
The previous chapter introduced the index, which almost all databases use to speed up and optimize queries. In this chapter, we will show how to take control of indexes. Instead of relying on RavenDB to create them automatically, you can specify them explicitly as “static” indexes. Along with ways to index one or multiple collections, you will also learn how to handle referenced documents and create stored, dynamic, and computed fields. Finally, we will cover techniques to index hierarchical data models in your database.
Static Indexes
In the previous chapter, we saw how RavenDB does not allow queries against raw data. Queries are always executed over indexes, and if you do not have one, RavenDB’s query optimizer will create one for you.
will trigger the creation of the Auto/Employees/ByFirstName automatic index. Once created, this index will remain active after the query results are generated, and RavenDB will use it for all future filtering and ordering queries over the same field.
Querying index directly
Such query will produce the same result as a previous query.
Hence, you can either use from [Collection] form and let the query optimizer choose for you or go with from index '[Index_name]' and take control over the selection of the index used to deliver results.
You can take control even further. Instead of relying on a query optimizer to create indexes, you can define it yourself. Such indexes are called static indexes.
Static Map Index

A screenshot displays 1 query, results with columns preview, first name, and id, save button, search, settings drop-down box with 2 enabled among 4 toggle buttons, play, and delete documents button.
Content of Automatic Index

A screenshot displays a dialog box with save and cancel buttons at the top, a text box for index name, a drop-down button for deployment mode, and a list box for maps placed at the bottom.
Create a New Index Dialog
and you can already see it with Auto/Employees/ByFirstName.
Hence, use Employees/ByFirstName for the name.
Content of Employees/ByFirstName index

A screenshot of the indexes list with 2 sections, companies with 141 entries and employees with 9 entries on 2 sublists, query search, drop-down menu for index status, delete, play, lock, and add new index buttons.
List of Indexes
you will get identical results.
Static Index Analysis
The first argument is a collection name. One by one, the document will be fetched from that collection and passed to the JavaScript function, which is the second argument.
This object literal will be indexing entry.
A simplified version of the Employees/ByFirstName index
Expanding Map Index
Employees/ByLastName index
and will produce results .
Employees/ByFirstNameByLastName index
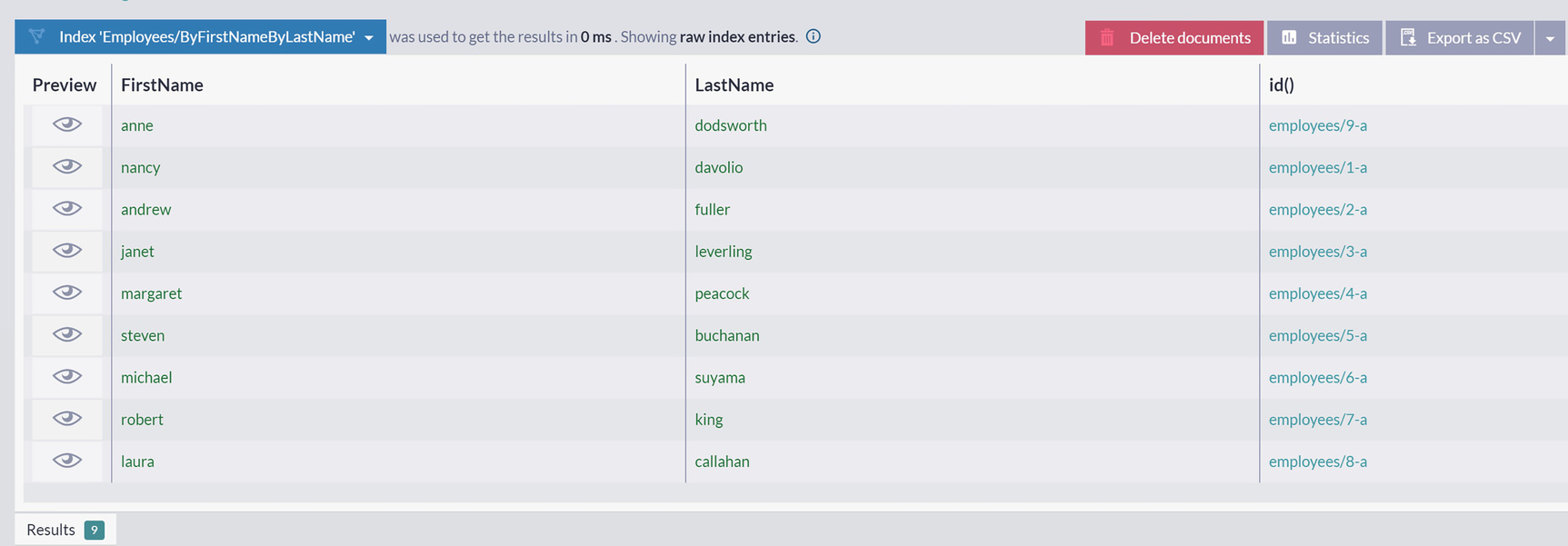
A screenshot of the index employees slash by first name by last name index displays a table of raw index entries with 4 columns and tabs on top namely delete documents, statistics, and export as C S V.
Raw Content of Index Employees/ByFirstNameByLastName
This way, you can use just one index to cover multiple fields of documents in one collection.
Indexing References
Order orders/830-A
Orders/ByEmployee index

A screenshot of the index terms for orders slash by employee with 2 sections, i d and employee that has 9 loaded data, employees slash 1-a to 9-a.
Index Terms for Orders/ByEmployee Index
However, it would be much more natural if you could query by Nancy Davolio’s first name – that would not force you to check what her ID is. That would require an index to read an employee’s id, load that document, and read FirstName property.
Orders/ByEmployeeName index
The first argument is the document’s ID, and the second one is the document’s collection.
This index will react to changes over Orders document collection and recalculate. Every time you call the load function in an index, RavenDB will note that your index depends not only on the collection it is indexing but also on the collection from which referenced documents are loaded. Since we are loading Employee documents, changes to that collection will also trigger updates to the index .
Stored Fields
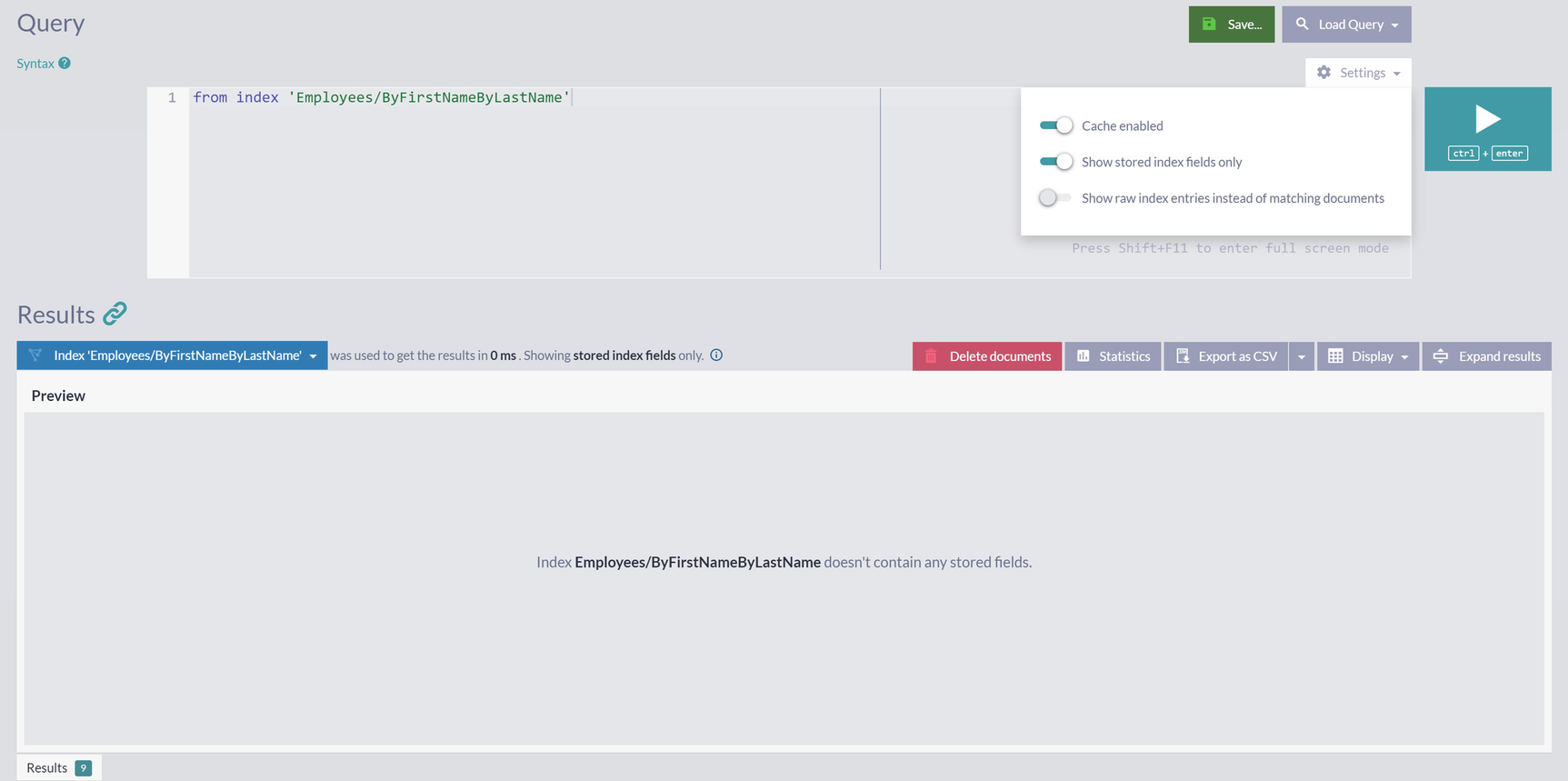
A screenshot displays a query, a settings menu with 2 enabled among 3 toggle buttons, search query, and save and play buttons. The results panel displays no data during the preview of stored index fields.
No Stored Fields for Index Employees/ByFirstNameByLastName
the database engine will first perform filtering based on an index, which will result in single ID employees/1-A. After that, the engine will make one more round trip to the storage to fetch this document and read its FirstName and LastName properties.
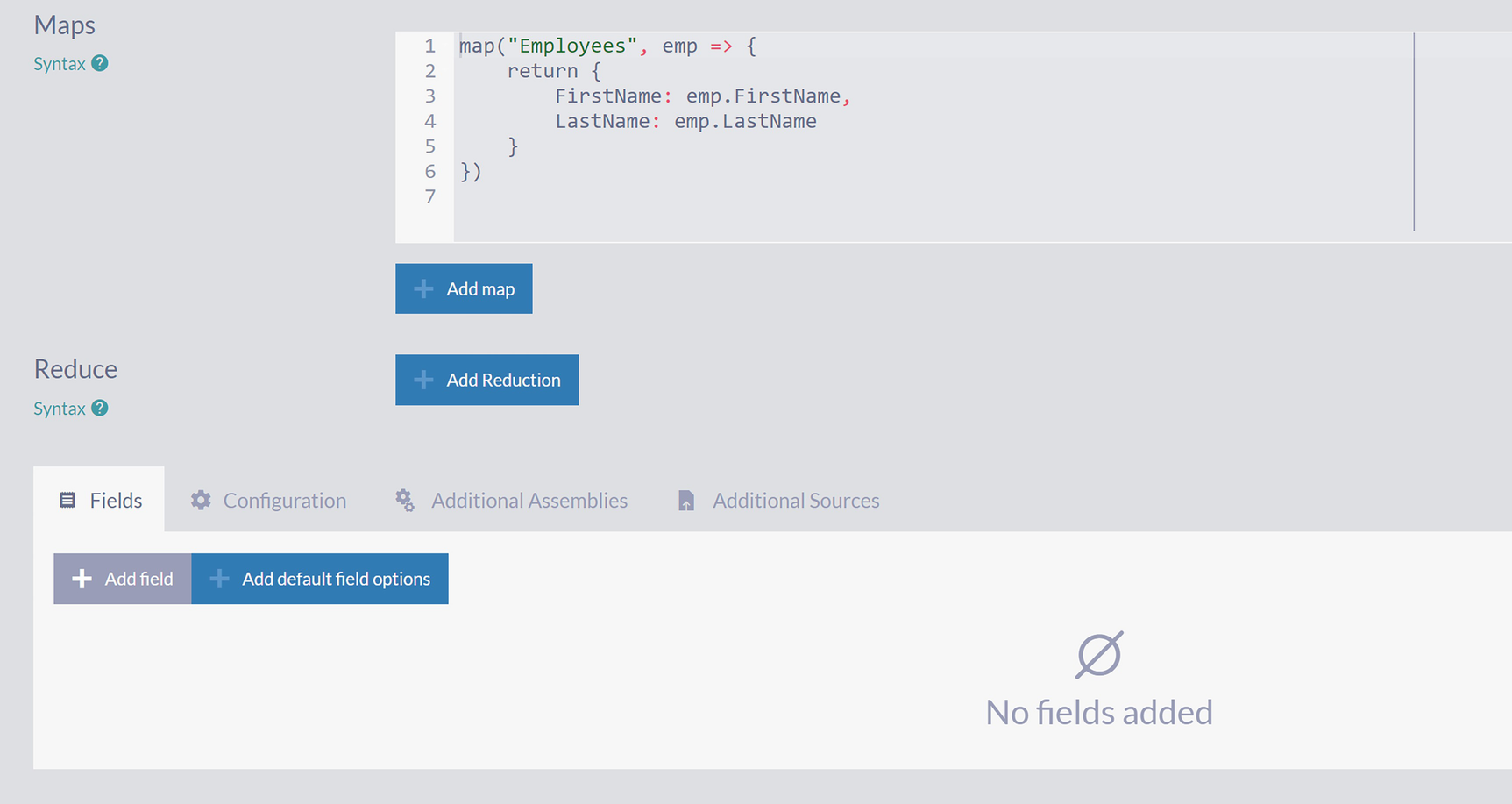
A screenshot with 2 sections, maps with 6 lines of syntax and buttons add map and add reduction and reduce with 4 tabs and buttons add field and add default field options in the fields tab.
Fields Tab on Edit Index Page
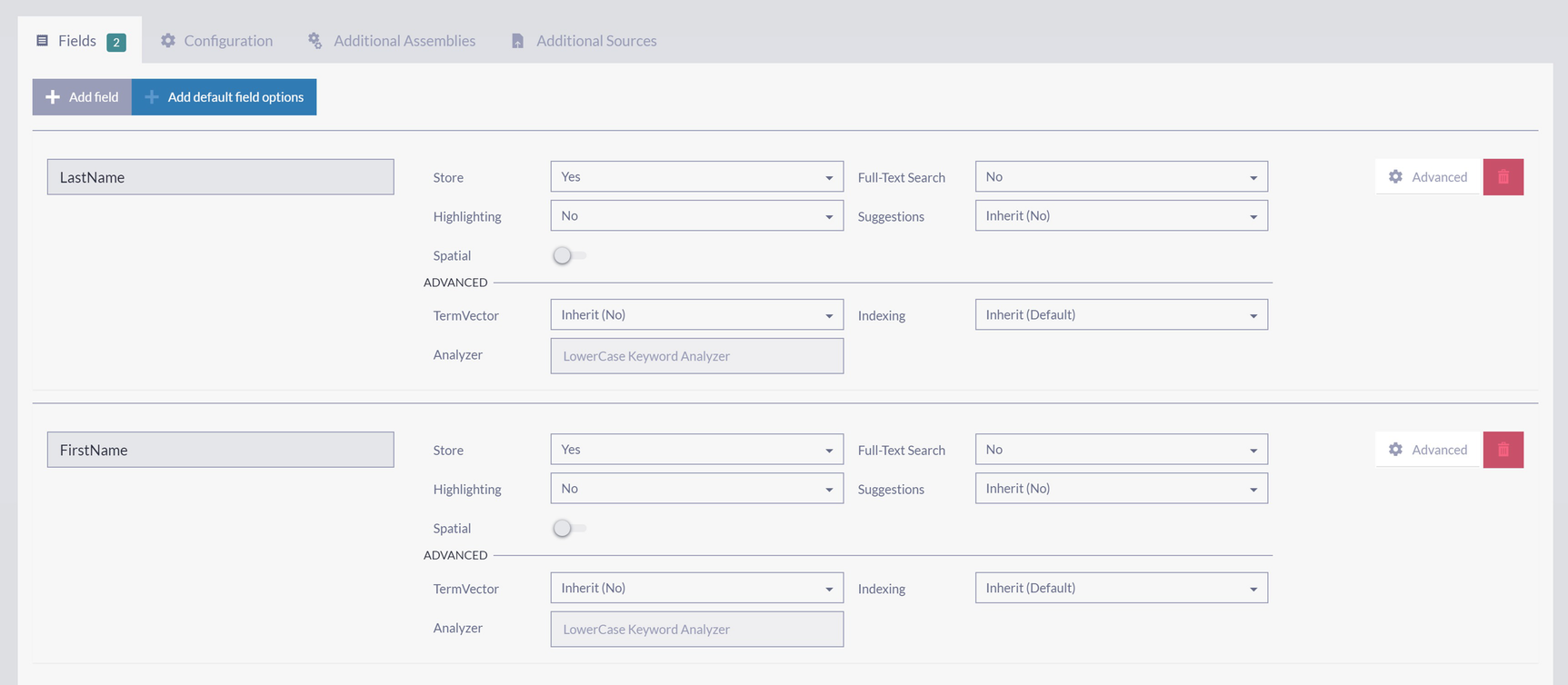
A screenshot with 4 tabs namely fields, configuration, additional assemblies, and additional sources. The fields tab has 2 buttons, add field and add default field options, to add details under last name and first name.
Adding FirstName and LastName as Stored Fields in the Index
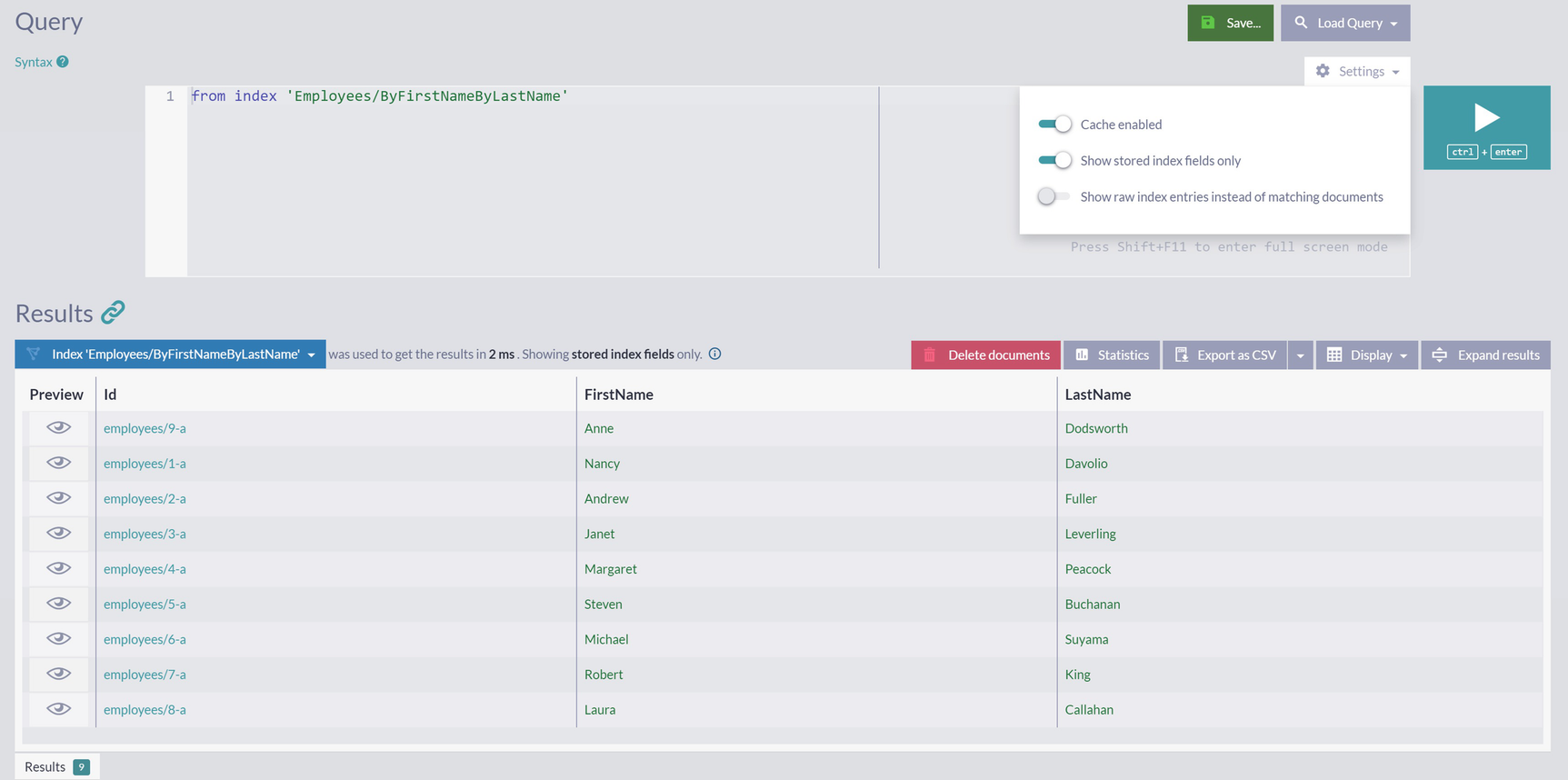
A screenshot displays a query, settings drop-down box with 2 enabled among 3 toggle buttons, search query, save, play, and delete documents buttons. The results panel displays a table with 4 columns.
Stored Fields for Index Employees/ByFirstNameByLastName
As a result of the change you just made, the database engine will be able to create projections consisting of FirstName and LastName with just one trip to the storage. Index entry fetched via filtering operation will contain these two fields, which will be available immediately.

A screenshot of the storage report displays the allocation details and various fields of the index storage when the icon Stats is clicked.
Storage Report
You can add or remove various fields from the index storage and check the impact of your changes in the Storage report.
Computed Fields
So far, you have created several static indexes that include the value of the fields. In some cases, like the Employees/ByFirstName index, the field value is read directly from processed documents. In others, like Orders/ByEmployeeName, a referenced document was loaded, and then the content of its field was indexed.
However, it is also possible to create index fields containing a value that does not exist in any documents. Such fields are called computed fields. We usually calculate their value based on one or more other fields.
Index Orders/ByEmployeeNameByTotal with Computed Field Total
This is a relatively standard piece of imperative JS code. It iterates over Order.Lines array, and for every line, the total is quantity * price * (1 – discount). Line totals are accumulated, and after lines are processed, variable total holds calculated total for Order.
Index Orders/ByEmployeeNameByTotal with functionality extracted into JS function
Index Orders/ByEmployeeNameByTotal with declarative-style JS function
Index Orders/ByEmployeeNameByTotal expanded with business rules
We are giving a 10% discount to orders shipped to Poland, and that rule is embedded into the index as part of a computed field calculation .
to get all orders with a total monetary value of over 15,000.
So, with computed fields, you can create new properties calculated on existing properties with the application of possibly very complex logic. You can offload a significant portion of your business logic to a database if needed .
Dynamic Fields
As we mentioned earlier, RavenDB is a schemaless database. You do not have to define schema upfront, and you will be able to accept various semi-structured or even unstructured data. The moment you know least about your domain is the very moment when the project starts. The ability to postpone decisions about data structures you will use is a significant advantage. It will not just speed up development, but it will also provide much-needed flexibility as additional requirements arrive along the way of implementation and inevitably after you launch your product .
In other cases, you have very well-defined requirements, but the data you need to store inside a database is inherently heterogeneous. A typical situation is a need for globalization of your application. Expanding your business to a new part of the world often means learning about concepts you forgot to cover and modifying your application and database to take them into account.
Take the concept of an address as an example. Various countries around the world have different ways of addressing locations. It is enough to read multiple administrative division terms for countries worldwide – state, county, province, district, prefecture, emirate, canton, municipality, circuit, raion , oblast – to comprehend the full complexity of modeling such heterogeneous data.
Schemaless JSON as a data format for your documents in RavenDB will provide you with much-needed flexibility for expanding entities that you store. However, you need to propagate these changes to queries and the application itself. And, since queries are using indexes, you will also have to expand the RavenDB index definition. Once it’s changed, this will trigger recomputation of the whole index, which can be both computation-heavy and time-consuming.
Employees/DynamicFields index
Address literal of employees/8-A
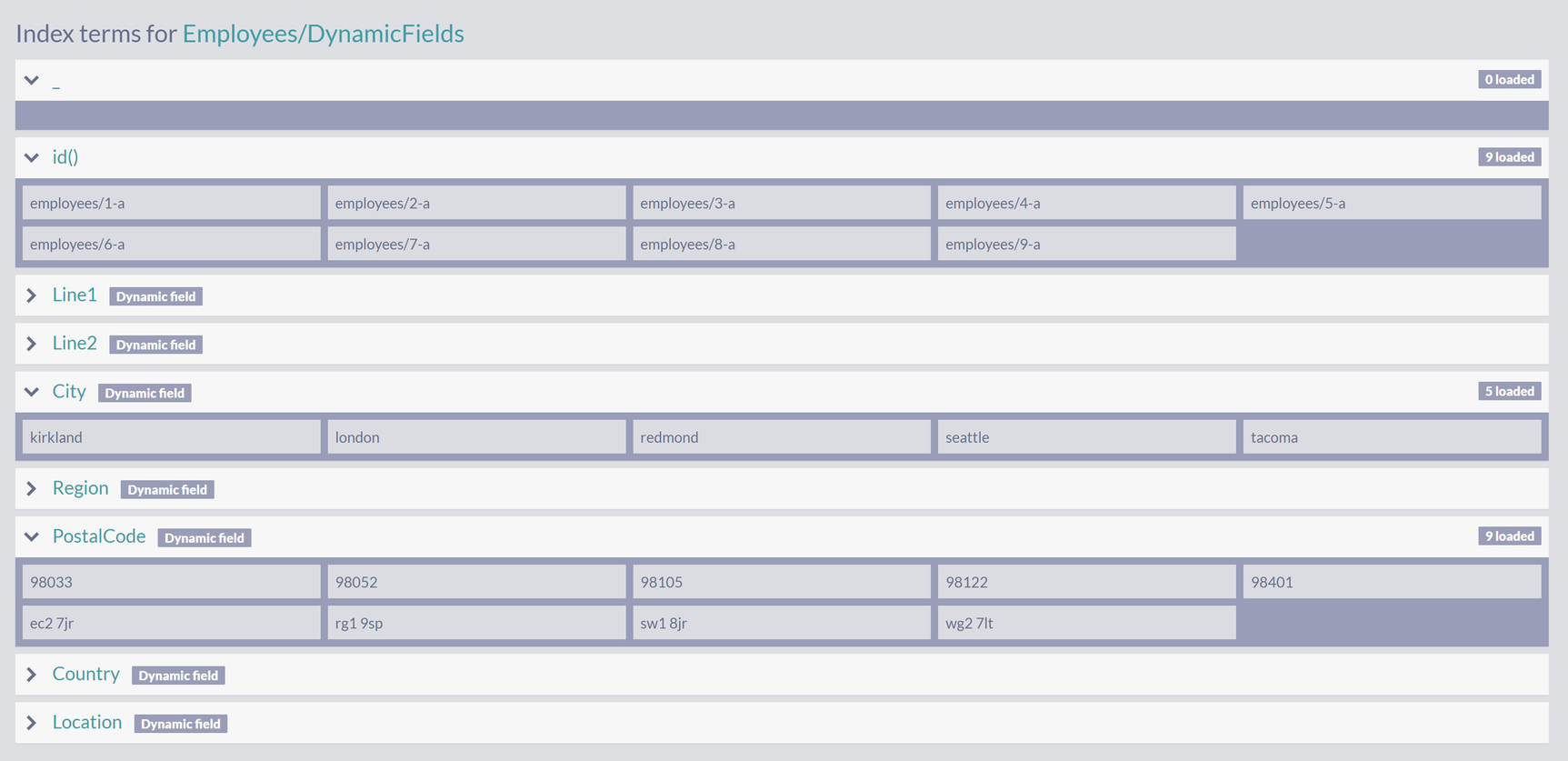
A screenshot of index terms for employees slash dynamic fields namely i d with 9 loaded data, line 1, line 2, city with 5 loaded data, region, postal code with 9 loaded data, country, and location.
Index Terms for Employees/DynamicFields Index
Each property of the address (like Line1, Line2, City, etc.) is one collection of terms. Values of such group are extracted from all occurrences of that property on any of the employee documents.
Underscore as an object literal name is just a convention. Figure 5-11 shows that a collection with the name _ will be created, but it does not have content.
An empty array is defined. The indexing engine will iterate over all address’ properties and add a new dynamic field for every one of them .
You can use it to create a dynamic field name:property.
Note that the CreateDynamicFields function is entirely generic – no exact field names are stated. It can process any object literal passed to it, extract all property names and their values, and create dynamic fields for every property it finds.
After saving changes, verify that a new index term collection with the name Continent has been created.
Overall, dynamic fields are a tool for creating flexible indexes which can process heterogeneous data and, at the same time, adapt to future changes your domain model might introduce .
Fanout Index

A screenshot of the index employees with a checkbox, employees slash by first name, displays 9 entries up to date with normal state, normal priority, and unlocked mode.
Summary for Index Employees/ByFirstName
Summary shows nine entries, one per document. The number of index entries equals number of documents in the collection.
Orders/ByProductName index
Fanout indexes can produce dozens, even hundreds, of entries per document. Index in Listing 5-15 iterates over all lines in every order and creates one indexing entry for each line. Every such entry contains a product name. Hence, for every order document , the index will create as many entries as there are order lines.

A screenshot displays a query from index orders slash by product name where i d = orders slash 154-a. The results panel has a table with 3 columns namely preview, product name, and i d and delete documents button.
Indexing Entries for Orders/154-a
Going back to the index overview, you will see that this index contains 2,155 entries for 830 processed orders.
In the same manner, you can index all documents with embedded values .
Multi-Map Index
Up to this point, all indexes we defined were processing a single collection, loading properties of its documents, and extracting their values into indexing entries. However, it is not uncommon for documents in different collections to have the same properties . A typical example of this would be an address – in our sample dataset, Employees, Companies, and Suppliers all have this property.
RavenDB provides a way to merge these two indexes into one. Such an index is called the multi-map index.
Search/ByCity Index
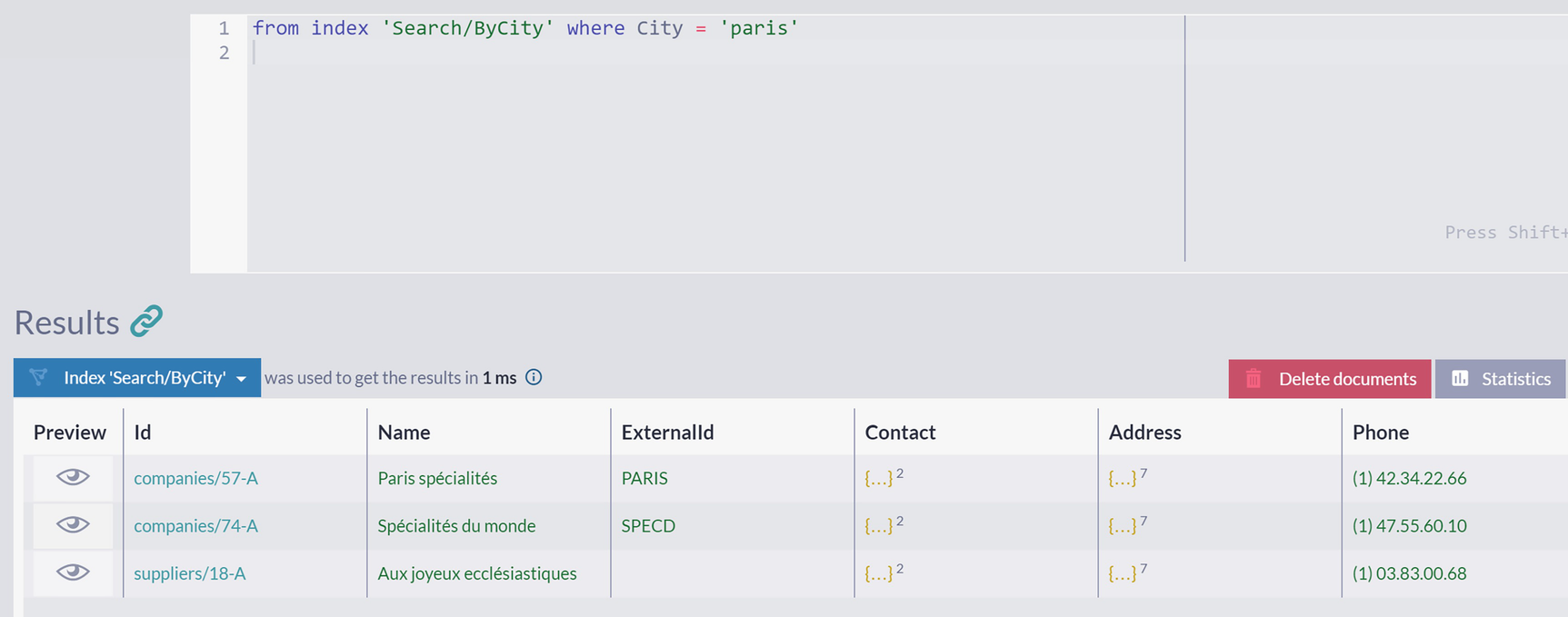
A screenshot displays a query from index search slash by city where city = paris. The results panel has a table with 7 columns, preview, i d, name, external I d, contact, address, and phone number, and delete documents button.
Querying Multi-Map Search/ByCity Index
The results you got are all companies and suppliers located in Paris.
You can expand this index with one more map that would process Employees . We will leave this as an exercise for you.
Indexing Hierarchical Data
Besides simple linear relations, your applications will inevitably need to represent and store more complex setups. One such structure is the hierarchy – chain of documents pointing to the next one sequentially. Typical representatives of hierarchical data are genealogical trees or threads of comments on a blog post.
ReportsTo property of employees/9-A document
Employees/ByReportsToFirstName index
will reveal the structure of Northwind Traders company: Anne, Michael, and Robert report directly to Steven. Everyone else, including Steven, reports directly to Andrew. This hierarchy is also revealing itself in employee titles. Andrew is “Vice President, Sales” and Steven is “Sales Manager.” All other employees bear “Sales Representative” and “Inside Sales Coordinator.”
However, unlike most programming languages, the null reference here will not create any problems. RavenDB will recognize an attempt to load a nonexisting document and handle that gracefully – it will not generate any indexing entries for Andrew. If you check the overview for this index, you will see that it has eight entries for nine processed employees.
Employees/ByManagers index
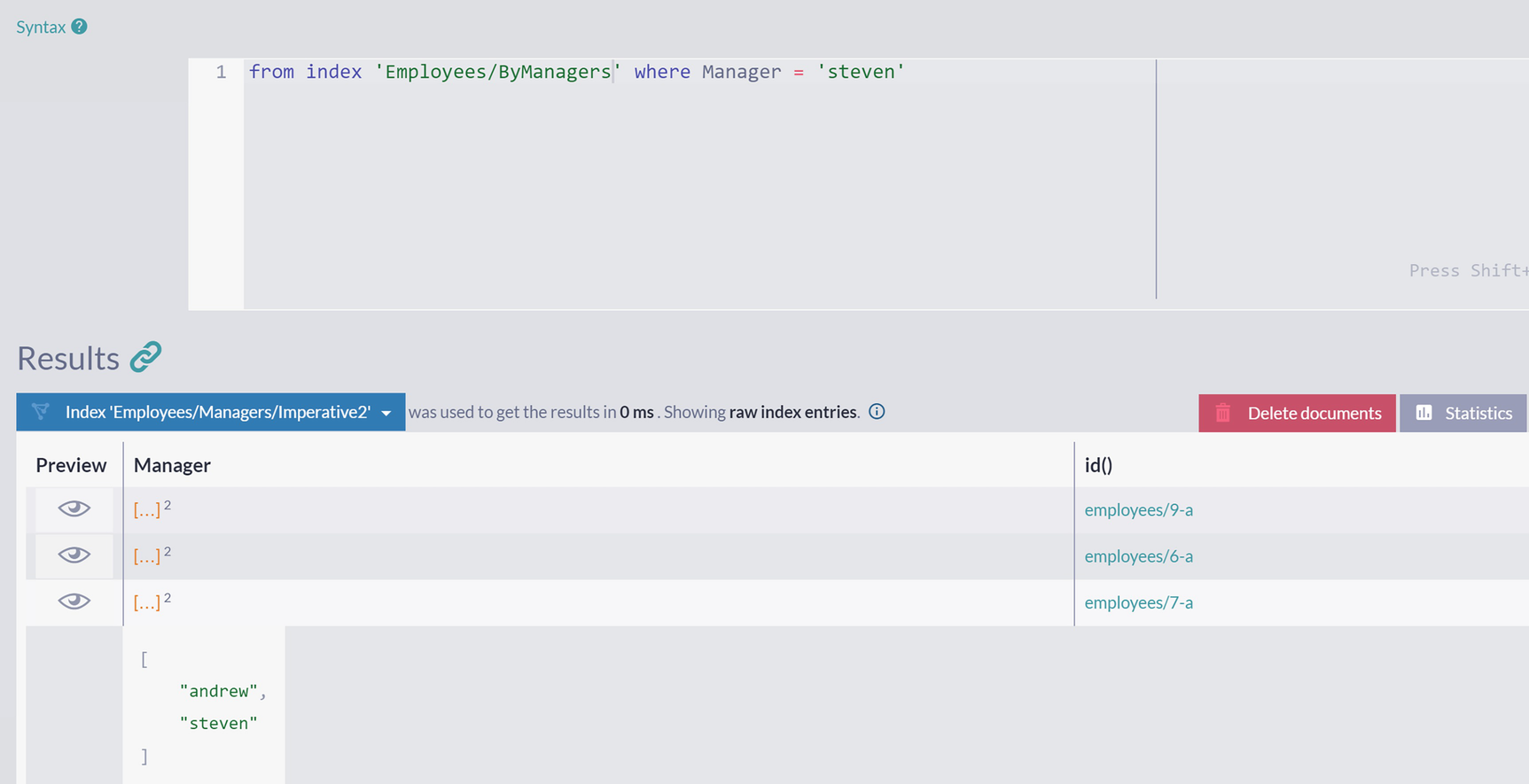
A screenshot displays a query from index employees slash by managers where manager = steven. The results panel has a table with 3 columns, preview, manager, and i d, statistics tab, and delete documents button.
Indexing Entries for Employees/ByManagers Index
As you can see, we queried for all employees where a manager is Steven, and we got all three of them. However, index entries for these employees contain both Steven and Andrew – as we were looping up the hierarchy in Listing 5-19, Steven was added to an array , followed by Andrew, loaded as Steven’s reporting officer.
Recursive version of Employees/ByManagers index
Both imperative and declarative versions of this index are equal in the result. You will be able to query hierarchy by any of the values in the chain .
Summary
In this chapter, we introduced static indexes to define an index explicitly. You saw ways to index one or multiple collections and specify dynamic fields, stored fields, and computed fields of such index. We presented techniques for indexing references to other documents and approaches to handle hierarchical data structures.
The next chapter will show how to create indexes performing data aggregations.