsewhere. But some way
down the list is the original article from which most of the text was
copied (http://meria.idc.ac.il/journal/2002/issue3/jv6n3a1.html).
The measure of similarity that Google uses to relate texts is not
ideal for this purpose and it can return a bunch of seemingly
unrelated material. But if two or more pages with very similar content
have been indexed in Google, then a related: search with any one of them should
identify the other examples.
The downside of this approach is that the text you want to
search with must be available on the Web and already be
indexed by Google prior to your search. Unfortunately, you
cannot create a new page, post it on a web site, and submit a related: search that refers to it. Google
appears to look for that page in its existing index, rather than
fetching it from the original site. If it fails to retrieve the page,
then it returns results based simply on the URL, which is not going to
be what you expect.
Having discovered two documents that appear to be related, the
next step is to identify the identical or similar text. This is a
difficult problem in and of itself. If the files are essentially
carbon copies of each other, then the Unix utility diff might be useful, but for most cases it
fails completely. diff was designed
for comparing very structured text from source code listings and
computer output, and it cannot handle the diversity in the way text is
laid out in regular documents.
The comparison of arbitrary text and the alignment of similar, but non-identical, sentences are hard problems that continue to attract the interest of computer scientists. A related problem is that of DNA and protein sequence comparison, which lie at the heart of bioinformatics. Algorithms based on dynamic programming have proven to be very useful in both fields, although their performance characteristics have led to faster, more approximate methods being developed.
The Perl script shown in Example 8-2 is a very simple implementation of dynamic programming as applied to text comparison. It has a number of significant limitations but it serves as a useful way to find identical text within two arbitrary documents. It splits the text of the two documents into two arrays of words, eliminating punctuation and words of less than four characters. It then takes each word from the first document in turn and looks for a match in the second document. For every match it finds, it initiates a comparison of the arrays starting at that point. It steps forward through the arrays one word at a time, increasing the score of the matching segment if the words are identical. Conceptually, this is like taking a diagonal path through a matrix where each element represents the comparison of word i from array 0 with word j from array 1. All matching segments with greater than a minimum score are saved, overlapping segments are resolved, and finally, the text that comprises each of these is output. A more complete implementation would be able to handle insertions or deletions of words in one text relative to the other.
#!/usr/bin/perl -w
die "Usage: $0 <file1> <file2>
" unless @ARGV == 2;
my $minscore = 5;
my @words0 = ();
my @words1 = ();
loadWords($ARGV[0], @words0);
loadWords($ARGV[1], @words1);
my %segment = ();
my $score = 0;
my $maxscore = 0;
my $maxi0 = 0;
my $maxi1 = 0;
for(my $i0 = 0; $i0 < @words0; $i0++) {
my $word0 = $words0[$i0];
for(my $i1 = 0; $i1 < @words1; $i1++) {
if(lc $words1[$i1] eq lc $word0) {
($maxscore, $maxi0, $maxi1) =
matchDiagonal(@words0, @words1, $i0, $i1);
if(exists $segment{$maxi0}{$maxi1}) {
if($maxscore > $segment{$maxi0}{$maxi1}){
$segment{$maxi0}{$maxi1} = $maxscore;
}
} else {
$segment{$maxi0}{$maxi1} = $maxscore;
}
}
}
}
foreach my $maxi0 (sort keys %segment) {
foreach my $maxi1(sort keys %{$segment{$maxi0}}) {
$maxscore = $segment{$maxi0}{$maxi1};
if($maxscore >= $minscore) {
printf "%s
",
traceBack(@words0, @words1, $maxi0, $maxi1, $maxscore);
}
}
}
sub matchDiagonal {
# Extend an initial word match along both word arrays
my ($words0, $words1, $i0, $i1) = @_;
my $maxscore = 0;
my $maxi0 = $i0;
my $maxi1 = $i1;
my $score = 0;
my $j1 = $i1;
for(my $j0 = $i0; $j0 < @$words0; $j0++) {
if(lc $words0->[$j0] eq lc $words1->[$j1]) {
$score++;
if($score > $maxscore) {
$maxscore = $score;
$maxi0 = $j0;
$maxi1 = $j1;
}
} else {
$score--;
}
if($score < 0) {
$score = 0;
last;
}
$j1++;
last if($j1 >= @$words1);
}
($maxscore, $maxi0, $maxi1);
}
sub traceBack {
# Trace back from the maximum score to reconstruct the matching string
my ($words0, $words1, $maxi0, $maxi1, $score) = @_;
my @array0 = ();
my @array1 = ();
my $i1 = $maxi1;
for(my $i0 = $maxi0; $i0 >= 0; $i0--) {
push @array0, $words0[$i0];
push @array1, $words1[$i1];
if(lc $words0[$i0] eq lc $words1[$i1]) {
$score--;
}
last if($score == 0);
$i1--;
last if($i1 < 0);
}
my @array = ();
for(my $i=0; $i<@array0; $i++) {
if(lc $array0[$i] eq lc $array1[$i]) {
push @array, $array0[$i];
} else {
push @array, sprintf "((%s/%s))", $array0[$i], $array1[$i];
}
}
join ' ', reverse @array;
}
sub loadWords {
# Read in the text word by word - skip short words
my ($filename, $words) = @_;
my $minsize = 4;
open INPUT, "< $filename" or die "Unable to open file: $filename
";
while(<INPUT>) {
$_ =~ s/[^a-zA-Z0-9]+/ /g;
$_ =~ s/^s+//;
foreach my $word (split /s+/, $_) {
if(length $word >= $minsize) {
push @$words, $word;
}
}
}
close INPUT;
}To use the script, you need to extract the plain text from the two documents, as opposed to the HTML source of a web page, for example. The removal of punctuation and short words improves the quality of the comparison but makes the output more difficult to read. Word differences within matching segments are shown within two sets of parentheses, which enclose the non-matching words.
Applying the program to the text files saved from the Iraq dossier Word document, and a web page containing the al-Marashi paper, on which it was based, produces a large number of matching segments that indicate the extent of the plagiarism in that case. Here are some examples from that output:
% ./compare_documents.pl marashi.txt dossier.txt
[...]
Jihaz Hamaya Khas Special Protection Apparatus charged with
protecting Presidential Offices Council Ministers
[...]
informants external activities include ((monitoring/spying)) Iraqi
((embassies/diplomats)) abroad collecting overseas intelligence
((aiding/supporting)) ((opposition/terrorist)) ((groups/organisations))
hostile regimes conducting sabotage subversion terrorist operations
against
[...]
shifting directors these agencies establish base security
((organization/organisation)) substantial period time
[...]Some of the differences represent simple replacement of the
original American English text by the British spelling of the same
word—for example, organization has
been replaced with organisation
throughout the document. Most troubling are examples like the second
block in this output. Here the original text aiding opposition groups has been replaced
with the more strongly worded phrase supporting terrorist organisations.
Even though this script has serious limitations, it provides a simple way to compare two text files, to display similar blocks of text, and to highlight small but possibly significant differences between them.
The Right Way to Distribute Documents
Most of these Word document problems could have been prevented if the authors had converted the files to PDF before distributing them. All of the Word-specific revision logs, comments, and edits would have been stripped out as part of that process. PDF files do have hidden information of their own but it is typically limited to identifying the software used to create the file, unless the author has explicitly added comments and the like. using Adobe Acrobat. The publicity surrounding the various Word document disclosures in recent years has prompted many governments to require that documents be converted to PDF prior to publication.
But for many other purposes, it still makes sense to transfer documents in Word format, especially in the business world. Many situations arise where two or more parties need to revise and comment on the wording of a document, and Word documents remain the most convenient way to do this. So how should you sanitize a document?
Most of the issues can be dealt with by removing any identifying information in the program preferences, such as your name, and then either avoiding Track Changes or being careful to accept or reject all outstanding edits and comments before final release.
If the text styling and layout of the document is relatively simple, then a quick and effective solution is to save the document in Rich Text Format (RTF). This is a subset of native Word format that can represent most documents, but RTF has the advantage of not including the metadata with it.
Microsoft has proven to be quite forthcoming about metadata and
its removal. One of several Knowledge Base articles on its web site,
entitled “How to minimize metadata in Word 2003” (http://support.microsoft.com/kb/825576), details 20
different types of metadata that can be removed manually or through
setting certain preferences. They also offer a Remove Hidden Data plug-in for recent
versions of Word, Excel, and PowerPoint to make the process less
burdensome.
Tools are also available from third-party vendors. Most of these are targeted at law firms, and some can be integrated with mail servers to apply security policies automatically to all outgoing email. Workshare Protect, iScrub, and Metadata Scrubber are three commercial tools.
Be aware that any complex document format may contain hidden metadata. At the very least, be sure to check for identifying information in the various menu items available in the software used to create or view the document. To be thorough, run the script shown in Example 8-1 on the document file and look for hidden strings. Always understand the hidden information that your documents carry with them.
Document Forgery
One advantage of using PDF files for document transfer is that they can be digitally signed and even encrypted. Signatures are overkill for most applications, but in the case of an especially sensitive document, they offer an important safeguard, preventing a malicious third party from changing the document after it has been released. This technology has been around for a number of years, but it’s not as widely used as it could be. I predict this will change over time as more cases emerge where electronic documents have been modified or forged in order to commit fraud or to embarrass, discredit, or blackmail people.
Two dramatic examples of forgery came to light during the 2004 U.S. presidential election. The fact that sophisticated forgeries were created with the sole intent of influencing public opinion is very disturbing and does not bode well for future election campaigns.
CBS News aired a story in September 2004 concerning President Bush’s service in the Texas Air National Guard in 1972. The report was based on documents that turned out to be forgeries. Even though the materials they were given were in the form of physical pieces of paper that appeared to date from that era, their electronic origin was revealed by careful analysis of the scanned documents. What gave them away was the presence of superscripts in several places. For example:
Bush wasn’t here during rating period and I don’t have any feedback from 187th in Alabama.
Electric typewriters in the seventies could not produce
superscripts that were scaled down in size like the th in 187th. That
suggested that a word processor had been used. Typing the same text in
Microsoft Word, scaling the text to fit the scanned memo, and overlaying
the two produced a remarkable concordance.
The original story, with links to the scanned memos and to the later internal review by CBS, is available at http://www.cbsnews.com/stories/2004/09/08/60II/main641984.shtml. An extremely detailed analysis of the typography in the memos, written by Joseph Newcomer, can be found at http://www.flounder.com/bush2.htm.
The second example involved a photograph of John Kerry appearing to share the stage at an anti-Vietnam war rally in 1970 with the actress Jane Fonda (see http://www.snopes.com/photos/politics/kerry2.asp). The photograph was published on the conservative web site http://NewsMax.com in February 2004. It caused quite a stir, especially among veterans, as it suggested a more radical side to Kerry’s character than had been presented thus far. The picture was quickly revealed as a fake by Ken Light, the photographer who took the original picture of Fonda at a rally in 1971, one year after the supposed joint appearance. The fake image was a clever composite. The image of Fonda had been carefully excised from its image and then placed next to Kerry. Her image appears in front of the background trees but behind the papers that Kerry is holding in his hand. With hindsight, you can tell that the light on their faces is coming from two different directions, but overall it’s a pretty good fake.
The selective manipulation of digital photographs is nothing new. Pick up any of the tabloid papers in a U.S. supermarket and you’re bound to see an example on the cover. But the tremendous recent growth in digital photography, and the ease with which images can be retrieved from the Web, are destined to make abuses of the art ever more frequent. Digital signatures and watermarks offer a way to protect future images, but there is little we can do to guard against the manipulation of historical material.
Redaction of Sensitive Information
Information hidden in a document can be the unintentional consequence of using complex software. From a forensics point of view, it represents a bonus—something we didn’t expect to find. But information can also be intentionally hidden, disguised, or removed. Uncovering what someone does not want you to know represents a challenge.
In a variety of circumstances, government agencies, the courts, and others need to publish documents that contain sensitive information. Within these documents, they may need to remove or obscure the names of individuals, identification numbers such as a social security IDs, or colorful expletives that are deemed inappropriate for publication. A good example would be the publication of a government intelligence briefing as part of a congressional hearing, in which a foreign informant is named. The name for this selective editing is redaction . It is a polite name for censorship.
In the past, redaction has meant obscuring the relevant text on a piece of paper with a black marker. Any subsequent photocopies of the paper would retain the blacked-out region and there would be no way for anyone to read the underlying words. That has proven to be a simple, cheap, and extremely effective way of hiding information. But these days, most of the documents that we deal with are in electronic form. The PDF file format, in particular, is a very convenient way to distribute documents, including those scanned from handwritten or other non-electronic sources.
In redacting documents of this kind, the approach taken by some has been to use the metaphor of the black marker on the contents of the PDF file. You can import the document into Adobe Illustrator, Macromedia Freehand, or something similar, cover the offending text with a black box, and then export the file as a PDF. Publish this on the Web, and anyone viewing it with Adobe Acrobat Reader, Apple Preview, or other simple PDF viewers, will see the text blacked out and will have no way to see what lies beneath. It is simple and appears to be effective, but you can see the problem, right?
Instead of obliterating the text, what you have done is, in effect, placed a piece of black tape over it. Peel back the tape and everything will be revealed. If you have the full version of Adobe Acrobat, as opposed to the ubiquitous Reader, you can use the TouchUp Object Tool to simply move the blacked-out region to one side, revealing the secrets beneath. Similarly, you can open PDF files in Adobe Illustrator or Macromedia Freehand and select and move the regions. It couldn’t be simpler.
This is clearly a really bad way to do redaction. Nobody would actually use that with real sensitive documents, would they?
The D.C. Sniper Letter
In October 2002, the Washington D.C. area witnessed a number of fatal shootings that all appeared to be carried out by the same sniper. Two men were eventually arrested and convicted for the string of murders. In the course of that investigation, the police found a handwritten letter at the scene of one of the shootings in Ashland, VA, on October 19, apparently from the sniper, demanding a 10-million-dollar ransom. The note explained that the money was to be deposited to a specific credit card account.
As part of its coverage of the investigation, the Washington Post obtained a copy of the letter and decided to publish its contents. Somewhere along the line, either the Post, the police, or whoever passed the letter to the Post, chose to redact certain text in the letter including the credit card account number, the name on the card, a contact phone number, and so on. The letter was scanned and then a program such as Adobe Illustrator was used to black out the text, and the composite document was exported as a PDF file. The modified image was printed in the Washington Post and nobody reading the paper was able to read the redacted text. But then they put the PDF on their web site.
Anyone with the full version of Acrobat was able to click on the black boxes, move them to one side and reveal the personal credit card information that was covered. As it turned out, the snipers were arrested shortly thereafter and, in due course, convicted. The credit card had been stolen in California and has, undoubtedly, been cancelled.
None of the disclosed information appears to have disrupted the investigation or subsequent trials. Things could have been very different, however. Keeping evidence confidential prior to an arrest or conviction is a central tenet of police work. Failing to do so can make finding the criminal more difficult and it can seriously jeopardize any court proceedings that follow. This oversight in preparing the PDF files could have had very serious implications.
The PDF files are no longer on the Washington Post site, but you can find copies of the redacted and un-redacted versions here:
The CIA in Iran in 1953
The New York Times made a similar mistake a couple of years prior to this in April 2000. At that time they published a detailed analysis of the involvement of the CIA in the overthrow of the government in Iran in 1953, which returned Shah Mohammed Reza Pahlevi to power. The articles, along with some of the supporting documentation, are available on the Times web site at http://www.nytimes.com/library/world/mideast/041600iran-cia-index.html.
The report was based on leaked documents, most notably a classified CIA history of the entire episode. The Times initially decided to withhold certain documents to avoid disclosing the identities of certain agents and informants, and they placed the documents they chose to release on their web site as PDF files. In mid-June 2000, however, they decided to make all the documents available. But prior to doing this, they reviewed the documents and redacted any names or information they thought might jeopardize any intelligence agents. Just as with the D.C. sniper case, they simply blacked out the offending text in Illustrator and exported the PDF file.
How the snafu was uncovered was a little different in this case. John Young of New York just had a copy of the standard Acrobat Reader with which to view the file. He also had a slow computer, which turned out be the critical element. Because of it, the PDF files loaded very slowly and, to his surprise, he got to see the original text for several seconds before the black redaction was overlaid on top of it. By stopping the page load at the right time, he was able to view all the redacted information. More details are available at http://cryptome.org/cia-iran.htm.
This feature was discovered using Version 3.01 of Acrobat Reader and has been fixed in newer releases. If you download the D.C. sniper letter using the current version of Reader with a slow PC or Internet connection, you will see the black boxes appear before the underlying image. All the same, it remains a clear example of the surprises that occur with software when enough people use the same product in different circumstances.
U.S. Army Report on the Death of Nicola Calipari
Both of the previous examples involved printed documents that had been scanned and then redacted. A more recent example from May 2005 involves text that was converted from a Microsoft Word document into PDF format. The document was a report by the U.S. Army on their investigation into the tragic shooting death of an Italian intelligence agent at an army checkpoint in Baghdad in March 2005.
The original report had been heavily redacted to conceal classified information prior to its release to the public. Figure 8-3 shows a sample of this. The blacked out text was intended to conceal the names of military personnel, current operational procedures, and recommendations for their improvement.

But within a few hours of its publication, an uncensored version
of the report was available. Salvatore Schifani, an IT worker in
Italy, had spotted the PDF document on a news site and quickly
realized that he could reveal the hidden text simply by cutting and
pasting it into another application. On Mac OS X, for example, with
the document loaded into the Preview application, the keyboard
sequence ![]() -2,
-2, ![]() -A,
-A, ![]() -C is all it takes to copy the entire uncensored
text to the Clipboard.
-C is all it takes to copy the entire uncensored
text to the Clipboard.
As with the D.C. sniper example, the creator of this document simply laid black boxes over the sensitive text and did not take the additional steps necessary to fix them in place. This is perhaps the largest and most serious disclosure from a badly redacted PDF document thus far. To add insult to injury, the creator of the PDF file is clearly identified in the document summary.
A BBC news story on the disclosure and an Italian report from the newspaper Corriere Della Sera, which includes links to both versions of the document, can be accessed via these links:
Intelligence on Al Qaeda
Even if a redacted document has been prepared correctly, there may still be a way to uncover the text in certain cases, or at least to make an educated guess about it. In April 2004, David Naccache of Luxembourg and Clare Whelan of Dublin figured out a clever way to reveal the blacked out words in a U.S. intelligence briefing released to the public in redacted form as part of the inquiry into the September 11 attacks (http://www.theregister.com/2004/05/13/student_unlocks_military_secrets/). Their solution used a combination of font measurements, dictionary searches, and human intuition. One example they studied was this sentence:
An Egyptian Islamic Jihad (EIJ) operative told an ######## service at the time that Bin Ladin was planning to exploit the operative’s access to the US to mount a terrorist strike.
Starting with a slightly rotated copy of the original printed
document, they aligned the text and figured out that it was in the
font Arial. Then they counted up the number of pixels that were
blacked out in the sentence. They looked through all the words in a
relevant dictionary and selected those which, when rendered in Arial
at the right size, would cover that number of pixels, give or take a
few. They whittled down the list of those candidate words from 1,530
to 346 using semantic rules of some sort. Presumably this took into
account the word an immediately
before the redaction, indicating it began with a vowel. Visual
analysis of that subset reduced that further to just seven candidates.
Eventually human intuition led them to choose between the words
Ukranian, Ugandan, and
Egyptian, and they chose the latter. This is not
such a remarkable choice given the rest of the sentence, but it’s
still a very clever way of figuring out the secret. They applied the
same technique to a Defense Department memo and identified
South Korea as the redacted words in a sentence
concerning the transfer of information about helicopters to
Iraq.
The Right Way to Redact
How should you redact sensitive information? PDF files are still a great way to distribute documents over the Web. What you need is a way to completely remove the redacted text before the PDF file is created.
If the text is already in the form of a Word document or plain
text file, then we can easily replace the problematic words with a
standard string such as [redaction], or a string of dashes or other
symbols, one for each character that is replaced. The benefit of the
latter is that it shows you how much text has been modified. In
assessing a document of this sort, especially a redacted government
report, I really want to know if the censors removed only a few words
or whether there are several pages that I am not being shown.
Replacement characters let you see that, but if they cover only a word
or two, then they leave useful clues about the hidden text. Using the
fixed string hides that information effectively.
With scanned images, the best way to modify them is to use an image editor and erase the offending section of the image. It is important to do this in the same layer as the original image to avoid the aforementioned overlay problems. Save the image out as a simple image format file such as JPEG or PNG and check that it is properly redacted before including it in a PDF file. This does not get around the pixel counting approach, however. In that case, it would be necessary to expand, shrink, or move surrounding sub-images so as to confound this technique.
If the document is already in PDF format, there are two approaches that can protect the content. You can export the document as an image, such as a PNG format file, in which case all the PDF objects are projected onto a single layer. It is impossible to recover the hidden text from this format because the pixels of the overlaid black boxes have replaced it. The problem here is that you lose the flexibility that comes with PDF in terms of viewing individual pages, convenient printing, and so forth.
Alternatively, you can apply one of several document security options that are available in the full version of Adobe Acrobat. These options can allow document printing and viewing but prevent anyone from selecting or changing the text. While this is a convenient approach, the hidden text is still contained within the document, and a successful attack on the security mechanism could potentially reveal it. The best approach is to prevent the sensitive text from ever appearing in the file.
Redaction and censorship are two sides to the same coin. Sometimes the reason for redaction is political, suppressing damaging revelations or simply avoiding embarrassment. Discovering the hidden text might be seen as an act of good investigative journalism. But in many instances, redaction is used legitimately to protect the identity of a victim of crime, a child, or someone whose life may be placed in danger by the revelation. Just because you can reveal a secret does not mean that you should. Think before you act.