
Chapter 6
More about Program Structure
- What a pointer to a function is
- How to define and use pointers to functions
- How to define and use arrays of pointers to functions
- What an exception is and how to write exception handlers that deal with them
- How to write multiple functions with a single name to handle different kinds of data automatically
- What function templates are and how to define and use them
- How to write a substantial program using several functions
You can find the wrox.com code downloads for this chapter on the Download Code tab at www.wrox.com/go/beginningvisualc. The code is in the Chapter 6 download and individually named according to the names throughout the chapter.
POINTERS TO FUNCTIONS
A pointer stores an address value that up to now has been the address of another variable. This has provided considerable flexibility in allowing you to use different variables at different times through a single pointer. A pointer can also store the address of a function. This enables you to call a function through a pointer, which will be the function at the address that was last assigned to the pointer.
Obviously, a pointer to a function must contain the address of the function that you want to call. To work properly, the pointer must also maintain information about the parameter list for the function it points to, as well as the return type. Therefore, the type for a pointer to a function must incorporate the parameter types and the return type of the functions to which it can point. Clearly, this is going to restrict what you can store in a particular pointer to a function.
If you have declared a pointer to functions that accept one argument of type int and return a value of type double, you can only store the address of a function that has exactly this form. If you want to store the address of a function that accepts two arguments of type int and returns type char, you must define another pointer with a type that includes these characteristics.
Declaring Pointers to Functions
You can declare a pointer pfun that you can use to point to functions that take two arguments, of type char* and int, and return a value of type double like this:
double (*pfun)(char*, int); // Pointer to function declarationAt first, you may find that the parentheses make this look a little weird. This declares a pointer with the name pfun that can point to functions that accept two arguments, one of type pointer to char and another of type int, and return a value of type double. The parentheses around the pointer name, pfun, and the asterisk are essential; without them, the statement would be a function declaration rather than a pointer declaration. In this case, it would look like this:
double *pfun(char*, int); This is a prototype for a function pfun() that has two parameters, and returns a pointer to a double value. The general form of a declaration of a pointer to a function looks like this:
return_type (*pointer_name)(list_of_parameter_types);The declaration of a pointer to a function consists of three components:
- The return type of the functions that can be pointed to
- The pointer name preceded by an asterisk to indicate it is a pointer
- The parameter types of the functions that can be pointed to
You can initialize a pointer to a function with the name of a function within the declaration of the pointer. The following is an example of this:
long sum(long num1, long num2); // Function prototype
long (*pfun)(long, long) {sum}; // Pointer to function points to sum()In general, you can set the pfun pointer that you declared here to point to any function that accepts two arguments of type long and returns a value of type long. In the first instance, you initialized it with the address of the sum() function that has the prototype given by the first statement.
When you initialize a pointer to a function in the declaration, you can use the auto keyword for the type. You can write the previous declaration as:
auto pfun = sum;As long as the prototype or definition for sum() precedes this statement in the source file, the compiler can work out the pointer type.
Of course, you can also initialize a pointer to a function by using an assignment statement. Assuming the pointer pfun has been declared as in the preceding code, you could set the value of the pointer to a different function with these statements:
long product(long, long); // Function prototype
...
pfun = product; // Set pointer to function product()As with pointers to variables, you must ensure that a pointer to a function is initialized before you use it. Without initialization, catastrophic failure of your program is guaranteed.
A Pointer to a Function as an Argument
Because “pointer to a function” is a perfectly reasonable type, a function can also have a parameter that is of a pointer to a function type. The function can then call the function pointed to by the argument. The pointer can point to different functions in different circumstances, which allows the particular function that is to be called from inside a function to be determined in the calling program. You can pass a function name explicitly as the argument for a parameter that is of a pointer to function type.
Arrays of Pointers to Functions
In the same way as with regular pointers, you can declare an array of pointers to functions. You can also initialize them in the declaration. Here is an example:
double sum(const double, const double); // Function prototype
double product(const double, const double); // Function prototype
double difference(const double, const double); // Function prototype
double (*pfun[])( const double, const double)
{ sum, product, difference }; // Array of function pointersEach array element is initialized by the corresponding function address in the initializing list. The array length is determined by the number of values in the list. You cannot use auto to deduce an array type, so you must put the specific type here.
To call product() using the second element of the pointer array, you would write:
pfun[1](2.5, 3.5);The square brackets that select the function pointer array element appear immediately after the array name and before the arguments to the function being called. Of course, you can place a function call through an element of a function pointer array in any appropriate expression that the original function might legitimately appear in, and the index value selecting the pointer can be any expression producing a valid index.
INITIALIZING FUNCTION PARAMETERS
With all the functions you have used up to now, you have had to take care to provide an argument corresponding to each parameter in a function call. It can be quite handy to be able to omit one or more arguments in a function call and have some default values supplied automatically for the arguments that you leave out. You can arrange this by providing initial values for the parameters to a function in its prototype.
Suppose that you write a function to display a message, where the message is passed as the argument. Here is the definition of such a function:
void showit(const char message[])
{
cout << endl
<< message;
return;
}You can specify a default value for the parameter to this function by specifying the initializing string in the function prototype, as follows:
void showit(const char message[] = "Something is wrong.");The default value for the message parameter is the string literal shown. If you omit the argument when you call the function, the default value is used.
EXCEPTIONS
If you’ve had a go at the exercises that appear at the end of the previous chapters, you’ve more than likely come across compiler errors and warnings, as well as errors that occur while the program is running. Exceptions are a way of flagging errors or unexpected conditions that occur in your programs, and you already know that the new operator throws an exception if the memory you request cannot be allocated.
So far, you have typically handled error conditions by using an if statement to test some expression, and then executing some specific code to deal with the error. C++ provides another, more general mechanism for handling errors that allows you to separate the code that deals with these conditions from the code that executes when such conditions do not arise. It is important to realize that exceptions are not intended to be used as an alternative to the normal data checking and validating that you might do in a program. The code that is generated when you use exceptions carries quite a bit of overhead with it, so exceptions are really intended to be applied in the context of exceptional, near-catastrophic conditions that might arise, but are not expected to occur in the normal course of events. An error reading a disk might be something that you use exceptions for. An invalid data item being entered is not a good candidate for using exceptions.
The exception mechanism uses three new keywords:
try—Identifies a code block in which an exception can occur. Atryblock must be immediately followed by at least onecatchblock.throw—Causes an exception condition to be originated and throws an exception of a particular type.catch—Identifies a block of code that handles the exception. Acatchblock is executed when an exception is thrown in the precedingtryblock that is of the type that is specified between parentheses following thecatchkeyword. Atryblock may be followed by severalcatchblocks, each catching a different type of exception.
In the following Try It Out, you can see how they work in practice.
Throwing Exceptions
You can throw an exception anywhere within a try block using a throw statement, and the throw statement operand determines the type of the exception. The exception thrown in the example is a string literal and, therefore, of type const char[]. The operand following the throw keyword can be any expression, and the type of the result of the expression determines the type of exception thrown. There must be a catch block to catch an exception of the type that may be thrown.
Exceptions can also be thrown in functions that are called from within a try block and can be caught by a catch block following the try block if they are not caught within the function. You could add a function to the previous example to demonstrate this, with the definition:
void testThrow()
{
throw " Zero count - calculation not possible.";
}You place a call to this function in the previous example in place of the throw statement:
if(0 == count)
testThrow(); // Call a function that throws an exceptionThe exception is thrown by the testThrow() function and caught by the catch block whenever the array element is zero, so the output is the same as before. Don’t forget the function prototype if you add the definition of testThrow() to the end of the source code.
Catching Exceptions
The catch block following the try block in our example catches any exception of type const char[]. This is determined by the parameter specification that appears in parentheses following the keyword catch. You must supply at least one catch block for a try block, and the catch blocks must immediately follow the try block. A catch block catches all exceptions (of the specified type) that occur anywhere in the code in the immediately preceding try block, including those thrown and not caught in any functions called directly or indirectly within the try block.
If you want to specify that a catch block is to handle any exception thrown in a try block, you put an ellipsis (...) between the parentheses enclosing the exception declaration:
catch (...)
{
// code to handle any exception
}This catch block catches exceptions of any type. It must appear last if you have other catch blocks defined for the try block.
Here’s how a try block followed by two catch blocks looks:
try
{
...
}
catch (const type1& ex)
{
...
}
catch (type2 ex)
{
...
}When an exception is thrown in a try block with more than one catch block, the catch blocks are checked in sequence until a match for the exception type is found. The code in the first catch block that matches will be executed.
Rethrowing Exceptions
It may be that when you catch an exception, you want to pass it on the calling program for some additional action, rather that handling it entirely in the catch block. In this case you can rethrow the exception for onward processing. For example:
try
{
...
}
catch (const type1& ex)
{
...
}
catch (type2 ex)
{
// Process the exception...
throw; // Rethrow the exception for processing by the caller
}Using throw without an operand causes the exception that is being handled to be rethrown. You can only use throw without an operand within a catch block. Rethrowing an exception allows the exception to be caught by an enclosing try/catch block or by a caller of this function. The calling function must place its call to the function in a try block to catch the rethrown exception.
Exception Handling in the MFC
This is a good point to raise the question of MFC and exceptions because they are used to some extent. If you browse the documentation that came with Visual C++, you may come across TRY, THROW, and CATCH in the index. These are macros defined within the MFC that were created before exception handling was implemented in the C++ language. They mimic the operation of try, throw, and catch in C++, but the language facilities for exception handling really render these obsolete, so you should not use them. They are, however, still there for two reasons. There are large numbers of programs still around that use these macros, and it is important to ensure that, as far as possible, old code still compiles. Also, most of the MFC that throws exceptions was implemented in terms of these macros. In any event, any new programs should use the try, throw, and catch keywords because they work with the MFC.
There is one slight anomaly you need to keep in mind when you use MFC functions that throw exceptions. The MFC functions that throw exceptions generally throw exceptions of class types — you will find out about class types before you get to use the MFC. Even though the exception that an MFC function throws is of a given class type — CDBException, say — you need to catch the exception as a pointer, not as the type of the exception. So, with the exception thrown being of type CDBException, the type that appears as the catch block parameter is CBDException*. If you are not rethrowing the exception, you must also delete the exception object in the catch block by calling its Delete() function. For example:
try
{
// Execute some code that might throw an MFC exception...
}
catch (CException* ex)
{
// Handle the exception here...
ex->Delete(); // Delete the exception object
}You should not use delete to delete the exception object because the object may not be allocated on the heap. CException is the base class for all MFC exceptions so the catch block here will catch MFC exceptions of any type.
HANDLING MEMORY ALLOCATION ERRORS
When you used the new operator to allocate memory (as you saw in Chapters 4 and 5), you ignored the possibility that the memory might not be allocated. If the memory isn’t allocated, an exception is thrown that results in the termination of the program. Ignoring this exception is quite acceptable in most situations because having no memory left is usually a terminal condition for a program that you can usually do nothing about. However, there can be circumstances where you might be able to do something about it if you had the chance, or you might want to report the problem in your own way. In this situation, you can catch the exception that the new operator throws. Let’s contrive an example to show this happening.
FUNCTION OVERLOADING
Suppose you have written a function that determines the maximum value in an array of values of type double:
// Function to generate the maximum value in an array of type double
double maxdouble(const double data[], const size_t len)
{
double maximum {data(0)};
for(size_t i {1}; i < len; i++)
if(maximum < data[i])
maximum = data[i];
return maximum;
}
You now want to create a function that produces the maximum value from an array of type long, so you write another function similar to the first, with this prototype:
long maxlong(const long data[], const size_t len);You have chosen the function name to reflect the particular task in hand, which is OK for two functions, but you may also need the same function for several other types of argument. It seems a pity that you have to keep inventing names. Ideally, you would use the same function name max() regardless of the argument type, and have the appropriate version executed. It probably won’t be any surprise to you that you can, indeed, do this, and the C++ mechanism that makes it possible is called function overloading.
What Is Function Overloading?
Function overloading allows you to use several functions with the same name as long as they each have different parameter lists. When one of the functions is called, the compiler chooses the correct version for the job based on the list of arguments. Obviously, the compiler must always be able to decide unequivocally which function should be selected in any particular instance of a function call, so the parameter list for each function in a set of overloaded functions must be unique. Following on from the max() function example, you could create overloaded functions with the following prototypes:
int max(const int data[], const size_t len); // Prototypes for
long max(const long data[], const size_t len); // a set of overloaded
double max(const double data[], const size_t len); // functionsThese functions share a common name, but have different parameter lists. Overloaded functions that have the same number of parameters must have at least one parameter with a unique type. An overloaded function can have a different number of parameters from the others in the set.
Note that a different return type does not distinguish a function adequately. You can’t add the following function to the previous set:
double max(const long data[], const size_t len); // Not valid overloadingThe reason is that this function would be indistinguishable from the function that has this prototype:
long max(const long data[], const size_t len);If you define functions like this, it causes the compiler to complain with the following error:
error C2556: 'double max(const long [],const size_t)' :
overloaded function differs only by return type from 'long max(const long [],const size_t)'This may seem slightly unreasonable, until you remember that you can write statements such as these:
long numbers[] {1, 2, 3, 3, 6, 7, 11, 50, 40};
const size_t len {_countof(numbers)}
max(numbers, len);The call for the max() function doesn't make much sense here because you discard the result, but this does not make it illegal. If the return type were permitted as a distinguishing feature, the compiler would be unable to decide whether to choose the version with a long or a double return type. For this reason, the return type is not considered to be a differentiating feature of overloaded functions.
Every function — not just overloaded functions — is said to have a signature, where the signature of a function is determined by its name and its parameter list. All functions in a program must have unique signatures, otherwise the program does not compile.
Reference Types and Overload Selection
When you use reference types for parameters in overloaded functions, you must take care to ensure the compiler can select an appropriate overload. Suppose you define functions with the following prototypes:
void f(int n);
void f(int& rn);These functions are differentiated by the type of the parameter, but code using these will not compile. When you call f() with an argument of type int, the compiler has no means of determining which function should be selected because either function is equally applicable. In general, you cannot overload on a given type, type, and an lvalue reference to that type, type&.
However, the compiler can distinguish the overloaded functions with the following prototypes:
void f(int& arg); // Lvalue reference parameter
void f(int&& arg); // Rvalue reference parameterEven though for some argument types, either function could apply, the compiler adopts a preferred choice. The f(int&) function will always be selected when the argument is an lvalue. The f(int&&) version will be selected only when the argument is an rvalue. For example:
int num{5};
f(num); // Calls f(int&)
f(2*num); // Calls f(int&&)
f(25); // Calls f(int&&)
f(num++); // Calls f(int&&)
f(++num); // Calls f(int&)Only the first and last statements call the overload with the lvalue reference parameter, because the other statements call the function with arguments that are rvalues.
When to Overload Functions
Function overloading provides you with the means of ensuring that a function name describes the function being performed and is not confused by extraneous information such as the type of data being processed. This is akin to what happens with basic operations in C++. To add two numbers, you use the same operator, regardless of the types of the operands. Our overloaded function max() has the same name, regardless of the type of data being processed. This helps to make the code more readable and makes these functions easier to use.
FUNCTION TEMPLATES
The last example was somewhat tedious in that you had to repeat essentially the same code for each function, but with different variable and parameter types. However, there is a way of avoiding this. You have the possibility of creating a recipe that will enable the compiler to automatically generate functions with various parameter types. The code defining the recipe for generating a particular group of functions is called a function template.
A function template has one or more type parameters, and you generate a particular function by supplying a concrete type argument for each of the template’s parameters. Thus, the functions generated by a function template all have the same basic code, but customized by the type arguments that you supply. You can see how this works in practice by defining a function template for the function max() in the previous example.
Using a Function Template
You can define a template for the function max() as follows:
template<class T> T max(const T x[], const size_t len)
{
T maximum {x[0]};
for(size_t i{1}; i < len; i++)
if(maximum < x[i])
maximum = x[i];
return maximum;
}The template keyword identifies this as a template definition. The angled brackets following the template keyword enclose the type parameters that are used to create a particular instance of the function separated by commas; in this instance, you have just one type parameter, T. The class keyword before the T indicates that the T is the type parameter for this template, class being the generic term for type. Later in the book, you will see that defining a class is essentially defining your own data type. Consequently, you have fundamental types in C++, such as type int and type char, and you also have the types that you define yourself. You can use the keyword typename instead of class to identify the parameters in a function template, in which case, the template definition would look like this:
template<typename T> T max(const T x[], const size_t len)
{
T maximum {x[0]};
for(size_t i {1}; i < len; i++)
if(maximum < x[i])
maximum = x[i];
return maximum;
}Some programmers prefer to use the typename keyword as the class keyword tends to connote a user-defined type, whereas typename is more neutral and, therefore, is more readily understood to imply fundamental types as well as user-defined types. In practice, you’ll see both used widely.
Wherever T appears in the definition of a function template, it is replaced by the specific type argument, such as long, that you supply when you create an instance of the template. If you try this out manually by plugging in long in place of T in the template, you’ll see that this generates a perfectly satisfactory function for calculating the maximum value from an array of type long:
long max(const long x[], const size_t len)
{
long maximum {x[0]};
for(size_t i {1}; i < len; i++)
if(maximum < x[i])
maximum = x[i];
return maximum;
}The creation of a particular function instance is referred to as instantiation. Each time you use max() in your program, the compiler checks to see if a function corresponding to the type of arguments that you have used in the function call already exists. If the function required does not exist, the compiler creates one by substituting the argument type that you have used in your function call in place of the parameter T throughout the template definition.
You could exercise the template for the max() function with the same main() function that you used in the previous example.
USING THE DECLTYPE OPERATOR
You use the decltype operator to obtain the type of an expression, so decltype(exp) is the type of the value that results from evaluating the expression exp. For example, you could write the following statements:
double x {100.0};
int n {5};
decltype(x*n) result(x*n);The last statement specifies the type of result to be the type of the expression x*n, which is type double. While this shows the mechanics of what the decltype operator does, the primary use for the decltype operator is in defining function templates. Occasionally, the return type of a template function with multiple type parameters may depend on the types used to instantiate the template. Suppose you want to write a template function to multiply corresponding elements of two arrays, possibly of different types, and return the sum of these products. Because the types of the two arrays may be different, the type of the result will depend on the actual types of the array arguments, so you cannot specify a particular return type. The function template might notionally look like this:
template<typename T1, typename T2>
return_type f(T1 v1[], T2 v2[], const size_t count)
{
decltype(v1[0]*v2[0]) sum {};
for(size_t i {}; i<count; i++) sum += v1[i]*v2[i];
return sum;
}return_type needs to be the type of the result of multiplying corresponding elements of the array arguments. The decltype operator can help, but unfortunately the following will not compile:
template<typename T1, typename T2>
decltype(v1[0]*v2[0]) f(T1 v1[], T2 v2[], const size_t count) // Will not compile!
{
decltype(v1[0]*v2[0]) sum {};
for(size_t i {}; i<count; i++) sum += v1[i]*v2[i];
return sum;
}This specifies what you want, but the compiler cannot compile this because v1 and v2 are not defined at the point where the return type specification is processed.
It requires a different syntax to take care of it:
template<typename T1, typename T2>
auto f(T1 v1[], T2 v2[], const size_t count) -> decltype(v1[0]*v2[0])
{
decltype(v1[0]*v2[0]) sum {};
for(size_t i {}; i<count; i++) sum += v1[i]*v2[i];
return sum;
}As you saw in Chapter 5, this is referred to as a trailing return type. You specify the return type using the auto keyword. The actual return type can be determined by the compiler when an instance of the template is created because, at that point, the parameters v1 and v2 have been parsed. The decltype expression following the -> determines the return type for any instance of the template. Let’s see if it works.
AN EXAMPLE USING FUNCTIONS
You have covered a lot of ground in C++ up to now and a lot on functions in this chapter alone. After wading through a varied menu of language capabilities, it’s not always easy to see how they relate to one another. Now would be a good point to see how some of this goes together to produce something with more meat than a simple demonstration program.
Let’s work through a more realistic example to see how a problem can be broken down into functions. The process involves defining the problem to be solved, analyzing the problem to see how it can be implemented in C++, and, finally, writing the code. The approach here is aimed at illustrating how various functions go together to make up the final result, rather than providing a tutorial on how to develop a program.
Implementing a Calculator
Suppose you need a program that acts as a calculator; not one of these fancy devices with lots of buttons and gizmos designed for those who are easily pleased, but one for people who know where they are going, arithmetically speaking. You can really go for it and enter a calculation from the keyboard as a single arithmetic expression, and have the answer displayed immediately. An example of the sort of thing that you might enter is:
2*3.14159*12.6*12.6 / 2 + 25.2*25.2To avoid unnecessary complications for the moment, you won’t allow parentheses in the expression and the whole computation must be entered in a single line; however, to allow the user to make the input look attractive, you will allow spaces to be placed anywhere. The expression may contain the operators multiply, divide, add, and subtract represented by *, /, +, and –, respectively, and it will be evaluated with normal arithmetic rules, so that multiplication and division take precedence over addition and subtraction.
The program should allow as many successive calculations to be performed as required, and should terminate if an empty line is entered. It should also have helpful and friendly error messages.
Analyzing the Problem
A good place to start is with the input. The program reads in an arithmetic expression of any length on a single line, which can be any construction within the terms given. Because nothing is fixed about the elements making up the expression, you have to read it as a string of characters and then work out within the program how it’s made up. You can decide arbitrarily that you will handle a string of up to 80 characters, so you could store it in an array declared within these statements:
const size_t MAX {80}; // Maximum expression length including '�'
char buffer[MAX]; // Input area for expression to be evaluatedTo change the maximum length of the string processed by the program, you will only need to alter the initial value of MAX.
You’ll need to analyze the basic structure of the information that appears in the input string, so let’s break it down step by step.
You will want to make sure that the input is as uncluttered as possible when you are processing it, so before you start analyzing the input string, you will get rid of any spaces in it. You can call the function that will do this eatspaces(). This function can work by stepping through the input buffer — which is the array buffer[] — and shuffling characters up to overwrite any spaces. This process uses two indexes to the buffer array, i and j, which start out at the beginning of the buffer; in general, you’ll store element j at position i. As you progress through the array elements, each time you find a space, you increment j but not i, so the space at position i gets overwritten by the next character you find at index position j that is not a space. Figure 6-2 illustrates the logic of this.
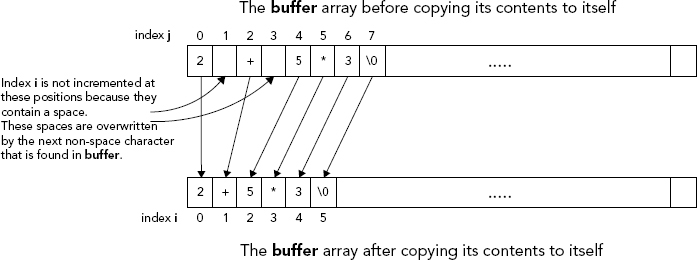
This process is one of copying the contents of the buffer array to itself, excluding any spaces. Figure 6-2 shows the buffer array before and after the copying process, and the arrows indicate which characters are copied and the position to which each character is copied.
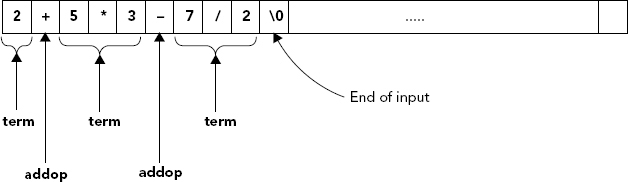
When you have removed spaces from the input, you are ready to evaluate the expression. You define the expr() function that returns the value that results from evaluating the whole expression in the input buffer. To decide what goes on inside the expr() function, you need to look into the structure of the input in more detail. The add and subtract operators have the lowest precedence and so are evaluated last. You can think of the input string as comprising one or more terms connected by operators, which can be either the operator + or the operator -. You can refer to either operator as an addop. With this terminology, you can represent the general form of the input expression like this:
expression: term addop term ... addop termThe expression contains at least one term and can have an arbitrary number of following addop term combinations. In fact, assuming that you have removed all the blanks, there are only three legal possibilities for the character that follows each term:
- The next character is
'�', so you are at the end of the string. - The next character is
'-', in which case you should subtract the nexttermfrom the value accrued for the expression up to this point. - The next character is
'+', in which case you should add the value of the nexttermto the value of the expression accumulated so far.
If anything else follows a term, the string is not what you expect, so you’ll throw an exception. Figure 6-3 illustrates the structure of a sample expression.
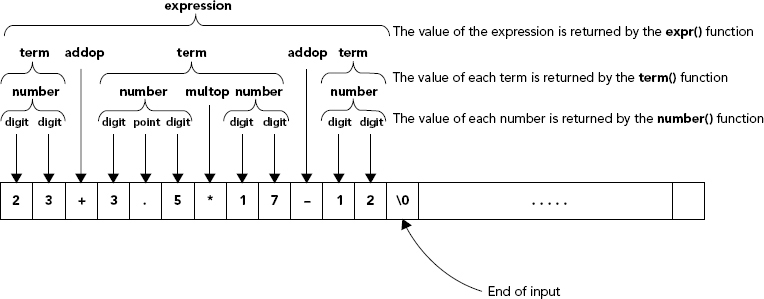
Next, you need a more detailed and precise definition of a term. A term is simply a series of numbers connected by either the operator * or the operator /. Therefore, a term (in general) looks like this:
term: number multop number ... multop numbermultop represents either a multiply or a divide operator. You could define a term() function to return the value of a term. This needs to scan the string to a number first and then to look for a multop followed by another number. If a character is found that isn’t a multop, the term() function assumes that it is an addop and returns the value that has been found up to that point.
The last thing you need to figure out before writing the program is how you recognize a number. To minimize the complexity of the code, you’ll only recognize unsigned numbers; therefore, a number consists of a series of digits that optionally may be followed by a decimal point and some more digits. To determine the value of a number, you step through the buffer looking for digits. If you find anything that isn’t a digit, you check whether it’s a decimal point. If it’s not a decimal point, it has nothing to do with a number, so you return what you have got. If you find a decimal point, you look for more digits. As soon as you find anything that’s not a digit, you have the complete number and you return that. Imaginatively, you’ll call the function to recognize a number and return its value number(). Figure 6-4 shows an example of how an expression breaks down into terms and numbers.
You now have enough understanding of the problem to write some code. You can work through the functions you need and then write a main() function to tie them all together. The first and, perhaps, easiest function to write is eatspaces(), which will eliminate spaces from the input string.
Eliminating Blanks from a String
You can write the prototype for the eatspaces() function as follows:
void eatspaces(char* str); // Function to eliminate blanksThe function doesn’t need to return any value because spaces can be eliminated from the string in situ, modifying the original string directly through the pointer that is passed as the argument. The process for eliminating spaces is very simple. You copy the string to itself, overwriting any spaces, as you saw earlier in this chapter.
You can define the function to do this as follows:
// Function to eliminate spaces from a string
void eatspaces(char* str)
{
size_t i {}; // 'Copy to' index to string
size_t j {}; // 'Copy from' index to string
while((*(str + i) = *(str + j++)) != '�') // Loop while character is not �
if(*(str + i) != ' ') // Increment i as long as
i++; // character is not a space
return;
}How the Function Functions
All the action is in the while loop. The loop condition copies the string by moving the character at position j to the character at position i, and then increments j to the next character. If the character copied was '�', you have reached the end of the string and you’re done.
The only action in the loop statement is to increment i to the next character if the last character copied was not a blank. If it is a blank, i is not to be incremented and the blank can therefore be overwritten by the character copied on the next iteration.
That wasn’t hard, was it? Next, you can try writing the function that returns the result of evaluating the expression.
Evaluating an Expression
The expr() function returns the value of the expression specified in a string that is supplied as an argument, so you can write its prototype as:
double expr(char* str); // Function evaluating an expressionThe function declared here accepts a string as an argument and returns the result as type double. Based on the structure for an expression that you worked out earlier, you can draw a logic diagram for the process of evaluating an expression, as shown in Figure 6-5.
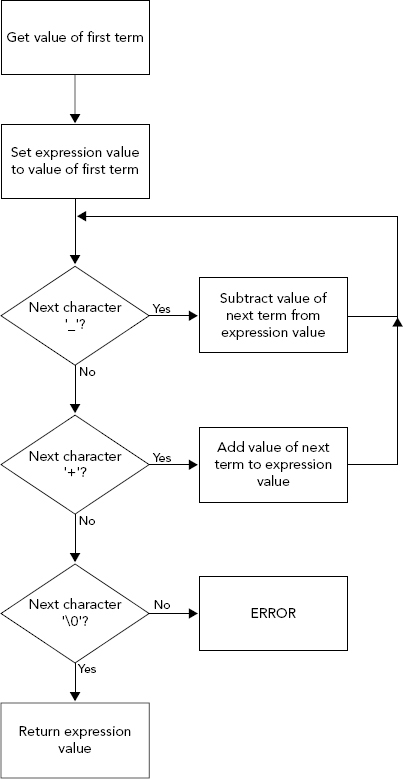
Using this basic definition of the logic, you can now write the function:
// Function to evaluate an arithmetic expression
double expr(const char* str)
{
double value {}; // Store result here
int index {}; // Keeps track of current character position
value = term(str, index); // Get first term
for(;;) // Indefinite loop, all exits inside
{
switch(*(str + index++)) // Choose action based on current character
{
case '�': // We're at the end of the string
return value; // so return what we have got
case '+': // + found so add in the
value += term(str, index); // next term
break;
case '-': // - found so subtract
value -= term(str, index); // the next term
break;
default: // If we reach here the string is junk
char message[38] {"Expression evaluation error. Found: "}
strncat_s(message, str + index - 1, 1); // Append the character
throw message;
break;
}
}
}How the Function Functions
Considering this function is analyzing any arithmetic expression that you care to throw at it (as long as it uses our operator subset), it’s not a lot of code. You define a variable index of type int, which keeps track of the current position in the string where you are working, and you initialize it to 0, which corresponds to the index position of the first character in the string. You also define a variable value of type double in which you’ll accumulate the value of the expression that is passed to the function in the char array str.
Because an expression must have at least one term, the first action in the function is to get the value of the first term by calling the function term(), which you have yet to write. This actually places three requirements on the function term():
- It should accept a
char*and anintparameter, the second parameter being an index to the first character of the term in the string supplied through the first parameter. - It should update the index value passed so that it references the string character following the last character of the term found.
- It should return the value of the term as type
double.
The rest of the program is an indefinite for loop. Within the loop, the action is determined by a switch statement, which is controlled by the current character in the string. If it is a '+', you call the term() function to get the value of the next term in the expression and add it to the variable value. If it is a '-', you subtract the value returned by term() from value. If it is a '�', you are at the end of the string, so you return the current contents of value to the calling function. If it is any other character, it shouldn’t be there, so throw an exception. The exception is a string that has the offending character appended.
As long as either a '+' or a '-' is found, the loop continues. Each call to term() moves the value of index to the character following the term that was evaluated, and this should be either another '+' or '-', or the end-of-string character '�'. Thus, the function either terminates normally when '�' is reached, or abnormally by throwing an exception.
You could also analyze an arithmetic expression using a recursive function. If you think about the definition of an expression slightly differently, you could specify it as being either a term, or a term followed by an expression. The definition here is recursive (i.e., the definition involves the item being defined), and this approach is very common in defining programming language structures. This definition provides just as much flexibility as the first, but using it as the base concept, you could arrive at a recursive version of expr() instead of using a loop as you did in the implementation of expr(). You might want to try this alternative approach as an exercise after you have completed the first version.
Getting the Value of a Term
The term() function returns a value for a term as type double and receives two arguments: the string being analyzed and an index to the current position in the string. There are other ways of doing this, but this arrangement is quite straightforward. The prototype of the function term() is:
double term(const char* str, size_t& index); // Function analyzing a termThe second parameter is a reference. This is because you want the function to be able to modify the value of the index variable in the calling program to position it at the character following the last character of the term found in the input string. You could return index as a value, but then you would need to return the value of the term in some other way, so this arrangement seems quite natural.
The logic for analyzing a term is going to be similar to that for an expression. A term is a number, potentially followed by one or more combinations of a multiply or a divide operator and another number. You can write the definition of the term() function as:
// Function to get the value of a term
double term(const char* str, size_t& index)
{
double value {}; // Somewhere to accumulate
// the result
value = number(str, index); // Get the first number in the term
// Loop as long as we have a good operator
while(true)
{
if(*(str + index) == '*') // If it's multiply,
value *= number(str, ++index); // multiply by next number
else if(*(str + index) == '/') // If it's divide,
value /= number(str, ++index); // divide by next number
else
break;
}
return value; // We've finished, so return what
// we've got
}How the Function Functions
You first declare a local double variable, value, in which you’ll accumulate the value of the current term. Because a term must contain at least one number, the first action is to obtain the value of the first number by calling the number() function and storing the result in value. The code implicitly assumes that number() accepts the string and an index to a position in the string as arguments, and returns the value of the number found. Because the number() function must also update the index to the string to the position after a number is found, you’ll specify the second parameter for the function as a reference.
The rest of the term() function is a while loop that continues as long as the next character is '*' or '/'. Within the loop, if the character found at the current position is '*', you increment index to position it at the beginning of the next number, call the function number() to get the value of the next number, and then multiply the contents of value by the value returned. In a similar manner, if the current character is '/', you increment index and divide the contents of value by the value returned from number(). Because number() automatically alters the value of index to the character following the number found, index is already set to select the next available character in the string on the next iteration. The loop terminates when a character other than a multiply or divide operator is found, whereupon the current value of the term accumulated in the variable value is returned to the calling function.
The last analytical function that you require is number(), which determines the numerical value of any number appearing in the string.
Analyzing a Number
Based on the way you have used number() within the term() function, you need to declare it with this prototype:
double number(const char* str, size_t& index); // Function to recognize a numberThe specification of the second parameter as a reference allows the function to update the argument in the calling program directly, which is what you require.
You can make use of a function provided by the standard library here. The cctype header file provides definitions for a range of functions for testing single characters. These functions return values of type int where nonzero values correspond to true and zero corresponds to false. Four of these functions are shown in the following table:
| FUNCTIONS | DESCRIPTION |
|---|---|
int isalpha(int c) |
Returns nonzero if the argument is alphabetic; otherwise, returns 0 |
int isupper(int c) |
Returns nonzero if the argument is an uppercase letter; otherwise, returns 0. |
int islower(int c) |
Returns nonzero if the argument is a lowercase letter; otherwise, returns 0. |
int isdigit(int c) |
Returns nonzero if the argument is a digit; otherwise, returns 0. |
You only need the last of the functions shown in the table in the program. Remember that isdigit() is testing a character, such as the character '9' (ASCII character 57 in decimal notation) for instance, not a numeric 9, because the input is a string. You can define the function number() as:
// Function to recognize a number in a string
double number(const char* str, size_t& index)
{
double value {}; // Store the resulting value
// There must be at least one digit...
if(!isdigit(*(str + index)))
{ // There's no digits so input is junk...
char message[31] {"Invalid character in number: "}
strncat_s(message, str+index, 1); // Append the character
throw message;
}
while(isdigit(*(str + index))) // Loop accumulating leading digits
value = 10*value + (*(str + index++) - '0'),
// Not a digit when we get to here
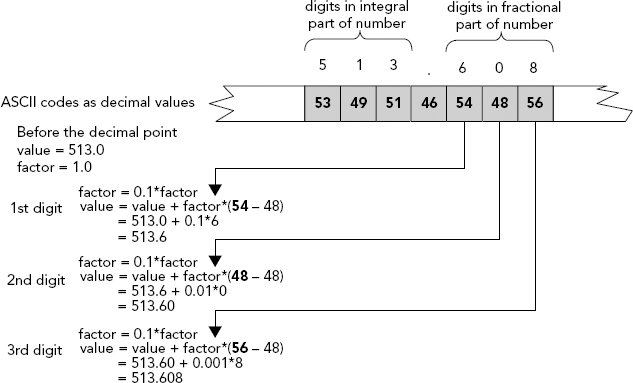
if(*(str + index) != '.') // so check for decimal point
return value; // and if not, return value
double factor {1.0}; // Factor for decimal places
while(isdigit(*(str + (++index)))) // Loop as long as we have digits
{
factor *= 0.1; // Decrease factor by factor of 10
value = value + (*(str + index) - '0')*factor; // Add decimal place
}
return value; // On loop exit we are done
}How the Function Functions
You declare the local variable value as type double that holds the value of the number that is found. You initialize it with 0.0 because you add in the digit values as you go along. There must always be at least one digit present for the number to be valid, so the first step is to verify that this is the case. If there is no initial digit, the input is badly formed, so you throw an exception that identifies the problem and the erroneous character.
A number in the string is a series of digits as ASCII characters so the function steps through the string accumulating the value of the number digit by digit. This occurs in two phases — the first phase accumulates digits before the decimal point; then, if you find a decimal point, the second phase accumulates the digits after it.
The first step is in the while loop that continues as long as the current character selected by the variable index is a digit. The value of the digit is extracted and added to the variable value in the loop statement:
value = 10*value + (*(str + index++) - '0'),The way this is constructed bears a closer examination. A digit character has an ASCII value between 48, corresponding to the digit 0, and 57, corresponding to the digit 9. Thus, if you subtract the ASCII code for '0' from the code for a digit, you convert it to its equivalent numeric digit value from 0 to 9. You have parentheses around the subexpression:
*(str + index++) - '0'These are not essential, but they do make what’s going on a little clearer. The contents of value are multiplied by 10 to shift the value one decimal place to the left before adding in the digit value, because you’ll find digits from left to right — that is, the most significant digit first. This process is illustrated in Figure 6-6.
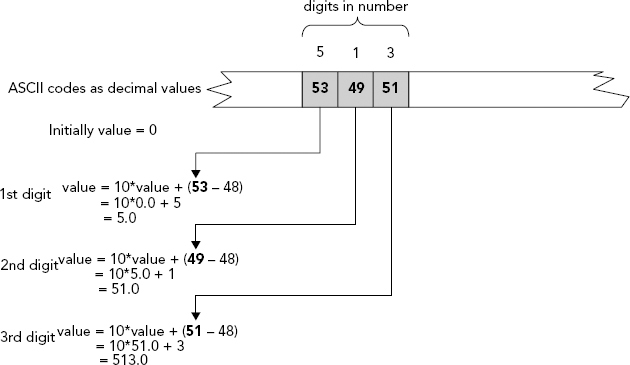
As soon as you come across something other than a digit, it is either a decimal point or something else. If it’s not a decimal point, you’ve finished, so you return the current contents of value to the calling function. If it is a decimal point, you accumulate the digits corresponding to the fractional part of the number in the second loop. In this loop, you use the factor variable, which has the initial value 1.0, to set the decimal place for the current digit, and, consequently, factor is multiplied by 0.1 for each digit found. Thus, the first digit after the decimal point is multiplied by 0.1, the second by 0.01, the third by 0.001, and so on. This process is illustrated in Figure 6-7.
As soon as you find a non-digit character, you are done, so after the second loop you return value. You almost have the whole thing now. You just need a main() function to read the input and drive the process.
Putting the Program Together
You can collect the #include statements together and assemble the function prototypes at the beginning of the program for all the functions used in this program:
// Ex6_10.cpp
// A program to implement a calculator
#include <iostream> // For stream input/output
#include <cstdlib> // For the exit() function
#include <cctype> // For the isdigit() function
using std::cin;
using std::cout;
using std::cerr;
using std::endl;
void eatspaces(char* str); // Function to eliminate blanks
double expr(char* str); // Function evaluating an expression
double term(const char* str, size_t& index); // Function analyzing a term
double number(const char* str, size_t& index); // Function to recognize a number
const size_t MAX {80}; // Maximum expression length,
// including '�'You have also defined a global variable MAX, which is the maximum number of characters in the expression processed by the program (including the terminating '�' character).
Now, you can add the definition of the main() function, and your program is complete. The main() function should read a string and exit if it is empty; otherwise, call expr() to evaluate the input and display the result. This process should repeat indefinitely. That doesn’t sound too difficult, so let’s give it a try.
int main()
{
char buffer[MAX] {}; // Input area for expression to be evaluated
cout << endl
<< "Welcome to your friendly calculator."
<< endl
<< "Enter an expression, or an empty line to quit."
<< endl;
for(;;)
{
cin.getline(buffer, sizeof buffer); // Read an input line
eatspaces(buffer); // Remove blanks from input
if(!buffer[0]) // Empty line ends calculator
return 0;
try
{
cout << " = " << expr(buffer) // Output value of expression
<< endl << endl;
}
catch( const char* pEx)
{
cerr << pEx << endl;
cerr << "Ending program." << endl;
return 1;
}
}
}How the Function Functions
In main(), you set up the char array, buffer, to accept an expression up to 80 characters long (including the string termination character). The expression is read within the indefinite for loop using the getline() function. After obtaining the input, spaces are removed from the string by calling eatspaces().
All the other things that main() provides for are also within the loop. It checks for an empty string, which consists of just the null character, '�', in which case the program ends. It also outputs the value returned by expr() function. The statement that does this is in a try block, because both expr() and the number() function that it calls indirectly can throw an exception when things go wrong. The exception thrown by both functions is of the same type. The catch block will catch exceptions of type const char* so it will catch an exception thrown by either function. When an exception is thrown, the catch block outputs the string that is the exception and ends the program.
After you add all the function definitions to the code and compile and run it, you should get output similar to the following:
2 * 35
= 70
2/3 + 3/4 + 4/5 + 5/6 + 6/7
= 3.90714
1 + 2.5 + 2.5*2.5 + 2.5*2.5*2.5
= 25.375You can enter as many calculations as you like, and when you are fed up with it, just press Enter to end the program. If you want to see the error handling in action, just enter an invalid expression.
Extending the Program
Now that you have got a working calculator, you can start to think about extending it. Wouldn’t it be nice to be able to handle parentheses in an expression? It can’t be that difficult, can it? Let’s give it a try.
Think about the relationship between something in parentheses that might appear in an expression and the kind of expression analysis that you have made so far. Look at an example of the kind of expression you want to handle:
2*(3 + 4) / 6 - (5 + 6) / (7 + 8)
Notice that an expression between parentheses always forms part of a term in our original parlance. Whatever sort of computation you come up with, this is always true. In fact, if you could substitute the value of the expressions within parentheses back into the original string, you would have something that you can already deal with. This indicates a possible approach to handling parentheses. You might be able to treat an expression in parentheses as just another number, and modify the number() function to sort out the value of whatever appears between the parentheses.
That sounds like a good idea, but “sorting out” the expression in parentheses requires a bit of thought: the clue to success is in the terminology used here. An expression that appears within parentheses is a perfectly good example of a full-blown expression, and you already have the expr() function that will return the value of an expression. If you can get the number() function to work out what lies between the parentheses and extract those from the string, you could pass the substring to the expr() function, and recursion would really simplify the problem. What’s more, you don’t need to worry about nested parentheses. Any set of parentheses contains what you have defined as an expression, so nested parentheses are taken care of automatically. Recursion wins again.
Let’s take a stab at rewriting number() to recognize an expression between parentheses:
// Function to recognize an expression in parentheses
// or a number in a string
double number(const char* str, size_t& index)
{
double value {}; // Store the resulting value
if(*(str + index) == '(') // Start of parentheses
{
char* psubstr {}; // Pointer for substring
psubstr = extract(str, ++index); // Extract substring in brackets
value = expr(psubstr); // Get the value of the substring
delete[]psubstr; // Clean up the free store
return value; // Return substring value
}
// There must be at least one digit...
if(!isdigit(*(str + index)))
{ // There's no digits so input is junk...
char message[31] {"Invalid character in number: "}
strncat_s(message, str+index, 1); // Append the character
throw message;
}
while(isdigit(*(str + index))) // Loop accumulating leading digits
value = 10*value + (*(str + index++) - '0'),
// Not a digit when we get to here
if(*(str + index)!= '.') // so check for decimal point
return value; // and if not, return value
double factor{1.0}; // Factor for decimal places
while(isdigit(*(str + (++index)))) // Loop as long as we have digits
{
factor *= 0.1; // Decrease factor by factor of 10
value = value + (*(str + index) - '0')*factor; // Add decimal place
}
return value; // On loop exit we are done
}This is not yet complete, because you still need the extract() function, but you’ll fix that in a moment.
How the Function Functions
Very little has been changed to support parentheses. I suppose it is a bit of a cheat, because you use the extract() function that you haven’t written yet, but for one extra function, you get as many levels of nested parentheses as you want. This really is icing on the cake, and it’s all down to the magic of recursion!
The first thing that number() does now is to test for a left parenthesis. If it finds one, it calls another function, extract() to extract the substring between the parentheses from the original string. The address of this new substring is stored in the pointer psubstr, so you then apply the expr() function to the substring by passing this pointer as an argument. The result is stored in value, and after releasing the memory allocated on the free store in the extract() function (as you will eventually implement it), you return the value obtained for the substring as though it were a regular number. Of course, if there is no left parenthesis to start with, the function number() continues exactly as before.
Extracting a Substring
You now need to write the extract() function. It’s not difficult, but it’s also not trivial. The main complication comes from the fact that the expression within parentheses may also contain other sets of parentheses, so you can’t just go looking for the first right parenthesis after you find a left parenthesis. You must watch out for more left parentheses as well, and for every one that you find, ignore the corresponding right parenthesis. You can do this by maintaining a count of left parentheses as you go along, adding one to the count for each left parenthesis you find. If the left parenthesis count is not zero, you subtract one for each right parenthesis. Of course, if the left parenthesis count is zero and you find a right parenthesis, you’re at the end of the substring. The mechanism for extracting a parenthesized substring is illustrated in Figure 6-8.
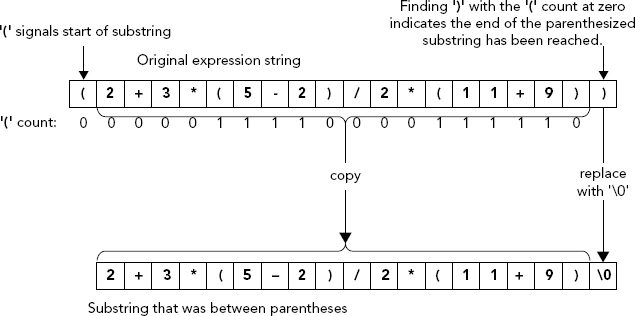
Because the string you extract here contains subexpressions between parentheses, eventually extract() is called again to deal with those.
The extract() function also needs to allocate memory for the substring and return a pointer to it. Of course, the index to the current position in the original string must end up selecting the character following the substring, so the parameter for that should be specified as a reference. Thus the prototype of extract() is:
char* extract(const char* str, size_t& index); //Function to extract a substringYou can now have a shot at the definition of the function:
// Function to extract a substring between parentheses
// (requires cstring header file)
char* extract(const char* str, size_t& index)
{
char* pstr {}; // Pointer to new string for return
size_t numL {}; // Count of left parentheses found
size_t bufindex {index}; // Save starting value for index
do
{
switch(*(str + index))
{
case ')':
if(0 == numL)
{
++index;
pstr = new char[index - bufindex];
if(!pstr)
{
throw "Memory allocation failed.";
}
// Copy substring to new memory
strncpy_s(pstr, index-bufindex, str+bufindex, index-bufindex-1);
return pstr; // Return substring in new memory
}
else
numL--; // Reduce count of '(' to be matched
break;
case '(':
numL++; // Increase count of '(' to be
// matched
break;
}
} while(*(str + index++) != '�'), // Loop - don't overrun end of string
throw "Ran off the end of the expression, must be bad input.";
}How the Function Functions
You declare a pointer to a string, pstr, that will eventually point to the substring that you will return. You declare a counter numL to keep track of left parentheses in the substring. The initial value of index (when the function begins execution) is stored in the variable bufindex. You use this in combination with incremented values of index to determine the range of characters to be extracted from str and returned.
The executable part of the function is basically one big do-while loop that walks through str looking for parentheses. You check for left or right parentheses during each cycle. If a left parenthesis is found, numL is incremented, and if a right parenthesis is found and numL is non-zero, it is decremented. When you find a right parenthesis and numL is zero, you have found the end of the substring. Sufficient memory is obtained on the heap to hold the substring and the address is stored in pstr. The substring that you want from str is then copied to the memory that you obtained through the operator new by using the strncpy_s() function that is declared in the cstring header. This function copies the string specified by the third argument, str+bufindex, to the address specified by the first argument, pstr. str+bufindex is a pointer to the character in str where the substring starts. The second argument is the length of the destination string, pstr and the fourth argument is the number of characters to be copied from the source string.
If you fall through the bottom of the loop, it means that you hit the '�' at the end of the expression in str without finding the complementary right parenthesis, so you throw an exception that will be caught in main().
Running the Modified Program
After replacing the number() function in the old version of the program, adding the #include directive for cstring, and incorporating the prototype and the definition for the new extract() function you have just written, you’re ready to roll with an all-singing, all-dancing calculator. If you have assembled all that without error, you can get output like this:
Welcome to your friendly calculator.
Enter an expression, or an empty line to quit.
1/(1+1/(1+1/(1+1)))
= 0.6
(1/2-1/3)*(1/3-1/4)*(1/4-1/5)
= 0.000694444
3.5*(1.25-3/(1.333-2.1*1.6))-1
= 8.55507
2,4-3.4
Expression evaluation error. Found:, Ending program.The friendly and informative error message in the last output line is due to the use of the comma instead of the decimal point in the expression above it, in what should be 2.4. As you can see, you get nested parentheses to any depth with a relatively simple extension of the program, all due to the amazing power of recursion.
SUMMARY
You now have a reasonably comprehensive knowledge of writing and using functions, and you have used overloading to implement a set of functions providing the same operation with different types of parameters. You have also seen how you can define function templates that you can use to generate different versions of essentially the same function. You’ll see more about overloading functions in the following chapters.
You also got some experience of using several functions in a program by working through the calculator example. But remember that all the uses of functions up to now have been in the context of a traditional procedural approach to programming. When you come to look at object-oriented programming, you will still use functions extensively, but with a very different approach to program structure and to the design of the solution to a problem.
EXERCISES
- Consider the following function:
int ascVal(size_t i, const char* p) { // Return the ASCII value of the char if (!p || i > strlen(p)) return -1; else return p[i]; }- Write a program that will call this function through a pointer and verify that it works. You’ll need an
#includedirective for thecstringheader in your program to use thestrlen()function.
- Write a program that will call this function through a pointer and verify that it works. You’ll need an
- Write a family of overloaded functions called
equal(), which take two arguments of the same type, returning 1 if the arguments are equal, and 0 otherwise. Provide versions havingchar, int, double, andchar*arguments. (Use thestrcmp()function from the runtime library to test for equality of strings. If you don’t know how to usestrcmp(), search for it in the online help. You’ll need an#includedirective for thecstringheader file in your program.) Write test code to verify that the correct versions are called. - At present, when the calculator hits an invalid input character, it prints an error message, but doesn’t show you where the error was in the line. Write an error routine that prints out the input string, putting a caret (
^) below the offending character, like this:12 + 4,2*3 ^ - Add an exponentiation operator,
^, to the calculator, fitting it in alongside*and/. What are the limitations of implementing it in this way, and how can you overcome them? - (Advanced) Extend the calculator so it can handle trig and other math functions, allowing you to input expressions such as:
2 * sin(0.6)- The math library functions all work in radians; provide versions of the trigonometric functions so that the user can use degrees, for example:
2 * sind(30)
WHAT YOU LEARNED IN THIS CHAPTER
| TOPIC | CONCEPT |
|---|---|
| Pointers to functions | A pointer to a function stores the address of a function, plus information about the number and types of parameters and return type for a function. |
| Exceptions | An exception is a way of signaling an error in a program so that the error handling code can be separated from the code for normal operations. |
| Throwing exceptions | You throw an exception with a statement that uses the keyword throw. |
try blocks |
Code that may throw exceptions should be placed in a try block, and the code to handle a particular type of exception is placed in a catch block immediately following the try block. There can be several catch blocks following a try block, each catching a different type of exception. |
| Overloaded functions | Overloaded functions are functions with the same name, but with different parameter lists. |
| Calling an overloaded function | When you call an overloaded function, the function to be called is selected by the compiler based on the number and types of the arguments that you specify. |
| Function templates | A function template is a recipe for generating overloaded functions automatically. |
| Function template parameters | A function template has one or more parameters that are type variables. An instance of the function template — that is, a function definition — is created by the compiler for each function call that corresponds to a unique set of type arguments for the template. |
| Function template instances | You can force the compiler to create a particular instance from a function template by specifying the function you want in a prototype declaration. |
The decltype operator |
You use the decltype operator to determine the type of the result of an expression. |
| Trailing return types | When a function template has a return type that depends on the arguments types, you can specify the return type using the auto keyword and define the return type using the decltype operator following -> after the function header. |