
In the narrow sense of the word, a database is a collection of information. In a broader meaning of that term, database management system (DBMS) is what we usually think about when we talk about “database ” - a system providing means for manipulating databases to define, store, manage, and retrieve data.
Although many developers still consider relational database to be the “golden standard,” they are just one phase in the history of data persistence solutions. This chapter will go over a brief historical overview of DBMS and their origins, development, and produced solutions. As you will see, relational databases emerged as a solution to one set of problems. In the same way, engineers created NoSQL databases to solve the next-generation set of challenges.
Finally, we will introduce RavenDB as a second-generation NoSQL database and look at its origins, history, and some of the features that make RavenDB an excellent choice both for small projects and large enterprise systems.
A Brief History of Databases
Since the first days of computing , machines have produced computation results and persisted them. Over time, different solutions for storing data emerged. Still, all these systems were tightly coupled to hardware and operating system to maximize the speed at the expense of flexibility and standardization. As hardware continued to evolve, this compromise was increasingly unnecessary, and many general-purpose DBMS emerged. One of the first such systems, Integrated Data Store (IDS) , was developed by Charles Bachman in the early 1960s, using the Navigational Database Model.
In June of 1970, Edgar F. Codd published the seminal paper “A Relational Model of Data for Large Shared Data Banks,” where he introduced the Relational Database Management System (RDBMS) . The importance of his groundbreaking idea lies in the concept of describing data only with its natural structure, avoiding the need to superimpose any additional structures for low-level machine representation. This high level of data representation provides a basis for high-level data language, giving such programs independence from low-level details of machine representation and RDBMS internal data organization.
Unlike the navigational approach that required programs to loop to collect records, Codd’s solution provided set-oriented declarative language. This approach led to the birth of Structured Query Language - SQL - in 1974. Following this standardization, Oracle released the first commercial implementation of SQL in 1979.
A landmark year for the relational model was 1980 when IBM released their product for mainframes, and smaller vendors began selling second-generation relational systems with great commercial success. During the 1980s, RDBMSes finally came of age and established themselves as the first choice for large datasets typically present in government agencies and financial institutions. Furthermore, relational persistence became a default pick by developers around the world.
Problems with Relational DBMS
Relational databases work best with structured data stored in well-organized tables. For unstructured data, tables with fixed predefined schema are not the best choice.
Users can scale a relational database by running it on more powerful (and expensive) servers. This approach is “scaling up” and is feasible up to a certain point. After that, a database must be distributed across multiple servers – “scaling out.” Relational databases are inherently single-server databases, and distributed solutions are not elegant and seamless.
Relational databases do not natively support data partitioning and distributed setup. ACID transactions that are the basis of RDBMS are fundamentally clashing with distributed computing.
Impedance Mismatch
When developing computer software , developers are modeling data structures that represent an abstraction of the real-life domain. These models (which are part of objects in object-oriented languages) are nonlinear and almost always contain complex constructs like collections of primitive values or nested objects containing other primitive values. On the other hand, many popular relational databases cannot store anything beyond scalar values (like numbers and strings). As a result, relational databases cannot directly store and manipulate your objects and data structures. This incompatibility is a very well-known phenomenon and has been named impedance mismatch .
Before you can store your objects into a relational database, you need to transform them into a set of structures matching your RDBMS schema. And the other way around - data in tables and rows need to be manipulated and reshaped to populate objects. So, storing things into a relational database and fetching them again require a process of two-way translation.
This translation occurs between two models - your (usually object-oriented) domain model and tabular model intended for saving into your database.
Hence, developers need to create an additional data model and provide a bidirectional translation service. Also, every time they make corrections or changes to their primary domain model, they need to update this translation logic. Modeling twice and maintaining translation service are a nontrivial task that will make changes harder, and that will make you move slower in the face of ever-coming change requests from your customers.
Object-Relational Mappers
ORM is abstracting away RDBMS details, so over time developer inevitably starts thinking about the database as a collection of data in memory.
Generated SQL statements are inferior to handwritten SQL.
There is an inevitable overhead of ORM.
Initial configuration of ORM can be complicated.
Object/Relational Mapping is the Vietnam of Computer Science. It represents a quagmire which starts well, gets more complicated as time passes, and before long entraps its users in a commitment that has no clear demarcation point, no clear win conditions, and no clear exit strategy
Indeed, over time as your application grows and expands, ORM usage will lead to the accumulation of antipatterns.
Select N+1 is just one of those antipatterns. Your code will first fetch N entities from the database, then iterate over this collection, making additional calls for every object to bring other referenced things. A typical example would be a web page where you are rendering the list of articles. Each of these articles has comments, and you need to make an additional call to the database to fetch the latest comment to show along with each piece. Furthermore, you would like to display the location of the comment author. As you can see, there is a cascading set of parent-child relations, and in every step, you are accessing the next level, descending hierarchy, and making more and more calls.
Normalization
Normalization is a modeling technique that is an essential part of Codd’s model of relational databases. In the early 1970s, storage was expensive, and eliminating data redundancy was a critical design factor for a database system designer.
Codd defined first (1NF), second (2NF), and third (3NF) normal forms as a theoretical basis for best practices of data modeling. With the application of 3NF principles, you will eliminate redundancy by breaking records into their most atomic form, store those pieces in separate tables, and then relate them via Foreign Keys (FK) .
FK is nothing more than a pointer. For example, when storing customers in the Customers table, you would separate their address and keep it in the Address table. Then, you would create FK to connect these two tables to establish a relationship between the row in the Customers table and the row in Address table containing the customer’s address.
After developing a concept of normalization to eliminate data redundancy, Codd constructed a mathematical theory of normalization and provided theoretical guarantees about 3NF providing data consistency and preventing anomalies when inserting, updating, and deleting rows.
Today, storage is cheap. Not only that, your server’s RAM will most likely have dozens of gigabytes at your disposal, usually in the range of your database size. Good DBMS will detect this and optimize it by loading large parts of your database to working memory. So, over time, redundancy faded away as a motivation for normalization, and today you will hear relational database proponents speaking about 3NF only in the context of database consistency.
However, normalization leads to several problems, and two of them are major ones.
The first challenge is related to projections . Every time you need to display a web page that contains complex data, you will have to create a projection – a combination of rows from different tables. For example, to show an invoice, you will have to combine data from several tables, including Invoices, Customers, Addresses, Products, and Employees. Joining five tables is not a demanding operation. Still, once you load your database with tens of thousands of invoices and when you start creating aggregations that are answering questions like “what are the top 5 countries where we export to,” you will notice performance degradation of your RDBMS. Hence, projections in relational databases are putting a load on the developer and on the database itself.
A second major problem of normalization is temporal snapshots . As we already mentioned, RDBMS are priding themselves with a solid theoretical background that guarantees that data will not be corrupted. However, a straightforward example will show you how normalization is fragile in the light of changes that your data undergo over time. Returning to the story of invoices modeled with a normalized approach, we can see that Invoices are residing in one table, pointing to the Companies table. Further, Companies are related to the Countries table that contains a list of all countries. This way, Invoices are related to Countries via Companies. Now, imagine that Company relocates from London to Berlin – you will go into the Companies table and change FK related to the Countries table to point to the row containing Germany.
This simple change should not have dramatic consequences. However, due to normalized modeling, the modification you just performed has a rippling effect . Although you did not touch Invoices in this process, they are affected since they are related to the Company that changed address. As a result, next time you repeat that aggregation, “what are the top 5 countries where we export to,” you may discover that the United Kingdom is not there anymore. In other words – by making a simple change to the address of one Company, you introduced data corruption on a historical level.
Normalization is incapable of modeling temporal dependencies of this kind. To store a snapshot of your invoice, you will have to apply the denormalization process . Finally, we can conclude that, instead of bringing promised consistency and validity of your data, normalization will corrupt your historical data.
Modern Web Applications
In the 1970s and 1980s, data arriving at your application was predictable and highly structured. With the emergence of the Internet and the globalization of your user base, things started developing more rapidly. Today, modern Internet applications serve a wide variety of users, offering many services and evolving rapidly. Having hundreds of concurrent users of your application is nothing strange.
Twenty or 30 years ago, you would experience this only with applications deployed to large enterprises. Thirty years ago, you would receive a Requirements Specification document with a precisely defined schema of the data you need to store in the relational database. Then you would apply waterfall methodology, spend months implementing it, and finally release it. Today, you are working in 2-week sprints, with change requests coming merely days after delivering working functionality.
Relational databases, in their nature, were optimized for writing data. Reading data was a secondary priority. Modern web applications will commonly store data once and then request it dozens or hundreds of times before making another write. Data that was disassembled into atomic units and stored over dozens of tables during the writing process now needs to be reassembled again to produce a model for rendering information on a web page. And this is not happening just once. Thousands of visitors to your web application will trigger many such calls.
Rendering modern web pages will generate many requests to the database. These same users who are requesting pages will also interact with your application and generate new data that will be stored. Think about a small mom-and-pop shop two decades ago – they are running one POS, with a number of transactions limited by the physical factors – customers standing in line, one customer at a time. Small shop managed to survive and expand, and it is now online. There are no more limitations of physical nature; they are now in a virtual world where 50 customers can purchase within 3 minutes.
The relational database model was conceived at different times – fewer read requests, more occasional users, highly structured data, and slow pace of changes to your application. You could say that the present situation is the opposite.
NoSQL
Problems we just described grew only more painful over time. As the pace of change requests sped up, as the number of users and amount of data grew exponentially, it was clear that we needed some alternatives. It was evident that RDBMS were not the most suitable solution in all cases and that some systems required different approaches for storing and querying data.
This section will look into the evolution that emerged in the 1990s and 2000s and lead to creating the NoSQL movement. We will examine the origins of NoSQL as a term, the advantages and challenges of such a database, and, finally, the broader impact of this movement on the whole industry.
Origins of “NoSQL” Name
NoSQL databases are a further evolution of databases. You could say that databases you can characterize as “non-relational” existed before the invention of RDBMS. However, the NoSQL movement is not returning to these historical solutions; they represent further advancement in data persistence solutions.
Ironically, the NoSQL acronym was first used as a name of Relational Database Management System built by Carlo Strozzi in 1998. NoSQL name was inspired by the fact that this system was not a database but rather a shell-level tool, with data in regular UNIX ASCII files that various UNIX utilities and editors could manipulate. Hence, the intentional lack of support for SQL as a query language was an inspiration for the name.
Johan Oskarsson was the first to use “NoSQL” that we recognize today. He was seeking a name for a meetup he organized in San Francisco in June 2009. This meetup showcased a number of non-relational distributed databases. In subsequent months and years, the term “NoSQL ” was adopted, but it was never standardized or defined precisely, so we can only discuss some general characteristics exposed by the databases belonging to this broad category.
Why NoSQL?
Web applications emerged, and data started arriving in all forms and shapes - structured, semi-structured, unstructured, and polymorphic. Defining comprehensive schema upfront became almost impossible, or in the best case, such attempts resulted in solutions that were cumbersome to work with and hard for maintenance over the long run.
The cost of storage dramatically decreased. Data duplication on the database level was no longer a determining factor for creating complex and complicated data models. Rather than disk storage, developers and their valuable time became the primary cost factor of software development. Optimizing for productivity instead of storage space was the main driving factor.
Cloud computing rose in popularity in the late 2000s and became a legitimate choice for hosting applications and data. As developers started distributing data across multiple servers, they needed a way to scale out instead of scale-up, make their applications resilient, and geo-distribute data in the proximity of their users.
Agile Manifesto was gaining traction, and rapidly changing requirements were looked upon not as a disturbing factor but as a fact of the developer’s life that needs to be accepted, embraced, and incorporated into the development cycle. Software engineers worldwide started recognizing a need to change their code quickly, and reshaping of persisted data was an integral part of that effort. NoSQL databases found their place in this puzzle as a flexible solution that could provide less painful pivot and remodeling on the fly.
Characteristics
The first and most obvious point is the negation in the name - NoSQL databases are not using SQL, in the sense of being non-relational.
NoSQL databases emerged from the open source community. Although today you can find NoSQL solutions coming from closed-source producers like IBM, Oracle, and Amazon, in general, NoSQL databases are primarily open source projects.
Most NoSQL databases are supporting cluster setup, which has a significant impact on their approach to consistency and data modeling.
NoSQL databases do not have a mandatory schema, so fields in records can be added and removed without a need to define changes in the structures first.
They are based on the needs of modern web applications, where a massive number of concurrent users can store a humongous amount of data that can have different shapes and form.
These are broad characteristics, and due to the heterogeneous nature of these databases, there is a low chance we will ever have a definitive coherent definition.
Additional Advantages
Scaling out - buying more powerful servers as database load increases – known as scaling up - has been a standard approach with relational databases over the years. However, as transaction rates and availability requirements increase, NoSQL databases offer a different solution. Scaling out is the approach of distributing databases across multiple servers or virtualized environments. Most RDBMS requests specialized or expensive hardware to scale up, while NoSQL databases can scale out cheap commodity hardware.
Economics – traditionally , RDBMS has been relying on expensive proprietary servers and storage systems. Most NoSQL databases are open source licensed. Combined with the already mentioned ability to run on cheap commodity servers, even toy machines like Raspberry Pi, the total cost of ownership and cost per gigabyte or transactions per second are much lower with NoSQL DBMS.
Big data - over the last decade , modern applications increased the volume of persisted data immensely. RDBMS capacity has been growing to match this demand, but constraints of specific relational systems became the limiting factor for enterprises. Presently, the capacity of “big data” NoSQL solutions like Hadoop surpasses the capabilities of the most significant RDBMS systems.
Administration - NoSQL databases are, in most cases, designed from the ground up with clear intention to require less attention and administration compared to relational ones. Simpler data models, automatic maintenance, data distribution, and internal reconfiguration based on the environmental factors eliminate the need for a dedicated full-time DBA (Database Administrator). Despite numerous improvements in the manageability of relational systems, organizations using RDBMS still need the expertise of specialized personnel who will install, design, and maintain RDBMS. Of course, NoSQL databases are still requesting a certain level of knowledge from their users. Still, they eliminate mandatory expertise for someone to be able to run an efficient database-powered system.
Challenges
Maturity - RDBMS has been around for over four decades now. They are well developed, mature, and stable, reassuring for most of the users. The mentality of the expression “nobody ever got fired for buying IBM” from the 1970s lives up to this day - RDBMS is perceived as a “safe choice,” and NoSQL is looked upon as gambling with new “cool” technology. From the perspective of many companies, NoSQL is a unique, young technology, cutting edge that may be exciting for developers, but a big unknown in production.
Support - in case of a system failure, competent and timely support is vital for every organization’s business continuity plan. All RDBMS vendors go to great lengths to provide such support. On the other hand, many NoSQL products are open source and lack business entities that offer support options. When they exist, these companies are small startups without global presence, support resources, or credibility of an IBM, Oracle, or Microsoft.
Analytics and business intelligence - data presents a valuable resource for every Company. They are analyzing data, mining, and making conclusions that improve their decision-making processes, efficiency, and, as a result, profitability in the market. Business intelligence (BI) is a strategic area for most companies. Over the years, the primary functionality of RDBMS has been augmented by a rich ecosystem of products offering additional BI services for analysis of the data. It is only recently that NoSQL DBMS started to catch up, offering similar solutions.
Outcome
The emergence of NoSQL databases did not eliminate the need for relational databases. Instead, it helped us reach a nondogmatic and balanced standpoint that there are other legitimate and reliable choices for data persistence.
This mental liberation started in 2006 when Neal Ford coined the term Polyglot Programming . This idea promotes implementing applications in multiple languages, understanding that specific problems could be solved in more straightforward and more convenient ways via different languages. Simply said - different programming languages are more suitable than others in solving particular problems.
Polyglot persistence is a concept that follows the same philosophy. Different situations and circumstances may call for other ways to model and store persisted data. Also, very often, one business domain can be split into multiple subdomains. Various data models might be the best representation of different subdomains. Polyglot persistence philosophy acknowledges this and eliminates compromising on data models to squeeze them all inside just one database.
So, instead of selecting a relational database for your next project as a default solution without too much thinking, you need to consider the nature of the data, business scenarios, and how you plan to manipulate data and then consider the best match among various technologies for persisting data. Consequently, organizations are moving from the concept of the database as an integration point and coming toward application databases, ending up with a mix of technologies that are serving different needs by different applications.
This mental liberation further flourished with the emergence of domain-driven design and microservices, where one solution consists of several databases, which can be a mix of persistence technologies. That way, databases are encapsulating data within applications, and services are performing integration.
NoSQL Database Types
As we already mentioned, various non-relational databases are using different approaches to solving needs for storing and querying data. There are four main types of NoSQL databases, with each type solving a problem that relational databases can’t address adequately.
Key-Value Stores (KVS)
Prominent examples: Redis, Memcached, and CosmosDB
In some scenarios , using a full-blown database with powerful indexing and data retrieval would be overkill. You are looking for a quick and easy way to take an arbitrary piece of information, label it with a key, and store it in the database. Later, when you present a key, the database will deliver you associated value.
Key-value stores are databases, but highly specialized ones, built with just one purpose and deliberately constrained in design and functionality. Some are intentionally minimal, like Memcached, which is not even storing data on a disk. Others, like CosmosDB, added more features over time but are still based around the key-value paradigm.
Overall, key-value stores are intended for elementary tasks like caching or sharing common data between application services. Many relational databases can be used as a key-value store , but they would consume lots of resources and be more inefficient than specialized solutions. You would be overprovisioning resources and power in the same way if you would use an 18-wheeler for grocery shopping.
Document Stores (DS)
Prominent examples: MongoDB, RavenDB, Couchbase, and DocumentDB
Expanding on the capabilities provided by key-value stores, document stores can not only persist and retrieve information but also comprehend its structure. In the terminology of DS, documents are semi-structured data that are representing your business objects. You can index, manage, and manipulate documents based on their internal structure.
DS is aware of your documents’ internal structure, so you can query your business partners by the address city, while KVS would provide just a way to store and retrieve them.
Relational databases force you to artificially split your objects into multiple sub-entities, which are then stored in tables and rows. DS can accept your documents in their natural form, index them, and provide you with means of creating projections producing the same results as JOINs in RDBMS but much more efficiently.
Before storing , your objects will be serialized to some standard format or encoding. Common encodings include JSON, XML, YAML, as well as a binary format like BSON.
Graph Databases (GD)
Prominent examples: Neo4j, OrientDB, TigerGraph, and ArangoDB
A graph is a mathematical structure representing a set of objects in which pairs of objects are related. Graph databases are implementing this concept, treating relationships between entities equally important as entities themself. Hence, GD is suitable for all those business domains where relationships are the crux of your model.
Graph databases are highly specialized NoSQL databases. You could say that they are building on the basis established by relational databases, bringing connections and relations between them to the status of full citizenship in the world of databases. Hence, besides data, GD contains metadata, or “data about data,” and this metadata often matters more than the data itself.
With GD , independently of the total size of your dataset, you can efficiently explore highly connected data, perform searches based on patterns, and isolate your interactions with the data to just a tiny subset.
Wide-Column Stores (WCS)
Prominent examples: Bigtable, DynamoDB, Cassandra, ScyllaDB, and HBase
This category is also known under the name extensible record stores. Similar to relational databases, WCS is using tables, rows, and columns. However, columns are not fixed, and records can have billions of columns if needed. From the perspective of the key-value store, you could say that WCS is a two-dimensional KVS.
Multi-Model Databases
Multi-model databases are not the fifth category of NoSQL databases, but an emerging trend first mentioned in 2012 by Luca Garulli. Starting from Polyglot persistence, he envisioned a second generation of NoSQL databases, where one product supports different data models. This approach would combine the NoSQL ideal of selecting the most appropriate persistence for each subdomain of your application without having several different databases. Hence, you would not compromise in modeling and would end up with just one database to learn and manage.
Database choice is fraught with difficulty and risk since this choice is committed to a particular model upfront. Considering the fast pace of changes modern applications must support, this choice can be easily invalidated by unpredictable future changes.
Going with a multi-model database means that database choice can be less risky. Your database will be able to support you in various circumstances as your data model evolves under the stream of change requests you receive from your customers over time.
RavenDB
In this section, we will introduce RavenDB, a second-generation NoSQL database. You will learn about its history, why RavenDB is a good choice of data persistence for your applications, as well as how to start working with RavenDB in no time.
History
RavenDB was created by Oren Eini, a developer from Israel. In the late 2000s, he was an active contributor on the NHibernate project, .Net port of famous Hibernate ORM, one of the most popular mappers used by developers worldwide. Besides being involved in the open source community, Oren worked as a consultant for companies using relational databases. Being a prolific blogger under the pseudonym Ayende Rahien at https://ayende.com , he recorded various experiences with companies he was helping. It felt like one long Groundhog Day – they all had problems with applications, and canonical RDBMS caused all these problems most of us experienced – lack of indexes, Select N+1, projections that JOINed seven or eight tables… Could it be that so many developers were using relational databases in the wrong way? Or is there something inherently problematic with them? Do you need to be an expert in databases to develop your application swiftly and produce a solution that will be long-lasting and reliable?
It is not uncommon for software developers to observe problems over time, think about them, and become passionate about solving them. You could say that RavenDB was born equal parts from frustration with the present state of database landscape and passion for creating an elegant solution to practical problems.
In May 2010, Oren released version 1.0 of RavenDB . In October, the first commercial installation was secured, and after that, RavenDB started gaining popularity – up to the point when 1 million developers’ downloads were reached in September 2015.
Today, RavenDB is a mature and reliable database, battle-proven from installations on small machines like Raspberry Pi up to clusters consisting of over a million nodes. Let’s look at some reasons that helped RavenDB become such a versatile database.
Advantages of RavenDB
Along with all the advantages RavenDB has as a Document NoSQL database, which we discussed in previous sections, some specifics make it stand out.
Extreme Performance
RavenDB is highly optimized. Even on toy machines like Raspberry Pi 400, you will be able to serve over 2.000 concurrent read requests per second. Commodity hardware will bring you to 150.000 writes/s and 1.000.000 reads/s, and all of that with low latency. Furthermore, your queries will continuously operate over precomputed indexes so that you will get your results blazingly fast.
Fully Transactional
Since the very beginning, RavenDB is offering fully transactional ACID guarantees. Multi-document and multicollection transactions are supported as well, along with cluster-wide transactions. We will cover ACID in later chapters, but now, let’s say – ACID is a bare minimum that any database should guarantee. It will ensure that your data is not lost and that your database maintains its consistency despite all challenges.
Auto Tuning
RavenDB is a grown-up database that knows how to take care of itself. If you try to execute a query without an index that will support it, RavenDB will create an index for you. If one node of your cluster gets slower for some reason, traffic will be redirected to the fastest node dynamically. Your cluster is on constant and ongoing self-monitoring mode. It will track vital parameters like CPU usage or memory utilization and act upon them. Overall, RavenDB is observing its environment and reacting intelligently.
Safe by Default
Encryption - default encryption in transit and optional encryption at rest mean that your data will never be exposed in plain text form to anyone who might listen to the traffic between your application and RavenDB.
Authentication – X.509 digital certificates are used for access control as well as a basis for HTTPS access to the RavenDB cluster.
Limiting the number of database calls per session – too many requests per single database session is dangerous. If developers are not careful, antipatterns like Select N+1 can result in dozens, even hundreds, of calls for fetch data to render just one web page. RavenDB client will try to batch multiple calls whenever possible and throw an exception if you cross the default threshold of 30 calls per single session. However, as you will see later, you can reduce the number of calls to one or two in most cases. This is a significant speedup for your application, and it is lowering the load on your database.
High Availability
RavenDB is an inherently distributed database. Even if you are running just one node, it will be treated as a cluster of one node. Clusters usually consist of several nodes, most commonly three. Such a multi-node setup will provide several exact copies of your database , and as long as just one node is up and running, your data will be available.
Topologies
RavenDB clusters can scale from one node to several million nodes. Your setup can include cloud hosting, local machines, and all kinds of heterogeneous arrangements. Finally, various star-shaped topologies are supported with a central location performing two-way complete or filtered replication with millions of edge locations.
How to Start?

A screenshot of the Raven D B studio displays 5 tabs on the left and 5 small windows on the right. The windows are titled, traffic, databases, C P U, and memory, indexing, and storage. The tabs include databases, server dashboard, cluster dashboard, manage server, and about.
RavenDB Playground Server Studio
What you are now looking at in Figure 1-1 is RavenDB studio , a web application for managing your RavenDB server. As you can see, there is no need to install anything – your server is providing you with a web application accessible from all major web browsers.
Playground Server is a public instance of RavenDB, open for everyone without a need to authenticate. You can create new databases, play around with them, and evaluate how RavenDB works.
Do not use Playground Server for anything but evaluation of RavenDB. Do not store any sensitive data in any of the databases. They are unprotected and open for anyone in the world to access, see all the databases, and read and modify data. Also, all databases are wiped out periodically.
Docker will fetch the latest RavenDB image and will spin up a new container to run this image. Now, if you open http://127.0.0.1:8080/, you will see Studio in your browser.
You are now running RavenDB in developer mode. There is no authentication nor authorization enforced. Developer mode is the only situation when RavenDB will allow unauthenticated access.
You can also run RavenDB natively on Windows, Linux, OSX, and even Raspberry Pi.

A screenshot of the windows power shell displays the Raven D B console. It has lines of text which display the build version and specification.
RavenDB PowerShell Console in Windows

A screenshot of a window displays the end-user license agreement during the installation process for Raven D B software. There is an accept button at the bottom right corner, to complete the installation.
RavenDB License Agreement in a Default Browser

A screenshot of the Raven D B setup wizard window. It displays two types of security options for the setup, with details for each option.
RavenDB Setup Wizard, the First Step

A screenshot of the Raven D B setup wizard, unsecured mode setup page. It has 3 text boxes labelled, H T T P port, T C P port, and I P address. It has an option below to create a new cluster and 2 buttons labelled back and next respectively are at the bottom.
RavenDB Setup Wizard, the Second Step

A screenshot of the third step in the Raven D B setup wizard, which displays the completed configuration and an option to restart the server or to go back.
RavenDB Setup Wizard, the Third and Final Step
There is just one step, shown in Figure 1-6, needed before you can start working with your local instance of RavenDB under Windows. Clicking on the Restart server button will restart the server and reload your browser window. Finally, http://127.0.0.1:8080/studio/index.html will open, and you will see the same screen from Figure 1-1.
Creating Your First Database

A screenshot of the Raven D B studio displays 5 tabs on the left in which the databases tab is selected. The main page displays a text, that reads no databases have been created.
Creating New Database

A screenshot of a window titled new database displays a filled text box labelled name and 3 options below it with radio buttons. The options include encryption, replication, and path, in which replication is selected. The replication factor on the main page is set to 1.
New Database Dialog
At this point, as shown in Figure 1-8, all you need to do is to enter the name of the new database and click on Create button. Name your new database Northwind, accept all defaults, and new empty database will be created.

A screenshot of the window of Raven D B studio displays a database named North wind. The related information about the database is depicted below it, with settings on the right.
Listing of the Databases
Residing on Node A.
It allocates 65.54 MB on the hard drive.
Contains zero documents and zero indexes.
Uptime is “few seconds.”
Has never been backed up.
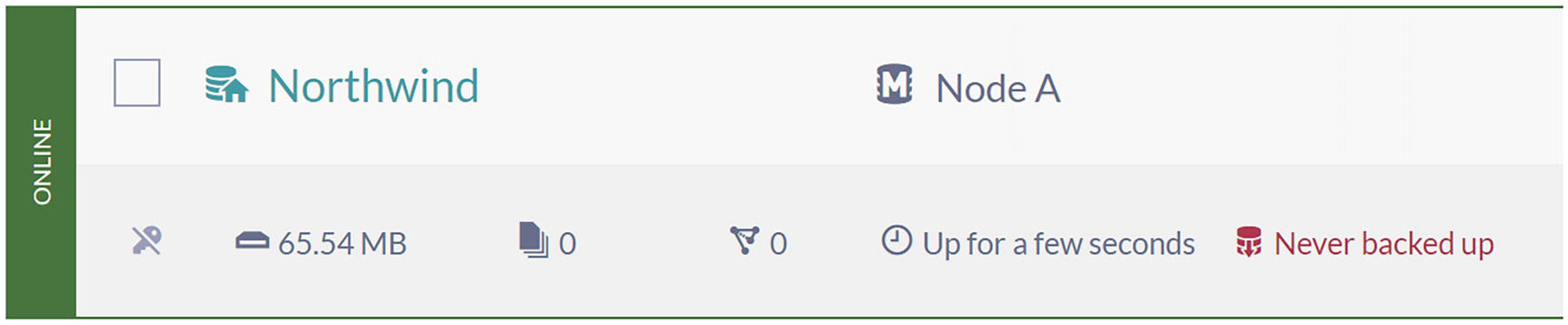
A screenshot displays information about the database as follows. It resides on node A, allocated 65.54 M B, 0 documents, 0 indexes, a few seconds of uptime, and has never been backed up.
Basic Database Info

A window of a Raven D B studio displays the documents page of the North wind database. There are no documents in the database. The column labels of the documents table include I d, change vector, last modified, collection, and a flag symbol.
An Empty List of Documents in the Database
Seeding Sample Data

A window of a Raven D B studio displays 5 tasks on the left, in which create sample data is selected. The selected tab depicts a page of sample data with a button labeled create on it.
Seeding Sample Data into Empty Database
Seeding sample data will only work on completely empty database. If you have even a single document, RavenDB will disable Create button.
Northwind Database

A window of a Raven D B studio depicts the documents page of the database. The list of documents is depicted under the column labels I d, change vector, last modified, collection, and a flag symbol. The collection list and the number of documents in each of them are depicted on the left.
Collections and Documents in the Northwind Database
Collections are one of the basic concepts in RavenDB. They contain documents and are very similar to tables in relational databases. However, there are no requirements for documents in one collection to have identical structures or any schema. Every document belongs to exactly one collection, and you will usually group similar documents in one collection.
The database in front of you is Northwind. It is one of the sample databases Microsoft is shipping with Access and SQL Server applications. Since 1994, it has been used as a basis for tutorials and demonstrations of various features in various database products. The wider community accepted it as an excellent tutorial schema for a small business ERP, and it has been ported to a variety of non-Microsoft databases, including PostgreSQL. Hence, the choice of this data as a sample in RavenDB was a logical one. There is a high probability that an average user is already familiar with a relational version.
The Northwind database contains the sales data for a fictitious company called “Northwind Traders ,” which imports and exports specialty foods worldwide.
Categories (8 documents): Product categories
Companies (91): Customers who buy products from Northwind
Employees (9): Employee details of Northwind traders
Orders (830): Sales order transactions taking place between the customers and the Northwind Traders Company
Products (77): Product information
Regions (4): List of cities divided into four regions
Shippers (3): The details of the shippers who ship the products from the traders to the end-customer Companies
Suppliers (29): Suppliers and vendors of Northwind Traders
Comparing this list with collections in RavenDB studio, you will notice that one of them is missing from this list: @hilo. This collection is a system one, created and maintained by the database. Even though it is publicly exposed, you will rarely inspect its content. Documents you can see inside are used to create unique identifiers for documents in your collections. Also, pay attention to a specific prefix of this collection; its name starts with the “at” sign. This prefix is a standard convention for all properties and names used internally by RavenDB. Even though nothing stops you from naming your properties using the same prefix, we recommend you avoid this to prevent any conflict with system names.
Documents

A screenshot depicts the documents page of Raven D B studio. The page depicts a list of collections on the left, in which orders are selected. In the documents list, orders slash 830 A is selected.
Documents in the Orders Collection

A screenshot depicts a document titled orders slash 830 A. The buttons under the title are labelled save, clone, and delete. The document depicts 33 lines of code in the J S O N structure.
JSON Document
If you have been working with relational databases, this is not a familiar sight. There are no columns. The whole document is one JSON structure. Lines property is an array consisting of JSON objects. Scroll down, and you will see the ShipTo property, which contains a complex nested JSON structure.
Comparing this document to the usual RDBMS modeling, you will find out that we did not have to split it into several pieces to satisfy the tabular nature of relational databases. Company and Employee properties, for example, are references to other documents in this database, but they are not special properties – they are just simple strings.
Document-based modeling is an important topic which we will cover in more detail in the following chapters. For now, feel free to click on other collections and inspect their documents.
Summary
In this chapter, we briefly covered the history of relational databases and their inception, advantages, and some shortcomings of these systems. As a next step in the evolution of data persistence, NoSQL databases emerged. We went over the motivation for creating this new class of databases, some problems they are solving, and their main categories. RavenDB was introduced, and we covered installation steps, creation of your first database, an overview of the sample dataset, and the very concept of JSON documents.
In the next chapter, we will show the data modeling approach with NoSQL document databases, explaining how you can apply them in RavenDB. Additionally, we will also cover techniques for modeling NoSQL document relationships.