
Chapter 9. People and Places
In the previous chapters, I introduced the main tools and techniques of Internet forensics that you will use all the time in your own explorations. But I am a firm believer that you can never have too many tools, so this chapter presents a miscellany of techniques that you may want to keep on hand for that special occasion.
These are the one-of-a-kind tools that, in the real world, you would find rattling around in the bottom of your toolbox among the orphaned nuts and bolts and the blunt drill bits. They are the sort of thing that you don’t need very often, but when the occasion arises, they are just right for the job.
Geographic Location
Knowing where in the world someone is located is very valuable
information. In Chapter
2, I talked about how you can infer the location of a computer
from its IP address and the whois
record for its domain name. I also explained how many of those records
contain bogus contact information that is placed there to
deceive.
To recap those points, you can use the whois command with an IP address to find out
the network block that contains a specific machine. This should specify
the country and may be able to define the region or even the city in
which it is located. Using dig -x on
the IP address may return a different hostname than you started with,
especially if it hosts multiple web servers. The canonical name that DNS
returns for the host may contain clues about its location.
If the host lies within a country specific domain, such as .uk or .fr, then you can tell right away with which country the server is associated. But be aware that smaller countries with interesting domain suffixes will sell domains to anyone, allowing them to locate those servers anywhere in the world. One example is the island of Tonga in the South Pacific, which manages domains with the .to suffix.
Inferring location at a higher level of resolution requires a certain amount of local knowledge. Take these three hostnames, for example:
In the first of these, working right to left, you can infer that this host in the United States from the us component of the name. OH is the abbreviation for Ohio, so the oh part suggests a location in that state and columbus1 implies that this machine is located in the city of Columbus. The other two examples require a little more intuition. Placing ameritech in the United States is pretty obvious and can be easily verified. chcgil and sbndin might be hard to decode if you had a single example only. But having the pair helps reveal that chcgil means Chicago, Illinois, and sbndin means South Bend, Indiana.
But bear in mind that reverse DNS lookups will only work if the machine has been given a hostname and a reverse mapping record has been added to the DNS tables. The reason many fraud-related sites use a numeric IP address in their URLs is to make it difficult for anyone to locate their server.
Even if the name of a computer is uninformative, you may be able
to infer location from the names of the routers that link your system to
theirs. traceroute will list those
names as it builds its path. These routers are often given informative
names by the companies that operate network backbones because this can
help them debug system problems. The following block of traceroute
output shows the path from my system in Seattle to one in
Chicago:
% traceroute 68.251.56.245
[...]
11 ex1-p9-0.eqsjca.sbcglobal.net (151.164.191.201)
bb1-p6-0.crsfca.sbcglobal.net (151.164.41.9)
core1-p5-0.crsfca.sbcglobal.net (151.164.243.1)
14 core1-p5-0.crskut.sbcglobal.net (151.164.42.11)
15 core1-p2-0.crdnco.sbcglobal.net (151.164.243.242)
16 core1-p5-0.crkcmo.sbcglobal.net (151.164.42.23)
17 core2-p5-0.crchil.sbcglobal.net (151.164.191.199)It is easy to figure out the naming convention of these routers if
you know a little about U.S. geography. They reveal that packets are
being routed through San Jose (sj) in
California, then through San Francisco (sf), Salt Lake City (sk) in Utah, Denver (dn) in Colorado, Kansas City (kc) in Missouri, and finally to Chicago
(ch) in Illinois. Now, if I had to
analyze a route within, say, Japan or China, then I might not be quite
as successful. But the technique can be useful in a surprising number of
cases.
In principle, the address information contained in a whois record for a domain should be accurate.
But the registries do not validate contact information and you can
presume that domains that are associated with any form of scam will
contain false information. But in other cases, you might want to check a
block of contact information rather than disregarding it on
principle.
There are three scenarios. The address could be correct and completely legitimate. It could be a real address that belongs to some random person with no connection to this domain. Or it could be a completely fictitious address. You can use the resources of the Web to help prove or disprove the third of these options.
For example, here is part of the listing for a domain used to host a fake eBay site. It looks like a legitimate address:
Admin Name........ Robert R.
Admin Address..... 1410 S. 12th St
Admin Address..... Philadelphia
Admin Address..... 19147
Admin Address..... PA
Admin Address..... UNITED STATES
Admin Phone....... +1.609892xxxxEntering that into any of the major mapping web sites, such as MapQuest (http://www.mapquest.com), shows that this is a real address. Searching for the person’s name in this city using http://people.yahoo.com, or a similar service, shows that a person by this name does live in this city. I have chosen to truncate the last name to protect their privacy. The address returned does not match the one in the record, but looking through Google search results, I can see a clear connection between this person and this very specific neighborhood of Philadelphia. Perhaps the person used to live at the address in this record.
The piece of data that does not fit properly here is the phone number. The first three digits in a U.S. phone number, after the 1, define the area code. There are plenty of online directories of area codes that will give you the approximate location of that number. In this case, 609 maps to Trenton in the southern part of New Jersey. Trenton is very close to Philadelphia but is a distinct city in a different state. This is not a phone number for a traditional land line in Philadelphia. So that looks wrong. The fact that some people use mobile phones exclusively, coupled with the emergence of Internet telephony, means that it is becoming harder to rely on area codes as a measure of location. But these exceptions are still the minority.
Given the importance of location in commerce, government, and so on, you would think that some enterprising company such as Yahoo! or Google would have built a database that maps IP addresses to cities or regions. Such databases have been built by several companies and research groups, but none of these seem to be very good. The problem is that there is no automated way to generate the location from the IP address. Several efforts have encouraged individuals to register their IP address and physical location in a database, but the amount of data submitted has been disappointing, such that none of the services that I have tried produces an accurate result.
Time Zone
If direct clues about location are not forthcoming, then you may be able to infer something from the time at which an email message was received or that a web site visit was logged. This is definitely a low-resolution method but it can be quite useful in eliminating certain parts of the world from consideration. It is based on patterns of typical human behavior and simple probability.
Around the world, people tend to work during the day and sleep at night. They may well work on their home computers during the evening, but relatively few do so between, say, midnight and 7 a.m. local time. I realize there are many exceptions to this rule, but it applies to most people.
You can combine that pattern with the time zones used around the world to assess where a message might have come from. Each standard time zone represents a range of longitude values that cover 1/24th of the Earth’s surface. Time zones tell us nothing about latitude.
For example, I live on the West Coast of the United States and my father lives in the United Kingdom, in a time zone that, for most of the year, is eight hours ahead of me. My father is typically up and about between 8 a.m. and 10 p.m. So if he sends me an email, I would expect it to arrive between midnight and 2 p.m. I would be surprised if it arrived outside that range and might question its authenticity.
To demonstrate that this pattern applies beyond my father, I extracted all records in my web server logs that originated from IP addresses that are managed by BT, a leading ISP in the United Kingdom. Restricting the data to this one ISP ensured that all activity came from within the same time zone. Figure 9-1 shows the distribution by hour at which those visits occurred, mapped back to U.K. time. This fits well with what you might expect, although there are clearly quite a number of night owls.
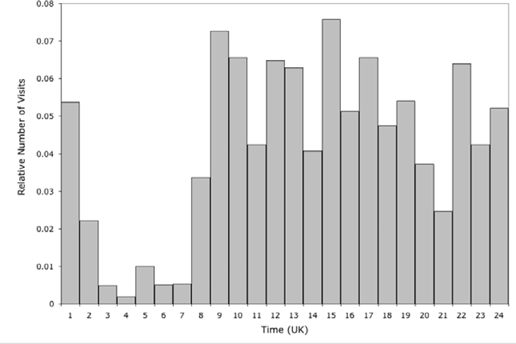
You can use this pattern in a broader sense to assess where a message of site visit might have come from or, more realistically, where it probably did not come from. For example, a timestamp of 3 a.m. local time in Seattle is very unlikely to have come from someone in the United States. Even on the East Coast, that is still only 6 a.m. That leaves most of the world, from Europe through to Japan, as possible countries of origin, but in combination with other information, this can be a useful technique.
Language
Sometimes insight into the person responsible for a message or web site can come from the language they use to express themselves. Part of this is glaringly obvious. If someone sends me an email in Korean, then it is a good bet that she is Korean. But in the case of English, the most common language used on the Internet, you cannot assume that to be the author’s native language.
But careful examination may reveal clues about that language. In most cases, these will add weight to other clues about location and nationality. In others, they disagree with other evidence, suggesting that the author is using a computer in a foreign country or that he is a resident in that country.
Email is usually the richest source of this type of clue. Here you
want to look at the headers Content-Transfer-Encoding and Content-Type. These occur in the main block of
mail headers or in each block of a multipart message. Here is a simple
example:
Content-Transfer-Encoding: quoted-printable
Content-Type: text/html; charset="iso-8859-1"The Content-Type header is the
more important of the two, but it helps to know a little about content
encoding first.
The original specification for email was only set up to handle the
first 128 characters of the ASCII character set, which can be encoded in
7 bits. That was fine for basic messages in English or languages that
used this basic character set. But for languages with even a few special
characters, such as a German umlaut or French accented characters, the
specification was too rigid. The solution was to encode the additional
characters using a pair of characters from the 7-bit alphabet along with
a special character, the equals sign (=), which told email software where these
special codes started. This type of encoding is called quoted-printable and is very widely used in
email today. Mail readers handle it transparently but it makes things
difficult for anyone looking through the source of a message, as this
example of some encoded Korean text illustrates:
<TITLE>=C3=BB=B1=B9=C8=AF<br>*** =C0=CC=B9=CC=C1=F6=BA=B8=B1=
=E2=B8=A6=B4=AD==B7=AF=C1=D6=BC=BC=BF=E4 ***<br>***=C0=CC=
=B9=CC=C1=F6=BA=B8=B1=E2=B8=A6=B4=AD=B7=AF=C1=D6=BC=BC=BF=E4=
***<br></TITLE>The Perl script shown in Example 9-1 will convert quoted-printable text into plain ASCII, as far as it can. Decoded characters that are not in the ASCII character set will not be displayed, so use the script with caution. It does help you read an otherwise indecipherable message. This type of encoding can be used as a form of obfuscation, such as those described in Chapter 4, but in most cases it is used legitimately for handling international characters.
#!/usr/bin/perl -w
if(@ARGV > 1) {
die "Usage: $0 <mail file>
";
} elsif(@ARGV == 0) {
$ARGV[0] = '-';
}
my $lastline = '';
open INPUT, "< $ARGV[0]" or die "$0: Unable to open file $ARGV[0]
";
while(<INPUT>) {
my $line = $_;
$line =~ s/=([0-9A-Fa-f][0-9A-Fa-f])/chr hex $1/ge;
if($line =~ /=$/) {
chomp $line;
$line =~ s/=$//;
$lastline .= $line;
} else {
$line = $lastline . $line;
print $line;
$lastline = '';
}
}
close INPUT;A more recent alternative to quoted-printable uses all 8 bits in a byte to
carry information. This encoding is more compact and allows you to read
the source for an email message in the native alphabet, given an
appropriate mail client.
Content encoding lets you transfer international characters via the ASCII-based mail protocol. But if you are to get your message across, you need to tell the receiving mail client what language those codes represent. That is defined in the Character Set, also known as the Code Page. All this machinery falls under the term Internationalization. Be very grateful that other people have figured out how to do this, so you don’t have to! Fortunately, we are only concerned with character sets, although that is complicated enough.
A character set is basically a lookup table that maps a code into a font character. Modern mail clients come with a collection of these sets and the ability to display them. A mail message that wants to display German characters, for example, will encode those characters and include a mail header that specifies which character set should be used.
There are a lot of character sets. Many more, in fact, than there are languages in the world. You can learn more about them from this online tutorial http://www.w3.org/International/tutorials/tutorial-char-enc/, and see a list of them at http://www.iana.org/assignments/character-sets.
The character set that should be used with a specific email
message is defined in the charset
attribute of the Content-Type
header.
Content-Type: text/html; charset="iso-8859-1"
Probably the most common character set used is iso-8859-1, which covers what linguists call
the Latin alphabet. This covers all the characters in the English
alphabet and most of those needed to represent the majority of Western
European languages, as well as Swahili and Afrikaans. More interesting
from the forensics perspective are those for other alphabets such as
Cyrillic, Arabic, Hebrew, Korean, and so on.
If your language does not use the Latin alphabet, then you will
most likely set your operating system to use the appropriate character
set. When you send an email message that set is defined in the Content-Type header. Most character sets can
represent the core English alphabet in addition to their own characters.
So you often find English text displayed in one of these alternative
character sets. By looking for that mismatch, you may be able to
identify the native language of the author. This pair of headers, taken
from a phishing email, is a good example:
Content-Transfer-Encoding: Base64
Content-Type: text/html; charset="windows-1251"Decoded from its Base64
representation, the content was a message in English that appeared to
come from a bank. The character set is defined as windows-1251. Microsoft has defined a number
of their own character sets; this one happens to be used for Cyrillic
alphabets. That is a strong indication that the author speaks one of the
Slavic languages, such as Russian, Bulgarian, Ukrainian, and so forth.
Software used to create web pages will also define the appropriate
character set, typically as a meta
tag. In these three examples, the first defines a Cyrillic character set
followed by two variants of the Korean alphabet.
<meta http-equiv="Content-Type" content="text/html; charset= iso-8859-5">
<meta http-equiv="Content-Type" Content="text-html; charset=ks_c_5601-1987">
<meta http-equiv="Content-Type" content="text/html; charset=euc_kr">There are so many character sets in use that I can’t list them all here. Running a Google search on the name is probably the easiest way to find out more about a specific set.
Interestingly, some of the unusual sets that I have encountered
turn out to be bogus. iso-4238-5,
iso-7981-6, iso-2426-6, and iso-9110-9 do not match any character set in
any list that I can find and produce no hits with Google. They all
occurred in spam emails, so they may have been placed there as a way to
avoid spam filters. However, they may do the spammer more harm than good
in that they could serve as distinctive signature strings for this
source of spam.
If you have looked at much spam, you will be familiar with the
poor usage of the English language in many of them. This alone may
indicate a source outside the main English-speaking countries, but
trying to infer any more detail than this is effectively impossible.
However, if you are able to access the source code of a script, then you
may get lucky. Assuming that no one else will look at their code,
programmers may be tempted to use variable names and strings in their
native language. Example
5-4 illustrates this with the use of the word “parola,” in place
of “password,” suggesting that the author is Italian. The U.K. Honeynet
Project have identified a Romanian connection to a script they
uncovered, based on the variable names $mesaj and $muie (http://www.honeynet.org/papers/phishing/). Such examples
are rare but are very rewarding when you find them.
Expertise
Assessing the expertise of the person responsible for a scam is extremely subjective and usually not possible. But you may encounter clues that offer a glimpse into this aspect.
If you observe a series of scams that are clearly related, then you might want to look at the timeline of events that occur in each of them. A professional con artist is going to set up a scam, announce it via email, collect some data, and then shut it down quickly. In many cases, a series of scams will be run back to back in order to maximize the return and minimize the risk of being caught. But if the timeline is spread out over weeks or months, you might infer that the author is less experienced. Similarly, this might suggest someone working alone rather than as part of an organized gang.
Mistakes made in the setup of a web site suggest inexperience on the part of the author. The first case study in Chapter 11 serves as a good example of this.
If you are fortunate enough to access the source of server-side scripts on a web site, then you may be able to assess the author’s level of programming skill. In particular, it may reveal whether the script is the work of the scammer or whether it is part of a distribution kit, as was the case with the PHP script shown in Example 5-4 in Chapter 5.
One of the best indicators of expertise is whether the web site has been set up on its own server or been surreptitiously inserted into an existing site. The former implies that they have the resources needed to set up a server and the confidence that they will not be revealed. The latter requires that the scammers have the skills necessary to break into someone else’s server, although the widespread availability of scripts to exploit known vulnerabilities challenges that assumption.
Criminal or Victim?
It is critical that you determine whether a web site associated with a scam is the sole work of the con artist, or whether a legitimate and innocent site has been hijacked . I would estimate that one-third of the phishing sites that I look at have been hijacked. In almost all of these cases, the owner of the legitimate site is completely unaware of the attack until their ISP notifies them or closes the site down.
The telltale sign of a hijacked site lies in the URL for the first web page of the scam. If the site is under the complete control of the scammer, then the URL will typically point to a page at the top level of the document tree, or perhaps one level down from it. On the other hand, the scammer will try and hide the page within the existing document tree so as to avoid detection by the owner. Sites such as the ones listed here are often located several levels down the tree and often include a directory name that begins with a period. By default, these are hidden from a basic Unix directory listing and from a web index list. The first two of these examples use dot directories, whereas the last two bury their content in directories that are commonly found on Linux systems. All appear to be hijacked servers.
In contrast, if the scammer owns the site, then there is no need for this subterfuge, as these examples illustrate:
Hardware and Software
In Chapters 5 and 6, I explained how information about operating systems and software components is revealed in the HTTP headers that are exchanged between the browser and server during a standard web transaction. The version numbers for each component can offer insight into how recently a computer has been updated. They also have the potential to advertise security vulnerabilities to would-be attackers.
While those data will not tell you anything about hardware , you may learn something by looking at the hostnames of machines. Reverse DNS lookups on home computers will often reveal the type of Internet connection they use. In these four examples, the first two are clearly connected via cable modems, whereas the third uses DSL. You can assume the fourth uses DSL as well, since this ISP offers only this type of connection.
CableLink44-##.INTERCABLE.net
modemcable077.56-###-###.mc.videotron.ca
DSL217-132-###-###.bb.netvision.net.il
h-64-105-###-###.sttnwaho.covad.netIn some cases, a hostname can tell you something about the network
of which it is a part. Network administrators often name machines
according to a defined scheme. This helps them track their inventory and
can help in troubleshooting. For example, one of my collaborators has
the machine name HPEDY2K0112. If I
knew nothing about this person I might guess it was running Windows 2000
from the Y2K reference, and I might guess that it was machine ID 112 on
that network. This person works in a Pediatrics Department at a
hospital, which explains the HPED part of the name. Looking at just this
one example, I now know the naming convention used throughout this
institute and have an estimate of how many machines are in this
department. Embedding information in hostnames in this way may be
convenient but it can backfire on you.